计算全距平均差方差和标准差
- 格式:docx
- 大小:13.05 KB
- 文档页数:5


心理和教育方面的实验或调查所得到的数据,大都具有随机变量的性质。
而对这些随机变量的描述,仅有前一章所讲集中趋势的度量是不够的。
集中量数只描述数据的集中趋势和典型情况,它还不能讲明一组数据的全貌。
数据除典型情况之外,还有变异性的特点。
关于数据变异性即离中趋势进行度量的一组统计量,称作差异量数,这些差异量数有标准差或方差,全距,平均差,四分差及各种百分差等等。
第一节方差与标准差方差(Variance)也称变异数、均方。
作为统计量,常用符号S2表示,作为总体参数,常用符号σ2表示。
它是每个数据与该组数据平均数之差乘方后的均值,即离均差平方后的平均数。
方差,在数理统计中又常称之为二阶中心矩或二级动差。
它是度量数据分散程度的一个特别重要的统计特征数。
标准差(Standarddeviation)即方差的平方根,常用S或SD表示。
假设用σ表示,那么是指总体的标准差,本章只讨论对一组数据的描述,尚未涉及总体咨询题,故本章方差的符号用S2,标准差的符号用S。
符号不同,其含义不完全一样,这一点瞧读者能够给予充分的注重。
一、方差与标准差的计算(一)未分组的数据求方差与标准差全然公式是:〔3—la〕〔3—1b〕表3—1讲明公式3—1a与3—1b的计算步骤表3—1未分组的数据求方差与标准差应用3—1公式的具体步骤:①先求平均数X=36/6=6;②计算X i-X;③求(Xi-X)2即离均差x2;④将各离均差的平方求和(∑x2);⑤代进公式3—1a与3—1b求方差与标准差。
具体结果如下:S2(二)已分组的数据求标准差与方差数据分组后,便以次数分布表的形式出现,这时原始数据不见了,假设计算方差与标准差可用下式:(3—3a)(3—3b)式中d=(Xc-AM)/i,AM为估量平均数Xc为各分组区间的组中值f为各组区间的次数N=Σf为总次数或各组次数和i为组距。
下面以表1—8数据为例,讲明分组数据求方差与标准差的步骤:表3—2次数分布表求方差与标准差具体步骤:①设估量平均数AM,任选一区间的Xc充任;②求d⑧用f乘d,并计算Σfd;④用d与fd相乘得fd2,并求Σfd2;⑤代进公式计算。





方差标准差方差和标准差是统计学中常用的两个概念,它们都是用来衡量数据的离散程度的。
在实际的数据分析中,我们经常会用到这两个指标来描述数据的分布情况。
接下来,我们将详细介绍方差和标准差的概念、计算方法以及它们在实际应用中的意义。
首先,让我们来了解一下方差的概念。
方差是衡量数据离散程度的一个重要指标,它是各个数据与平均值之差的平方的平均数。
方差越大,说明数据的离散程度越大,反之则离散程度较小。
在统计学中,方差通常用σ^2来表示,其中σ代表总体标准差。
接下来,让我们来介绍一下标准差。
标准差是方差的平方根,它也是衡量数据离散程度的一个重要指标。
标准差的计算方法是先计算方差,然后对方差进行开方运算。
标准差的大小和数据的离散程度成正比,离散程度越大,标准差越大,反之则标准差越小。
在统计学中,标准差通常用σ来表示,其中σ代表总体标准差。
在实际应用中,方差和标准差都有着重要的意义。
它们可以帮助我们更好地理解数据的分布情况,从而进行更准确的数据分析和决策。
例如,在投资领域,我们可以利用标准差来衡量投资组合的风险程度,从而选择更合适的投资组合。
在质量控制方面,我们可以利用方差来衡量产品质量的稳定程度,从而及时发现和解决质量问题。
此外,方差和标准差还可以帮助我们进行数据的比较和评估。
通过比较不同数据集的方差和标准差,我们可以更好地了解它们的差异和特点。
在科学研究中,方差和标准差也经常被用来评估实验数据的稳定性和可靠性。
总之,方差和标准差是统计学中非常重要的概念,它们可以帮助我们更好地理解和分析数据。
通过对方差和标准差的深入了解,我们可以更加准确地把握数据的特点和规律,从而为实际应用提供有力的支持。
希望本文能够帮助读者更好地理解方差和标准差的概念和意义,为实际应用提供参考和指导。
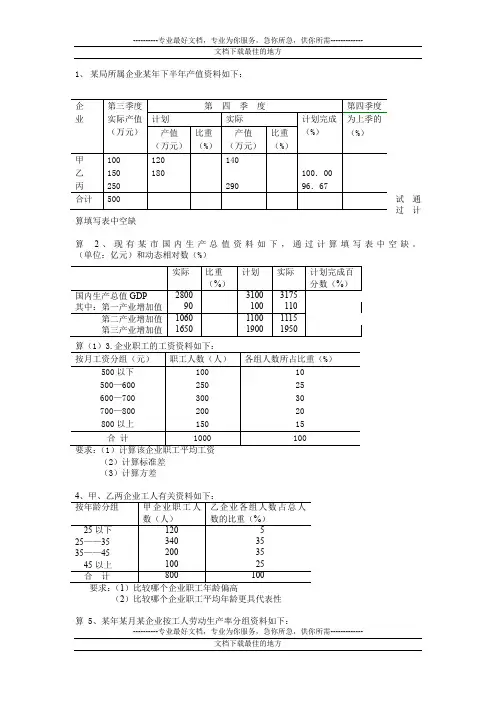
----------专业最好文档,专业为你服务,急你所急,供你所需-------------1、 某局所属企业某年下半年产值资料如下:试通过计算填写表中空缺算 2、现有某市国内生产总值资料如下,通过计算填写表中空缺。
(单位:亿元)和动态相对数(%)(2)计算标准差 (3)计算方差(2)比较哪个企业职工平均年龄更具代表性算 5、某年某月某企业按工人劳动生产率分组资料如下:7、甲、乙两企业工人有关资料如下:要求:(1)比较哪个企业职工工资偏高(2)比较哪个企业职工平均工资更具代表性10、甲、乙两钢铁生产企业某月上旬的钢材供货量资料如下:----------专业最好文档,专业为你服务,急你所急,供你所需-------------11、某校甲、乙两班学生的统计学原理考试成绩分组情况如下:要求:(1)计算各班学生的平均成绩(2)通过计算说明哪个班学生平均成绩的代表性强12求平均利润率。
13、设甲乙两公司进行招员考试,甲公司用百分制记分,乙公司用五分制记分,有关资料如问哪一个公司招员考试的成绩比较整齐?(用标准差)----------专业最好文档,专业为你服务,急你所急,供你所需-----------------------专业最好文档,专业为你服务,急你所急,供你所需-------------3、(1)平均工资=655元 (组中值:450 550 650 750 850。
450*100+550*250+650*300+750*200+850*150=655000。
655000/1000) (2)标准差=120.3元 (3)方差=144754、(1)甲、乙两企业的平均年龄分别为34元、38元,乙企业职工年龄偏高(2)甲、乙两企业的平均差系数分别为22.35%、19.47%,所以乙企业职工的平均年龄更具代表性5、该企业工人平均劳动生产率为67.6件/人 (组中值:55 65 75 85 95。
8250/55+6500/65+5250/75+2550/85+1520/95=366。

统计学练习题(计算题)第四章第一部分总量指标与相对指标4.1 : (1)某企业产值计划完成程度为105%,比上年增长7%,试计算计划规定比上年增长多少?(2)单位产品成本上年为420元,计划规定今年成本降低5%,实际降低6%,试确定今年单位成本的计划数字和实际数字,并计算出降低成本计划完成程度指标。
(3)按计划规定,劳动生产率比上年提高10%实际执行结果提高了12%劳动生产率计划完成程度是多少?4.2 :某市三个企业某年的下半年产值及计划执行情况如下:要求:[1] 试计算并填写上表空栏,并分别说明(3)、(5)、(6)、(7)是何种相对数;[2] 丙企业若能完成计划,从相对数和绝对数两方面说明该市三个企业将超额完成计划多少?4.3 :我国2008年-2013年国内生产总值资料如下:根据上述资料,自行设计表格:(1)计算各年的第一产业、第二产业、第三产业的结构相对指标和比例相对指标;(2)计算我国国内生产总值、第一产业、第二产业、第三产业与上年对比的增长率;(3)简要说明我国经济变动情况。
4.4 :某公司下属四个企业的有关销售资料如下:根据上述资料:(1)完成上述表格中空栏数据的计算;(2)若A能完成计划,则公司的实际销售额将达到多少?比计划超额完成多少?(3)若每个企业的计划完成程度都达到B企业的水平,则公司的实际销售额将达到多少? 比计划超额完成多少?第四章-----第二部分平均指标与变异指标4.5 :已知某地区各工业企业产值计划完成情况以及计划产值资料如下:要求:(1 )根据上述资料计算该地区各企业产值计划的平均完成程度。
(2)如果在上表中所给资料不是计划产值而是实际产值,试计算产值计划平均完成程度。
、4.6 :已知某厂三个车间生产不同的产品,其废品率、产量和工时资料如下:计算:(1)三种产品的平均废品率;(2)假定三个车间生产的是同一产品,但独立完成,产品的平均废品率是多少;(3)假定三个车间是连续加工某一产品,产品的平均废品率是多少。

第四章 差异量教学目的:1.理解全距、四分位距、百分位距、平均差、方差、标准差和差异系数等概念;2.掌握各种差异量指标的计算方法。
数据的分布特征不仅有集中趋势,还有离中趋势。
以动态的眼光,从不同的角度看,数据是向中间变动的,也是向两端变动的。
两组数据可能平均水平相同,但两组数据的分布特征并不完全相同。
【如】:比较以下两组数据 A 组:88、82、73、76、81 B 组:92、86、70、72、80两组平均数,80==B A X X 但R A =88-73=15,R B=92-70=22。
即A 组较集中,B 组较分散。
因此,我们描述一组数据的分布特征,既要描述其集中趋势,也要描述其离中趋势。
差异量:表示一组数据的离中趋势或变异程度的量称为差异量。
常用的差异量指标有全距、四分位距、百分位距、平均差、方差、标准差和差异系数。
第一节全距、四分位距、百分位距一、全距全距:是一组数距中最大值与最小值之差。
优点:意义明确,计算方便。
缺点:反响不灵敏,易受极端值影响。
二、四分位距〔一〕四分位距的的概念四分位距:是指一组按大小顺序排列的数据中间部位50%个频数距离的一半。
QD :表示四分位距; Q 3:表示第三四分位数; Q 1:表示第一四分位数。
所以:四分位距的公式又为: 〔二〕四分位数的计算方法 1、原始数据计算法〔1〕将数据由小到大进行排列;〔2〕分别求出三位四分位数〔点〕;〔3〕代入公式计算。
【例如】:有以下16个数据25、22、29、12、40、15、14、39、37、31、33、19、17、20、35、30,其中四分位距的计算方法如下:〔1〕先将原始数据从小到大排列好;12、14、15、17、*19、20、22、25、*29、30、31、33、*35、37、39、40Q1=18 Md=27 Q3=34〔2〕求出Q1、Md、Q3;〔3〕将Q1、Md、Q3的得数代入公式〔4.1〕。
2、频数分布表计算法利用频数分布表计算公式为:关键是分别计算P75和P25,百分位数计算方法掌握了,这里的计算就不会有什么问题。

《统计学原理》第2套测试题〔第4~5章〕一、单项选择题(在每小题列出的4个备选项中选择1个正确答案并将其字母填写在题后的括号内)1. 作为认识现象的起点、提供反映现象总体特征的基础数据的统计指标是(A)A.总量指标B.平均指标C.相对指标D.价值量指标2.反映各种能源的生产总量和消耗总量,通常采用(A)A.价值量指标B.实物量指标C.标准实物量指标D.劳动量指标3.下列指标中属于时期指标的是(A)A.固定资产总额B.负债总额C.对外贸易总额D.存款余额4.下列指标中属于时点指标的是( B )A负债总额B出生人数C新增固定资产总额D外商投资总额5.为了综合反映全国农产品总量,应采用( B )A.实物量指标B.价值量指标C.劳动量指标D.标准实物量指标6.某企业计划要使本月产品的单位成本比上月降低2%,实际降低了1.5%,则该项计划的计划完成程度为(A)A.75.00%B.99.49%C.100.51%D.133.3%7. 在各种数量分析方法中,最简单、应用最广泛的统计分析方法是( D )A.差异分析B. 动态分析C. 平衡分析D.对比分析8. 某商场某月商品销售额为1200万元,月末商品库存额为400万元,这两个指标( C )A.是时期指标B.是时点指标C.前者是时期指标,后者是时点指标D.前者是时点指标,后者是时期指标9.计量单位可以表现为复名数形式的相对指标是()A.结构相对数B.比例相对数C.动态相对数D.强度相对数10.同一总体的同一指标在不同时间的数值之比,所得的比率称为(D)A.结构相对数B.比例相对数C.强度相对数D.动态相对数11.相对指标来反映总体的内部构成状况,此类相对指标的对比基础是()A.总体数值B.总体中有关部分的数值C.计划数D.基期数值12.两个年级同学的《统计学》平均成绩相等,但成绩的标准差不等,则( D )A.标准差标准差值小,其代表性较大B.标准差值大,其代表性较大C.两个平均数代表性相同D.无法进行正确判断13.基期甲、乙两组工人的平均日产量分别为70件和50件,若报告期两组工人的平均日产量不变,乙组工人数占两组工人总数的比重上升,则报告期两组工人总平均日产量( D )A.上升B.下降C.不变D.可能上升也可能下降 14. 当各变量值的频数相等时,该变量的( B )A.众数不存在B.众数等于均值C.众数等于中位数D.众数等于最大的数据值15. 8个大学生的年龄分别为21、24、28、22、26、24、22、20岁,他们的年龄中位数为(D ) A. 21 B. 22 C. 23 D .2416.有三批产品,废品率分别为1.5%、2%、1%,废品数量相应为25件、30件、45件,则这三批产品平均废品率的计算式应为( C )A.3%1%2%5.1++ B.3%1%2%5.1⨯⨯C.%145%230%5.125453025++++ D.453025%1%2%5.1++++17.某地区城市和乡村平均每人居住面积分别为7.3和18平方米,标准差分别为2.8和6平方米,则居住面积的差异程度( C )A.城市大B.乡村大C.城市和乡村一样D.二者不能比较18.假定某人6个月的收入分别是2800元、2840元、2840元、2840元、2840元、8800元,反映他月收入一般水平应该采用( D )A.算术平均数B.几何平均数C.众数D.调和平均数19.某公司下属10个企业,共有6500名职工。
1、 某局所属企业某年下半年产值资料如下:试通过计算填写表中空缺算 2、现有某市国内生产总值资料如下,通过计算填写表中空缺。
(单位:亿元)和动态相对数(%)(2)计算标准差 (3)计算方差(2)比较哪个企业职工平均年龄更具代表性算 5、某年某月某企业按工人劳动生产率分组资料如下:7、甲、乙两企业工人有关资料如下:要求:(1)比较哪个企业职工工资偏高(2)比较哪个企业职工平均工资更具代表性10、甲、乙两钢铁生产企业某月上旬的钢材供货量资料如下:11、某校甲、乙两班学生的统计学原理考试成绩分组情况如下:要求:(1)计算各班学生的平均成绩(2)通过计算说明哪个班学生平均成绩的代表性强12、某公司所属40个企业资金利润及有关资料如下表:求平均利润率。
13、设甲乙两公司进行招员考试,甲公司用百分制记分,乙公司用五分制记分,有关资料如问哪一个公司招员考试的成绩比较整齐?(用标准差)3、(1)平均工资=655元(组中值:450 550 650 750 850。
450*100+550*250+650*300+750*200+850*150=655000。
655000/1000)(2)标准差=120.3元(3)方差=144754、(1)甲、乙两企业的平均年龄分别为34元、38元,乙企业职工年龄偏高(2)甲、乙两企业的平均差系数分别为22.35%、19.47%,所以乙企业职工的平均年龄更具代表性5、该企业工人平均劳动生产率为67.6件/人(组中值:55 65 75 85 95。
8250/55+6500/65+5250/75+2550/85+1520/95=366。
24070/366).06、各道工序的平均合格率为4967、(1)甲、乙两企业的平均工资分别为1875元、2420元,所以乙企业职工工资偏高(2)甲、乙两企业的平均差系数分别为41.6%、36.6%,所以乙企业职工的平均工资更具代表性8、平均计划完成程度为108.09% (组中值:97.5 102.5 107.5 105 125。
第二章数据描述1、组距=上限—下限2、简单平均数:x=Σx/n3、加权平均数:x=Σxf/Σf4、全距: R=x max-x min5、方差和标准差:方差是将各个变量值和其均值离差平方的平均数。
其计算公式:未分组的计算公式:σ2=Σ(x-x)2/n分组的计算公式:σ2=Σ(x-x)2f/Σf样本标准差则是方差的平方根:未分组的计算公式:s=[Σ(x-x)2/(n-1)]1/2分组的计算公式:s=[Σ(x-x)2f/(Σf-1)] 1/2σ=[Σ(x-x)/n] 1/26、离散系数:总体数据的离散系数:Vσ=σ/x样本数据的离散系数:V s=s/x10、标准分数:标准分数也称标准化值或Z分数,它是变量值与其平均数的离差除以标准差后的值,用以测定某一个数据在该组数据的相对位置。
其计算公式为:Z i=(x i-x)/s标准分数的最大的用途是可以把两组数组中的两个不同均值、不同标准差的数据进行对比,以判断它们在各组中的位置。
第三章参数估计1、统计量的标准误差:(样本误差)(1)在重复抽样时;样本标准误差:σx=σ/n或σx=s/n样本的比例误差可表示为:σp=[π(1-π)/n]1/2或σp=[p(1-p)/n] 1/2(2)不重复抽样时:σ2x=σ2/n×(N-n/N-1)σ2p=p(1-p)/n×(N-n/N-1)2、估计总体均值时样本量的确定,在重复抽样的条件下:n= Z2σ2/E23、估计总体比例时样本量的确定,在重复抽样的条件下:n=Z2×p(1-p)/E24、(1)在大样本情况下,样本均值的抽样分布服从正态分布,因此采用正态分布的检验统计量,当总体方差已知时,总体均值检验统计量为:Z=(x-μ)/( σ/n)(2)当总体方差未知时,可以用样本方差来代替,此时总体均值检验的统计量为:Z=(x-μ)/( s/n)5、小样本的检验:在小样本(n<30)情况下,检验时,首先假定总体均值服从正态分布。
统计学原理计算复习题1、以下为10位工人2005年11月11日的产量资料:(单位:件):100 120 120 180 120 192 120 136 429 120。
试据以计算其中位数、均值及众数。
2、某厂2005年第四季度各月的生产工人人数和产量资料见下表:时间10月11月12月月初人数(人)200020802200产量(万件)260280369又知2005年12月31日的生产工人数为2020人,试计算第四季度的劳动生产率。
3、从一火柴厂随机抽取了100盒进行调查,经检查平均每盒装有火柴98支。
标准差10支,试以95%的概率(置信水平)推断该仓库中平均每盒火柴支数的可能范围。
4、某商店2005年的营业额为12890万元,上年的营业额为9600万元,零售价格比上年上升了11.5%,试对该商店营业额的变动进行因素分析。
5.某国对外贸易总额2003年比上年增长7.9%,2004年比上年增长4.5%,2005年比上年增长10%,试写出2002~2005年每年平均增长速度的计算公式(不要求算出结果,只要求写出计算公式即可)。
6.某地区2002~2006年粮食产量资料如下表:年份20022003200420052006产量(万吨)240300320340380试用最小二乘法配合直线趋势方程,并预测2007年的粮食产量。
7.某商店有三种商品的有关资料如下表所示:商品销售额(万元)价格上升或下降的%2005年2006年D3*******E500600-12G404510合计9001045-试计算三种商品的价格总指数,以及由于价格变动对商品销售额的影响额。
8、某灯泡的质量标准是平均使用寿命不得低于1200小时。
已知该灯泡的使用寿命服从标准差为100小时的正态分布。
一商场打算从该厂进货,随机抽取121件进行检验,测得其平均寿命为1100小时,问商场是否应决定购进这批灯泡?(已知)9、某班40名学生统计学考试成绩分别为:68 89 88 84 86 87 75 73 72 6875 82 97 58 81 54 79 76 95 7671 60 90 65 76 72 76 85 89 9264 57 83 81 78 77 72 61 70 81 学校规定:60分以下为不及格,60─70分为及格,70─80分为中,80─90分为良,90─100分为优。
计算全距、平均差、方差和标准差
一、全距 R(range)
全距是一组数据中的最大值(maximum)与该组数据中最小值(minimum)之差,又称极差。
R=Xmax-Xmin
一般用于研究的预备阶段,用它检查数据的分布范围,以便确定如何进行统计分析
原始数据计算公式
三、四分位差(Quartile)
四分位差是第一个四分位数与第三个四分位数之差计算公式为
Q=Q
3-Q
1
四、方差与标准差
方差:又称为变异数、均方,是每个数据与该组数据平均数之差乘方后的均值,是表示一组数据离散程度的统计指标。
样本的方差用表示,总体的方差用表示。
标准差是方差的算术平方根。
一般样本的标准差用 S 表示,总体的标准差用表示。
标准差和方差是描述数据离散程度的最常用的差异量。
分组数据方差与标准差的计算公式
方差与标准差的性质
•方差是对一组数据中各种变异的总和的测量,具有可加性和可分解性特点。
•标准差是一组数据方差的算术平方根,它不可以进行代数计算,但有以下特性:
总体方差、标准差或者方差、标准才差的合成
•方差具有可加性的特点。
当已知几个小组数据的方差或标准差时,可
以计算几个小组联合在一起的总的方差或标准差。
•需要注意的是,只有在应用同一种观测手段,测量的是同一种特质,只是样本不同的数据时,才能计算合成方差或标准差。
方差和标准差的优点:
方差与标准差是表示一组数据离散程度的最好指标,其值越大,离散程度越大。
应用方差和标准差表示一组数据的离散程度,须注意必须是同一类数据(即同一种测量工具的测量结果),而且被比较样本的水平比较接近。
优点:
•反应灵敏。
每个数据发生变化,方差与标准差也随之变化
•有一定计算公式的严密确定
•容易计算
•受抽样变动的影响小
•简单明了
•方差具有可加性(区分变异源,组间/组内)
五、差异系数(coefficient of variation)
差异系数指标准差与其算术平均数的百分比,它是没有单位的相对数。
用CV表示。
何种情况下运用差异系数:
•两个或两个以上样本所测特质不同,即所使用的观测工具不同,如何比较两者的离散程度?
•即使使用同一种观测量具,但样本水平相差较大,如何比较其离散程度?
差异系数的作用
•比较不同单位资料的差异程度
•比较单位相同而平均数相差较大的两组资料的差异程度
•可判断特殊差异情况
根据经验,一般CV值常在5%-35%之间。
如果CV大于35%时,可怀疑所求得的平均数是否失去了意义;如果CV小于5%时,可怀疑平均数与标准差是否计算有误。
六、标准分数(standard score)
1、概念
标准分数,又称为基分数或Z分数(Z-score),是以标准差为单位,反映一个原始分数在团体中所处位置。
具体来说,Z分数表示原始分数在以平均数为中心时的相对位置。
•标准分数从分数对平均数的相对地位、该组分数的离中趋势两个方面来表示原始分数的地位。
•Z分数可以表明原始分数在团体中的相对位置,因此称为相对位置量数。
2、计算
把原始分数转换成Z分数,就把单位不等距的和缺乏明确参照点的分数转换成以标准差为单位、以平均数为参照点的分数。
线性变换
标准分数带有小数和负值,为了克服标准分数出现的小数、负数和不易为人们所接受等缺点,常常是将其转换成正态标准分数。
例如:早期智力测验中运用智力商数表示智力测查的指标这种表示智力的方法后来被离差智商取代:
标准分数的性质
•Z分数无实际单位,是以平均数为参照点、以标准差为单位的相对量。
•一组原始分数得到的Z分数既有正值,也有负值,所有原始分数的Z分数之和为零。
•一组原始数据中,各个Z分数的标准差为1。
标准分数的应用
•用于比较几个分属性质不同的观测值在各自数据分布中相对位置的高低。
•表示标准测验分数。
经过标准化的心理和教育测验,常常用标准分数表示测验结果。
标准分数的优点
•可比性:标准分数以团体的平均数为基准,以标准差为单位,因而具有可比性。
•可加性:标准分数使不同的原始分数具有相同的参照点,因而具有可加性。
•明确性:标准分数较原始分数的意义更为明确。
•合理性:标准分数保证了不同性质的分数在总分数中的权重相同,使分数更合理地反映事实。
七、百分位数与百分位差
把一个次数分布排序后,分为100个单位。
百分位数就是次数分布中相对于某个特定百分点的原始分数,它表明在次数分布中特定个案百分比低于该分数。
百分位数用P m表示
百分位差(距)
•百分位差是指两个百分位数(percentile)之差。
•常用的百分位距有两种:
P90-P10和 P93-P7。
第三节数据的分布形状
一、正态分布
二、偏态系数(skewness SK)
•当数据较多的出现在均值的一侧时,数据分布左右不对称,此时,数据分布称为偏态分布。
•描述变量非对称分布的数字特征是偏态系数,也称为偏度。
•偏态分布有正偏态分布和负偏态分布两种。
当N>200以上时,计算的偏态系数才是可靠的。
SK>0为正偏态,SK<0为负偏态,SK=0 为正态。
•如果偏态系数的绝对值大于1,则说明数据的分布与正态分布有明显的不同
三、峰态系数(kurtosis Ku)
Ku以为判断值,小于为高狭峰,大于为低阔峰
四、偏态系数与峰态系数的计算方法
1、皮尔逊偏态量数法
2、峰度、偏度检验法。