河南工业大学实验报告_实验三 查找和排序(一)——查找
- 格式:doc
- 大小:34.50 KB
- 文档页数:5

查找和排序算法实验报告一、实验目的本次实验的主要目的是深入理解和掌握常见的查找和排序算法,通过实际编程实现和性能比较,分析不同算法在不同数据规模和数据分布情况下的效率和优劣,为在实际应用中选择合适的算法提供依据。
二、实验环境本次实验使用的编程语言为 Python 3x,开发环境为 PyCharm。
实验中使用的操作系统为 Windows 10。
三、实验内容(一)查找算法1、顺序查找顺序查找是最基本的查找算法,从数组的一端开始,逐个比较元素,直到找到目标元素或遍历完整个数组。
```pythondef sequential_search(arr, target):for i in range(len(arr)):if arri == target:return ireturn -1```2、二分查找二分查找要求数组是已排序的。
通过不断将数组中间的元素与目标元素比较,缩小查找范围,直到找到目标元素或确定目标元素不存在。
```pythondef binary_search(arr, target):low = 0high = len(arr) 1while low <= high:mid =(low + high) // 2if arrmid == target:return midelif arrmid < target:low = mid + 1else:high = mid 1return -1```(二)排序算法1、冒泡排序冒泡排序通过反复比较相邻的元素并交换位置,将最大的元素逐步“浮”到数组的末尾。
```pythondef bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n i 1):if arrj > arrj + 1 :arrj, arrj + 1 = arrj + 1, arrj```2、插入排序插入排序将未排序的元素逐个插入到已排序的部分中,保持已排序部分始终有序。

查找和排序1.需求分析1.编写一个程序输出在顺序表{3,6,2,10,1,8,5,7,4,9}中采用顺序方法查找关键字5的过程;2.编写一个程序输出在顺序表{1,2,3,4,5,6,7,8,9,10}中采用顺序方法查找关键字9的过程;3.编写一个程序实现直接插入排序算法,并输出{9,8,7,6,5,4,3,2,1,0}的排序过程;4.编写一个程序实现快速排序算法,并输出{6,8,7,9,0,1,3,2,4,5}的排序过程2.系统设计1.静态查找表的抽象数据类型定义:ADT StaticSearchTable{数据对象D:D是具有相同特性的数据元素的集合。
各个数据元素均含有类型相同,可惟一标识数据元素的关键字数据关系R:数据元素同属一个集合基本操作P:Create(&ST,n)操作结果:构造一个含n个数据元素的静态查找表STDestroy(&ST)初始条件:静态查找表ST存在操作结果:销毁表STSearch(ST,key)初始条件:静态查找表ST存在,key为和关键字类型相同的给定值操作结果:若ST中存在其关键字等于key的数据元素,则函数值为该元素的值或在表中的位置,否则为“空”Traverse(ST,V isit())初始条件:静态查找表ST存在,Visit是对元素操作的应用函数操作结果:按某种次序对ST的每个元素调用函数Visit()一次且仅一次。
一旦Visit()失败,则操作失败}ADT StaticSearchTable3.调试分析(1)要在适当的位置调用Print函数,以正确显示排序过程中顺序表的变化(2)算法的时间复杂度分析:顺序查找:T(n)=O(n)折半查找:T(n)=O(logn)直接插入排序:T(n)=O(n2)快速排序:T(n)=O(nlogn)4.测试结果用需求分析中的测试数据顺序查找:顺序表3,6,2,10,1,8,5,7,4,9,查找5折半查找:顺序表1,2,3,4,5,6,7,8,9,10,查找9直接插入排序:顺序表9,8,7,6,5,4,3,2,1,0,从小到大排序快速排序:顺序表6,8,7,9,0,1,3,2,4,5,从小到大排序5.用户手册(1)输入表长;(2)依次输入建立顺序表;(3)查找:输入要查找的关键字(4)回车输出,查找为下标的移动过程;排序为顺序表的变化过程6.附录源程序:(1)顺序查找#include <stdio.h>#include <stdlib.h>#define ST_INIT_SIZE 200#define EQ(a,b) ((a)==(b))#define OVERFLOW -2typedef int KeyType;typedef struct{KeyType key;}ElemType;typedef struct{ElemType *elem;//数据元素存储空间基址,建表时按实际长度分配,0号单元留空int length;//表长度}SSTable;void InitST(SSTable &ST){ST.elem=(ElemType*)malloc(ST_INIT_SIZE*sizeof(ElemType));if(!ST.elem)exit(OVERFLOW);ST.length=0;}void CreateST(SSTable &ST){int i;printf("输入表长:");scanf("%d",&ST.length);for(i=1;i<=ST.length;i++)scanf("%d",&ST.elem[i].key);}void PrintST(SSTable ST){int i;for(i=1;i<=ST.length;i++)printf("%2d",ST.elem[i].key);printf("\n");}int Search_Seq(SSTable ST,KeyType key){//在顺序表ST中顺序查找其关键字等于key的数据元素//若找到则函数值为该元素在表中的位置,否则为0int i;ST.elem[0].key=key;printf("下标:");for(i=ST.length;!EQ(ST.elem[i].key,key);--i)printf("%d→",i);//从后往前找return i;}void main(){SSTable ST;KeyType key;InitST(ST);CreateST(ST);printf("顺序查找表:");PrintST(ST);printf("输入要查找的关键字:");scanf("%d",&key);int found=Search_Seq(ST,key);if(found)printf("找到,为第%d个数据\n",found);else printf("没有找到!\n");}(2)折半查找#include <stdio.h>#include <stdlib.h>#define ST_INIT_SIZE 200#define EQ(a,b) ((a)==(b))#define LT(a,b) ((a)<(b))#define OVERFLOW -2typedef int KeyType;typedef struct{KeyType key;}ElemType;typedef struct{ElemType *elem;//数据元素存储空间基址,建表时按实际长度分配,0号单元留空int length;//表长度}SSTable;void InitST(SSTable &ST){ST.elem=(ElemType*)malloc(ST_INIT_SIZE*sizeof(ElemType));if(!ST.elem)exit(OVERFLOW);ST.length=0;}void CreateST(SSTable &ST){int i;printf("输入表长:");scanf("%d",&ST.length);for(i=1;i<=ST.length;i++)scanf("%d",&ST.elem[i].key);}void PrintST(SSTable ST){int i;for(i=1;i<=ST.length;i++)printf("%2d",ST.elem[i].key);printf("\n");}int Search_Bin(SSTable ST,KeyType key){//在有序表ST中折半查找其关键字等于key的数据元素//若找到,则函数值为该元素在表中的位置,否则为0int low,high,mid;low=1;high=ST.length;//置区间初值printf("下标:");while(low<=high){mid=(low+high)/2;printf("%d→",mid);if(EQ(key,ST.elem[mid].key))return mid;//找到待查元素else if(LT(key,ST.elem[mid].key))high=mid-1;//继续在前半区间进行查找else low=mid+1;}return 0;//顺序表中不存在待查元素}void main(){SSTable ST;KeyType key;InitST(ST);CreateST(ST);printf("顺序查找表:");PrintST(ST);printf("输入要查找的关键字:");scanf("%d",&key);int found=Search_Bin(ST,key);if(found)printf("找到,为第%d个数据\n",found);else printf("没有找到!\n");}(3)直接插入排序#include <stdio.h>#define MAXSIZE 20#define LT(a,b) ((a)<(b))typedef int KeyType;typedef struct{KeyType key;}RedType;//记录类型typedef struct{RedType r[MAXSIZE+1];//r[0]闲置或用作哨兵单元int length;//顺序表长度}SqList;//顺序表类型void CreateSq(SqList &L){int i;printf("输入表长:");scanf("%d",&L.length);for(i=1;i<=L.length;i++)scanf("%d",&L.r[i].key);}void PrintSq(SqList L){int i;for(i=1;i<=L.length;i++)printf("%2d",L.r[i].key);printf("\n");}void InsertSort(SqList &L){//对顺序表L作直接插入排序int i,j;printf("排序过程:\n");for(i=2;i<=L.length;++i){if(LT(L.r[i].key,L.r[i-1].key)){//"<",需将L.r[i]插入有序子表L.r[0]=L.r[i];//复制为哨兵L.r[i]=L.r[i-1];for(j=i-2;LT(L.r[0].key,L.r[j].key);--j)L.r[j+1]=L.r[j];//记录后移L.r[j+1]=L.r[0];//插入到正确位置}PrintSq(L);}}//InsertSortvoid main(){SqList L;CreateSq(L);printf("原始顺序表:");PrintSq(L);InsertSort(L);printf("排序后的顺序表:");PrintSq(L);}(4)快速排序#include <stdio.h>#define MAXSIZE 20typedef int KeyType;typedef struct{KeyType key;}RedType;//记录类型typedef struct{RedType r[MAXSIZE+1];//r[0]闲置或用作哨兵单元int length;//顺序表长度}SqList;//顺序表类型void CreateSq(SqList &L){int i;printf("输入表长:");scanf("%d",&L.length);for(i=1;i<=L.length;i++)scanf("%d",&L.r[i].key);}void PrintSq(SqList L){int i;for(i=1;i<=L.length;i++)printf("%2d",L.r[i].key);printf("\n");}int Partition(SqList &L,int low,int high){//交换顺序表L中子表r[low…high]的记录,枢轴记录到位,并返回其所在位置, //此时在它之前/后的记录均不大/小于它int pivotkey;L.r[0]=L.r[low];//用子表的第一个记录作枢轴记录pivotkey=L.r[low].key;//枢轴记录关键字while(low<high){//从表的两端交替地向中间扫描while(low<high&&L.r[high].key>=pivotkey)--high;L.r[low]=L.r[high];//将比枢轴记录小的记录移到低端while(low<high&&L.r[low].key<=pivotkey)++low;L.r[high]=L.r[low];//将比枢轴记录大的记录移到高端}L.r[low]=L.r[0];//枢轴记录到位PrintSq(L);return low;//返回枢轴位置}//Partitionvoid QSort(SqList &L,int low,int high){//对顺序表L中的子序列L.r[low…high]作快速排序int pivotloc;if(low<high){//长度大于1pivotloc=Partition(L,low,high);//将L.r[low…high]一分为二QSort(L,low,pivotloc-1);//对低子表递归排序,pivotloc是枢轴位置QSort(L,pivotloc+1,high);//对高子表递归排序}}//QSortvoid QuickSort(SqList &L){//对顺序表L作快速排序printf("排序过程:\n");QSort(L,1,L.length);}//QuickSortvoid main(){SqList L;CreateSq(L);printf("原始顺序表:");PrintSq(L);QuickSort(L);printf("快速排序后的顺序表:");PrintSq(L);}。

查找排序实验报告一、实验目的本次实验的主要目的是深入理解和比较不同的查找和排序算法在性能和效率方面的差异。
通过实际编程实现和测试,掌握常见查找排序算法的原理和应用场景,为今后在实际编程中能够选择合适的算法解决问题提供实践经验。
二、实验环境本次实验使用的编程语言为 Python,开发环境为 PyCharm。
计算机配置为:处理器_____,内存_____,操作系统_____。
三、实验内容1、查找算法顺序查找二分查找2、排序算法冒泡排序插入排序选择排序快速排序四、算法原理1、顺序查找顺序查找是一种最简单的查找算法。
它从数组的一端开始,依次比较每个元素,直到找到目标元素或者遍历完整个数组。
其时间复杂度为 O(n),在最坏情况下需要遍历整个数组。
2、二分查找二分查找适用于已排序的数组。
它通过不断将数组中间的元素与目标元素进行比较,将查找范围缩小为原来的一半,直到找到目标元素或者确定目标元素不存在。
其时间复杂度为 O(log n),效率较高。
3、冒泡排序冒泡排序通过反复比较相邻的两个元素并交换它们的位置,将最大的元素逐步“浮”到数组的末尾。
每次遍历都能确定一个最大的元素,经过 n-1 次遍历完成排序。
其时间复杂度为 O(n^2)。
4、插入排序插入排序将数组分为已排序和未排序两部分,每次从未排序部分取出一个元素,插入到已排序部分的合适位置。
其时间复杂度在最坏情况下为 O(n^2),但在接近有序的情况下性能较好。
5、选择排序选择排序每次从待排序数组中选择最小的元素,与当前位置的元素交换。
经过 n-1 次选择完成排序。
其时间复杂度为 O(n^2)。
6、快速排序快速排序采用分治的思想,选择一个基准元素,将数组分为小于基准和大于基准两部分,然后对这两部分分别递归排序。
其平均时间复杂度为 O(n log n),在大多数情况下性能优异。
五、实验步骤1、算法实现使用Python 语言实现上述六种查找排序算法,并分别封装成函数,以便后续调用和测试。

实验七查找、排序的应用一、实验目的1、本实验可以使学生更进一步巩固各种查找和排序的基本知识。
2、学会比较各种排序与查找算法的优劣。
3、学会针对所给问题选用最适合的算法。
4、掌握利用常用的排序与选择算法的思想来解决一般问题的方法和技巧。
二、实验内容[问题描述]对学生的基本信息进行管理。
[基本要求]设计一个学生信息管理系统,学生对象至少要包含:学号、姓名、性别、成绩1、成绩2、总成绩等信息。
要求实现以下功能:1.总成绩要求自动计算;2.查询:分别给定学生学号、姓名、性别,能够查找到学生的基本信息(要求至少用两种查找算法实现);3.排序:分别按学生的学号、成绩1、成绩2、总成绩进行排序(要求至少用两种排序算法实现)。
[测试数据]由学生依据软件工程的测试技术自己确定。
三、实验前的准备工作1、掌握哈希表的定义,哈希函数的构造方法。
2、掌握一些常用的查找方法。
1、掌握几种常用的排序方法。
2、掌握直接排序方法。
四、实验报告要求1、实验报告要按照实验报告格式规范书写。
2、实验上要写出多批测试数据的运行结果。
3、结合运行结果,对程序进行分析。
五、算法设计a、折半查找设表长为n,low、high和mid分别指向待查元素所在区间的下界、上界和中点,key为给定值。
初始时,令low=1,high=n,mid=(low+high)/2,让key与mid指向的记录比较,若key==r[mid].key,查找成功若key<r[mid].key,则high=mid-1若key>r[mid].key,则low=mid+1重复上述操作,直至low>high时,查找失败b、顺序查找从表的一端开始逐个进行记录的关键字和给定值的比较。
在这里从表尾开始并把下标为0的作为哨兵。
void chaxun(SqList &ST) //查询信息{ cout<<"\n************************"<<endl;cout<<"~ (1)根据学号查询 ~"<<endl;cout<<"~ (2)根据姓名查询 ~"<<endl;cout<<"~ (3)根据性别查询 ~"<<endl;cout<<"~ (4)退出 ~"<<endl;cout<<"************************"<<endl; if(m==1) 折半查找算法:for(int i=1;i<ST.length;i++)//使学号变为有序for(int j=i;j>=1;j--)if(ST.r[j].xuehao<ST.r[j-1].xuehao){LI=ST.r[j];ST.r[j]=ST.r[j-1];ST.r[j-1]=LI;}int a=0;cout<<"输入要查找的学号"<<endl;cin>>n;int low,high,mid;low=0;high=ST.length-1; // 置区间初值while (low<=high){mid=(low+high)/2;if(n==ST.r[mid].xuehao){cout<<ST.r[mid].xuehao<<""<<ST.r[mid].xingming<<""<<ST.r[mid].xingbei<<""<<ST.r[mid].chengji1<<""<<ST.r[mid].chengji2<<""<<ST.r[mid].zong<<endl;a=1;break;}else if(n<ST.r[mid].xuehao )high=mid-1; // 继续在前半区间进行查找elselow=mid+1; // 继续在后半区间进行查找顺序查找算法:cout<<"输入要查找的姓名"<<endl;cin>>name;for(int i=0;i<ST.length;i++){if(name==ST.r[i].xingming){cout<<ST.r[i].xuehao<<""<<ST.r[i].xingming<<""<<ST.r[i].xingbei<<""<<ST.r[i].chengji1<<""<<ST.r[i].chengji2<<""<<ST.r[i].zong<<endl;a=1;}1、插入排序每步将一个待排序的记录,按其关键码大小,插入到前面已经排好序的一组记录的适当位置上,直到记录全部插入为止。

实验四:查找与排序【实验目的】1.掌握顺序查找算法的实现。
2.掌握折半查找算法的实现。
【实验内容】1.编写顺序查找程序,对以下数据查找37所在的位置。
5,13,19,21,37,56,64,75,80,88,922.编写折半查找程序,对以下数据查找37所在的位置。
5,13,19,21,37,56,64,75,80,88,92【实验步骤】1.打开VC++。
2.建立工程:点File->New,选Project标签,在列表中选Win32 ConsoleApplication,再在右边的框里为工程起好名字,选好路径,点OK->finish。
至此工程建立完毕。
3.创建源文件或头文件:点File->New,选File标签,在列表里选C++ SourceFile。
给文件起好名字,选好路径,点OK。
至此一个源文件就被添加到了你刚创建的工程之中。
4.写好代码5.编译->链接->调试#include "stdio.h"#include "malloc.h"#define OVERFLOW -1#define OK 1#define MAXNUM 100typedef int Elemtype;typedef int Status;typedef struct{Elemtype *elem;int length;}SSTable;Status InitList(SSTable &ST ){int i,n;ST.elem = (Elemtype*) malloc (MAXNUM*sizeof (Elemtype)); if (!ST.elem) return(OVERFLOW);printf("输入元素个数和各元素的值:");scanf("%d\n",&n);for(i=1;i<=n;i++){scanf("%d",&ST.elem[i]);}ST.length = n;return OK;}int Seq_Search(SSTable ST,Elemtype key){int i;ST.elem[0]=key;for(i=ST.length;ST.elem[i]!=key;--i);return i;}int BinarySearch(SSTable ST,Elemtype key){int low,high,mid;low=1;high=ST.length;while(low<=high){mid=(low+high)/2;if(ST.elem[mid]==key)return mid;else if(key<ST.elem[mid])high=mid-1;elselow=mid+1;}return 0;}void main(){int key;SSTable ST;InitList(ST);printf("输入查找的元素的值:");scanf("%d",&key);Seq_Search(ST,key);printf("查找的元素所在的位置:%d\n",Seq_Search(ST,key));printf("输入查找的元素的值:");scanf("%d",&key);BinarySearch(ST,key);printf("查找的元素所在的位置:%d\n",BinarySearch(ST,key));}【实验心得】这是本学期的最后一节实验课,实验的内容是查找与排序。

排序和查找的实验报告实验报告:排序和查找引言排序和查找是计算机科学中非常重要的基本算法。
排序算法用于将一组数据按照一定的顺序排列,而查找算法则用于在已排序的数据中寻找特定的元素。
本实验旨在比较不同排序和查找算法的性能,并分析它们的优缺点。
实验设计为了比较不同排序算法的性能,我们选择了常见的几种排序算法,包括冒泡排序、插入排序、选择排序、快速排序和归并排序。
我们使用相同的随机数据集对这些算法进行了测试,并记录了它们的执行时间和占用空间。
在查找算法的比较实验中,我们选择了顺序查找和二分查找两种常见的算法。
同样地,我们使用相同的随机数据集对这些算法进行了测试,并记录了它们的执行时间和占用空间。
实验结果在排序算法的比较实验中,我们发现快速排序和归并排序在大多数情况下表现最好,它们的平均执行时间和空间占用都要优于其他排序算法。
而冒泡排序和插入排序则表现较差,它们的执行时间和空间占用相对较高。
在查找算法的比较实验中,二分查找明显优于顺序查找,尤其是在数据规模较大时。
二分查找的平均执行时间远远小于顺序查找,并且占用的空间也更少。
结论通过本实验的比较,我们得出了一些结论。
首先,快速排序和归并排序是较优的排序算法,可以在大多数情况下获得较好的性能。
其次,二分查找是一种高效的查找算法,特别适用于已排序的数据集。
最后,我们也发现了一些排序和查找算法的局限性,比如冒泡排序和插入排序在大数据规模下性能较差。
总的来说,本实验为我们提供了对排序和查找算法性能的深入了解,同时也为我们在实际应用中选择合适的算法提供了一定的参考。
希望我们的实验结果能够对相关领域的研究和应用有所帮助。

河南工业大学实验报告课程数据结构 _ 实验名称实验六:内部排序院系_国际高等技术学院__ 专业班级__ 国计1005班_____ 实验地点 513-2机房姓名____王普花__ 学号__201038940532 实验时间 12月6日指导老师王云侠实验成绩批改日期一.实验目的1.熟悉相关的排序算法二.实验内容及要求1.实现两种排序算法三.实验过程及结果#include <malloc.h>#include<stdio.h>#define N 11/*冒泡排序法*/void mpsort(int array[]){int i,j,a;a=0;for(i=1;i<N;i++)for(j=i+1;j<N;j++)if(array[i]>array[j]){a=array[i];array[i]=array[j];array[j]=a;}}/*直接插入排序*/void insertsort(int array[]){int i,j;for(i=2;i<N;i++){array[0]=array[i];j=i-1;while(array[0]<array[j]){array[j+1]=array[j--];array[j+1]=array[0];}}}/*建立*/void creat(int array[]){int i;printf("请输入一列数: ");for(i=1;i<N;i++)scanf("%d",&array[i]);}/*显示*/void print(int array[]){int i;printf("排序后的结果是: ");for(i=1;i<N;i++)printf("%d ",array[i]);printf("\n");}main(){int a[11],i,x,chang;aga:printf(" 1:冒泡排序法 \n");printf(" 2:直接插入排序法 \n");printf(" 3:退出 \n");printf(" 请选择:");scanf("%d",&chang);switch (chang){case 1:{creat(a);insertsort(a);print(a);goto aga;}case 2:{creat(a);mpsort(a);print(a);goto aga;}case 3:{ printf("exit! \n");break;}default:{printf("Error! "); goto aga;} }}排序运行结果如图:四.实验中的问题及心得在设计的过程中遇到问题,可以说是困难重重,同时在设计过程中发现了自己的不足之处,对以前所学过的知识理解的不透彻,掌握的不够牢固,通过这次课程设计之后,一定把以前所学过的知识重新温故一下。

查找和排序实验报告
本实验主要针对以查找、排序算法为主要实现目标的软件开发,进行实验室研究。
实
验包括:冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、基数排序,
以及折半查找算法。
实验采用C语言编写,在完成以上排序以及查找方法的基础上,针对实验的工程要求,进行了性能分析,分析了算法空间复杂度以及时间复杂度。
通过首先采用循环方式,构建未排序数组,在此基础上,调用算法实现查找和排序。
也对不同算法进行对比分析,将数据量在100个至30000个之间进行测试。
结果表明:快速排序与希尔排序在时间复杂度方面具有最好的表现,而冒泡排序和选
择排序时间复杂度较高。
在空间复杂度方面,基数排序表现最佳,折半查找的空间复杂度
则比较可观。
在工程应用中,根据对不同排序算法的研究,可以更准确、有效地选择正确的算法实现,有效应用C语言搭建软件系统,提高软件应用效率。
(建议加入算法图)
本实验结束前,可以得出结论:
另外,也可以从这些研究中发现,在使用C语言实现软件系统时,应该重视算法支持
能力,以提高软件应用效率。
由于查找和排序算法在软件应用中占有重要地位,此次实验
对此有贡献,可为未来开发提供支持。
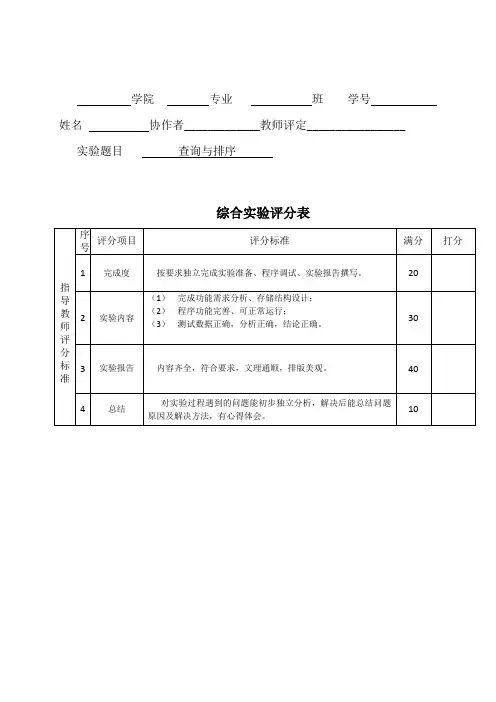
学院专业班学号姓名协作者_____________教师评定_________________实验题目查询与排序综合实验评分表实验报告一、实验目的与要求1、掌握散列表的构造及实现散列查找;2、掌握堆排序的算法;3、综合比较各类排序算法的性能。
二、实验内容#include""#include""#include""#include""#define MAX 20typedef struct{unsigned long key;int result;char name[30];}RNode;RNode t[MAX],r[MAX];int h(unsigned long k) /*散列函数*/{return((k-00)%11);}void insert(RNode t[],RNode x) /*插入函数,以线性探查方法解决冲突*/ {int i,j=0;i=h;while((j<MAX)&&(t[(i+j)%MAX].key!=&&(t[(i+j)%MAX].key>0))j++;if(j==MAX) printf("full\n");i=(i+j)%MAX;if(t[i].key==0){t[i]=x;}else{if(t[i].key==printf("记录已存在!\n");}}int search(RNode t[],unsigned long k) /*插入函数,以线性探查方法解决冲突*/{int i,j=0;i=h(k);while((j<MAX)&&(t[(i+j)%MAX].key!=k)&&(t[(i+j)%MAX].key!=0))j++;i=(i+j)%MAX;if(t[i].key==k)return(i);if(j==MAX)return MAX;elsereturn(-i);}void sift(RNode r[],int v,int w){int i,j;RNode a;i=v;a=r[i];j=2*i+1;while(j<=w){if((j<w)&&(r[j].result>r[j+1].result))j++;if>r[j].result){r[i]=r[j];i=j;j=2*j+1;}else break;}r[i]=a;}void sort(RNode r[],int n){int i;RNode y;for(i=n/2-1;i>=0;i--)sift(r,i,n-1);for(i=n-1;i>0;i--){y=r[0];r[0]=r[i];r[i]=y;printf("学生姓名:%s\t学生学号:%u\t学生成绩:%d\n",r[i].name,r[i].key,r[i].result);sift(r,0,i-1);}printf("学生姓名:%s\t学生学号:%u\t学生成绩:%d\n",r[0].name,r[0].key,r[0].result);}int menu() /*菜单函数*/{int select;printf("\n\n");printf("\n");printf("\t\t*************查找排序实验******************\n");printf("\t\t*\n");printf("\t\t*************欢迎进入系统******************\n");printf("\t\t* menu: *\n");printf("\t\t* 1.查找*\n");printf("\t\t* 2.排序*\n");printf("\t\t* 0.退出*\n");printf("\t\t*******************************************\n");printf("\n");printf("\t\t\t请输入0--2\n ");printf("\n");printf("请选择您所要的操作(选择(0)退出):");scanf("%d",&select);getchar();return(select);}void main() /*主函数*/{int i,s,n,select;int j=0,m=0;RNode y;for(i=0;i<MAX;i++)t[i].key=0; /*初始化*/for(i=0;i<10;i++) /*导入记录*/{switch(i){case 0:{RNode x;=310900***;strcpy," ***");=90;insert(t,x);break;}case 1:{RNode x;=31090***1;strcpy," ***");=95;insert(t,x);break;}case 2:{RNode x;=3109005***;strcpy," ***");=92;insert(t,x);break;}case 3:{RNode x;=31090***;strcpy," ***");=93;insert(t,x);break;}case 4:{RNode x;=3109005***;strcpy," ***");=94;insert(t,x);break;}case 5:{RNode x;=310900***;strcpy," ***");=91;insert(t,x);break;}case 6:{RNode x;=3109005***;strcpy," ***");=96;insert(t,x);break;}case 7:{RNode x;=310900***;strcpy," ***");=99;insert(t,x);break;}case 8:{RNode x;=310900***;strcpy," ***");=98;insert(t,x);break;}case 9:{RNode x;=310900***;strcpy,"***");=97;insert(t,x);break;}}}printf("\n\n\n\n\n\n\n");system("cls");loop:{printf("\n\n\n");select=menu();switch(select){case 1:{printf("\n请输入要查找的学生学号:");scanf("%u",&;s=search(t,;if(s==MAX||s<0) printf("not find\n");else{printf("\n\n你要查找的学生信息\n");printf("学生姓名:%s\t学生学号:%u",t[s].name,t[s].key);}break; }case 2:{for(i=0;i<MAX;i++){if(t[i].key!=0){r[j++]=t[i];m++;}}printf("排序之前:\n\n");for(i=0;i<m;i++)printf("学生姓名:%s\t学生学号:%u\t学生成绩:%d\n",r[i].name,r[i].key,r[i].result);printf("\n排序之后:\n");sort(r,m);break;}case 0:exit(0);}getchar();goto loop;}}三、实验结果和数据处理(1)查找数据(310900****)(2)排序四、总结这次的课程实验完成了主控界面,录入,输出,排序,查找,结束界面等功能。

一、实验目的本次实验旨在通过编写程序实现查找和排序算法,掌握基本的查找和排序方法,了解不同算法的优缺点,提高编程能力和数据处理能力。
二、实验内容1. 查找算法本次实验涉及以下查找算法:顺序查找、二分查找、插值查找。
(1)顺序查找顺序查找算法的基本思想是从线性表的第一个元素开始,依次将线性表中的元素与要查找的元素进行比较,若找到相等的元素,则查找成功;若线性表中所有的元素都与要查找的元素进行了比较但都不相等,则查找失败。
(2)二分查找二分查找算法的基本思想是将待查找的元素与线性表中间位置的元素进行比较,若中间位置的元素正好是要查找的元素,则查找成功;若要查找的元素比中间位置的元素小,则在线性表的前半部分继续查找;若要查找的元素比中间位置的元素大,则在线性表的后半部分继续查找。
重复以上步骤,直到找到要查找的元素或查找失败。
(3)插值查找插值查找算法的基本思想是根据要查找的元素与线性表中元素的大小关系,估算出要查找的元素应该在大致的位置,然后从这个位置开始进行查找。
2. 排序算法本次实验涉及以下排序算法:冒泡排序、选择排序、插入排序、快速排序。
(1)冒泡排序冒泡排序算法的基本思想是通过比较相邻的元素,将较大的元素交换到后面,较小的元素交换到前面,直到整个线性表有序。
(2)选择排序选择排序算法的基本思想是在未排序的序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
以此类推,直到所有元素均排序完毕。
(3)插入排序插入排序算法的基本思想是将一个记录插入到已排好序的有序表中,从而得到一个新的、记录数增加1的有序表。
(4)快速排序快速排序算法的基本思想是选择一个元素作为基准元素,将线性表分为两个子表,一个子表中所有元素均小于基准元素,另一个子表中所有元素均大于基准元素,然后递归地对两个子表进行快速排序。
三、实验结果与分析1. 查找算法通过实验,我们发现:(1)顺序查找算法的时间复杂度为O(n),适用于数据量较小的线性表。

排序查找实验报告排序查找实验报告一、引言排序和查找是计算机科学中非常重要的基础算法。
排序算法可以将一组无序的数据按照某种规则重新排列,而查找算法则可以在大量数据中快速找到目标元素。
本实验旨在通过实际操作和观察,对比不同的排序和查找算法的性能和效果,以便更好地理解和应用这些算法。
二、实验目的本实验的主要目的有以下几点:1. 理解不同排序算法的原理和特点;2. 掌握不同排序算法的实现方法;3. 比较不同排序算法之间的性能差异;4. 理解不同查找算法的原理和特点;5. 掌握不同查找算法的实现方法;6. 比较不同查找算法之间的性能差异。
三、实验过程1. 排序算法实验在排序算法实验中,我们选择了冒泡排序、选择排序和快速排序三种常见的排序算法进行比较。
首先,我们编写了一个随机生成一组无序数据的函数,并将其作为排序算法的输入。
然后,分别使用冒泡排序、选择排序和快速排序对这组数据进行排序,并记录下每种算法的执行时间。
最后,我们比较了三种算法的执行效率和排序结果的准确性。
2. 查找算法实验在查找算法实验中,我们选择了顺序查找、二分查找和哈希查找三种常见的查找算法进行比较。
首先,我们编写了一个生成有序数据的函数,并将其作为查找算法的输入。
然后,分别使用顺序查找、二分查找和哈希查找对这组数据进行查找,并记录下每种算法的执行时间。
最后,我们比较了三种算法的执行效率和查找结果的准确性。
四、实验结果1. 排序算法实验结果经过实验比较,我们发现快速排序算法在大多数情况下具有最好的性能表现,其平均时间复杂度为O(nlogn)。
冒泡排序算法虽然简单,但其时间复杂度为O(n^2),在数据量较大时效率较低。
选择排序算法的时间复杂度也为O(n^2),但相对于冒泡排序,其交换次数较少,因此效率稍高。
2. 查找算法实验结果顺序查找算法是最简单的一种查找算法,其时间复杂度为O(n),适用于小规模数据的查找。
二分查找算法的时间复杂度为O(logn),适用于有序数据的查找。
查找和排序实验报告查找和排序实验报告一、引言查找和排序是计算机科学中非常重要的基础算法之一。
查找(Search)是指在一组数据中寻找目标元素的过程,而排序(Sort)则是将一组数据按照特定的规则进行排列的过程。
本实验旨在通过实际操作和实验验证,深入理解查找和排序算法的原理和应用。
二、查找算法实验1. 顺序查找顺序查找是最简单的查找算法之一,它的基本思想是逐个比较待查找元素与数据集合中的元素,直到找到目标元素或遍历完整个数据集合。
在本实验中,我们设计了一个包含1000个随机整数的数据集合,并使用顺序查找算法查找指定的目标元素。
实验结果显示,顺序查找的时间复杂度为O(n)。
2. 二分查找二分查找是一种高效的查找算法,它要求待查找的数据集合必须是有序的。
二分查找的基本思想是通过不断缩小查找范围,将待查找元素与中间元素进行比较,从而确定目标元素的位置。
在本实验中,我们首先对数据集合进行排序,然后使用二分查找算法查找指定的目标元素。
实验结果显示,二分查找的时间复杂度为O(log n)。
三、排序算法实验1. 冒泡排序冒泡排序是一种简单但低效的排序算法,它的基本思想是通过相邻元素的比较和交换,将较大(或较小)的元素逐渐“冒泡”到数列的一端。
在本实验中,我们设计了一个包含1000个随机整数的数据集合,并使用冒泡排序算法对其进行排序。
实验结果显示,冒泡排序的时间复杂度为O(n^2)。
2. 插入排序插入排序是一种简单且高效的排序算法,它的基本思想是将数据集合分为已排序和未排序两部分,每次从未排序部分选择一个元素插入到已排序部分的适当位置。
在本实验中,我们使用插入排序算法对包含1000个随机整数的数据集合进行排序。
实验结果显示,插入排序的时间复杂度为O(n^2)。
3. 快速排序快速排序是一种高效的排序算法,它的基本思想是通过递归地将数据集合划分为较小和较大的两个子集合,然后对子集合进行排序,最后将排序好的子集合合并起来。
第1篇一、实验目的1. 熟悉常见的查找和排序算法。
2. 分析不同查找和排序算法的时间复杂度和空间复杂度。
3. 比较不同算法在处理大数据量时的性能差异。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.73. 开发工具:PyCharm三、实验内容1. 实现以下查找和排序算法:(1)查找算法:顺序查找、二分查找(2)排序算法:冒泡排序、选择排序、插入排序、快速排序、归并排序2. 分析算法的时间复杂度和空间复杂度。
3. 对不同算法进行性能测试,比较其处理大数据量时的性能差异。
四、实验步骤1. 实现查找和排序算法。
2. 分析算法的时间复杂度和空间复杂度。
3. 创建测试数据,包括小数据量和大数据量。
4. 对每种算法进行测试,记录运行时间。
5. 分析测试结果,比较不同算法的性能。
五、实验结果与分析1. 算法实现(1)顺序查找def sequential_search(arr, target): for i in range(len(arr)):if arr[i] == target:return ireturn -1(2)二分查找def binary_search(arr, target):low, high = 0, len(arr) - 1while low <= high:mid = (low + high) // 2if arr[mid] == target:return midelif arr[mid] < target:low = mid + 1else:high = mid - 1return -1(3)冒泡排序def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j](4)选择排序def selection_sort(arr):n = len(arr)for i in range(n):min_idx = ifor j in range(i+1, n):if arr[min_idx] > arr[j]:min_idx = jarr[i], arr[min_idx] = arr[min_idx], arr[i](5)插入排序def insertion_sort(arr):for i in range(1, len(arr)):key = arr[i]j = i-1while j >=0 and key < arr[j]:arr[j+1] = arr[j]j -= 1arr[j+1] = key(6)快速排序def quick_sort(arr):if len(arr) <= 1:pivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)(7)归并排序def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])return merge(left, right)def merge(left, right):result = []i = j = 0while i < len(left) and j < len(right):if left[i] < right[j]:result.append(left[i])i += 1else:result.append(right[j])result.extend(left[i:])result.extend(right[j:])return result2. 算法时间复杂度和空间复杂度分析(1)顺序查找:时间复杂度为O(n),空间复杂度为O(1)。
一、实验目的本次实验旨在通过实际操作,加深对排序和查找算法的理解,掌握几种常见的排序和查找方法,提高编程能力,并了解它们在实际应用中的优缺点。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 开发工具:PyCharm三、实验内容1. 排序算法(1)冒泡排序冒泡排序是一种简单的排序算法,基本思想是通过相邻元素的比较和交换,逐步将较大的元素移动到序列的后面,较小的元素移动到序列的前面,直到整个序列有序。
(2)选择排序选择排序是一种简单直观的排序算法,基本思想是遍历整个序列,每次从剩余未排序的元素中找到最小(或最大)的元素,将其与未排序序列的第一个元素交换,然后继续在剩余未排序的元素中寻找最小(或最大)的元素。
(3)插入排序插入排序是一种简单直观的排序算法,基本思想是将一个记录插入到已经排好序的有序表中,从而得到一个新的、记录数增加1的有序表。
(4)快速排序快速排序是一种效率较高的排序算法,基本思想是选取一个基准值,将待排序序列分为两个子序列,一个子序列中所有元素都比基准值小,另一个子序列中所有元素都比基准值大,然后递归地对两个子序列进行快速排序。
2. 查找算法(1)顺序查找顺序查找是一种最简单的查找算法,基本思想是从线性表的第一个元素开始,依次将线性表中的元素与要查找的元素进行比较,若相等,则查找成功;若线性表中所有元素都与要查找的元素不相等,则查找失败。
(2)二分查找二分查找是一种效率较高的查找算法,基本思想是对于有序的线性表,通过将待查找元素与线性表中间的元素进行比较,逐步缩小查找范围,直到找到目标元素或查找失败。
四、实验结果与分析1. 排序算法分析(1)冒泡排序:时间复杂度为O(n^2),空间复杂度为O(1),稳定排序。
(2)选择排序:时间复杂度为O(n^2),空间复杂度为O(1),不稳定排序。
(3)插入排序:时间复杂度为O(n^2),空间复杂度为O(1),稳定排序。
查找、排序实验班级学号姓名一、实验目的1 掌握不同的查找和排序方法,并能用高级语言实现相应算法。
2 熟练掌握顺序查找和二分查找方法。
3 熟练掌握直接插入排序、选择排序、冒泡排序、快速排序。
二、实验内容1 创建给定的静态查找表。
表中共包含十条学生信息,信息如下:学号姓名班级C++ 数据结构1 王立03511 85 762 张秋03511 78 883 刘丽03511 90 794 王通03511 75 865 赵阳03511 60 716 李艳03511 58 687 钱娜03511 95 898 孙胜03511 45 602 使用顺序查找方法,从查找表中查找姓名为赵阳和王夏的学生。
如果查找成功,则显示该生的相关信息;如果查找不成功,则给出相应的提示信息。
3使用快速排序方法,对学生信息中的学号进行排序,然后使用二分查找方法,从查找表中查找学号为7和12的学生。
如果查找成功,则显示该生的相关信息;如果查找不成功,则给出相应的提示信息。
4 使用直接插入排序方法,对学生信息中的姓名进行排序。
输出排序前和排序后的学生信息表,验证排序结果。
5 使用选择排序方法,对学生信息中的C成绩进行排序。
输出排序前和排序后的学生信息表,验证排序结果。
6 使用冒泡排序方法,对学生信息中的数据结构成绩进行排序。
输出排序前和排序后的学生信息表,验证排序结果。
7 编写一个主函数,将上面函数连在一起,构成一个完整程序。
8 调试实验源程序并运行。
三、实验结果源程序代码:#include <iostream> using namespace std; #include <string>#include <iomanip> #define M 100 typedef string Keytype; typedef struct{Keytype classNum;Keytype name;int studentNum;int C;int structure;}Student;typedef struct{Student s[M];int length;}s_t;int creat(s_t *t,int Num){int i;t->length=Num;for(i=1;i<=t->length;i++){cout<<"请输入第"<<i<<"个学生的信息(学号,姓名,班级,C++,数据结构):"<<endl;cin>>t->s[i].studentNum>>t->s[i].n ame>>t->s[i].classNum>>t->s[i].C>>t->s [i].structure;}return 0;}int print(s_t *t){int i;cout<<" "<<"学号"<<" "<<"姓名"<<" "<<"班级"<<" "<<"C++成绩"<<" "<<"数据结构"<<" "<<endl;for(i=1;i<=t->length;i++){cout<<" "<<t->s[i].studentNum<<""<<t->s[i].name<<""<<t->s[i].classNum<<""<<t->s[i].C<<""<<t->s[i].structure<<" "<<endl;}return 0;}int S_Search(s_t *t,Keytype kx){int i;t->s[0].name=kx;for(i=t->length;i>=0;i--)if(t->s[i].name==kx)return i;}void InserSort(s_t *t){int i;for(i=2;i<=t->length;i++)if(t->s[i].name<t->s[i-1].name){t->s[0]=t->s[i];for(intj=i-1;t->s[0].name<t->s[j].name;j--)t->s[j+1]=t->s[j];t->s[j+1]=t->s[0];}}int Select_Sort(s_t *t){int i,j,k;for(i=0;i<t->length;i++){k=i;for(j=i+1;j<=t->length;j++)if(t->s[k].C>t->s[j].C)k=j;if(i!=k){t->s[0]=t->s[k];t->s[k]=t->s[i];t->s[i]=t->s[0];}}return 0;}int Half_Sort(s_t *t,int num){int flag=0;int low,high,mid;low=1;high=t->length;while(low<=high){mid=(low+high)/2;if(t->s[mid].studentNum>num)high=mid-1;elseif(t->s[mid].studentNum<num)low=mid+1;else{flag=mid;break;}}return flag;}int Bu_Sort(s_t *t){int i,j,swap;for(i=1;i<t->length;i++){swap=0;for(j=1;j<=t->length-i;j++)if(t->s[j].structure>t->s[j+1].structur e){t->s[0]=t->s[j];t->s[j]=t->s[j+1];t->s[j+1]=t->s[0];swap=1;}if(swap==0)break;}return 0;}int Partition(s_t *t,int i,int j){t->s[0]=t->s[i];while(i<j){while(i<j&&t->s[j].studentNum>=t->s[0] .studentNum)j--;if(i<j){t->s[i]=t->s[j];i++;}while(i<j&&t->s[i].studentNum<t->s[0].stude ntNum)i++;if(i<j){t->s[j]=t->s[i];j--;}}t->s[i]=t->s[0];return i;}void Quick_sort(s_t *t,int s,int p){int i;if(s<p){i=Partition(t,s,p);Quick_sort(t,s,i-1);Quick_sort(t,i+1,p);}}void Quick(s_t *t,int n){Quick_sort(t,1,n);}int main(){s_t *t;int i,n,n1,Num;int flag=1;Keytype kx;t=new s_t;cout<<" *********欢迎进入学生管理系统************** "<<endl;cout<<" 1 按姓名顺序查找2 输出所有学生信息 3 直接插入排序"<<endl;cout<<" 4 按C++选择排序5 按学号二分查找 6 按数据结构冒泡排序"<<endl;cout<<" 7 按学号快速排序8 建立学生的信息0 退出程序"<<endl;cout<<"********************************* *********** "<<endl;while(flag){cout<<"请选择要进行的操作:";cin>>n;switch(n){case 1:cout<<"请输入要查找的学生的姓名:"<<endl;cin>>kx;i=S_Search(t,kx);if(i){cout<<" "<<"学号"<<" "<<"姓名"<<" "<<"班级"<<" "<<"C++成绩"<<" "<<"数据结构"<<" "<<endl;cout<<""<<t->s[i].studentNum<<""<<t->s[i].name<<""<<t->s[i].classNum<<""<<t->s[i].C<<""<<t->s[i].structure<<" "<<endl;cout<<endl;}else cout<<"没有此人!"<<endl;break;case 2:cout<<"输出现在学生的全部信息:"<<endl;print(t);break;case 3:cout<<"直接插入排序:"<<endl;cout<<"排序前的学生信息"<<endl;print(t);cout<<"排序后的学生信息"<<endl;InserSort(t);print(t);break;case 4:cout<<"选择排序:"<<endl;cout<<"排序前的学生信息"<<endl;print(t);Select_Sort(t);cout<<"排序后的学生信息"<<endl;print(t);break;case 5:Select_Sort(t);cout<<"输入要查找的学号"<<endl;cin>>n1;i=Half_Sort(t,n1);if(i){cout<<" "<<"学号"<<" "<<"姓名"<<" "<<"班级"<<" "<<"C++成绩"<<" "<<"数据结构"<<" "<<endl;cout<<""<<t->s[i].studentNum<<""<<t->s[i].name<<""<<t->s[i].classNum<<""<<t->s[i].C<<""<<t->s[i].structure<<" "<<endl;cout<<endl;}else cout<<"不存在此学号!"<<endl;break;case 6:cout<<"冒泡排序"<<endl;cout<<"排序前的学生信息"<<endl;print(t);Bu_Sort(t);cout<<"排序后的学生信息"<<endl;print(t);break;case 7:cout<<""<<endl;print(t);cout<<""<<endl;Quick(t ,Num);print(t);break;case 8:cout<<"请输入学生的个数:";cin>>Num;creat(t,Num);break;case 0: return 0;default:cout<<"没有此功能,请选择正确的操作!"<<endl;break;}}return 0;} else cout<<"没人得此成绩!"<<endl;break;case 6:Bu_Sort(t);print(t);break;case 7:Quick(t ,Num);break;case 8:cout<<"请输入学生的个数:";cin>>Num;creat(t,Num);break;case 0: return 0;default:cout<<"没有此功能,请选择正确的操作!"<<endl;break;}}return 0;}运行结果:表1 输入学生信息表2 顺序查找方法表3 按姓名直接插入表4 按C成绩选择排序表5 按学号进行二分法查找表6 按数据结构成绩进行冒泡法排序四、实验总结(1)直接插入排序时,要明确后移的结束条件,以便进行正确插入。
查找与排序实验报告《查找与排序实验报告》摘要:本实验旨在通过不同的查找与排序算法对比分析它们的效率和性能。
我们使用了常见的查找算法包括线性查找、二分查找和哈希查找,以及排序算法包括冒泡排序、快速排序和归并排序。
通过实验数据的对比分析,我们得出了每种算法的优缺点和适用场景,为实际应用提供了参考依据。
1. 实验目的通过实验对比不同查找与排序算法的性能,分析它们的优缺点和适用场景。
2. 实验方法(1)查找算法实验:分别使用线性查找、二分查找和哈希查找算法,对含有一定数量元素的数组进行查找操作,并记录比较次数和查找时间。
(2)排序算法实验:分别使用冒泡排序、快速排序和归并排序算法,对含有一定数量元素的数组进行排序操作,并记录比较次数和排序时间。
3. 实验结果(1)查找算法实验结果表明,二分查找在有序数组中的查找效率最高,哈希查找在大规模数据中的查找效率最高。
(2)排序算法实验结果表明,快速排序在平均情况下的排序效率最高,归并排序在最坏情况下的排序效率最高。
4. 实验分析通过实验数据的对比分析,我们得出了以下结论:(1)查找算法:二分查找适用于有序数组的查找,哈希查找适用于大规模数据的查找。
(2)排序算法:快速排序适用于平均情况下的排序,归并排序适用于最坏情况下的排序。
5. 结论不同的查找与排序算法在不同的场景下有着不同的性能表现,选择合适的算法可以提高程序的效率和性能。
本实验为实际应用提供了参考依据,对算法的选择和优化具有一定的指导意义。
通过本次实验,我们深入了解了不同查找与排序算法的原理和性能,为今后的算法设计和优化工作提供了宝贵的经验和参考。
xxx大学实验报告课程名称数据结构实验项目实验三查找和排序(一)——查找院系信息学院计类系专业班级计类1501姓名学号指导老师日期批改日期成绩一实验目的1.掌握哈希函数——除留余数法的应用;2. 掌握哈希表的建立;3. 掌握冲突的解决方法;4. 掌握哈希查找算法的实现。
二实验内容及要求实验内容:已知一组关键字(19,14,23,1,68,20,84,27,55,11,10,79),哈希函数定义为:H(key)=key MOD 13, 哈希表长为m=16。
实现该哈希表的散列,并计算平均查找长度(设每个记录的查找概率相等)。
实验要求:1. 哈希表定义为定长的数组结构;2. 使用线性探测再散列或链地址法解决冲突;3. 散列完成后在屏幕上输出数组内容或链表;4. 输出等概率查找下的平均查找长度;5. 完成散列后,输入关键字完成查找操作,要分别测试查找成功与不成功两种情况。
注意:不同解决冲突的方法会使得平均查找长度不同,可尝试使用不同解决冲突的办法,比较平均查找长度。
(根据完成情况自选,但至少能使用一种方法解决冲突)三实验过程及运行结果#include <stdio.h>#include <stdlib.h>#include <string.h>#define hashsize 16#define q 13int sign=2;typedef struct Hash{int date; //值域int sign; //标记}HashNode;void compare(HashNode H[],int p,int i,int key[]) //线性冲突处理{p++;if(H[p].sign!=0){sign++;compare(H,p,i,key);}else{H[p].date=key[i];H[p].sign=sign;sign=2;}}void Hashlist(HashNode H[],int key[]){int p;for(int i=0;i<12;i++){p=key[i]%q;if(H[p].sign==0){H[p].date=key[i];H[p].sign=1;}elsecompare(H,p,i,key);}}int judge(HashNode H[],int num,int n) //查找冲突处理{n++;if(n>=hashsize) return 0;if(H[n].date==num){printf("位置\t 数据\n");printf("%d\t %d\n\n",n,H[n].date);return 1;}elsejudge(H,num,n);}int search(char num,HashNode H[]) //查找{int n;n= num % q;if(H[n].sign==0){printf("失败");return 0;}if(H[n].sign!=0&&H[n].date==num){printf("位置\t 数据\n");printf("%d\t %d\n\n",n,H[n].date);}else if(H[n].sign!=0&&H[n].date!=num){if(judge(H,num,n)==0) return 0;}return 1;}int main(void){int key[q]={19,14,23,1,68,20,84,27,55,11,10,79};float a=0;HashNode H[hashsize];for(int i=0;i<hashsize;i++)H[i].sign=0;Hashlist(H,key);printf("位置\t 数据\n\n");for(int i=0;i<hashsize;i++){if(H[i].sign!=0){printf("%d\t %d\n",i,H[i].date);}else{H[i].date=0;printf("%d\t %d\n",i,H[i].date);}}int num;printf("请输入查找数值(‘-1’查找完成):\n");for(int i=0;;i++){scanf("%d",&num);if(num==-1)break;if(search(num,H)==0)printf("不存在\n");}for(int i=0;i<hashsize;i++){printf("%d ",H[i].sign);a=a+H[i].sign;}printf("\n%2.0f",a);printf("平均查找长度:%0.2f\n",a/12);return 0;}四调试情况、设计技巧及体会首先得确定哈希函数,虽然冲突是无法避免的,但是我们应该选择合适的函数,减少冲突,最简单的可以采用开放定止法,出现冲突后,以原地址为基点再次寻找下一个地址。
xxx大学实验报告
课程名称数据结构实验项目实验三查找和排序(一)——查找
院系信息学院计类系专业班级计类1501 姓名学号
指导老师日期
批改日期成绩
一实验目的
1.掌握哈希函数——除留余数法的应用;
2. 掌握哈希表的建立;
3. 掌握冲突的解决方法;
4. 掌握哈希查找算法的实现。
二实验内容及要求
实验内容:已知一组关键字(19,14,23,1,68,20,84,27,55,11,10,79),哈希
函数定义为:H(key)=key MOD 13, 哈希表长为m=16。
实现该哈希表的散列,并
计算平均查找长度(设每个记录的查找概率相等)。
实验要求:1. 哈希表定义为定长的数组结构;2. 使用线性探测再散列或链
地址法解决冲突;3. 散列完成后在屏幕上输出数组内容或链表;4. 输出等概率
查找下的平均查找长度;5. 完成散列后,输入关键字完成查找操作,要分别测
试查找成功与不成功两种情况。
注意:不同解决冲突的方法会使得平均查找长度不同,可尝试使用不同解决
冲突的办法,比较平均查找长度。
(根据完成情况自选,但至少能使用一种方法
解决冲突)
三实验过程及运行结果
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define hashsize 16
#define q 13
int sign=2;
typedef struct Hash
{
int date; //值域
int sign; //标记
}HashNode;
void compare(HashNode H[],int p,int i,int key[]) //线性冲突处理{
p++;
if(H[p].sign!=0)
{
sign++;
compare(H,p,i,key);
}
else
{
H[p].date=key[i];
H[p].sign=sign;
sign=2;
}
}
void Hashlist(HashNode H[],int key[])
{
int p;
for(int i=0;i<12;i++)
{
p=key[i]%q;
if(H[p].sign==0)
{
H[p].date=key[i];
H[p].sign=1;
}
else
compare(H,p,i,key);
}
}
int judge(HashNode H[],int num,int n) //查找冲突处理
{
n++;
if(n>=hashsize) return 0;
if(H[n].date==num)
{
printf("位置\t 数据\n");
printf("%d\t %d\n\n",n,H[n].date);
return 1;
}
else
judge(H,num,n);
}
int search(char num,HashNode H[]) //查找
{
int n;
n= num % q;
if(H[n].sign==0)
{
printf("失败");
return 0;
}
if(H[n].sign!=0&&H[n].date==num)
{
printf("位置\t 数据\n");
printf("%d\t %d\n\n",n,H[n].date);
}
else if(H[n].sign!=0&&H[n].date!=num)
{
if(judge(H,num,n)==0) return 0;
}
return 1;
}
int main(void)
{
int key[q]={19,14,23,1,68,20,84,27,55,11,10,79};
float a=0;
HashNode H[hashsize];
for(int i=0;i<hashsize;i++)
H[i].sign=0;
Hashlist(H,key);
printf("位置\t 数据\n\n");
for(int i=0;i<hashsize;i++)
{
if(H[i].sign!=0)
{
printf("%d\t %d\n",i,H[i].date);
}
else
{
H[i].date=0;
printf("%d\t %d\n",i,H[i].date);
}
}
int num;
printf("请输入查找数值(‘-1’查找完成):\n");
for(int i=0;;i++)
{
scanf("%d",&num);
if(num==-1)
break;
if(search(num,H)==0)
printf("不存在\n");
}
for(int i=0;i<hashsize;i++)
{
printf("%d ",H[i].sign);
a=a+H[i].sign;
}
printf("\n%2.0f",a);
printf("平均查找长度:%0.2f\n",a/12);
return 0;
}
四调试情况、设计技巧及体会
首先得确定哈希函数,虽然冲突是无法避免的,但是我们应该选择合适的函数,减少冲突,最简单的可以采用开放定止法,出现冲突后,以原地址为基点再次寻找下一个地址。