多元统计分析实验报告判别分析
- 格式:doc
- 大小:77.84 KB
- 文档页数:20


《应用多元统计分析》第四章判别分析实验报告第四章判别分析实验报告实验环境Windows xp、Windows vista、Windows 7等,软件SPSS 11.0版本及以上。
实验结果与分析本题中记变量值CF_TD, NI_TA, CA_CL, CA_NS分别为X1,X2,X3,X4 (1)Fisher判别函数特征值EigenvaluesFunction Eigenvalue% of Variance Cumulative %CanonicalCorrelation1.940a100.0100.0.696a. First 1 canonical discriminant functions were used in the analysis.(2)Fisher判别函数有效性检验Wilks' LambdaTest ofFunction(s)Wilks' Lambda Chi-square df Sig.1.51527.8394.000(3)标准化的Fisher判别函数系数Standardized Canonical Discriminant FunctionCoefficientsFunction1CF_TD.134NI_TA.463CA_CL.715CA_NS-.220所以标准化的判别函数为:Y=0.134X1+0.463X2+0.715X3-0.220X4得出Y=0.9012(4)未标准化的Fisher判别函数系数Canonical Discriminant Function CoefficientsFunction1CF_TD.629NI_TA 4.446CA_CL.889CA_NS-1.184 (Constant)-1.327 Unstandardized coefficients所以为标准化的费希尔判别函数为:Y=-1.327+0.629X1+4.446X2+0.889X3-1.184X4得出Y=-0.1703(5)组重心处的费希尔判别函数值Functions at Group CentroidsG Function11.8692-1.035 Unstandardized canonical discriminant functions evaluated at group means各类重心在空间中的坐标位置。

【精品】多元统计分析--判别分析SPSS实验报告一、实验目的1.掌握判别分析的基本原理和应用方法;2.掌握SPSS软件进行判别分析的具体操作;3.通过一个实例,学习如何运用判别分析对指标进行判别。
二、实验内容三、实验原理1.判别分析基本原理:判别分析(Discriminant Analysis),是一种统计学中的分类技术,它是对变量进行归类的技术。
判别分析是用来确定一个对象或自变量集合属于哪一个预设类型或者组别的过程。
判别分析能够生成一个函数,将数据点映射到特定的类型上。
判别分析的应用领域非常广泛,主要应用于以下领域:(1)股票市场(预测股价的涨跌与时间、公司发展情况等因素的关系);(2)医学(区分疾病、患者状态等);(3)市场调查(确定客户类型、产品或服务喜好);(4)产业分析(区分有助于产品销售的市场决策因素);(5)经济学(预测月度或季度的经济指标)。
3.判别分析的主要应用步骤:(1)建立模型:首先选择和收集数据,将收集的数据分为训练集和测试集;(2)训练模型:使用训练数据建立模型;(3)评估模型:通过模型诊断来评估建立的模型的好坏;(4)应用模型:对新的数据建立模型并进行预测。
四、实验过程1. 上机操作:1)打开SPSS软件,加载数据文件;2)选择分类变量和连续变量;3)选择训练数据集;4)建立模型;5)预测实验数据集。
2. 操作步骤:SPSS分析的步骤如下:1)将数据输入SPSS软件,确保数据格式正确;2)选择Analyse- Classify- Discriminant;3)有两种不同的分类变量,单分类或多分类,如果你要解释一个特定的分类变量,选择单分类。
如果你不确定哪个分类变量最适合,请尝试不同的选项;4)选择两个或更个你认为与指定分类变量相关的连续变量;5)选择要用于判别分析的数据集;6)确定分类变量分类比率。
这可以在设置选项中完成;7)点击OK,开始进行分析;8)评估结果,包括汇总、判别函数、方差-方差贡献、判别矩阵;五、实验结果选取鸢尾花数据,经过训练,得到如下表所示的结果。

《多元统计实验》判别分析实验报告cbind(类别,newG,Z$post,Z$x)#合并原分类、回判分类回判后验概率及判别tab=table(类别,newG)#原分类和新分类列表比较tabsum(diag(prop.table(tab)))prenew=predict(ld,newdata=newdata)prenew#对三个待判样本进行判定cbind(prenew$class,prenew$post,prenew$x)#也可以按列合并在一起看二、实验结果分析5.5进行Fisher判别分析.若一位新客户的8个指标分别为(2 500, 1 500, 0,3, 2,3, 4, 1),试对该客户的信用度进行评价.以上输出结果中包括了lad()所用的公式、先验概率1、2、3、4、5 为:0.2941176 、0.1176471 、0.1764706 0.1764706 、0.2352941,各组均值向量、线性判别函数的系数。
输出所有分类组由输出结果可知第十二号样品为第四组的被误判给了第五组,且与距离判别法结果一致,最后对新客户的8个指标(2500,1500,0,3,2,3,4,1)进行判定。
说明:由$class可以看出该新用户被判入第一组,结果与距离判别法一致,对应的后验概率决定该新用户的归类组。
因此该新用户的信用度评价为一。
5.6试对表5-7中的数据进行Bayes判别分析并对8个待判样品的类别进行判定.由上结果可知,两个组别为一的被误判为第二组,第二组的三个被误判为第一组。
出现5个误判结果正确率为:0.9411765,误判错误的概率仍然较低。
Bayes判别法对八个待测样本的判定结果为:四个判给第一组,四个判给第二组,且Bayes 判别法是采用了新的后验概率,而不是先验概率。
因此判出概率相同。


判别分析实验报告SPSS实验目的:判别分析(Discriminant Analysis)是一种经典的多元统计分析方法,用于解释和预测分类变量。
该实验旨在使用SPSS软件进行判别分析,探索一组变量对分类结果的贡献和预测能力。
实验步骤:1.数据收集:从一些公司的人力资源数据库中随机选择了200个员工作为样本,收集了以下变量:性别(男、女)、教育程度(本科、研究生、博士)、工龄(年)、绩效评分(0-5)、离职与否(是、否)。
2.数据清洗:检查数据中是否存在缺失值,并对缺失值进行处理。
删除离职与否变量中缺失值。
3.数据探索:使用SPSS进行描述性统计分析,了解样本的基本情况。
分别计算男女性别比例和各教育程度及离职状态的分布情况。
4. 变量选择:使用SPSS进行判别分析,将离职与否作为分类变量,性别、教育程度、工龄和绩效评分作为预测变量。
使用Wilks' Lambda检验选择预测变量,确定对分类结果的贡献。
5.判别函数计算:根据选择的预测变量,计算判别函数。
使用判别函数对样本进行分类,并计算分类结果的准确率。
实验结果:1.数据探索结果显示,样本中男女性别比例约为1:1,教育程度主要集中在本科和研究生,离职比例为14%。
2. 判别分析结果显示,Wilks' Lambda检验结果为0.632,p值小于0.05,说明选取的预测变量对分类结果有统计上显著的贡献。
3.计算得到的判别函数为D=-0.311(性别)+0.236(教育程度)+0.011(工龄)+0.585(绩效评分)。
4.使用判别函数对样本进行分类,分类准确率为81.5%。
其中,离职样本的分类准确率为75%,非离职样本的分类准确率为82%。
实验结论:通过判别分析实验,我们得出以下结论:1.性别、教育程度、工龄和绩效评分这四个变量对员工的离职与否有显著的预测能力。
2.预测变量中绩效评分对离职结果的贡献最大,说明绩效评分较低的员工更容易离职。

《多元统计分析》实验报告实验名称: 判别分析及正态检验专业:统计学班级:120802姓名:指导教师:2014 年6 月26 日给出血友病基因携带者数据1,共分2组,第一组为非携带者(1π),第二组为必然携带者(2π),分组变量为g ,变量x1表示()10log AHF 活性,变量x2表示()10log AHF 抗原,利用上述数据: (1)对两个组检查二元正态性假定;一通过菜单系统实现 二运行结果第一组的正态性检验一运行程序proc princomp data=sasuser.zu1 out=prin prefix=z standard;var x1 x2;run;proc univariate data=work.prin normal plot;var z1 z2;run;二运行结果三结论分析第二组的正态性检验一运行程序proc princomp data=sasuser.zu2 out=prin1 prefix=z standard; var x1 x2;run;proc univariate data=work.prin1 normal plot;var z1 z2;run;二运行结果三结论分析(2)假定两组先验概率相等,求样本线性判别函数,并估计误判概率;一运行程序proc discrim data=sasuser.liangzu listerr crosslisterr;class g;var x1-x2;run;二运行结果三结论分析(3)将血友病基因携带者数据2中的10个新事例用(2)得到的判别函数进行分类;一运行程序proc discrim data=sasuser.liangzu testdata=sasuser.daipan listerr crosslisterr testlist;class g;var x1-x2;run;二运行结果三结论分析(3)假定必然携带者(组2)的先验概率为0.25。

多元统计分析实验报告(精选多篇)第一篇:多元统计分析实验报告多元统计分析得实验报告院系:数学系班级:13级 B 班姓名:陈翔学号:20131611233 实验目得:比较三大行业得优劣性实验过程有如下得内容:(1)正态性检验;(2)主体间因子,多变量检验a;(3)主体间效应得检验;(4)对比结果(K 矩阵);(5)多变量检验结果;(6)单变量检验结果;(7)协方差矩阵等同性得Box 检验a,误差方差等同性得Levene 检验 a;(8)估计;(9)成对比较,多变量检验;(10)单变量检验。
实验结果:综上所述,我们对三个行业得运营能力进行了具体得比较分析,所得数据表明,从总体来瞧,信息技术业要稍好于电力、煤气及水得生产与供应业以及房地产业。
1。
正态性检验Kolmogorov-SmirnovaShapir o—Wilk 统计量 df Sig.统计量df Sig、净资产收益率。
113 35、200*。
978 35。
677 总资产报酬率。
121 35、200*。
964 35、298 资产负债率。
086 35。
200*.962 35、265 总资产周转率.180 35、006。
864 35。
000流动资产周转率、164 35、018.88535、002 已获利息倍数、28135.000。
55135、000 销售增长率.103 35、200*。
949 35、104 资本积累率。
251 35。
000、655 35。
000 *。
这就是真实显著水平得下限。
a。
Lilliefors显著水平修正此表给出了对每一个变量进行正态性检验得结果,因为该例中样本中n=35<2000,所以此处选用 Shapiro—W ilk 统计量。
由 Sig。
值可以瞧到,总资产周转率、流动资产周转率、已获利息倍数及资本积累率均明显不遵从正态分布,因此,在下面得分析中,我们只对净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标进行比较,并认为这四个变量组成得向量遵从正态分布(尽管事实上并非如此)。

判别分析:实验步骤:1.在SPSS窗口中选择:分析-分类-判别,将变量导入自变量框中,group导入分组变量中,选择定义范围,最小为1最大为3,并选择一起输入自变量,点击继续2.点击统计量,描述性中选择“均值”,“单变量”和”Box”,选择函数系数中的“Fisher”“未标准化”,矩阵中选择“组内相关”,点击继续3.点击分类点击继续4.点击“保存”,三个框均选中,点击继续5.点击确定实验结果分析:1.表1 组统计量看各个总体在均值等指标上的值是否接近,若接近说明各类之间在该指标差异不大表2表3 汇聚的组内矩阵若自变量之间存在高度相关,则判别分析价值不大,但并不严格,允许出现一定的相关表4 协方差矩阵的均等性的箱式检验检验结果p值>0.05时,说明协方差矩阵相等,可以进行bayes检验表7由表7可知,两个Fisher 判别函数分别为1123456212345674.99 1.861 1.6560.8770.7980.098 1.57929.4820.867 1.1550.3560.0890.0540.69y XX X X X X y X X X XX X =--+-+++=--+--++表8 结构矩阵该表是原始变量与典型变量(标准化的典型判别函数)的相关系数,相关系数的绝对值越大,说明原始变量与这个判别函数的相关性越强由表9可知各类别重心的位置,通过计算观测值与各重心的距离,距离最小的即为该观测值的分类。
表10 给出贝叶斯判别函数系数第一类:11234565317.2143.9153.190.153.011.0189.3F X X X X X X =--+-+++2. 将各样品的自变量值代入上述三个Bayes 判别函数,得到函数值。
比较函数值,哪个函数值比较大就可以判断该样品判入哪一类。

2015——2016学年第一学期实验报告课程名称:多元统计分析实验项目:判别分析实验类别:综合性□√设计性□验证性□专业班级:姓名:学号:实验地点:统计与金融创新实验室(新60801) 实验时间:指导教师:曹老师成绩:数学与统计学院实验中心制一、实验目的让学生掌握判别分析的基本步骤和分析方法;学习《spss统计分析从入门到精通》P307-P320的内容,掌握一般判别分析与逐步判别分析方法。
二、实验内容1、应用《胃病患者的测量数据》和《表征企业类型的数据.sav》,掌握一般判别分析与逐步判别分析方法。
数据来源于《spss统计分析从入门到精通数据文件》第12章的数据。
2、参考教材例4-2的数据进行分析,数据见文件《何晓群多元统计分析(数据)》中的例4-2new。
三、实验方案(程序设计说明)四、程序运行结果1. (1)分析案例处理摘要未加权案例N 百分比有效14 93.3排除的缺失或越界组代码 1 6.7 至少一个缺失判别变量0 .0 缺失或越界组代码还有至少一个缺失判别变量0 .0 合计 1 6.7合计15 100.0组统计量类别均值标准差有效的N(列表状态)未加权的已加权的胃癌患者铜蓝蛋白188.60 57.138 5 5.000 蓝色反应150.40 16.502 5 5.000 尿吲哚乙酸13.80 5.933 5 5.000 中性琉化物20.00 13.323 5 5.000萎缩性胃炎铜蓝蛋白156.25 47.500 4 4.000 蓝色反应118.75 14.104 4 4.000 尿吲哚乙酸7.50 1.732 4 4.000 中性琉化物14.50 8.386 4 4.000其他胃病铜蓝蛋白151.00 33.801 5 5.000 蓝色反应121.40 13.012 5 5.000 尿吲哚乙酸 5.00 1.871 5 5.000 中性琉化物8.00 7.314 5 5.000合计铜蓝蛋白165.93 46.787 14 14.000 蓝色反应131.00 20.203 14 14.000 尿吲哚乙酸8.86 5.318 14 14.000 中性琉化物14.14 10.726 14 14.000汇聚的组内矩阵a铜蓝蛋白蓝色反应尿吲哚乙酸中性琉化物协方差铜蓝蛋白2217.995 -168.268 -48.264 158.682 蓝色反应-168.268 214.832 12.082 -13.773 尿吲哚乙酸-48.264 12.082 14.891 -8.273 中性琉化物158.682 -13.773 -8.273 103.182a. 协方差矩阵的自由度为11。
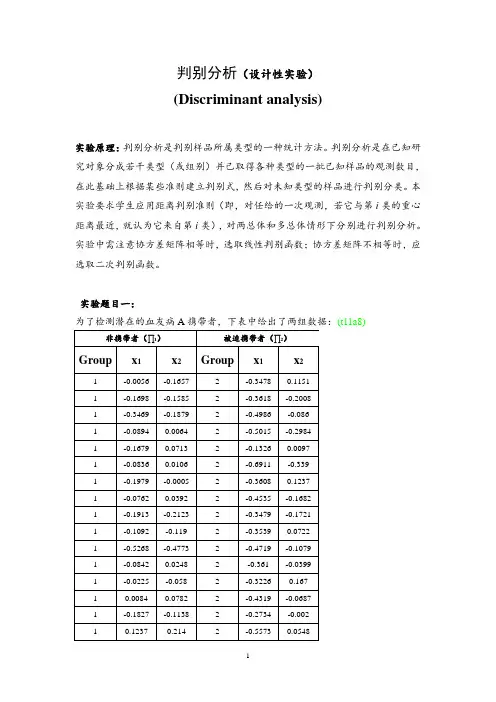
判别分析(设计性实验)(Discriminant analysis)实验原理:判别分析是判别样品所属类型的一种统计方法。
判别分析是在已知研究对象分成若干类型(或组别)并已取得各种类型的一批已知样品的观测数目,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类。
本实验要求学生应用距离判别准则(即,对任给的一次观测,若它与第i类的重心距离最近,就认为它来自第i类),对两总体和多总体情形下分别进行判别分析。
实验中需注意协方差矩阵相等时,选取线性判别函数;协方差矩阵不相等时,应选取二次判别函数。
实验题目一:为了检测潜在的血友病A携带者,下表中给出了两组数据:(t11a8)其中x1=log10(AHF activity),x2=log10(AHF antigen)。
下表给出了五个新的观测,试对这些观测判别归类;(t11b8)实验要求:(1)分别检验两组数据是否大致满足二元正态性;(2)分别计算两组数据的协方差矩阵,是否可以认为两者近似相等?(3)对训练样本和新观测合并作散点图,不同的类用不同颜色标识;(4)用lda函数做判别分析,即在协方差矩阵相等的情形下作判别分析;(5)用qda函数做判别分析,即在协方差矩阵不相等的情形下作判别分析;(6)比较方法(4)和方法(5)的误判率。
实验题目二:某商学研究生院的招生官员利用指标――大学期间平均成绩GPA和研究生管理能力考试GMAT的成绩,将申请者分为三类:接受,不接受,待定。
下表中给出了三类申请者的GPA与GMAT成绩:(t11a6)GPA (x1)GMAT(x2)接受GPA(x1)GMAT(x2)不接受GPA(x1)GMAT(x2)待定2.96 596 1 2.54 446 2 2.86 494 33.14 473 1 2.43 425 2 2.85 496 3 3.22 482 1 2.2 474 2 3.14 419 3 3.29 527 1 2.36 531 2 3.28 371 3 3.69 505 1 2.57 542 2 2.89 447 3 3.46 693 1 2.35 406 2 3.15 313 3 3.03 626 1 2.51 412 2 3.5 402 3 3.19 663 1 2.51 458 2 2.89 485 3 3.63 447 1 2.36 399 2 2.8 444 3 3.59 588 1 2.36 482 2 3.13 416 3 3.3 563 1 2.66 420 2 3.01 471 3 3.4 553 1 2.68 414 2 2.79 490 33.5 572 1 2.48 533 2 2.89 431 33.78 591 1 2.46 509 2 2.91 446 33.44 692 1 2.63 504 2 2.75 546 33.48 528 1 2.44 336 2 2.73 467 33.47 552 1 2.13 408 2 3.12 463 33.35 520 1 2.41 469 2 3.08 440 33.39 543 1 2.55 538 2 3.03 419 33.28 523 1 2.31 505 2 3 509 33.21 530 1 2.41 489 2 3.03 438 33.58 564 1 2.19 411 2 3.05 399 33.33 565 1 2.35 321 2 2.85 483 33.4 431 1 2.6 394 2 3.01 453 33.38 605 1 2.55 528 2 3.03 414 33.26 664 1 2.72 399 2 3.04 446 33.6 609 1 2.85 381 23.37 559 1 2.9 384 23.8 521 13.76 646 13.24 467 1实验要求:(1)对上表中的数据作散点图,不同的类用不同的颜色标识;(2)用lda函数做判别分析,即在协方差矩阵相等的情形下作判别分析;(3)用qda函数做判别分析,即在协方差矩阵不相等的情形下作判别分析;(4)比较方法(2)和方法(3)的误判率;(5)现有一新申请者的GPA为3.21,GMAT成绩为497。
实验四——判别分析一、实验内容1、实验目的为研究某地区人口死亡状况,已按某种方法将15个已知样品分为3类,通过对指标及原始数据进行判别分析并建立判别函数,判定另外4个待判样品属于哪类。
2、实验要求找出较为合适的判别方法,判别待判样品属于哪一类。
二、实验报告1、问题提出为研究某地区人口死亡状况,已按某种方法将15个已知样品分为3类,通过判别分析判定另外4个待判样品属于哪类。
2、指标选择选取以下六项指标: X1:0岁组死亡概率 X2:1岁组死亡概率 X3:10岁组死亡概率 X4:55岁组死亡概率 X5:80岁组死亡概率 X6:平均预期寿命 3、数据来源表 4-1 原始数据X1:0岁组死亡概率 X2:1岁组死亡概率X4:55岁组死亡概率 X5:80岁组死亡概率4、数据处理经观察分析,表中数据没有错误值或是缺失值,因此不需要进行处理。
5、操作步骤(1)按照表4-2把数据输入SPSS数据表中。
(2)通过单击Analyze→Classify→Discriminant展开判别分析对话框。
(3)选择group这个变量为被解释变量,移到Grouping Variable(分组变量)框中,打开Define Range,在Minimum后填1,在Maximum后填3,表示分为三组;选择x1、x2、x3、x4、x5、x6这六个变量为解释变量,移到Independents框中。
再点选Enter independents together(全部变量进入)单选按钮。
(4)选择要求输出的统计量。
在主对话框中单击Statistics按钮,展开统计量选择对话框,选择描述统计量Means,Univariate ANOVAs,函数选择Fisher函数和Unstandardized (非标准化函数),矩阵选择Within-groups correlation,单击Continue返回主对话框。
(5)在主对话框中单击classify按钮,展开分类选择对话框,选择先验概率(All groups equal,所有组相等或根据组的大小计算概率);子选项(display)中选择每个个体的结果(Casewise results),综合表(Summary Table)和“留一个在外”(Leave-one-out classification)的验证原则;协方差矩阵选择Within-groups;作图选择Combined-groups。
多元统计分析_判别分析实验报告一、实验目的本实验旨在通过对一组数据进行判别分析,了解判别分析的基本原理和应用过程,掌握判别分析的实现方法并运用MATLAB软件进行实现。
二、实验原理判别分析是一种分类方法,用于将已知的样本分类到已知类别中。
判别分析的目的是找到一个统计模型,通过对样本进行观测和测量,能够把它们判别为若干类别中的一种。
在判别分析中,样本数据是由多个指标组成,每个指标都是一个随机变量。
在多元统计中,这些指标被称为变量。
判别函数是一个用于将样本分类的函数,它以样本的多个变量作为输入,并输出该样本属于哪一类的分类决策。
判别函数的形式取决于所使用的判别方法。
判别分析中最重要的判别方法是线性判别分析。
线性判别分析是一种找到最佳线性分类器的方法。
在线性判别分析中,样本被认为是由每个变量线性组合而成,各个变量之间存在某种相关性。
判别分析的目标是找到一条分割两个类别的直线,使得该直线上或下的样本属于不同的类别。
这条直线被称为判别函数。
对于一个具有p个指标的样本,判别函数可以通过下式计算得到:$g_j(x)=x^T\hat{a_j}+\hat{a}_{j0}$其中,j表示第j个判别函数,x是一个向量,包含了样本各个指标的取值,$\hat{a_j}$是一个向量,表示样本各个变量在第j个判别函数中的系数,$\hat{a}_{j0}$是一个截距项。
在线性判别分析中,判别函数的系数可以通过最小平方判别函数系数估计公式获得:$\hat{a_j}=(\sum_{i=1}^{n_j}(x_i-\bar{x_j})(x_i-\bar{x_j})^T)^{-1}(\bar{x_1}-\ bar{x_2})$其中,$\bar{x_1}=\frac{1}{n_1}\sum_{i=1}^{n_1}x_i$n1和n2分别是两个类别的样本数。
三、实验步骤1. 导入数据并分别计算两个类别数据的均值和协方差矩阵。
2. 计算最佳线性判别函数,并作图展示判别平面和两个类别的分布情况。
实验课程名称: __多元统计分析--判别分析___准则判别归类,则可写成:⎪⎩⎪⎨⎧=>∈<∈),(),( ,),(),(,),(),(,21212211G X D G X D G X D G X D G X G X D G X D G X 当待判当当题目:表11.5的数据包含三种鸢尾的X2=萼片宽度与X4=花瓣的宽度的观测值。
对每种鸢尾有n1=n2=n3=50个观测值。
部分数据:第二部分:实验过程记录(可加页)(包括实验原始数据记录,实验现象记录,实验过程发现的问题等)散点图:图形→旧对话框→散点图,打开简单散点图子对话框;将想X2选入X轴变量,X4选入Y轴变量,将总体选入设置标记框中,点击确定。
判别分析:步骤:1、选择分析→分类→判别,打开判别分析子对话框。
2、选择变量“总体”,单击→,将其加入到分组变量栏中。
3、打开定义范围子对话框,最小值输入1,最大值输入3。
4、将变量“X2萼片宽度”、“X4花瓣的宽度”选入自变量栏中。
选择“一起输入自变量”的方法。
5、打开统计变量子对话框,选择均值、单变量ANOVA、Box’M、未标准化、组内协方差、分组协方差及总体协方差,单击继续。
6、打开分类子对话框,选择不考虑该个案时的分类,其余为默认值。
7、打开保存,选择所有的变量。
相关系数矩阵a总体萼片宽度X2 花瓣宽度X4合计萼片宽度X2 .190 -.122花瓣宽度X4 -.122 .581对数行列式总体秩对数行列式1 2 -6.4962 2 -6.1413 2 -5.189汇聚的组内 2 -5.583检验结果箱的M 52.832F 近似。
8.632df1 6df2 538562.769Sig. .000Wilks 的Lambda函数检验Wilks 的Lambda 卡方df Sig.1 到2 .038 477.868 4 .0002 .809 31.075 1 .000典型判别式函数系数函数1 2萼片宽度X2 -1.987 2.680花瓣宽度X4 5.477 .817(常量) -.494 -9.174非标准化系数组质心处的函数总体函数1 21 -5.958 .2152 1.265 -.6673 4.693 .452分类结果b,c总体预测组成员1 2 3 合计初始计数 1 50 0 0 502 0 49 1 503 04 46 50% 1 100.0 .0 .0 100.02 .0 98.0 2.0 100.03 .0 8.0 92.0 100.0 交叉验证a计数 1 50 0 0 502 0 48 2 503 04 46 50% 1 100.0 .0 .0 100.02 .0 96.0 4.0 100.03 .0 8.0 92.0 100.0。
可编辑修改精选全文完整版实验报告5判别分析(设计性实验)(Discriminant analysis)实验原理:判别分析是判别样品所属类型的一种统计方法。
判别分析是在已知研究对象分成若干类型(或组别)并已取得各种类型的一批已知样品的观测数目,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类。
本实验要求学生应用距离判别准则(即,对任给的一次观测,若它与第i类的重心距离最近,就认为它来自第i类),对两总体和多总体情形下分别进行判别分析。
实验中需注意协方差矩阵相等时,选取线性判别函数;协方差矩阵不相等时,应选取二次判别函数。
实验题目一:为了检测潜在的血友病A携带者,下表中给出了两组数据:(t11a8)其中x1=log10(AHF activity),x2=log10(AHF antigen)。
下表给出了五个新的观测,试对这些观测判别归类;(t11b8)实验要求:(1)分别检验两组数据是否大致满足二元正态性;(2)分别计算两组数据的协方差矩阵,是否可以认为两者近似相等?(3)对训练样本和新观测合并作散点图,不同的类用不同颜色标识;(4)用lda函数做判别分析,即在协方差矩阵相等的情形下作判别分析;(5)用qda函数做判别分析,即在协方差矩阵不相等的情形下作判别分析;(6)比较方法(4)和方法(5)的误判率。
实验题目二:某商学研究生院的招生官员利用指标――大学期间平均成绩GPA和研究生管理能力考试GMAT的成绩,将申请者分为三类:接受,不接受,待定。
下表中给出了三类申请者的GPA与GMAT成绩:(t11a6)GPA (x1)GMAT(x2)接受GPA(x1)GMAT(x2)不接受GPA(x1)GMAT(x2)待定2.96 596 1 2.54 446 2 2.86 494 33.14 473 1 2.43 425 2 2.85 496 3 3.22 482 1 2.2 474 2 3.14 419 3 3.29 527 1 2.36 531 2 3.28 371 3 3.69 505 1 2.57 542 2 2.89 447 3 3.46 693 1 2.35 406 2 3.15 313 3 3.03 626 1 2.51 412 2 3.5 402 3 3.19 663 1 2.51 458 2 2.89 485 3 3.63 447 1 2.36 399 2 2.8 444 33.59 588 1 2.36 482 2 3.13 416 33.3 563 1 2.66 420 2 3.01 471 33.4 553 1 2.68 414 2 2.79 490 33.5 572 1 2.48 533 2 2.89 431 33.78 591 1 2.46 509 2 2.91 446 33.44 692 1 2.63 504 2 2.75 546 33.48 528 1 2.44 336 2 2.73 467 33.47 552 1 2.13 408 2 3.12 463 33.35 520 1 2.41 469 2 3.08 440 33.39 543 1 2.55 538 2 3.03 419 33.28 523 1 2.31 505 2 3 509 33.21 530 1 2.41 489 2 3.03 438 33.58 564 1 2.19 411 2 3.05 399 33.33 565 1 2.35 321 2 2.85 483 33.4 431 1 2.6 394 2 3.01 453 33.38 605 1 2.55 528 2 3.03 414 33.26 664 1 2.72 399 2 3.04 446 33.6 609 1 2.85 381 23.37 559 1 2.9 384 23.8 521 13.76 646 13.24 467 1实验要求:(1)对上表中的数据作散点图,不同的类用不同的颜色标识;(2)用lda函数做判别分析,即在协方差矩阵相等的情形下作判别分析;(3)用qda函数做判别分析,即在协方差矩阵不相等的情形下作判别分析;(4)比较方法(2)和方法(3)的误判率;(5)现有一新申请者的GPA为3.21,GMAT成绩为497。
页眉2015——2016学年第一学期实验报告课程名称:多元统计分析实验项目:判别分析设计性□验证性□实验类别:综合性□√专业班级:姓名:学号:实验地点:统计与金融创新实验室(新60801) 实验时间:指导教师:曹老师成绩:数学与统计学院实验中心制页脚一、实验目的统计《spss 让学生掌握判别分析的基本步骤和分析方法;学习的内容,掌握一般判别分析与逐分析从入门到精通》P307-P320步判别分析方法。
二、实验内容,掌》应用《胃病患者的测量数据》和《表征企业类型的数据.sav、1统计分析从spss握一般判别分析与逐步判别分析方法。
数据来源于《章的数据。
入门到精通数据文件》第12的数据进行分析,数据见文件《何晓群多元统计2、参考教材例4-2 》中的例4-2new。
)分析(数据三、实验方案(程序设计说明)四、程序运行结果1. (1)分析案例处理摘要未加权案例N百分比93.3 14 有效6.7 缺失或越界组代码1.0 至少一个缺失判别变量0.0排除的缺失或越界组代码还有至少0一个缺失判别变量6.7 合计1100.015合计组统计量1N(列表状态)类别均值标准差有效的未加权的已加权的5.000 188.60 57.138 5 铜蓝蛋白5.000 16.502 5 150.40 蓝色反应胃癌患者5.000 5.933 5 尿吲哚乙酸13.805.000 13.323 5 中性琉化物20.004.000 47.500 4 铜蓝蛋白156.254.000 118.75 14.104 4 蓝色反应萎缩性胃炎4.000 1.732 4 尿吲哚乙酸7.504.000 8.386 4 中性琉化物14.505.000 33.801 5 铜蓝蛋白151.005.000 13.012 5 蓝色反应121.40 其他胃病5.000 1.871 5 尿吲哚乙酸5.005.000 5 中性琉化物8.00 7.31414.000 14 铜蓝蛋白165.93 46.78714.000 14 蓝色反应131.00 20.203 合计14.000 14 8.86 5.318 尿吲哚乙酸14.00010.72614中性琉化物14.14汇聚的组内矩阵a中性琉化物尿吲哚乙酸铜蓝蛋白蓝色反应158.682 -48.264 2217.995 -168.268 铜蓝蛋白-13.773 12.082 -168.268 214.832 蓝色反应协方差-8.273 14.891 -48.264 12.082 尿吲哚乙酸103.182-13.773-8.273中性琉化物158.68211。
a. 协方差矩阵的自由度为协方差矩阵中性琉化物尿吲哚乙酸类别铜蓝蛋白蓝色反应402.000 -103.350 3264.800 -711.300 铜蓝蛋白-39.750 272.300 9.100 蓝色反应-711.300 胃癌患者-25.000 35.200 -103.350 9.100 尿吲哚乙酸177.500 -39.750 -25.000 中性琉化物402.000-110.833-27.5002256.250铜蓝蛋白萎缩性胃炎138.750274.167 20.500 138.750 198.917 蓝色反应12.333 3.000 -27.500 20.500 尿吲哚乙酸70.333 74.167 12.333 中性琉化物-110.833117.500 144.500 -8.750 铜蓝蛋白1142.500-53.750 8.750 169.300 蓝色反应144.500 其他胃病-7.000 3.500 尿吲哚乙酸-8.750 8.75053.500-53.750-7.000中性琉化物117.500对数行列式对数行列式类别秩20.9434 胃癌患者.萎缩性胃炎.ba15.315 4 其他胃病20.1164汇聚的组内打印的行列式的秩和自然对数是组协方差矩阵的秩和自然对数。
< 4a. 秩案例太少无法形成非奇异矩阵b.检验结果a26.091 箱的M1.121 近似。
10 df1 F305.976df2.345Sig.对相等总体协方差矩阵的零假设进行检验。
有些协方差矩阵是奇异矩a.阵,因此一般程序不会起作用。
将相对非奇异组的汇聚组内协方差矩阵检验非奇异组。
其行列。
式的对数为21.390特征值3累积%正则相关性函数特征值方差的%.872 95.2 95.2 1 3.167a.370100.04.82.159a 2 个典型判别式函数。
a. 分析中使用了前的LambdaWilksSig.dfWilks 函数检验的卡方Lambda.060 14.958 8 1 到2 .207.7061.39823.863标准化的典型判别式函数系数函数 2 1-.295 .443 铜蓝蛋白-.753 .605 蓝色反应.532 .685 尿吲哚乙酸.668.347中性琉化物结构矩阵函数 2 1.309 .623尿吲哚乙酸*-.031 .229 铜蓝蛋白* .611 -.630蓝色反应* .527中性琉化物.294 *判别变量和标准化典型判别式函数之间的汇聚组间相关性按函数内相关性的绝对大小排序的变量。
每个变量和任意判别式函数间最大*.的绝对相关性4典型判别式函数系数函数 2 1-.006 .009 铜蓝蛋白-.051 .041 蓝色反应.138 .177 尿吲哚乙酸.066 .034 中性琉化物5.622-9.023(常量)非标准化系数组质心处的函数类别函数12胃癌患者2.092 -.072萎缩性胃炎-.825 .527其他胃病-1.431-.349在组均值处评估的非标准化典型判别式函数组的先验概率类别先验用于分析的案例未加权的已加权的胃癌患.35755.000萎缩性胃.28644.000其他胃.35755.000合1.0001414.000分类函数系数类别胃癌患者萎缩性胃炎其他胃病铜蓝蛋白.154.122.1225.649 .780 .629 蓝色反应.201 .865 .429 尿吲哚乙酸-.008 .131 .071 中性琉化物-50.128-81.468-50.292(常量)Fisher 的线性判别式函数区域图典则判别2函数 6.0 2.0 4.0 -4.0 -2.0 .0 -8.0 -6.0 8.0+---------+---------+---------+---------+---------+---------+---------+---------+21 8.0 ++21 II21 III 21I21 II21 II+ 6.0 + + + + + 21 ++21 II21 I2II322 21I21 I 3322I21 I 33222I33322+ 4.0 + + + + 21 + + + +21 I 33222I33322 I 21 I21 3322 II33222 I 216II 33322 21I2.0 + + 33222 + + 21 + + ++I 33322 21II 3322 21II 33222 21I33322 I * 21I21 33222 II+ 33322 + 21 + * + .0 + + ++I * 3322 21II 33221 I331 II31 II31 II-2.0 + + + + + + + 31 + +I 31II 31II 31II 31II 31I+ -4.0 + + + + 31 + + ++I 31II 31I7I 31II 31II 31I-6.0 + + + + + 31 + + ++I 31II 31I31 III 31 I31 II31 -8.0 +++---------+---------+---------+---------+---------+---------+---------+---------+-2.0 .0 6.0 4.0 2.0 -4.0 -6.0 -8.08.01 典则判别函数区域图中使用的符号组符号标签------------------- --- ------胃癌患者1 12 2 萎缩性胃炎3 其他胃病3* 表示一个组质心8分类结果a合计类别预测组成员其他胃病胃癌患者萎缩性胃炎5 1 0 胃癌患者44 1 萎缩性胃炎0 3 计数5 4 0 1 其他胃病1 0 0 1 未分组的案例初始100.0 .0 20.0 胃癌患者80.0100.0 25.0 萎缩性胃炎.0 75.0 %100.0 .0 20.0 80.0 其他胃病100.0 .0100.0未分组的案例.0已对初始分组案例中的78.6% 个进行了正确分类。
a.2.分析案例处理摘要9N百分比未加权案例93.5 29 有效6.5 2 缺失或越界组代码.0 0 至少一个缺失判别变量.0 0 排除的缺失或越界组代码还有至少一个缺失判别变量6.5 2 合计100.031合计组统计量N(列表状态)有效的Group均值标准差已加权的未加权的5.00053640.78267471732.344675348x14642002244005.0005666.639518083229.859408466x2203180594905.00051709.21054749423.831137448x34869707958705.0005586.681081039145.747543294x41593015.000353.2611211971334.939189865x55786008718405.000287.2928338245931.561032197x6583100183105.000269.6513056515814.191150933x7237300539905.0005260.86584182142.3036495598x8 56130 0031313.000131674.38215879524.988766483x1 780200 30904013.000157.79134124513335.326281081x22075007282713.00013917.158655004320.239807432x3 2 8602009127013.00090.364061532013316.399631349x4 104109544613.000210.96526196613541.528070391x52706001013.000 13 166.862761183353.446078647x6 509120 2605513.000 13 444.169265921173.205494866x7 747240 2933413.000 43.883878258513 122.832097828x8 04275 2359711.000 278.77147250311 1621.79674326x1 797100 28711011.000 67.846485790111 449.205466129x2 18630 7872011.000 212.78758683811 983.385217780x3 133250 5356011.000 47.325755156411 275.989397543x4 4249089720311.000 11 639.430727434117.404576993x5 389040 9123011.000 11 421.895272149119.130823552x6 343900 3098011.000 11 551.125263323128.834528404x7 794640 9250011.000 11 151.14600667730.6171649538x8 52978 6363429.000899.229366421291993.47053840x185200056197029.000184.75806678429 435.644805927x27141508655529.00029 415.2818907261078.83974648x357530075710029.00029 347.671861576141.448775178x460985083010合计29.000355.905561478715.45858159329 x5 2517005363029.000271.96673299829 479.084557829x6 3018400590029.00029 548.535658903216.413198176x7 4338007134029.00029 157.37077773562.4306393737x8 9121038218组均值的均等性的检验11Sig.F df1 df2 的Wilks Lambda.000 .275 34.246 2 26 x1.001 .582 9.342 2 26 x2.000 26 .497 13.135 x3 2.000 26 .367 22.465 2 x4.000 26.371 2 26 x5 .330.000 20.396 2 26 x6 .389.002 7.871 2 26 x7 .623.00026x82.363对数行列式对数行列式秩Group.1 .ba68.643 2 866.156 3874.0548汇聚的组内打印的行列式的秩和自然对数是组协方差矩阵的秩和自然对数。