logistic回归分析案例
- 格式:doc
- 大小:473.33 KB
- 文档页数:5
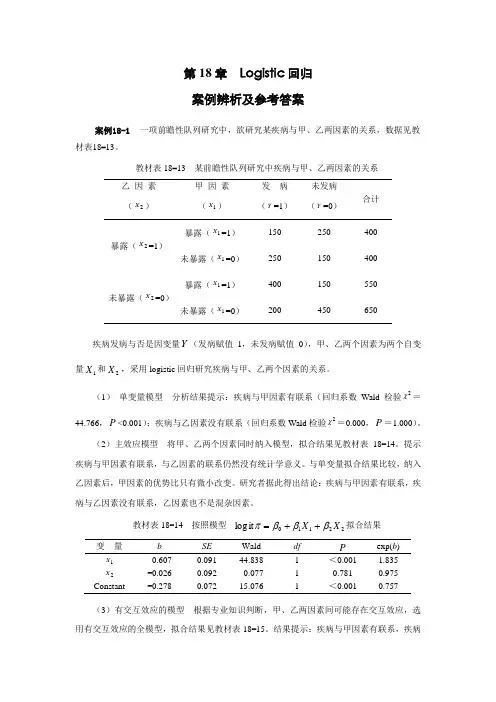
第18章 Logistic 回归 案例辨析及参考答案案例18-1 一项前瞻性队列研究中,欲研究某疾病与甲、乙两因素的关系,数据见教材表18-13。
教材表18-13 某前瞻性队列研究中疾病与甲、乙两因素的关系 乙 因 素 甲 因 素 发 病 未发病 合计(2X )(1X ) (Y =1) (Y =0) 暴露(2X =1)暴露(1X =1)150250400未暴露(1X =0) 250 150 400 未暴露(2X =0)暴露(1X =1)400150550未暴露(1X =0)200450650疾病发病与否是因变量Y (发病赋值1,未发病赋值0),甲、乙两个因素为两个自变量1X 和2X ,采用logistic 回归研究疾病与甲、乙两个因素的关系。
(1) 单变量模型 分析结果提示:疾病与甲因素有联系(回归系数Wald 检验2χ=44.766,P <0.001);疾病与乙因素没有联系(回归系数Wald 检验2χ=0.000,P =1.000)。
(2)主效应模型 将甲、乙两个因素同时纳入模型,拟合结果见教材表18-14。
提示疾病与甲因素有联系,与乙因素的联系仍然没有统计学意义。
与单变量拟合结果比较,纳入乙因素后,甲因素的优势比只有微小改变。
研究者据此得出结论:疾病与甲因素有联系,疾病与乙因素没有联系,乙因素也不是混杂因素。
教材表18-14 按照模型22110it log X X βββπ++=拟合结果变 量 b SE Wald df Pexp(b ) 1X 0.607 0.091 44.838 1 <0.001 1.835 2X -0.026 0.092 0.077 1 0.781 0.975 Constant-0.2780.07215.0761<0.0010.757(3)有交互效应的模型 根据专业知识判断,甲、乙两因素间可能存在交互效应,选用有交互效应的全模型,拟合结果见教材表18-15。
结果提示:疾病与甲因素有联系,疾病与乙因素也有联系,甲、乙两因素间还有交互效应。

Logistic回归分析报告范文结果解读分析Logitic回归常用于分析二分类因变量(如存活和死亡、患病和未患病等)与多个自变量的关系。
比较常用的情形是分析危险因素与是否发生某疾病相关联。
例如,若探讨胃癌的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群有不同的临床表现和生活方式等,因变量就为有或无胃癌,即“是”或“否”,为二分类变量,自变量包括年龄、性别、饮食习惯、是否幽门螺杆菌感染等。
自变量既可以是连续变量,也可以为分类变量。
通过Logitic回归分析,就可以大致了解胃癌的危险因素。
Logitic回归与多元线性回归有很多相同之处,但最大的区别就在于他们的因变量不同。
多元线性回归的因变量为连续变量;Logitic回归的因变量为二分类变量或多分类变量,但二分类变量更常用,也更加容易解释。
1.Logitic回归的用法一般而言,Logitic回归有两大用途,首先是寻找危险因素,如上文的例子,找出与胃癌相关的危险因素;其次是用于预测,我们可以根据建立的Logitic回归模型,预测在不同的自变量情况下,发生某病或某种情况的概率(包括风险评分的建立)。
2.用Logitic回归估计危险度所谓相对危险度(rikratio,RR)是用来描述某一因素不同状态发生疾病(或其它结局)危险程度的比值。
Logitic回归给出的OR(oddratio)值与相对危险度类似,常用来表示相对于某一人群,另一人群发生终点事件的风险超出或减少的程度。
如不同性别的胃癌发生危险不同,通过Logitic回归可以求出危险度的具体数值,例如1.7,这样就表示,男性发生胃癌的风险是女性的1.7倍。
这里要注意估计的方向问题,以女性作为参照,男性患胃癌的OR是1.7。
如果以男性作为参照,算出的OR将会是0.588(1/1.7),表示女性发生胃癌的风险是男性的0.588倍,或者说,是男性的58.8%。
撇开了参照组,相对危险度就没有意义了。

logistic回归分析案例Logistic回归分析案例。
Logistic回归分析是一种常用的统计分析方法,主要用于预测二分类或多分类的结果。
在实际应用中,Logistic回归分析可以帮助我们理解影响某一事件发生的因素,以及对事件发生的概率进行预测。
本文将通过一个实际的案例来介绍Logistic回归分析的应用。
案例背景。
假设我们是一家电商公司的数据分析师,现在我们需要分析用户的购买行为,并预测用户是否会购买某一产品。
我们收集了一些用户的个人信息和他们最近一次购买的产品,希望通过这些数据来预测用户是否会购买新产品。
数据准备。
首先,我们需要收集用户的个人信息和购买行为数据。
个人信息包括年龄、性别、职业等;购买行为数据包括购买的产品类型、购买时间等。
在收集完数据后,我们需要对数据进行清洗和预处理,包括缺失值处理、异常值处理等。
模型建立。
在数据准备完成后,我们可以开始建立Logistic回归模型。
首先,我们需要将数据划分为训练集和测试集,以便对模型进行验证。
然后,我们可以利用训练集来拟合Logistic回归模型,并利用测试集来评估模型的预测效果。
模型评估。
在模型建立完成后,我们需要对模型进行评估。
常用的评估指标包括准确率、精确率、召回率等。
这些指标可以帮助我们判断模型的预测效果,并对模型进行调优。
模型应用。
最后,我们可以利用建立好的Logistic回归模型来预测用户是否会购买新产品。
通过输入用户的个人信息和购买行为数据,模型可以给出用户购买新产品的概率,从而帮助我们进行精准营销和推广。
结论。
通过以上实例,我们可以看到Logistic回归分析在预测用户购买行为方面具有很好的应用价值。
通过收集用户数据、建立模型、评估模型和应用模型,我们可以更好地理解用户行为,并做出更精准的预测和决策。
总结。
Logistic回归分析是一种强大的统计工具,可以帮助我们预测二分类或多分类的结果。
在实际应用中,我们可以根据具体情况收集数据、建立模型,并利用模型进行预测和决策。


logistic回归医学案例
逻辑回归在医学中有广泛的应用,尤其是在预测疾病风险和诊断疾病方面。
以下是一个逻辑回归在医学中的实际案例:
案例:预测糖尿病风险
背景:糖尿病是一种常见的慢性疾病,预测糖尿病风险对于预防和控制疾病非常重要。
通过逻辑回归模型,可以基于患者的特征预测其患糖尿病的风险。
数据集:数据集中包含患者的年龄、性别、体重指数(BMI)、家族病史、饮食习惯等特征以及是否患有糖尿病的标签(0表示无糖尿病,1表示有糖
尿病)。
模型训练:使用逻辑回归模型训练数据集,将特征作为输入,标签作为输出。
通过训练模型,可以学习到特征与糖尿病风险之间的关系。
模型评估:使用测试集评估模型的准确性和预测能力。
可以通过计算准确率、灵敏度、特异度等指标来评估模型的性能。
应用:基于训练好的逻辑回归模型,对于具有不同特征的患者,可以预测其患糖尿病的风险,并提供相应的预防和治疗建议。
总结:逻辑回归是一种强大的预测模型,在医学领域中具有广泛的应用。
通过逻辑回归模型,可以根据患者的特征预测其患病风险,并提供针对性的预防和治疗建议,有助于提高疾病的预防和控制效果。

二分类logistic回归案例
以下是一个二分类Logistic回归的案例:
假设我们正在研究肺癌的危险因素。
在这个案例中,因变量是是否患有肺癌(是或否),自变量可能包括性别、体重指数(BMI)、是否吸烟、年龄以及是否有慢性阻塞性肺病(COPD)病史等。
首先,我们需要收集数据,包括所有可能的影响因素以及是否患有肺癌的结果。
然后,我们进行数据清理和预处理,包括处理缺失值、异常值和编码问题。
接下来,我们进行单变量分析,单独考察每个自变量与因变量之间的关系。
例如,我们可以使用卡方检验来分析性别、吸烟状况、COPD病史等分类变量与肺癌的关系,使用t检验来分析年龄和BMI等连续变量与肺癌的关系。
根据单变量分析的结果,我们筛选出与肺癌有显著关系的变量,然后进行多因素分析。
在这个案例中,我们可以使用二分类Logistic回归模型来分析这些变量与肺癌的关系。
我们可以通过逐步回归、向前选择或向后删除等方法选择自变量进入模型。
在Logistic回归分析中,我们可以通过估计回归系数、似然比检验和AIC 等信息准则来评估模型的拟合优度和预测能力。
我们还可以使用交叉验证等技术来评估模型的泛化能力。
最后,我们解释结果并撰写研究报告或论文。
在解释结果时,我们需要考虑自变量之间的相互作用和多重共线性问题。
如果存在多重共线性问题,我们需要采取措施解决它,例如使用主成分分析或岭回归等方法。
总之,二分类Logistic回归是一种强大的统计工具,可以帮助我们了解分类结果与一组影响因素之间的关系,并预测新数据点的分类概率。
在案例研究中,我们需要注意数据预处理、变量选择和结果解释等方面的问题。
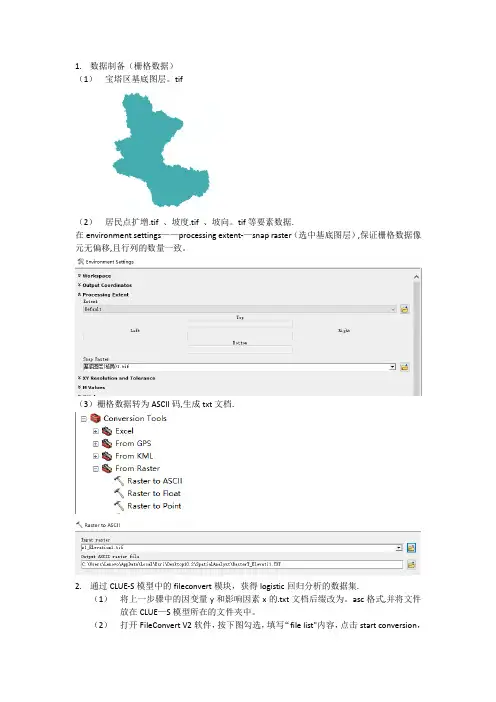
1.数据制备(栅格数据)
(1)宝塔区基底图层。
tif
(2)居民点扩增.tif 、坡度.tif 、坡向。
tif等要素数据.
在environment settings——processing extent-—snap raster(选中基底图层),保证栅格数据像元无偏移,且行列的数量一致。
(3)栅格数据转为ASCII码,生成txt文档.
2.通过CLUE-S模型中的fileconvert模块,获得logistic回归分析的数据集.
(1)将上一步骤中的因变量y和影响因素x的.txt文档后缀改为。
asc格式,并将文件放在CLUE—S模型所在的文件夹中。
(2)打开FileConvert V2软件,按下图勾选,填写“file list"内容,点击start conversion,
生成stat.txt 文档。
3.Spss软件中logistic二元回归分析
(1)数据标准化处理,加载数据——描述统计——描述,勾选“将标准化得分另存为变量”
(2)logistic回归分析
按图设置参数因变量、自变量;由于x3属于分类变量,点击分类按钮,按图设置参数。
点击“选项”按钮,按图进行勾选,继续.点击“保存"按钮,勾选“概率”. ROC曲线检测。

logistic回归例题Logistic回归是一种线性分类器,针对的是线性可分问题。
以下是使用Logistic 回归进行分类的一个简单例子:假设我们有一个数据集,其中包含一个人的年龄、收入和信用评分。
我们的目标是预测这个人是否会违约。
首先,我们需要收集数据。
假设我们有100个人的数据,其中50人违约,50人没有违约。
我们可以将这些数据分为训练集和测试集,例如80%的数据用于训练集,20%的数据用于测试集。
接下来,我们需要将数据转换为数值形式,以便在计算机中处理。
我们可以将年龄和收入作为特征,将是否违约作为目标变量。
我们可以将年龄和收入的值标准化或归一化,以便它们在同一尺度上。
然后,我们可以使用Logistic回归模型来拟合数据。
在这个例子中,Logistic 回归模型的公式如下:\(\ln\frac{P}{1 - P} = \alpha + \beta_1 \cdot X_1 + \beta_2 \cdot X_2\)其中\(P\)表示这个人违约的概率,\(\alpha\)和\(\beta_1\)和\(\beta_2\)是待估计的参数,\(X_1\)和\(X_2\)分别是年龄和收入的值。
通过最大似然估计等优化方法,我们可以估计出\(\alpha\)、\(\beta_1\)和\(\beta_2\)的值。
一旦我们得到了这些值,我们就可以使用它们来预测新数据点的违约概率。
最后,我们可以使用测试集来评估模型的性能。
我们可以计算模型的准确率、召回率、F1得分等指标,以评估模型的分类性能。
这个例子仅仅是一个简单的Logistic回归应用,实际上它可以应用于更复杂的问题,例如医学诊断、金融欺诈检测、推荐系统等。

转载⼏个R语⾔中实现Logistic回归模型的案例案例⼀:本⽂⽤例来⾃于John Maindonald所著的《Data Analysis and Graphics Using R》⼀书,其中所⽤的数据集是anesthetic,数据集来⾃于⼀组医学数据,其中变量conc表⽰⿇醉剂的⽤量,move则表⽰⼿术病⼈是否有所移动,⽽我们⽤nomove做为因变量,因为研究的重点在于conc的增加是否会使nomove的概率增加。
⾸先载⼊数据集并读取部分⽂件,为了观察两个变量之间关系,我们可以利cdplot函数来绘制条件密度图install.packages('DAAG')library(lattice)library(DAAG)head(anesthetic)move conc logconc nomove1 0 1.0 0.0000000 12 1 1.2 0.1823216 03 0 1.4 0.3364722 14 1 1.4 0.3364722 05 1 1.2 0.1823216 06 0 2.5 0.9162907 1cdplot(factor(nomove)~conc,data=anesthetic,main='条件密度图',ylab='病⼈移动',xlab='⿇醉剂量')从图中可见,随着⿇醉剂量加⼤,⼿术病⼈倾向于静⽌。
下⾯利⽤logistic回归进⾏建模,得到intercept和conc的系数为-6.47和5.57,由此可见⿇醉剂量超过1.16(6.47/5.57)时,病⼈静⽌概率超过50%。
anes1=glm(nomove~conc,family=binomial(link='logit'),data=anesthetic)summary(anes1)结果显⽰:Call:glm(formula = nomove ~ conc, family = binomial(link = 'logit'),data = anesthetic)Deviance Residuals:Min 1Q Median 3Q Max-1.76666 -0.74407 0.03413 0.68666 2.06900Coefficients:Estimate Std. Error z value Pr(>|z|)(Intercept) -6.469 2.418 -2.675 0.00748 **conc 5.567 2.044 2.724 0.00645 **---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1(Dispersion parameter for binomial family taken to be 1)Null deviance: 41.455 on 29 degrees of freedomResidual deviance: 27.754 on 28 degrees of freedomAIC: 31.754Number of Fisher Scoring iterations: 5下⾯做出模型的ROC曲线anes1=glm(nomove~conc,family=binomial(link='logit'),data=anesthetic)对模型做出预测结果pre=predict(anes1,type='response')将预测概率pre和实际结果放在⼀个数据框中data=data.frame(prob=pre,obs=anesthetic$nomove)将预测概率按照从低到⾼排序data=data[order(data$prob),]n=nrow(data)tpr=fpr=rep(0,n)根据不同的临界值threshold来计算TPR和FPR,之后绘制成图for (i in 1:n){threshold=data$prob[i]tp=sum(data$prob>threshold&data$obs==1)fp=sum(data$prob>threshold&data$obs==0)tn=sum(data$probfn=sum(data$probtpr[i]=tp/(tp+fn) #真正率fpr[i]=fp/(tn+fp) #假正率}plot(fpr,tpr,type='l')abline(a=0,b=1)R中也有专门绘制ROC曲线的包,如常见的ROCR包,它不仅可以⽤来画图,还能计算ROC曲线下⾯⾯积AUC,以评价分类器的综合性能,该数值取0-1之间,越⼤越好。


logistic回归模型例题在统计学和机器学习中,逻辑回归模型是一种常用的分类算法。
它可以用于解决二分类问题,并根据输入特征预测样本属于某个类别的概率。
本文将详细介绍逻辑回归模型,并通过一个例题来展示其应用。
逻辑回归模型的基本原理是基于线性回归模型,但在输出结果上使用了逻辑函数(或称为sigmoid函数),将线性变换的结果映射到0到1之间的概率值。
逻辑函数的数学表达式为:f(x) = 1 / (1 + exp(-x))。
其中,x为线性组合的结果。
我们以一个银行客户分类的例子来说明逻辑回归模型的应用。
假设银行根据客户的收入和年龄等特征,来判断该客户是否会购买一款新的金融产品。
客户的收入和年龄即为输入特征,购买与否即为输出结果。
首先,我们需要准备一个包含训练数据的数据集。
我们可以从银行的数据库中提取一部分客户的数据作为训练数据集。
对于每个客户,我们需要记录其收入、年龄和是否购买的信息。
这样就形成了一个包含多行数据的数据集,每行数据有两个输入特征和一个输出结果。
接下来,我们需要对数据进行预处理。
预处理的目的是将数据转化为数学模型可以处理的形式。
对于逻辑回归模型而言,通常需要对数据进行标准化处理,使得不同特征的数值范围一致。
这可以通过z-score标准化或min-max标准化等方法实现。
然后,我们需要将数据集分为训练集和测试集。
训练集用于训练逻辑回归模型的参数,而测试集用于评估模型的性能。
通常,我们将数据集按照一定比例划分,例如将数据集的80%用作训练集,20%用作测试集。
接下来,我们可以使用逻辑回归模型来进行训练。
逻辑回归模型的训练过程涉及到最大化似然函数或最小化损失函数的优化过程。
这个过程可以通过梯度下降算法来实现,逐步调整模型参数,使得模型的拟合效果越来越好。
训练完成后,我们可以通过模型预测新样本的分类结果。
对于一个新的客户,我们可以将其收入和年龄作为输入特征输入到模型中,并得到该客户购买的概率。
逻辑回归例子逻辑回归例子【篇一:逻辑回归例子】1.logit回归本期将会大家介绍逻辑回归,虽然逻辑回归并不复杂,但正是由于其简单,高效,可解释性强的特点,在实际用途中十分的广泛,从购物预测到用户营销响应,从流失分析到信用评价,都能看到其活跃的身影,可以说,逻辑回归占据了分类算法中非常重要的地位。
回想在上一期中,我们谈到当因变量与自变量的关系式不再是线性时,通过引入衍生变量y’,使其转换为线性表达形式。
那么很自然地,对于我们现在面临的任务,我们就需要一个转换,使得分类变量0和1转化为可用的形式。
先考虑一个二分类的预测变量,正如前面所说的,显然由于分类数据的特点,已经不适合运用传统的线性函数进行分析。
但是二分类事件的y的期望值e(y)来说,它等价于事件发生概率,从y到e(y),我们就把事件发生与否与值域在[0,1]区间的事件发生概率相联系,这提示我们可以用事件发生的概率进行代替。
既然使用发生概率代替的话,一个自然而然的选择是把回归函数的值域限制在[0,1]区间内,这样当f(xi)接近负无穷时,将有e( yi)趋近于0,而在f(xi)接近正无穷时,将有e(yi )趋近于1,这样看来,显然相比于研究二元变量y与x的关系,研究y发生的条件概率与x 更具适应性。
在没有任何先验条件的情况下,这里的阈值一般选择0.5。
但当我们有进一步明确需求的时候,阈值也是可以调整的,例如我们希望对正例样本有更高的准确率要求,则可以把阈值适当地调高,例如调高到0.6;相反,假如我们希望对正例样本的召回率要求更高,则可以把阈值适当地降低,例如降低到0.4;一般地,我们选择logit函数作为转换函数,logit函数的形式:logit函数图像是一个典型的s型的曲线,并且它的值域是在[0,1]之间进一步地,我们利用logit函数,可以把事件发生的条件概率与x 表示为同样,我们也可以定义一个事件不发生的概率为:为了更显简洁,不妨作如下转换:上式左边实际上就是表示“事件发生的概率”与“事件不发生的概率”之比,称之为事件的发生比,简称odds。
逻辑回归(Logistic+Regression)经典实例机器学习算法完整版见房价预测数据集描述数据共有81个特征SalePrice - the property’s sale price in dollars. This is the target variable that you’re trying to predict.MSSubClass: The building classMSZoning: The general zoning classificationLotFrontage: Linear feet of street connected to propertyLotArea: Lot size in square feetStreet: Type of road accessAlley: Type of alley accessLotShape: General shape of propertyLandContour: Flatness of the propertyUtilities: Type of utilities availableLotConfig: Lot configurationLandSlope: Slope of property….导⼊所需模块import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport math as matfrom scipy import statsfrom scipy.stats import normfrom sklearn import preprocessingimport statsmodels.api as smfrom patsy import dmatricesimport warningswarnings.filterwarnings('ignore')%matplotlib inlineimport sklearn.linear_model as LinRegimport sklearn.metrics as metrics导⼊数据#loading the datadata_train = pd.read_csv('../DATA/SalePrice_train.csv')data_test = pd.read_csv('../DATA/SalePrice_test.csv')数据共有81个特征,为了便于说明只挑选7个特征OverallQualGrLivAreaGarageCarsTotalBsmtSF1stFlrSFFullBathYearBuilt因为这些数据与房⼦的售卖价格相关性⽐较⼤具体如何选择特征,见数据预处理data_train.shape(1460, 81)vars = ['OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'FullBath','YearBuilt']Y = data_train[['SalePrice']] #dim (1460, 1)ID_train = data_train[['Id']] #dim (1460, 1)ID_test = data_test[['Id']] #dim (1459, 1)#extract only the relevant feature with cross correlation >0.5 respect to SalePriceX_matrix = data_train[vars]X_matrix.shape #dim (1460,6)X_test = data_test[vars]X_test.shape #dim (1459,6)(1459, 6)查看丢失数据#check for missing data:#missing datatotal = X_matrix.isnull().sum().sort_values(ascending=False)percent = (X_matrix.isnull().sum()/X_matrix.count()).sort_values(ascending=False)missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])missing_data.head(20)#no missing data in this training setTotal PercentYearBuilt00.0FullBath00.0TotalBsmtSF00.0GarageCars00.0Total PercentGrLivArea00.0OverallQual0.0total = X_test.isnull().sum().sort_values(ascending=False)percent = (X_test.isnull().sum()/X_test.count()).sort_values(ascending=False)missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])missing_data.head(20)#missing data in this test setTotal PercentTotalBsmtSF10.000686GarageCars10.000686YearBuilt00.000000FullBath00.000000GrLivArea00.000000OverallQual00.000000#help(mat.ceil) #去上限使⽤均值代替缺失的数据#使⽤均值代替缺失的数据X_test['TotalBsmtSF'] = X_test['TotalBsmtSF'].fillna(X_test['TotalBsmtSF'].mean())X_test['GarageCars'] = X_test['GarageCars'].fillna(mat.ceil(X_test['GarageCars'].mean()))total = X_test.isnull().sum().sort_values(ascending=False)percent = (X_test.isnull().sum()/X_test.count()).sort_values(ascending=False)missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])missing_data.head(20)Total PercentYearBuilt00.0FullBath00.0TotalBsmtSF00.0GarageCars00.0GrLivArea00.0OverallQual00.0X_test.shape(1459, 6)然后预处理模块的特征缩放和均值归⼀化。
医学论文数据统计分析之多因素logistic回归分析背景:近期经常收到一些关于影响因素对相关疾病危害程度分析的咨询,其实可以通过SPSS进行多因素logistic回归分析实现。
多因素logistic回归分析是多个二元logistic回归模型描述各类与参考分类相比的各因素的综合分析。
工具:SPSS 19.0实例:代谢综合征中相关因素,包括: BMI、血压、血糖和血脂(甘油三酯)对产生结石危害程度分析。
BMI分为偏高和正常;血压分为偏高和正常;血糖分为高血糖和正常;血脂分为偏高和正常。
此外,校正因素包括年龄和性别,其中年龄分为小于36岁,36-50岁和大于50岁。
结石包括:草酸钙、尿酸和碳酸磷灰石三种类型。
说明: 本实例纯属为操作说明使用,结论不具有科学依据。
1、将整理好的数据导入SPSS软件工作表中,具体排列方式见下表。
2、选择分析-回归-多项logistic回归,进入“多项logistic回归”主对话框,其中因变量选择结石类型;BMI、血压、血糖和甘油三酯作为因子。
具体见下图。
3、点击“参考类别”进入话框,本例参考类别选择“最后类别”,类别顺序“升序”,点击继续。
具体见下图。
4、打开“模型”对话框,指定“主效应”后点击继续。
具体见下图。
5、打开“统计”对话框,按照下图勾选相应的选项后点击继续。
6、打开“保存”对话框,按照下图勾选相应的选项后点击继续。
7、点击“确定”按钮,软件开始建模。
8、结果解读,主要研读的是“参数估计表”,详见下图。
(1) 第二列B值,反应的各个影响因素不同水平在模型中的拟合系数,正负号表示其与结石类型是正还是反相关。
(2) 第六列是瓦尔德检验显著性值,若<0.05,说明自变量因素对因变量不同分类水平的变化有显著影响。
本例中血糖就是显著的影响因素。
(3) Exp(B)值即论文中常见的OR值,本例中空腹血糖被认为是草酸钙结石相关的重要危险因素。
9、将年龄和性别加到自变量中,重复前面所述的操作,得到校正结果,见下表。
209察值的差异性越小,回归方差的拟合程度越高。
若检验概率值<0.05,则说明模型不能很好地解释观测数据。
在图4-54中,“步骤1”的卡方值为0.475,检验概率为0.491,表示回归方程的预测值与原始的观察值没有显著性差异,本回归方程应该是有效的。
但“步骤2”的卡方值很大,而且其Sig 值为0,表示回归预测值与实际观测值有显著性差异。
因此,图4-54中“步骤1”提供的回归方程的拟合优度要高于“步骤2”。
4.5.2 二元Logistic 回归的实用案例1.二元Logistic 回归分析的成功案例(1)案例要求对于文件“大学生学习状态测试.sav ”文档,其内容如图4-55所示。
请以“喜欢物理否”为因变量,以性别、认知风格、学习态度、爱好、专业为自变量开展回归分析,并解释回归分析结果。
图4-55 待实施二元Logistic 分析的原始数据(2)分析解决方案由于被解释变量“喜欢物理否”是二元变量,所以可以使用二元Logistic 回归分析。
在执行回归分析前,应该进行数据的预处理,使相关数据完成必要的数值化变形。
另外,为了能很好地评价回归分析效果,在解读回归分析输出时,要重点关注NagelKerke R 方系数值和错判矩阵的正确判定率。
(3)操作过程首先,以SPSS 打开“大学学习状态测试.sav ”文档,使之处于“数据视图”状态。
然后,检查题目中要求的每个自变量,对于字符型变量“性别”“爱好”“认知风格”“学习态度”“专业”进行数值化编码,使之成为定序的数值型量,新变量名称为“Sex ”“S 爱好”“S 风格”“S 态度”“S 专业”。
然后对因变量“喜欢物理否”数值化编码为新变量“LikePhy ”,而且用1代表“喜欢”,用0代表“不喜欢”。
第三,利用菜单【分析】—【回归】—【二元Logistic 】命令,启动“Logistic 回归”对话框,如图4-56所示。
210图4-56 “Logistic回归”对话框第四,在“Logistic回归”对话框中,从左侧把数值型的被解释变量“S喜欢物理否[LikePhy]”添加到右侧的【因变量】列表框中。
二元Logistic回归案例分析二元Logistic,从字面上其实就可以理解大概是什么意思,Logistic中文意思为“逻辑”但是这里,并不是逻辑的意思,而是通过logit变换来命名的,二元一般指“两种可能性”就好比逻辑中的“是”或者“否”一样,Logistic 回归模型的假设检验——常用的检验方法有似然比检验(likelihood ratio test)和 Wald检验)似然比检验的具体步骤如下:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL02:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InL13: 最后比较两个对数似然函数值的差异,若两个模型分别包含l个自变量和P个自变量,记似然比统计量G的计算公式为 G=2(InLP - InLl). 在零假设成立的条件下,当样本含量n较大时,G统计量近似服从自由度为 V = P-l 的 x平方分布,如果只是对一个回归系数(或一个自变量)进行检验,则 v=1.wald 检验,用u检验或者X平方检验,推断各参数βj是否为0,其中u= bj / Sbj, X的平方=(bj / Sbj), Sbj 为回归系数的标准误这里的“二元”主要针对“因变量”所以跟“曲线估计”里面的Logistic曲线模型不一样,二元logistic回归是指因变量为二分类变量是的回归分析,对于这种回归模型,目标概率的取值会在(0-1),但是回归方程的因变量取值却落在实数集当中,这个是不能够接受的,所以,可以先将目标概率做 Logit变换,这样它的取值区间变成了整个实数集,再做回归分析就不会有问题了,采用这种处理方法的回归分析,就是Logistic回归设因变量为y, 其中“1” 代表事件发生,“0”代表事件未发生,影响y的 n个自变量分别为 x1, x2 ,x3 xn 等等记事件发生的条件概率为 P那么P= 事件未发生的概理为 1-P事件发生跟”未发生的概率比为( p / 1-p ) 事件发生比,记住Odds将Odds做对数转换,即可得到Logistic回归模型的线性模型:还是以教程“blankloan.sav"数据为例,研究银行客户贷款是否违约(拖欠)的问题,数据如下所示:上面的数据是大约700个申请贷款的客户,我们需要进行随机抽样,来进行二元Logistic回归分析,上图中的“0”表示没有拖欠贷款,“1”表示拖欠贷款,接下来,步骤如下:1:设置随机抽样的随机种子,如下图所示:选择“设置起点”选择“固定值”即可,本人感觉200万的容量已经足够了,就采用的默认值,点击确定,返回原界面、2:进行“转换”—计算变量“生成一个变量(validate),进入如下界面:在数字表达式中,输入公式:rv.bernoulli(0.7),这个表达式的意思为:返回概率为0.7的bernoulli分布随机值如果在0.7的概率下能够成功,那么就为1,失败的话,就为"0"为了保持数据分析的有效性,对于样本中“违约”变量取缺失值的部分,validate变量也取缺失值,所以,需要设置一个“选择条件”点击“如果”按钮,进入如下界面:如果“违约”变量中,确实存在缺失值,那么当使用"missing”函数的时候,它的返回值应该为“1”或者为“true",为了剔除”缺失值“所以,结果必须等于“0“也就是不存在缺失值的现象点击”继续“按钮,返回原界面,如下所示:将是“是否曾经违约”作为“因变量”拖入因变量选框,分别将其他8个变量拖入“协变量”选框内,在方法中,选择:forward.LR方法将生成的新变量“validate" 拖入"选择变量“框内,并点击”规则“设置相应的规则内容,如下所示:设置validate 值为1,此处我们只将取值为1的记录纳入模型建立过程,其它值(例如:0)将用来做结论的验证或者预测分析,当然你可以反推,采用0作为取值记录点击继续,返回,再点击“分类”按钮,进入如下页面在所有的8个自变量中,只有“教育水平”这个变量能够作为“分类协变量” 因为其它变量都没有做分类,本例中,教育水平分为:初中,高中,大专,本科,研究生等等, 参考类别选择:“最后一个”在对比中选择“指示符”点击继续按钮,返回再点击—“保存”按钮,进入界面:在“预测值"中选择”概率,在“影响”中选择“Cook距离” 在“残差”中选择“学生化”点击继续,返回,再点击“选项”按钮,进入如下界面:点击继续,再点击确定,可以得出分析结果了分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为 1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为 489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1, sig为0.000,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为 129,选定案例总和为489那么: y¯ = 129/489 = 0.2638036809816x¯ = 16951 / 489 = 34.664621676892所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.2638036809816 *(1-0.2638036809816 )则:y¯(1-y¯)* ∑(Xi-x则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 = 7.4595982010876 = 7.46 (四舍五入)计算过程采用的是在 EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~!!!!1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和 Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和 0.446,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR方的值!提示:将Hosmer 和 Lemeshow 检验和“随机性表” 结合一起来分析1:从 Hosmer 和 Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507卡方统计量< 临界值,从SIG 角度来看: 0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
logistic回归预测模型案例
以下是一个使用Logistic回归进行预测的案例:
我们使用Logistic回归来预测患有疝气病症的马的存活问题。
数据集包含299个训练样本和67个测试样本,每个样本有21个特征值。
这些特征可
能代表各种因素,例如马的年龄、体重、健康状况等。
首先,对特征值和因变量(存活率)进行二元Logistic回归分析,以确定哪些特征对存活率有影响。
分析过程中,可以使用方差分析来研究连续型变量(如年龄、体重等)与“是否违约”的关系,或者使用卡方检验来研究分类变量(如健康状况、疾病状况等)与“是否违约”的关系。
确定好分析项之后,进行Logistic回归分析,并解决回归分析中可能出现的多重共线性问题。
在这个过程中,可以采用随机抽样的方法来更新回归系数,以确保新数据仍然具有一定的影响。
通过这个过程,可以构建一个预测模型,以根据马的特征预测其存活率。
这样的模型可以帮助我们更好地理解影响马存活的各种因素,并优化马的健康管理和治疗策略。
以上案例仅供参考,如需更多信息,建议咨询统计学专业人士或查阅统计学相关书籍。
1.数据制备(栅格数据)
(1)宝塔区基底图层.tif
(2)居民点扩增.tif 、坡度.tif 、坡向.tif等要素数据。
在environment settings——processing extent——snap raster(选中基底图层),保证栅格数据像元无偏移,且行列的数量一致。
(3)栅格数据转为ASCII码,生成txt文档。
2.通过CLUE-S模型中的fileconvert模块,获得logistic回归分析的数据集。
(1)将上一步骤中的因变量y和影响因素x的.txt文档后缀改为.asc格式,并将文件放在CLUE-S模型所在的文件夹中。
(2)打开FileConvert V2软件,按下图勾选,填写“file list”内容,点击start
conversion,生成stat.txt 文档。
3.Spss软件中logistic二元回归分析
(1)数据标准化处理,加载数据——描述统计——描述,勾选“将标准化得分另存为变量”
(2)logistic回归分析
按图设置参数因变量、自变量;由于x3属于分类变量,点击分类按钮,按图设置参数。
点击“选项”按钮,按图进行勾选,继续。
点击“保存”按钮,勾选“概率”。
ROC曲线检测
欢迎您的下载,
资料仅供参考!
致力为企业和个人提供合同协议,策划案计划书,学习资料等
等
打造全网一站式需求。