数据仓库与数据挖掘基础第6章关联规则(赵志升)
- 格式:pptx
- 大小:520.10 KB
- 文档页数:61


一、数据挖掘中的关联规则是什么:所谓关联规则,是指数据对象之间的相互依赖关系,而发现规则的任务就是从数据库中发现那些确信度(Conk一dente)和支持度(Support)都大于给定值的强壮规则。
从数据库中发现关联规则近几年研究最多。
目前,已经从单一概念层次关联规则的发现发展到多个概念层次的关联规则的发现。
在概念层次上的不断深人,使得发观的关联规则所提供的信息越来越具体,实际上这是个逐步深化所发现知识的过程。
在许多实际应用中,能够得到的相关规则的数目可能是相当大的,而且,用户也并不是对所有的规则感兴趣,有些规则可能误导人们的决策,所以,在规则发现中常常引人”兴趣度”(指一则在一定数据域上为真的知识被用户关注的程度)概念。
而基于更高概念层次上的规则发现研究(如一般化抽象层次上的规则和多层次上的规则发现)则是当前研究的重点之一。
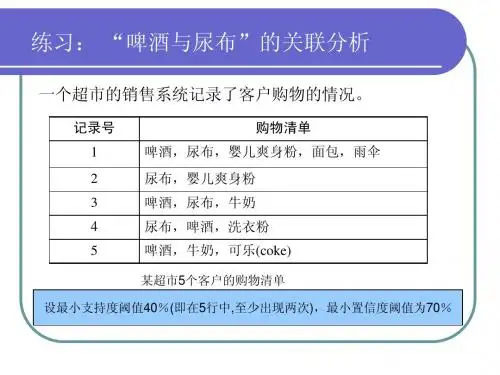
二、关联规则数据挖掘中最经典的案例:关联规则数据挖掘中最经典的案例就是沃尔玛的啤酒和尿布的故事。
沃尔玛拥有世界上最大的数据仓库系统,为了能够准确了解顾客在其门店的购买习惯,沃尔玛对其顾客的购物行为进行购物篮分析,想知道顾客经常一起购买的商品有哪些。
沃尔玛数据仓库里集中了其各门店的详细原始交易数据。
在这些原始交易数据的基础上,沃尔玛利用数据挖掘方法对这些数据进行分析和挖掘。
一个意外的发现是:“跟尿布一起购买最多的商品竟是啤酒!”经过大量实际调查和分析,揭示了一个隐藏在“尿布与啤酒”背后的美国人的一种行为模式:在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,而他们中有30%~40%的人同时也为自己买一些啤酒。
产生这一现象的原因是:美国的太太们常叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买尿布后又随手带回了他们喜欢的啤酒。
三、关联规则的一些定义与属性:考察一些涉及许多物品的事务:事务1 中出现了物品甲,事务2 中出现了物品乙,事务 3 中则同时出现了物品甲和乙。
那么,物品甲和乙在事务中的出现相互之间是否有规律可循呢?在数据库的知识发现中,关联规则就是描述这种在一个事务中物品之间同时出现的规律的知识模式。


数据仓库与数据挖掘习题答案第1章数据仓库的概念与体系结构1。
面向主题的,相对稳定的。
2。
技术元数据,业务元数据。
3。
联机分析处理OLAP。
4. 切片(Slice),钻取(Drill—down和Roll—up等)。
5。
基于关系数据库。
6。
数据抽取,数据存储与管理。
7. 两层架构,独立型数据集市,依赖型数据集市和操作型数据存储,逻辑型数据集市和实时数据仓库。
8。
可更新的,当前值的.9。
接近实时。
10. 以报表为主,以分析为主,以预测模型为主,以营运导向为主.11。
答:数据仓库就是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,通常用于辅助决策支持.数据仓库的特点包含以下几个方面:(1)面向主题。
操作型数据库的数据组织是面向事务处理任务,各个业务系统之间各自分离;而数据仓库中的数据是按照一定的主题域进行组织。
主题是一个抽象的概念,是指用户使用数据仓库进行决策时所关心的重点领域,一个主题通常与多个操作型业务系统或外部档案数据相关。
(2)集成的.面向事务处理的操作型数据库通常与某些特定的应用相关,数据库之间相互独立,并且往往是异构的。
而数据仓库中的数据是在对原有分散的数据库数据作抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企事业单位一致的全局信息。
也就是说存放在数据仓库中的数据应使用一致的命名规则、格式、编码结构和相关特性来定义.(3)相对稳定的。
操作型数据库中的数据通常实时更新,数据根据需要及时发生变化。
数据仓库的数据主要供单位决策分析之用,对所涉及的数据操作主要是数据查询和加载,一旦某个数据加载到数据仓库以后,一般情况下将作为数据档案长期保存,几乎不再做修改和删除操作,也就是说针对数据仓库,通常有大量的查询操作及少量定期的加载(或刷新)操作。






第六章作业1.数据挖掘与知识发现两个概念有什么不同?P116知识发现被认为是从数据中发现有用知识的整个过程。
数据挖掘被认为是知识发现过程中的一个特定步骤,它用专门算法从数据中抽取模式。
2.知识发现过程由哪三部分组成?每部分的工作是什么?P116KDD过程可以概括为三个子步骤:数据准备、数据挖掘和结果的解释和评价。
数据准备:数据准备又可分为三个子步骤:数据选取、数据预处理和数据变换。
数据选取的目的是确定发现任务的操作对象,即目标数据,它是根据用户的需要从原始数据库中抽取的一组数据。
数据预处理一般可能包括消除噪声、推导计算缺值数据、消除重复记录、完成数据类型转换(如把连续值数据转换为离散型的数据,以便于符号归纳;或是把离散型的转换为连续值型的,以便于神经网络归纳)等。
当数据开采的对象是数据仓库时,一般来说,数据预处理已经在生成数据仓库时完成了。
数据变换的主要目的是消减数据维数或降维,即从初始特征中找出真正有用的特征以减少数据开采时要考虑的特征或变量个数。
数据挖掘:数据挖掘是利用一系列方法或算法从数据中获取知识。
按照数据挖掘任务的不同,数据挖掘方法分类分为聚类、分类、关联规则发现等。
结果的解释和评价:数据挖掘阶段发现的模式,经过用户或机器的评估,可能存在冗余或无关的模式,这时需要将其剔除;也有可能模式不满足用户要求,这时则需要让整个发现过程退回到发现阶段之前,如重新选取数据、采用新的数据变换方法、设定新的数据挖掘参数值,甚至换一种挖掘算法(如当发现任务是分类时,有多种分类方法,不同的方法对不同的数据有不同的效果)。
另外,由于KDD最终是面向人类用户的,因此可能要对发现的模式进行可视化,或者把结果转换为用户易懂的另一种表示,如把分类决策树转换为“if...then...”规则。
3.数据挖掘的对象有哪些?他们各自的特点是什么?P1181.关系数据库特点:(1)数据动态性(2)数据不完全性(3)数据噪声(4)数据冗余性(5)数据稀疏性(6)海量数据2.文本特点:(1)关键词或特征提取(2)相似检索(3)文本聚类(4)文本数据3.图像与视频数据特点:(1)图像与视频特征提取(2)基于内容的相似检索(3)视频镜头的编辑与组织4.web数据(1)异构数据集成和挖掘(2)半结构化数据模型抽取4.1).关联分析若两个或多个数据项的取值之间重复出现且概率很高时,它就存在某种关联,可以建立起这些数据项的关联规则。
数据挖掘中的关联规则算法数据挖掘是一门利用计算机技术从大量数据中发现潜在模式和信息的过程。
在数据挖掘中,关联规则算法是一种常用的技术,用于发现数据集中的相关关系。
关联规则分析在商业智能、市场营销、电子商务等领域有着广泛的应用,它可以帮助企业了解客户购买行为、优化商品摆放位置、提高销售额等。
关联规则算法的基本概念是通过发现数据项之间的共同出现模式来确定它们之间的关联关系。
在关联规则算法中,有两个重要指标:支持度和置信度。
支持度指的是某个项集在所有的事务中出现的频率,而置信度则表示当一个项集出现时,另一个项集也出现的概率。
常用的关联规则算法有Apriori算法和FP-Growth算法。
Apriori算法是关联规则分析中最经典和最早的算法之一。
它的基本思想是:首先找到数据集中所有的频繁项集,然后根据频繁项集生成关联规则。
Apriori算法包含两个主要步骤:扫描数据库以获取频繁项集和使用频繁项集生成关联规则。
在扫描数据库的过程中,Apriori算法会生成候选项集,并使用支持度来剪枝,以找出频繁项集。
然后,根据频繁项集生成关联规则,并使用置信度来筛选出符合要求的关联规则。
FP-Growth算法是一种更有效的关联规则算法,它通过建立基于前缀树的数据结构FP树来发现频繁项集。
FP-Growth算法包含三个主要步骤:构建FP树、挖掘频繁项集和生成关联规则。
在构建FP树的过程中,FP-Growth算法会将事务按照频繁项集的顺序进行排序,然后使用这些排序后的事务构建FP树。
接下来,通过遍历FP树来挖掘频繁项集,并使用置信度来生成关联规则。
关联规则算法的应用场景非常广泛。
在市场营销中,企业可以利用关联规则算法将相关产品进行组合销售,从而提高销售额。
在电子商务中,关联规则算法可以帮助电商平台推荐用户可能感兴趣的商品,提高用户的购买率。
在医疗保险中,关联规则算法可以分析医疗数据,帮助保险公司识别高风险人群,制定相应的保险政策。