《数据分析》实验报告三
- 格式:doc
- 大小:123.50 KB
- 文档页数:6

《数据分析》实验报告三一、实验目的本次数据分析实验旨在通过对给定数据集的深入分析,探索数据中的潜在规律和关系,以获取有价值的信息,并为决策提供支持。
具体目标包括:1、熟悉数据分析的流程和方法,包括数据收集、清理、预处理、分析和可视化。
2、运用统计学和数学知识,对数据进行描述性分析和推断性分析。
3、掌握数据挖掘技术,如分类、聚类等,发现数据中的隐藏模式。
4、培养解决实际问题的能力,通过数据分析为实际业务场景提供有效的建议和决策依据。
二、实验环境1、操作系统:Windows 102、数据分析工具:Python 38(包括 Pandas、NumPy、Matplotlib、Seaborn 等库)3、数据库管理系统:MySQL 80三、实验数据本次实验使用的数据集是一份关于某电商平台销售记录的数据集,包含了以下字段:订单号、商品名称、商品类别、销售价格、销售数量、销售日期、客户地区等。
数据量约为 10 万条。
四、实验步骤1、数据收集从给定的数据源中获取数据集,并将其导入到数据分析工具中。
2、数据清理(1)处理缺失值:检查数据集中各个字段是否存在缺失值。
对于数值型字段,使用平均值或中位数进行填充;对于字符型字段,使用最常见的值进行填充。
(2)处理重复值:删除数据集中的重复记录,以确保数据的唯一性。
(3)异常值处理:通过绘制箱线图等方法,识别数据中的异常值,并根据实际情况进行处理,如删除或修正。
3、数据预处理(1)数据标准化:对数值型字段进行标准化处理,使其具有相同的量纲,便于后续的分析和比较。
(2)特征工程:根据分析需求,对原始数据进行特征提取和构建,例如计算商品的销售额、销售均价等。
4、数据分析(1)描述性分析计算数据集中各个字段的统计指标,如均值、中位数、标准差、最小值、最大值等,以了解数据的集中趋势和离散程度。
绘制柱状图、折线图、饼图等,直观展示数据的分布情况和比例关系。
(2)推断性分析进行假设检验,例如检验不同商品类别之间的销售价格是否存在显著差异。

数据分析与挖掘实验报告一、实验背景在当今数字化的时代,数据成为了企业和组织决策的重要依据。
通过对大量数据的分析与挖掘,能够发现隐藏在数据背后的规律和趋势,为决策提供有力的支持。
本次实验旨在通过实际操作,深入了解数据分析与挖掘的流程和方法,并探索其在实际应用中的价值。
二、实验目的1、熟悉数据分析与挖掘的基本流程和常用技术。
2、掌握数据预处理、特征工程、模型建立与评估等关键环节。
3、运用数据分析与挖掘方法解决实际问题,提高数据分析能力和解决问题的能力。
三、实验环境1、操作系统:Windows 102、编程语言:Python 383、数据分析库:Pandas、NumPy、Matplotlib、Seaborn、Scikitlearn 等四、实验数据本次实验使用了一份来自某电商平台的销售数据,包含了商品信息、用户信息、销售时间、销售金额等字段。
数据规模约为 10 万条记录。
五、实验步骤1、数据导入与预处理使用 Pandas 库读取数据文件,并对数据进行初步的查看和分析。
处理缺失值:对于包含缺失值的字段,根据数据特点采用了不同的处理方法。
例如,对于数值型字段,使用均值进行填充;对于分类型字段,使用众数进行填充。
数据清洗:去除重复记录和异常值,确保数据的准确性和可靠性。
2、特征工程特征提取:从原始数据中提取有意义的特征,例如计算用户的购买频率、平均购买金额等。
特征编码:对分类型特征进行编码,将其转换为数值型特征,以便模型处理。
例如,使用 OneHot 编码将商品类别转换为数值向量。
3、模型建立与训练选择合适的模型:根据问题的特点和数据的分布,选择了线性回归、决策树和随机森林三种模型进行实验。
划分训练集和测试集:将数据按照一定比例划分为训练集和测试集,用于模型的训练和评估。
模型训练:使用训练集对模型进行训练,并调整模型的参数,以提高模型的性能。
4、模型评估与比较使用测试集对训练好的模型进行评估,计算模型的均方误差(MSE)、均方根误差(RMSE)和决定系数(R²)等指标。

初始问卷编制数据分析实验报告一、引言在社会科学研究、市场调研以及各类数据收集工作中,问卷是一种常用且有效的工具。
而初始问卷的编制质量直接影响到后续数据的准确性和有效性。
为了确保问卷的科学性和合理性,对初始问卷进行数据分析是必不可少的环节。
本实验报告旨在详细介绍初始问卷编制数据分析的过程、方法以及结果。
二、实验目的本次实验的主要目的是对初始编制的问卷进行数据质量评估、信度和效度检验,以发现问卷中可能存在的问题,并对其进行优化和改进,为后续的正式调研提供可靠的工具。
三、实验方法(一)数据收集通过线上和线下相结合的方式,共发放问卷X份,回收有效问卷X 份。
(二)数据分析工具使用 SPSS 250 和 Excel 2019 进行数据录入、整理和分析。
(三)具体分析方法1、数据描述性统计对问卷中各题目的回答情况进行频率、均值、标准差等统计分析,了解数据的分布特征。
2、项目分析通过计算每题的临界比率(CR 值)和题总相关系数,评估每个题目的区分度。
3、信度分析采用Cronbach's α 系数来检验问卷的内部一致性信度。
4、效度分析运用因子分析方法,检验问卷的结构效度。
四、实验结果(一)数据描述性统计1、样本特征参与本次调查的受访者中,男性占X%,女性占X%;年龄分布在最小年龄最大年龄之间,其中主要年龄段占比最高;教育程度涵盖了各个学历层次,主要学历层次居多。
2、各题目的回答情况对问卷中每个题目的选项选择频率进行统计,发现大部分题目选项的分布较为均匀,但也有个别题目存在选项集中的情况。
(二)项目分析1、临界比率(CR 值)通过将问卷总分按照高低排序,取前 27%和后 27%作为高分组和低分组,计算每个题目的 CR 值。
结果显示,有X个题目的 CR 值达到显著水平(p<005),表明这些题目具有较好的区分度。
2、题总相关系数计算每个题目得分与问卷总分的相关系数,发现大部分题目与总分的相关性较强(r>03),但仍有X个题目相关性较弱,需要进一步审视。

第1篇一、实验背景随着大数据时代的到来,数据分析已成为各个行业提高效率、优化决策的重要手段。
本实验旨在通过实际案例分析,运用数据分析方法对某一特定数据集进行深入挖掘,并提出相应的优化策略。
本实验选取了一个典型的电商数据集,通过对用户行为数据的分析,旨在提高用户满意度、提升销售业绩。
二、实验目的1. 熟练掌握数据分析的基本流程和方法。
2. 深入挖掘用户行为数据,发现潜在问题和机会。
3. 提出针对性的优化策略,提升用户满意度和销售业绩。
三、实验内容1. 数据收集与预处理实验数据来源于某电商平台,包含用户购买行为、浏览记录、产品信息等数据。
首先,对数据进行清洗,去除缺失值、异常值,确保数据质量。
2. 数据探索与分析(1)用户画像分析通过对用户性别、年龄、地域、职业等人口统计学特征的统计分析,绘制用户画像,了解目标用户群体特征。
(2)用户行为分析分析用户浏览、购买、退货等行为,探究用户行为模式,挖掘用户需求。
(3)产品分析分析产品销量、评价、评分等数据,了解产品受欢迎程度,识别潜力产品。
3. 数据可视化运用图表、地图等可视化工具,将数据分析结果直观展示,便于理解。
四、实验结果与分析1. 用户画像分析通过分析,发现目标用户群体以年轻女性为主,集中在二线城市,职业以学生和白领为主。
2. 用户行为分析(1)浏览行为分析用户浏览产品主要集中在首页、分类页和搜索页,其中搜索页占比最高。
(2)购买行为分析用户购买产品主要集中在促销期间,购买产品类型以服饰、化妆品为主。
(3)退货行为分析退货率较高的产品主要集中在服饰类,主要原因是尺码不合适。
3. 产品分析(1)销量分析销量较高的产品主要集中在服饰、化妆品、家居用品等类别。
(2)评价分析用户对产品质量、服务、物流等方面的评价较好。
五、优化策略1. 提升用户体验(1)优化搜索功能,提高搜索准确度。
(2)针对用户浏览行为,推荐个性化产品。
(3)加强客服团队建设,提高用户满意度。

第1篇一、实验背景随着科学技术的不断发展,数据处理与分析已成为各个领域不可或缺的重要环节。
为了更好地掌握数据运算的基本原理和方法,我们开展了数据运算实验,通过实际操作加深对数据运算的理解和应用。
本次实验旨在提高我们对数据处理与分析技能的掌握,为后续学习与研究打下坚实基础。
二、实验目的1. 掌握数据运算的基本概念和常用方法;2. 熟悉各类数据运算工具的使用;3. 提高数据处理的实际操作能力;4. 培养团队合作精神与交流能力。
三、实验内容本次实验主要包括以下内容:1. 数据的收集与整理:通过调查问卷、网络爬虫等手段获取数据,并进行数据清洗和预处理;2. 数据的统计分析:运用统计软件对数据进行描述性统计分析、推断性统计分析等;3. 数据的建模与预测:根据实际需求,选择合适的模型对数据进行建模,并对未来趋势进行预测;4. 数据可视化:运用图表、图形等方式展示数据,以便更好地理解和分析。
四、实验过程1. 数据收集与整理:本次实验以我国某地区居民消费数据为例,通过网络爬虫获取相关数据,并使用Python进行数据清洗和预处理,包括去除缺失值、异常值等;2. 数据统计分析:运用Python中的Pandas、NumPy等库对数据进行描述性统计分析,如计算均值、方差、标准差等,并绘制直方图、箱线图等图表;3. 数据建模与预测:针对消费数据,选择线性回归模型进行建模,运用Python中的scikit-learn库进行训练和预测,并对预测结果进行评估;4. 数据可视化:运用Python中的matplotlib、seaborn等库,将统计数据、模型预测结果以图表形式展示,便于直观理解。
五、实验结果与分析1. 数据收集与整理:通过数据清洗和预处理,提高了数据质量,为后续分析奠定了基础;2. 数据统计分析:描述性统计分析结果显示,居民消费水平整体呈上升趋势,其中食品、教育、医疗等消费支出占比较大;3. 数据建模与预测:线性回归模型对消费数据的拟合度较高,预测结果与实际数据基本吻合;4. 数据可视化:通过图表展示,直观地反映了居民消费趋势和结构,为相关决策提供了参考。

分析数据实训报告1. 引言本报告是针对分析数据实训项目的报告。
项目是基于提供的数据集进行分析工作,旨在探索数据的特征和关联性,并通过数据可视化的方式呈现分析结果。
本报告将介绍项目的背景、数据集的概述、分析方法和结果。
2. 背景数据分析在现代社会中扮演着重要的角色,帮助人们更好地理解和利用数据。
分析数据实训项目旨在让学员通过实践项目,掌握数据分析的基本工具和技巧。
此项目要求学员能够运用数据分析工具和统计方法,从给定的数据集中提取有用的信息和洞察力。
3. 数据集概述本项目使用的数据集是一个包含多个变量的表格。
数据集的每一行代表一个样本,每一列代表一个变量。
数据集中的变量包括但不限于年龄、性别、收入、教育程度等。
数据集还包含了一些其他指标,如消费习惯、购物行为等。
数据集的规模为1000行 × 20列。
4. 分析方法为了更好地理解数据集并发现其中的模式和关联性,我们采用了以下分析方法:4.1 数据清洗在进行分析之前,我们首先对数据进行了清洗。
清洗的过程包括处理缺失值、删除异常值、处理重复数据等。
通过数据清洗,我们确保了分析的准确性和可靠性。
4.2 描述性统计分析描述性统计是一种描述和总结数据的方法。
我们对数据集中的各个变量进行了描述性统计分析,包括计算均值、中位数、标准差、最小值、最大值等。
通过描述性统计,我们得到了各个变量的基本统计特征,从而更好地了解了数据的分布和范围。
4.3 相关性分析为了研究数据集中变量之间的关联性,我们进行了相关性分析。
我们计算了各个变量之间的相关系数,并通过热图的形式进行了可视化展示。
通过相关性分析,我们发现了一些变量之间具有较强的相关性,这为后续的分析工作提供了指导。
4.4 数据可视化数据可视化是一种将数据以图形的形式展现出来的方法。
为了更好地理解数据集,并能够直观地展示分析结果,我们使用了数据可视化技术。
我们绘制了柱状图、折线图、散点图等不同类型的图表,以展示数据的不同特征和关系。

销售数据分析实验报告1. 引言销售数据分析是企业决策过程中的重要环节,通过对销售数据的深入分析,企业可以了解产品销售情况、市场需求以及竞争对手情况,从而制定相应的市场策略和销售目标。
本实验旨在通过对一段时间内的销售数据进行分析,探索销售趋势和影响销售的关键因素。
2. 数据收集在实验中,我们收集了过去一年内的销售数据,包括产品名称、销售金额、销售时间等信息。
这些数据以电子表格的形式存储,并通过数据清洗和整理,确保数据的准确性和一致性。
3. 数据预处理在进行数据分析之前,我们需要对数据进行预处理,以确保数据的质量和适用性。
预处理的主要步骤包括:3.1 数据清洗通过删除重复数据、修复缺失值和处理异常值等方式,清洗数据,使其符合分析的要求。
3.2 数据转换在数据转换阶段,我们将销售时间字段转换为日期格式,并根据需要进行数据类型转换,以便于后续的分析处理。
3.3 特征工程特征工程是指根据业务需求,将原始数据转换为可用于建模和分析的特征。
在本实验中,我们通过提取销售金额、产品类别和销售时间等特征,为后续的销售数据分析提供基础。
4. 数据分析基于预处理后的销售数据,我们进行了以下分析:4.1 销售趋势分析通过对销售金额随时间的变化进行可视化分析,我们可以观察到销售的整体趋势。
在分析中,我们使用了折线图和柱状图等图表,直观地展示了销售的季节性、周期性和趋势性。
4.2 产品销售分析我们对不同产品的销售情况进行了分析,包括销售占比、销售额等指标。
通过对产品销售数据的统计和可视化,我们可以了解到各个产品的销售情况,并评估产品的市场潜力和竞争力。
4.3 影响销售的因素分析我们通过建立销售金额与其他因素(如季节、促销活动、竞争对手销售额等)之间的关系模型,探索影响销售的关键因素。
通过回归分析和相关系数分析,我们可以确定哪些因素对销售金额具有显著影响,并据此提出相应的改进措施。
5. 结果与讨论通过对销售数据的分析,我们得出以下结论:1.销售在过去一年内呈现出明显的季节性和周期性变化,其中春季和年末是销售高峰期。

实验报告数据分析实验报告数据分析引言实验报告是科学研究中不可或缺的一部分,通过对实验数据的分析可以得出结论,验证假设,推动科学的发展。
本文将围绕实验报告数据分析展开讨论,旨在探索数据分析在科研中的重要性和应用。
数据收集与整理在进行实验之前,首先需要进行数据的收集。
数据可以通过实验仪器、观察、调查问卷等方式获得。
在收集数据时,需要注意数据的准确性和完整性,以确保后续的分析结果可靠。
收集到的数据需要进行整理和清洗,以便后续的分析。
整理数据包括对数据进行分类、排序和归纳等操作,使得数据更加清晰易懂。
同时,还需要对数据进行清洗,剔除异常值和缺失值,以保证数据的准确性。
数据分析方法数据分析是一种对数据进行统计和解读的过程。
常用的数据分析方法包括描述统计、推断统计和数据挖掘等。
描述统计是对数据进行总结和描述的方法。
通过计算平均值、标准差、频率分布等指标,可以对数据的集中趋势、离散程度和分布情况进行描述。
描述统计能够直观地展示数据的特征,为后续的分析提供基础。
推断统计是通过对样本数据进行分析,推断总体特征的方法。
通过构建假设检验和置信区间等方法,可以对总体参数进行估计和推断。
推断统计能够从有限的样本数据中推断出总体的特征,提高数据分析的效率和精度。
数据挖掘是一种通过算法和模型挖掘数据中隐藏信息的方法。
通过数据挖掘技术,可以发现数据中的规律、关联和趋势等。
数据挖掘能够帮助科研人员发现新的问题和解决方案,推动科学的发展。
数据分析应用举例数据分析在科研中有着广泛的应用。
以下是一些常见的数据分析应用举例。
1. 实验结果分析:通过对实验数据进行统计和推断,可以验证实验假设,得出结论。
例如,在药物研发中,科研人员可以通过对药物试验数据的分析,评估药物的疗效和安全性。
2. 趋势分析:通过对时间序列数据的分析,可以揭示数据的趋势和周期性变化。
例如,在经济学研究中,经济学家可以通过对经济指标的时间序列数据进行分析,预测未来的经济发展趋势。

第1篇一、实验背景随着互联网技术的飞速发展,直播行业在我国迅速崛起,成为新一代互联网经济的重要组成部分。
直播数据分析作为直播行业的重要环节,对于了解用户行为、优化直播内容、提升直播效果具有重要意义。
本实验旨在通过对直播数据进行深入分析,探索直播行业的发展趋势,为直播平台和主播提供有益的参考。
二、实验目的1. 了解直播数据的来源和类型;2. 分析直播数据中的关键指标,如观看人数、点赞数、评论数等;3. 探究直播数据与直播效果之间的关系;4. 为直播平台和主播提供优化建议。
三、实验方法1. 数据采集:通过直播平台API接口,采集直播数据,包括主播信息、观众信息、直播信息等。
2. 数据预处理:对采集到的数据进行清洗、去重、填充等处理,确保数据质量。
3. 数据分析:运用统计学、机器学习等方法对直播数据进行深入分析,包括描述性分析、相关性分析、回归分析等。
4. 结果展示:通过图表、文字等形式展示分析结果。
四、实验内容1. 数据来源及类型实验所采集的数据来自某知名直播平台,包括主播信息、观众信息、直播信息等。
其中,主播信息包括主播ID、昵称、性别、年龄、直播时长等;观众信息包括观众ID、昵称、性别、年龄、观看时长等;直播信息包括直播ID、直播标题、直播时长、观看人数、点赞数、评论数等。
2. 关键指标分析(1)观看人数:观看人数是衡量直播效果的重要指标。
通过分析观看人数的变化趋势,可以了解直播的受欢迎程度。
(2)点赞数:点赞数反映了观众对直播内容的喜爱程度。
分析点赞数的变化,有助于了解直播内容的优劣。
(3)评论数:评论数反映了观众参与直播互动的积极性。
通过分析评论数的变化,可以了解直播氛围的好坏。
(4)观看时长:观看时长反映了观众对直播内容的关注程度。
分析观看时长,有助于了解直播内容的吸引力。
3. 直播数据与直播效果之间的关系(1)观看人数与直播效果:通过相关性分析,发现观看人数与直播效果呈正相关,即观看人数越多,直播效果越好。

《数据分析》实验报告三实验报告三:数据分析实验目的:本实验旨在通过对一批数据进行分析,探索数据之间的关系、趋势和规律,从而为决策提供科学依据。
实验方法:1. 数据收集:从数据库中获取相关数据。
2. 数据清洗:对数据进行去重、缺失值处理和异常值处理。
3. 数据预处理:对数据进行标准化、归一化等预处理操作,以保证数据的可比性。
4. 数据分析:采用统计学和机器学习等方法对数据进行分析,包括描述性统计分析、相关性分析、回归分析等。
5. 结果展示:将分析结果以表格、图表等形式进行可视化展示,以便于观察和理解。
实验步骤:1. 数据收集:从公司A的销售系统中获取了过去一年的销售数据,包括销售额、销售时间、销售地区等信息。
2. 数据清洗:对数据进行去重,并对缺失值和异常值进行处理,确保数据的准确性和完整性。
3. 数据预处理:对销售额数据进行了归一化处理,使得数据符合正态分布。
4. 数据分析:a. 描述性统计分析:对销售额进行了统计分析,得出平均销售额、最大销售额、最小销售额等数据。
b. 相关性分析:通过计算销售额与销售时间、销售地区之间的相关系数,探索二者之间的关系。
c. 回归分析:利用线性回归模型,分析销售时间对销售额的影响,并进行模型评估和预测。
5. 结果展示:将分析结果以表格和图表的形式展示出来,其中包括描述性统计结果、相关系数矩阵、回归模型的参数等。
实验结果:1. 描述性统计分析结果:- 平均销售额:10000元- 最大销售额:50000元- 最小销售额:100元- 销售额标准差:5000元2. 相关性分析结果:- 销售额与销售时间的相关系数为0.8,表明销售时间对销售额有较强的正相关性。
- 销售额与销售地区的相关系数为0.5,表明销售地区对销售额有适度的正相关性。
3. 回归分析结果:- 线性回归模型:销售额 = 500 + 100 * 销售时间- 模型评估:通过计算均方差和决定系数,评估回归模型的拟合优度。
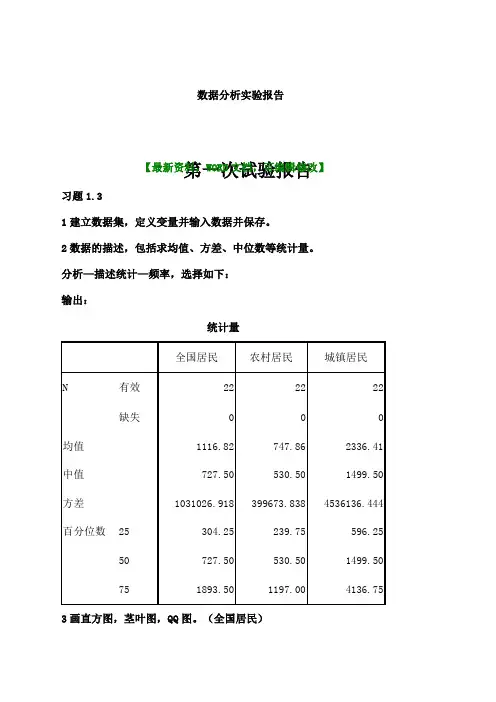
第一次试验报告习题1.31建立数据集,定义变量并输入数据并保存。
2数据的描述,包括求均值、方差、中位数等统计量。
分析—描述统计—频率,选择如下: 输出:3画直方图,茎叶图,QQ 图。
(全国居民)数据分析实验报告【最新资料,WORD 文档,可编辑修改】分析—描述统计—探索,选择如下:输出:全国居民 Stem-and-Leaf PlotFrequency Stem & Leaf5.00 0 . 567882.00 1 . 031.00 1 . 71.00 2 . 33.00 2 . 6891.00 3 . 1Stem width: 1000Each leaf: 1 case(s)分析—描述统计—QQ图,选择如下:输出:习题1.14数据正态性的检验:K—S检验,W检验数据:取显着性水平为0.05分析—描述统计—探索,选择如下:(1)K—S检验单样本 Kolmogorov-Smirnov 检验结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。
(2)W检验结果:在Shapiro-Wilk 检验结果972.00=w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。
习题1.55多维正态数据的统计量 数据:均值向量为:)767.33,505.4,836.27,219.18(=-X结果:x4与其他数据无相关性,其他三组数据线性相关结果:由Spearman相关矩阵的输出结果看,取显着性水平0.1,p值皆小于0.1,所以数据相关性显着习题2.46线性回归线的拟合,回归系数的区间估计与假设检验,回归系数的选择、逐步回归。
7残差分析分析—回归—线性,选择如下:输出:逐步回归结果:两变量的系数p值均小于0.05均有统计学意义。
结果:由残差统计量表看出,数据无偏离值,标准差比较小,认为模型健康。
概率论课本习题7.58一个正态总体独立样本均值的t检验与区间估计分析—比较均值—独立样本T检验:输出:结果:样本均值为2833.50与总体均值2820比较接近结果:t值为1.218小于临界值2.26,且P值为0.254大于显着性水平0.05,接受原假设,即认为样本均值与总体均值之差可能是抽样误差所导致概率论课本习题7.79两个正态总体均值差异比较的t检验与配对检验分析—均值比较—独立样本T检验,选择如下:输出:结果:P值为1大于显着性水平0.05,认为方差相等。
数据分析实验报告理学院实验中心数学专业实验室编写数值分析实验指导实验一 SAS系统的使用【实验类型】(验证性)【实验学时】2学时【实验目的】使学生了解SAS系统,熟练掌握SAS数据集的建立及一些必要的SAS语句。
【实验内容】1. 启动SAS系统,熟悉各个菜单的内容;在编辑窗口、日志窗口、输出窗口之间切换。
2. 建立数据集表1Name Sex Math Chinese EnglishAlice f 90 85 91Tom m 95 87 84Jenny f 93 90 83Mike m 80 85 80Fred m 84 85 89Kate f 97 83 82Alex m 92 90 91Cook m 75 78 76Bennie f 82 79 84Hellen f 85 74 84Wincelet f 90 82 87Butt m 77 81 79Geoge m 86 85 82Tod m 89 84 84Chris f 89 84 87Janet f 86 65 871)通过编辑程序将表1读入数据集sasuser.score; 2)将下面记事本中的数据读入SAS数据集,变量名为code name scale share price:000096 广聚能源 8500 0.059 1000 13.27 000099 中信海直 6000 0.028 2000 14.2 000150 ST麦科特 12600 -0.003 1500 7.12 000151 中成股份 105000.026 1300 10.08 000153 新力药业 2500 0.056 2000 22.751数值分析实验指导 3)将下面Excel表格中的数据导入SAS数据集work.gnp;x1 x2 x3 x4 x5 x6 name北京 190.33 43.77 7.93 60.54 49.01 90.4天津 135.2 36.4 10.47 44.16 36.49 3.94河北 95.21 22.83 9.3 22.44 22.81 2.8山西 104.78 25.11 6.46 9.89 18.17 3.25 内蒙古 128.41 27.63 8.94 12.58 23.99 3.27辽宁 145.68 32.83 17.79 27.29 39.09 3.47吉林 159.37 33.38 18.37 11.81 25.29 5.22 黑龙江 116.22 29.57 13.24 13.76 21.75 6.04上海 221.11 38.64 12.53 115.65 50.82 5.89江苏 144.98 29.12 11.67 42.6 27.3 5.74浙江 169.92 32.75 21.72 47.12 34.35 5安徽 153.11 23.09 15.62 23.54 18.18 6.39福建 144.92 21.26 16.96 19.52 21.75 6.73江西 140.54 21.59 17.64 19.19 15.97 4.94山东 115.84 30.76 12.2 33.1 33.77 3.85河南 101.18 23.26 8.46 20.2 20.5 4.3湖北 140.64 28.26 12.35 18.53 20.95 6.23湖南 164.02 24.74 13.63 22.2 18.06 6.04广东 182.55 20.52 18.32 42.4 36.97 11.68广西 139.08 18.47 14.68 13.41 20.66 3.85四川 137.8 20.74 11.07 17.74 16.49 4.39贵州 121.67 21.53 12.58 14.49 12.18 4.57云南 124.27 19.81 8.89 14.22 15.53 3.03陕西 106.02 20.56 10.94 10.11 18 3.29甘肃 95.65 16.82 5.7 6.03 12.36 4.49青海 107.12 16.45 8.98 5.4 8.78 5.93宁夏 113.74 24.11 6.46 9.61 22.92 2.53新疆 123.24 38 13.72 4.64 17.77 5.754)使用VIEWTABLE格式新建数据集earn,输入如表所示数据 Year earn 1981 1250001982 1360001983 1223501984 652001985 8446001986 2550001987 2650001988 2800001989 1360002数值分析实验指导3. 将sasuser.score数据集的内容复制到一个临时数据集test,要求只包含变量name, sex, math。
weka数据分析实验报告1实验基本内容本实验的基本内容是通过使用weka中的三种常见分类方法(朴素贝叶斯,KNN和决策树C4.5)分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型该模型所有设置的最优参数。
最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。
2格式转换方法格式:原始数据是excel文件保存的xlsx格式数据,需要转换成Weka支持的arff文件格式或csv文件格式。
由于Weka对arff格式的支持更好,这里我们选择arff格式作为分类器原始数据的保存格式。
转换方法:在excel中打开“movie_given.xlsx”,选择菜单文件->另存为,在弹出的对话框中,文件名输入“total_data”,保存类型选择“CSV(逗号分隔)”,保存,我们便可得到“total_data.csv”文件;然后,打开Weka的Exporler,点击Open file按钮,打开刚才得到的“total_data”文件,点击“save”按钮,在弹出的对话框中,文件名输入“total_data”,文件类型选择“Arff data files (*.arff)”,这样得到的数据文件为“total_data.arff”。
3预处理具体步骤第一步:合并movie_given.xlsx和test.xlsx,保存为total_data.xlsx。
第二步:在total_data.xlsx中删除多余的ID列信息。
第三步:在excel中打开“total_data.xlsx”,选择菜单文件->另存为,在弹出的对话框中,文件名输入“total_data”,保存类型选择“CSV(逗号分隔)”。
第四步:使用UltraEdit工具把total_data.csv中的数据缺失部分补上全局常量‘?’。
数据分析与挖掘实验报告1. 引言数据分析与挖掘是一门应用广泛且不断发展的技术领域,在各个行业中都有着重要的应用。
本实验旨在通过应用数据分析与挖掘技术解决一个实际问题,并探索不同方法的效果与应用场景。
2. 实验背景我们的实验对象是一家电商平台,该平台积累了大量的用户购买记录、搜索记录、浏览记录等数据。
为了提升销售量与用户粘性,平台希望能够通过数据分析与挖掘技术,对用户行为和购买偏好进行深入分析,从而制定更加精准的推荐策略和营销方案。
3. 数据采集与预处理首先,我们从电商平台的数据库中导出了一份包含大量用户购买记录和相关信息的数据集。
由于数据量较大且存在一定的噪声,为了方便后续分析与挖掘,我们进行了数据预处理工作。
包括清洗数据、去除重复记录、处理缺失值、筛选有效特征等。
4. 数据探索与可视化在数据预处理完成后,我们进行了数据探索与可视化的工作,旨在通过对数据的观察和分析,了解用户的消费行为模式和潜在特征。
通过使用统计分析方法和数据可视化工具,我们得到了一系列有意义的结论。
首先,我们对用户的购买行为进行了分析。
通过统计每个用户的购买频次和购买金额,我们发现了一部分高价值用户和潜在的忠实用户。
这对于电商平台的个性化推荐和定制化营销策略具有重要指导意义。
其次,我们对用户的搜索行为进行了分析。
通过对用户搜索关键词、搜索次数以及搜索时间等数据进行统计,我们发现了用户的购买偏好和需求特征。
这些信息可以用于电商平台的商品推荐、搜索引擎优化和广告投放等方面。
最后,我们对用户的浏览行为进行了分析。
通过统计浏览商品的页面停留时间、浏览量等数据,我们发现了用户的兴趣爱好和潜在需求。
这对于电商平台的内容推荐和广告精准投放有着重要意义。
5. 数据挖掘与模型构建在数据探索阶段,我们获得了大量关于用户行为和购买偏好的信息,为了进一步发掘数据的潜在价值,我们进行了数据挖掘与建模工作。
我们首先应用了关联规则挖掘算法,通过分析购买记录,发现了一些具有关联关系的商品,如牛奶和麦片、沐浴露和洗发水等。
数据分析与挖掘实验报告一、引言数据分析与挖掘是一项重要的技术,通过对大量的数据进行分析和挖掘,可以帮助我们揭示数据背后的规律和信息,为决策提供科学依据。
本实验旨在利用数据分析与挖掘的方法,探索数据中的隐藏信息,并运用所学的算法和技术对数据进行分析和挖掘。
二、实验背景本实验的数据集为一个电子商务网站的销售数据,包括网站用户的浏览记录、购买记录、收藏记录等。
数据集包含了大量的信息,包括用户的个人信息、商品的详细信息以及用户与商品之间的交互信息。
通过对这些数据进行分析与挖掘,可以从中发现用户的购物习惯、商品的热门程度以及用户与商品之间的关联等信息,为电子商务网站提供价值的决策依据。
三、数据预处理在进行数据分析与挖掘之前,首先需要对原始数据进行预处理。
本次实验的预处理包括以下几个步骤:1. 数据清洗:对于数据中存在的异常值、缺失值或者错误值,需要进行清洗处理。
比如,对于缺失值可以采取填补或删除的方法,对于异常值可以进行修正或删除。
2. 数据转换:对于某些数据类型,需要将其进行转换,使其适应后续分析与挖掘的需求。
比如,将日期格式转换为数值格式,将文本类型转换为数值类型等。
3. 数据集成:将多个数据集进行整合,形成一个完整的数据集。
比如,将用户的个人信息与商品的信息关联起来,形成一个用户商品交互的数据集。
四、数据分析与挖掘1. 关联规则挖掘关联规则挖掘是一种常用的数据挖掘技术,用于寻找数据集中的项集之间的关联关系。
在本实验中,我们使用Apriori算法对用户购买的商品进行关联规则挖掘。
通过分析购买数据集中的商品组合,我们可以发现用户的购物喜好和商品之间的相关性。
2. 聚类分析聚类分析是一种常见的数据分析方法,用于将具有相似特征的对象划分到同一个类别中。
在本实验中,我们使用K均值算法对用户的浏览记录进行聚类分析。
通过将用户划分到不同的类别中,我们可以发现用户间的行为差异,为电子商务网站提供个性化推荐。
3. 预测模型建立预测模型建立是数据分析与挖掘的一个重要环节,通过对历史数据的建模与预测,可以预测未来的趋势和结果。
《数据分析与应用软件》实验报告新一、实验目的随着信息技术的不断发展,数据已成为当今社会中最重要的资产之一。
数据分析能够帮助我们从海量的数据中提取有价值的信息,为决策提供有力的支持。
本实验的目的在于通过实际操作和应用,深入了解数据分析的基本流程和常用应用软件的使用方法,提高我们的数据分析能力和解决实际问题的能力。
二、实验环境本次实验使用的软件包括 Excel、Python 中的 Pandas 库和Matplotlib 库。
硬件环境为一台配备英特尔酷睿 i5 处理器、8GB 内存的计算机。
三、实验内容1、数据收集首先,我们需要确定数据的来源和收集方法。
在本次实验中,我们选择了从互联网上获取一份公开的销售数据,该数据包含了不同产品的销售数量、销售价格、销售地区等信息。
2、数据预处理收集到的数据往往存在缺失值、异常值和重复值等问题,需要进行预处理。
使用 Excel 对数据进行初步的清理和整理,包括删除重复行、填充缺失值和处理异常值。
3、数据分析(1)使用 Excel 的数据透视表功能,对销售数据进行分类汇总,分析不同产品在不同地区的销售情况,计算销售额和销售利润等指标。
(2)利用 Python 的 Pandas 库读取数据,并进行进一步的分析。
计算各种统计量,如均值、中位数、标准差等,以了解数据的集中趋势和离散程度。
(3)通过数据可视化,更直观地展示数据分析结果。
使用Matplotlib 库绘制柱状图、折线图和饼图等,展示不同产品的销售占比、销售额的趋势以及不同地区的销售分布情况。
4、建立模型基于分析结果,尝试建立简单的预测模型。
例如,使用线性回归模型预测未来的销售额。
四、实验步骤1、数据收集在互联网上搜索并下载相关的销售数据文件,保存为 CSV 格式,以便后续处理。
2、数据预处理(1)打开 Excel,导入 CSV 数据文件。
(2)使用“删除重复项”功能删除重复的行。
(3)对于缺失值,根据数据的特点和业务逻辑,采用适当的方法进行填充,如使用平均值或中位数填充。