大数据Hadoop生态圈思维导图
- 格式:xmin
- 大小:3.74 KB
- 文档页数:1

第1章初识Hadoop大数据技术本章主要介绍大数据的时代背景,给出了大数据的概念、特征,还介绍了大数据相关问题的解决方案、Hadoop大数据技术以及Hadoop的应用案例。
本章的主要内容如下。
(1)大数据技术概述。
(2)Google的三篇论文及其思想。
(3)Hadoop概述。
(4)Hadoop生态圈。
(5)Hadoop的典型应用场景和应用架构。
1.1 大数据技术概述1.1.1 大数据产生的背景1946年,计算机诞生,当时的数据与应用紧密捆绑在文件中,彼此不分。
19世纪60年代,IT系统规模和复杂度变大,数据与应用分离的需求开始产生,数据库技术开始萌芽并蓬勃发展,并在1990年后逐步统一到以关系型数据库为主导,具体发展阶段如图1-1所示。
Hadoop 大数据技术与应用图1-1 数据管理技术在2001年前的两个发展阶段 2001年后,互联网迅速发展,数据量成倍递增。
据统计,目前,超过150亿个设备连接到互联网,全球每秒钟发送290万封电子邮件,每天有2.88万小时视频上传到YouTube 网站,Facebook 网站每日评论达32亿条,每天上传照片近3亿张,每月处理数据总量约130万TB 。
2016年全球产生数据量16.1ZB ,预计2020年将增长到35ZB (1ZB = 1百万,PB = 10亿TB ),如图1-2所示。
图1-2 IDC 数据量增长预测报告2011年5月,EMC World 2011大会主题是“云计算相遇大数据”,会议除了聚焦EMC 公司一直倡导的云计算概念外,还抛出了“大数据”(BigData )的概念。
2011年6月底,IBM 、麦肯锡等众多国外机构发布“大数据”相关研究报告,并予以积极的跟进。
19世纪60年代,IT 系统规模和复杂度变大,数据与应用分离的需求开始产生,数据库技术开始萌芽并蓬勃发展,并在1990年后逐步统一到以关系型数据库为主导1946年,计算机诞生,数据与应用紧密捆绑在文件中,彼此不分1946 1951 1956 1961 1970 1974 1979 1991 2001 … 网络型E-RSQL 关系型数据库 数据仓库 第一台 计算机 ENIAC 面世 磁带+ 卡片 人工 管理 磁盘被发明,进入文件管理时代 GE 公司发明第一个网络模型数据库,但仅限于GE 自己的主机 IBM E. F.Dodd 提出关系模型 SQL 语言被发明 ORACLE 发布第一个商用SQL 关系数据库,后续快速发展数据仓库开始涌现,关系数据库开始全面普及且与平台无关,数据管理技术进入成熟期 0.8ZB :将一堆DVD 堆起来够地球到月亮一个来回 35ZB :将一堆DVD 堆起来是地球到火星距离的一半IDC 报告“Data Universe Study ”预测:全世界数据量将从2009年的0.8ZB 增长到2020年的35ZB ,增长44倍!年均增长率>40%!1.1.2 大数据的定义“大数据”是一个涵盖多种技术的概念,简单地说,是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。

大数据教程分享Hadoop入门学习线路图好程序员大数据教程分享Hadoop入门学习线路图,Hadoop是系统学习大数据的必会知识之一,Hadoop里面包括几个组件HDFS、MapReduce和YARN,HDFS是存储数据的地方就像我们电脑的硬盘一样文件都存储在这个上面,MapReduce是对数据进行处理计算的。
YARN是一种新的Hadoop资源管理器,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
如何入门Hadoop学习,不妨从以下这些知识点学起,希望我的分享能对大家的学习有帮助:先附一张大数据学习线路图:Zookeeper这是个万金油,安装Hadoop的HA的时候就会用到它,以后的Hbase也会用到它。
它一般用来存放一些相互协作的信息,这些信息比较小一般不会超过1M,都是使用它的软件对它有依赖,对于我们个人来讲只需要把它安装正确,让它正常的run起来就可以了。
Mysql我们学习完大数据的处理了,接下来学习学习小数据的处理工具mysql数据库,因为一会装hive的时候要用到,mysql需要掌握到什么层度那?你能在Linux上把它安装好,运行起来,会配置简单的权限,修改root的密码,创建数据库。
这里主要的是学习SQL的语法,因为hive的语法和这个非常相似。
Sqoop这个是用于把Mysql里的数据导入到Hadoop里的。
当然你也可以不用这个,直接把Mysql数据表导出成文件再放到HDFS上也是一样的,当然生产环境中使用要注意Mysql的压力。
Hive这个东西对于会SQL语法的来说就是神器,它能让你处理大数据变的很简单,不会再费劲的编写MapReduce程序。
Oozie既然学会Hive了,我相信你一定需要这个东西,它可以帮你管理你的Hive或者MapReduce、Spark脚本,还能检查你的程序是否执行正确,出错了给你发报警并能帮你重试程序,最重要的是还能帮你配置任务的依赖关系。

Hadoop生态圈以及各组成部分的简介_光环大数据hadoop培训1.Hadoop是什么?适合大数据的分布式存储与计算平台HDFS: Hadoop Distributed File System分布式文件系统MapReduce:并行计算框架2.Hadoop生态圈Google Bigtable的开源实现列式数据库可集群化可以使用shell、web、api等多种方式访问适合高读写(insert)的场景HQL查询语言NoSQL的典型代表产品②Hive数据仓库工具。
可以把Hadoop下的原始结构化数据变成Hive中的表支持一种与SQL几乎完全相同的语言HiveQL。
除了不支持更新、索引和事务,几乎SQL的其它特征都能支持可以看成是从SQL到Map-Reduce的映射器提供shell、JDBC/ODBC、Thrift、Web等接口③ZookeeperGoogle Chubby的开源实现用于协调分布式系统上的各种服务。
例如确认消息是否准确到达,防止单点失效,处理负载均衡等应用场景:Hbase,实现Namenode自动切换工作原理:领导者,跟随者以及选举过程④Sqoop用于在Hadoop和关系型数据库之间交换数据通过JDBC接口连入关系型数据库⑤Chukwa架构在Hadoop之上的数据采集与分析框架主要进行日志采集和分析通过安装在收集节点的“代理”采集最原始的日志数据代理将数据发给收集器收集器定时将数据写入Hadoop集群指定定时启动的Map-Reduce作业队数据进行加工处理和分析⑥PigHadoop客户端使用类似于SQL的面向数据流的语言Pig LatinPig Latin可以完成排序,过滤,求和,聚组,关联等操作,可以支持自定义函数Pig自动把Pig Latin映射为Map-Reduce作业上传到集群运行,减少用户编写Java程序的苦恼⑦Avro数据序列化工具,由Hadoop的创始人Doug Cutting主持开发用于支持大批量数据交换的应用。




Hadoop生态圈的技术架构解析Hadoop生态圈是一个开源的大数据处理框架,它包括了多个开源组件,如Hadoop、HDFS、YARN、MapReduce等。
这些组件共同构成了Hadoop生态圈。
本文将分别解析Hadoop生态圈的技术架构,以及介绍该生态圈能够如何帮助人们更好地处理海量数据。
一、Hadoop技术架构Hadoop在存储和处理大数据方面具有很强的优势。
它的技术架构包括了机器集群、分布式文件系统和MapReduce执行框架。
机器集群是Hadoop生态圈中最基本的组成部分,它由部署在多个计算节点上的物理或虚拟计算机组成。
这些计算机之间相互通信,由此形成了一个集群。
分布式文件系统是在机器集群上运行的,它是Hadoop生态圈中的分布式存储系统。
HDFS(Hadoop Distributed File System)是其中最为著名的文件系统,它将大文件分割成多个更小的块,并将这些块分散存储到机器集群中的不同节点上。
这种分布式存储方式可以提高数据的可用性,并且允许多个数据处理作业同时处理存储在HDFS上的数据。
MapReduce是一种Hadoop中的并行计算模型,它将大规模任务划分成多个子任务,并将这些子任务分配给机器集群中的不同计算节点上。
当每个计算节点处理完它们分配到的任务后,MapReduce将结果合并,然后将最终结果交付给用户。
通过这种方式,用户可以在较短的时间内处理大量数据。
Hadoop处理数据的流程通常为:用户输入数据(可能是大量的非结构化数据),Hadoop将数据分割存储到HDFS中,然后使用MapReduce模型创建作业,并将作业分离成若干子作业,从而让集群中的计算节点能够并行处理任务。
处理完成后,Hadoop将结果输出到HDFS,供用户访问。
二、Hadoop生态圈中的其他组件为了满足不同的大数据需求,Hadoop生态圈中还包括了许多其他组件,以下将对其中几个组件进行简单介绍。
1. HBaseHBase是一个基于Hadoop的分布式数据库系统,它使用HDFS 作为底层存储系统,同时提供了快速、随机的实时读写操作。

无论你是否承认,Hadoop如今已经成为大数据运动的代名词和重心。
围绕Hadoop产品技术已经形成软件、应用、服务的综合体,或者说生态系统。
Hadoop生态系统就像一颗年轻的超新星,随时都在快速分化和增长,新产品、新模式不断涌现。
为了帮助企业和业界的大数据技术和应用的实践者快速理清Hadoop生态系统的头绪,GigaOM最近制作了一张Hadoop生态系统地图,按照不同的应用场景和交付模式,将Hadoop生态系统的厂商和产品划分为六大层面和八类玩家:
版本发行商
第三方管理软件提供商
Hadoop基础功能扩展厂商(例如SQL on Hadoop)
Hadoop打包服务商(例如Oracle、惠普等公司的大数据一体机产品或者整合入现有的产品套件,此类厂商并未开发Hadoop层面的技术,而是直接采用Hortonworks和Cloudera等公司的现成的发行版本)
Hadoop基础设施提供商
Hadoop应用开发商
Hadoop分析应用平台服务商
Hadoop竞争平台、HDFS替代产品提供商
大家也可以结合IT经理网之前的大数据生态地图:大数据的38种商业模式,对比阅读。
Hadoop生态系统地图中的亮点信息还包括:
● SQL-on-Hadoop是最近的热点,这个领域的厂商和企业希望能在全新的数据平台上提供类似传统数据仓库的体验,在Hadoop应用领域也存在类似的热点。
● Hadoop版本发行依然是最稳定的和利润最丰厚的Hadoop市场领域,参与其中的都是大公司或者有大量投资支撑的创业公司。
参考阅读:Hadoop发行版战争升级,NoSQL的未来是SQL?。

01Hadoop概述Hadoop体系也是一个计算框架,在这个框架下,可以使用一种简单的编程模式,通过多台计算机构成的集群,分布式处理大数据集。
Hadoop是可扩展的,它可以方便地从单一服务器扩展到数千台服务器,每台服务器进行本地计算和存储。
除了依赖于硬件交付的高可用性,软件库本身也提供数据保护,并可以在应用层做失败处理,从而在计算机集群的顶层提供高可用服务。
Hadoop核心生态圈组件如图1所示。
图1Haddoop开源生态02Hadoop生态圈Hadoop包括以下4个基本模块。
1)Hadoop基础功能库:支持其他Hadoop模块的通用程序包。
2)HDFS:一个分布式文件系统,能够以高吞吐量访问应用中的数据。
3)YARN:一个作业调度和资源管理框架。
4)MapReduce:一个基于YARN的大数据并行处理程序。
除了基本模块,Hadoop还包括以下项目。
1)Ambari:基于Web,用于配置、管理和监控Hadoop集群。
支持HDFS、MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig和Sqoop。
Ambari还提供显示集群健康状况的仪表盘,如热点图等。
Ambari以图形化的方式查看MapReduce、Pig和Hive应用程序的运行情况,因此可以通过对用户友好的方式诊断应用的性能问题。
2)Avro:数据序列化系统。
3)Cassandra:可扩展的、无单点故障的NoSQL多主数据库。
4)Chukwa:用于大型分布式系统的数据采集系统。
5)HBase:可扩展的分布式数据库,支持大表的结构化数据存储。
6)Hive:数据仓库基础架构,提供数据汇总和命令行即席查询功能。
7)Mahout:可扩展的机器学习和数据挖掘库。
8)Pig:用于并行计算的高级数据流语言和执行框架。
9)Spark:可高速处理Hadoop数据的通用计算引擎。
Spark提供了一种简单而富有表达能力的编程模式,支持ETL、机器学习、数据流处理、图像计算等多种应用。
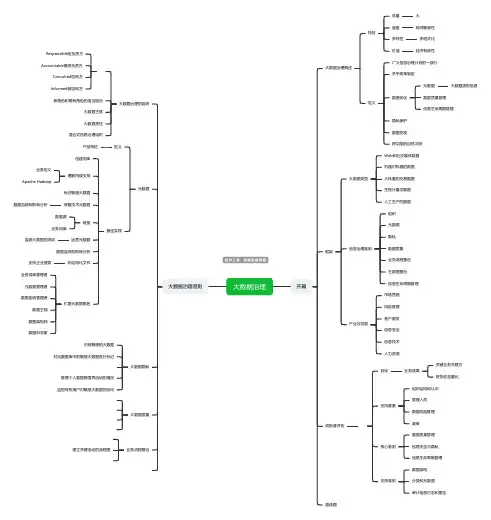
大数据治理开篇大数据治理概述特征体量大速度时间敏感性多样性多格式化价值经济有效性定义广义信息治理计划的一部分关乎政策制定数据优化元数据大数据类别信息数据质量管理信息生命周期管理隐私保护数据变现跨功能的自然冲突框架大数据类型Web和社交媒体数据机器对机器的数据大体量的交易数据生物计量学数据人工生产的数据信息治理准则组织元数据隐私数据质量业务流程整合主数据整合信息生命周期管理产业与功能市场营销风险管理客户服务信息安全信息技术人力资源成熟度评估目标业务成果关键业务关联方财务收益量化支持要素组织结构和认识管理人员数据风险管理政策核心准则数据质量管理信息安全与隐私信息生命周期管理支持准则数据架构分类和元数据审计信息日志和报告路线图大数据治理准则大数据治理的组织Responsible应负责方Accountable最终负责方Consulted咨询方Informed被告知方新角色和既有角色的适当组合大数据主管大数据责任混合式信息治理组织元数据定义产品特征最佳实践创建词库理解持续支持业务定义Apache Hadoop标记敏感大数据保留技术元数据数据血统和影响分析链接数据源业务词库运营元数据监测大数据的流动数据血统和影响分析非结构化文件支持企业搜索扩展元数据角色业务词库管理者元数据管理者数据血统管理者数据主观数据架构师数据科学家大数据隐私识别敏感的大数据对元数据库中的敏感大数据进行标记管理个人数据跨国界流动的情况监控特权用户对敏感大数据的访问大数据质量业务流程整合建立关键活动的流程图。