spss主成分分析.ppt
- 格式:ppt
- 大小:535.01 KB
- 文档页数:29
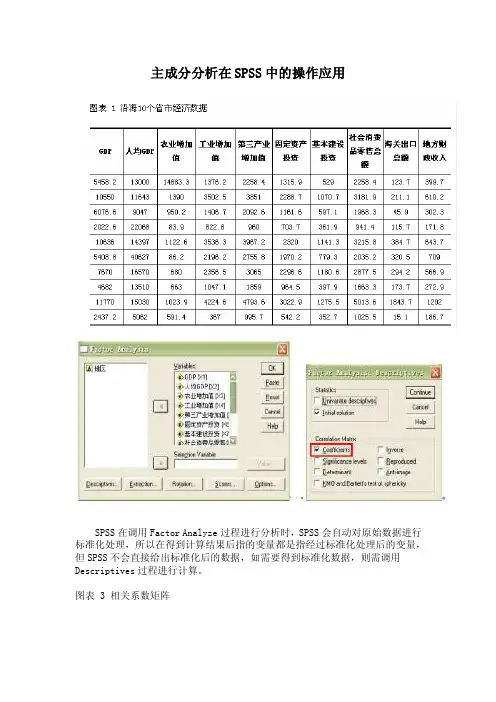
主成分分析在SPSS中的操作应用SPSS在调用Factor Analyze过程进行分析时,SPSS会自动对原始数据进行标准化处理,所以在得到计算结果后指的变量都是指经过标准化处理后的变量,但SPSS不会直接给出标准化后的数据,如需要得到标准化数据,则需调用Descriptives过程进行计算。
图表 3 相关系数矩阵图表 4 方差分解主成分提取分析表主成分分析在SPSS中的操作应用(3) 图表 5 初始因子载荷矩阵从图表3可知GDP与工业增加值,第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、地方财政收入这几个指标存在着极其显著的关系,与海关出口总额存在着显著关系。
可见许多变量之间直接的相关性比较强,证明他们存在信息上的重叠。
主成分个数提取原则为主成分对应的特征值大于1的前m个主成分。
注:特征值在某种程度上可以被看成是表示主成分影响力度大小的指标,如果特征值小于1,说明该主成分的解释力度还不如直接引入一个原变量的平均解释力度大,因此一般可以用特征值大于1作为纳入标准。
通过图表4(方差分解主成分提取分析)可知,提取2个主成分,即m=2,从图表5(初始因子载荷矩阵)可知GDP、工业增加值、第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、海关出口总额、地方财政收入在第一主成分上有较高载荷,说明第一主成分基本反映了这些指标的信息;人均GDP和农业增加值指标在第二主成分上有较高载荷,说明第二主成分基本反映了人均GDP和农业增加值两个指标的信息。
所以提取两个主成分是可以基本反映全部指标的信息,所以决定用两个新变量来代替原来的十个变量。
但这两个新变量的表达还不能从输出窗口中直接得到,因为“Component Matrix”是指初始因子载荷矩阵,每一个载荷量表示主成分与对应变量的相关系数。
用图表5(主成分载荷矩阵)中的数据除以主成分相对应的特征值开平方根便得到两个主成分中每个指标所对应的系数[2]。


S P S S学习系列30.主成份分析-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN30. 主成份分析一、基本原理主成份分析,是数学上对数据降维的一种方法,是将多个变量转化为少数综合变量(集中了原始变量的大部分信息)的一种多元统计方法。
其主要目的是将变量减少,并使其改变为少数几个相互独立的线性组合形成的新变量(主成份,其方差最大),使得原始资料在这些成份上显示最大的个别差异来。
在所有的线性组合中所选取的F1应该是方差最大的,称为第一主成分。
如果第一主成分不足以代表原来所有指标的信息,再考虑选取第二个线性组合F2, 称为第二主成分。
为了有效地反映原有信息,F1已有的信息就不需要再出现在F2中,用数学语言表达就是要求Cov(F1,F2)=0. 依此类推可以构造出第三、第四、…、第p个主成分。
主成份分析,可以用来综合变量之间的关系,也可用来减少回归分析或聚类分析中的变量数目。
设有n个样品(多元观测值),每个样品观测p项指标(变量):X1,…,X p,得到原始数据资料阵:其中,X i = (x1i,x2i,…,x ni)T,i = 1, …, p.用数据矩阵X的p个列向量(即p个指标向量)X1,…,X p作线性组合,得到综合指标向量:简写成:F i = a1i X1 + a2i X2+…+a pi X p i = 1, …, p限制系数a i = (a1i,a2i,…,a pi)T为单位向量,即且由下列原则决定:(1)F i与F j互不相关,即COV(F i, F j)= a i T∑a i=0,其中∑为X 的协方差矩阵;(2)F1是X1,X2,…,X p的所有满足上述要求的线性组合中方差最大的,即F2是与F1不相关的X1,…,X p所有线性组合中方差最大的,…,F p 是与F1,…,F p-1都不相关的X1,…,X p所有线性组合中方差最大的。
满足上述要求的综合指标向量F1,F2,…,F p就是主成分,这p个主成分从原始指标所提供的信息总量中所提取的信息量依次递减,每一个主成分所提取的信息量用方差来度量,主成分方差的贡献就等于原指标相关系数矩阵相应的特征值λi,每一个主成分的组合系数a i = (a1i,a2i,…,a pi)T就是特征值λi所对应的单位特征向量。



利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Statistics 栏中选中Univariate descriptives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix 栏中,选中Coefficients 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant 复选项,则会给出相关系数矩阵的行列式,如果希望在Excel 中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue 按钮完成设置(图5)。
⒉ 设置Extraction 选项。
打开Extraction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(∏ρινχιπαλ χομπονεντσ),因此对此栏不作变动,就是认可了主成分分析方法。



如何在SPSS数据分析报告中进行主成分分析?关键信息项1、数据准备要求2、主成分分析步骤3、结果解读方法4、报告撰写要点1、数据准备要求11 数据质量检查确保数据的完整性,不存在缺失值。
若有缺失值,需采取适当的方法进行处理,如均值插补、回归插补等。
检查数据的准确性,避免错误的数据录入。
评估数据的分布特征,判断是否符合正态分布。
若不符合,可能需要进行数据转换。
12 变量选择选择具有相关性且能反映研究问题的变量。
避免包含过多无关或冗余的变量,以免增加分析的复杂性。
13 数据标准化对数据进行标准化处理,使不同变量具有相同的量纲和可比性。
2、主成分分析步骤21 打开 SPSS 软件并导入数据启动 SPSS 程序,通过“文件”菜单中的“打开”选项导入准备好的数据文件。
22 选择主成分分析方法在“分析”菜单中,选择“降维”子菜单中的“因子分析”。
23 设置分析参数将需要分析的变量选入“变量”框。
选择提取主成分的方法,如基于特征值大于 1 或指定提取的主成分个数。
24 输出结果选项设置根据需求选择输出相关的统计量和图表,如成分矩阵、碎石图等。
25 执行分析点击“确定”按钮,执行主成分分析。
3、结果解读方法31 成分矩阵解读观察成分矩阵中各变量在主成分上的载荷值,判断变量与主成分的相关性。
载荷值的绝对值越大,表明变量与主成分的相关性越强。
32 特征值和方差贡献率关注特征值,通常选择特征值大于 1 的主成分。
方差贡献率表示主成分解释原始变量变异的比例,累计方差贡献率反映了所选主成分对原始变量信息的综合解释程度。
33 碎石图分析通过碎石图直观判断主成分的重要性和提取的合理性。
34 成分得分计算如有需要,可计算成分得分,用于后续的进一步分析或建模。
4、报告撰写要点41 研究背景和目的阐述简要介绍研究的背景、问题以及进行主成分分析的目的。
42 数据来源和预处理说明描述数据的来源、样本量以及所进行的数据预处理步骤和方法。