SqlServer2008--学习笔记(自己总结)
- 格式:docx
- 大小:2.57 MB
- 文档页数:27

sql-sever-2008-数据库知识点总结第一章数据库基础1数据库系统:是由数据库及其管理软件组成的系统,常常把数据库有关的硬件和软件系统成为数据库系统2.数据库:数据库就是数据的仓库,由表、关系以及操作对象组成3.数据:是描述事物的符号记录(数字、文字、图形、图像、声音等)4.数据库的作用存储大量数据,方便检索和访问保持数据信息的一致、完整共享和安全通过组合分析,产生新的有用信息5.数据库经历的三个阶段及特点1)人工管理阶段: 数据不保存;使用应用程序管理数据;数据不共享;数据不具有独立性。
2)文件系统阶段:数据可以长期保存;由文件系统管理数据;共享性差,数据冗余大;数据独立性差。
3)数据库系统阶段:数据结构化;数据共享性高;数据独立性强;数据粒度小;独立的6)数据库Standard 部门级应用程序的数据库服务器Enterprise 高度可伸缩和高度可用的企业级数据库Developer Enterprise 版,但是只授予开发和测试用许可Web 供托管公司提供低成本、高伸缩的托管服务,只收取低廉的每月许可费Mobile 用于智能手持式设备的精简数据库12.掌握SQL Server 2008数据库的安装与卸载第三章数据库的管理1.T-SQL语言分类DDL(数据定义语言)-create(创建)-alter (修改)-drop (删除)DQL(数据查询语言)-inter(插入)-update(更新)DML(数据操作语言)-select(查询)DCL(数据控制语言)-revoke(撤销)-deny(拒绝)-grant(同意、授权)2.数据库文件主数据文件(.mdf):一个数据库有且只有一个辅助数据文件(.ndf):根据需要自由选择,当数据库很大时,可以选择多个日志文件(.ldf):用于存储恢复数据库所需的事务日志信息3.掌握数据库的创建及修改(图形化及代码)修改数据库包括:扩展、收缩、分离附加、删除4.语法1)修改数据库名Alter database 原数据库名Modify name =新数据库名例子:【例】将数据库book的名字改为books alter database bookmodify name=books2)修改文件属性Alter database 数据库名Modify file(name='逻辑名',size=修改后的大小,maxsize=修改后的大小,filegrowth=修改后的大小)Go例子:把初始大小由原来5mb增大为12mb alter database booksmodify file(name='book_data',size=12mb)go3)添加日志文件Alter database 数据库名Add log file(name= ‘逻辑名’,filename = ‘文件的存放路径’,size=日志文件的初始大小,maxsize=日志文件的最大大小,filegrowth=日志文件的增长方式)Go例子:【例】向shop数据库中添加一个日志文件alter database shopadd log file(name='shop_log2',filename ='c:\shop_log2.ldf',size=10mb, maxsize=20mb,filegrowth=10%)go4)删除空文件Alter database 数据库名Remove file 文件的逻辑名例子: 删除文件shop_data2 alterdatabase shop removefile shop_data27)添加辅助数据文件alter database 数据库名add file(name=‘逻辑名’,filename=‘文件存放的路径’,size=初始大小,maxsixe=最大大小,filegrowth=增长方式)Go例子:向数据库shop中添加一个辅助数据文件alter database shopadd file(name='shop_data3',filename='c:\shop_data3.ndf',size=5mb,maxsize=10mb,filegrowth=10%)go5)创建/删除数据库Create database 数据库名on primary(--数据文件 name=‘逻辑名’,filename=‘文件的存放路径’,size=数据文件的初始大小,maxsize=数据文件的最大大小,filegrowth=文件的增长方式 ) log on(--日志文件 name=‘逻辑名’,filename=‘文件的存放路径’,size=数据文件的初始大小,maxsize=数据文件的最大大小,filegrowth=文件的增长方式 )go例子:创建一个名为book的数据库,其初始值大小为5MB,最大大小为 50MB,允许数据库自动增长,增长方式是按10%比例增长;日志文件初始为2MB,最大可增长到5MB,按1MB增长。

sql学习心得5篇精选汇总结构化查询语言(SQL)是用于关系数据库管理和数据操作的标准计算机语言。
下面给大家带来一些关于sql实验心得,希望对大家有所帮助。
sql实验心得1sQL是structured Query Language(结构化查询语言)的缩写。
sQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言。
在使用它时,只需要发出做什么的命令,怎么做是不用使用者考虑的。
sQL功能强大、简单易学、使用方便,已经成为了数据库操作的基础,并且现在几乎所有的数据库均支持sQL。
它的强大功能以前就听人说过,所以就选了这门课。
经过一个学期的数据库课程的学习,我们掌握了创建数据库以及对数据库的操作的基础知识。
幸老师的教学耐心细致,课堂上我们有不理解的地方老师都反复讲解,使我们的基础知识掌握的比较牢固。
数据库这门课涉及到以前的知识不多,是一门从头学起的课程,即使基础不是很好,只要认真听讲、复习功课,还是一门比较容易掌握的课。
通过学习,我对数据库没有了神秘感,简单的说下我对数据库的理解吧。
我觉得它就是创建一些表格,然后再用一些语句根据他们之间的关系,把它们组合在一起。
最基本的就是子查询了。
我的子查询经验就是先写出select _ 我们要找什么,然后写条件,我们要找的东西有什么条件,然后在写条件,我们的条件涉及那些表,那些字段,再在这些字段中通过我们学过的简单select语句选出来,有时候还要用到几层子查询,不过无所谓,只要思路是清晰的就没什么问题了。
接下来,关联查询之类的,学起来也是不难的,但有一点必须注意,那就是上课必须跟着老师的进度走,一定要注意听讲,勤做笔记.这样,你学起来就会得心应手,没什么困难。
总之,这是一门很值得学的课程,自己学过获益匪浅,就算自己将来不从事这个行业,但是至少对数据不再陌生,甚至还略知一二。
呵呵谢谢老师~!延伸阅读:数据库设计心得体会跟老板做了两个算是比较大的项目,数据库主体都是我设计的。
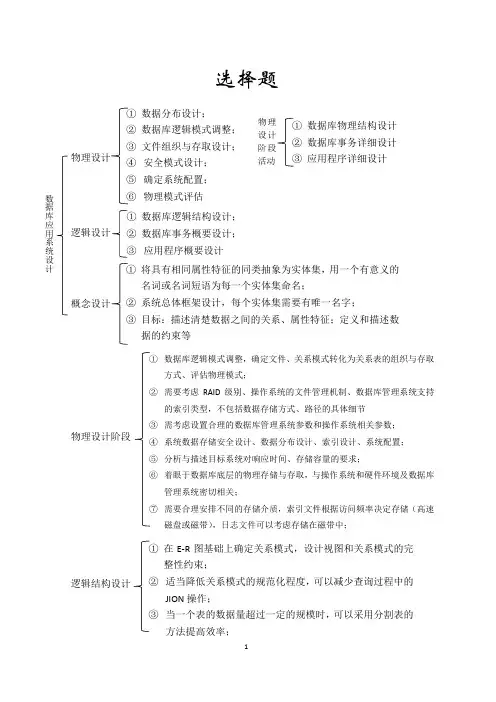
选择题物理设计逻辑设计概念设计物理设计阶段逻辑结构设计①数据库逻辑模式调整,确定文件、关系模式转化为关系表的组织与存取方式、评估物理模式;②需要考虑RAID级别、操作系统的文件管理机制、数据库管理系统支持的索引类型,不包括数据存储方式、路径的具体细节③需考虑设置合理的数据库管理系统参数和操作系统相关参数;④系统数据存储安全设计、数据分布设计、索引设计、系统配置;⑤分析与描述目标系统对响应时间、存储容量的要求;⑥着眼于数据库底层的物理存储与存取,与操作系统和硬件环境及数据库管理系统密切相关;⑦需要合理安排不同的存储介质,索引文件根据访问频率决定存储(高速磁盘或磁带),日志文件可以考虑存储在磁带中;①在E-R图基础上确定关系模式,设计视图和关系模式的完整性约束;②适当降低关系模式的规范化程度,可以减少查询过程中的JION操作;③当一个表的数据量超过一定的规模时,可以采用分割表的方法提高效率;数据库应用系统设计①数据分布设计;②数据库逻辑模式调整;③文件组织与存取设计;④安全模式设计;⑤确定系统配置;⑥物理模式评估①数据库逻辑结构设计;②数据库事务概要设计;③应用程序概要设计①将具有相同属性特征的同类抽象为实体集,用一个有意义的名词或名词短语为每一个实体集命名;②系统总体框架设计,每个实体集需要有唯一名字;③目标:描述清楚数据之间的关系、属性特征;定义和描述数据的约束等①数据库物理结构设计②数据库事务详细设计③应用程序详细设计物理设计阶段活动概念结构设计视图(外模式实现的方式之一)将查询命令和结果用虚拟表(临时表)保存起来:①提供安全性,表结构不允许修改;②提高数据处理效率数据库性能优化数据库性能优化① 增加派生性冗余列增加负担,但减少查询时JOIN 操作;根据业务需要调整相关查询或视图 ② 反规范化(适当降低关系模式规范化程度),可以减少查询过程中的JION 操作;处理后的数据表不一定满足第三范式要求, ③ 当一个表的数据量超过一定的规模时,可以采用分割表的方法提高效率; ④ 修改频繁使用的SQL 语句,提高其性能,可能会大幅度降低数据库的CPU 使用率 ⑤ 现阶段性能优化一般以软件为主要调优手段; ⑥ 服务器磁盘IO 出现写瓶颈时,可以考虑使用高速磁盘存储常用数据,低速磁盘存储不常用数据 ⑦ 根据应用系统运行情况完善应用功能,提高人员工作效率; ① 索引视图只能引用同一数据库中的基表,不能是其它标准视图; 视图返回的结果集的格式与基本表相同,所以可以在视图上再定义视图。

SQLServer物化视图学习笔记⼀、基本知识索引视图实际上是⼀种将⼀组唯⼀值“物化”为群集索引形式的视图(⽩话是,给视图中的唯⼀值列加聚集索引,然后数据会存储在硬盘中),提⾼查询速度。
通过使⽤来⾃第⼀个索引的聚集键作为参考点,SQL Server还能在视图上建⽴额外的索引。
其限制如下:1. 如果视图引⽤了任何⽤户⾃定义函数,那么这些函数也必须是模式绑定的;2. 视图不可以引⽤任何其他的视图-只能引⽤表和UDF;3. 在视图中引⽤的所有表和UDF必须采⽤两部分的命名约定(例如:dbo..Customers),并且也必须具有和视图相同的所有者;4. 视图和视图引⽤的所有对象必须在相同的数据库中;5. 在创建视图和所有底层表时,必须打开ANSI_NULLS以及QUOTED_IDENTIFIER选项;6. 视图引⽤的任何函数必须是确定的;7、必须要加上WITH SCHEMABINDING, 就是绑定到架构. 8、创建完视图后, 必须紧跟着创建⼀个CLUSTERED聚集唯⼀索引,⽽且必须在第⼀列(第⼀列是唯⼀值,类似于主键那样). 9、只⽀持两部分命名的表或UDF, 如 dbo.SalesOrder.10. 涉及到多个表连接时, 不⽀持left join 或right join的写法, 只能⽤from...where的⽅式或inner join的⽅式连接. (这⼀点有时很要命只能⽤inner join太蛋疼)11. 不⽀持table.*这种懒省事的⽅式, 得⼀个⼀个把想要的列写清楚.--创建模式绑定视图CREATE VIEW PersonAge_vwWITH SCHEMABINDINGASSELECT Age,COUNT_BIG(*) AS CountAge FROM dbo.PersonTenMillionGROUP BY Age--为视图创建索引CREATE UNIQUE CLUSTERED INDEX ivPersonAgeON PersonAge_vw(Age)SQL Server中的索引视图也具有查询重写的功能, 所谓的查询重写,就是如果符合条件的数据在索引视图上,并且查询列都包含在在索引视图上,此时可以直接通过查询索引视图来替代基于原始表的查询。

前言:最近看了看自己的这个简单的文章感觉不错,有机会一定将这个文档更新,分享给所有人们,祝大家学有所成。
本人最近研究mysql,有机会和大家分享mysql笔记^_^文档书写时间:2009年Sql server基础1 Transact-SQL 语言SQL 语言是一种介于关系代数与关系演算之间的语言其功能包括查询操纵定义和控制4 个方面是一个通用的功能极强的关系数据库语言SQL 语言的组成:数据定义语言DDL Data Definition Languagecreate table 创建一个数据库表drop table 从数据库中删除表alter table 修改数据库表结构create view 创建一个视图drop view 从数据库中删除视图create index 为数据库表创建一个索引drop index 从数据库中删除索引create procedure 创建一个存储过程drop procedure 从数据库中删除存储过程...数据操纵语言DML Data Manipulation Languageselect 从数据库表中检索数据行和列insert 向数据库表添加新数据行delete 从数据库表中删除数据行update 更新数据库表中的数据数据控制语言DCL Data Control Languagegrant 授予用户访问权限deny 拒绝用户访问revoke 解除用户访问权限2 条件表达式和逻辑运算符SQL Server提供的算术运算符运算符功能+ 完成两个数值型数据的相加操作/两个字符型数据的字符串串联操作- 完成两个数值型数据的相减操作* 完成两个数值型数据的相乘操作/ 完成两个数值型数据的相除操作% 完成两个数值型数据的模运算SQL Server提供的逻辑运算符运算符功能AND 二元运算,当参与运算的子表达式全部返回TRUE时,整个表达式的最终结果为TRUEOR 二元运算,当参与运算的子表达式中有一个返回为TRUE时,整个表达式返回TRUENOT 对参与运行的表达式结果取反IN 如果操作数与表达式列表中的任何一项匹配,则返回TRUE BETWEEN 如果操作数位于某一指定范围,则返回TRUEEXISTS 如果表达式的执行结果不为空,则返回TRUEANY 对OR操作符的扩展,将二元运算推广为多元运算ALL 对AND运算符的扩展,将二元运算推广为多元运算SOME 如果在一系列比较中,有某些子表达式的值为TRUE,那么整个表达式返回TRUELIKE 如果操作数与一种模式相匹配,那么就为 TRUE比较运算符运算符功能!= 不等于,等同于<>!< 不小于,等同于>=!> 不大于,等同于<=注:通配符:'_' % []3 T-SQL基础操作:Insert:语法:insert into table_name(col_name1...) values (value1...)通过insert select语句将现有表中的数据添加到新表中例如:Insert into tongxulu (姓名,地址,电子邮件)Select SName,SAddress,SEmailFrom student通过select into 语句将现有的表中的数据添加到新表中Select student.SName,student.SAddressInto tongxueluFrom student通过union关键字合并数据进行插入Union:用于将两个不同的数据或查询结果组合成新的结果集例如:Insert student(sname,sgread)Select '张三',1 unionSelect '李四',2 unionSelect '王五',3Update:语法:update <表名> set <列名=更新值> [where <更新条件>]Delete:语法:delete from <表名> [where <删除条件>]Truncate table:语法:Truncate table <表名>数据查询1 使用select查询语法:select <列名>From <表名>[where <条件查询>][order by <排序的列名> [desc 或 asc]]A 查询数据和列B 条件查询C 使用别名D 查询空行(is null)E 查询中使用常量F 查询使用的行数(top num)2 查询排序:使用。

SQL Server 2008中的数据类型总结SQL Server表中的每一个字段都只能包含一个预先指定的特定数据类型,例如字符或数字。
这个声明叫做数据类型。
在这篇文章里,我们将比较和对照SQL Server 2008的各种数据类型。
此外,我们还将展示各种特定环境下哪种数据类型是最好的解决方法。
在SQL Server 2008中有超过35种的不同数据类型。
分类Microsoft将各种数据类型分为以下7种大的分类:精确数字、大约数字、日期和时间、字符串、Unicode字符串、二进制字符串和其它数据类型。
数字有两种数字分类:精确数字和大约数字。
精确数字包括Real和Float类型。
在一般情况下,当需要科学符号时使用精确数字。
科学符号是一种使用10的幂数来描述非常大或非常小的数字的方法(也称作指数符号)。
精确数字包括Decimals(小数)、Integers(整数)和Money amounts(货币值)。
一个Integer是一个没有小数或分数的计算数值。
所有的负数、正数和零都是整数。
SQL Server将整数分为四个部分:BigInt:从-9,223,372,036,854,775,808到9,223,372,036,854,775,807Int:从-2,147,483,648到2,147,483,648SmallInt:从-32,768到32,767TinyInt:从0到255正确地设置大小为Int类型而不是将所有都设置为BigInt是有两个主要的原因的。
首先是物理磁盘空间。
对于BigInt来说每条记录占据8个字节,而Int只使用两个字节。
另一个原因是确保你的应用程序只接收到它所预期的数据大小,从而避免了出现缓冲溢出的现象。
具有小数的精确数字包括Decimal、Numeric、Money和SmallMoney 数据类型。
Decimal和Numeric类型功能上是一样的。
就是说,它们的使用、计算和行为都是一样的,唯一的不同就是在数学定义上而不是SQL Server使用它们的方法上。

一、简介:a)BI项目的流程i.业务探索:面向业务ii.信息调研:面向数据iii.逻辑数据建模iv.设计ETL架构v.设计维度Cubevi.设计展现方式二、数据仓库a)构成:i.维度表:实体1.合并来源于不同数据库或业务系统的同一类实体a)去掉冗余的信息b)保留原有键值,但需要新生成新的Key做为主键,用于引用。
c)让用户协助解决数据的冲突。
d)去掉一些对分析无作用的属性2.时间作为独立的实体,事先统计好年,月,日,财年等,如要统计小时,可将小时,放到事实表中。
3.存储渐变的数据。
(如部门的变更)a)在事实表中存储b)在维度表中增加行:员工key 员工ID 部门,姓名c)维度表中个别重要属性变动,可在事实表中存储。
d)维度罗多的属性变动,在维度表中新增记录存储。
ii.事实表:事件1.维度表的外键及度量值来组成2.度量值:解释事实,提供分组汇总的依据a)一定是数值,用于统计和汇总的,表达业务状况的一种值3.事先统计好的度量值:利润,成本,运费,税,管理支行等。
4.每个主题分一个事实表:可考虑在做维度属性不同时,分多张维度表。
三、分析服务a)建立数据源i.使用服务账号,代表:启动分析服务的账号。
去访问分析服务。
b)建立数据视图i.数据源视图中可以用CTRL+轮子放大、缩小,事实指向维度。
ii.自我引用关系,是上级拉到Key上。
iii.友好名称:iv.创建命名计算:字段,计算字段v.创建命名查询:相当于视图,合并结果集c)建立维度i.分析数据视角ii.数据来源于DW中的维度表iii.键列:关连到事实表的列iv.名称列:显示实体名称的列v.选择一些分组的属性列:常用的统计列(可用属性)vi.可形成特有的层次结构的vii.维度的类型:1.星形维度:由一张维度表来形成的维度2.雪花维度:由多张维度表来形成的维度叫雪花维度。
更规范,减少冗余。
3.时间维度:由时间维度表来形成的4.父子维度:有自我引用关系的维度viii.建好维度后,可以从右边的视国中再拉过来。

SQL Server学习资料⏹表的管理---表名和列的命名⏹表的管理---支持的数据类型⏹表的管理----修改数据⏹表的管理---删除数据删除全部数据Delete from 表名;删除指定数据Delete from 表名where 字段名=‘值’and 字段名=‘值’建表:表的基本查询----简单的查询语句使用where子句:或者写成:如何使用like操作符(模糊查询):在where条件中使用in:使用is null的操作符:使用逻辑操作符号:使用order by子句:Select ename,(sal+isnull(comm.,0))*13 as 年薪from emp order by 年薪⏹表的复杂查询数据分组-max,min,avg,sum,count:Group by和having子句:对数据分组的总结:1)分组函数只能出现在选择列表,having,order by,子句中;2)如果在select语句中同时包含group by,having,order by,那么他们的顺序是group by,having,order by;3)在选择列中如果有列,表达式和分组函数,那么这些列和表达式必须有一个出现在group by子句中,否则就会报错;如:select depot,avg(sal),max(sal) from emp group by deptno having avg(sal)<2000;这里deptno就一定要出现在group by中;⏹表的复杂查询----多表查询多表查询是指基于两个或两个以上表或是视图的查询或者:⏹表的复杂查询----子查询1)(子查询)是指嵌入在其它sql语句中的select语句,也叫嵌套查询。
2)(单行子查询)是指只返回一行数据的子查询语句3)(多行子查询)指返回多行数据的子查询⏹在from子句中使用子查询请思考:如何显示高于部门平均工资的员工的姓名,薪水,她部门的平均工资和部门编号分析:1,首先要知道各个部门的平均工资Select avg(sal),dept from emp group by deptno2,把上面的查询结果,当做一个临时表对待这里需要说明的:当在from子句中使用子查询时,该子查询会被作为一个临时表对待,当在from子句中使用子查询时,必须给子查询指定别名。

1.数据库管理系统功能1数据定义功能(2)数据操纵功能3)数据库运行时的管理功能(4)数据库的维护功能2..SQL语言(1)数据定义语言DDL(2)数据操纵语言DML(3)数据控制语言3.数据库的操作方式(1)交互方式(2)程序嵌入方式4..数据库的连接方式1.ODBC数据库接口2.OLE DB数据库接口3.ADO数据库接口4.数据库接口5.JDBC数据库接口6.数据库连接池技术5.客户机/服务器模式浏览器/服务器模式SQL Server是一个基于客户机/服务器(C/S)模式的关系数据库管理系统,6.服务器组件1Database Engine 2.Analysis Services 3.Integration Services 4 Reporting Services7.SQL Server 2008的数据库对象表视图(view)、索引(index)、存储过程(stored procedure)、触发器(trigger)和约束8.对象名完全限定名是对象的全名,在SQL Server 2008上创建的每个对象都有唯一的完全限定名。
包括四个部分:服务器名、数据库名、数据库架构名和对象名对象全名的4个部分中的前3个部分均可被省略,当省略中间的部分时,圆点符“.”不可省略9.系统数据库1)master数据库包含了SQL Server 2008诸如登录账号、系统配置、数据库位置及数据库错误信息等,用于控制用户数据库和SQL Server的运行。
(2)model数据库为新创建的数据库提供模板。
(3)msdb数据库为“SQL Server代理”调度信息和作业记录提供存储空间。
(4)tempdb数据库为临时表和临时存储过程提供存储空间,所有与系统连接的用户的临时表和临时存储过程都存储于该数据库中。
10.数据库文件SQL Server 2008所使用的文件包括三类文件:①主数据文件。
.mdf。
②辅助数据文件。
Ndf ③日志文件.ldf11.文件组①主文件组。
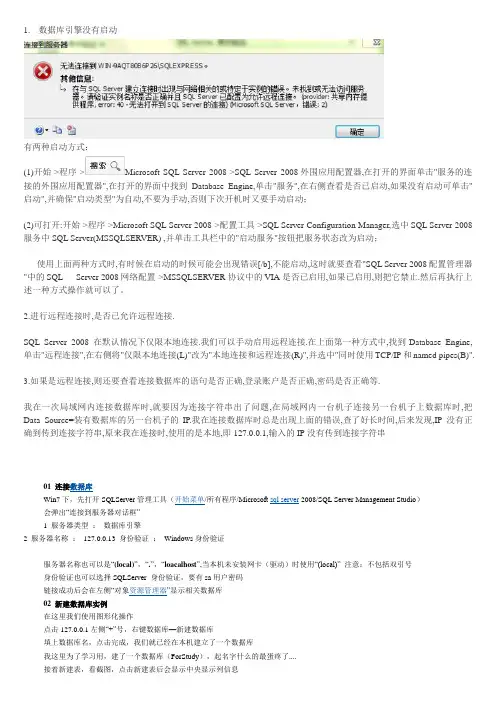
1.数据库引擎没有启动有两种启动方式:(1)开始->程序->Microsoft SQL Server 2008->SQL Server 2008外围应用配置器,在打开的界面单击"服务的连接的外围应用配置器",在打开的界面中找到Database Engine,单击"服务",在右侧查看是否已启动,如果没有启动可单击"启动",并确保"启动类型"为自动,不要为手动,否则下次开机时又要手动启动;(2)可打开:开始->程序->Microsoft SQL Server 2008->配置工具->SQL Server Configuration Manager,选中SQL Server 2008服务中SQL Server(MSSQLSERVER) ,并单击工具栏中的"启动服务"按钮把服务状态改为启动;使用上面两种方式时,有时候在启动的时候可能会出现错误[/b],不能启动,这时就要查看"SQL Server 2008配置管理器"中的SQL Server 2008网络配置->MSSQLSERVER协议中的VIA是否已启用,如果已启用,则把它禁止.然后再执行上述一种方式操作就可以了。
2.进行远程连接时,是否已允许远程连接.SQL Server 2008 在默认情况下仅限本地连接.我们可以手动启用远程连接.在上面第一种方式中,找到Database Engine,单击"远程连接",在右侧将"仅限本地连接(L)"改为"本地连接和远程连接(R)",并选中"同时使用TCP/IP和named pipes(B)".3.如果是远程连接,则还要查看连接数据库的语句是否正确,登录账户是否正确,密码是否正确等.我在一次局域网内连接数据库时,就要因为连接字符串出了问题,在局域网内一台机子连接另一台机子上数据库时,把Data Source=装有数据库的另一台机子的IP.我在连接数据库时总是出现上面的错误,查了好长时间,后来发现,IP没有正确到传到连接字符串,原来我在连接时,使用的是本地,即127.0.0.1,输入的IP没有传到连接字符串01 连接数据库Win7下,先打开SQLServer管理工具(开始菜单/所有程序/Microsoft sql server 2008/SQL Server Management Studio)会弹出“连接到服务器对话框”1 服务器类型:数据库引擎2 服务器名称:127.0.0.13 身份验证:Windows身份验证服务器名称也可以是“(local)”,“.”,“loacalhost”,当本机未安装网卡(驱动)时使用“(local)” 注意:不包括双引号身份验证也可以选择SQLServer 身份验证,要有sa用户密码链接成功后会在左侧“对象资源管理器”显示相关数据库02 新建数据库实例在这里我们使用图形化操作点击127.0.0.1左侧“+”号,右键数据库—新建数据库填上数据库名,点击完成,我们就已经在本机建立了一个数据库我这里为了学习用,建了一个数据库(ForStudy),起名字什么的最蛋疼了....接着新建表,看截图,点击新建表后会显示中央显示列信息我们可以在右侧“属性”框把名称改成自己的表名(默认Table_1)设置好列信息后,点击左侧工具栏中的钥匙图标可以在选中的列设置主键,如下Ctrl+S 保存即可在“对象资源管理器”,依次点击打开我们刚刚创建的表(我的是dbo.student)右键,编辑前200行,就可以向刚建的表添加信息了此时数据库中已经建好表,我们也可以对表进行增删改查各种操作在这里多说两句,表的设计很重要,在程序开发的工程中一定要先把数据库设计好否则,等到写代码的途中需要修改数据库的时候你会发现这是有多么的操蛋...03 使用查询语句操作表点击“新建查询”,在中央文本框输入我们查询语句,点击执行即可04 分离数据库文件分离数据库文件,以便在不同的主机中使用该数据库关闭之前的查询语句文本框,在“ForStudy”右键-任务-分离,显示分离对话框点击“确定”,这时我们已经把数据库文件从本机分离出去05 导入数据库能分离必然可以重新导入右键对象资源管理器里的“数据库”,点击“附加”在弹出的对话框中选择“添加”按钮,选择要添加的数据库文件(.mdf后缀的)比如我的是ForStudy.mdf,然后点击确定即可小技巧:使用sqlcmd修改sa密码:CMD下输入(原密码为123456新密码I2e456)sqlcmd 实用工具使用sqlcmd 实用工具,可以在命令提示符处、在SQLCMD 模式下的“查询编辑器”中、在Windows 脚本文件中或者在SQL Server 代理作业的操作系统(Cmd.exe) 作业步骤中输入Transact-SQL 语句、系统过程和脚本文件。

SQL2008知识点总结一、数据库的基本操作1. 创建数据库在SQL Server 2008中,可以使用CREATE DATABASE语句来创建一个新的数据库。
这个语句的基本格式如下所示:```sqlCREATE DATABASE database_name;```其中,database_name是要创建的数据库的名称。
2. 删除数据库如果要删除一个数据库,可以使用DROP DATABASE语句,其基本格式如下所示:```sqlDROP DATABASE database_name;```需要注意的是,删除一个数据库将会永久删除所有与该数据库相关联的数据和对象,所以在执行这个语句之前,一定要慎重考虑。
3. 备份和恢复数据库在SQL Server 2008中,可以使用备份和恢复功能来保护数据库的数据。
在执行备份操作时,可以使用BACKUP DATABASE语句,其基本格式如下所示:```sqlBACKUP DATABASE database_name TO disk=’backup_file_path’;```而在执行恢复操作时,可以使用RESTORE DATABASE语句,其基本格式如下所示:```sqlRESTORE DATABASE database_name FROM disk=’backup_file_path’;```在这两个语句中,backup_file_path是指定备份文件的路径。
4. 修改数据库如果要修改数据库的一些属性,可以使用ALTER DATABASE语句,其基本格式如下所示:```sqlALTER DATABASE database_name SET new_property;```其中,new_property是要修改的属性值。
5. 查看数据库在SQL Server 2008中,可以使用系统视图sys.databases来查看当前服务器中存在的所有数据库。
这个视图中包含了每个数据库的详细信息,如数据库的名称、创建日期、状态等。
SQLServer学习笔记sql的范围内查找,sql数据类型,字符串处理函数sql的范围内查找(1)between.....and⽤法通常情况下我们查找⼀个在某固定区域内的所有记录,可以采⽤>=,<=来写sql语句,例如:查找订单价格在1000到2000之间的所有记录,可以这样写:1 select * from sales.ordervalues2 where val>=1000 and val<=2000查询结果:此处的sales.ordervalues来⾃于定义的视图,关于视图后续会讲到。
如果采⽤between.....and.....则可以同样达到效果。
1 select * from sales.ordervalues2 where val between 1000 and 2000注意⼀点:between....and.....是包含边界的,即此处包含1000和2000这个边界值。
(2)in ⽤法假如要查找1号顾客,2号顾客,9号顾客订单信息,⼀般情况下,我们会这样写:1 select * from sales.ordervalues2 where custid=1 or custid=2 or custid=9结果为:采⽤in,则减少了写法的繁杂,可以这样如下写法也能达到要求。
1 select * from sales.ordervalues2 where custid in(1,2,9)(3)like⽤法,⽤来匹配字符或字符串。
假如要查找雇员表Hr.employees⾥⾯lastname⾥包含a的字符。
可以这样写:1 select * from Hr.employees2 where lastname like '%a%'显⽰结果为:其中%表⽰通配符,即可以为任意字符。
sql数据类型sql包含多种数据类型,满⾜多种开发需求。
常见的数据类型包括:(1)⼆进制数据类型。
SQL Server 2008 总结-----第八章-----8.l、数据库的安全概述对于任何数据库使用者而言,首先考虑的问题是数据库安全。
所谓的安全,主要是指根据用户的权限不同,来决定用户是否可以登录到当前的SQL Server数据库,以及可以对数据库实施哪些操作。
8.1.1、服务器认证SQL Server支持的服务器认证模式共有3类,分别是:Windows认证模式、SQL Server认证模式和混合模式。
8.1.2、数据库认证当前用户通过服务器认证后,按常理来说是可以对SQL Server对内部数据库进行操作访问了,当由于SQL Server是服务器/客户型数据库服务平台,访问SQL Server数据库的不可能只有一个用户。
所以在访问SQL Server之前,还要进行数据库认证。
数据库认证就要有数据库用户及其权限。
A.数据库用户:SQL Server是以数据库用户为依据来决定来访问用户可以操作哪些数据库的。
用来访问的用户是唯一的。
B.权限:是指数据库用户可以对哪些数据库对象执行哪些操作的规则。
在这里权限共有3种,分别是:对象权限、语句权限和暗示性权限。
(1)、对象权限:处理数据或执行数据库查询操作时使用的权限。
如Select、Insert、Deletet和Update。
(2)、语句权限:用户在创建数据库或数据库对象是要使用的权限。
如Create、DataBase、Create Table等。
(3)、暗示性权限:用来控制那些只能由预定义系统角色的成员或数据库对象组才能执行的操作。
如sysadmin固定服务器角色成员有在SQL Server安装中进行操作或查看数据的全部权限。
8.2、服务器身份验证模式的更改在SQL Server 2008中,更改服务器身份验证模式的方法共有两种,一种是利用SQL Server Management Sutdio直接更改,另一种是利用T-SQL代码更改。
8.3、登录账号的基本操作在SQL Server 2008中,可以利用SQL Server Management Sutdio直接操作登录账号,也可以利用T-SQL 操作登录账号。
第一章:数据库:存放数据的仓库,只不过这些数据具有一定的关联!数据库管理系统(DBMS):管理数据库的系统,按照一定数据模型组织数据,提供以下功能:1.数据定义功能、数据操作功能、数据的完整性检查功能、数据的安全保护功能2.数据的并发控制功能、数据库系统的故障恢复功能、在网络环境下访问数据库的功能3.方便、有效地存取数据库信息的接口和工具数据模型:层次模型(树状层次模型),网状模型(多节点相互关联的模型),关系模型(二维表格(关系表))关系型数据库的标准语言:是SQL(Structured Query Language, 结构化查询语言)数据库设计的概念结构设计:实体:每一类数据对象的个体!实体集:每一类对象个体的集合,且实体集中得实体是可区分的!实体集之间的关系:一对一的联系(1:1)、一对多的联系(1:N)、多对多的联系(M:N)E-R模型:数据库设计的逻辑结构设计:(即将E-R图到关系模型的转换)一对一的联系(1:1)、一对多的联系(1:N)的转换:公司表(公司代码,公司名,地址)厂家表(厂家代码,厂家名,地址)多对多的联系(M:N):销售表(员工号,商品号,单价,数量)Sql-Server的安装:CPU奔腾3以上,内存512以上,硬盘1.7G以上必须安装:.net framework 3.5第二章表:数据库对象,用来存储和操作数据的一种逻辑结构,由行与列组成!视图:从一个表或多个表中引出的表!索引:一种不用扫描整个数据库就可以对表中的数据实行快速访问的途径,是对表中的一列或多列数据进行排序的一种结构!约束:保证数据的一致性和完整性。
主键约束当前表记录的唯一性,外键约束当前表记录与其他表的关系。
存储过程:一组为了完成特定功能的SQL语句集合,可接收,输出参数,返回单个或多个结果以及返回值的功能!触发器:与表紧密相联,可以实现更加复杂的数据操作,可有效保证数据库系统的完整性的一致性,可对多个表进行操作!默认值:在用户没有给出具体数据时,系统自动生成的值!规则:用来限制字段的数据范围!数据库的创建:(数据库的主文件.mdf、数据库的辅文件.ndf、日志文件.ldf)create database CPXSON(NAME='销售数据库CPXS',FILENAME='C: \销售数据库CPXS.mdf',SIZE=5MB,MAXSIZE=50MB,FILEGROWTH=10%)LOG ON(NAME='CPXS_log', FILENAME='C: \销售数据库CPXS.ndf', SIZE=2MB, MAXSIZE=5MB, FILEGROWTH=1MB)修改数据库:ALTER database cpxs Modify file(Name=数据库CPXS, Maxsize=100mb, Filegrowth=5mb)删除数据库:Drop database cpxsGo创建数据库快照:Create database pxscj 01On(Name =pxscj,filename=’d:\数据库’;filename=’D:\abc.mdf’) As snapshot of pxscjGo第三章常用的数据类型:整形:int高精度类型:decimal(8,3)或者numeric(8,3)货币型:money,smallmoney字符型:(ASCII):Char(10)不满足长度,补充空格,varchar(10)Unicode:nchar(10), 不满足长度,补充空格,nvarchar(10)时间类型:datetime(时间类型)图片类型:image 二进制类型:binary创建表:use CPXSgocreate table 产品表(产品编号char(20) NOT NULL PRIMARY KEY , 产品名称char(20) NULL,价格float NULL , 库存量int NULL)表的删除:Use pxscjGoDrop table 产品表修改表(添加列):Alter table xsbAdd 奖金tinyint nullGo修改表(删除列,必须删除列的索引与约束)Alter table xsbDrop column 奖金Go删除表(删除表之前必须删除表中相关列的索引与约束):Use pxscjGoDrop table xsb插入数据:Insert into xsb (学号,姓名) values(‘010001’,’张三’)将一个表中的数据插入到另一个表中:Insert top(5) into xsbSelect 学号,姓名,专业from xsb where 专业=‘计算机’删除符合条件的记录(数据):Delete from xsb where name=’张三’GoDelete from xsb where 备注is nullGo删除表中的所有数据(两种方法):Truncate 比Delete速度快,切实用的系统和事务日志资源少,Delete每次删除一行,事务日志就记录一次,Truncate则不同,且删除包含外键约束的表数据是,只能用Delete! Delete xsbTruncate table xsb修改表记录(行数据):Update xsb set 总学分=总学分+10GoUpdate xsbset 专业=‘软工’,备注=‘11111’ ,学号=‘000’ where name=‘张三’go第四章DISTINCT关键字:在查询中用于去除结果集中去除重复的值,在查询的选择列表中它只能使用一次如果选中了多个列,DISTINCT会去除列值相同的所有行select distinct employeeid from employeesselect count (distinct 学号) from cjbdistinct在内部排序行以消除重复的值,如果必须依赖排序的行,则要使用order byselect distinct employeeid from employees order by employeeid asc|desc (升序,降序),默认为升序子查询:1.in操作符:确定指定列的值是否匹配一个值列表,这个列表的数据类型必须与要匹配的列兼容可以由逗号分隔开的字面量或子查询的结果集组成,但不能由这两者组成select * from employees where employeeid in(select employeeid from employees3) order by employeeid2.not in表示选择不匹配选择列表中行的值select * from employees where employeeid not in('123','456') order by employeeid3.使用函数和in谓词substring函数返回字符串的一部分,此方法可代替link谓词select * from employeeid where substring(name,1,1) in ('胡','王') //提取name列的第一个字符,是否含有胡和王的第一个参数:数据列第二个参数:提取子串的起始位置第三个参数:提取的字符数4.group by 子句用于把相同列值的行组合在一起,查询职员表的同性别的工作年限之和selectSex '性别' ,sum(WorkYear) '工作年限'from "employees"group bysex5.合计函数(max最大值,min最小值,avg平均数)select employeeid "职员ID",min(workyear) "最少工作年限",max(workyear) "最大工作年限",avg(workyear) "总共工作年限"from employeesgroup by employeeidorder by employeeid6.日期函数selectCURRENT_TIMESTAMP '完整的时间值',getdate() '完整的时间值',year(getdate()) '年份',datepart(year,getdate()) '年份',datepart(month,getdate()) '月份',datepart(day,getdate()) '日',datepart(hour,getdate()) '时间',year(getdate())- year(birthday) ‘获取年龄’from employees where EmployeeID ='102208'7.case表达式分为简单case表达式和搜索case表达式允许根据列值显示另一个值SELECT DISTINCT YEAR(birthday) '年',case year(birthday)when 1978 thenstr(year(birthday))elsecase year(birthday)when 1978 then '今年'else'非今年'endend '今年'from employees8.连接从两个表中获取数据,根据连接规范匹配他们的行,最终生成一个表每个连接都是二元操作1.内连接只有所连接的表行匹配时,才能使用内连接,连接规范中可以使用任意关系运算符,使用等号运算符的连接称为自然连接inner join 是一个二元操作,on关键字表示连接规范的开始,连接规范可以包含能用于where子句的任何条件select <select list>fromleft-table inner join right-tableon<join specification>多表连接时,指定列来自那个表,在列名前加上表名和一个句号(.)即为去除模糊查询,让数据库知道使用那一列,最后所有列名使用表前缀selectEmployees.EmployeeID,,Employees.AddressfromEmployees inner join Salaryon Employees.EmployeeID=Salary.EmployeeIdselecte.EmployeeID,,e.AddressfromEmployees e inner join Salary son e.EmployeeID=s.EmployeeId为每个表提供一个相关名称,这简化了表的引用,用于引用列,列的别名用于标记列selecte.EmployeeID ID, 姓名,e.Address 地址s.Income-s.outcomefromEmployees e inner join Salary son e.EmployeeID=s.EmployeeId等同于selecte.EmployeeID ID, 姓名,e.Address 地址,s.Income-s.outcome 收入fromEmployees e,Salary swhere e.EmployeeID=s.EmployeeId连接两个以上的表,需要多个连接运算符,每个连接都要带有自己的on子句三个表的内连接,多表连接时,所查询的列,只要属于所查询的表,就可以查询selecte.EmployeeID ID, 姓名,e.Address 地址,s.Income-s.outcome 收入,d.DepartmentName 工作部门from Employees einner join Salary son e.EmployeeID=s.EmployeeIdinner join Departments don d.DepartmentID=e.DepartmentID2.外连接(outer),outer关键字可选,写不写都无所谓,至少返回一个连接表中的所有行,即使一个表中的行不匹配另一个表中的行也是如此左,右表示连接操作左边和右边的操作数,颠倒操作数,就可以把左连接置换为右连接同一个查询中使用左外连接或者右外连接均可,但不要都使用,查询优化器不会考虑这一点,因为连接总是沿着同一方向进行,复杂的查询较容易编写1.左外连接(left outer)会提取左表中的所有行,而不管他们是否匹配右表中的行selecte.EmployeeID id, 姓名,s.InCome-s.OutCome 收入from Employees eleft outer join Salary son e.EmployeeID=s.EmployeeIdorder by 2,12.右外连接(right outer)会提取右表中的所有行,而不管他们是否匹配左表中的行selecte.EmployeeID id, 姓名,s.InCome-s.OutCome 收入from Employees eright outer join Salary son e.EmployeeID=s.EmployeeIdorder by 2,13.全连接(full outer)返回两个表中的所有行,即使他们没有相关的行!3.其他连接(union outer)创建一个包含两个表中得所有的行的表,且这两个表必须有相同的列,对应列的数据类型必须兼容select * from table union allselect * from table2。
SQLServer2008新特性总结复习(⼀)1. TVP,表变量,临时表,CTE 的区别TVP和临时表都是可以索引的,总是存在tempdb中,会增加系统数据库开销,⽽表变量和CTE只有在内存溢出时才会被写⼊tempdb中。
对于数据量⼤,并且反复使⽤,反复进⾏查询关联的,建议使⽤临时表或TVP,数据量⼩,使⽤表变量或CTE⽐较合适2. sql_variant 万能类型可以存放所有数据类型,相当于C#中的object数据类型3. datetime, datetime2, datetimeoffsetdatetime 时间有效期较⼩,在1753-1-1 之前就不能使⽤了,精度为毫秒级别,⽽datetime2 数据范围相当于C#中的datetime ,精度达到了秒后⾯⼩数点后7位,datetimeoffset则是考虑是时区的⽇期类型4. MERGE的⽤法语法很简单就不说了,主要是处理两张表某些字段对⽐后的操作,需注意 when not matched (by target) 与 when not matched by source的区别,前者是是针对对⽐后⽬标表不存在的记录,可以选择insert操作,⽽后者则是针对对⽐后⽬标表多出来的记录,可以选择delete或update操作5. rowversion 类型代替以前的timestamp,时间戳,8字节⼆进制值,常⽤来进⾏解决并发操作的问题6. Sysdatetime()返回datetime2类型,精度⽐datetime⾼7. with cube , with rollup , grouping sets 运算符都可与group by 后连⽤,with cube 表⽰汇总所有级别的组合,with rollup 则是按级别汇总,从下⾯的代码可以详细看出区别。
注意,汇总⾏,null可以看成所有值⽽grouping sets运算符,则仅返回每个分组顶级汇总⾏,在查询汇总⾏中可使⽤grouping(字段名) = 1来判断,该运算符可和rollup, cube连⽤,表⽰按照grouping by sets和按照rollup/cube处理的结果集union all⽰例代码如下:复制代码代码如下:With cube, With rollup--⽰例代码declare @t table(goodsname VARCHAR(max) ,sku1name VARCHAR(max) , sku2name VARCHAR(max), qty INT)insert @t select '凡客TX','红⾊','S',1insert @t select '凡客TX','⿊⾊','S',2insert @t select '凡客TX','⽩⾊','L',3insert @t select '京东村⼭','⽩⾊','L',4insert @t select '京东村⼭','红⾊','S',5insert @t select '京东村⼭','⿊⾊','L',6insert @t select '亚马逊拖鞋','⽩⾊','L',7insert @t select '亚马逊拖鞋','红⾊','S',8SELECT * FROM @tselect goodsname,sku1name,sku2name,sum(qty) sumqtyfrom @tgroup by goodsname,sku1name,sku2name with rollupORDER BY goodsname,sku1name,sku2nameselect goodsname,sku1name,sku2name,sum(qty) sumqtyfrom @tgroup by goodsname,sku1name,sku2name with cubeORDER BY goodsname,sku1name,sku2name-----------------------declare @t table(goodsname VARCHAR(max) ,sku1name VARCHAR(max) , sku2name VARCHAR(max), qty INT)insert @t select '凡客TX','红⾊','S',1insert @t select '凡客TX','⿊⾊','S',2insert @t select '凡客TX','⽩⾊','L',3insert @t select '京东村⼭','⽩⾊','L',4insert @t select '京东村⼭','红⾊','S',5insert @t select '京东村⼭','⿊⾊','L',6insert @t select '亚马逊拖鞋','⽩⾊','L',7insert @t select '亚马逊拖鞋','红⾊','S',8--GROUPING SETS 运算符SELECT goodsname,sku1name,sku2name, SUM(qty) FROM @t GROUP BY GROUPINGSETS(goodsname,sku1name,sku2name)SELECT goodsname, sku1name, sku2name ,SUM(qty) FROM @tGROUP BY GROUPING SETS(goodsname), ROLLUP(sku1name,sku2name)ORDER BY goodsname,sku1name,sku2nameSELECT goodsname, sku1name, sku2name ,SUM(qty) FROM @tGROUP BY ROLLUP(goodsname,sku1name,sku2name)ORDER BY goodsname,sku1name,sku2nameSELECT CASE WHEN GROUPING(goodsname) = 1 THEN '[ALL]' ELSE goodsname END goodsname,CASE WHEN GROUPING(sku1name) = 1 THEN '[ALL]' ELSE sku1name END sku1name,CASE WHEN GROUPING(sku2name) = 1 THEN '[ALL]' ELSE sku2name END sku2name ,SUM(qty) FROM @t GROUP BY GROUPING SETS(goodsname), ROLLUP(sku1name,sku2name)ORDER BY goodsname,sku1name,sku2name8. ⼀些快捷的语法例如 Declare @id int = 0虽然有时很快捷,但DBA不建议这样使⽤,Declare @id = select top 1 id from 表名,建议声明和查表赋值分开9. 公⽤表达式 CTE特点:可嵌套使⽤,代替联接表中的⼦查询,结构层次更加清晰,也可⽤来递归查询,另外通过巧妙的常量列控制递归层次⽰例代码如下:复制代码代码如下:使⽤CTE--公⽤表达式CTE Common table expression--⽤CTE实现递归算法CREATE TABLE EMPLOYEETREE(EMPLOYEE INT PRIMARY KEY,employeename nvarchar(50),reportsto int)insert into EMPLOYEETREE values(1,'Richard',null)insert into EMPLOYEETREE values(2,'Stephen',1)insert into EMPLOYEETREE values(3,'Clemens',2)insert into EMPLOYEETREE values(4,'Malek',2)insert into EMPLOYEETREE values(5,'Goksin',4)insert into EMPLOYEETREE values(6,'Kimberly',1)insert into EMPLOYEETREE values(7,'Ramesh',5)------------------------确定哪些员⼯向Stephen报告的递归查询with employeeTemp as(select EMPLOYEE, employeename, reportsto from EMPLOYEETREE where EMPLOYEE = 2union allselect a.EMPLOYEE, a.employeename, a.reportsto from EMPLOYEETREE as ainner join employeeTemp as b on a.reportsto = b.EMPLOYEE)select * from employeeTemp where EMPLOYEE <> 2 --option(maxrecursion 2)--不报错设置级联关联递归with employeeTemp as(select EMPLOYEE, employeename, reportsto,0 as sublevel from EMPLOYEETREE where EMPLOYEE = 2union allselect a.EMPLOYEE, a.employeename, a.reportsto,sublevel+1 from EMPLOYEETREE as ainner join employeeTemp as b on a.reportsto = b.EMPLOYEE)select * from employeeTemp where EMPLOYEE <> 2 and sublevel <=2 --option(maxrecursion 2)10. pivot 与 unpivot前者⽤在⾏转列,注意:必须⽤聚合函数与PIVOT⼀起使⽤,计算聚会时将不考虑出现在值列中的任何空值;⼀般情况下,可以⽤列上的⼦查询来替换pivot语句,但是这样做效率不⾼后者⽤在列转⾏,注意:如果某些列中有null值,将会被过滤掉,不产⽣新⾏;语法上For前指定的新列,对应原表指定列名中的值,For后指定的新列对应原表指定列名中的标题的值两者都有的共性:语法上最后必须要有别名;IN⾥⾯指定的列类型必须是⼀致的。
SQL Server 2008学习笔记
第一章SQL Server 基础
1、利用T-SQL 语句创建数据库, 删除一个数据库, 更改数据库名称
第二章T-SQL 语句
1、SQL 2008 视频教程-数据库表常用术语
数据表常用术语:
关系:关系即二维表,每一个关系有一个关系名,就是表名。
表中的行,称之为记录
表中的列,称之为字段或属性
关联:是指不同数据库表之间的数据彼此联系的方式。
关键字:属性或属性的组合,可以用于维一标识一条记录。
外部关键字:如果表中的一个字段(即表中的列),不是本表中的关键字而是其它表的关键字,称之为外部关键字。
2、SQL 2008 视频教程-系统数据库
Master(主)
Model(模型)
Tempdb (临时数据库)
Msdb(MS 数据库)
3、T-SQL 创建数据库详解
4、T-SQL 语句3 (T-SQL 语句浏览表格(教师表))Select * from 教师表--表示浏览教师表里所有的信息*号是通配符,表示所有的意思
执行Select * from教师表结结果如下
5、用T-SQL 语句在教师表里如何增加字段,删除某个字段,更新某个字段的内容(1)用T-SQL 语句在教师表里如何增加字段
执行Select * from教师表结结果如下
(2)用T-SQL 语句在教师表里如何删除某个字段
执行Select * from教师表结结果如下
(3)用T-SQL 语句在教师表里更新某个字段的内容
执行Select * from教师表结结果如下
6、查询(重中之重)
(1) 查询要用到的三张表:(下面的所有操作都是基于这三张表)1.emp 表(员工表employee)
2.dept 表(部门表department) 3.salgrade 表(工资等级表)
(2)对以上三张表查询操作(包括计算列,distinct,between,in,top,null,order by,模糊查询,聚合函数,group by,having,链接查询)
注意distinct 的用法
例子如下图:
实例如下:
注意group by 与COMPUTE BY 的区别
GROUP BY 子句有个缺点,就是返回的结果集中只有合计数据,而没有原始的详细记录。
如果想在SQL SERVER 中完成这项工作,可以使用COMPUTE BY 子句。
(具体看下面的例子)
运行结果对比:
查询的顺序(非常重要)
习题集
第一个习题
求出每个员工的姓名部门编号薪水和薪水的等级
第二个习题
查找每个部门的编号该部门所有员工的平均工资平均工资的等级
第三个习题
查找每个部门的编号部门名称该部门所有员工的平均工资平均工资的等级
第四个习题
求出emp 表中所有领导的信息
第五个习题
求出平均薪水最高的部门的编号和部门的平均工资
第六个习题
有一个人工资最低把这个人排除掉
剩下的人中工资最低的前个人的姓名工资部门编号部门名称工资等级输出
答案及运行结果:
7. 两个表(dept 表和salgrade 表)内连接,左连接和右连接
下面只给了右连接的运行结果(其它的自己试)
8. 约束、索引和视图
约束(主键(即关键字),外键(外部关键字),唯一键,非空,check,default ,触发器)
索引
唯一的索引 (Unique Index)
在表格上面创建某一个唯一的索引。
唯一的索引意味着两个行不能拥有相同的索引值。
CREATE UNIQUE INDEX 索引名称
ON 表名称(列名称)
create unique index teacher_index on teacher (teacher_address)
--在 teacher 表中 teacher_address 字段创建了一个唯一的索引(名称为teacher_index)
视图
为什么需要视图:
注意:不能一次执行,应该创建完视图后执行以下,再执行下面的代码
9.T-SQL 编程
所以一般来说,如果含有中文字符,用nchar/nvarchar,如果纯英文和数字,用char/varchar。
注意:如果想同时显示多个变量用 select
如果想显示单个变量用 print
执行结果为:执行结果为:执行结果为:
执行结果为:
执行结果为:10. 函数
为局部变量
执行结果为:
字符串函数:
执行结果为:
日期函数:
执行结果为:
创建函数:
创建代码及结果显示如下图
再写个测试代码
执行结果:(注意 dbo. 不能省)11. 存储过程
(2)用户如何创建存储过程
执行execute newProc 这行代码的结果为:(写 exec newProc 也可以)
12. 游标(cursor)
注意:用中括号[]括起来的可以写也可以不写
13. 触发器(trigger)
触发器是一种特殊的存储过程﹐它不能被显式地调用﹐而是在往表
中插入记录﹑更新记录或者删除记录时被自动地激活。
所以触发器
可以用来实现对表实施复杂的完整性约束。
1)
After 触发器在一个Insert,Update 或Deleted 语句之后执行﹐进行约束检查等动作都在After 触发器被激活之前发生。
After 触发器只能用于表。
一个表或视图的每一个修改动作
(insert,update 和delete)都可以有一个instead of 触发
器﹐一个表的每个修改动作都可以有多个After 触发器。
如果一个Insert﹑update 或者delete 语句违反了约束﹐那幺After 触发器不会执行﹐因为对约束的检查是在After 触发器被激动之前发生的。
所以After 触发器不能超越束。
执行insert into teacher values()后的结果:
说明他是在插入一条记录之后调用这个触发器即After 触发器
2)Instead of 触发器(即替代触发器)是用于替代引起触
发器执行的T-SQL 语句。
除表之外﹐Instead of 触发器也可以用于视图﹐用来扩展视图可以支持的更新操作。
执行结果为:
14.事务
2015年11月27日
李巍。