第4章串第2讲-串的模式匹配
- 格式:pptx
- 大小:146.27 KB
- 文档页数:29


串串(String)又叫做字符串,是一种特殊的线性表的结构,表中每一个元素仅由一个字符组成。
随着计算机的发展,串在文字编辑、词法扫描、符号处理以及定理证明等诸多领域已经得到了越来越广泛的应用。
第一节串的定义和表示1、串的逻辑结构定义串是由零个到任意多个字符组成的一个字符序列。
一般记为:S=’ a1a2a3……a n’(n>=0)其中S为串名,序列a1a2a3……a n为串值,n称为串的长度,我们将n=0的串称为空串(null string)。
串中任意一段连续的字符组成的子序列我们称之为该串的子串,字符在序列中的序号称为该字符在串中的位置。
在描述中,为了区分空串和空格串(s=‘’),我们一般采用来表示空串。
2、串的基本操作串一般包含以下几种基本的常用操作:1、length(S),求S串的长度。
2、delete(S,I,L),将S串从第I位开始删除L位。
3、insert(S,I,T),在S的第I位之前插入串T。
4、str(N,S),将数字N转化为串S。
5、val(S,N,K),将串S转化为数字N;K的作用是当S中含有不为数字的字符时,K记录下其位置,并且S没有被转化为N。
3、串的储存结构一般我们采用以下两种方式保存一个串:1、字符串类型,描述为:const n=串的最大长度type strtype=string[n]这里由于tp的限制,n只能为[1..255]。
在fp或者delphi中,我们还可以使用另外一种类型,描述为:const n=串的最大长度type strtype=qstring[n]这里的n就没有限制了,只要空间允许,开多大都可以。
2、数组来保存,描述为:const n=串的最大长度type strtype=records:array[1..n] of char;len:0..n;end;第二节模式匹配问题与一般的线性表不同,我们一般将串看成一个整体,它有一种特殊的操作——模式匹配。


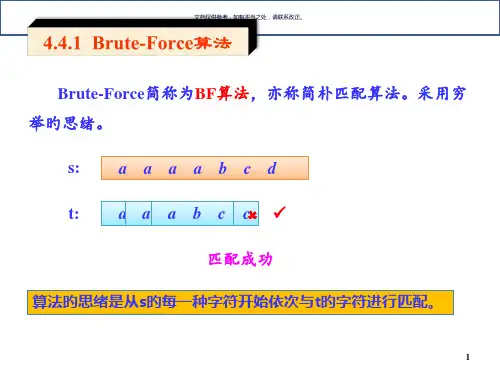
竭诚为您提供优质文档/双击可除串的模式匹配算法实验报告篇一:串的模式匹配算法串的匹配算法——bruteForce(bF)算法匹配模式的定义设有主串s和子串T,子串T的定位就是要在主串s中找到一个与子串T相等的子串。
通常把主串s称为目标串,把子串T称为模式串,因此定位也称作模式匹配。
模式匹配成功是指在目标串s中找到一个模式串T;不成功则指目标串s中不存在模式串T。
bF算法brute-Force算法简称为bF算法,其基本思路是:从目标串s的第一个字符开始和模式串T中的第一个字符比较,若相等,则继续逐个比较后续的字符;否则从目标串s的第二个字符开始重新与模式串T的第一个字符进行比较。
以此类推,若从模式串T的第i个字符开始,每个字符依次和目标串s中的对应字符相等,则匹配成功,该算法返回i;否则,匹配失败,算法返回0。
实现代码如下:/*返回子串T在主串s中第pos个字符之后的位置。
若不存在,则函数返回值为0./*T非空。
intindex(strings,stringT,intpos){inti=pos;//用于主串s中当前位置下标,若pos不为1则从pos位置开始匹配intj=1;//j用于子串T中当前位置下标值while(i j=1;}if(j>T[0])returni-T[0];elsereturn0;}}bF算法的时间复杂度若n为主串长度,m为子串长度则最好的情况是:一配就中,只比较了m次。
最坏的情况是:主串前面n-m个位置都部分匹配到子串的最后一位,即这n-m位比较了m次,最后m位也各比较了一次,还要加上m,所以总次数为:(n-m)*m+m=(n-m+1)*m从最好到最坏情况统计总的比较次数,然后取平均,得到一般情况是o(n+m).篇二:数据结构实验报告-串实验四串【实验目的】1、掌握串的存储表示及基本操作;2、掌握串的两种模式匹配算法:bF和Kmp。
3、了解串的应用。
【实验学时】2学时【实验预习】回答以下问题:1、串和子串的定义串的定义:串是由零个或多个任意字符组成的有限序列。


《数据结构与算法》第四章串知识点及例题精选串(即字符串)是一种特殊的线性表,它的数据元素仅由一个字符组成。
4.1 串及其基本运算4.1.1 串的基本概念1.串的定义串是由零个或多个任意字符组成的字符序列。
一般记作:s="s1 s2 … s n""其中s 是串名;在本书中,用双引号作为串的定界符,引号引起来的字符序列为串值,引号本身不属于串的内容;a i(1<=i<=n)是一个任意字符,它称为串的元素,是构成串的基本单位,i是它在整个串中的序号; n为串的长度,表示串中所包含的字符个数,当n=0时,称为空串,通常记为Ф。
2.几个术语子串与主串:串中任意连续的字符组成的子序列称为该串的子串。
包含子串的串相应地称为主串。
子串的位置:子串的第一个字符在主串中的序号称为子串的位置。
串相等:称两个串是相等的,是指两个串的长度相等且对应字符都相等。
4.2 串的定长顺序存储及基本运算因为串是数据元素类型为字符型的线性表,所以线性表的存储方式仍适用于串,也因为字符的特殊性和字符串经常作为一个整体来处理的特点,串在存储时还有一些与一般线性表不同之处。
4.2.1 串的定长顺序存储类似于顺序表,用一组地址连续的存储单元存储串值中的字符序列,所谓定长是指按预定义的大小,为每一个串变量分配一个固定长度的存储区,如:#define MAXSIZE 256char s[MAXSIZE];则串的最大长度不能超过256。
如何标识实际长度?1. 类似顺序表,用一个指针来指向最后一个字符,这样表示的串描述如下:typedef struct{ char data[MAXSIZE];int curlen;} SeqString;定义一个串变量:SeqString s;这种存储方式可以直接得到串的长度:s.curlen+1。
如图4.1所示。
s.dataMAXSIZE-1图4.1 串的顺序存储方式12. 在串尾存储一个不会在串中出现的特殊字符作为串的终结符,以此表示串的结尾。

串的模式匹配算法字符串模式匹配是计算机科学中一种常用的算法。
它是一种检索字符串中特定模式的技术,可以用来在字符串中查找相应的模式,进而完成相应的任务。
字符串模式匹配的基本思想是,用一个模式串pattern去匹配另一个主串text,如果在text中找到和pattern完全匹配的子串,则该子串就是pattern的匹配串。
字符串模式匹配的过程就是在text中搜索所有可能的子串,然后比较它们是否和pattern完全匹配。
字符串模式匹配的算法有很多,其中著名的有暴力匹配算法、KMP算法、BM算法和Sunday算法等。
暴力匹配算法是最简单也是最常用的字符串模式匹配算法,其思想是从主串的某一位置开始,依次比较pattern中每一个字符,如果某个字符不匹配,则从主串的下一位置重新开始匹配。
KMP算法(Knuth-Morris-Pratt算法)是一种更为高效的字符串模式匹配算法,它的特点是利用了已匹配过的字符的信息,使搜索更加有效。
它的实现思想是,在pattern中先建立一个next数组,next数组的值代表pattern中每个字符前面的字符串的最大公共前缀和最大公共后缀的长度,这样可以在主串和模式串匹配失败时,利用next数组跳转到更有可能匹配成功的位置继续搜索,从而提高字符串模式匹配的效率。
BM算法(Boyer-Moore算法)也是一种高效的字符串模式匹配算法,它的实现思想是利用主串中每个字符最后出现的位置信息,以及模式串中每个字符最右出现的位置信息来跳转搜索,从而减少不必要的比较次数,提高搜索效率。
Sunday算法是一种简单而高效的字符串模式匹配算法,它的实现思想是,在主串中搜索时,每次从pattern的最右边开始比较,如果不匹配,则根据主串中下一个字符在pattern中出现的位置,将pattern整体向右移动相应位数,继续比较,这样可以减少不必要的比较次数,提高算法的效率。
字符串模式匹配算法的应用非常广泛,它可以用来查找文本中的关键字,检查一个字符串是否以另一个字符串开头或结尾,查找文本中的模式,查找拼写错误,检查字符串中是否包含特定的字符等。


简述串的模式匹配原理嘿,咱聊聊串的模式匹配原理呗!这串的模式匹配,听着挺神秘,其实也不难理解。
就像在一堆宝藏里找宝贝。
啥是串的模式匹配呢?简单说,就是在一个大字符串里找一个小字符串。
这就像在一片大海里找一条小鱼。
你得有办法才能找到它。
比如说,你想在一篇文章里找一个特定的词,这就是串的模式匹配。
那怎么找呢?有好几种方法呢。
一种是暴力匹配。
这就像一个愣头青,一个一个地比对。
从大字符串的开头开始,一个字符一个字符地和小字符串比对。
如果不一样,就往后移一个字符,继续比对。
这就像在一堆沙子里找一颗小石子,得一颗一颗地找。
虽然有点笨,但是有时候也能管用。
还有一种是KMP 算法。
这就像一个聪明的侦探,有自己的一套方法。
它会先分析小字符串的特点,然后根据这些特点来快速匹配。
比如说,如果在比对的过程中发现不一样了,它不会像暴力匹配那样从头开始,而是根据之前的分析,直接跳到合适的位置继续比对。
这就像你知道了宝藏的线索,就能更快地找到宝藏。
串的模式匹配有啥用呢?用处可大了。
比如说,在文本编辑软件里,你想查找一个特定的词或者句子,就用到了串的模式匹配。
还有在搜索引擎里,也是用串的模式匹配来找到你想要的信息。
这就像你有一把神奇的钥匙,能打开知识的大门。
你说要是没有串的模式匹配,那会咋样呢?那找东西可就麻烦了。
就像在一个乱七八糟的房间里找东西,没有头绪,得翻个底朝天。
有了串的模式匹配,就像有了一个指南针,能让你更快地找到你想要的东西。
总之,串的模式匹配就像一个神奇的工具,能在大字符串里找到小字符串。
咱可得好好理解它,让它为我们的生活带来更多的便利。

数据结构—串的模式匹配数据结构—串的模式匹配1.介绍串的模式匹配是计算机科学中的一个重要问题,用于在一个较长的字符串(称为主串)中查找一个较短的字符串(称为模式串)出现的位置。
本文档将详细介绍串的模式匹配算法及其实现。
2.算法一:暴力匹配法暴力匹配法是最简单直观的一种模式匹配算法,它通过逐个比较主串和模式串的字符进行匹配。
具体步骤如下:1.从主串的第一个字符开始,逐个比较主串和模式串的字符。
2.如果当前字符匹配成功,则比较下一个字符,直到模式串结束或出现不匹配的字符。
3.如果匹配成功,返回当前字符在主串中的位置,否则继续从主串的下一个位置开始匹配。
3.算法二:KMP匹配算法KMP匹配算法是一种改进的模式匹配算法,它通过构建一个部分匹配表来减少不必要的比较次数。
具体步骤如下:1.构建模式串的部分匹配表,即找出模式串中每个字符对应的最长公共前后缀长度。
2.从主串的第一个字符开始,逐个比较主串和模式串的字符。
3.如果当前字符匹配成功,则继续比较下一个字符。
4.如果当前字符不匹配,则根据部分匹配表的值调整模式串的位置,直到模式串移动到合适的位置。
4.算法三:Boyer-Moore匹配算法Boyer-Moore匹配算法是一种高效的模式匹配算法,它通过利用模式串中的字符出现位置和不匹配字符进行跳跃式的匹配。
具体步骤如下:1.构建一个坏字符规则表,记录模式串中每个字符出现的最后一个位置。
2.从主串的第一个字符开始,逐个比较主串和模式串的字符。
3.如果当前字符匹配成功,则继续比较下一个字符。
4.如果当前字符不匹配,则根据坏字符规则表的值调整模式串的位置,使模式串向后滑动。
5.算法四:Rabin-Karp匹配算法Rabin-Karp匹配算法是一种基于哈希算法的模式匹配算法,它通过计算主串和模式串的哈希值进行匹配。
具体步骤如下:1.计算模式串的哈希值。
2.从主串的第一个字符开始,逐个计算主串中与模式串长度相同的子串的哈希值。
数据结构-第四章串串也叫字符串,它是由零个或多个字符组成的字符序列。
基本内容1 串的有关概念串的基本操作2 串的定长顺序存储结构,堆分配存储结构;3 串的基本操作算法;4 串的模式匹配算法;5 串操作的应⽤。
学习要点1 了解串的基本操作,了解利⽤这些基本操作实现串的其它操作的⽅法;2 掌握在串的堆分配存储结构下,串的基本操作算法;3 掌握串的模式匹配算法;第四章串 4.1 串的基本概念4.2 串存储和实现4.3 串的匹配算法4.4 串操作应⽤举例第四章串 4.1 串的基本概念 4.2 串存储和实现 4.3 串的匹配算法 4.4 串操作应⽤举例第四章串4.1 串的基本概念 4.2 串存储和实现 4.3 串的匹配算法 4.4 串操作应⽤举例4. 1 串类型的定义⼀、串的定义1 什么是串串是⼀种特殊的线性表,它是由零个或多个字符组成的有,a2, a3, ... a n’限序列,⼀般记作s = ‘a1其中 s----串名, a1,a2, a3, ... a n----串值串的应⽤⾮常⼴泛,许多⾼级语⾔中都把串作为基本数据类型。
在事务处理程序中,顾客的姓名、地址;货物的名称、产地。
可作为字符串处理,⽂本⽂件中的每⼀⾏字符等也可作为字符串处理。
下⾯是⼀些串的例⼦:(1)a = ‘ LIMING’(2)b = ‘NANJING UNIVERSITY OF SCIENCE &TECHNOLOGY’(3)c = ‘ DATA STRUCTURE’(4)d = ‘’说明:1) 串中包含的字符个数,称为串的长度。
长度为0的串称为空串,它不包括任何字符,上⾯(4)中的串d 是空串,(5)中的e 是包含⼀个空格符的空格串;2)串中所包含的字符可以是字母、数字或其他字符,这依赖于具体计算机所允许的字符集。
2 串的有关术语1)⼦串串中任意连续的字符组成的⼦序列称为该串的⼦串例:c = ‘ DATA STRUCTURE’,f=‘DATA’ f是c的⼦串2)⼦串的位置⼦串T 在主串S中的位置是指主串S中第⼀个与T相同的⼦串的⾸字母在主串中的位置。