CloudStack管理节点高可用部署
- 格式:doc
- 大小:66.00 KB
- 文档页数:9

需要了解的15家顶级云管理服务提供商云管理服务是云计算市场中的一项重要服务,它帮助企业管理和监控云资源,提高云基础设施的效率和可靠性。
下面是15家顶级云管理服务提供商,它们是市场上领先且享有良好声誉的公司:1. AWS CloudFormation:AWS CloudFormation是亚马逊网络服务(AWS)的一项服务,它使用户可以以模板的形式创建和管理AWS资源。
它提供了灵活的自动化部署和管理解决方案,并与其他AWS服务紧密集成。
2. Azure Management Group:Azure Management Group是微软Azure云平台的一项服务,它提供了统一的资源组织和管理功能。
它允许用户以层次化的方式组织资源,并为资源设置策略和权限。
3. Google Cloud Deployment Manager:Google Cloud Deployment Manager是谷歌云平台的一项服务,它允许用户以模板的方式定义和管理基础架构。
它提供了强大的自动化部署和管理功能,并与谷歌云平台的其他服务紧密集成。
4. VMware vRealize Suite:VMware vRealize Suite是一套基于虚拟化技术的云管理解决方案,它提供了多种功能,包括资源管理、监控和自动化等。
它与VMware的虚拟化产品集成紧密,可以帮助用户以高效和灵活的方式管理云基础设施。
5. IBM Cloud Orchestrator:IBM Cloud Orchestrator是IBM的一项云管理服务,它提供了一套工具和框架,帮助用户实现云基础设施的自动化管理。
它具有灵活的资源编排和自动化功能,可以与IBM的云平台和其他第三方平台集成。
6. Red Hat CloudForms:Red Hat CloudForms是由红帽公司推出的一款云管理平台,它提供了全面的资源管理和自动化功能。
它支持多种虚拟化和云平台,并提供了灵活的编排和自动化工具。

高可用集群三节点原理高可用集群是一种分布式计算系统,它通过将多个节点(一般为三个节点)连接在一起,以实现数据的冗余备份和资源的共享,从而提高系统的可用性和容错能力。
下面将介绍三节点高可用集群的工作原理。
在三节点高可用集群中,每个节点都是一台独立的服务器,具备相同的硬件和软件配置。
这三个节点通过高速网络互连,并通过软件共享存储来实现数据的同步和共享。
集群中的节点可以分为两个角色:主节点(Primary)和备节点(Secondary)。
在正常运行状态下,主节点负责处理客户端请求,并将数据同步至备节点。
同时,备节点以热备份的形式,实时复制主节点的数据和状态。
这样,在主节点发生故障或不可用时,备节点可以立即接管并继续提供服务,实现故障的无缝切换。
为了确保高可用性和数据一致性,集群采用了心跳机制和共享存储的方式。
心跳机制用于监控节点的状态,每个节点定期发送心跳信号以及当前节点的状态信息给其余节点。
如果主节点的心跳信号长时间未接收到,备节点可以判断主节点已经失效,并将自己切换为主节点运行。
共享存储用于存储集群的数据,主节点和备节点通过共享存储来实现数据的同步,确保数据在节点之间的一致性和可用性。
除了故障切换外,三节点高可用集群还可以进行软件和硬件的维护操作,如升级、扩容、修复等,而不会中断用户的访问。
这是因为在进行维护操作时,可以通过将一个节点切换到维护模式,并将其任务和数据迁移到其他节点上,再进行相应的操作。
维护完成后,将节点切换回正常模式,实现集群的无缝恢复。
综上所述,三节点高可用集群通过节点之间的数据同步和故障切换,提高了系统的可用性和容错能力。
它可以保证在主节点故障或维护时,集群可以继续正常提供服务,从而保证系统的稳定性和可靠性。

基于 OpenStack 高可用云计算平台研究与部署摘要】云计算是继互联网、计算机后在信息时代有一种新的革新,云计算是信息时代的一个大飞跃,未来的时代可能是云计算的时代。
随着云计算兴起与发展,对OpenStack的研究也风起云涌。
不同的云平台也都研究openstack技术,在此基础上搭建各自的私有云或公有云,本文深入分析OpenStack技术,并给出搭建云平台的不同部署方案。
【关键词】OpenStack;高可用云计算平台;研究;部署1. OpenStack技术概述1.1什么是云计算云计算(cloud computing)是分布式计算的一种,指的是通过网络“云”将巨大的数据计算处理程序分解成无数个小程序,然后,通过多部服务器组成的系统进行处理和分析这些小程序得到结果并返回给用户。
云计算早期,简单地说,就是简单的分布式计算,解决任务分发,并进行计算结果的合并。
因而,云计算又称为网格计算。
通过这项技术,可以在很短的时间内(几秒种)完成对数以万计的数据的处理,从而达到强大的网络服务。
云计算不是一种全新的网络技术,而是一种全新的网络应用概念,云计算的核心概念就是以互联网为中心,在网站上提供快速且安全的云计算服务与数据存储,让每一个使用互联网的人都可以使用网络上的庞大计算资源与数据中心。
1.2什么是openstackOpenStack是一个开源的云计算管理平台项目,是一系列软件开源项目的组合。
由NASA(美国国家航空航天局)和Rackspace合作研发并发起,以Apache许可证(Apache软件基金会发布的一个自由软件许可证)授权的开源代码项目。
OpenStack为私有云和公有云提供可扩展的弹性的云计算服务。
项目目标是提供实施简单、可大规模扩展、丰富、标准统一的云计算管理平台。
1.3Openstack组件类型OpenStack覆盖了网络、虚拟化、操作系统、服务器等各个方面。
下面介绍10个核心项目1、计算(Compute):Nova。


安装部署CloudStack 4.0企业私有云平台Ubuntu安装方式参考资料CloudStack Installation_Guide/installation.htmlCloudStack Admin_guide/working-with-iso.htmlCloudStack Admin_guide/creating-vms.htmlCloudStack Admin_guide/create-templates-overview.html目录结构1. 什么是CloudStack2. 宿主机的系统需求3. 配置安装源4. 安装Management Server5. 安装配置KVM虚拟化Host主机6. 用户界面7. 配置Management Server8. 创建Instance类型9. 创建ISO安装源并创建Instance10. 创建并定制Template11. 通过定制的Template创建VM Instance12. 其它优化设置环境介绍OS: Ubuntu Server 12.04.1 64-bitServer:10.6.203.10 cloudstack-server-1- CloudStack Management Server- CloudStack Agent- NFS Server- MySQL Server注:CloudStack支持很好的分布式架构,上面- 代表的所有角色都可以部署在不同的机器上,但在测试环境中因为条件有限我全部都部署到了一台机器上。
1. 什么是CloudStackCloudStack是一个开源的具有高可用性及扩展性的云计算平台。
提到开源的云计算平台,相信大家首先想到的可能是OpenStack,目前国内的几家云计算平台如阿里云、盛大云以及新浪SAE貌似都基于OpenStack做了二次开发。
但使用过CloudStack之后,你会发现其实CloudStack更像是一个商业化过后的产品,有着非常好的用户界面,各个模块默认集成的很好,且安装与部署过程也相对容易一些。

部署私有云CloudStack(上)目录•前言o 1.集群规划o 2.设置yum源o 3.关闭防火墙和selinuxo 4.安装nfso 5.安装和启动mysql-servero 6.安装和启动Cloudstack-Managemento7.浏览器访问前言CloudStack形成的基础设施云和数据中心运营商可以快速,轻松地建立在其现有的基础设施提供云服务的需求,弹性云计算服务。
CloudStack用户可以充分利用云计算提供更高的效率,无限的规模和更快地部署新服务和系统的最终用户。
CloudStack 是一个开源的云操作系统,它可以帮助用户利用自己的硬件提供类似于Amazon EC2那样的公共云服务。
CloudStack可以通过组织和协调用户的虚拟化资源,构建一个和谐的环境。
CloudStack具有许多强大的功能,可以让用户构建一个安全的多租户云计算环境。
CloudStack 兼容Amazon API 接口。
CloudStack可以让用户快速和方便地在现有的架构上建立自己的云服务。
CloudStack可以帮助用户更好地协调服务器、存储、网络资源,从而构建一个IaaS平台。
1.集群规划IP 角色192.168.0.232 Xenserver虚拟机、CloudStack服务端、主存储、二级存储192.168.0.231 物理主机、Xenserver服务端2.设置yum源wget -O /etc/yum.repos.d/CentOS-Base.repo /repo/Centos-7.repowget -O /etc/yum.repos.d/epel.repo /repo/epel-7.repoyum clean allyum makecache3.关闭防火墙和selinuxsystemctl stop firewalldsystemctl disable firewalldsetenforce 0sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config4.安装nfsyum -y install nfs-utilsmkdir /data/export/{primary,secondary} -pecho -e "/data/export/primary 192.168.0.0/24(rw,async,no_root_squash,no_subtree_check)\n/d ata/export/secondary192.168.0.0/24(rw,async,no_root_squash,no_subtree_check)" >> /etc/exportscat >>/etc/sysconfig/nfs <<EOFLOCKD_TCPPORT=32803LOCKD_UDPPORT=32769MOUNTD_PORT=892RQUOTAD_PORT=875STATD_PORT=662STATD_OUTGOING_PORT=2020EOFsystemctl start nfssystemctl start rpcbindsystemctl enable rpcbindsystemctl enable nfs5.安装和启动mysql-serveryum -y install mariadb-servervi /etc/f #在[mysqld]下添加下列参数:innodb_rollback_on_timeout=1innodb_lock_wait_timeout=600max_connections=350log-bin=mysql-binbinlog-format= 'ROW'systemctl start mariadb.servicesystemctl enable mariadb.service6.安装和启动Cloudstack-Managementrpm --import /RPM-GPG-KEY-mysql #从MySQL导入GPG公钥yum -y install mysql-connector-python #安装mysql-connectorcd /root/cloudstack4.11.1/ && yum -y localinstall cloudstack-* #/centos/7/4.11/cloudstack-setup-databases cloud:123456@localhost --deploy-as=root #初始化CloudStack数据库mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION; #授权用户权限/usr/share/cloudstack-common/scripts/storage/secondary/cloud-install-sys-tmplt -m/data/export/secondary/ -f /root/cloudstack4.11.1/systemvmtemplate-4.11.1-xen.vhd.bz2 -h xenserver -F #导入基础模版systemvmtemplate-4.11.1-xen.vhd.bz2下载地址:/en/4.11.1.0/adminguide/systemvm.html cloudstack-setup-managementsystemctl enable cloudstack-management7.浏览器访问用户名/密码为:admin/passwordhttp://192.168.0.232:8080/client/。


构建高可用性的物联网平台架构随着物联网技术的迅猛发展,物联网平台的建设变得越来越重要。
在构建物联网平台架构时,高可用性是一个关键的考虑因素。
本文将探讨一些构建高可用性物联网平台架构的方法和策略。
1. 设计分布式架构为了保证物联网平台的高可用性,我们需要设计一个分布式架构。
分布式架构采用多个节点分布在不同的地理位置,通过高速网络连接。
每个节点都是平等的,在发生单点故障时可以自动地从其他节点接管工作。
这种架构能够提供良好的负载均衡和故障恢复能力,有效地减少单点故障的影响。
2. 实施容错机制容错机制是构建高可用性物联网平台架构的重要组成部分。
容错机制包括数据备份、故障检测和故障恢复等功能。
数据备份可以将数据多次复制到不同的节点上,确保数据不会因某个节点的故障而丢失。
故障检测可以通过实时监控节点的状态,并及时发现故障并采取相应的措施。
故障恢复可以在发生故障时自动切换到备用节点,实现无缝的故障恢复。
3. 采用负载均衡策略负载均衡是确保物联网平台高可用性的一项重要策略。
在高负载情况下,单个节点可能无法处理所有的请求。
通过使用负载均衡器,可以将请求分发到多个节点上,实现负载均衡。
负载均衡策略可以根据节点的负载情况动态地调整请求的分发,确保每个节点都能均衡地处理请求。
4. 引入自动化部署和监控工具为了更好地管理和监控物联网平台,引入自动化部署和监控工具是必不可少的。
自动化部署工具可以帮助快速部署和更新平台的各个组件,减少人工操作出错的可能性。
监控工具可以实时监测平台的性能指标和状态,及时发现问题并采取相应的措施。
这些工具的引入可以提高平台的可维护性和稳定性,减少故障的风险。
5. 引入容器化技术容器化技术可以进一步增强物联网平台的高可用性。
通过将应用程序和依赖项捆绑在一个容器中,并在不同的节点上运行,可以实现应用程序的高度隔离和可移植性。
容器化技术还可以快速地扩展和缩小应用程序的规模,以适应不同的负载需求。
这种灵活性和可扩展性可以有效地保证平台的高可用性。

Cloudstack 4.4安装手册目录1.环境要求 (1)2.环境介绍 (1)3.管理节点安装配置 (1)3.1.网络配置 (1)3.2.主机名配置 (1)3.3. SELinux配置 (2)3.4.配置NTP (2)3.5配置ClouStack软件库 (2)3.6 配置NFS (3)3.7. 安装配置数据库 (4)3.8.安装Cloudstack (4)3.9.导入虚拟机系统模板 (4)4. KVM安装和配置 (5)4.1.安装cloudstack-agent (5)4.2. 配置KVM (5)5.访问管理界面 (5)1.环境要求⏹至少一个支持硬件虚拟化的服务器主机,在主板BIOS里面开启CPU可虚拟化支持。
⏹服务器安装Centos 6.5 x86_64的Desktop。
⏹一个以xxx.xxx.xxx.1/24作为网关的C类地址并且该网络中不能存在DHCP服务器。
⏹运行Cloudstack的机器不能使用动态地址。
本项目环境中是10.8.8.0/24网络。
2.环境介绍3.管理节点安装配置3.1.网络配置默认情况下,网络需要配置才能在我们的环境中正常使用。
由于没有使用DHCP服务器所以我们需要手动配置网络接口。
本次部署仅使用eth0这一个网络接口。
使用root用户在登录本地控制台。
检查/etc/sysconfig/network-scripts/ifcfg-eth0,使其配置如下所示:DEVICE=eth0HWADDR=52:54:00:B9:A6:C0NM_CONTROLLED=noONBOOT=yesBOOTPROTO=noneIPADDR=10.8.8.148NETMASK=255.255.255.0GATEWAY=10.8.8.254DNS1=8.8.8.8ARPCHECK=no在配置好网络之后,我们需要运行一些命令来启动网络:# chkconfig network on# service network start3.2.主机名配置CloudStack要求正确配置主机名。

大数据应用与实践(8)胡经国本文根据有关文献和资料编写而成,供读者参考。
本文在篇章结构、内容和文字上对原文献作了一些修改和补充,并且添加了一些小标题,特此说明。
十七、确保大数据业务成功的七个步骤1、关于大数据的三个重要事实对于大数据有以下三个重要的事实。
⑴、大数据并不是新趋势自20世纪90年代,亚马逊、微软和谷歌就开始进行大数据工作。
几十年来,很多公司都一直在挖掘数据。
可能由于当时只有资金雄厚的大型公司,才能够进行大数据研究;但是大数据确实早已存在。
现在,基于廉价的计算和存储能力以及新工具和技术,几乎每个人都可以使用高级数据挖掘技术和算法了。
很多人认为,大数据只是商业智能(BI)的新名称。
虽然这两者有相似之处,但是大数据已超出了BI的范畴。
⑵、大数据的“大”是相对的现在,各行业各组织确实正面对创纪录水平的数据增长。
据IDC称,我们每秒创造超过58 TB数据。
到2020年,将拥有超过35ZB的存储数据。
然而,大数据并不一定是巨大的;大数据并不在于其规模,而在于需要如何处理它。
拥有100 TB数据的小公司可能也存在大数据问题。
因为,他们需要提取、分析数据,并且据以作出决策。
⑶、大数据处理的数据的定义是广泛的它可以包含结构化和非结构化数据。
对于一些公司来说,最重要的是大数据的元数据,或者是关于数据的数据。
麦肯锡将大数据定义为:“其规模超出传统数据库软件的捕捉、存储、管理和分析能力的数据集”。
然而,这些数据集需要大量运行在数百甚至数千台服务器(云)中的并行软件(系统)来处理。
2、大数据业务成功必须遵循的七个步骤以下是确保大数据业务成功必须遵循的七个步骤。
⑴、承认存在问题这往往是最难的一个步骤。
以前,我们拒绝承认我们的网络已不再受防火墙和代理服务器设置的保护;而我们不得不为员工远程访问开放基础设施并拥抱互联网。
对于大数据,IT领导者需要评估其数据情况:①、你的数据集是否让你不堪重负?②、你不知道所有数据的位置?③、你(或者企业领导者)没有从你的数据中得到所需的信息?④、企业领导没有基于数据来做决策?⑤、有可能提高IT在企业政策和战略决策中的相关性?如果你像大多数公司一样,部分或者所有这些问题的答案都是肯定的,那么是时候控制你的数据,并从中挖掘出情报以提供给领导层做决策。
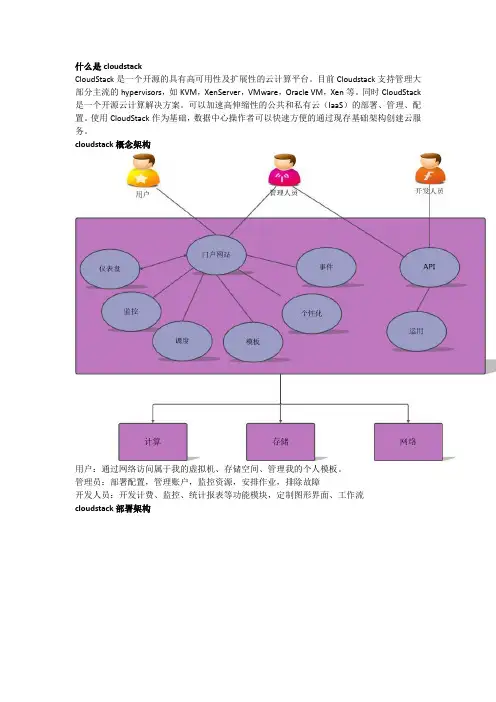
什么是cloudstackCloudStack是一个开源的具有高可用性及扩展性的云计算平台。
目前Cloudstack支持管理大部分主流的hypervisors,如KVM,XenServer,VMware,Oracle VM,Xen等。
同时CloudStack 是一个开源云计算解决方案。
可以加速高伸缩性的公共和私有云(IaaS)的部署、管理、配置。
使用CloudStack作为基础,数据中心操作者可以快速方便的通过现存基础架构创建云服务。
cloudstack概念架构用户:通过网络访问属于我的虚拟机、存储空间、管理我的个人模板。
管理员:部署配置,管理账户,监控资源,安排作业,排除故障开发人员:开发计费、监控、统计报表等功能模块,定制图形界面、工作流cloudstack部署架构Zone:Zone 对应于现实中的一个数据中心,它是CloudStack中最大的一个单元。
Pod:Pod 对应着一个机架。
同一个pod 中的机器在同一个子网(网段)中。
Cluster:Cluster 是多个主机组成的一个集群。
同一个cluster 中的主机有相同的硬件,相同的Hypervisor,和共用同样的存储。
同一个cluster 中的虚拟机,可以实现无中断服务地从一个主机迁移到另外一个上。
Host:Host 就是运行虚拟机(VM)的主机。
即从包含关系上来说,一个zone 包含多个pod,一个pod 包含多个cluster,一个cluster 包含多个host。
Primary storage:一级存储与cluster 关联,它为该cluster 中的主机的全部虚拟机提供磁盘卷。
一个cluster 至少有一个一级存储,且在部署时位置要临近主机以提供高性能。
Secondary storage:二级存储与zone 关联,它存储模板文件,ISO 镜像和磁盘卷快照。
∙模板:可以启动虚拟机的操作系统镜像,也包括了诸如已安装应用的其余配置信息。
一项目背景为公司其他部门提供的虚拟机运行在Vmware,Citrix的产品上,它们各自都是由相应的客户端管理虚拟机。
为了能够通过WEB方式对虚拟机进行统一化管理,我们开始寻找已有产品的官方解决方案,但是Vmware,Citrix官方的虚拟化WEB管理工具都是需要付费购买。
本身Vmware,Citrix的产品也不是开源的,从公司的利益以及其他技术方面的角度考虑,我们将采用开源的虚拟化平台软件来完全更换现有的商用虚拟化平台软件。
二开源虚拟化管理程序的选用熟知的开源虚拟化管理程序有XEN和KVM两种。
1.XEN介绍XEN是一个开放源代码的虚拟机管理程序。
由剑桥大学开发,它打算在单个计算上运行多达128个具有完全功能的操作系统。
在旧的处理器上运行XEN,操作系统必需进行显式地修改以在XEN上运行。
这使得XEN无需特殊硬件平台支持,就能达到高性能的虚拟化。
XEN通过一种叫做半虚拟化的技术获得高性能的表现。
在比较旧的硬件平台上,没有CPU的虚拟化支持,XEN可以通过半虚拟化获得比较高的性能。
半虚拟化使用虚拟机管理程序分享存取底层的硬件,但是它的客户操作系统集成了虚拟化方面的代码,该方法无需重新编译或引起陷阱,因为操作系统自身能够与虚拟化管理程序进行很好地协作,半虚拟化技术的优点是性能高,特别是I/0方面,但是操作系统需要进行更改,用户体验方面不强。
XEN也支持全虚拟化技术。
全虚拟化技术也称为原始虚拟化技术。
它使用虚拟机协调客户操作系统和原始硬件。
全虚拟化最大的优点是操作系统不需经过任何修改,但是性能方面不如半虚拟化。
2.KVM介绍KVM全称是Kernel-based Virtual Machine,即基于内核的虚拟机。
KVM项目代表下一代开源虚拟化。
该项目的目标是通过建立在先前的技术和充分利用当今的硬件条件下创造出一个现代的虚拟化管理程序。
KVM以一种可加载模块的方式移植到linux内核中,它将linux 转换成一种可以裸机安装的虚拟化管理程序。
CloudStack拥有强大的硬件管理能力,可以把企业的内部硬件资源统一管理起来,虚拟化为一个硬件资源池,实现按需分配。
CloudStack对硬件资源的管理功能全部放在“基础架构”菜单下。
登录后,选择左侧导航上的“基础架构”-->区域-->添加区域。
区域是CloudStack中最大的范围,可以理解为一个机房或数据中心。
你完全能够把天津/上海/广州等地区的机房都纳入同一个CloudStack中管理。
点击“添加区域”后会显示一个向导。
不得不赞一下,CloudStack这方面非常人性化,将复杂的操作简化为向导,一步步引导你操作,有效降低了使用难度。
不过,在接下来的操作中你要小心谨慎,因为每个选项都可能为你将来的使用埋雷!而CloudStack错误提示做的很差,许多问题根本没有准确的提示,甚至日志里也找不到任何有用的信息。
也许你会在为一个问题郁闷好久后突然豁然开朗,发现也许这个问题与当初建立基础架构时某个选项有关。
一、Add Zone根据虚拟化后网络类型的不同,“区域”分为“基本资源域”和“高级资源域”。
1、使用基本资源域,将对虚拟机采用扁平化管理,所有生成的虚拟机与主机都使用相同的CIDR段。
简单的说:你使用的网络是外网的话,则每台虚拟机都会产生一个公网IP,因此在前期规划IP地址时需要预留足够的IP地址。
由于虚拟机都在一个网段中,为保证安全,虚拟机间采用“安全组”方式进行网络隔离,用户可以通过“安全组”来设置虚拟机之间的连通性。
2、使用高级资源域,你可以将“公共网络”、“来宾网络”、“管理网络”、“存储网络”分别划分不同的网段,并能将不同的网络使用不同的网卡以提高性能。
在高级资源域中,虚拟机间的网络采用VLAN方式隔离,并且提供了“防火墙”、“负载均衡”、“端口转发”、“冗余路由器”等强大的网络管理功能。
注:高级资源域功能虽然强大,但未必就好,具体还是得看你的需求,按需选择。
今天我们就主要来讲“基本资源域”。
淮安区防汛防旱指挥系统设计与实现王龙宝;陶飞飞;吕鑫;余霖;韦明伦【摘要】针对淮安区防汛防旱信息系化建设中存在的问题,合理整合淮安市已建成的信息化资源,通过淮安市水利局私有云实现资源整合与数据共享,给出已建云平台的实施方案.采用Java EE相关技术,构建灵活的系统中间层,最终实现淮安区原始办公形式向高效信息化办公形式的转变和GIS地图预警,提供防汛防旱参考解决方案,大大提高淮安区水利局日常办公效率,加速淮安区信息化建设的步伐.【期刊名称】《水利信息化》【年(卷),期】2016(000)003【总页数】7页(P66-72)【关键词】防汛防旱;信息化;私有云;中间层;JavaEE;效率【作者】王龙宝;陶飞飞;吕鑫;余霖;韦明伦【作者单位】河海大学计算机与信息学院,江苏南京 210098;河海大学计算机与信息学院,江苏南京 210098;河海大学计算机与信息学院,江苏南京 210098;河海大学计算机与信息学院,江苏南京 210098;河海大学计算机与信息学院,江苏南京210098【正文语种】中文【中图分类】TV87近年来,我国在防汛信息化建设方面做了大量的基础工作。
张永进等[1]开发了不同级别的基于现代信息技术的防汛决策支持系统,建立了防汛决策系统的总体框架、设计开发了 AAF 中间件框架、水利信息门户的开发、设计开发了 WRAF 中间件开发平台和核心示范系统。
吴常清等[2]认为私有云的使用可提高企业的硬件资源利用率,降低企业的成本,除此之外,还能提高企业数据的安全性和服务的可靠性。
姜毅[3]等提出私有云平台的构建可以采用研究机构自行开发、商业解决方案和使用开源解决方案 3 种模式。
沈筱飞等[4]提出了基于云细算的信息资源整合方案,构建了水利信息资源集成模型。
冯彦清等[5]提出将 OpenStack 中间件部署在OpenStack 基础设施之上并向上层提供服务。
周力峰[6]指出以云计算为核心的新技术应用将会有助于提高水利科研核心竞争力。
Docker容器部署实现高可用的成功案例近年来,Docker容器技术在软件开发和部署领域得到了广泛的应用。
其轻量级、隔离性强、易于迁移和扩展的特点,使得许多企业纷纷尝试使用Docker容器来实现应用的高可用性。
本文将介绍一则成功的案例,展示了如何通过Docker容器部署实现高可用。
一、初步部署和测试该案例的背景是一个电商平台的系统升级。
传统的部署方式存在许多不足,如依赖性管理繁琐、环境配置复杂以及系统故障时恢复困难等。
为了解决这些问题,企业决定采用Docker容器部署实现高可用。
首先,他们进行了初步的部署和测试。
在一台云服务器上搭建了Docker环境,并将系统的各个模块封装为Docker镜像。
然后,使用Docker Compose编排文件定义了多个容器的服务组配置。
通过这种方式,他们实现了基本的系统部署和测试。
二、构建高可用集群在初步部署和测试的基础上,他们开始着手构建高可用的集群。
首先,他们采用了Docker Swarm来管理多台云服务器上的Docker容器。
通过Swarm集群,他们可以将容器动态调度和管理,实现了容器的高可用性和负载均衡。
其次,他们使用了Docker的网络功能,创建了一个专用的overlay网络,使得Docker容器在Swarm集群中可以互相通信。
这样,他们可以轻松地实现容器之间的服务发现和通信,并使得整个系统在分布式环境下能够顺利运行。
三、故障恢复和水平扩展为了实现高可用,他们还采用了一些故障恢复和水平扩展的策略。
首先,他们为每个容器配置了副本数,以确保即使某个节点故障,其他节点上的容器仍然可以继续提供服务。
当有容器故障或被下线时,Swarm集群会自动在其他节点上启动新的容器。
其次,他们使用了Docker的服务扩展功能,可以根据负载情况自动增加或减少容器的数量。
当访问压力增大时,Swarm集群会自动创建新的容器来应对。
而当访问压力减小时,多余的容器会被自动回收,以节省资源和降低成本。
软件系统运维技术中高可用集群的部署方法在软件系统运维技术中,高可用集群是一种常用的部署方法,它可以提高系统的稳定性和可靠性。
本文将介绍软件系统运维技术中高可用集群的部署方法,包括负载均衡、故障恢复、监控和自动化等方面的内容。
首先,负载均衡是高可用集群部署的重要组成部分。
负载均衡可以将流量分配到不同的服务器上,确保系统的负载均衡和高可用性。
常见的负载均衡算法有轮询算法、加权轮询算法和最少连接算法等。
通过将负载均衡器放置在系统前端,可以实现流量的智能分发,提高系统的性能和可用性。
其次,故障恢复是高可用集群部署中不可或缺的环节。
故障恢复包括故障检测、故障转移和故障恢复等步骤。
在高可用集群中,通过监控系统的各个节点的状态,一旦发现节点故障,可以快速地将流量切换到其他正常的节点上,从而实现系统的快速故障恢复。
监控是保证高可用集群运行稳定的关键。
通过对系统的实时监控,可以及时发现潜在的问题并采取相应的措施。
监控的内容包括服务器的负载情况、网络流量、磁盘空间、内存使用率等。
可以使用各种监控工具进行监控,如Zabbix、Nagios 等。
监控可以通过设置阈值和报警机制,实现对系统异常情况的及时响应和处理。
自动化是提高高可用集群部署效率和可靠性的重要手段。
通过自动化工具,可以快速地部署、配置和管理集群。
常见的自动化工具有Ansible、Puppet、SaltStack 等。
自动化部署可以减少人工操作的繁琐性和误操作的风险,提高部署的一致性和可靠性。
此外,备份和恢复策略也是保证高可用集群的重要环节。
定期对系统进行备份,以防系统发生故障时能够及时恢复。
备份的内容包括数据、配置文件及系统镜像等。
可以使用各种备份工具进行备份和恢复操作,如rsync、tar等。
总之,软件系统运维技术中高可用集群的部署方法包括负载均衡、故障恢复、监控和自动化等方面的内容。
通过合理部署高可用集群,可以提高系统的稳定性和可用性,并保证系统在面对故障时能够快速恢复正常运行。
CloudStack管理服务器的高可用部署1.1. 环境规划节点名称说明VLAN ID IPhaproxy 负载均衡节点,安装haproxy。
3 192.168.3.14/24 manager1 管理节点1,安装CloudStack的3 192.168.3.15/24management部分。
3 192.168.3.26/24 manager2 管理节点2,安装CloudStack的management部分。
3 192.168.3.27/24 mysql1 数据库节点1,安装CloudStack的mysql数据库,作为主库。
3 192.168.3.28/24 mysql2 数据库节点2,安装CloudStack的mysql数据库,作为从库。
Host 安装虚拟化管理软件xen。
4 192.168.4.41/24 storage CloudStack环境需要的存储。
5 192.168.5.5/24 结构图:以root用户登录管理服务器。
修改/etc/Hosts文件,添加fqdn名称。
#vi /etc/Hosts192.168.3.15 manager1#Hostname manager1配置安装光盘为YUM源。
#vi /etc/yum.repo.d/rhel.repo[rhel-cdrom]name=rhel-cdrombaseurl=file:///mediaenabled=1gpgcheck=0修改/etc/selinux/config文件关闭SELINUX,并重启服务器。
# vi /etc/selinux/config# This file controls the state of SELinux on the system.# SELINUX= can take one of these three values:# enforcing - SELinux security policy is enforced.# permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded.SELINUX=disabled# SELINUXTYPE= can take one of these two values:# targeted - Targeted processes are protected,# mls - Multi Level Security protection.SELINUXTYPE=targeted上传CloudStack安装包并解压缩。
安装管理服务器[M]。
配置NFS服务。
# chkconfig rpcbind on# chkconfig NFS on# service rpcbind start# service NFS startStarting NFS services:[ OK ]Starting NFS quotas:[ OK ]Starting NFS daemon:[ OK ]Starting NFS mountd:[ OK ]按照第一台的安装方法安装第二台管理节点1.4. 安装第一台数据库节点以root用户登录192.168.3.27服务器。
修改/etc/Hosts文件,添加fqdn名称。
#vi /etc/Hosts192.168.3.27 mysql1#Hostname mysql1配置安装光盘为YUM源。
#vi /etc/yum.repo.d/rhel.repo[rhel-cdrom]name=rhel-cdrombaseurl=file:///mediaenabled=1gpgcheck=0修改/etc/selinux/config文件关闭SELINUX,并重启服务器。
# vi /etc/selinux/config# This file controls the state of SELinux on the system.# SELINUX= can take one of these three values:# enforcing - SELinux security policy is enforced.# permissive - SELinux prints warnings instead of enforcing.# disabled - No SELinux policy is loaded.SELINUX=disabled# SELINUXTYPE= can take one of these two values:# targeted - Targeted processes are protected,# mls - Multi Level Security protection.SELINUXTYPE=targeted上传CloudStack安装包并解压缩。
安装MySQL数据库[D]。
修改/etc/my.conf文件。
# vi /etc/f[mysqld]datadir=/var/lib/mysqlsocket=/var/lib/mysql/mysql.sockuser=mysql# Disabling symbolic-links is recommended to prevent assorted security riskssymbolic-links=0innodb_rollback_on_timeout=1innodb_lock_wait_timeout=600max_connections=700log-bin=mysql-binbinlog-format = 'ROW'server_id=1[mysqld_safe]log-error=/var/log/mysqld.logpid-file=/var/run/mysqld/mysqld.pid设置MySQL的root密码,删除不必要的登录权限,创建复制用户。
并刷新权限。
#mysql –u rootmysql> grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option; mysql> delete from er where PASSWORD="";mysql> delete from er where HOST='localhost';mysql> grant replication slave on *.* to 'slaver'@'192.168.3.%' identified by '123456';mysql>flush privileges;重新启动mysql并用新密码重新登录。
如能正常登录mysql,则配置正确。
#/etc/init.d/mysqld restart#mysql –u root –p123456关闭掉mysql服务为下面的步骤做准备。
#/etc/init.d/mysqld stop1.5. 安装第二台数据库节点以root用户登录192.168.3.28服务器。
修改/etc/Hosts文件,添加fqdn名称。
#vi /etc/Hosts192.168.3.28 mysql2#Hostname mysql2配置安装光盘为YUM源。
#vi /etc/yum.repo.d/rhel.repo[rhel-cdrom]name=rhel-cdrombaseurl=file:///mediaenabled=1gpgcheck=0修改/etc/selinux/config文件关闭SELINUX,并重启服务器。
# vi /etc/selinux/config# This file controls the state of SELinux on the system.# SELINUX= can take one of these three values:# enforcing - SELinux security policy is enforced.# permissive - SELinux prints warnings instead of enforcing.# disabled - No SELinux policy is loaded.SELINUX=disabled# SELINUXTYPE= can take one of these two values:# targeted - Targeted processes are protected,# mls - Multi Level Security protection.SELINUXTYPE=targeted上传CloudStack安装包并解压缩。
安装MySQL数据库[D]。
修改/etc/my.conf文件。
# vi /etc/f[mysqld]datadir=/var/lib/mysqlsocket=/var/lib/mysql/mysql.sockuser=mysql# Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0innodb_rollback_on_timeout=1innodb_lock_wait_timeout=600max_connections=700server_id=2[mysqld_safe]log-error=/var/log/mysqld.logpid-file=/var/run/mysqld/mysqld.pid删除掉初始数据。
#/etc/init.d/mysqld stop#cd /var/lib/mysql/确保当前目录为/var/lib/mysql/,再执行下一行的命令:[root@Hostname mysql]#rm -fr *1.6. 做数据库复制从mysql1机器拷贝数据文件到mysql2机器,在mysql1机器上操作:#scp -fr /var/lib/mysql/* 192.168.3.28:/var/lib/mysql/启动mysql1与mysql2上的mysql服务分别在两台机器上执行#/etc/init.d/mysqld start查看mysql1机器的binlog位置点,在mysql1机器上执行:#mysql –u root -p123456mysql>show master status\G;看到如下显示,记录下File字段和Position字段的值:*************************** 1. row ***************************File:mysql-bin.000002Position:106Binlog_Do_DB:Binlog_Ignore_DB:1 row in set (0.00 sec)在mysql2机器上设置同步,并启动同步线程。