深入分析 Linux 内核链表
- 格式:pdf
- 大小:296.04 KB
- 文档页数:9

Linux内核:RCU机制与使⽤Linux 内核:RCU机制与使⽤背景学习Linux源码的时候,发现很多熟悉的数据结构多了__rcu后缀,因此了解了⼀下这些内容。
介绍RCU(Read-Copy Update)是数据同步的⼀种⽅式,在当前的Linux内核中发挥着重要的作⽤。
RCU主要针对的数据对象是链表,⽬的是提⾼遍历读取数据的效率,为了达到⽬的使⽤RCU机制读取数据的时候不对链表进⾏耗时的加锁操作。
这样在同⼀时间可以有多个线程同时读取该链表,并且允许⼀个线程对链表进⾏修改(修改的时候,需要加锁)。
RCU适⽤于需要频繁的读取数据,⽽相应修改数据并不多的情景,例如在⽂件系统中,经常需要查找定位⽬录,⽽对⽬录的修改相对来说并不多,这就是RCU发挥作⽤的最佳场景。
RCU(Read-Copy Update),是 Linux 中⽐较重要的⼀种同步机制。
顾名思义就是“读,拷贝更新”,再直⽩点是“随意读,但更新数据的时候,需要先复制⼀份副本,在副本上完成修改,再⼀次性地替换旧数据”。
这是 Linux 内核实现的⼀种针对“读多写少”的共享数据的同步机制。
RCU机制解决了什么在RCU的实现过程中,我们主要解决以下问题:1、在读取过程中,另外⼀个线程删除了⼀个节点。
删除线程可以把这个节点从链表中移除,但它不能直接销毁这个节点,必须等到所有的读取线程读取完成以后,才进⾏销毁操作。
RCU中把这个过程称为宽限期(Grace period)。
2、在读取过程中,另外⼀个线程插⼊了⼀个新节点,⽽读线程读到了这个节点,那么需要保证读到的这个节点是完整的。
这⾥涉及到了发布-订阅机制(Publish-Subscribe Mechanism)。
3、保证读取链表的完整性。
新增或者删除⼀个节点,不⾄于导致遍历⼀个链表从中间断开。
但是RCU并不保证⼀定能读到新增的节点或者不读到要被删除的节点。
RCU(Read-Copy Update),顾名思义就是读-拷贝修改,它是基于其原理命名的。

Linux 内核启动分析1. 内核启动地址1.1. 名词解释ZTEXTADDR解压代码运行的开始地址。
没有物理地址和虚拟地址之分,因为此时MMU处于关闭状态。
这个地址不一定时RAM的地址,可以是支持读写寻址的flash等存储中介。
Start address of decompressor. here's no point in talking about virtual or physical addresses here, since the MMU will be off at the time when you call the decompressor code. Y ou normally call the kernel at this address to start it booting. This doesn't have to be located in RAM, it can be in flash or other read-only or read-write addressable medium.ZRELADDR内核启动在RAM中的地址。
压缩的内核映像被解压到这个地址,然后执行。
This is the address where the decompressed kernel will be written, and eventually executed. The following constraint must be valid:__virt_to_phys(TEXTADDR) == ZRELADDRThe initial part of the kernel is carefully coded to be position independent.TEXTADDR内核启动的虚拟地址,与ZRELADDR相对应。
一般内核启动的虚拟地址为RAM的第一个bank地址加上0x8000。

linux内核源码分析-nvme设备的初始化本⽂基于3.18.3内核的分析,nvme设备为pcie接⼝的ssd,其驱动名称为nvme.ko,驱动代码在drivers/block/nvme-core.c.驱动的加载 驱动加载实际就是module的加载,⽽module加载时会对整个module进⾏初始化,nvme驱动的module初始化函数为nvme_init(),如下:static struct pci_driver nvme_driver = {.name = "nvme",.id_table = nvme_id_table,.probe = nvme_probe,.remove = nvme_remove,.shutdown = nvme_shutdown,.driver = {.pm = &nvme_dev_pm_ops,},.err_handler = &nvme_err_handler,};static int __init nvme_init(void){int result;/* 初始化等待队列nvme_kthread_wait,此等待队列⽤于创建nvme_kthread(只允许单进程创建nvme_kthread) */init_waitqueue_head(&nvme_kthread_wait);/* 创建⼀个workqueue叫nvme */nvme_workq = create_singlethread_workqueue("nvme");if (!nvme_workq)return -ENOMEM;/* 在内核中注册新的⼀类块设备驱动,名字叫nvme,注意这⾥只是注册,表⽰kernel⽀持了nvme类的块设备,返回⼀个major,之后所有的nvme设备的major都是此值 */result = register_blkdev(nvme_major, "nvme");if (result < 0)goto kill_workq;else if (result > 0)nvme_major = result;/* 注册⼀些通知信息 */nvme_nb.notifier_call = &nvme_cpu_notify;result = register_hotcpu_notifier(&nvme_nb);if (result)goto unregister_blkdev;/* 注册pci nvme驱动 */result = pci_register_driver(&nvme_driver);if (result)goto unregister_hotcpu;return0;unregister_hotcpu:unregister_hotcpu_notifier(&nvme_nb);unregister_blkdev:unregister_blkdev(nvme_major, "nvme");kill_workq:destroy_workqueue(nvme_workq);return result;} 这⾥⾯其实最重要的就是做了两件事,⼀件事是register_blkdev,注册nvme这类块设备,返回⼀个major,另⼀件事是注册了nvme_driver,注册了nvme_driver后,当有nvme设备插⼊后系统后,系统会⾃动调⽤nvme_driver->nvme_probe去初始化这个nvme设备.这时候可能会有疑问,系统是如何知道插⼊的设备是nvme设备的呢,注意看struct pci_driver nvme_driver这个结构体,⾥⾯有⼀个nvme_id_table,其内容如下:/* Move to pci_ids.h later */#define PCI_CLASS_STORAGE_EXPRESS 0x010802static const struct pci_device_id nvme_id_table[] = {{ PCI_DEVICE_CLASS(PCI_CLASS_STORAGE_EXPRESS, 0xffffff) },{ 0, }};再看看PCI_DEVICE_CLASS宏是如何定义的#define PCI_DEVICE_CLASS(dev_class,dev_class_mask) \.class = (dev_class), .class_mask = (dev_class_mask), \.vendor = PCI_ANY_ID, .device = PCI_ANY_ID, \.subvendor = PCI_ANY_ID, .subdevice = PCI_ANY_ID也就是当pci class为PCI_CLASS_STORAGE_EXPRESS时,就表⽰是nvme设备,并且这个是写在设备⾥的,当设备插⼊host时,pci driver(并不是nvme driver)回去读取这个值,然后判断它需要哪个驱动去做处理.nvme数据结构 现在假设nvme.ko已经加载完了(注册了nvme类块设备,并且注册了nvme driver),这时候如果有nvme盘插⼊pcie插槽,pci会⾃动识别到,并交给nvme driver去处理,⽽nvme driver就是调⽤nvme_probe去处理这个新加⼊的设备. 在说nvme_probe之前,先说⼀下nvme设备的数据结构,⾸先,内核使⽤⼀个nvme_dev结构体来描述⼀个nvme设备, ⼀个nvme设备对应⼀个nvme_dev,nvme_dev如下:/* nvme设备描述符,描述⼀个nvme设备 */struct nvme_dev {struct list_head node;/* 设备的queue,⼀个nvme设备⾄少有2个queue,⼀个admin queue,⼀个io queue,实际情况⼀般都是⼀个admin queue,多个io queue,并且io queue会与CPU做绑定 */ struct nvme_queue __rcu **queues;/* unsigned short的数组,每个CPU占⼀个,主要⽤于存放CPU上绑定的io queue的qid,⼀个CPU绑定⼀个queues,⼀个queues绑定到1到多个CPU上 */unsigned short __percpu *io_queue;/* ((void __iomem *)dev->bar) + 4096 */u32 __iomem *dbs;/* 此nvme设备对应的pci dev */struct pci_dev *pci_dev;/* dma池,主要是以4k为⼤⼩的dma块,⽤于dma分配 */struct dma_pool *prp_page_pool;/* 也是dma池,但是不是以4k为⼤⼩的,是⼩于4k时使⽤ */struct dma_pool *prp_small_pool;/* 实例的id,第⼀个加⼊的nvme dev,它的instance为0,第⼆个加⼊的nvme,instance为1,也⽤于做/dev/nvme%d的显⽰,%d实际就是instance的数值 */int instance;/* queue的数量, 等于admin queue + io queue */unsigned queue_count;/* 在线可以使⽤的queue数量,跟online cpu有关 */unsigned online_queues;/* 最⼤的queue id */unsigned max_qid;/* nvme queue⽀持的最⼤cmd数量,为((bar->cap) & 0xffff)或者1024的最⼩值 */int q_depth;/* 1 << (((bar->cap) >> 32) & 0xf),应该是每个io queue占⽤的bar空间 */u32 db_stride;/* 初始化设置的值* dev->ctrl_config = NVME_CC_ENABLE | NVME_CC_CSS_NVM;* dev->ctrl_config |= (PAGE_SHIFT - 12) << NVME_CC_MPS_SHIFT;* dev->ctrl_config |= NVME_CC_ARB_RR | NVME_CC_SHN_NONE;* dev->ctrl_config |= NVME_CC_IOSQES | NVME_CC_IOCQES;*/u32 ctrl_config;/* msix中断所使⽤的entry,指针表⽰会使⽤多个msix中断,使⽤的中断的个数与io queue对等,多少个io queue就会申请多少个中断* 并且让每个io queue的中断尽量分到不同的CPU上运⾏*/struct msix_entry *entry;/* bar的映射地址,默认是映射8192,当io queue过多时,有可能会⼤于8192 */struct nvme_bar __iomem *bar;/* 其实就是块设备,⼀张nvme卡有可能会有多个块设备 */struct list_head namespaces;/* 对应的在/sys下的结构 */struct kref kref;/* 对应的字符设备,⽤于ioctl操作 */struct miscdevice miscdev;/* 2个work,暂时还不知道什么⽤ */work_func_t reset_workfn;struct work_struct reset_work;struct work_struct cpu_work;/* 这个nvme设备的名字,为nvme%d */char name[12];/* SN号 */char serial[20];char model[40];char firmware_rev[8];/* 这些值都是从nvme盘上获取 */u32 max_hw_sectors;u32 stripe_size;u16 oncs;u16 abort_limit;u8 vwc;u8 initialized;}; 在nvme_dev结构中,最最重要的数据就是nvme_queue,struct nvme_queue⽤来表⽰⼀个nvme的queue,每⼀个nvme_queue会申请⾃⼰的中断,也有⾃⼰的中断处理函数,也就是每个nvme_queue在驱动层⾯是完全独⽴的.nvme_queue有两种,⼀种是admin queue,⼀种是io queue,这两种queue都⽤struct nvme_queue来描述,⽽这两种queue的区别如下:admin queue: ⽤于发送控制命令的queue,所有⾮io命令都会通过此queue发送给nvme设备,⼀个nvme设备只有⼀个admin queue,在nvme_dev中,使⽤queues[0]来描述.io queue: ⽤于发送io命令的queue,所有io命令都是通过此queue发送给nvme设备,简单来说读/写操作都是通过io queue发送给nvme设备的,⼀个nvme设备有⼀个或多个io queue,每个io queue的中断会绑定到不同的⼀个或多个CPU上.在nvme_dev中,使⽤queues[1~N]来描述. 以上说的io命令和⾮io命令都是nvme命令,⽐如快层下发⼀个写request,nvme驱动就会根据此request构造出⼀个写命令,将这个写命令放⼊某个io queue中,当controller完成了这个写命令后,会通过此io queue的中断返回完成信息,驱动再将此完成信息返回给块层.明⽩了两种队列的作⽤,我们看看具体的数据结构struct nvme_queue/* nvme的命令队列,其中包括sq和cq。

深入分析request_irq的dev_id参数作用上一篇/ 下一篇 2010-07-21 22:06:44 / 个人分类:Linux移植查看( 358 ) / 评论( 0 ) / 评分( 0 / 0 )注:若对kernel中断处理模型不是很清楚的话(如:irqaction的作用)可以先参考一下这篇文档:/u2/60011/showart.php?id=1079281这里主要讲request_irq的参数dev_id的作用,内容会涉及到少许上面文档提到的内容。
Request_irq的作用是申请使用IRQ并注册中断处理程序。
request_irq()函数的原型如下:我们知道,当使用内核共享中断时,request_irq必须要提供dev_id参数,并且dev_id的值必须唯一。
那么这里提供唯一的dev_id值的究竟是做什么用的?起先我以为dev_id的值是提供给kernel进行判断共享中断线上的哪一个设备产生了中断(即哪个irqaction 产生中断),然后执行相应的中断处理函数(irqaction->handler)。
实际上不是的,我们来看看《Linux Kernel Development – Second Edition》第六章中Shared Handlers这一节,其中有段总结性的文字如下:When the kernel receives an interrupt, it invokes sequentially each registered handler on the line. Therefore, it is important that the handler be capable of distinguishing whether it generated a giveninterrupt. The handler must quickly exit if its associated device did not generate the interrupt. This requires the hardware device to have a status register (or similar mechanism) that the handler can check. Most hardware does indeed have such a feature.这段话的大概意思是,发生中断时,内核并不判断究竟是共享中断线上的哪个设备产生了中断,它会循环执行所有该中断线上注册的中断处理函数(即irqaction->handler函数)。
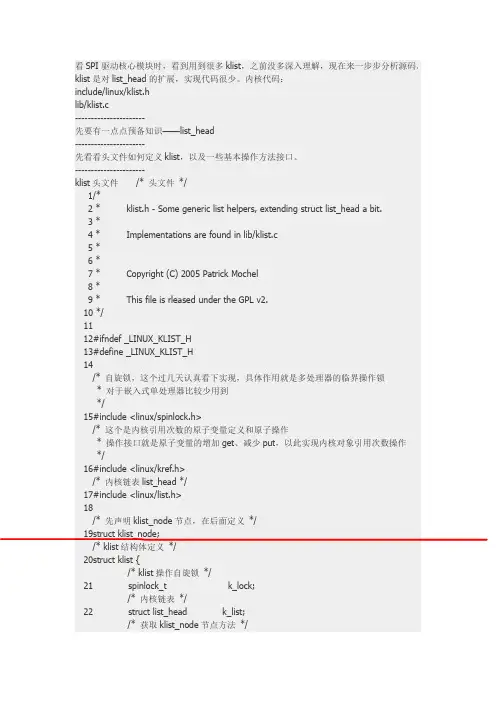
142/**143*klist_add_after-Init a klist_node and add it after an existing node 144*@n:node we're adding.145*@pos:node to put@n after146*//*在节点pos后面插入节点n*/147void klist_add_after(struct klist_node*n,struct klist_node*pos)148{149struct klist*k=knode_klist(pos);150151klist_node_init(k,n);152spin_lock(&k->k_lock);153list_add(&n->n_node,&pos->n_node);154spin_unlock(&k->k_lock);155}156EXPORT_SYMBOL_GPL(klist_add_after);157158/**159*klist_add_before-Init a klist_node and add it before an existing node 160*@n:node we're adding.161*@pos:node to put@n after162*//*在节点pos前面插入节点n*/163void klist_add_before(struct klist_node*n,struct klist_node*pos)164{165struct klist*k=knode_klist(pos);166167klist_node_init(k,n);168spin_lock(&k->k_lock);169list_add_tail(&n->n_node,&pos->n_node);170spin_unlock(&k->k_lock);171}172EXPORT_SYMBOL_GPL(klist_add_before);173/*等待者结构体,用于删除节点,删除完成唤醒进程*/174struct klist_waiter{175struct list_head list;176struct klist_node*node;177struct task_struct*process;178int woken;179};180/*定义并初始化klist节点移除自旋锁*/181static DEFINE_SPINLOCK(klist_remove_lock);/*定义一个等待器的链表*/182static LIST_HEAD(klist_remove_waiters);183184static void klist_release(struct kref*kref)185{186struct klist_waiter*waiter,*tmp;187struct klist_node*n=container_of(kref,struct klist_node,n_ref);188189WARN_ON(!knode_dead(n));/*删除链表中的节点入口*/190list_del(&n->n_node);191spin_lock(&klist_remove_lock);/*内核链表操作宏include/linux/list.h,遍历klist节点移除等待链表*/192list_for_each_entry_safe(waiter,tmp,&klist_remove_waiters,list){/*是要删除链表节点的等待器*/193if(waiter->node!=n)194continue;195/*等待者唤醒标志*/196waiter->woken=1;197mb();/*唤醒等待进程*/198wake_up_process(waiter->process);/*删除链表入口*/199list_del(&waiter->list);200}201spin_unlock(&klist_remove_lock);/*设置节点n指向的klist为空*/202knode_set_klist(n,NULL);203}204/*减引用次数并删除节点*/205static int klist_dec_and_del(struct klist_node*n)206{/*n->nref减引用次数,若引用次数减完不为0,调用klist_release清除节点对象,返回1;为0,则返回0*/207return kref_put(&n->n_ref,klist_release);208}209/*带锁操作的节点删除,不判断是否成功,减引用次数*/210static void klist_put(struct klist_node*n,bool kill)211{/*获取节点的put方法*/212struct klist*k=knode_klist(n);213void(*put)(struct klist_node*)=k->put;214215spin_lock(&k->k_lock);/*“需要杀死节点”==*/216if(kill)217knode_kill(n);/*节点对象引用次数为0了,则不需要调用put方法*/218if(!klist_dec_and_del(n))219put=NULL;220spin_unlock(&k->k_lock);/*调用put方法*/221if(put)222put(n);223}224225/**226*klist_del-Decrement the reference count of node and try to remove. 227*@n:node we're deleting.228*//*删除节点“杀死死节点*/229void klist_del(struct klist_node*n)230{231klist_put(n,true);232}233EXPORT_SYMBOL_GPL(klist_del);234235/**236*klist_remove-Decrement the refcount of node and wait for it to go away. 237*@n:node we're removing.238*/239void klist_remove(struct klist_node*n)240{/*定义一个等待者,并加入等待者加入移除等待者链表*/241struct klist_waiter waiter;242243waiter.node=n;244waiter.process=current;245waiter.woken=0;246spin_lock(&klist_remove_lock);247list_add(&waiter.list,&klist_remove_waiters);248spin_unlock(&klist_remove_lock);249/*清除节点,并设置等待者*/330*First grab list lock.Decrement the reference count of the previous 331*node,if there was one.Grab the next node,increment its reference 332*count,drop the lock,and return that next node.333*//*“预下”链表中下一节点*/334struct klist_node*klist_next(struct klist_iter*i)335{336void(*put)(struct klist_node*)=i->i_klist->put;337struct klist_node*last=i->i_cur;338struct klist_node*next;339/*抢占锁*/340spin_lock(&i->i_klist->k_lock);341/*获取下一节点*/342if(last){343next=to_klist_node(last->n_node.next);/*减上一节点引用次数*/344if(!klist_dec_and_del(last))345put=NULL;346}else347next=to_klist_node(i->i_klist->k_list.next);348349i->i_cur=NULL;/*链表中有节点“没死”,增加引用次数*/350while(next!=to_klist_node(&i->i_klist->k_list)){351if(likely(!knode_dead(next))){352kref_get(&next->n_ref);353i->i_cur=next;354break;355}356next=to_klist_node(next->n_node.next);357}358/*丢弃锁*/359spin_unlock(&i->i_klist->k_lock);360361if(put&&last)362put(last);363return i->i_cur;364}365EXPORT_SYMBOL_GPL(klist_next);366----------------------/*使用迭代查找下一链表节点*/1124struct klist_node*n=klist_next(i);1125struct device*dev=NULL;1126struct device_private*p;11271128if(n){/*根据节点入口获取该节点上的设备*/1129p=to_device_private_parent(n);1130dev=p->device;1131}1132return dev;1133}/*-------------------------------------------------------------------------------*//*其中device_private是设备私有数据结构,一下代码不难看出*想要由链表节点迭代查找设备非常容易*/66/**67*struct device_private-structure to hold the private to the driver core portions of the device structure.68*69*@klist_children-klist containing all children of this device70*@knode_parent-node in sibling list71*@knode_driver-node in driver list72*@knode_bus-node in bus list73*@driver_data-private pointer for driver specific info.Will turn into a74*list soon.75*@device-pointer back to the struct class that this structure is76*associated with.77*78*Nothing outside of the driver core should ever touch these fields.79*/80struct device_private{81struct klist klist_children;82struct klist_node knode_parent;83struct klist_node knode_driver;84struct klist_node knode_bus;85void*driver_data;86struct device*device;87};88#define to_device_private_parent(obj)\89container_of(obj,struct device_private,knode_parent)90#define to_device_private_driver(obj)\91container_of(obj,struct device_private,knode_driver)92#define to_device_private_bus(obj)\93container_of(obj,struct device_private,knode_bus) 94driver_attach()函数driver_attach()函数2009-04-2114:39:03|分类:linux kernel|字号订阅最近在看一个mpc8315CPU上的驱动程序发现在使用spi_register注册完成后没有调用到相应的probe函数,分析后发现在driver_attach()函数执行时没有找到匹配的device,在网上狗狗后找到关于这部分的分析,引用如下:个浅析linux2.6.23驱动自动匹配设备driver_attach()函数文章来源:int driver_attach(struct device_driver*drv){return bus_for_each_dev(drv->bus,NULL,drv,__driver_attach);}调用该函数,那么drv驱动程式会和drv所在总线上连接了的物理设备进行一一匹配,再来看看下面:int bus_for_each_dev(struct bus_type*bus,struct device*start,void*data,int(*fn)(struct device*,void*)){struct klist_iter i;//专门用于遍历的链表结构体,其中i_cur是遍历移动的关键struct device*dev;int error=0;if(!bus)return-EINVAL;klist_iter_init_node(&bus->klist_devices,&i,(start?&start->knode_bus:NULL));//i->i_klist=&bus->klist_devices;//i->i_head=&bus->klist_devices.k_list;//i->i_cur=NULL;//表示从最前端开始遍历挂接到bus总线上的整个设备链条.while((dev=next_device(&i))&&!error)//dev为该bus总线链表上的一个设备,[就像一根藤条上的一朵小花gliethttp_20071025] //这些device设备把自己的&device->knode_bus链表单元链接到了bus->klist_devices 上//这也说明名字为knode_bus的list单元将是要被挂接到bus->klist_devices的链表上//同理&device->knode_driver将是这个device设备链接到drivers驱动上的list节点识别单元//见driver_bound()->klist_add_tail(&dev->knode_driver,&dev->driver->klist_devices);error=fn(dev,data);//调用__driver_attach函数,进行匹配运算klist_iter_exit(&i);return error;//成功匹配返回0}struct klist_iter{struct klist*i_klist;struct list_head*i_head;struct klist_node*i_cur;};void klist_iter_init_node(struct klist*k,struct klist_iter*i,struct klist_node*n){i->i_klist=k;//需要被遍历的klisti->i_head=&k->k_list;//开始的链表头i->i_cur=n;//当前位置对应的klist_node节点,next_device()会从当前n 开始一直搜索到//链表的结尾,也就是i_head->prev处停止if(n)kref_get(&n->n_ref);//引用计数加1}static struct device*next_device(struct klist_iter*i){struct klist_node*n=klist_next(i);return n?container_of(n,struct device,knode_bus):NULL;//因为n是device->knode_bus的指针,所以container_of将返回device的指针}struct klist_node*klist_next(struct klist_iter*i){struct list_head*next;struct klist_node*lnode=i->i_cur;struct klist_node*knode=NULL;//赋0,当next==i->i_head时用于退出void(*put)(struct klist_node*)=i->i_klist->put;spin_lock(&i->i_klist->k_lock);if(lnode){next=lnode->n_node.next;if(!klist_dec_and_del(lnode))//释放前一个i_cur对象的引用计数put=NULL;//klist_dec_and_del成功的对引用计数做了减1操作,那么失效用户定义put}elsenext=i->i_head->next;//如果lnode=0,那么从链表头开始,所以head->next指向第1个实际对象if(next!=i->i_head){//head并不链接设备,所以head无效//当next==i->i_head时,说明已遍历到了head牵头的链表的末尾,回环到了head, //所以knode将不会进行赋值,这时knode=0,while((dev=next_device(&i))&&!error)因为0而退出knode=to_klist_node(next);//调用container_of()获取klist_node->n_node中klist_node地址kref_get(&knode->n_ref);//对该node的引用计数加1}i->i_cur=knode;//记住当前遍历到的对象,当next==i->i_head时,knode=0spin_unlock(&i->i_klist->k_lock);if(put&&lnode)put(lnode);return knode;}static int klist_dec_and_del(struct klist_node*n){return kref_put(&n->n_ref,klist_release);//对该node的引用计数减1,如果引用计数到达0,那么调用klist_release}static void klist_release(struct kref*kref){struct klist_node*n=container_of(kref,struct klist_node,n_ref);list_del(&n->n_node);//从节点链表上摘掉该node节点complete(&n->n_removed);//n->n_klist=NULL;}void fastcall complete(struct completion*x){unsigned long flags;spin_lock_irqsave(&x->wait.lock,flags);//关闭中断,防止并发x->done++;//唤醒因为某些原因悬停在klist_node->n_removed等待队列上的task们//这种现象之一是:__device_release_driver()删除挂接在设备上的driver时,会出现//删除task小憩在node的wait上__wake_up_common(&x->wait,TASK_UNINTERRUPTIBLE|TASK_INTERRUPTIBLE,1,0,NULL);spin_unlock_irqrestore(&x->wait.lock,flags);//恢复中断}static void__wake_up_common(wait_queue_head_t*q,unsigned int mode,int nr_exclusive,int sync,void*key){struct list_head*tmp,*next;list_for_each_safe(tmp,next,&q->task_list){//遍历以head牵头的链表上的task们wait_queue_t*curr=list_entry(tmp,wait_queue_t,task_list);unsigned flags=curr->flags;if(curr->func(curr,mode,sync,key)&&//调用wait上准备好了的回调函数func (flags&WQ_FLAG_EXCLUSIVE)&&!--nr_exclusive)break;}}//抛开链表上的head,当最后一个post==head时,说明链表已遍历结束(gliethttp_20071025) #define list_for_each_safe(pos,n,head)\for(pos=(head)->next,n=pos->next;pos!=(head);\pos=n,n=pos->next)void klist_iter_exit(struct klist_iter*i){if(i->i_cur){//对于正常遍历的退出,i->i_cur会等于0,如果找到了匹配对象,提前退出了,那么就会在这里对引用进行释放klist_del(i->i_cur);i->i_cur=NULL;}}static int__driver_attach(struct device*dev,void*data){struct device_driver*drv=data;//data就是打算把自己匹配到bus上挂接的合适设备上的driver驱动if(dev->parent)down(&dev->parent->sem);//使用信号量保护下面的操作down(&dev->sem);if(!dev->driver)//如果当前这个dev设备还没有挂接一个driver驱动driver_probe_device(drv,dev);//那么尝试该dev是否适合被该drv驱动管理up(&dev->sem);if(dev->parent)up(&dev->parent->sem);return0;}int driver_probe_device(struct device_driver*drv,struct device*dev){int ret=0;if(!device_is_registered(dev))//设备是否已被bus总线认可return-ENODEV;if(drv->bus->match&&!drv->bus->match(dev,drv))//调用该driver驱动自定义的match函数,如:usb_device_match(),查看//这个设备是否符合自己,drv->bus->match()返回1,表示本drv认可该设备//否则,goto done,继续检测下一个device设备是否和本drv匹配goto done;pr_debug("%s:Matched Device%s with Driver%s\n",drv->bus->name,dev->bus_id,drv->name);//这下来真的了,ret=really_probe(dev,drv);done:return ret;}static inline int device_is_registered(struct device*dev){return dev->is_registered;//当调用bus_attach_device()之后,is_registered=1}static int really_probe(struct device*dev,struct device_driver*drv){int ret=0;atomic_inc(&probe_count);pr_debug("%s:Probing driver%s with device%s\n",drv->bus->name,drv->name,dev->bus_id);WARN_ON(!list_empty(&dev->devres_head));dev->driver=drv;//管理本dev的驱动指针指向drvif(driver_sysfs_add(dev)){//将driver和dev使用link,链接到一起,使他们真正相关printk(KERN_ERR"%s:driver_sysfs_add(%s)failed\n",__FUNCTION__,dev->bus_id);goto probe_failed;}if(dev->bus->probe){//总线提供了设备探测函数ret=dev->bus->probe(dev);if(ret)goto probe_failed;}else if(drv->probe){//驱动自己提供了设备探测函数//因为drv驱动自己也不想管理那些意外的非法设备//所以一般drv都会提供这个功能,相反//比如:usb_bus_type没有提供probe,而usb驱动提供了usb_probe_interface//来确认我这个driver软件真的能够管理这个device设备ret=drv->probe(dev);if(ret)goto probe_failed;}driver_bound(dev);ret=1;pr_debug("%s:Bound Device%s to Driver%s\n",drv->bus->name,dev->bus_id,drv->name);goto done;probe_failed:devres_release_all(dev);driver_sysfs_remove(dev);dev->driver=NULL;if(ret!=-ENODEV&&ret!=-ENXIO){printk(KERN_WARNING"%s:probe of%s failed with error%d\n",drv->name,dev->bus_id,ret);}ret=0;done:atomic_dec(&probe_count);wake_up(&probe_waitqueue);return ret;}static void driver_bound(struct device*dev){if(klist_node_attached(&dev->knode_driver)){//本dev已挂到了某个driver驱动的klist_devices链条上了//感觉不应该发生printk(KERN_WARNING"%s:device%s already bound\n",__FUNCTION__,kobject_name(&dev->kobj));return;}pr_debug("bound device’%s’to driver’%s’\n",dev->bus_id,dev->driver->name);if(dev->bus)blocking_notifier_call_chain(&dev->bus->bus_notifier,BUS_NOTIFY_BOUND_DRIVER,dev);//将本dev的knode_driver链表结构体节点挂接到该driver->klist_devices上//这样driver所管理的device设备又多了1个,//也能说又多了1个device设备使用本driver驱动管理他自己(gilethttp_20071025).klist_add_tail(&dev->knode_driver,&dev->driver->klist_devices);}Linux内核中的klist分析分析的内核版本照样是2.6.38.5。

深⼊解读Linux进程调度Schedule【转】调度系统是现代操作系统⾮常核⼼的基础⼦系统之⼀,尤其在多任务并⾏操作系统(Multitasking OS)上,系统可能运⾏于单核或者多核CPU上,进程可能处于运⾏状态或者在内存中可运⾏等待状态。
如何实现多任务同时使⽤资源并且提供给⽤户及时的响应实现实时交互以及提供⾼流量并发等对现代操作系统的设计实现带来了巨⼤挑战,⽽Linux调度⼦系统的设计同样需要实现这些看似⽭盾的要求,适应不同的使⽤场景。
我们看到Linux是⼀个复杂的现在操作系统,各个⼦系统之间相互合作才能完成⾼效的任务。
本⽂从围绕调度⼦系统,介绍了调度⼦系统核⼼的概念,并且将其与Linux各个相关组件的关系进⾏探讨,尤其是与调度⼦系统息息相关的中断(softirq和irq)⼦系统以及定时器Timer,深⼊⽽全⾯地展⽰了调度相关的各个概念以及相互联系。
由于笔者最近在调试PowerPC相关的芯⽚,因此相关的介绍会以此为例提取相关的内核源代码进⾏解读展⽰。
涉及的代码为Linux-4.4稳定发布版本,读者可以查看源码进⾏对照。
1. 相关概念要理解调度⼦系统,⾸先需要总体介绍调度的流程,对系统有⼀个⾼屋建瓴的认识之后,再在整体流程中对各个节点分别深⼊分析,从⽽掌握丰富⽽饱满的细节。
在系统启动早期,会注册硬件中断,时钟中断是硬件中断中⾮常重要的⼀种,调度过程中需要不断地刷新进程的状态以及设置调度标志已决定是否抢占进程的执⾏进⾏调度。
时钟中断就是周期性地完成此项⼯作。
这⾥⼜引出另外⼀个现代OS的调度设计思想即抢占(preempt),⽽与其对应的概念则为⾮抢占或者合作(cooperate),后⾯会给出两者的详细区别。
时钟中断属于硬件中断,Linux系统不⽀持中断嵌套,所以在中断发⽣时⼜会禁⽌本地中断(local_irq_disable),⽽为了尽快相应其他可能的硬件事件,必须要尽快完成处理并开启中断,因此引出了中断下半部,也就是softirq的概念。

Linux内存管理分析与研究随着计算机技术的不断发展,操作系统在计算机系统中扮演着越来越重要的角色。
作为开源操作系统领域的佼佼者,Linux被广泛用于各种应用场景,包括服务器、桌面、嵌入式系统等。
内存管理是操作系统核心功能之一,对于系统性能和稳定性具有重要影响。
本文将对Linux内存管理进行深入分析,并探讨其存在的问题与解决方案。
Linux内存管理采用分页和分段技术,将物理内存划分为大小不同的页框或段框,以便更有效地利用和管理内存资源。
Linux通过将内存分为内核空间和用户空间,实现了内存的隔离和保护,同时允许用户进程使用不同的内存空间。
Linux内存管理存在的一个主要问题是内存分配不均。
由于内存分配是基于页框或段框的,当某些进程需要更多内存时,操作系统会从空闲的内存页框中分配内存。
然而,在实际情况中,由于页框大小固定,当需要分配大量内存时,可能会造成内存分配不均的情况。
另一个问题是浪费空间。
Linux为了提高内存利用率,采用了一种称为内存分页的技术。
然而,在某些情况下,当进程不再需要使用内存时,操作系统并不会立即将内存页框回收,而是保留在内存中以备将来使用,这可能会导致内存空间的浪费。
针对内存分配不均的问题,可以采取交换技术。
交换技术是一种将进程使用的内存部分移至磁盘上,以腾出更多内存供其他进程使用的方法。
在Linux中,可以使用瑞士文件系统(Swiss File System,SFS)作为交换设备,将不常用的内存页框交换到磁盘上,以便在需要时重新加载。
为了解决内存浪费问题,可以优化内存分配算法。
Linux中使用的内存分配算法是基于伙伴系统的,该算法会跟踪每个内存块的空闲状态。
当需要分配内存时,伙伴系统会选择一个适当大小的空闲块,并将其划分为所需的内存大小。
为了避免内存浪费,可以采取以下措施:增加空闲内存块的大小,以便更好地适应大内存需求;引入动态内存分配机制,使操作系统能够在需要时分配和回收内存;定期清理不再使用的内存块,以便及时回收内存空间。

需要了解Linux内核通知链机制的原理及实现一、概念:大多数内核子系统都是相互独立的,因此某个子系统可能对其它子系统产生的事件感兴趣。
为了满足这个需求,也即是让某个子系统在发生某个事件时通知其它的子系统,Linux 内核提供了通知链的机制。
通知链表只能够在内核的子系统之间使用,而不能够在内核与用户空间之间进行事件的通知。
通知链表是一个函数链表,链表上的每一个节点都注册了一个函数。
当某个事情发生时,链表上所有节点对应的函数就会被执行。
所以对于通知链表来说有一个通知方与一个接收方。
在通知这个事件时所运行的函数由被通知方决定,实际上也即是被通知方注册了某个函数,在发生某个事件时这些函数就得到执行。
其实和系统调用signal的思想差不多。
二、数据结构:通知链有四种类型:原子通知链( Atomic notifier chains ):通知链元素的回调函数(当事件发生时要执行的函数)只能在中断上下文中运行,不允许阻塞。
对应的链表头结构:struct atomic_noTIfier_head{ spinlock_t lock; struct noTIfier_block *head;};可阻塞通知链( Blocking noTIfier chains ):通知链元素的回调函数在进程上下文中运行,允许阻塞。
对应的链表头:struct blocking_noTIfier_head{ struct rw_semaphore rwsem; struct notifier_block *head;}; 原始通知链( Raw notifier chains ):对通知链元素的回调函数没有任何限制,所有锁和保护机制都由调用者维护。
对应的链表头:struct raw_notifier_head{ struct notifier_block *head;};SRCU 通知链( SRCU notifier chains ):可阻塞通知链的一种变体。

其中基于sparc64平台的Linux用户空间可以运行32位代码,用户空间指针是32位宽的,但内核空间是64位的。
内核中的地址是unsigned long类型,指针大小和long类型相同。
内核提供下列数据类型。
所有类型在头文件<asm/types.h>中声明,这个文件又被头文件<Linux/types.h>所包含。
下面是include/asm/types.h文件。
#ifndef _I386_TYPES_H#define _I386_TYPES_H#ifndef __ASSEMBLY__typedef unsigned short umode_t;// 下面__xx类型不会损害POSIX 名字空间,在头文件使用它们,可以输出给用户空间typedef __signed__ char __s8;typedef unsigned char __u8;typedef __signed__ short __s16;typedef unsigned short __u16;typedef __signed__ int __s32;typedef unsigned int __u32;#if defined(__GNUC__) && !defined(__STRICT_ANSI__)typedef __signed__ long long __s64;typedef unsigned long long __u64;#endif#endif /* __ASSEMBLY__ *///下面的类型只用在内核中,否则会产生名字空间崩溃#ifdef __KERNEL__#define BITS_PER_LONG 32#ifndef __ASSEMBLY__#include <Linux/config.h>typedef signed char s8;typedef unsigned char u8;typedef signed short s16;typedef unsigned short u16;typedef signed int s32;typedef unsigned int u32;typedef signed long long s64;typedef unsigned long long u64;/* DMA addresses come in generic and 64-bit flavours. */ #ifdef CONFIG_HIGHMEM64Gtypedef u64 dma_addr_t;#elsetypedef u32 dma_addr_t;#endiftypedef u64 dma64_addr_t;#ifdef CONFIG_LBDtypedef u64 sector_t;#define HAVE_SECTOR_T#endiftypedef unsigned short kmem_bufctl_t;#endif /* __ASSEMBLY__ */#endif /* __KERNEL__ */#endif下面是Linux/types.h的部分定义。

Linux内核分析_课程设计计算机科学与⼯程学院课程设计报告题⽬全称:Linux内核初起代码分析学⽣学号:姓名:指导⽼师:职称:指导⽼师评语:签字:课程设计成绩:⽬录摘要 (2)第⼀章引⾔ (1)1.1 问题的提出 (1)1.2任务与分析 (1)第⼆章代码分析 (2)2.1系统初始化过程流程 (2)2.2数据结构 (2)2.3常量和出错信息的意义 (4)2.4调⽤关系图 (4)2.5各模块/函数的功能及详细框图 (5)2.5.1 static void time_init(void)分析 (6)2.5.2 void main(void)分析 (6)2.5.3 pause()分析 (8)2.5.4 static int printf(const char *fmt, ...)分析 (8)2.5.5 void init(void)分析 (9)第三章内核调试 (12)3.1运⾏环境 (12)3.2编译内核过程 (12)第四章总结与体会 (15)致谢 (16)参考⽂献 (17)摘要随着计算机的普及,计算机发挥着越来越重要的作⽤,计算机的使⽤也越来越普遍,所以让更多的⼈能够更好的使⽤和掌握⼀些计算机⽅法显得⼗分重要。
充分发挥计算机的作⽤也显得⼗分重要。
操作系统应运⽽⽣。
操作系统是⼀种软件,⽤来帮助其他的程序控制计算机并和⽤户进⾏交互。
因⽽,对操作系统的研究是很有必要的。
操作系统包含了多个部分或者组件,最核⼼的部分是内核。
其他的部分⽤来帮助内核完成计算机资源的管理和应⽤程序的控制。
Linux操作系统是使⽤很⼴泛的,⾼质量的⼀个操作系统。
此次起始代码分析,我分析了init/main.c⽂件中的main()、init()以及编译内核代码。
main()中主要是关于起始的调⽤和设备和系统信息初始化,以及创建进程。
此时中断仍被禁⽌着,做完必要的设置后就将其开启init()是创建进程,并检测是否出错,出错则再次创建执⾏并打印出出错信息。
Linux实验总结分析报告SA20225405 苏俊杰作业要求:1、请您根据本课程所学内容总结梳理出⼀个精简的Linux系统概念模型,最⼤程度统摄整顿本课程及相关的知识信息,模型应该是逻辑上可以运转的、⾃洽的,并举例某⼀两个具体例⼦(⽐如读写⽂件、分配内存、使⽤I/O驱动某个硬件等)纳⼊模型中验证模型。
2、然后将⼀个应⽤程序放⼊该系统模型中系统性的梳理影响应⽤程序性能表现的因素,并说明原因。
3、产出要求是发表⼀篇博客⽂章,长度不限,1要简略,2是重点,只谈⾃⼰的思考和梳理。
1.精简的Linux系统概念模型Linux操作系统:通俗的操作系统主要是包含软件和硬件两部分统⼀运⾏的,并由操作系统来统⼀管理硬件的软件系统,⽽linux是⼀个基于POSIX的多⽤户、多任务、⽀持多线程和多CPU的操作系统。
Linux系统主要包含4个主要部分:内核、shell、⽂件系统和应⽤程序。
其中内核、shell和⽂件系统⼀起形成了基本的操作系统结构,它们使得⽤户可以运⾏程序、管理⽂件并使⽤系统。
Linux操作系统相对于其他操作系统的特点是万物皆可看做⽂件,⽆论是软件资源还是硬件资源都看做⽂件进⾏操作。
Linux操作系统被抽象为不同的层级和模块,如下图所⽰。
如果让我们把Linux系统再精简些,就是下图所⽰的模样:如图中所⽰,我们可以看到,内核直接与硬件打交道,并给上层应⽤提供系统调⽤,让他们间接的使⽤硬件资源。
shell似乎Linux系统中⽅便⼈机交互的界⾯软件,库函数不属于Linux内核,但是它封装了基本的功能供⼈使⽤,提⾼了编程效率。
2.进程管理进程管理是linux系统的核⼼部分,在Linux内核中⽤⼀个数据结构struct task_struct来描述进程,直接或间接提供了进程相关的所有信息。
struct task_struct的结构包括了进程的状态、进程双向链表的管理,以及控制台tty、⽂件系统fs的描述、进程打开⽂件的⽂件描述符files、内存管理的描述mm,还有进程间通信的信号signal的描述等内容。
物理内存的管理3.5.1 伙伴系统的结构系统中每个物理内存页都对应于一个struct page实例,每个内存域都关联一个struct zone的实例。
order:描述了内存分配的数量单位。
order范围0~MAX_ORDER●第0个链表包含的内存区为单页,第1为2的一次方..........●内存区中第1页内的链表元素,可用于将内存区维持在链表中,所以不必引入新的数据结构来管理,否则这些页不可能在同一内存区。
●主要优点之一:管理工作较少。
●备用列表:连接所有内存域和节点。
●内存分配原则:在首选的内存域或节点无法满足内存分配请求时,首先尝试同一节点的另一个内存域,接下来再尝试另一个节点,直至满足要求。
3.5.2 避免碎片1、依据可移动性组织页上图表示所有的空闲内存和非空闲内存都是连续的,而下面的图不是连续的,空闲内存最大只有一个页。
●内核的方法是反碎片。
不可移动页:在内存中有固定位置,不能移动到其他地方。
可回收页:不能直接移动,但可以删除,其内容可以从某些源重新生成。
可移动页:可以随意移动。
●内核使用反碎片技术,基于将具有相同可移动性的页分组的思●如图所示:●数据结构:内核定义的迁移类型●初始化基于可移动性的分组在内存子系统初始化期间,memmap_init_zone负责处理内存域的page实例,所有页最初都标记为可移动的!分配内存时,如果必须“盗取”不同于预定迁移类型的内存区,内核在策略上倾向于“盗取”更大的内存区。
2、虚拟可移动内存域●虚拟内存域ZONE_MOV ABLE,必须由管理员显式激活。
●基本思想:可用的物理内存分为两个内存域,一个用于可移动分配,一个用于不可移动分配。
●数据结构:Kernelcore指定用于不可移动分配的内存数量;Movablecore控制用于可移动内存分配的内存数量。
●物理内存域提取的用于ZONE_MOV ABLE的内存数量必须考虑下面两种情况:①用于不可移动分配的内存会平均地分布到所有内存结点。
【原创】Linux内核源码分析之进程概要及调度时机❝❞进程概要及调度时机这篇⽂章从 Linux 内核层⾯分析进程概要及调度时机。
0 本⽂内容⼀分钟速览如果读者没有耐⼼看完整篇⽂章,下⾯是本⽂的核⼼内容预览,⼀分钟内能读完。
0.1 进程概要•进程是对物理世界的建模抽象,每个进程对应⼀个 task_struct 数据结构,这个数据结构包含了进程的所有的信息。
•在 Linux 内核中,不会区分线程和进程的概念,线程也是通过进程来实现的,线程和进程的唯⼀区别就是:线程没有独⽴的资源,进程有。
•所有的进程都是通过其他进程创建出来的,因此,整个进程组织为⼀棵进程树。
•0 号进程是⽆中⽣有凭空产⽣的,是静态定义出来的,是所有进程的祖先,创建了 INIT (1号)和 kthreadd (2号进程)。
0.2 进程调度时机•系统调⽤ yield 、 pause 会使得当前进程让出 CPU,随后进⾏⼀次进程调度。
•系统调⽤ futex(wait)等待某个信号量,将进程设置为 TASK_INTERRUPTIBLE 状态,然后进⾏⼀次进程调度。
•进程在退出的时候,会系统调⽤到 exit ⽅法,将当前进程设置为 TASK_DEAD 之后,进⾏⼀次进程调度。
•在创建新进程、唤醒进程、周期调度过程中,内核会给当前进程设置⼀个需要调度的标志,然后在下⼀次中断返回到⽤户空间时,进⾏⼀次调度。
•每颗 CPU 都会绑定⼀个 IDLE 进程,没事就在 CPU 上⽆聊地空转,偶尔进⾏⼀次进程调度。
1 进程概要 1.1 进程是对物理世界的建模抽象⼈们在⾯对⼀个问题束⼿⽆策的时候,经常会创造⼀个概念,然后基于这个概念来演化出⼀个系统来解决这个问题。
进程的概念就是⼈类发明出来,为了解决物理世界想要同时做若⼲件事情的需求,最终演化出了进程⼦系统。
关于进程的基本知识⽹上有很多,这⾥说下我的理解:••加载器将可执⾏程序⽂件(Linux 中是 ELF 格式)加载到操作系统,操作系统中就多了⼀个进程。
深入理解linux内核v4l2框架之videobuf Videobuf下面来介绍以下videobuffer相关的一些东西。
V4L2核心api提供了一套标准的方法来处理视频缓冲,这些方法允许驱动实现read(),mmap(), overlay()等操作。
同样也有方法支持DMA的scatter/gather操作,并且支持vmallocbuffer(这个大多用在USB驱动上)。
videobuf层功能是一种在v4l2驱动和用户空间当中的依附层,这话看起来有点绕,说白了就是提供一种功能框架,用来分配和管理视频缓冲区,它相对独立,却又被v4l2驱动使用。
它有一组功能函数集用来实现许多标准的POSIX系统调用,包括read(),poll()和mmap()等等,还有一组功能函数集用来实现流式(streaming)IO的v4l2_ioctl 调用,包括缓冲区的分配,入队和出队以及数据流控制等操作。
使用videobuf需要驱动程序作者遵从一些强制的设计规则,但带来的好处是代码量的减少和v4l2框架API的一致。
缓冲类型并不是所有的视频设备都使用相同的缓冲类型。
实际上,有三种通用的类型:–被分散在物理和内核虚拟地址空间的缓冲,几乎所有的用户空间缓冲都是这种类型,如果可能的话分配内核空间的缓冲也很有意义,但是不幸的是,这个通常需要那些支持离散聚合DMA操作的硬件设备。
–物理上离散的但是虚拟地址是连续的,换句话说,就是用vmalloc分配的内核缓冲。
这些缓冲很难用于DMA操作。
–物理上连续的缓冲。
videobuf可以很好地处理这三种类型的缓冲,但是在此之前,驱动程序作者必须选择一种类型,并且以此类型为基础设计驱动。
数据结构,回调函数和初始化根据选择的类型,包含不同的头文件,这些头文件在include/media/下面<media/videobuf-dma-sg.h><media/videobuf-vmalloc.h><media/videobuf-dma-contig.h>v4l2驱动需要包含一个videobuf_queue的实例用来管理缓冲队列,同时还要一个链表来维护这个队列,另外还要一个中断安全的spin_lock来保护队列的操作。
linux内核⾥的字符串转换,链表操作常⽤函数(转)1.对双向链表的具体操作如下:1. list_add ———向链表添加⼀个条⽬2. list_add_tail ———添加⼀个条⽬到链表尾部3. __list_del_entry ———从链表中删除相应的条⽬4. list_replace———⽤新条⽬替换旧条⽬5. list_del_init———从链表中删除条⽬后重新初始化6. list_move———从⼀个链表中删除并加⼊为另⼀个链表的头部7. list_move_tail———从⼀个列表中删除并加⼊为另⼀个链表的尾部8. list_is_last———测试是否为链表的最后⼀个条⽬9. list_empty———测试链表是否为空10. list_empty_careful———测试链表是否为空并没有被修改11. list_rotate_left———向左转动链表12. list_is_singular———测试链表是否只有⼀个条⽬13. list_cut_position———将链表⼀分为⼆14. list_splice———将两个链表进⾏合并15. list_splice_tail———将两个链表进⾏合并为⼀个链表16. list_splice_init———将两个链表进⾏合并为⼀个链表并初始化为空表17. list_splice_tail_init———将两个链表进⾏合并为⼀个链表(从尾部合并)并初始化为空表18. list_entry———获取条⽬的结构,实现对container_of 的封装19. list_first_entry———获取链表的第⼀个元素20. list_first_entry_or_null———获取链表的第⼀个元素21. list_for_each———遍历链表22. list_for_each_prev———反向遍历链表23. list_for_each_safe———遍历链表并删除链表中相应的条⽬24. list_for_each_prev_safe———反向遍历链表并删除链表中相应的条⽬25. list_for_each_entry———遍历指定类型的链表26. list_for_each_entry_reverse———反向遍历指定类型的链表27. list_prepare_entry———准备⼀个⽤于list_for_each_entry_continue 的条⽬28. list_for_each_entry_continue———从指定点开始继续遍历指定类型的链表29. list_for_each_entry_continue_reverse———从指定点开始反向遍历链表30. list_for_each_entry_from———从当前点遍历指定类型的链表31. list_for_each_entry_safe———反向遍历指定类型的链表并删除链表中相应的条⽬32. list_for_each_entry_safe_continue———继续遍历链表并删除链表中相应的条⽬33. list_for_each_entry_safe_from———从当前点遍历链表并删除链表中相应的条⽬34. list_for_each_entry_safe_reverse———反向遍历链表并删除链表中相应的条⽬35. list_safe_reset_next———获得下⼀个指定类型的条⽬36. hlist_for_each_entry———遍历指定类型的单指针表头链表37. hlist_for_each_entry_continue———从当前点继续遍历单指针表头链表38. hlist_for_each_entry_from———从当前点继续遍历单指针表头链表39. hlist_for_each_entry_safe———遍历指定类型的单指针表头链表并删除链表中相应的条⽬2.字符串相关内核中经常会有字符串转换的需要, 其接⼝如下:1. simple_strtoull———变换⼀个字符串为⽆符号的long long 型2. simple_strtoul———变换⼀个字符串为⽆符号的long 型3. simple_strtol———变换⼀个字符串为有符号的long 型4. simple_strtoll———变换⼀个字符串为有符号的long long 型5. vsnprintf———格式化⼀个字符串并放⼊缓冲区6. vscnprintf———格式化⼀个字符串并放⼊缓冲区7. snprintf———格式化⼀个字符串并放⼊缓冲区8. scnprintf———格式化⼀个字符串并放⼊缓冲区9. vsprintf———格式化⼀个字符串并放⼊缓冲区10. sprintf———格式化⼀个字符串并放⼊缓冲区11. vbin_printf———解析格式化字符串并将⼆进制值放⼊缓冲区12. bstr_printf———对⼆进制参数进⾏格式化字符串操作并放⼊缓冲区13. bprintf———解析格式化字符串并将⼆进制值放⼊缓冲区14. vsscanf———从格式化字符串中分离出的参数列表15. sscanf———从格式化字符串中分离出的参数列表16. kstrtol———变换⼀个字符串为long 型17. kstrtoul———变换⼀个字符串为⽆符号的long 型18. kstrtoull———变换⼀个字符串为⽆符号的long long 型19. kstrtoll———变换⼀个字符串为long long 型20. kstrtouint———变换⼀个字符串为⽆符号的int 型21. kstrtoint———变换⼀个字符串为int 型⽰例:char buf[]="115200";unsigned int rate;kstrtouint(buf,0,&rate);//buf:输⼊字符串,0:⾃动识别,也可以是10(10进制)或16(16进制),rate:存放转换后的整形值. //当没有错误时返回值是0;3.另外字符串本⾝的操作接⼝如下:1. strnicmp———长度有限的字符串⽐较,这⾥不分⼤⼩写2. strcpy———复制⼀个以NULL 结尾的字符串3. strncpy———复制⼀个以NULL 结尾的有限长度字符串4. strlcpy———复制⼀个以NULL 结尾的有限长度字符串到缓冲区中5. strcat———在字符串后附加以NULL 结尾的字符串6. strncat———在字符串后附加以NULL 结尾的⼀定长度的字符串7. strlcat———在字符串后附加以NULL 结尾的⼀定长度的字符串8. strcmp———⽐较两个字符串9. strncmp———⽐较两个限定长度的字符串10. strchr———在字符串中查找第⼀个出现指定字符的位置11. strrchr———在字符串中查找最后出现指定字符的位置12. strnchr———在字符串中查找出现指定字符串的位置13. skip_spaces———从字符串中移除前置空格14. strim———从字符串中移除前置及后置的空格15. strlen———获得字符串的长度16. strnlen———获得⼀个有限长度字符串的长度17. strspn———计算⼀个仅包含可接受字母集合的字符串的长度18. strcspn———计算⼀个不包含指定字母集合的字符串的长度19. strpbrk———找到字符集合在字符串第⼀次出现的位置20. strsep———分割字符串21. sysfs_streq———字符串⽐较,⽤于sysfs22. strtobool———⽤户输⼊转换成布尔值23. memset———内存填充24. memcpy———内存复制25. memmove———内存复制26. memcmp———内存⽐较27. memscan———在内存中找指定的字符28. strstr———在⼀个以NULL 结尾的字符串中找到第⼀个⼦串29. strnstr———在⼀个限定长度字符串中找到第⼀个⼦串30. memchr———找到内存中的字符31. memchr_inv———找到内存中的不匹配字符。