蛋白质序列
- 格式:ppt
- 大小:1.62 MB
- 文档页数:60

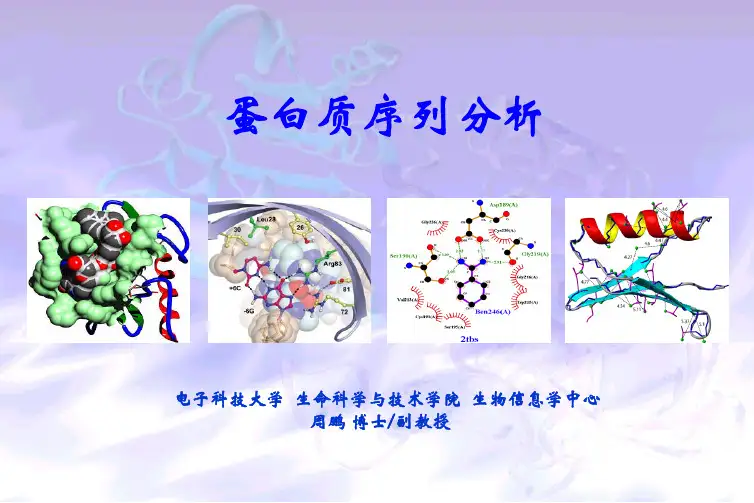
蛋白质序列分析电子科技大学 生命科学与技术学院 生物信息学中心周鹏博士/副教授理化性质: 分子量、等电点、氨基酸组成等结构分析:一级结构、二级结构、三级结构功能预测:motif、domain、信号肽、跨膜区、亚细胞定位、GO等一、蛋白序列的获得1. 基因序列翻译推导得到2. 氨基酸测序(多肽)得到3. 双向电泳、质谱分析得到4. 数据库得到SRS(Sequence Retrieval System )序列检索系统胶质纤维酸性蛋白(glial fibrillary acidic protein, GFAP)二、蛋白质理化性质分析三、蛋白质结构分析(一)、二级结构预测二级结构。
– α螺旋,是蛋白质中最常见最典型含量最丰富的二级结构元件.在α螺旋中,每轮卷曲的螺旋包含3.6氨基酸残基,残基侧链伸向外侧,同一肽链上的每个残基的酰胺氢和位于它后面的第4个残基上的羰基氧彼此之间形成氢键。
这种氢键大致与螺旋轴平行。
在水环境中,肽键上的酰胺氢和羰基氧既能形成内部(α-螺旋内)的氢键,也能与水分子形成氢键。
– 不同的氨基酸对α螺旋形成的影响是不同的。
– β折叠是通过肽链间或肽段间的氢键维系。
可以把它们想象为由折叠的条状纸片侧向并排而成,每条纸片可看成是一条肽链, 称为β折叠股或β股(β-strand),肽主链沿纸条形成锯齿状。
需要注意的是在折叠片上的侧链都垂直于折叠片的平面,并交替的从平面上下二侧伸出。
-无规则卷曲(randon coil)无规则卷曲或称卷曲(coil),泛指那些不能被归入明确的二级结构如折叠片或螺旋的多肽区段。
实际上这些区段大多数既不是卷曲,也不是完全无规的,虽然也存在少数柔性的无序片段。
它们也像其他二级结构那样是明确而稳定的结构。
它们受侧链相互作用的影响很大,经常构成酶活性部位和其他蛋白质特异的功能部位如许多钙结合蛋白中结合钙离子的EF 手结构(E-F hand structure)的中央环二级结构预测面临的困难二级结构在不同的溶剂环境中构象可能会不同同一肽段在不同的蛋白质中的结构也不一样预测序列模体和结构域都是通过对相关蛋白质的多序列比对分析而获得的– 线性模体(Linear motif),较短的特定序列模式。

蛋白质序列查法
蛋白质序列测定主要有以下几种方法:
1. 末端测序法,包括Edman降解法和羧肽酶法等,这种方法是通过测定蛋白质的末端氨基酸序列来推断整个蛋白质的序列。
2. 基于质谱的方法,如鸟枪法蛋白质测序,通过将蛋白质多重水解成小分子肽段,再对经高效液相色谱分离的肽段进行质谱鉴定,根据肽段的质谱信息获取肽段的氨基酸组成和排列顺序,然后将各肽段拼接成完整的蛋白质便可以得到完整样品蛋白的氨基酸组成和排列顺序。
3. 质谱法(Mass Spectrometry),蛋白质或多肽被分解成较小的片段,然后使用质谱仪来测量这些片段的质量/质荷比,从而推断出氨基酸序列。
这通常通过碎片化技术(如碰撞诱导解离或电子转移解离)来实现。
这些方法各有优缺点,可以根据需要选择合适的方法进行蛋白质序列测定。

蛋白质序列分析日期:目录•蛋白质序列分析简介•蛋白质序列获取与预处理•蛋白质序列分析方法•功能与结构预测•蛋白质序列分析的挑战与展望•案例研究:蛋白质序列分析在生物医学中的应用蛋白质序列分析简介•蛋白质序列分析是指通过算法和软件工具对蛋白质序列进行各种层面的分析,以揭示其结构、功能和进化关系等生物信息。
这种分析可以基于一级结构(即氨基酸序列)以及更高层次的结构(如二级、三级和四级结构)进行。
蛋白质序列分析的定义通过序列分析,可以预测蛋白质的功能,进而理解其在生物体内的角色。
揭示蛋白质功能比较不同物种间同源蛋白质的序列变异,可以推断它们的进化关系。
解析进化关系了解蛋白质的结构和功能,有助于设计针对特定蛋白质的小分子药物。
助力药物设计蛋白质序列分析的重要性基础科学研究:在生物学、生物化学、生物物理学等基础科学领域,蛋白质序列分析是理解和揭示生命活动基本规律的重要手段。
生物工程:在生物工程领域,蛋白质序列分析可用于蛋白质工程、代谢工程等方面,指导工业生产和应用。
医学领域:通过蛋白质序列分析,可以研究疾病的发生发展机制,寻找新的药物靶点和治疗手段。
综上所述,蛋白质序列分析在生命科学研究中扮演着至关重要的角色,其应用场景广泛,意义重大。
蛋白质序列分析的应用领域蛋白质序列获取与预处理常见的蛋白质序列数据库包括UniProt、NCBI的Protein Database (nr)等。
这些数据库收录了大量的蛋白质序列及其相关信息。
常用数据库这些数据库通常提供分类、注释、检索等功能,用户可以根据需要获取特定物种、特定功能或特定实验条件下的蛋白质序列。
数据库特点蛋白质序列数据库简介从数据库中获取蛋白质序列用户可以通过关键词、序列ID、物种信息等方式在数据库中进行检索,获取目标蛋白质序列。
数据格式获取的蛋白质序列通常以FASTA、GenBank等格式提供,这些格式包含了序列的基本信息和序列数据。
在获取到的蛋白质序列中,可能会包含一些非氨基酸字符或特殊符号,需要进行相应的去除或替换。



ncbi蛋白质序列
NCBI(National Center for Biotechnology Information)是一个提供生物技术信息的数据库,其中包含了大量的蛋白质序列数据。
要获取特定蛋白质的序列,你可以按照以下步骤进行:
1. 打开NCBI的网站()。
2. 在搜索栏中输入你感兴趣的蛋白质的名称或相关关键词,然后按下回车键进行搜索。
3. 在搜索结果中,你可以点击进入相关蛋白质的页面。
4. 在该页面中,你可以找到蛋白质的序列信息,通常可以在“Sequence”或“Sequence Information”等标签下找到。
5. 如果你需要特定格式的序列数据,比如FASTA格式,你可以在页面上选择相应的选项进行下载或复制。
此外,你还可以使用NCBI提供的工具和数据库来进行更深入的蛋白质序列分析,比如BLAST(Basic Local Alignment Search
Tool)等工具可以用来比对蛋白质序列,了解其在不同物种中的保守性等信息。
总之,NCBI是一个非常强大的资源,可以帮助你获取并分析蛋白质序列数据,希望这些信息能对你有所帮助。


蛋白质的fasta序列
蛋白质是生命体中的重要分子,由氨基酸组成。
蛋白质的fasta 序列是指将蛋白质序列按照fasta格式进行存储和呈现的一种方式。
fasta格式是一种用于存储和呈现核酸和蛋白质序列的文本格式,其基本格式为一行序列标识符,后跟一行序列。
在蛋白质fasta序列中,序列标识符通常包括蛋白质名称、描述信息和GI号等信息。
fasta
序列可以方便地用于蛋白质序列比对、结构预测、功能研究等方面。
同时,fasta序列是公共数据库中存储蛋白质序列的重要格式之一,为生命科学研究提供了基础数据支持。
- 1 -。

蛋白质dna序列蛋白质DNA序列是生物体内蛋白质合成的基础,它决定了蛋白质的结构和功能。
本文将从DNA的结构、蛋白质合成的过程以及蛋白质DNA序列的应用等方面进行介绍。
一、DNA的结构DNA是由核苷酸组成的双链螺旋结构,每个核苷酸由糖、磷酸和一种碱基组成。
碱基共有四种:腺嘌呤(A)、胸腺嘧啶(T)、鸟嘌呤(G)和胞嘧啶(C)。
DNA的两条链通过碱基间的氢键相互连接,其中A和T之间形成两个氢键,G和C之间形成三个氢键。
这种碱基配对规则使得DNA的两条链具有互补性。
二、蛋白质合成的过程蛋白质合成是通过DNA转录成RNA,再通过RNA翻译成蛋白质的过程。
首先,DNA的双链解旋,在DNA的模板链上进行转录,合成一条称为mRNA的单链RNA。
mRNA带着DNA上的遗传信息离开细胞核,进入细胞质中的核糖体。
在核糖体中,mRNA的遗传信息被翻译成蛋白质。
翻译过程中,tRNA带着特定的氨基酸与mRNA上的密码子配对,形成多肽链。
随着mRNA的移动,tRNA逐个释放氨基酸并连在一起,最终合成出具有特定结构和功能的蛋白质。
三、蛋白质DNA序列的应用蛋白质DNA序列具有广泛的应用价值。
首先,通过分析蛋白质DNA序列可以揭示生物体的遗传信息,帮助我们了解基因的功能和调控机制。
其次,蛋白质DNA序列可以用于鉴定物种和个体之间的遗传差异,对生物进化和种群遗传学的研究具有重要意义。
蛋白质DNA序列还可以用于疾病检测和药物研发。
许多疾病的发生和发展与蛋白质的结构和功能异常有关,通过分析蛋白质DNA 序列可以寻找疾病相关基因,并研发相应的治疗方法。
药物研发中,蛋白质DNA序列的分析可以帮助研究人员设计具有特定作用靶点的药物,提高药效和减少副作用。
总结起来,蛋白质DNA序列是生物体内蛋白质合成的基础,对于我们了解生物的遗传信息、研究进化和种群遗传学、开展疾病检测和药物研发等方面都具有重要意义。
通过深入研究蛋白质DNA序列,我们可以揭示生命的奥秘,并为人类的健康和生活质量提供更多可能性。
蛋白质序列编码
蛋白质序列编码是指将一个蛋白质的氨基酸序列用数字或字母进行编码。
这种编码方式可以用来描述蛋白质的特征和功能,也可以用来进行蛋白质结构预测和功能预测。
常见的编码方式包括BLOSUM 矩阵、PAM矩阵、One-hot编码等。
其中BLOSUM矩阵是通过对已知的同源蛋白质序列进行比对,计算它们之间的相似性来生成的。
PAM矩阵则是通过对不同物种的蛋白质序列进行比对来生成的。
而One-hot 编码则是将每个氨基酸用一个二进制向量来表示,其中只有一个元素为1,其余元素为0。
这种编码方式可以用于机器学习等领域中。
蛋白质序列编码是蛋白质研究和分析的重要组成部分,可以帮助人们更好地理解蛋白质的结构和功能。
- 1 -。
蛋白质序列.蛋白质序列,是生物体内一类重要的有机分子。
它是由氨基酸构成的长链状聚合物,通过肽键连接在一起。
蛋白质在生物体内发挥着多种重要的功能,包括结构支持、代谢调控、信号传递等。
一条蛋白质序列的组成是由20种不同的氨基酸按照一定的顺序排列而成的。
这个顺序决定了蛋白质的结构和功能。
不同的蛋白质序列会导致不同的空间结构,从而决定了它们在生物体内的功能和相互作用方式。
蛋白质序列的研究对于理解生物体内的生命活动具有重要意义。
科学家通过对蛋白质序列的研究,可以揭示蛋白质的功能、结构和相互作用网络。
这对于疾病的诊断和治疗具有重要的指导意义。
蛋白质序列的研究方法主要包括实验方法和计算方法。
实验方法包括蛋白质的分离、纯化和测序技术。
计算方法则利用计算机模拟和算法来预测蛋白质的结构和功能。
这些方法的发展为蛋白质序列研究提供了强有力的工具和手段。
蛋白质序列的研究在生物学、医学和生物工程等领域具有广泛的应用。
在生物学中,研究蛋白质序列可以帮助科学家理解生物体内的基因调控、细胞信号转导和代谢途径等生命过程。
在医学中,研究蛋白质序列可以帮助诊断疾病、设计新药和治疗疾病。
在生物工程中,研究蛋白质序列可以帮助设计和改造蛋白质,用于生物制药和工业生产等领域。
蛋白质序列的研究还面临着一些挑战和难题。
首先,蛋白质序列的空间结构是非常复杂的,预测蛋白质的结构仍然是一个难题。
其次,蛋白质序列的功能是多样的,如何准确预测蛋白质的功能也是一个挑战。
此外,蛋白质序列的大规模数据分析和挖掘也是一个重要的研究方向。
蛋白质序列是生物体内重要的有机分子,对于生命活动具有重要的作用。
通过研究蛋白质序列,可以揭示蛋白质的结构和功能,为疾病诊断和治疗提供指导。
蛋白质序列的研究方法包括实验方法和计算方法,具有广泛的应用前景。
然而,蛋白质序列的研究还面临着一些挑战和难题。
我们期待未来的研究能够解决这些问题,推动蛋白质序列研究的进一步发展和应用。
蛋白质序列中的星号
蛋白质序列中的星号通常表示该位置的氨基酸残基与参考序列或野生型序列不同,即存在突变或变异。
星号的位置和数量可以提供关于蛋白质变异程度的信息。
在一些情况下,蛋白质序列中的星号也可能表示其他信息,例如缺失的氨基酸残基、修饰的氨基酸残基或不确定的氨基酸残基等。
需要注意的是,不同的数据库或软件可能使用不同的符号或注释方式来表示蛋白质序列中的变异或修饰,因此在实际应用中需要结合具体情况进行解释。