浙江移动基于Hadoop的详单系统建设方案v1.97
- 格式:pptx
- 大小:2.20 MB
- 文档页数:54

中国移动一级业务运营支撑中心工程帐务枢纽和客服枢纽系统系统集成技术规范书2002年4月目次1.总则 (1)2.技术建议书要求 (2)3.项目简述 (3)3.1.一级业务中心系统概述 (3)3.2.现有相关系统的现状 (3)3.2.1. 全国中心现状 (3)3.2.2. 省中心现状 (4)3.3.本期工程主要设想 (4)4.本期工程要实现的功能 (4)4.1.一级业务中心的系统模型 (4)4.2.本期工程主要实现的功能 (5)4.2.1. 全国客服枢纽 (5)4.2.2. 全国帐务枢纽 (6)4.2.3. 结算处理 (7)4.2.4. 集团用户接口 (7)5.应用软件部分 (8)5.1.应用软件的技术要求 (8)5.2.开发和运行环境 (9)5.3.应用软件其它要求 (9)6.系统集成部分 (10)7.数据库部分 (12)7.1.需求说明 (12)7.2.数据库系统的技术要求 (12)8.网络设备部分 (14)8.1.概述 (14)8.2.本期工程的主要接口要求 (14)8.2.1. 与省中心的接口 (14)8.2.2. 与公司内其它计算机系统之间的接口 (14)8.2.3. 与非中国移动的计算机系统之间的通信 (15)8.2.4. 一级业务中心与其容灾备份中心间的接口 (16)8.3.IP地址规划 (16)8.4.网络设备 (16)8.5.网络设备技术要求 (17)8.5.1. 概述 (17)8.5.2. 核心层局域网交换机 (17)8.5.3. 接入局域网交换机 (18)8.5.4. 一级业务中心路由器 (19)9.主机系统部分 (21)9.1.概述 (21)9.2.主机设备技术要求 (21)10.磁盘阵列部分 (22)10.1.概述 (22)10.2.磁盘阵列技术要求 (23)10.3.磁盘阵列配置要求 (24)10.4.其它配置要求 (24)11.磁带库部分 (25)11.1.概述 (25)11.2.磁带库系统设备技术要求 (25)11.3.磁带库配置容量要求 (26)11.4.备份设备的其他要求 (26)12.各省设备的配置 (26)13.系统管理 (28)14.可靠性要求 (29)15.安全管理 (30)15.1.概述 (30)15.2.网络安全管理 (30)15.3.系统安全管理 (30)15.4.应用系统安全管理 (31)15.5.网络范围内的防病毒管理 (31)15.6.安全策略集中管理 (31)15.7.对安全产品的技术要求 (32)16.设备供电、环境及安装要求 (33)17.设备配置要求 (34)1.总则1.1 本文件是中国移动通信集团公司(简称买方)一级业务运营支撑中心工程帐务枢纽和客服枢纽系统系统集成的技术规范书,包括了本系统服务器主机、存储设备、备份设备、网络设备、数据库、应用软件及系统集成各个部分的要求,供厂商/公司(以下简称卖方)编写技术建议书和报价之用。

为什么选择这样的大数据平台架构?作者:傅一平当前BAT基本公开了其大数据平台架构,从网上也能查询到一些资料,关于大数据平台的各类技术介绍也不少,但在那个机制、那个环境、那个人才、那个薪酬体系下,对于传统企业,可借鉴的东西也是有限的。
技术最终为业务服务,没必要一定要追求先进性,各个企业应根据自己的实际情况去选择自己的技术路径。
与传统的更多从技术的角度来看待大数据平台架构的方式不同,笔者这次,更多的从业务的视角来谈谈关于大数据架构的理解,即更多的会问为什么要采用这个架构,到底能给业务带来多大价值,实践的最终结果是什么。
它不一定具有通用性,但从一定程度讲,这个架构可能比BAT的架构更适应大多数企业的情况,毕竟,大多数企业,数据没到那个份上,也不可能完全自研,商业和开源的结合可能更好一点,权当抛砖引玉。
大数据平台架构的层次划分没啥标准,以前笔者曾经做过大数据应用规划,也是非常纠结,因为应用的分类也是横纵交错,后来还是觉得体现一个“能用”原则,清晰且容易理解,能指导建设,这里将大数据平台划分为“五横一纵”。
具体见下图示例,这张图是比较经典的,也是妥协的结果,跟当前网上很多的大数据架构图都可以作一定的映射。
何谓五横,基本还是根据数据的流向自底向上划分五层,跟传统的数据仓库其实很类似,数据类的系统,概念上还是相通的,分别为数据采集层、数据处理层、数据分析层、数据访问层及应用层。
同时,大数据平台架构跟传统数据仓库有一个不同,就是同一层次,为了满足不同的场景,会采用更多的技术组件,体现百花齐放的特点,这是一个难点。
数据采集层:既包括传统的ETL离线采集、也有实时采集、互联网爬虫解析等等。
数据处理层:根据数据处理场景要求不同,可以划分为HADOOP、MPP、流处理等等。
数据分析层:主要包含了分析引擎,比如数据挖掘、机器学习、深度学习等。
数据访问层:主要是实现读写分离,将偏向应用的查询等能力与计算能力剥离,包括实时查询、多维查询、常规查询等应用场景。

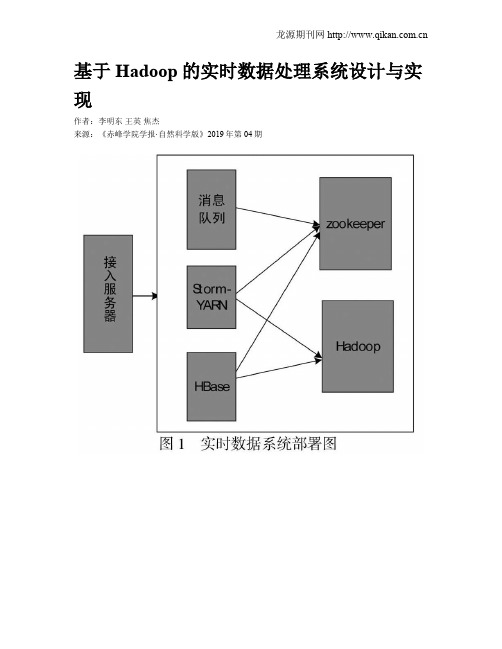
基于Hadoop的实时数据处理系统设计与实现作者:李明东王英焦杰来源:《赤峰学院学报·自然科学版》2019年第04期摘要:本文基于Hadoop平台设计了一个实时数据处理系统,通过对主流实时计算框架的研究,解决了Spark,puma没能解决的数据源主动接入问题.本系统设计主要包括核心计算模块设计、数据接入模块设计和存储模块设计.主要用到的算法包括可靠性机制算法、信号量机制算法、事务性机制算法等.实践结果表明,系统处理效率高且运行稳定.关键词:Hadoop;实时数据处理;可靠性机制中图分类号:TP311.13; 文献标识码:A; 文章编号:1673-260X(2019)04-0047-03随着大数据技术的快速发展,要求现有平台不仅能够处理海量数据,还要能够快速的对接批量数据,实现数据的实时处理与结果的展现;本文以Hadoop主流数据处理平台为基础,使用storm计算框架完成各个模块的功能设计.在整个系统框架下,分别对可靠性等机制进行了内外部环境的功能及性能的测试.为后续数据可视化的实时展现以及预测提供了坚实的理论和实验基础.1 实时数据处理系统结构与功能设计基于ARM微处理器芯片的智能远程防盗系统的结构功能设计主要包括:电源模块、无线本系统开发核心基于Hadoop架构,结合了kafka[1]、HBase、Thritf,以及Zookeeper[2]集群等开源工具,使用Storm作为数据计算模块.实时数据处理系统的环境和服务部署框架如图1所示.1.1 Storm-YARNHadoop集群中的3台机器提供给Storm- YARN使用,一台作为Nimbus,另外两台作为Supervisor机,每个开启4个工作进程.1.2 Kafka用于提供高吞吐消息服务的Kafka队列部署在一台Linux物理机器上,Kafka可以有效地解决在线数据活跃导致与系统之间速度不匹配的问题.Kafka通过追加数据的方法完成对磁盘数据的长久保持,提高系统运算能力的同时又能稳定存储数据.1.3 HBaseHadoop集群中的3台机器被划分用于部署HBase服务.HBase架构图如图2所示.HBase中客户端通过远程过程调用机制与HRegionServer和HMaster进行通信.当用户对数据进行读写操作时,客户端通过远程过程调用机制与HRegionServer通信,对数据进行创建、权限、删除等操作时,客户端通过远程过程调用机制与HMaster通信.1.4 实时系统中Hadoop集群配置本系统Hadoop集群包括10台机器,一台机器为Namenode,其余为node 用于维护文件系统树,包括树内的文件和目录,Datanode存储和检索数据块,并维护数据块存储列表,一定周期内将信息发送给Namenode[3].1.5 Zookeeper集群配置Zookeeper集群分配4台机器,Zookeeper采用与文件系统相似的目录节点树来存储数据,数据的集群管理通过维护和检测数据的变化以实现,此外Zookeeper在本系统中为HBase 等程序提供服务.2 实时数据接入2.1 实时数据处理首先启动kafka消息队列服务,将用户数据源接入系统缓冲池,第二步启动位于数据源层的数据源接入模组,读取配置,向外提供服务.用户向系统发送一项任务时,系统首先对任务进行逻辑解析,将解析后的任务发送到计算層,完成实时计算和存储.系统外应用使用应用程序编程接口将数据发送到系统,并在消息队列中进行缓存,数据在消息队列中排队等待,对数据处理需要在计算层有相关的在线处理进程.在采用C/S架构的数据源接入层中,外部应用被称为Client,系统即为Sever端.Client端可以通过发送数据给Server后,等待Server确定后继续发送数据或者不经过Server确定一直发送数据这两种方式传输数据[4].实时数据接入流程图如图3所示.2.2 数据处理模式设计数据处理[4]包括对数据的统计、提取、过滤、计算TopN、数据聚合等,还要对中文数据流进行分词操作.数据处理流程如图4所示.2.3 实时处理系统实现实时处理系统由数据接入模块、存储模块、核心计算模块组成.(1)数据接入工作流程如图5所示.模块中分为客户端、服务器、通信以及消息队列;客户端发送流式数据至服务器,同时为了提升消息的传输效率和质量,在客户端中加入了Retey机制,并设置最大的Retry次数是5次,当连续5次调用失败才算最终失败.当客户端调用失败时抛出异常,系统调用handleTException方法处理异服务器需要能快速响应客户端的请求,因此本文服务器采用线程池工作模式,设置最小线程数8,最大线程数256,这样提高了服务器响应速度,又最大程度减少了资源的消耗[5].Kafka消息队列部署在一台linux机器上,Kafka将来自同一数据源的消息即同一主题,默认分区个数为10.在Kafka中,生产者产生消息并且将消息发送给服务器;消费者负责使用消息,这三者的关系如图6所示.通信部分有handleMsg以及handleMsg两个接口方法,用户根据需求选择调用.(2)实时数据处理系统核心计算框架本系统中的实时计算部分是基于Storm框架开发,spout组件提供数据喷发服务,Bolt组件提供数据处理操作,二者构成Storm的在线计算任务.核心计算框架如图7所示.3 实时数据处理系统算法的设计与处理3.1 可靠性机制算法设计在基于Storm平台的可靠性机制算法下构建流程如下图所示.如果消息处理失败,则调用fail方法.首先将消息队列头中的消息移除,消息处理结果被标记为失败,进行计时.消息处理成功,调用ack方法,将消息队列头中的消息移除,消息处理结构被标记为成功,开始计时,计时结束调用nextTuple方法发送接下来的消息[6].3.2 信号量机制算法本系统基于Storm信号量机制开发了一个组件Signalspout.Signalspout组件用于发送清空缓存等操作的信号给其他组件,只需signalspout组件定时发射信号就能实现从一个方面控制多个时间粒度[7],signalspout工作原理如图9所示.3.3 事务性机制算法使用TridentTopology事务性在线任务完成该算法,Trident包括Partition-local操作、Merge/Join操作、流分组操作、Pepartitionning操作、Aggregation操作[8].4 总结本文基于Hadoop平台设计了一个实时数据处理系统,弥补了spark、Hadoop平台不能供多用户实时操作数据的不足.HBaseBolt组件实现了存储消息序列到HBase数据库中,将tuple 数据样例转变为put实例进行存储.改进后的实时处理系统确保数据源组件spout发出的信息能被bolts及时捕捉并处理.系统采用的信号量机制控制对时间粒度不同时,控制数据分流并进行置零计数;通过多次运行试验,系统处理数据及时且运行稳定,提升了平台处理数据的效率.参考文献:〔1〕曲风富.京东基于Samza的流失计算实践[J].程序员,2014(2):40-43.〔2〕Yang L,Yan Z.A method to avoid single failure of Namenode inHDFSZookeeper[J].Software,2016.〔3〕金晓军.Trident Storm与流计算经验[J].程序员,2015(10):99-103.〔4〕朱珠.基于Hadoop的海量數据处理模型研究与应用[D].北京邮电大学,2014.〔5〕陈飞.基于MapReduce的数据清洗算法研究[D].昆明理工大学,2016.101-103.〔6〕徐媛媛.基于MapReduce的相似性连接研究[D].宁波大学,2014.22-25.〔7〕雷斌.面向复杂距离度量的MapReduce相似性连接技术研究[D].东北大学,2016.55-58.龙源期刊网 〔8〕韩来明.基于遗传算法的分布式数据挖MapReduce架构研究[D].天津大学,2015.31-35.。

移动办公系统〔MOA〕建设方案2021年1月目录1工程概述 (2)2技术方案概述 (4)MOA概述 (4)MOA工作原理简介 (5)MOA系统的部署 (6)3详细设计 (8)系统现状与需求 (8)系统现状 (8)用户需求 (8)设计理念 (9)系统架构设计 (9)网络控制 (10)用户和终端控制 (11)数据和代码控制 (12)业务控制 (13)精简设计 (13)系统物理结构图 (14)应用软件的部署 (14)移动终端用户的平安接入 (15)1 工程概述国家努力推进的各大“金字工程〞在把传统政务数字化,而移动信息化大潮又让很多数字化的业务过程“移动〞起来。
将市政府办公电子化、数字化、移动化,从而提高办公效率,做一心一意为人民效劳一直是国家公务人员期望到达的目标。
而“移动数字城市〞的逐步开展正将这一目标拉近。
众所周知,市政府系统是数据集中的中心,数据访问量巨大,要求设备具有极高的稳定性、功能兼容性和较高的处理性能。
市政府对MOA的应用主要表达在移动办公、信息系统查询等方面。
市政府人员外出办公时,需要在线查询时,使用终端(或PDA)接入市政府APN网络,访问单位内部网页,进行实时公文处理。
由于市政府对从内部网接入移动网络时的平安性非常重视,中国移动MOA和APN网络在通信和传输过程中,对市政府内部数据进行加密处理。
同时,为了更好地保证网络数据传输的平安性,MOA效劳器和市政府终端之间建立加密的图形碎片专用隧道。
通过设置在市政府内部网的MOA效劳器实现市政府用户身份认证。
同时,构建市政府移动信息查询系统的APN,以保证市政府专有系统的平安性。
移动办公自动化系统即移动OA,是以“简单、实用、使用不受地点限制〞为设计理念开发的办公自动化系统。
移动办公自动化系统网络部署方案是利用XXXX提供的GPRS/EDGE专用网络。
在移动状态下,通过智能移动终端利用GPRS/EDGE专用网络实现查询、审批、回复、确认等OA办公操作,使办公信息可以随时随地地进行交互流动,整体运作更加协调。

中国移动浙江公司设计说明书ESOP营销管理需求编号:需求名称:文档编号:文档修改记录修改日期修改人修改说明版本号2013-05-27 黄伟新建V1.0目录1需求概述 (3)1.1需求情况说明 (3)1.2需求改造功能描述 (3)2总体设计 (3)2.1系统外部关系图 (3)2.2系统总体结构设计 (3)2.3总体流程 (3)2.4系统边界 (3)3核心数据模型 (4)4系统功能点设计 (5)4.1PBOSS订单中下周期带宽属性数据沉淀........................... 错误!未定义书签。
4.1.1功能概述 (5)4.1.2界面原型 (5)4.1.3界面流程图........................................................... 错误!未定义书签。
4.1.4配置信息 (6)4.1.5后台处理流程 (6)4.1.6涉及表及使用方法................................................... 错误!未定义书签。
4.1.7接口调用说明 (6)4.2PBOSS带宽属性变更订单反撤...................................... 错误!未定义书签。
4.2.1功能概述.............................................................. 错误!未定义书签。
4.2.2界面原型.............................................................. 错误!未定义书签。
4.2.3界面流程图........................................................... 错误!未定义书签。
4.2.4配置信息.............................................................. 错误!未定义书签。
黑龙江移动业务支撑网经营分析(BASS)系统基于Hadoop的ETL试点项目总结V1.00中国移动通信集团黑龙江有限公司2013年06月目录1.试点基本情况 (4)1.1试点情况总述 (4)1.2试点项目组织 (5)1.3试点目标场景 (7)1.3.1ETL (7)1.3.2数据挖掘 (12)1.4试点系统平台 (12)1.4.1硬件平台 (12)1.4.2软件平台 (18)2.试点技术方案 (20)2.1整体架构 (20)2.2关键转换能力 (22)2.2.1ETL转换能力 (22)2.2.2Colocation方案 (27)2.2.3流程预编译方案 (28)2.3应用开发 (28)2.4调度管理 (30)2.4.1BDI调度控制 (30)2.4.2BDI与现网ETL调度集成 (32)2.5平台监控 (33)2.5.1ETL监控 (33)2.5.2Hadoop监控 (34)2.5.3集群资源监控 (35)2.5.4自动安装部署 (37)2.6数据质量 (38)2.7元数据 (39)3.系统运行情况 (41)3.1.1上线情况 (41)3.1.2应用情况 (41)3.1.3平台情况 (50)3.1.4性能记录 (53)4.其他情况总结 (57)4.1经验教训 (57)4.2成本分析 (60)4.2.1建设成本 (60)4.2.2运维成本 (60)4.3技能储备 (61)4.4选型比较 (61)4.5下阶段规划 (62)4.5.1应用规划 (62)4.5.2BDI产品路标规划 (63)1.试点基本情况1.1试点情况总述黑龙江分公司Hadoop ETL试点项目建设包括针对“8个典型业务场景”完成Hadoop ETL(下称BDI)流程配置、流程调测、数据核对、功能测试、性能测试、集成测试、并行运行等,包括对多个产品进行了性能处理比对;在技术保障方面与集团研究院、集成商进行多次产品技术交流、产品特性展示、难点问题讨论等工作,确保试点项目的顺利推进、支撑经验的及时总结,试点里程碑计划如下:✓2012年03月•启动Hadoop ETL试点项目建设•组建试点运作团队,包括省公司及集成商团队✓2012年06月•确定总体技术路线,包括Hadoop平台、产品选型等•完成试点总体集成方案编写并上报集团公司✓2012年09月•确定试点应用场景,包括确定关键数据接口范围等•集成商完成云ETL产品初始版本研发•完成试点第一阶段实施验证,包括功能测试和性能测试,输出中期总结报告✓2012年12月•完成试点集群设备采购,包括主机、交换机、机架等✓2013年02月•集群设备到货,完成设备安装、加电、调测✓2013年03月•完成集群设备组网,包括系统安装、磁盘划分、网络调测等✓2013年04月•启动试点第二阶段实施验证,包括功能测试、性能测试、集成测试✓2013年05月•启动试点选定业务场景的并运行测试✓2013年07月•完成试点第二阶段实施验证•针对重点业务场景,启动Hadoop ETL和现网ETL并运行处理1.2试点项目组织试点合作方式:试点项目成员来自省公司和集成商团队,省公司侧重于方案评审、合作伙伴协调、项目推动等,集成商侧重于方案设计、产品研发、项目实施等;省公司和集成商定期召开项目例会,以及时规避项目风险、推动问题的跟踪解决;省公司人员安排姓名职责组别孙德志项目管理项目管理组赵洪松项目管理项目管理组张美鸥技术负责实施保障组李方岩ETL产品支撑实施保障组闫文ETL产品支撑实施保障组✓合作伙伴1:华为,省级经分系统集成商,负责试点方案设计、产品研发、试点交付等,针对Hadoop ETL有明确的产品路标规划,研发团队规模:超过50人,包括2名被Hadoop开源社区认可的committer专家;✓合作伙伴2:神州数码思特奇,地市数据集市集成商,负责试点配合以及ETL接口数据源改造工作,团队规模:超过5人;集成商核心团队姓名职责组别高立项目管理项目管理组王奇项目管理项目管理组徐建鹏架构设计系统架构组黄红莉架构设计系统架构组邱宁架构设计系统架构组范建斌架构设计系统架构组刘超产品开发项目开发组王仁康产品开发项目开发组张林辉产品开发项目开发组陈克广产品开发项目开发组彭林伟产品开发项目开发组李金方产品开发项目开发组孙成高产品开发项目开发组朱礼明产品开发项目开发组蔡腾飞产品开发项目开发组王泽产品开发项目开发组朱文奇产品开发项目开发组朱玉麒产品开发项目开发组罗奎产品开发项目开发组范荣产品开发系统测试组苑宗港系统测试系统测试组高进进系统测试系统测试组屈文喜系统测试系统测试组张乾系统测试系统测试组朱光耀系统测试系统测试组张然海系统测试系统测试组程雪娟系统测试系统测试组周磊系统测试系统测试组姜波系统测试系统测试组周峰系统测试系统测试组麻新瑜系统测试系统测试组刘志龙试点实施实施保障组张莹试点实施实施保障组刘德龙试点实施实施保障组1.3试点目标场景1.3.1ETL1.3.1.1现网痛点问题分析现网ETL主机组网图•负载不均:由于两台ETL节点机承载的业务内容不同,导致接口量、数据量、服务器忙闲度等不够均衡;•效率瓶颈:接口处理通常集中在每日0:00-5:00,较为耗时,且随着业务量的增长,处理效率已出现瓶颈,导致部分应用展现推迟到8:30之后,对业务分析影响较大!如:受限于计算能力和存储能力,现网ETL始终没有引入Gn口数据,始终无法开展流量经营分析;•资源争用:ETL数据转换、逻辑加工均在数据仓库内完成,与业务分析资源争用现象严重,数据仓库的计算压力太大,直接降低了经分系统整体分析效率;•流程低效:部分关键接口数据量大、逻辑复杂、处理时间长、后续依赖任务多,严重影响后续应用展现;如用户表接口整体处理时长超过4.5小时,导致后续1000+以上的依赖任务整体延时;•扩容受限:基于目前的处理架构,可采用增加节点机(小型机)、增加存储、分业务库等扩容优化方案,但投资成本、建设难度较大;1.3.1.2针对现网痛点问题,本次试点建设思路关键数据接口(数据量大、计算效率低、后续依赖任务多)的性能问题是整个ETL系统的性能瓶颈所在,可考虑将此部分接口处理迁移至基于Hadoop ETL平台,通过计算转移、均衡负载、流程重构实现ETL流程的最优化处理,促进经分系统整体性能提升;除关键数据接口外,数据仓库“汇总计算”的业务复杂度高、消耗服务器资源大,本次试点会针对性地选取部分“汇总计算场景”进行验证,为下阶段汇总迁移积累经验;•计算转移:将现网“关键数据接口”的数据抽取、转换、装载逻辑迁移至Hadoop ETL 平台,通过引入基于Map/Reduce框架的并行计算引擎提升接口处理效率,同时降低数据仓库的性能压力;•均衡负载:通过“大数据文件”的平均分割、集群内部的任务平均分发,实现ETL 任务内的均衡负载,促进ETL系统整体性能提升;•流程重构:将外部系统存在性能瓶颈的“预处理逻辑”(经分ETL流程依赖此部分数据接口)纳入Hadoop ETL平台,通过经分系统内部、外部接口融合,实现端到端流程的最优化处理;针对现网痛点问题,结合ETL接口处理特点,从以下几方面选取“ETL接口场景”:•数据总量大;如:单数据周期数据量超过3000万条的数据接口•处理时间长;如:近3个数据周期,平均处理时长超过30分钟的数据接口•后续依赖多;如:超过20个应用依赖的数据接口1.3.1.3ETL目标场景1.3.1.3.1月欠费状态接口应用类型接口处理数据处理单表抽取、转换、装载Sql 特点select、insert同分布键不涉及输入数据月欠费:4亿+、35G+ 输出数据月欠费:4亿+、35G+选取原因验证BDI在以下场景下的性能表现及数据处理一致性:1、单表抽取、转换、装载2、大数据量接口,数据量达到“亿级”1.3.1.3.2附加产品实例接口应用类型接口处理数据处理单表抽取、转换、装载Sql 特点select、insert同分布键不涉及输入数据产品实例:1.7亿+、22G+输出数据产品实例:1.7亿+、22G+选取原因验证BDI在以下场景下的性能表现及数据处理一致性:1、单表抽取、转换、装载2、大数据量接口,数据量达到“亿级”1.3.1.3.3SIM卡资源接口应用类型接口处理数据处理大表与维表关联Sql 特点Left join、nvl、trunc、dbms_random.value、case when同分布键不涉及输入数据•Sim卡资源:1亿+、17G+ •TD固话:1万+输出数据1亿+、17G+选取原因验证BDI在以下场景下的性能表现及数据处理一致性:1、两表关联,其中一张为“千万级”的大表,另一张为数据量较少的维表2、两表进行“外连接”关联1.3.1.3.4用户账单信息月高度汇总应用类型汇总处理数据处理单表汇总、高度汇总Sql 特点sum、group by同分布键未设置分布键,默认按全部字段处理输入数据用户账单:2.3亿+、37G+输出数据用户账单:0.8亿+、12G+选取原因验证BDI在以下场景下的性能表现及数据处理一致性:1、单表汇总、高度汇总(分组字段超过40个)2、分布键数据分布不均匀1.3.1.3.5用户信息日中度汇总应用类型汇总处理数据处理两表关联、均为大表,每个表数据量千万+Sql 特点Left join、decode、floor、months_between、nvl同分布键客户标识,数据分布离散输入数据•用户表:0.3亿+、10G+ •客户表:0.9亿+、10G+输出数据用户信息:0.3亿+、12G+选取原因验证BDI在以下场景下的性能表现及数据处理一致性:1、两个大表关联,数据量千万+2、涉及decode、floor、months_between等转换3、分布键数据分布离散1.3.1.3.6用户新业务功能订购中度汇总应用类型汇总处理数据处理三张表关联,两张表为“千万级”的大表,一张表为维表Sql 特点max、case when同分布键用户标识,数据分布离散输入数据•用户表:0.3亿+、7G+ •订购实例:1.7亿+、3G+ •产品:445输出数据用户新业务订购:0.3亿+、1G+选取原因验证BDI在以下场景下的性能表现及数据处理一致性:1、三张表关联,两张表为“千万级”的大表,一张表为维表2、多表关联过程中进行分组(Group by )、极值(Max)计算3、分布键数据分布离散1.3.1.3.7用户账单信息月轻度汇总应用类型汇总处理数据处理三张表关联,均为“千万级”的大表Sql 特点Left join、max、nvl、nvl2、case when、substr同分布键用户标识,数据分布均匀输入数据•收入表:0.3亿+、2.6G+ •账单明细:4亿+、33G+ •账单汇总:0.8亿+、0.8G输出数据用户账单:0.8亿+、1G+选取原因验证BDI在以下场景下的性能表现及数据处理一致性:1、三张表关联,均为“千万级”的大表2、多表关联过程中涉及group by、max、nvl2、substr等分组、转换逻辑3、分布键数据分布离散1.3.1.3.8日用户信息接口应用类型接口处理数据处理复杂逻辑加工,涉及插入、删除、分组、排重、关联、生成临时表等多步操作Sql 特点delete、group by、having、min、case when、left join、nvl、substr、floor、not in同分布键涉及多个基于分布键的关联操作,用户担保信息字段数据分布集中,其余离散输入数据•产品订购:2.2亿+、34G+•客户表:0.3亿+、6G+•Sim卡:0.3亿+、2G+•客户资料:0.4亿+、8G+•前一天的用户信息:0.3亿+、9G •邮递帐单:130W+、90M+•产品维表:3W+、9M+•详细品牌:2W+、10M+•离网用户SIM卡:13W+、7M+ •离网客户资料表:13W+、30M+ •离网用户:13w+、30M+•担保信息:2W+、10M+•TD固话:8W+、30M+•大品牌:3、0.2K输出数据用户信息:0.3亿+、9G选取原因验证BDI在以下场景下的性能表现及数据处理一致性:1、复杂逻辑加工,涉及插入、删除、分组、排重、关联、生成临时表等多步操作2、逻辑加工过程中涉及nvl、case when、not in、substr等转换、过滤操作综上,单周期总输入数据量超过21亿/237G,总输出数据量超过9亿/109G;BDI包括两类数据源,一类通过FTP从现网ETL接口机下载接口文件,文件分隔符为“|”,另一类通过OCI从现网数据仓库抽取待汇总数据,两类数据均由BDI装载进HDFS完成后续加工计算,最终计算结果提交至现网数据仓库。
基于Hadoop的电信业务日志分析系统的设计与实现中期报告一、选题背景随着移动互联网的普及和高速网络的发展,电信运营商积累了大量的日志数据。
这些日志数据包含着海量的用户行为信息和网络运营数据,对于电信运营商的业务运营和网络优化至关重要。
因此,如何高效地对这些数据进行分析和利用,成为电信行业亟待解决的问题。
在当前大数据技术的背景下,Hadoop作为分布式大数据处理的核心技术,已经在各行各业得到广泛的应用。
因此,利用Hadoop构建电信业务日志分析系统,具有重要意义和实际价值。
本课题的研究目的是设计和实现一个基于Hadoop的电信业务日志分析系统,为电信运营商的业务决策提供支持。
二、研究内容和计划(一)研究内容1.电信业务日志的采集和格式化通过Hadoop自带的数据采集工具Flume或Logstash实现采集,将采集到的日志转换成Hadoop可处理的格式。
2.电信业务日志数据的存储与检索采用Hadoop分布式文件系统(HDFS)作为存储介质,对海量的日志数据进行高效的存储和检索。
采用HBase或Elasticsearch构建索引,以提高数据检索的效率。
3.日志数据的清洗和预处理通过MapReduce编程和Hive SQL实现对日志数据的清洗和预处理,去除冗余数据、过滤异常数据,提取有用的数据信息。
4.电信业务日志数据的分析与挖掘采用MapReduce编程,通过编写自定义的Map和Reduce函数来实现各种分析指标的计算和统计,包括:用户活跃度、业务流量统计、网络拓扑分析等。
5.数据可视化和分析报告采用数据可视化工具(如Tableau)生成交互式的分析报告,为电信运营商提供直观的分析结果。
(二)研究计划1.选题立项和调研(完成时间:1周)明确系统需求和技术选型,调研相关技术和工具,确定实验环境。
2.系统设计与实现(完成时间:6周)(1)搭建Hadoop分布式集群,包括HDFS和YARN。
(2)设计和实现数据采集和格式化模块,采用Flume或Logstash 作为数据采集工具,将各个节点的日志数据集中到HDFS中。