shark工作流引擎表结构分析
- 格式:doc
- 大小:366.50 KB
- 文档页数:16

工作流引擎介绍工作流引擎技术架构工作流引擎是一种将工作流程转换为计算机可执行的流程的软件系统。
它允许用户通过图形化界面设计工作流程,并通过规则引擎和执行引擎实现工作流程的自动化执行和管理。
工作流引擎的设计是基于商业流程管理(BPM)理念的,它提供了一种能够将工作从一个任务转移到另一个任务的方式,从而提高工作效率和效果。
2.规则引擎:用于根据定义的规则和条件来自动决策工作流程中的走向和下一步操作。
规则引擎通常基于一套规则语言或表达式,可以动态地调整和优化工作流程的执行。
3.执行引擎:负责实际执行和管理工作流程。
执行引擎根据工作流程定义的顺序和条件,逐步执行工作流程的各个步骤,并将结果传递给下一步骤。
4.通信接口:用于与其他系统或应用程序进行交互。
通信接口可以接收和发送消息、数据和事件,从而实现工作流程与外部系统的集成和交互。
5.监控和报告模块:用于实时监控和跟踪工作流程的执行情况,并生成相应的报告和统计数据。
监控和报告模块可以显示工作流程的进度、延迟、错误和资源利用等信息。
6.安全和权限控制:用于管理和控制工作流程的访问权限和安全性。
安全和权限控制模块可以限制用户对工作流程的访问和操作,确保只有经过授权的用户才能执行和管理工作流程。
2.定义规则和条件:使用规则引擎定义工作流程中的规则和条件,以实现自动决策和分支。
3.配置和集成外部系统:使用通信接口将工作流程与其他系统或应用程序进行集成,以实现数据和消息的交换和共享。
4.执行和管理工作流程:使用执行引擎逐步执行和管理工作流程的各个步骤,并将结果传递给下一步骤。
5.监控和报告工作流程:使用监控和报告模块实时监控和跟踪工作流程的执行情况,并生成相应的报告和统计数据。
1.业务流程管理:工作流引擎可以用于自动化和管理各种业务流程,如销售、采购、审批、投诉处理等。
它可以帮助企业提高工作效率和质量,并加快决策和执行速度。
2.工作协同和协作:工作流引擎可以用于协调和协作多个部门或团队之间的工作,如项目管理、文档审批、会议安排等。

dolphinscheduler 表结构DolphinScheduler是一个分布式易用的DAG工作流任务调度系统,它主要由元数据库和项目数据库两个数据库组成。
以下是DolphinScheduler的核心表结构:元数据库表结构:1. ds_datasource:数据源管理表,用于存储与数据源相关的信息。
2. ds_process:工作流任务表,用于存储工作流任务的相关信息。
3. ds_project:项目表,用于存储项目的相关信息。
4. ds_user:用户表,用于存储用户的相关信息。
5. ds_user_group_relation:用户与用户组关联表,用于存储用户和用户组之间的关系。
项目数据库表结构:1. access_token:用户访问令牌表,用于存储用户的访问令牌信息。
2. cmd_record:任务执行记录表,用于存储任务的执行记录。
3. process_definition:工作流定义表,用于存储工作流的定义信息。
4. process_dependency:工作流依赖表,用于存储工作流之间的依赖关系。
5. process_instance:工作流实例表,用于存储工作流的实例信息。
6. process_instance_relation:工作流实例关系表,用于存储工作流实例之间的关系。
7. process_task_relation:工作流任务关系表,用于存储工作流任务之间的关系。
8. project_source_files:项目源文件表,用于存储项目的源文件信息。
9. resource:资源表,用于存储任务所需的资源信息。
以上是DolphinScheduler的主要表结构,它们一起构成了DolphinScheduler的数据模型,用于存储和管理任务调度系统的相关信息。

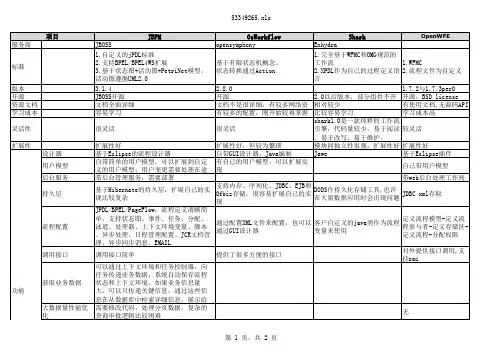


工作流开源框架JBPM:简介Java Business Process Management(业务流程管理),覆盖了业务流程管理、工作流、服务协作等领域的一个开源的、灵活的。
Jbpm是公开开源代码项目,它使用要遵循Apache License.Jbpm在2004年10月18日,发布了2.0版本,并在同一天加入了Jboss,成为了Jboss企业中间件平台的一个组成部分,jbpm也进入了一个全新的发展时代。
优势将业务流程复杂的系统结构清晰化,提供系统运行的灵活性解耦系统业务流程(流程独立,可以使用工具定义和建模,利于跟踪、监控、管理、调度、优化和重整)提供系统的灵活性(系统流程定义生产环境的修改和调整,用户和外部工具交互,任务的动态分派)使用使用简单,易上手,源代码也易读,作嵌入式工作流是一个很好的选择OSWORKFLOW:简介完全用java语言编写的开放源代码的工作流引擎,具有显著的灵活性及完全面向有技术背景的用户的特点。
用户可以根据自身的需求利用这款开源软件设计简单或是复杂的工作流。
优势绝对的灵活性、较为简单的和灵活的实现方式不足非标准脚本语言,工作流引擎对于自动任务支持尚不完善OpenWFE:简介John Mettraux所领导的项目组开发的一套符合WFMC标准的工作流管理系统组件。
项目使用JAVA语言编写,具有功能完善、通用型好、扩展能力强等特点。
其除了能够为各种开发环境提供一个符合要求的工作流引擎之外,也能够直接作为一个完整有效的工作流管理系统进行使用。
其主要功能模块包括优势可视化工作流、动态表单、智能报表, 丰富的应用模板开源工作流产品占有率趋势2004年前,国内的工作流引擎使用率最高的是osworkflow到2004年底,Shark就占有了明显的优势地位,分析有如下原因:国内的企业都看中XPDL,因为这意味着在产品说明书中又可以吹牛说“我们遵循WFMC……”Shark的确是一套不错的工作流引擎,就算你只是想学习XPDL,你也可以从学习Shark开始jbpm3支持bpel4ws的核心部分。

过程视图是工作流模型的核心视图。
它描述企业的业务流程,定义业务过程中包含的活动以及这些活动之间的逻辑关系。
活动和活动间以连接弧表示控制关系。
通过描述活动的基本属性,如活动由谁执行,有哪些人员、组织或盟员企业负责执行,活动执行需要的软件(如应用程序)和硬件(如机床设备)资源,以及活动的触发条件、执行状态等,可以建立过程视图、资源视图和组织视图的关系。
过程视图是本文研究的主要内容,本文通过ECA规则来表达过程视图。
基于ECA规则和元操作的工作流建模原理3.1 工作流模型的结构图:工作流模型的结构1.1.1过程视图过程视图是工作流模型的核心视图。
它描述企业的业务流程,定义业务过程中包含的活动以及这些活动之间的逻辑关系。
活动和活动间以连接弧表示控制关系。
通过描述活动的基本属性,如活动由谁执行,有哪些人员、组织或盟员企业负责执行,活动执行需要的软件(如应用程序)和硬件(如机床设备)资源,以及活动的触发条件、执行状态等,可以建立过程视图、资源视图和组织视图的关系。
过程视图是本文研究的主要内容,本文通过ECA规则来表达过程视图。
1.1.2组织视图组织视图描述企业中的组织单元和组织单元间的关系。
组织单元是具有一定功能和责任的组织实体,一般会承担过程模型产生的各种任务。
组织单元之间往往存在从属或协作关系,形成一定的对应关系。
本文对组织视图描述中,采用一种面向对象的关系模型,不同于传统的层次结构。
是在组织模型中引入类的概念(如角色类、组织类、人员类、职位类等),建立类之间的关系模型,支持层次化的查找和匹配规则,便于工作流的任务分配和执行者绑定。
1.1.3资源视图资源视图描述企业中资源的类型以及资源实体的属性。
资源是工作流模型中非常重要的一个概念,是活动可以执行的必备条件。
资源类型可以是执行活动所需的软件和硬件设施等,或者是活动执行后产生的新的物理实体。
组织视图和资源视图之间存在着映射关系,即每一个资源实体都有与其对应的责任组织单元,该组织单元负责对此资源实体的使用和维护。


工作流引擎的设计与实现1.引言随着企业业务处理的复杂性与数据量增大,工作流引擎已成为管理与处理企业级业务的核心技术之一。
在各大互联网公司中,工作流引擎已广泛应用于业务流程自动化、流程优化、审核管理等领域。
通过对工作流引擎的研究,本文旨在探讨工作流引擎的设计与实现。
2.工作流引擎概述工作流引擎是一个处理、管理和监视任务的计算机系统。
其包含的工作流管理系统(Workflow Management System,WMS)提供了全面的业务流程管理能力,可以通过定义和控制业务流程的任务、行为和数据,使得被管理的业务流程更为规范化、透明化和优化化。
通过定义和编排业务流程模型,工作流引擎可以实现高度定制化的任务执行。
同时,工作流引擎还具备自适应与灵活的特性,能够自动识别出任务的优先级,并可根据任务的优先级及相关属性,作出合适的调度和执行决策。
工作流引擎通过任务的流转和自动化处理,提升业务的效率与准确性,以及加强了业务可观性,使业务控制变得更加智能化和可预测。
3.工作流引擎原理工作流引擎的本质是一个状态机。
在状态机中,每个状态都代表业务流程中的一个阶段,状态之间的转移代表业务流程的转换,任务被分配到不同的状态机阶段,在每个阶段的状态中执行不同的业务处理,以完成整个业务流程。
同时,状态机还会在状态转换的同时触发执行相关的事件或任务,以驱动整个流程向前发展。
4.工作流引擎设计工作流引擎的设计应该从业务流程的需求出发,根据业务流程中任务和行为定义出抽象状态机,再通过策略、规则、算法等方式定义出不同状态的优先级和状态转移的决策规则。
事实上,工作流引擎的设计需要考虑到众多的复杂问题,如流程调度、任务计划、任务并发、异常处理、任务可视化和监控等。
因此,工作流引擎的设计必须考虑生命周期、模型、任务分层、任务优先级、任务理解和自动化级别等因素。
5.工作流引擎实现工作流引擎的实现需要同时考虑到效率和可靠性的问题。
在开发过程中,需要借助一些技术和框架,使得开发人员能够更好地实现工作流引擎,实现较高的可靠性成本效益比。

流程引擎表结构说明
流程引擎是一种用于管理和自动化业务流程的软件工具。
它可以帮助企业优化业务流程,提高效率和准确性。
流程引擎的核心是其表结构,它定义了流程引擎的数据模型和流程定义。
流程引擎的表结构通常包括以下几个主要表:
1. 流程定义表:该表存储了所有的流程定义信息,包括流程名称、流程描述、流程版本、流程状态等。
每个流程定义都有一个唯一的标识符,用于区分不同的流程。
2. 流程实例表:该表存储了所有的流程实例信息,包括流程实例编号、流程定义编号、流程状态、流程开始时间、流程结束时间等。
每个流程实例都有一个唯一的标识符,用于区分不同的流程实例。
3. 流程任务表:该表存储了所有的流程任务信息,包括任务编号、任务名称、任务描述、任务状态、任务创建时间、任务完成时间等。
每个流程任务都有一个唯一的标识符,用于区分不同的任务。
4. 流程变量表:该表存储了所有的流程变量信息,包括变量名称、变量值、变量类型等。
流程变量可以用于在流程中传递数据和状态信息。
5. 流程历史表:该表存储了所有的流程历史信息,包括流程实例编号、流程定义编号、流程状态、流程开始时间、流程结束时间、流
程执行时间等。
流程历史可以用于分析和优化业务流程。
以上是流程引擎的主要表结构,不同的流程引擎可能会有一些额外的表或字段,但基本上都是围绕这些表展开的。
流程引擎的表结构是其核心,它定义了流程引擎的数据模型和流程定义,是流程引擎实现自动化流程的基础。

工作流引擎功能概要1.流程设计与建模:工作流引擎提供了可视化的流程设计工具,使业务人员能够根据实际需要自定义不同的工作流程。
通过拖拽和连接不同的节点,可以设计出复杂的流程,并为每个节点设置不同的执行条件和规则。
2.流程监控与跟踪:工作流引擎可以实时监控和跟踪流程的执行情况。
用户可以随时查看每个流程实例的进度和状态,了解当前工作在哪个节点,以及是否有待处理的任务或通知。
3.角色与权限管理:工作流引擎支持对不同角色的用户进行权限管理。
可以为每个角色定义不同的权限和操作范围,确保只有具备相应权限的人员才能执行或查看一些流程节点。
4.任务分配与调度:工作流引擎可以自动将任务分配给指定的用户或角色,并根据不同的规则和优先级进行任务调度。
用户可以根据自己的工作负载和可用时间,灵活地接收或拒绝任务,并设置任务的截止日期和提醒通知。
5.表单与数据集成:工作流引擎可以与企业现有的表单系统和数据库进行集成。
用户可以在流程的每个节点上填写或修改相应的表单数据,并将数据与其他系统进行交互或整合。
6.通知与协作:工作流引擎支持通过邮件、短信、系统提醒等方式进行实时通知和沟通。
当流程的一些节点需要用户的处理或审批时,系统会自动发送通知,并提供相应的协作工具,如讨论区或注释功能。
7.报表与分析:工作流引擎可以生成各种统计数据和图表,用于分析和监控流程的效率和质量。
用户可以基于这些数据进行业务决策和流程改进,提高组织的整体绩效。
8.扩展与集成:工作流引擎通常支持与其他系统的集成,如ERP系统、CRM系统等。
通过API接口和插件机制,企业可以将工作流引擎与现有系统进行无缝对接,实现数据的共享和流转。
总结起来,工作流引擎是一种强大的工具,可以帮助企业进行流程管理和优化。
通过工作流引擎,企业可以实现流程自动化、任务分配和调度、流程监控与跟踪、角色与权限管理等功能,提高工作效率和质量,降低错误和风险。
同时,工作流引擎还可以与其他系统进行集成,提供完整的解决方案,满足企业不同层次和需求的用户。
一种基于关系数据库的工作流管理系统的设计与实现摘要:论述了一种基于关系数据库的工作流管理系统的设计与实现。
该工作流管理系统不仅拥有工作流管理系统应有的前向调度、回退调度、用户任务列表的展示等功能,还有效地利用了关系数据库的成熟技术,节省了工作流管理系统的开发成本。
关键词:关系数据库;工作流引擎;流程定义;流程实例abstract: the authors describe in this paper a workflow management system which is based on relational database. the wokflow management system not only has forward and backward scheduling and task list which is necessary to a complete workflow management system, but also uses the mature technology of relational database which can save its development cost.key words: relational database; workflow engine; process definition; process instance0 引言目前,市面上有很多开源工作流软件,最常用的有shark、osworkflow和jbpm。
其中shark的流程定义语言采用xpdl,osworkflow依赖于有限状态机,jbpm综合运用了状态图、活动图和petrinet。
各大厂商开发的工作流产品侧重于流程管理的通用性,导致系统非常复杂,再加上软件设计文档的缺乏,对于中小型项目来说,使用门槛比较高,因此很多公司选择开发适合本公司的工作流组件。
但开发一个运行稳定、有数据备份和恢复功能、支持并发、支持事务的工作流引擎,成本非常高。
表结构及表与其各字段属性说明整理人:路华金------------------------------------------------------------------------------------------------前言:1, ccflow 有自动修复数据表功能, 所以表的字段的变化不需要用户干预由ccflow自动完成. 所以如果你看到sql的错误,在执行一般就可以解决,如果解决不了,就执行一次数据库修复工具。
2, ccflow 有自动增加字段备注功能,所以每个字段的中文名称都已经增加了数据表的字段的备注属性上了,请注意对照,以方便您阅读ccflow.3, 了解ccflow 的表结构是您二次开发的基础,所以ccflow的高级用户需要熟悉每个表,掌握必要的表结构. 但是没有必要全部掌握。
4, ccflow 表命名规则是前缀+"_"+表名. 大多以英文缩写或者,拼音大写组成. 比如: Port_Emp 人员表. WF_Flow 流程表。
5,一个流程就有一个流程ID,叫OIDccflow 表分为框架表、流程规则描述表、流程数据运行表、公共表4大类:---------------------------------------------------------------------------------------------------------------------1, 框架表.通常以Sys_ 与Port_ 开头. 也可以称为ccflow系统表. 它是存储系统运行的基础信息. 没有必要多了解它们.列举如下:Port_Emp: 操作员表.Port_Station: 岗位表Port_Dept: 部门表Port_EmpStation: 人员岗位表.Port_EmpDept: 人员部门对应表.Port_Unit: 集团公司表,对于集团类的用户有效.【WF_Node】节点名称修改表(节点名称修改后保存的物理表)[NO]节点编号,[NAME] 节点名称【Sys_MapData: 映射主表】---新建流程或节点表、表单表、从表信息(只要要新建一张表的,都会在此出现),会在此表插入一条记录[No]主键,值=相应物理表的表名,[Name]描述(如节点就节点名称,流程就流程名称),[EnPK]实体主键,[SearchKeys]查询键,[PTable]物理表(值=相应物理表的表名),[Dtls]明细表(从表),[DBURL],[Tag],[FrmType]表单类型,[FK_FrmSort]表单类别,[AttrsInTable]在表格中显示的列,[AppType]应用类型,[Designer]设计者,[DesignerUnit]单位,[DesignerContact]联系方式,[FK_Flow]流程表单属性:FK_Flow,[FormType]流程表单属性:表单类型,枚举类型:0 傻瓜表单;1 自由表单;2 自定义表单;3 SDK表单;9 禁用(对多表单流程有效);,[URL]流程表单属性:Url,[FrmW]表单宽度,[FrmH]表单高度【Sys_MapAttr: 字段表】----保存在Sys_MapData表中保存的每一张表的各个字段属性(如在节点新建一个表单,表单里的各个属性及信息都会保存在这里。
本文一步步讲解如何从获得、编译、建立环境到运行Shark 的方法。
按照本文给出的步骤,Shark 可实际运行起来。
应该注意的是,本文所用数据库为MySQL,并在windows 2000 上运行。
本文是从很多笔记和Shark 小组提供的线索中总结出来的,这种经历痛苦而又幸运。
之所以我没有使用可执行安装程序的原因是,我想从零开始来构建Shark。
你最好拥有或能够安装下列程序,但这并不是shark 所必需的,仅仅是本文档的要求:1、MySQL - 我使用4.0.16-nt2、MySQL Connector - 我选择mysql-connector-java-3.0.11-stable-bin.jar3、Java - 我使用Sun j2sdk 版本为1.4.2_044、CVS, Winzip, 等等首先,自己独立安装它们,然后开始我们的shark 学习!获得Shark我个人的安装方式是把所有的源文件拷贝到C:\dev\Shark 目录下,最后的输出路径是C:\Shark。
你也可以自己放在任何地方,不过要调整以下命令。
首先下载Shark 1.0 /project/showfiles.php?group_id=74&release_id=512 对于Windows 系统,我下载zip 文件并解包到C:\dev\Shark 目录。
如果你想获取CVS (/scm/?group_id=74)上的版本,则命令说明如下:通过使用下面的命令集,你可以用anonymous 从shark 的cvs 库取到代码。
下面的modulename 指你想要checkout 的模块名称,如果你不知道模块名称,请用”.”代替。
如果有提示要求输入口令,按enter 就可以了。
cvs -d:pserver:anonymous@:/cvsroot/shark logincvs -z3 -d:pserver:anonymous@:/cvsroot/shark co modulename在使用CVS 的情况下,我把/dev/Shark 作为CVS 根目录。
国内外主流工作流引擎及规则引擎分析在当今信息化时代,工作流引擎和规则引擎是众多企业必备的核心技术。
工作流引擎主要用于定义、执行和管理业务过程,而规则引擎则用于管理业务规则的执行。
本文将分析国内外主流的工作流引擎和规则引擎。
工作流引擎是一种将业务逻辑以图形方式表示的工具,可以自动化、控制和优化组织中的业务流程。
国外主流的工作流引擎有IBM的WebSphere Business Process Manager、Oracle的BPEL Process Manager、SAP的NetWeaver BPM等。
其中,IBM的WebSphere Business Process Manager集成了业务流程管理、规则引擎和实时决策管理,提供了一套完整的商业流程管理解决方案;Oracle的BPEL Process Manager基于领先的Web服务技术,可以将不同系统中的业务流程进行集成和协作;SAP的NetWeaver BPM是一款基于开放标准的工作流引擎,可以与SAP的其他系统进行无缝集成。
国内主流的工作流引擎有华为的UniFlow、用友的U8 WorkFlow、金蝶的K/3 WorkFlow等。
华为的UniFlow是一款集成化的工作流引擎,支持多模式流程建模和多操作方式,能够满足不同行业的需求;用友的U8 WorkFlow基于用友NC软件平台,提供了强大的流程建模能力和灵活的流程执行机制;金蝶的K/3 WorkFlow是一款企业级工作流引擎,能够支持大规模的用户并发操作和高效的流程执行。
规则引擎是一种通过抽象和集成业务规则,实现业务逻辑的可配置化和易于管理的技术。
国外主流的规则引擎有Drools、IBM ODM、Oracle OBR等。
Drools是一款开源的规则引擎,具有灵活性和易用性,支持规则的动态加载和修改;IBM ODM是IBM的一款商业规则引擎,提供了强大的规则管理和决策管理功能;Oracle OBR则是Oracle的一款规则引擎,可以将业务规则集成到企业应用中,并提供了一套完整的规则管理平台。
SHARK工作流引擎的表结构
背景:
Shark作为一个满足XPDL规范的开源工作流引擎,由于有JAWE作为定义工具,现有的很多流程表达,接口的定义都比较丰富。
在数据库的数
据结构表达和代码结构上也有很多优点。
当然,Shark 还是在传统的关系数据库的基础上,提出了一个适用于关键业务开发的基于关系结构的工作流引擎的表结构。
关键词:表结构、工作流引擎、shark、数据结构
1数据库表的关系图
Shark中共含有44个表,分别表达不同的数据结构,对应表数据内容和功能的对应关系,分为用户管理、事件管理、包管理、流程流转的控制数据管理等部分。
1.1用户管理
系统的用户和用户组的基本信息
1.2事件管理
在流程运转过程中,针对流程启动和结束,上下文数据,状态数据的改变,任务结束等事件,都记录了变化的前后过程。
1.3包管理
1.4.1在流程定义的参与者和系统真正用户之间有对应关系
1.4.2应用和调用工具类之间的映射
1.5辅助表
1.6流程流转控制数据管理
2Shark持久层对表的封装
class=" usergroup.HibernateUser" table="usertable"
hibernate.participantmappin g.cfg.xml HibernateParticipant.hbm.xml
class =" partmappersistence.data.HibernateParticipant"
table="participant"
<joined-subclass
name="com.cs3.workflow.partmappersistence.data.HibernateProcessLevelParticipa table="proclevelparticipant">
<joined-subclass
name="com.cs3.workflow.partmappersistence.data.HibernatePackageLevelParticip table="packlevelparticipant">
HibernateGroupUser.hbm.xml
class =" partmappersistence.data.HibernateGroupUser"
table="groupuser"
HibernateNormalUser.hbm.xml
class=" partmappersistence.data.HibernateNormalUser"
table="normaluser"
HibernateProcessPartMap.hbm.xml"
class=" partmappersistence.data.HibernateProcessPartMap"
table="process"
<many-to-one name="pck" column="packageoid"
class=" partmappersistence.data.HibernatePackage" not-null="true"/> <bag name="processLevelParticipant" lazy="false" inverse="false">
<key column="processoid"/>
<one-to-many
class=" partmappersistence.data.HibernateProcessLevelParticipant"/> </bag>
HibernatePackage.hbm.xml
class="partmappersistence.data.HibernatePackage"
table="package"
<bag name="processes" lazy="false" inverse="true">
<key column="packageoid"/>
<one-to-many class=" partmappersistence.data.HibernateProcessPartMap"/> </bag>
<bag name="packageLevelParticipant" lazy="false" inverse="true">
<key column="packageoid"/>
<one-to-many class=" partmappersistence.data.HibernatePackageLevelParticip </bag>
hibernate.appmapping.cfg.x ml (比较怪异,文件直接含有hbm.xml的内容<hibernate-mapping)
<hibernate-mapping>
<class name="com.cs3.framework.test.HibernateActivity" table="activities"
<hibernate-mapping>
hibernate.applicationmappin g.cfg.xml HibernateApplicationMapping.hbm.xml
class="com.cs3.workflow.appmappersistence.HibernateApplicationMap"
table="applicationmappings"
hibernate.processlocking.cf g.xml HibernateLockEntry.hbm.xml
class=" processlocking.HibernateLockEntry"
table="locktable"
表三、独立的*.hbm.xml文件
3功能对应数据库表数据
3.1启动和登录
3.2用户管理
3.3存储库管理
3.4包管理
3.5流程化实例管理
3.6管理工作列表
3.7应用程序映射
3.8流程监控
4附录
4.1.1持久对象和表的对应关系
表二、持久对象和表的对应关系(静态数据)
5应用实例
待续…
见
附:
涉及用户管理的外部接口:
接口(wfservice)实现类及描述UserGroupAdministration UserGroupAdmin ParticipantMappingAdministration ParticipantMappingsAdministrationImpl ParticipantMap ParticipantMapImpl。