MPI并行编程系列二快速排序
- 格式:doc
- 大小:26.50 KB
- 文档页数:6


快速排序算法的并行实现-回复题目:快速排序算法的并行实现引言:随着计算机硬件的发展和多核处理器的普及,并行计算已成为提高算法性能的重要手段之一。
快速排序算法以其高效的平均时间复杂度而闻名,然而,传统的串行实现方式可能无法充分发挥硬件资源的优势。
因此,本文将介绍快速排序算法的并行实现,旨在提高排序算法的效率。
第一部分:快速排序算法基本原理1.1 快速排序算法简介快速排序算法是一种基于比较的排序算法,通过将待排序序列分成两个子序列,然后分别对子序列进行排序,最后合并成有序序列。
其核心思想是通过选取一个基准元素,将小于基准元素的数移到基准元素的左边,大于基准元素的数移到基准元素的右边,从而实现排序。
1.2 快速排序算法步骤- 选择一个基准元素,通常为序列的第一个元素- 比较待排序元素与基准元素,将小于基准元素的元素移动到基准元素的左边,大于基准元素的元素移动到基准元素的右边- 递归地对基准元素左侧和右侧的子序列进行排序,直到每个子序列只包含一个元素或为空第二部分:串行实现快速排序算法快速排序的串行实现是最基本的实现方式,其核心思想是利用递归将待排序序列不断分割,直到基准元素左右的子序列长度为1或空。
第三部分:并行实现快速排序算法3.1 并行化选取基准元素传统的快速排序算法中,基准元素的选择对算法性能有很大的影响。
在并行实现中,可以通过并行化选取基准元素来加速算法的执行。
具体步骤如下:- 将待排序序列划分为多个子序列,并同时选取每个子序列的中间元素作为候选基准元素- 在多个候选基准元素中选择一个全局基准元素,可以采用并行化的选取方法,例如选择所有候选基准元素的中位数作为全局基准元素3.2 并行化快速排序递归调用在串行实现中,快速排序算法使用递归调用对子序列进行排序。
然而,在并行实现中,递归调用可能导致负载不均衡,因此需要进行并行化处理。
具体步骤如下:- 将待排序序列分成多个子序列,并为每个子序列创建一个任务- 并行地对每个子序列进行递归调用,并等待所有任务的完成- 最后,将所有子序列的结果进行合并,得到有序序列第四部分:并行实现的优势和注意事项4.1 并行实现的优势通过并行化快速排序算法,可以充分发挥多核处理器的优势,提高排序的速度和算法的效率。

3。
1实验目的与要求1、熟悉快速排序的串行算法2、熟悉快速排序的并行算法3、实现快速排序的并行算法3。
2 实验环境及软件单台或联网的多台PC机,Linux操作系统,MPI系统。
3.3实验内容1、快速排序的基本思想2、单处理机上快速排序算法3、快速排序算法的性能4、快速排序算法并行化5、描述了使用2m个处理器完成对n个输入数据排序的并行算法.6、在最优的情况下并行算法形成一个高度为log n的排序树7、完成快速排序的并行实现的流程图8、完成快速排序的并行算法的实现3.4实验步骤3.4。
1、快速排序(Quick Sort)是一种最基本的排序算法,它的基本思想是:在当前无序区R[1,n]中取一个记录作为比较的“基准”(一般取第一个、最后一个或中间位置的元素),用此基准将当前的无序区R[1,n]划分成左右两个无序的子区R[1,i-1]和R[i,n](1≤i≤n),且左边的无序子区中记录的所有关键字均小于等于基准的关键字,右边的无序子区中记录的所有关键字均大于等于基准的关键字;当R[1,i—1]和R[i,n]非空时,分别对它们重复上述的划分过程,直到所有的无序子区中的记录均排好序为止。
3.4.2、单处理机上快速排序算法输入:无序数组data[1,n]输出:有序数组data[1,n]Begincall procedure quicksort(data,1,n) Endprocedure quicksort(data,i,j)Begin(1) if (i<j) then(1。
1)r = partition(data,i,j)(1。
2)quicksort(data,i,r—1);(1.3)quicksort(data,r+1,j);end ifEndprocedure partition(data,k,l)Begin(1)pivo=data[l](2) i=k-1(3)for j=k to l—1 doif data[j]≤pivo theni=i+1exchange data[i] and data[j]end ifend for(4)exchange data[i+1] and data[l](5) return i+1End3.4.3、快速排序算法的性能主要决定于输入数组的划分是否均衡,而这与基准元素的选择密切相关。

基于MPI的分布式并行排序算法的实现(信息工程学院,计算机系,计算机科学与技术专业凌广杰)(学号:2000131031)内容提要:本论文采用MPI(Message Passing Interface)在由独立处理器构成的计算机网络上实现了一个称之为IPBPS(Interconnected Processor-Based Parallel Sorting)的分布式并行排序算法。
IPBPS算法是基于一个特定的网络拓扑结构上,它的实现主要分为并行计数排序与归并排序两大模块。
采用MPI来实现IPBPS算法,利用MPI消息传递的同步机制,很好地解决了不同处理器间消息传递的同步问题。
每个处理器运行相同的程序,运行时间也几乎相同,计算负载均匀分布在网络上的每个处理器中,因此并行加速比较高。
关键词:MPI,并行排序,并行程序设计,分布式程序设计教师点评:该论文基于消息传递的并行计算模型,在多台独立互联的计算机上采用MPI(消息传递接口)实现了IPBPS分布式并行排序算法。
针对该具体问题,在任务分配、进程通信与同步、以及采用MPI构建IPBPS算法基于的虚拟网络结构上提出了自己的设想与实现方案。
解决了在由多计算机构成的分布式计算平台上不同计算机之间计算负载的均分、通信与同步等问题。
该论文具有一定的创新性,对基于MPI的并行与分布式程序设计具有一定的示范作用。
论文的表达书写也比较好。
(点评教师:陆楠。
副教授)1. 引言排序计算是计算机应用中最基本的运算之一,在20世纪60年代的计算机厂家就估计,当他们把所有的顾客都考虑在内时,在他们的计算机上,将有超过25%的时间花在排序上[3]。
排序的重要性不言而喻,传统的串行排序算法的速度已不能满足用户的要求。
为了提高排序的速度,人们普遍转向了并行排序算法的研究。
目前大部分并行排序算法的研究都是基于共享内存的多处理器或流水(Pipeline)计算机上的,但由于多处理机中微处理器的个数非常有限且通过共享内存可同时传送和访问的数据也不可能很多。

MPI实现并⾏奇偶排序奇偶排序使⽤ MPI 实现奇偶排序算法,并且 MPI 进程只能向其相邻进程发送消息nprocs是进程数。
每个进程拥有独⽴的⼀块数据data[0 ~ block_len-1],组合起来为整个待排序的数组。
⽅法每个阶段排序之后不进⾏check此前,在每个阶段的奇偶排序进⾏完之后,都会进⾏⼀次进程之间的信息传递,以判断排序是否完成,这个过程要进⾏约3∗nprocs次的send/recv。
现在的优化是:总共只进⾏nprocs轮排序,不再进⾏check。
这样的话,即使是⽬前在最⼩编号进程中的元素,⽽它值较⼤,本应排序到最⼤编号进程中,也可以在nprocs轮中排到正确的位置。
这样之后,⼤约有⼏⼗ms的优化。
进程之间互相传递数据,然后进⾏优化后的归并在⼀个排序阶段中,相邻进程块互相发送⾃⼰的全部数据,之后在每个块内部将两个块的数据进⾏归并,但是只保留最⼩/最⼤的block_len 个元素,将其拷贝到⾃⼰的data上。
这样可以省掉⼀半的归并时间。
这样之后⼤约有100+ms的优化。
进程之间发送全部数据之前,先发送端点处的数据进程之间发送全部数据之前,先发送端点处的数据,判断左边进程中的最⼤元素是否⼩于等于右边进程中的最⼩元素,如果是,那么⽆需进⾏后续数据的发送和归并。
这样之后⼤约有⼏⼗ms的优化。
代码#include <algorithm>#include <cassert>#include <cstdio>#include <cstdlib>#include <mpi.h>#include <cmath>#include "worker.h"using namespace std;bool is_edge(int rank, bool odd_or_even, bool last_rank){if (odd_or_even == 0){return (rank & 1) == 0 && last_rank;}else{return rank == 0 || ((rank & 1) == 1 && last_rank);}}void merge_left(float *A, int nA, float *B, int nB, float *C){ //make sure C[nA-1] is availablefloat *p1 = A, *A_end = A + nA, *p2 = B, *B_end = B + nB, *p = C, *C_end = C + nA;while( p != C_end && p1 != A_end && p2 != B_end)*(p++) = ((*p1) <= (*p2)) ? *(p1++) : *(p2++);while( p != C_end )*(p++) = *(p1++);}void merge_right(float *A, int nA, float *B, int nB, float *C){float *p1 = A + nA , *p2 = B + nB , *p = C + nB;while( p != C && p1 != A && p2 != B )*(--p) = (*(p1-1) >= *(p2-1)) ? *(--p1) : *(--p2);while( p != C )*(--p) = *(--p2);}void Worker::sort() {//data[0, block_len)if (out_of_range) return ;std::sort(data, data + block_len);//先把当前进程数据排好序if (nprocs == 1) return ;bool odd_or_even = 0; // = 0: even; = 1: odd;float *cp_data = new float [block_len];float *adj_data = new float [ceiling(n, nprocs)];int limit = nprocs;while(limit--){if(is_edge(rank, odd_or_even, last_rank)){//边界情况,没有与其他进程存在于同⼀个进程块内}else if((rank & 1) == odd_or_even){ //receive infosize_t adj_block_len = std::min(block_len, n - (rank + 1) * block_len);MPI_Request request[2];MPI_Isend(data + block_len - 1, 1, MPI_FLOAT, rank + 1, 0, MPI_COMM_WORLD, &request[0]);MPI_Irecv(adj_data, 1, MPI_FLOAT, rank + 1, 1, MPI_COMM_WORLD, &request[1]);MPI_Wait(&request[0], MPI_STATUS_IGNORE);MPI_Wait(&request[1], MPI_STATUS_IGNORE); //发送端点数据if(data [block_len - 1] > adj_data[0]) {//此时两块之间存在未排好序的数据,需要排序MPI_Sendrecv(data, block_len, MPI_FLOAT, rank + 1, 0,adj_data, adj_block_len, MPI_FLOAT, rank + 1, 1, MPI_COMM_WORLD, MPI_STATUS_IGNORE); //互相交换数据// mergemerge_left(data, (int)block_len, adj_data, (int)adj_block_len, cp_data);//进⾏归并排序,取前block_len个数据返回到cp_data中memcpy(data, cp_data, block_len * sizeof(float)); //拷贝回data}}else if ((rank & 1) == !odd_or_even){ //send infosize_t adj_block_len = ceiling(n, nprocs);MPI_Request request[2];MPI_Isend(data, 1, MPI_FLOAT, rank - 1, 1, MPI_COMM_WORLD, &request[1]);MPI_Irecv(adj_data + adj_block_len - 1, 1, MPI_FLOAT, rank- 1, 0, MPI_COMM_WORLD, &request[0]);MPI_Wait(&request[1], MPI_STATUS_IGNORE);MPI_Wait(&request[0], MPI_STATUS_IGNORE);//发送端点数据if (adj_data[adj_block_len - 1] > data[0]){//此时两块之间存在未排好序的数据,需要排序MPI_Sendrecv(data, block_len, MPI_FLOAT, rank - 1, 1,adj_data, adj_block_len, MPI_FLOAT, rank - 1, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); //互相交换数据// mergemerge_right(adj_data, (int)adj_block_len, data, (int)block_len, cp_data);//进⾏归并排序,取前block_len个数据返回到cp_data中memcpy(data, cp_data, block_len * sizeof(float)); //拷贝回data}}odd_or_even ^= 1;}delete[] cp_data;delete[] adj_data;}实验数据n N× P耗时(ms)相对单进程的加速⽐1000000001×112728.32600011000000001×26754.229000 1.8841000000001×43559.514000 3.5761000000001×82007.818000 6.3391000000001×161340.7710009.4931000000002×16870.30200014.625Processing math: 100%。
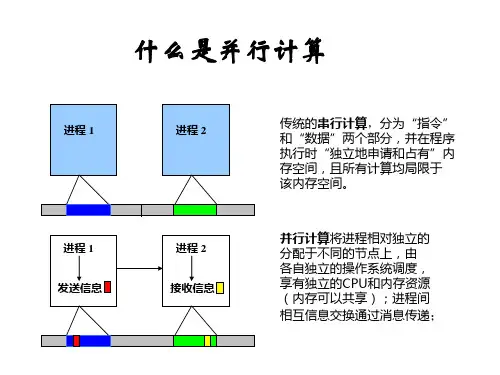



mpi并行计算代码MPI (Message Passing Interface) 是一种用于并行计算的规范,它定义了一组函数,这些函数可以在多个处理器之间传递消息。
以下是一个简单的MPI 代码示例,它使用了 MPI 的基本功能:```cinclude <>include <>int main(int argc, char argv) {// 初始化 MPI 环境MPI_Init(NULL, NULL);// 获取总的进程数量int world_size;MPI_Comm_size(MPI_COMM_WORLD, &world_size);// 获取当前进程的排名int world_rank;MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);// 获取当前进程的名字char processor_name[MPI_MAX_PROCESSOR_NAME];int name_len;MPI_Get_processor_name(processor_name, &name_len);// 打印一条消息printf("Hello world from processor %s, rank %d out of %d processors\n",processor_name, world_rank, world_size);// 清理 MPI 环境MPI_Finalize();}```这个程序首先初始化了 MPI 环境,然后获取了总的进程数量和当前进程的排名。
然后,它获取了当前进程的名字,并打印了一条包含该进程排名和名字的消息。
最后,它清理了 MPI 环境。
注意,为了运行此代码,你需要安装 MPI 库,并且使用特定的命令来编译和运行你的程序。
例如,如果你使用的是 Open MPI,你可以使用以下命令来编译和运行你的程序:```bashmpicc -o hellompiexec -n 4 ./hello```这里 `-n 4` 表示你想在四个进程上运行你的程序。

并行快速排序算法的实现摘要:利用多核并行思想实现快速排序算法,分析了不同数据量、不同数量处理器对于排序效率的影响,并基于多组实验数据对实验结果进行了分析对比。
由于划分进程及多核间通信需要时间,当参与快速排序的数据量大时,多核并行的排序所花费的时间少、效果好。
关键词:快速排序算法;多核并行思想;进程一、引言多核应用研究已成为最受关注的主题和最受瞩目的研究方向,多核的基础上并行计算得到了普遍的运用[1]。
多核并行编程充分利用多核心处理器的优异性能有效地提高运算速度[2]。
真对传统的排序算法—快速排序进行并行实现很有意义。
二、快速排序算法快速排序是对冒泡排序的一种改进,其基本思想是:通过一躺排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序的平均时间复杂度为。
当整个序列基本有序或倒序时快速排序蜕化成冒泡排序,最坏情况的时间复杂度为。
三、并行快速排序算法ForkJoin框架是Java7提供的一个并行计算的框架,适合分治思想的排序算法。
它主要是用于把一个大任务拆分为若干个小任务,然后把若干个小任务运行的结果再汇总为大任务的结果。
并行快速排序就是利用该框架,将待排序数组分割成若干短数组,对每个短数组进行串行排序,形成局部有序的数组,然后进行两两合并得到最后的有序数组。
具体实现过程如下:(1)生成随机的数据用于排序。
(2)调用ForkJoinPool对排序任务进行任务划分。
(3)运用快速排序的思想将已经划分好的小任务进行排序。
(4)调用各个小任务的排序结果进行汇总排序。
(5)得出最终结果。
四、实验结果及对比图1是当排序的数据为10个随机生成数时,并行快速排序所花费时间的结果。
图中可以得出参与排序的数据量不够大时,并行快速排序算法在进程的创建与通信上花费了很多时间,效率低。

MPI并行编程系列二快速排序阅读:63评论:0作者:飞得更高发表于2010-04-06 09:00原文链接在上一篇中对枚举排序的MPI并行算法进行了详细的描述和实现,算法相对简单,采用了并行编程模式中的单程序多数据流的并行编程模式。
在本篇中,将对快速排序进行并行化分析和实现。
本篇代码用到了上篇中的几个公用方法,在本篇中将不再做说明。
在本篇中,我们首先对快速排序算法进行描述和实现,并在此基础上分析此算法的并行性,确定并行编程模式,最后给出该算法的MPI实现。
一、快速排序算法说明快速排序时一种最基本的排序算法,效率相对较高。
其基本思想是:在当前无序数组R[1,n]中选取一个记录作为比较的"基准",即作为排序中的"轴"。
经过一趟排序后,当前无序数组R[1,n]就会以这个轴为核心划分为两个无序的子区r1[1,i-1],r2[i,n]。
其中左边的无序子区都会比"轴"小,右边的无序子区都会比"轴"大。
这样下一趟排序,我们就可以对这两个子区用同样的方法进行划分排序,知道所有的无序子区中的记录均排好为止。
根据算法的说明,快速排序时一个典型的递归算法,算法描述如下:无序数组R[1],R[2],.,R[n]quick_sort(R,start,end)if(start end)r=partion(R,start,end)quick_sort(R,start,r-1)quick_sort(R,r+1,end)endif end quick_sort方法partion的作用就是选取"轴",并将数组分为两个无序子区,并将该"轴"的最终位置返回,在这里我们选择数组的第一个元素为"轴",其算法描述为:partion(R,start,end)r=R[start]while(start end)while((R[end]=r)&&(start end))end--end ehile R[start]=R[end]while((R[start]r)&&(start end))start++end wile R[end]=R[start]end while R[start]=r return start end partion该排序算法的性能好坏主要取决于"轴"的选定,即无序数组的划分是否均衡。
⾼性能计算--MPI并⾏编程MPI常⽤函数MPI_Init(&argc, &argv)来初始化MPI环境,可能是⼀些全局变量的初始化。
MPI程序的第⼀个调⽤,它完成MPI程序所有的初始化⼯作,所有MPI程序的第⼀条可执⾏语句都是这条语句。
MPI_Comm_rank(communicator, &myid)来获取当前进程在通信器中具有的进程号。
不同的进程就可以将⾃⾝和其它的进程区别开来,实现各进程的并⾏和协作。
MPI_Comm_size(communicator, &numprocs)来获取通信器中包含的进程数⽬。
不同的进程通过这⼀调⽤得知在给定的通信域中⼀共有多少个进程在并⾏执⾏。
MPI_Finalize()来结束并⾏编程环境。
之后我们就可以创建新的MPI编程环境了。
MPI程序的最后⼀个调⽤,它结束MPI程序的运⾏,它是MPI程序的最后⼀条可执⾏语句,否则程序的运⾏结果是不可预知的。
int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)将发送缓冲区中的count个datatype数据类型的数据发送到⽬的进程,⽬的进程在通信域中的标识号是dest,本次发送的消息标志是tag,使⽤这⼀标志,就可以把本次发送的消息和本进程向同⼀⽬的进程发送的其它消息区别开来。
发送缓冲区是由count个类型为datatype的连续数据空间组成,起始地址为buf。
注意这⾥不是以字节计数,⽽是以数据类型为单位指定消息的长度。
int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int tag,MPI_Comm comm, MPI_Status *status)从指定的进程source接收消息,并且该消息的数据类型和消息标识和本接收进程指定的datatype和tag相⼀致,接收到的消息所包含的数据元素的个数最多不能超过count。
Python快速排序法(转)⽅法解读:例:对初始序列:“6 1 2 7 9 3 4 5 10 8”采⽤快速排序法:⼀、分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。
先从右往左找⼀个⼩于6的数,再从左往右找⼀个⼤于6的数,然后交换他们。
这⾥可以⽤两个变量 i 和 j ,分别指向序列最左边和最右边。
我们为这两个变量起个好听的名字“哨兵i”和“哨兵j”。
刚开始的时候让哨兵i 指向序列的最左边(即i=1),指向数字6。
让哨兵j 指向序列的最右边(即j=10),指向数字8。
⼆、⾸先哨兵j 开始出动。
因为此处设置的基准数是最左边的数,所以需要让哨兵j先出动,这⼀点⾮常重要(请⾃⼰想⼀想为什么)。
哨兵j ⼀步⼀步地向左挪动(即 j--),直到找到⼀个⼩于6的数停下来。
接下来哨兵i 再⼀步⼀步向右挪动(即 i++),直到找到⼀个数⼤于6的数停下来。
最后哨兵j 停在了数字5⾯前,哨兵i 停在了数字7⾯前。
现在交换哨兵i 和哨兵j 所指向的元素的值。
到此,第⼀次交换结束。
三、接下来开始哨兵j继续向左挪动(再友情提醒,每次必须是哨兵j 先出发)。
他发现了4(⽐基准数6要⼩,满⾜要求)之后停了下来。
哨兵i 也继续向右挪动的,他发现了9(⽐基准数6要⼤,满⾜要求)之后停了下来。
此时再次进⾏交换。
四、第⼆次交换结束,“探测”继续。
哨兵j 继续向左挪动,他发现了3(⽐基准数6要⼩,满⾜要求)之后⼜停了下来。
哨兵i 继续向右移动,糟啦!此时哨兵i 和哨兵j 相遇了,哨兵i 和哨兵j 都⾛到3⾯前。
说明此时“探测”结束。
我们将基准数6和3进⾏交换。
交换之后的序列如下。
五、到此第⼀轮“探测”真正结束。
此时以基准数6为分界点,6左边的数都⼩于等于6,6右边的数都⼤于等于6。
回顾⼀下刚才的过程,其实哨兵j 的使命就是要找⼩于基准数的数,⽽哨兵i 的使命就是要找⼤于基准数的数,直到 i 和 j 碰头为⽌。
现在基准数6已经归位,它正好处在序列的第6位。
基于MPI的快速排序算法的实现完整代码:#include <iostream>#include <cstdlib>#include <ctime>#include <algorithm>#include <cmath>#include <mpi.h>using namespace std;struct Pair {int left;int right;};const int MAX_PROCESS = 128;const int NUM = 8000;const int MAX = 1000000;const int MIN = 0;int arr[NUM];int temp[NUM];Pair pairs[MAX_PROCESS];int counter = -1;void swap(int A[], int i, int j) {int temp = A[i];A[i] = A[j];A[j] = temp;}int findpivot(int i, int j) {return (i + j) / 2;}int partition(int A[], int l, int r, int pivot) {do {while (A[++l] < pivot);while ((r != 0 && (A[--r] > pivot)));swap(A, l, r);} while (l < r);swap(A, l, r);return l;}void quicksort(int A[], int i, int j, int currentdepth, int targetdepth) {if (currentdepth == targetdepth) {int rank = ++counter;pairs[rank].left = i;pairs[rank].right = j;cout << pairs[rank].left << " and " << pairs[rank].right << " : rank " << rank << endl;return;}if (j <= i) return;int pivotindex = findpivot(i, j);swap(A, pivotindex, j);int k = partition(A, i - 1, j, A[j]);swap(A, k, j);quicksort(A, i, k - 1, currentdepth + 1, targetdepth);quicksort(A, k + 1, j, currentdepth + 1, targetdepth);}void quicksort(int A[], int i, int j) {if (j <= i) return;int pivotindex = findpivot(i, j);swap(A, pivotindex, j);int k = partition(A, i - 1, j, A[j]);swap(A, k, j);quicksort(A, i, k - 1);quicksort(A, k + 1, j);}int main(int argc, char* argv[]) {MPI_Init(&argc, &argv);int RANK, SIZE, targetdepth, left, right, REAL_SIZE;MPI_Comm_rank(MPI_COMM_WORLD, &RANK);MPI_Comm_size(MPI_COMM_WORLD, &SIZE);REAL_SIZE = SIZE;if (RANK == 0) {cout << "Quick sort start..." << endl;cout << "Generate random data... ";memset(arr, 0, NUM * sizeof(arr[0]));srand(time(NULL));for (int i = 0; i < NUM; i++) {arr[i] = MIN + rand() % (MAX - MIN);}cout << "Done." << endl;targetdepth = log2(SIZE);cout << "Rank: " << RANK << endl;cout << "Sorting... ";quicksort(arr, 0, NUM - 1, 0, targetdepth);REAL_SIZE = counter + 1;for (int i = 1; i < SIZE; i++) {int left = pairs[i].left;int right = pairs[i].right;MPI_Send(&REAL_SIZE, 1, MPI_INT, i, 99, MPI_COMM_WORLD);MPI_Send(&left, 1, MPI_INT, i, 0, MPI_COMM_WORLD);MPI_Send(&right, 1, MPI_INT, i, 1, MPI_COMM_WORLD);MPI_Send(&arr, NUM, MPI_INT, i, 2, MPI_COMM_WORLD);}left = pairs[0].left;right = pairs[0].right;quicksort(arr, left, right);cout << "Process " << RANK <<" done."<< endl;}for (int process = 1; process < REAL_SIZE; process++) {if (RANK == process) {MPI_Status status;MPI_Recv(&REAL_SIZE, 1, MPI_INT, 0, 99, MPI_COMM_WORLD, &status); MPI_Recv(&left, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, &status);MPI_Recv(&right, 1, MPI_INT, 0, 1, MPI_COMM_WORLD, &status);MPI_Recv(&arr, NUM, MPI_INT, 0, 2, MPI_COMM_WORLD, &status);if (process < REAL_SIZE) {quicksort(arr, left, right);MPI_Send(&arr, NUM, MPI_INT, 0, 0, MPI_COMM_WORLD);cout << "Process " << RANK << " done." << endl;}}}if (RANK == 0) {for (int i = 1; i < REAL_SIZE; i++) {//cout << "Master is ready to receive data from process " << i << endl;MPI_Status status;MPI_Recv(&temp, NUM, MPI_INT, i, 0, MPI_COMM_WORLD, &status);for (int j = pairs[i].left; j <= pairs[i].right; j++) {arr[j] = temp[j];}//cout << "Master has combined data from process " << i << endl;}cout << "Done." << endl;cout << "Result:" << endl;int counter = 1;int row = 20;for (int i = 0; i < NUM; i++, counter++) {cout << arr[i] << " ";if (arr[i] < arr[max(i - 1, 0)]) {cerr << "Invalid! " << arr[i] << " > "<< arr[max(i - 1, 0)] <<" i is "<< i << endl; }if (counter % row == 0) cout << endl;}}MPI_Finalize();}运⾏截图:。
一.实验要求1.写出原算法串行处理的思路或流程2.说明算法并行化的思路3.并且写出算法流程,最终编码实现二.实验环境硬件环境:Virtual PC 2007(XP)软件:VC++ 6.0;mpich.nt.1.2.5三.实验步骤和结果1.原插入排序原理插入排序过程示例将n个元素的数列分为已有序和无序两个部分,如下所示:{,{a2,a3,a4,…,an}}{{a1(1),a2(1)},{a3(1),a4(1) …,an(1)}}…{{a1(n-1),a2(n-1) ,…}, {an(n-1)}}每次处理就是将无序数列的第一个元素与有序数列的元素从后往前逐个进行比较,找出插入位置,将该元素插入到有序数列的合适位置中。
如果目标是把n个元素的序列升序排列,那么采用插入排序存在最好情况和最坏情况。
最好情况就是,序列已经是升序排列了,在这种情况下,需要进行的比较操作需(n-1)次即可。
最坏情况就是,序列是降序排列,那么此时需要进行的比较共有n(n-1)/2次。
插入排序的赋值操作是比较操作的次数加上 (n-1)次。
平均来说插入排序算法的时间复杂度为O(n^2)。
因而,插入排序不适合对于数据量比较大的排序应用。
2.并行化思路上文所说的插入排序在数据量大的情况下,运算量比较大,因此适合用并行计算来提高效率,下面是并行化算法的思路2.1 首先需要输入排序元素的个数,并输入需要排序的原色,用一个数组保存起来。
2.2将数组按照进程的数目平均分段,每个进程各领取一段去做插入排序。
2.3将进程排成一个二叉树的结构,每一个进程节点先将下面两个进程节点排好的数组接收进来,做一次归并排序。
再用这个归并排序结果跟进程节点再做一次归并排序。
2.4循环执行,直到树的根节点为止,排序完成。
2.5输出并行排序结果3.程序运行结果4.源代码//此算法实现插入排序的并行运算//陈仲策 2007034743011#include <stdio.h>#include <mpi.h>#include <time.h>#include <stdlib.h>int * merge(int *v1, int n1, int *v2, int n2); void swap(int *v, int i, int j);void sort(int *v, int n);double startT,stopT;double startTime;int * merge(int *v1, int n1, int *v2, int n2) {int i,j,k;int * result;result = (int *)malloc((n1+n2)*sizeof(int));i=0; j=0; k=0;while(i<n1 && j<n2)if(v1[i]<v2[j]){result[k] = v1[i];i++; k++;}else{result[k] = v2[j];j++; k++;}if(i==n1)while(j<n2){result[k] = v2[j];j++; k++;}elsewhile(i<n1){result[k] = v1[i];i++; k++;}return result;}/* 插入排序算法*/void InsertionSort(int *v, int n){int i;int j;int temp;for(i=1;i<n;i++){temp = v[i];for(j=i ; j>0 && temp < v[j-1] ; j--){v[j]=v[j-1];}v[j]=temp;}}/*主函数*/void main(int argc, char **argv){int m,n=500;int count;int *data;int *buf;int *other;int id,p;int s;int i;int step;MPI_Status status;/*MPI初始化*/MPI_Init(&argc,&argv);/*确定自己的进程标志号id*/MPI_Comm_rank(MPI_COMM_WORLD,&id);/*组内进程数是p*/MPI_Comm_size(MPI_COMM_WORLD,&p);/*根处理机(id=0)获取必要的信息,并协调各处理机工作*/if(id==0){scanf("%d",&count); //输入要排序的元素的个数n = count;int *a = (int *)malloc( count*sizeof(int));; //定义一个存放输入整数的指针,并分配空间for(int j=0;j<count;j++){scanf("%d,",&a[j]); //将输入的整数存入动态数组}int r;s = n/p;r = n%p;data = (int *)malloc((n+p-r)*sizeof(int));for(i=0;i<n;i++)data[i] = a[i];if(r!=0){for(i=n;i<n+p-r;i++)data[i]=0;s=s+1;}startT = clock();/* 从根处理机将数据序列广播到其他处理器 *//* 1表示传送的输入缓冲中的元素的个数 *//* MPI_INT表示输入元素的类型 *//* 0表示跟进程的id */MPI_Bcast(&s,1,MPI_INT,0,MPI_COMM_WORLD);buf = (int *)malloc(s*sizeof(int));MPI_Scatter(data,s,MPI_INT,buf,s,MPI_INT,0,MPI_COMM_WORLD);/*id号为0的处理器调度执行插入排序*/InsertionSort(buf,s);}else{MPI_Bcast(&s,1,MPI_INT,0,MPI_COMM_WORLD);buf = (int *)malloc(s*sizeof(int));MPI_Scatter(data,s,MPI_INT,buf,s,MPI_INT,0,MPI_COMM_WORLD);InsertionSort(buf,s);}step = 1;while(step<p){if(id%(2*step)==0){if(id+step<p){MPI_Recv(&m,1,MPI_INT,id+step,0,MPI_COMM_WORLD,&status);other = (int *)malloc(m*sizeof(int));MPI_Recv(other,m,MPI_INT,id+step,0,MPI_COMM_WORLD,&status);buf = merge(buf,s,other,m);s = s+m;}}else{int nears = id-step;MPI_Send(&s,1,MPI_INT,nears,0,MPI_COMM_WORLD);MPI_Send(buf,s,MPI_INT,nears,0,MPI_COMM_WORLD);break;}step = step*2;}if(id==0){FILE * fout;stopT = clock();/*显示执行并行运算后各个进程的总共所耗时间*/printf("element count %d ; \n %d processors cost total times; %f secs\n",count,p,(stopT-startT)/CLOCKS_PER_SEC);fout = fopen("result","w");for(i=0;i<s;i++)if (buf[i] != 0){fprintf(fout,"%d\n",buf[i]);//输出计算结果printf("%d\n",buf[i]);}fclose(fout);}MPI_Finalize();}。
MPI并行编程系列二快速排序阅读:63评论:0作者:飞得更高发表于2010-04-06 09:00原文链接在上一篇中对枚举排序的MPI并行算法进行了详细的描述和实现,算法相对简单,采用了并行编程模式中的单程序多数据流的并行编程模式。
在本篇中,将对快速排序进行并行化分析和实现。
本篇代码用到了上篇中的几个公用方法,在本篇中将不再做说明。
在本篇中,我们首先对快速排序算法进行描述和实现,并在此基础上分析此算法的并行性,确定并行编程模式,最后给出该算法的MPI实现。
一、快速排序算法说明快速排序时一种最基本的排序算法,效率相对较高。
其基本思想是:在当前无序数组R[1,n]中选取一个记录作为比较的"基准",即作为排序中的"轴"。
经过一趟排序后,当前无序数组R[1,n]就会以这个轴为核心划分为两个无序的子区r1[1,i-1],r2[i,n]。
其中左边的无序子区都会比"轴"小,右边的无序子区都会比"轴"大。
这样下一趟排序,我们就可以对这两个子区用同样的方法进行划分排序,知道所有的无序子区中的记录均排好为止。
根据算法的说明,快速排序时一个典型的递归算法,算法描述如下:无序数组R[1],R[2],.,R[n]quick_sort(R,start,end)if(start end)r=partion(R,start,end)quick_sort(R,start,r-1)quick_sort(R,r+1,end)endif end quick_sort方法partion的作用就是选取"轴",并将数组分为两个无序子区,并将该"轴"的最终位置返回,在这里我们选择数组的第一个元素为"轴",其算法描述为:partion(R,start,end)r=R[start]while(start end)while((R[end]=r)&&(start end))end--end ehile R[start]=R[end]while((R[start]r)&&(start end))start++end wile R[end]=R[start]end while R[start]=r return start end partion该排序算法的性能好坏主要取决于"轴"的选定,即无序数组的划分是否均衡。
最好的情况下,无序数组每次都会被划为两个均等的无序子区,这是算法的负责度为o(nlogn);最坏的情况,无序数组每次划分都是左边n-1个元素,右边0个元素,这时算法的复杂度为o(n^2)。
在通常的情况下,该算法的复杂度会依然保持在o(nlogn),上只不过具有更高的常数因子。
因此,选定一个有效地"轴",成为该算法的关键。
一般情况下,会选定无序数组的第一个,中间或者是最后一个元素作为算法的"轴",我们可以对着三个元素进行比较,取大小居中的那个元素作为该算法的"轴"。
二、快速排序算法的串行实现快速排序很明显的是一个递归的程序。
编写递归程序一个很重的要点就是确定在什么条件下终止递归操作。
主函数代码如下:1:void quick_sort_function(int*array,int start,int last){2:3:int part_position;4:5:if(start=last)6:return;7:8:part_position=part_array_head(array,start,last);9:quick_sort_function(array,start,part_position-1);10:quick_sort_function(array,part_position+1,last);11:}主函数代码很简单,一个终止递归的条件,一个递归方式。
在主函数中,核心函数为part_array_head,其代码如下:1:int part_array_head(int*array,int start,int last){2:3:int position_value=array[start];4:5:while(start last){6:while(startlast&&array[last]=position_value)7:last--;8:array[start]=array[last];9:10:while(startlast&&array[start]=position_value)11:start++;12:array[last]=array[start];13:}14:15:array[start]=position_value;16:17:return start;18:}从代码可以看出,快速排序的代码相对姜丹,总共不过三十行代码。
本人是非常喜欢递归操作的。
下面我们将对快速排序进行并行化分析。
三、快速排序并行化分析在并行编程策略中,有一种策略非常适合递归算法,自然也就成为我们快速排序并行化的首选策略。
这种策略为"分治策略",这种策略的核心思想就是将一个大而复杂的问题分解成若干个子问题分而治之。
若分解后的子问题依然过大或者是过于复杂,则可反复利用分治策略,直到很容易的求解子问题未知。
有此看出,分治策略也符合递归的思想。
要实现分治策略,主要分为三步:1、将大问题分解成小问题;2、求解小问题;3、归并小问题的解,得到最终结果。
其中各个小问题的求解就是我们并行化的所在。
分治策略的说明图如下:在快速排序算法中,我们就是将原无序数组按照一定得规则拆分成一个个子数组,即上图中的"分解"过程,每个子数组的排序可并行执行。
当各子数组排序完毕后,依此将结构传给其父数组,得到最终的结果,即上图中的"归并"过程。
基于以上的分析,我们给出快速排序算法MPI的实现如下:四、快速排序的MPI并行实现因为分治策略的特殊性,我们进行快速排序算法的进程数目为2^m个。
我们依然用进程p0来读取原数组,最终的排序结果也会由进程p0打印出来。
在该算法中,我们如果知道进程数目为2^m个,就应该能够求出m。
因此我写了一个实现函数,求一个整数的以2为底的对数的算法。
该算法的具体实现为:1:int log_int(int root,int num){2:3:int i,j;4:5:i=1;6:j=root;7:8:while(j num){9:j*=root;10:i++;11:}12:13:if(j num)14:i--;15:16:return i;17:}该并行算法的主函数为:1:void quick_sort_mpi(int*argv,char*argc){2:3:intprocess_id;4:int process_size;5:6:int*init_array;7:intarray_length;8:9:int log_num;10:int k;11:12:mpi_start(argv,argc,&process_size,&process_id,MPI_COMM_WORLD);13:14:if(process_size%2!=0){15:if(!process_id)16:printf("the sizeof the process must is the multipe of 2");17:18:MPI_Abort(MPI_COMM_WORLD,PROCESS_SIZE_ERROR);19:}20:21:log_num=log_int(2,process_size);22:array_length=ARRAY_LENGTH;23:24:if(!process_id){25:init_array=(int*)my_mpi_malloc(0,sizeof(int)*array_length);26:array_builder(init_array,array_length);27:array_int_print(array_length,init_array);28:}29:30://对数组进行快速排序31:quick_sort_mpi_function(init_array,array_length,log_num,process_id,0 ,MPI_COMM_WORLD);32:33:if(!process_id)34:array_int_print(array_length,init_array);35:36:MPI_Finalize();37:}在程序中出现的子函数在这里就不一一介绍了,其中主要的函数在上一篇枚举排序的MPI算法中都有所介绍。
主函数的核心就是quic_sort_mpi_fuction函数,该函数真正实现了快速排序,其代码如下:1:void quick_sort_mpi_function(2:int*init_array,//待排序数组3:int array_length,//待排序数组长度4:int log_num,//进程数取2为底的对数5:int process_id,//当前活动进程ID 6:int part_process_id,//对数组进行拆分的进程ID 7:MPI_Comm comm){8:9:int*local_array;10:int local_array_length=0;11:12:int send_array_length;13:14:int partion_position;15:16://取得要接收数据的进程号的进程号17:int receive_process_id;18:int j;19:20:MPI_Status status;21:22:if(log_num==0){23:if(process_id==part_process_id&&array_length1)24:quick_sort_function(init_array,0,array_length-1);25:26:return;27:}28:29:receive_process_id=part_process_id+pow_int(2,log_num-1);30:31://当活动进程为数组拆分进程时,按照快速排序方法对数组分成两部分32:if(process_id==part_process_id){33:partion_position=part_array_head(init_array,0,array_length-1);34:send_array_length=array_length-partion_position-1;35:local_array_length=partion_position;36:37:MPI_Send((void*)&send_array_length,1,MPI_INT,38:receive_process_id,LENGTH_MESSAGE,comm);39:40:if(send_array_length 0)41:MPI_Send((void*)(init_array+partion_position+1),send_array_length,42:MPI_INT,receive_process_id,DATA_MESSAGE,comm);43:}44:45://当活动进程为待接收数据的进程时,接收从拆分进程发送过来的数据46:if(process_id==receive_process_id){47:48:MPI_Recv((void*)&local_array_length,1,MPI_INT,part_process_id,49:LENGTH_MESSAGE,comm,&status);50:51:if(local_array_length 0)52:{53:local_array=(int*)my_mpi_malloc(process_id,sizeof(int)*local_array_l ength);54:MPI_Recv((void*)local_array,local_array_length,MPI_INT,part_process_ id,55:DATA_MESSAGE,comm,&status);56:57:}58:}59:60:j=local_array_length;61:MPI_Bcast(&j,1,MPI_INT,part_process_id,comm);62:if(j 1){64:quick_sort_mpi_function(init_array,local_array_length,log_num-1,65:process_id,part_process_id,comm);66:}67:68:j=local_array_length;69:MPI_Bcast(&j,1,MPI_INT,receive_process_id,MPI_COMM_WORLD);70:if(j 1)71:quick_sort_mpi_function(local_array,local_array_length,log_num-1,72:process_id,receive_process_id,comm);73:74:if(process_id==receive_process_id&&local_array_length 0)75:MPI_Send((void*)local_array,local_array_length,MPI_INT,76:part_process_id,DATA_MESSAGE_SORT,MPI_COMM_WORLD);77:78:if(process_id==part_process_id&&send_array_length 0)79:MPI_Recv((void*)(init_array+partion_position+1),send_array_length,80:MPI_INT,receive_process_id,DATA_MESSAGE_SORT,MPI_COMM_WORLD,&status);81:}该算法基本继承了并行编程策略的分治所发思想:分解---求解---归并。