word VBA文档词频统计代码
- 格式:doc
- 大小:34.50 KB
- 文档页数:3

完整的中英⽂词频统计步骤:1.准备utf-8编码的⽂本⽂件file2.通过⽂件读取字符串 str3.对⽂本进⾏预处理4.分解提取单词 list5.单词计数字典 set , dict6.按词频排序 list.sort(key=)7.排除语法型词汇,代词、冠词、连词等⽆语义词8.输出TOP(20)⼀、.英⽂歌曲词频统计str2='''I will run, I will climb, I will soarI'm undefeatedJumpiing out of my skin, pull the chordYeah I believe itThe past, is everything we weredon't make us who we areSo I'll dream, until I make it real,and all I see is starsIts not until you fall that you flyWhen your dreams come alive you're unstoppableTake a shot, chase the sun, find the beautifulWe will glow in the dark turning dust to goldAnd we'll dream it possiblepossibleAnd we'll dream it possibleI will chase, I will reach, I will flyUntil I'm breaking, until I'm breakingOut of my cage, like a bird in the nightI know I'm changing, I know I'm changingIn, into something big, better than beforeAnd if it takes, takes a thousand livesThen it's worth fighting forIts not until you fall that you flyWhen your dreams come alive you're unstoppableTake a shot, chase the sun, find the beautifulWe will glow in the dark turning dust to goldAnd we'll dream it possibleit possibleFrom the bottom to the topWe're sparking wild fire'sNever quit and never stopThe rest of our livesFrom the bottom to the topWe're sparking wild fire'sNever quit and never stopIts not until you fall that you flyWhen your dreams come alive you're unstoppableTake a shot, chase the sun, find the beautifulWe will glow in the dark turning dust to goldAnd we'll dream it possiblepossibleAnd we'll dream it possible'''.lower()#aa = '''."?!'''#for word in aa:# str2 =str2.replace('word','')str2 =str2.replace('\n',' ')str2 =str2.replace(',',' ')print(str2)#去除特殊符号str2 = str2.strip()#去掉⾸尾空格str2 = str2.split()#通过指定分隔符对字符串进⾏切⽚print(str2)print('统计每个单词出现的次数为:')for word in str2:print(word,str2.count(word))strSet=set(str2)newSet={'a','will','it','out','of','my','the','i','in','to','when','and'}strSet1=strSet-newSet#去除介词和其他print(strSet1)strdict={} #单词计数字典for word in strSet1:strdict[word] = str2.count(word)print(len(strdict),strdict)strList = list(strdict.items())def takesecond(elem):#定义函数return elem[1]#strList.sort(key=lambda x:x[1],reverse=True)#匿名函数strList.sort(key=takesecond,reverse=True)#按照数值⼤⼩进⾏排序print(strList)for i in range(20):print (strList[i])#前⼆⼗2.中⽂⼩说词频统计import jieba;#准备utf-8编码的⽂本⽂件filef = open('doupo.txt','r',encoding='utf-8')#通过⽂件读取字符串 str,对⽂本进⾏预处理fo=f.read()f.close()print(fo)#⽤字典形式统计每个词的字数doupols = jieba.lcut(fo)doupodict = {}for word in doupols:if len(word)==1:continueelse:doupodict[word]=doupodict.get(word,0)+1print(doupodict)#cutprint(list(jieba.cut(fo))) #精确模式,将句⼦最精确的分开,适合⽂本分析print(list(jieba.cut(fo,cut_all=True))) #全模式,把句⼦中所有的可以成词的词语都扫描出来print(list(jieba.cut_for_search(fo))) #搜索引擎模式,在精确模式的基础上,对长词再次切分,提⾼召回率,适合⽤于搜索引擎分词#以列表返回可遍历的(键, 值) 元组数组wcList = list(doupodict.items())wcList.sort(key = lambda x:x[1],reverse=True) #出现词汇次数由⾼到低排序print(wcList)#第⼀个词循环遍历输出5次for i in range(5):print(wcList[1])。

统计word文档基础信息文/青爷用word vba可以很方便地统计一篇word文档的基础信息,包括一篇文档的节数、域代码数量、表格数、书签数、浮动式图片(Shape)数、嵌入式图片(inlineshape)数等等。
这样一目了然,可以迅速形成对文章结构的总体认知。
一般来说,一篇文档包含的节、域代码、表格等数量越多,文档结构越复杂,对其后期的修改排版也随之复杂。
================================================Sub d()Rem 统计word文档基础信息Rem 以下均不考虑页眉页脚i1 = ActiveDocument.Shapes.Counti2 = ActiveDocument.InlineShapes.Counti3 = ActiveDocument.Sections.Counti4 = ActiveDocument.Tables.Counti5 = ActiveDocument.Bookmarks.Counti6 = ActiveDocument.Fields.Counti7 = ActiveDocument.Frames.Counti8 = ActiveDocument.Footnotes.Counti10 = ActiveDocument.OMaths.Counti13 = rmation(wdNumberOfPagesInDocument) '页数i14 = ActiveDocument.Endnotes.Counti15 = puteStatistics(wdStatisticWords) '字数For Each oField In ActiveDocument.FieldsIf oField.Code.Text Like "*Equation*" Or oField.Code.Text Like "*EQUATION*" Then 'Mathtype公式数量iflag = iflag + 1End IfNextIf iflag = 0 Then i9 = 0 Else i9 = iflagFor Each oField In ActiveDocument.FieldsIf oField.Code.Text Like "*TOC*" Then '目录lflag = lflag + 1End IfNextIf lflag = 0 Then i16 = 0 Else i16 = lflagFor i = ActiveDocument.Shapes.Count To 1 Step -1If ActiveDocument.Shapes(i).Type = msoTextBox Then '文本框数量jflag = jflag + 1End IfNextIf jflag = 0 Then i11 = 0 Else i11 = jflagFor Each oField In ActiveDocument.Fields'Debug.Print oField.TypeIf oField.Type = wdFieldPageRef Or oField.Type = wdFieldTOC Or oField.Code.Text Like "*Toc*" Then '目录域数量k = k + 1End IfNextRem 统计所有表格的嵌套表格个数(只统计第一层嵌套表格,针对该word文档统计全局嵌套表格总数)For Each Tbl In ActiveDocument.Tableskflag = kflag + Tbl.Tables.CountNextIf kflag = 0 Then i12 = 0 Else i12 = kflagMsgBox "本文共" & i3 & "节!本文共" & i13 & "页!" & "平均每页" & Round(i15 / i13, 0) & "个字!" & Chr(13) & Chr(13) & "本文共" & i6 - k & "个非目录域(其中" & i9 & "个Mathtype公式," & i6 - k - i9 & "个其他域)!" _& Chr(13) & Chr(13) & "本文共" & i16 & "个目录!" & Chr(13) & Chr(13) & "本文共" & i10 & "个自带公式!" _& Chr(13) & Chr(13) & "本文共" & i4 & "个表格(其中" & i12 & "个嵌套表格)!" & Chr(13) & Chr(13) & "本文共" & i5 & "个书签!" _& Chr(13) & Chr(13) & "本文共" & i8 & "个脚注!本文共" & i14 & "个尾注!" & Chr(13) & Chr(13) & "本文共" & i2 - i9 & "个InlineShape(不含Mathtype公式)!" & Chr(13) & Chr(13) _& "本文共" & i1 & "个Shape(其中" & i11 & "个文本框)!" & "本文共" & i7 & "个图文框!"End Sub。

如何在Word中统计相同字符(文字)出现的个数首先,在Word窗口中,执行操作:“工具”→“宏”→“宏”,弹出如下图的对话框!上图中,在输入框中输入宏的名称,如“查找相同字符个数”,之后点击“创建”按钮;弹出如下图的“Microsoft Visual Basic”窗口,并且会自动产生一个录入代码的过程名称!在上图代码输入小窗口中,录入如下图的代码即可!以上的代码输入了之后,就在“Microsoft Visual Basic”窗口中执行如下图的操作!上述操作完成就会自动返回到Word窗口!之后,在Word窗口中执行操作:“工具”→“自定义”,弹出如下图的窗口!上图中,首先选择“命令”页框,之后在“类别”里面找到“宏”,之后在右边的“命令”里面找到如上图的宏名称,即刚才我们所编写的那代码的宏名,“查找相同字符个数”;之后,如下图一样,用鼠标左键拖动的办法,将这个宏拖入“编辑”菜单中,这个时候,这个宏的名称就和菜单中的命令一样,显示在该菜单里面了!上图中,拖入菜单之后,只要选择宏的名称,点击右键,就可以修改名称了,为方便使用,建议修改为“查找相同字符个数”,如下图!如何使用这宏名呢,这操作就太简单了,如上图一样执行操作,就会弹出一个对话框,如下图!输入要查找的字符,如“计算机”,之后点击确定按钮,则会弹出如下图的对话框,提示您找到多少个了!这个宏的功能非常实用,尽管操作过程有点儿麻烦,貌似有点罗嗦,但是您做好一次之后,以后就会在“编辑”菜单中显示了,以后直接点击就能使用了!如何在excell中统计相同字符(文字)出现的个数用COUNTIF(range,criteria),例如=countif(A1:A100,"天天")[文档可能无法思考全面,请浏览后下载,另外祝您生活愉快,工作顺利,万事如意!]。

计算输入文本中词语数量的程序
编写一个程序来计算输入文本中词语的数量是一个相对简单的
任务。
你可以使用任何你喜欢的编程语言来实现这个程序,比如Python、Java、C++等。
下面我以Python为例,给出一个简单的实现:
python.
def count_words(text):
words = text.split() # 通过空格分割文本得到单词列表。
return len(words) # 返回单词列表的长度即为单词数量。
input_text = input("请输入文本,")。
word_count = count_words(input_text)。
print("输入文本中包含的单词数量为,", word_count)。
这个程序首先定义了一个函数`count_words`,该函数接受一个
文本参数,然后通过空格分割文本得到单词列表,最后返回单词列
表的长度即为单词数量。
然后通过`input`函数获取用户输入的文本,调用`count_words`函数计算单词数量,并打印输出结果。
当然,这只是一个简单的实现,实际中可能需要考虑更多的情况,比如标点符号的处理、特殊字符的处理等。
但是基本的思路就
是将文本按照空格分割成单词,然后统计单词的数量。
希望这个示
例对你有所帮助。

Dim fp As String = TextBox1.TextDim fl() As String = Directory.GetFiles(fp, "*.docx", SearchOption.AllDirec tories)Dim dt As New DataTabledt.Columns.Add("路径")dt.Columns.Add("文件名")'dt.Columns.Add()dt.Columns.Add("字符数_不记空格_注释")dt.Columns.Add("字符数_不记空格")dt.Columns.Add("字符数_记空格_注释")dt.Columns.Add("字符数_记空格")dt.Columns.Add("字数_注释")dt.Columns.Add("字数")probar.Maximum = fl.Lengthprobar.Value = 0For Each fn As String In flDim fnl() As String = tools1.getfileinfo(fn)Dim wdApp As Microsoft.Office.Interop.Word.ApplicationwdApp = CreateObject("Word.Application")Dim c1, c2, c3, c4, c5, c6 As StringTry'wdApp.ActiveDocument.BuiltInDocumentProperties(Index)Dim doc As Microsoft.Office.Interop.Word.Documentdoc = wdApp.Documents.Open(fn)' doc.BuiltInDocumentProperties(Index) 这样也可以'Dim prop As Microsoft.Office.Interop.Word.WdBuiltInProperty'prop = doc.BuiltInDocumentProperties'Dim doc As New Aspose.Words.Document(fn)'Dim prop As Aspose.Words.Properties.BuiltInDocumentPropertiesDim stat As Microsoft.Office.Interop.Word.WdStatisticstat = Microsoft.Office.Interop.Word.WdStatistic.wdStatisticCharact ers'c1 = puteStatistics(Microsoft.Office.Interop.Word.WdStatist ic.wdStatisticCharacters, True)'c2 = puteStatistics(Microsoft.Office.Interop.Word.WdStatist ic.wdStatisticCharacters, False)c3 = puteStatistics(Microsoft.Office.Interop.Word.WdStatisti c.wdStatisticCharactersWithSpaces, True)c4 = puteStatistics(Microsoft.Office.Interop.Word.WdStatisti c.wdStatisticCharactersWithSpaces, False)c5 = puteStatistics(Microsoft.Office.Interop.Word.WdStatisti c.wdStatisticWords, True)c6 = puteStatistics(Microsoft.Office.Interop.Word.WdStatisti c.wdStatisticWords, False)doc.Close()wdApp.Quit()wdApp = NothingCatch ex As Exception'MsgBox(fn & ex.Message)wdApp.Quit()wdApp = NothingEnd Try'wdApp.Quit()'wdApp = NothingDim dr As DataRow = dt.NewRowdr(0) = fnl(0)dr(1) = fnl(1)dr(2) = c1dr(3) = c2dr(4) = c3dr(5) = c4dr(6) = c5dr(7) = c6dt.Rows.Add(dr)tsCount1.Text = fnprobar.PerformStep()Application.DoEvents()Nextdgv1.DataSource = dt。

词频统计的主要流程引言词频统计是一种非常常见且实用的文本分析方法,它可以揭示文本中词语的使用情况和重要性。
在文本挖掘、自然语言处理、信息检索等领域中,词频统计被广泛应用于文本预处理、特征提取和文本分类等任务中。
本文将介绍词频统计的主要流程,包括数据预处理、构建词汇表、计算词频和排序等关键步骤。
我们将逐步深入探讨这些步骤,并给出详细的示例代码,以帮助读者更好地理解词频统计的过程和方法。
数据预处理在进行词频统计之前,需要对原始文本进行预处理,以便去除无用的标点符号、停用词等干扰因素,并将文本转换为合适的形式进行处理。
数据预处理的具体步骤如下: 1. 将文本转换为小写字母,以避免大小写的差异对统计结果造成影响。
2. 去除标点符号,包括句号、逗号、双引号等。
3. 去除停用词,停用词是指在文本分析中无实际含义的高频词汇,如“的”、“了”、“是”等。
常用的停用词列表可以从开源项目或自然语言处理工具包中获取。
4. 进行词干提取,将词语的不同形式转换为其原始形式。
例如,将单词的复数形式、时态变化等转换为词干形式。
5. 分词,将文本按照词语为单位进行切分。
常用的中文分词工具包有jieba、snownlp等。
下面给出一个示例代码,展示如何对原始文本进行数据预处理:import reimport stringfrom nltk.corpus import stopwordsfrom nltk.stem import SnowballStemmerimport jiebadef preprocess_text(text):# 将文本转换为小写text = text.lower()# 去除标点符号text = text.translate(str.maketrans('', '', string.punctuation)) # 去除停用词stop_words = set(stopwords.words('english')) # 英文停用词text = ' '.join([word for word in text.split() if word not in stop_words]) # 进行词干提取stemmer = SnowballStemmer('english')text = ' '.join([stemmer.stem(word) for word in text.split()]) # 中文分词text = ' '.join(jieba.cut(text))return text# 示例文本text = "Hello, world! This is a sample text."preprocessed_text = preprocess_text(text)print(preprocessed_text)以上代码演示了如何对英文文本进行预处理。

VBA 统计Word 字数、页数方法探讨我们在日常工作若需要文档的字数和页数,或是VBA编程处理文档时需要用的文档的字数或页数作参数。
那么如何获得一个文档的字数和页数,VBA有多种方法获得文档的字数和页数,那么具体如何获得字数和页数?获的数字到底代表了什么意义?与我们平时理解除的文档字数和页数有什么异同?相信你看完本文后,应该就明白了。
1. 使用Document.BuiltInDocumentProperties方法统计字数1.1第一种方法的实例1及结论我们先来看一个例子:如要统计一篇活动word文档的字数,可以在VBE代码窗口中输入以下代码:Public Sub getword()'显示当前文档的字数MsgBox "当前文档的的总字数为:" & ActiveDocument.BuiltInDocument Properties(wdPropertyWords)End Sub1、在代码窗口中输入上述代码,如图1-1所示。
运行按钮图1-12、点运行按钮,运行结果如下图1-2所示。
3、对此统计的数字我进行了多次测试,特作如下说明:(1)这里统计的字数是指汉字的字数+标点符号+加英文的单词数,英文的单词不区分大小写和正角性,只要有空格分开的就算两个字,如:Seeto、see,to、s ee.to、wdStatisticCharacters都是算一个字,但See to就是两个字,而see,to则算3个字。
图1-2程序运行结果(2)空格再多都不算作字,如“黄山村夫”和“黄 山 村 夫”都是算4个字。
(3)中文的引号只有配对后才能算一个字,否则不算。
(4)西文的标点符号与西文相连时不算字,但与中文相连时就算一个字,如:A,或a.都是算一个字,而“我,”或“我.”都是算2个字。
1.2 第一种方法的实例2及结论我们来看实例2,利用VBA 的ActiveDocument 对象的BuiltInDocumentPrope rties ,统计一篇活动word 文档的总页数,可以在VBE 代码窗口中输入以下代码:Public Sub getpagenumbers()'显示当前文档的页数MsgBox "当前文档的总页数为:" & ActiveDocument.BuiltInDocumentPro perties(wdPropertyPages)End Sub1、在代码窗口中输入上述代码,如图1-3所示。

VBA 统计Word 字数、页数等信息方法一. 使用Document.BuiltInDocumentProperties 方法统计适用于Document对象和Template 对象。
返回一个DocumentProperties 集合,该集合代表了指定文档的所有内置的文档属性。
可使用的参数有:wdPropertyAppName 应用程序名.wdPropertyAuthor 作者.wdPropertyBytes 字节数.wdPropertyCategory 类别.wdPropertyCharacters 字符数.wdPropertyCharsWSpaces 字符数(计空格).wdPropertyComments 批注.wdPropertyCompany 公司.wdPropertyKeywords 关键词.wdPropertyLastAuthor 上一个作者.wdPropertyLines 行数.wdPropertyManager 经理.wdPropertyNotes 注释.wdPropertyPages 页数.wdPropertyParas 段数.wdPropertyRevision 修订次数.wdPropertySecurity 安全性.wdPropertySubject 主题.wdPropertyTemplate 模板.wdPropertyTimeCreated 创建时间.wdPropertyTimeLastPrinted 上次打印时间.wdPropertyTimeLastSaved 上次保存时间.wdPropertyTitle 标题.wdPropertyVBATotalEdit 编辑时间总计.wdPropertyWords 字数.如要统计一篇活动word文档的字数:ActiveDocument.BuiltInDocumentProp erties(wdPropert yWords)方法二.使用puteStatistics方法统计可使用的参数如下:wdStatisticCharacters 字符数.wdStatisticCharactersWithSpaces 字符数(计空格).wdStatisticFarEastCharacters 中文字符和朝鲜文.wdStatisticLines 行数.wdStatisticPages 页数.wdStatisticParagraphs 段数.wdStatisticWords 字数.使用如下:统计活动文档的字数(包括脚注):1.应用于Document 对象的ComputeStatistics 方法。

对英⽂⽂档中的单词与词组进⾏频率统计⼀、程序分析1、以只读模式读取⽂件到字符串def process_file(path):try:with open(path, 'r') as file:text = file.read()except IOError:print("Read File Error!")return Nonereturn text2、对字符串进⾏数据清洗,返回⼀个字典import reword_list = re.sub('[^a-zA-Z0-9n]', '', textString).lower().split()使⽤正则表达式过滤掉⽂档中的特殊字符,把它们全部替换为空格,⽅便后续的分隔操作。
(忽略⼤⼩写,所以全部使⽤⼩写字母) 2.1、只考虑单词频率统计for word in word_list:if word in word_freq:word_freq[word] += 1else:word_freq[word] = 1 判断单词列表中的单词是否在单词频率字典中。
如果这个单词在字典中,则该单词的个数加1; 如果这个单词不在字典中,则以这个单词为键,赋值为1,表⽰这个单词第⼀次出现。
2.2、考虑单词和词组的频率 2.2.1、数据结构 词组是由单词连接构成的,⼀个单词既可以与前⾯的单词构成词组,也可以与后⾯的单词构成词组。
同时,⼀个单词可能在⽂章中多次出现,并且和前后的单词构成多种不同的词组。
这也就表⽰⼏乎每⼀个单词可以⼀前⼀后发散出去,这与图状结构颇为类似。
(适⽤于两个单词构成的词组) 选择图状结构与当前的问题颇为契合。
但是,⽬前python没有⼀种已知的图类来供我们操作。
(⾃定义类暂不作考虑) 于是我想到了树状结构(两个以上单词构成的词组也适⽤),砍去了单词向前的发散,只保留向后的。
⾄此,问题就变成了构建森林。

【初中化学】如何避免非智力因素引起的失分同学们每次小考之后,都有部分同学因非智力因素失分而懊丧、遗憾。
只有尽量避免非智力因素引起的失分,做到防患于未然,才能在高中入学考试中取得高分。
下面笔者就同学们在平时小考中因非智力因素引起的失分原因谈谈几点看法,以便帮助同学们加以避免。
一、字迹潦草,拼写错误同学们在解答填空题、简答题、实验题时,常使用错别字,造成表达意思错误或无法表达意思而丢分。
例如:将“水槽”写成“水糟”,“长颈漏斗”写成“长劲漏斗”或“长径漏斗”或“长颈露斗”,“元素”写成“原素”,“原子”写成“元子”,“置换反应”写成“置换反映”或“质换反应”等等。
产生这些错误的原因是看书不仔细,对字词的书写不细心。
有些同学平时不注意书写工整,养成潦草的习惯,从而使阅卷老师对考生所答内容分辨不清,作为错误处理而失分。
这就要求同学们在平时练习时,一定要养成书写工整、清楚的好习惯,避免再次产生遗憾。
二、粗心、心态有些同学在考试中粗心大意,不仔细审题,或受思维定势的影响,导致出错丢分。
例如,有的选择题要求考生选错误的选项,而部分同学粗心大意,受思维定势的影响(平时练习时多数选择题要求选正确结果),错选了正确的结论而失分。
再如,推断题中,要求同学们写物质的名称时,却写成了元素符号或化学式;要求写化学式时,却写了物质的名称。
可见认真审题,是正确解题的前提和基础。
三、回答不标准或表达混乱1、很多同学答题不规范,包括:(1)书写不规范。
如填选择题答案时,把“d”写成“o”;将?写成?等;(2)计算题解题步骤不完整,如没有解设过程或解后没有简要的写出答等。
2.表达混乱。
当一些学生回答论文时,虽然意思是正确的,但表达不准确。
最常见的问题是混淆实验现象和实验结论。
例如,在回答氧化铜氢还原的实验现象时,错误地描述为“黑色粉末逐渐变成红色金属铜”;针对镁燃烧现象,错误的描述是“白烟和白色固体氧化镁”。
再有,有的同学解答计算题时,虽然结果正确,但书写化学方程式时遗漏反应条件或计算出的结果没有带单位或单位不统一;还有的同学答题没有次序,版面设计不合理,计算过程混乱等,虽然求出了正确结果,但也不能得全分。
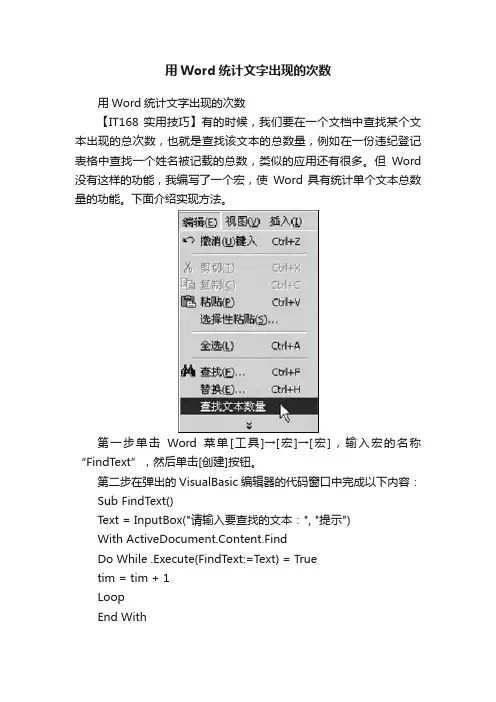
用Word统计文字出现的次数用Word统计文字出现的次数【IT168 实用技巧】有的时候,我们要在一个文档中查找某个文本出现的总次数,也就是查找该文本的总数量,例如在一份违纪登记表格中查找一个姓名被记载的总数,类似的应用还有很多。
但Word 没有这样的功能,我编写了一个宏,使Word 具有统计单个文本总数量的功能。
下面介绍实现方法。
第一步单击Word菜单[工具]→[宏]→[宏],输入宏的名称“FindText”,然后单击[创建]按钮。
第二步在弹出的VisualBasic编辑器的代码窗口中完成以下内容:Sub FindText()Text = InputBox("请输入要查找的文本:", "提示")With ActiveDocument.Content.FindDo While .Execute(FindText:=Text) = Truetim = tim + 1LoopEnd WithMsgBox ("当前文档查找到 " + Str(tim) + " 个 " + Text), 48, "完成"End Sub第三步录入完毕后,单击菜单[文件]→[关闭并返回到Micrcsoft后Word]。
第四步单击菜单[工具]→[自定义],单击“命令”选项卡,在“类别”中选择“宏”,将右边的“Normal.NewMacros.FindText”命令拖入“编辑”菜单中,并右击拖入的命令,在“命名”框中重命名为“查找文本数量”(如图)。
以后要统计文本数量时,只要单击[编辑]→[查找文本数量],按提示输入要查找的内容,单击[确定]就得到统计结果。
编写一个算法frequency,统计在一个输入字符串中各个不同字符出现的频度。
#include <stdio.h>#define MAX 100void detect(char s[]){char ch[MAX];/*记录出现的字符*/int num[MAX]={0};/*记录每个字符出现的次数*/int i,j,n=0;for(i=0;s[i]!='\0';i++){for(j=0;j<n;j++)if(s[i]==ch[j]||(ch[j]>='a'&&ch[j]<='z'&&s[i]+32==ch[j])) break;/*判断该字符是否已经出现过*/if(j<n)/*该字符出现过,对应的记数器num[j]加一*/num[j]++;else/*该字符是新出现的字符,记录到ch[j]中,对应计数器num[j]加一*/ {if(s[i]>='A'&&s[i]<='Z')ch[j]=s[i]+32;elsech[j]=s[i];num[j]++;n++;/*出现的字符的种类数加1*/}}for(i=0;i<n;i++)/*输出*/printf("\'%c\'出现了%d次\n",ch[i],num[i]);}main(){int i=0;char s[MAX];printf("请输入一个字符串:");while((s[i]=getchar())!='\n')/*输入*/i++;s[i]='\0';detect(s);}最新文件---------------- 仅供参考--------------------已改成-----------word文本--------------------- 方便更改赠人玫瑰,手留余香。
Sub 词频统计()'' 词频统计Macro'Dim SingleWord As String '从当前文档提取的一个单词Const maxWords = 15000 '允许出现的不同单词的最大数量,如不够,可适当加大Dim Words(maxWords) As String '用来保存各个不同的单词Dim Freq(maxWords) As Integer '出现频度计数器Dim WordNum As Integer '不同单词的数量Dim ByFreq As Boolean '输出结果的排序标准Dim ttlwds As Long '文档中的单词总数Dim Excludes As String '不在统计范围内的单词Dim Found As Boolean '临时标记Dim j, k, l, Temp As Integer '临时变量Dim tWord As String '' 设置要排除的单词。
' 英文排除词:[the][a][of][is][to][for][this][that][by][be][and][are]' 排除词可以从各大搜索引擎的说明获得,可根据实际情况修改Excludes = "[][的][是]"' 向用户询问排序标准ByFreq = Trueans = InputBox$("根据单词(1)还是频度(2)排序?", "排序标准", "1")If ans = "" Then EndIf Trim(ans) = "1" ThenByFreq = FalseEnd If'开始分析文档Selection.HomeKey Unit:=wdStorySystem.Cursor = wdCursorWaitWordNum = 0ttlwds = ActiveDocument.Words.Count' 处理文档中的每个单词For Each aWord In ActiveDocument.Words'英文单词不区分大小写SingleWord = Trim(LCase(aWord))'该单词是否在排除列表中?If InStr(Excludes, "[" & SingleWord & "]") Then SingleWord = ""If Len(SingleWord) > 0 Then'找到一个需要处理的单词Found = FalseFor j = 1 To WordNumIf Words(j) = SingleWord Then' 这个单词已经出现过了' 把它的出现频度加1Freq(j) = Freq(j) + 1Found = TrueExit ForEnd IfNext jIf Not Found Then' 这个单词还没有出现过' 将它登记为一个新的单词' 出现频度设置为1WordNum = WordNum + 1Words(WordNum) = SingleWordFreq(WordNum) = 1End IfIf WordNum > maxWords - 1 Thenj = MsgBox("已达到单词数量的最大限制值。
Word文件快速统计词语个数方法大全
Word文件快速统计词语个数方法大全
Word文件中经常需要使用到统计“一段文字符号”的个数,“一段文字符号”由字和符号连接而成,比如“我、good",在存贮专业中称为词,或者称为广义词。
这种词是由字符连接而成,比如“我、good"。
下面给出Word文件中统计“一段文字符号”个数的方法,有的方法非常简单。
例如表格文件中统计“我、good"的个数, 方法一:
1.打开要统计词的Word文件;
2、点击查找,
3、在查找内容栏中输入“我、good",
4、点击“突出显示查找内容(R)”,屏幕上就出现查找“我、good"的个数。
它就是要统计“我、good"的个数,
此法非常容易操作。
查找是经常用到的功能。
方法二:
1.打开要统计词的Word文件;;
2、点击查找替换(点编辑->查找替换),
3、在查找内容栏中输入“我、good",在替换为栏中也打入“我、good"。
4、点击“全部替换”,屏幕上就出现替换的个数。
它就是要统计“我、good"的个数,
此法非常容易操作。
替换是经常用到的功能。
方法三:
1.打开要统计词的Word文件;;
2、同时按Ctrl+H,
3、在查找内容栏中输入“我、good",在替换为栏中也打入“我、good"。
4、点击“全部替换”,屏幕上就出现替换的个数。
它就是要统计“我、good"的个数,
方法三是方法的命令操作,本质上一样。
统计单词,字母出现的次数和频率⼀、统计所给出⽂件中英⽂字母出现的频率(区分⼤⼩写),并且按着出现频率倒序输出思路:将⽂件⽤BufferedReader读取对每⾏进⾏读取在进⾏分割成单词对单词进⾏循环判断是否在A-Z,a-z之间,若在存储到数组⾥计数最终进⾏排序package com.wenjian;import java.util.Scanner;import java.util.HashMap;import java.util.Iterator;import java.util.Set;import java.io.*;public class hali {public static <type> void main (String[] args) throws IOException {File file=new File("E:\\Harry Potter and the Sorcerer's Stone.txt"); //��ȡ�ļ�if(!file.exists()){System.out.println("⽂件打不开");return;}Scanner scanner=new Scanner(file);BufferedReader buf = new BufferedReader(new FileReader(file));int []num=new int[100];//计数数组char []zimu=new char[100];//字母表数组char a='A';char b='a';for(int i=1;i<=52;i++){if(i<=26)zimu[i]=a++;elsezimu[i]=b++;}//计数String s=buf.readLine();while(s!=null) {String[] lineWords=s.split(" ");for(int i=0;i<lineWords.length;i++) {for(int j=0;j<lineWords[i].length();j++){if(lineWords[i].charAt(j)>='A'&&lineWords[i].charAt(j)<='Z')num[lineWords[i].charAt(j)-'A'+1]++;else if(lineWords[i].charAt(j)>='a'&&lineWords[i].charAt(j)<='z')num[lineWords[i].charAt(j)-'a'+1+24]++;}}s=buf.readLine();}//求总次数int sum=0;for(int i=1;i<=52;i++){sum+=num[i];}//排序for(int i=1;i<=52;i++){for(int j=i+1;j<=52;j++){if(num[i]<num[j]){int t=num[i];num[i]=num[j];num[j]=t;char p=zimu[i];zimu[i]=zimu[j];zimu[j]=p;}}}System.out.println(sum);for(int i=1;i<=52;i++){double ans=num[i]*1.0/sum*100;System.out.println(zimu[i]+":"+String.format("%.2f", ans)+"%");}}}⼆、输出单个⽂件的前N个最常出现的英⽂单词思路:⽤输⼊流读取⽂件利⽤HashMap<String,Integer>来存储单词和计数利⽤split进⾏空格分割然后再输出前n个单词频率⾼的package com.wenjian;import java.io.File;import java.util.Scanner;import java.io.FileNotFoundException;import java.util.HashMap;import java.util.Iterator;import java.util.Set;public class nword {public static <type> void main (String[] args) throws FileNotFoundException {File file=new File("E:\\Harry Potter and the Sorcerer's Stone.txt"); //��ȡ�ļ�if(!file.exists()){System.out.println("未找到⽂件");return;}Scanner in=new Scanner(System.in);System.out.println("请输⼊前n个常⽤单词");int n=in.nextInt();Scanner scanner=new Scanner(file);HashMap<String,Integer> hashMap=new HashMap<String,Integer>();while(scanner.hasNextLine()) {String line=scanner.nextLine();String[] lineWords=line.split(" ");Set<String> wordSet=hashMap.keySet();for(int i=0;i<lineWords.length;i++) {if(wordSet.contains(lineWords[i])) {//判断set集合⾥是否有该单词Integer number=hashMap.get(lineWords[i]);//若有次数+1number++;hashMap.put(lineWords[i], number);}else {//没有就将其放⼊set⾥,次数为1hashMap.put(lineWords[i], 1);}}}//计算总体单词数int sum=0;Iterator<String> it=hashMap.keySet().iterator();while(it.hasNext()){sum+=hashMap.get(it.next());}//输出前n个单词while(n>0){Iterator<String> iterator=hashMap.keySet().iterator();int max=0;String maxword=null;while(iterator.hasNext()){String word=iterator.next();if(hashMap.get(word)>max) {max=hashMap.get(word);maxword=word;}}hashMap.remove(maxword);double ans=max*1.0/sum*100;if(!maxword.equals("")) {System.out.println(maxword+":"+max);n--;}}}}三:指定⽂件⽬录,但是会递归⽬录下的所有⼦⽬录,每个⽂件执⾏统计单词的数量以及百分⽐思路:⾸先获取⽬录路径对⽬录下的⽬录进⾏判断,如果还是⽬录继续递归,否则就输出该⽂档⾥的单词package com.wenjian;import java.io.BufferedReader;import java.io.BufferedWriter;import java.io.File;import java.util.Scanner;import java.io.FileNotFoundException;import java.io.FileReader;import java.io.FileWriter;import java.io.IOException;import java.io.Reader;import java.nio.file.DirectoryStream;import java.nio.file.Files;import java.nio.file.Path;import java.nio.file.Paths;import java.util.HashMap;import java.util.Iterator;import java.util.Set;public class neng2 {//输出⽂档单词static public void print(String f) throws IOException{File file=new File(f);if(!file.exists()){System.out.println("⽆法打开⽂件");return;}BufferedReader buf = new BufferedReader(new FileReader(file));HashMap<String,Integer> hashMap=new HashMap<String,Integer>();String s;while((s=buf.readLine())!=null) {String[] lineWords=s.split(" ");Set<String> wordSet=hashMap.keySet();for(int i=0;i<lineWords.length;i++) {if(wordSet.contains(lineWords[i])) {Integer number=hashMap.get(lineWords[i]);number++;hashMap.put(lineWords[i], number);}else {hashMap.put(lineWords[i], 1);}}}while(hashMap.size()>0){Iterator<String> iterator=hashMap.keySet().iterator();int max=0;String maxword=null;while(iterator.hasNext()){String word=iterator.next();if(hashMap.get(word)>max) {max=hashMap.get(word);maxword=word;}else if(hashMap.get(word)==max){if(pareTo(maxword)<0){maxword=word;}}}hashMap.remove(maxword);if(!maxword.equals(""))System.out.println(maxword+":"+max+" ");}}//递归⽂件static public void getDirectory(File file) throws IOException {File flist[] = file.listFiles();if (flist == null || flist.length == 0) {return;}for (File f : flist) {if (f.isDirectory()) {getDirectory(f);} else{System.out.println("file==>" + f.getAbsolutePath()); print( f.getAbsolutePath());System.out.println();}}}static Scanner sc=new Scanner(System.in);public static void main(String[] args)throws IOException {String path="D:\\test";File fm=new File(path);getDirectory(fm);}}。
word统计字数近年来,Word件开始广泛使用,它是一种文本处理工具,它的实用功能使其受到广大用户的青睐。
Word的统计字数功能可以帮助用户快速统计文档所含字数,它也是Word软件中很常用的功能之一。
Word有两种统计字数的方式:一种是Reveal Formatting中的Word Count,另一种是利用VBA(Visual Basic for Application)进行统计数量的功能。
Reveal Formatting模式的Word Count,可以让用户快速知道文档的统计信息,如字数、句子数、行数、页数等,以便用户更好地控制文档内容。
打开Word文档,执行Word Count操作,可以在状态栏最右边找到此功能。
另一个使用VBA编程,可以得到文件统计字数的方法是:打开Word文档,点击“开发人员”选项卡,在“插入”按钮中点击“模块”,会出现设置界面,将下列代码贴入:Sub CountWords() MsgBox 文件中共有 & ActiveDocument.Words.Count &个字” End Sub,然后点击F5运行,即可出现文件中有多少字的提示语句。
另一方面,Word软件也具有计算字符数的功能。
从Reveal Formatting中开始,点击Word Count,就可以在状态栏中看到字符数,字符数包括空格和标点符号。
除此之外,用户还可以使用VBA编程来计算字符数,只需将下列代码复制到模块中:Sub CountCharacters() MsgBox文件中共有 &ActiveDocument.Characters.Count &个字符” End Sub,按F5运行,屏幕上会有提示窗口显示文件字符数。
无论是统计字数还是字符数,Word的软件都具备良好的实用功能,可以满足用户的需求。
文档的统计信息能够帮助用户更好地控制文档内容,从而提高文档制作质量。
通过Reveal Formatting界面或使用VBA编程,用户可以快速计算出文档中的字数和字符数,这不仅提高了工作效率,也大大改善了文档办理质量。
Sub 词频统计()
'
' 词频统计Macro
'
Dim SingleWord As String '从当前文档提取的一个单词
Const maxWords = 15000 '允许出现的不同单词的最大数量,如不够,可适当加大Dim Words(maxWords) As String '用来保存各个不同的单词
Dim Freq(maxWords) As Integer '出现频度计数器
Dim WordNum As Integer '不同单词的数量
Dim ByFreq As Boolean '输出结果的排序标准
Dim ttlwds As Long '文档中的单词总数
Dim Excludes As String '不在统计范围内的单词
Dim Found As Boolean '临时标记
Dim j, k, l, Temp As Integer '临时变量
Dim tWord As String '
' 设置要排除的单词。
' 英文排除词:[the][a][of][is][to][for][this][that][by][be][and][are]
' 排除词可以从各大搜索引擎的说明获得,可根据实际情况修改
Excludes = "[][的][是]"
' 向用户询问排序标准
ByFreq = True
ans = InputBox$("根据单词(1)还是频度(2)排序?", "排序标准", "1")
If ans = "" Then End
If Trim(ans) = "1" Then
ByFreq = False
End If
'开始分析文档
Selection.HomeKey Unit:=wdStory
System.Cursor = wdCursorWait
WordNum = 0
ttlwds = ActiveDocument.Words.Count
' 处理文档中的每个单词
For Each aWord In ActiveDocument.Words
'英文单词不区分大小写
SingleWord = Trim(LCase(aWord))
'该单词是否在排除列表中?
If InStr(Excludes, "[" & SingleWord & "]") Then SingleWord = ""
If Len(SingleWord) > 0 Then
'找到一个需要处理的单词
Found = False
For j = 1 To WordNum
If Words(j) = SingleWord Then
' 这个单词已经出现过了
' 把它的出现频度加1
Freq(j) = Freq(j) + 1
Found = True
Exit For
End If
Next j
If Not Found Then
' 这个单词还没有出现过
' 将它登记为一个新的单词
' 出现频度设置为1
WordNum = WordNum + 1
Words(WordNum) = SingleWord
Freq(WordNum) = 1
End If
If WordNum > maxWords - 1 Then
j = MsgBox("已达到单词数量的最大限制值。
请增加maxWords的值.", vbOKOnly) Exit For
End If
End If
ttlwds = ttlwds - 1
'在状态栏上显示处理进度
StatusBar = "剩余:" & ttlwds & " 不同单词数量: " & WordNum
Next aWord
' 对处理结果进行排序
For j = 1 To WordNum - 1
k = j
For l = j + 1 To WordNum
If (Not ByFreq And Words(l) < Words(k)) Or (ByFreq And Freq(l) > Freq(k)) Then k = l Next l
If k <> j Then
tWord = Words(j)
Words(j) = Words(k)
Words(k) = tWord
Temp = Freq(j)
Freq(j) = Freq(k)
Freq(k) = Temp
End If
'排序进度
StatusBar = "正在排序:" & WordNum - j
Next j
' 将统计结果显示到一个新的Word文档
tmpName = ActiveDocument.AttachedTemplate.FullName
' 创建一个新文档
Documents.Add Template:=tmpName, NewTemplate:=False
'清除...
Selection.ParagraphFormat.TabStops.ClearAll
' 将处理结果写入新文档,每个单词一行
With Selection
For j = 1 To WordNum
.TypeText Text:=Trim(Str(Freq(j))) & vbTab & Words(j) & vbCrLf
Next j
End With
System.Cursor = wdCursorNormal
j = MsgBox("该文档总共有" & Trim(Str(WordNum)) & "个不同的单词。
", vbOKOnly, "分析完毕!")
End Sub。