数据库查询事务
- 格式:pdf
- 大小:602.13 KB
- 文档页数:53

一、什么是transaction-sql语句Transaction-SQL语句是用于管理数据库事务的一种结构化查询语言。
事务是指一系列数据库操作,要么全部执行成功,要么全部执行失败,以保证数据的一致性和完整性。
Transaction-SQL语句提供了一种方式来管理这些事务操作,包括开始事务、提交事务和回滚事务等。
二、 Transaction-SQL语句的常用操作1. 开始事务(BEGIN TRANSACTION)- 用于标识事务的开始,将数据库操作置于一个事务中。
2. 提交事务(COMMIT TRANSACTION)- 用于提交已经执行的事务操作,表示事务执行成功。
3. 回滚事务(ROLLBACK TRANSACTION)- 用于撤销一系列数据库操作,回到事务开始之前的状态。
4. 保存点(SAVEPOINT)- 用于在事务中创建一个保存点,可以在事务回滚时回到保存点的状态。
5. 设置事务隔离级别(SET TRANSACTION ISOLATION LEVEL)- 用于设置事务的隔离级别,控制并发事务对数据的访问方式。
三、 Transaction-SQL语句的应用场景1. 复杂的数据操作- 包括更新、插入、删除等操作,需要保证一系列操作的一致性和完整性。
2. 并发事务控制- 多个用户对同一数据进行操作时,需要确保数据的并发访问不会导致数据的损坏或丢失。
3. 数据回滚- 当数据库操作发生错误或者执行结果不符合预期时,可以通过回滚事务来撤销已经执行的操作。
4. 事务隔离- 控制事务对数据的访问权限,保证事务的独立性和隔离性。
四、 Transaction-SQL语句的编写和优化1. 基本语法- 了解事务的基本操作语句和语法规则,包括BEGIN TRANSACTION、COMMIT TRANSACTION、ROLLBACK TRANSACTION等。
2. 逻辑严谨- 编写事务时要确保逻辑的严谨性,避免出现死锁、脏读等并发问题。

数据库transaction用法1. 介绍在数据库管理系统中,transaction(事务)是指一系列数据库操作,要么全部执行,要么全部不执行。
在现代的数据库系统中,transaction是一个非常重要的概念,它确保了数据库操作的一致性、可靠性和持久性。
本文将介绍数据库transaction的基本概念、用法和注意事项。
2. 事务的特性在数据库中,事务具有以下四个特性,通常被缩写为ACID:1)原子性(Atomicity):事务是一个不可分割的工作单位,要么全部执行,要么全部不执行。
2)一致性(Consistency):事务执行前后,数据库的完整性约束没有被破坏。
3)隔离性(Isolation):在并发情况下,事务的执行不会受到其他事务的影响。
4)持久性(Durability):一旦事务提交,其结果就会被永久保存在数据库中,即使系统发生故障也不会丢失。
3. 事务的基本操作在数据库系统中,事务具有四个基本操作,通常被缩写为ACID:1)开始事务(BEGIN TRANSACTION):标志着事务的开始。
2)提交事务(COMMIT TRANSACTION):将事务的操作永久保存到数据库中。
3)回滚事务(ROLLBACK TRANSACTION):撤销事务中的所有操作,回复到事务开始之前的状态。
4)保存点(SAVEPOINT):在事务中设置一个保存点,可以在事务回滚时回滚到该保存点。
4. 事务的使用在实际开发中,事务的使用非常普遍,特别是在对数据库进行复杂操作时。
下面是一些常见的事务使用场景:1)转账操作:假设有一个转账操作,需要从一个账户扣除一定金额然后添加到另一个账户。
这个操作必须是原子性的,否则就会出现数据不一致的情况。
2)订单处理:在订单处理中,通常涉及到减库存、生成订单、扣款等操作,这些操作必须是一致的,否则就会出现订单和库存不匹配的情况。
3)数据导入导出:在数据导入导出时,需要保证数据的完整性和一致性,这就需要使用事务来保证操作的一致性。

sql操作数据库(3)--外键约束、数据库表之间的关系、三⼤范式、多表查询、事务外键约束在新表中添加外键约束语法: constraint 外键约束名称 foreign key(外键的字段名称) references 主表表名(主键字段名)在已有表中添加外键约束:alter table 从表表名 add constraints 外键约束名称 foreign key(外键的字段名称) references 主表表名(主键字段名)删除外键语法: alter table 从表表名 drop foreign key 外键名称;级联操作:注意:在从表中,修改关联主表中不存在的数据,是不合法的在主表中,删除从表中已经存在的主表信息,是不合法的。
直接删除主表(从表中有记录数据关联) 会包删除失败。
概念:在修改或者删除主表的主键时,同时它会更新或者删除从表中的外键值,这种动作我们称之为级联操作。
语法:更新级联 on update cascade 级联更新只能是创建表的时候创建级联关系。
当更新主表中的主键,从表中的外键字段会同步更新。
删除级联 on delete cascade 级联删除当删除主表中的主键时,从表中的含有该字段的记录值会同步删除。
操作:-- 给从表student添加级联操作create table student(s_id int PRIMARY key ,s_name VARCHAR(10) not null,s_c_id int,-- constraint 外键约束名称 foreign key(外键的字段名称) references 主表表名(主键字段名)CONSTRAINT stu_cour_id FOREIGN key(s_c_id) REFERENCES course(c_id) -- 给s_c_id 添加外键约束ON UPDATE CASCADE ON DELETE CASCADE)insert into student VALUE(1,'⼩孙',1),(2,'⼩王',2),(3,'⼩刘',4);insert into student VALUE(4,'⼩司马',1),(5,'⼩赵',1),(6,'⼩钱',1);-- 查询学⽣表中的记录select * from student;-- 级联操作。

数据库中的数据查询数据库是指按照一定的数据模型建立起来的数据集合,它是数据管理技术的核心。
在一些大型的企业应用程序中,数据查询是非常重要的。
数据查询指的是根据一定的条件,从数据库中检索出所需要的数据。
在进行数据查询的过程中,我们可以通过一个查询语句来实现。
SQL语句在进行数据库的数据查询时,最常用的是SQL语句。
SQL(SQL Structured Query Language)语言是一种标准化的关系型数据库操作语言,它允许我们对数据库进行访问和操作。
SQL语句包含了非常多常用的命令,如SELECT、UPDATE、DELETE 和INSERT等,这些命令允许我们对数据进行增删改查的操作。
SELECT语句SELECT语句是SQL中最常用的查询语句,用于从数据库中查询出所需要的数据。
SELECT语句的基本格式如下:SELECT 列名 FROM 表名 WHERE 条件;```其中,列名是需要查询出来的列名称,可以是多个列,用逗号分隔开。
表名是需要查询的表名称,如果需要查询多个表,可以使用JOIN语句连接多个表。
WHERE是查询的条件,可以使用多个WHERE连接多个条件,可以使用AND或者OR链接多个条件。
SELECT语句可以非常灵活地查询出我们需要的数据,我们可以根据需求来设置查询条件,以此获得所需要的数据。
ORDER BY语句ORDER BY语句用于对查询结果进行排序。
使用ORDER BY语句,我们可以按照多个列进行排序,如:```SELECT 列名 FROM 表名 ORDER BY 列1 ASC, 列2 DESC;其中,ASC表示升序排列,DESC表示降序排列,我们可以根据需求来设置排序的方式。
GROUP BY语句GROUP BY语句用于对查询结果进行分组。
使用GROUP BY语句,我们可以根据某个列进行分组,并统计每个分组中的记录数量。
如:```SELECT 列1, COUNT(*) FROM 表名 GROUP BY 列1;```这条语句将根据列1进行分组,并统计每个分组中的记录数量。

sap查询数据库方法
在SAP系统中,有多种查询数据库的方法,以下是其中的几种:
1. 事务代码(Transactions Code):这是SAP系统中最常用的查询工具。
通过输入特定的事务代码,用户可以查询和操作数据库。
例如,SE16用于查
询表,SE11用于创建表等。
2. ABAP语言:ABAP是SAP的专用编程语言,用户可以使用ABAP语言
编写程序来查询和操作数据库。
通过使用ABAP的SQL语句或数据库函数,可以实现复杂的数据库查询和操作。
3. SAP SQL:SAP SQL是SAP系统的专用SQL查询工具,用户可以在其
中执行标准的SQL语句来查询数据库。
SAP SQL提供了对SAP数据库的访问和操作功能。
4. 外部工具:除了上述方法外,还可以使用一些外部工具来查询SAP数据库。
例如,可以使用数据库管理工具(如Oracle SQL Developer、Microsoft SQL Server Management Studio等)来查询SAP数据库。
这些工具可以提供更多的灵活性和功能,但需要一定的技能和经验。
无论使用哪种方法,查询数据库时都应该注意遵守系统的安全和数据保护政策,以确保数据的安全性和完整性。
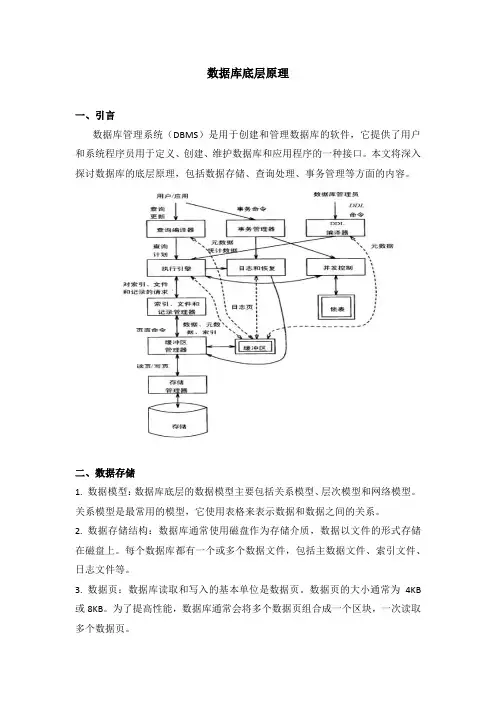
数据库底层原理一、引言数据库管理系统(DBMS)是用于创建和管理数据库的软件,它提供了用户和系统程序员用于定义、创建、维护数据库和应用程序的一种接口。
本文将深入探讨数据库的底层原理,包括数据存储、查询处理、事务管理等方面的内容。
二、数据存储1. 数据模型:数据库底层的数据模型主要包括关系模型、层次模型和网络模型。
关系模型是最常用的模型,它使用表格来表示数据和数据之间的关系。
2. 数据存储结构:数据库通常使用磁盘作为存储介质,数据以文件的形式存储在磁盘上。
每个数据库都有一个或多个数据文件,包括主数据文件、索引文件、日志文件等。
3. 数据页:数据库读取和写入的基本单位是数据页。
数据页的大小通常为4KB 或8KB。
为了提高性能,数据库通常会将多个数据页组合成一个区块,一次读取多个数据页。
三、查询处理1. 查询优化:查询优化是数据库底层的重要组成部分,它的目标是生成最有效的执行计划。
查询优化通常包括两个步骤:查询重写和查询执行计划生成。
2. 查询执行计划:查询执行计划描述了如何执行查询。
它包括一系列的操作,如读取数据页、连接数据页、过滤数据等。
3. 查询执行引擎:查询执行引擎是执行查询的实际组件。
它负责读取数据页、执行操作、返回结果。
四、事务管理1. 事务:事务是一组数据库操作,这些操作要么全部成功,要么全部失败。
事务的主要特性是原子性、一致性、隔离性和持久性,这被称为ACID属性。
2. 并发控制:并发控制是数据库底层的重要任务,它的目标是确保多个事务同时执行时,不会互相干扰。
常见的并发控制技术包括锁和多版本并发控制(MVCC)。
3. 恢复管理:恢复管理是数据库底层的另一个重要任务,它的目标是在系统崩溃或错误发生后,能够恢复数据库到一致的状态。
恢复管理通常包括日志管理和备份恢复。
五、内存管理1. 缓存:数据库通常会使用缓存来提高性能。
缓存的内容包括数据页、索引、查询执行计划等。
2. 缓冲池:缓冲池是数据库中的一个重要组件,它管理了数据库的缓存。

用sql语句dbcc log 查看SQL Server 数据库的事务日志1)用系统函数select * from fn_dblog(null,null)2)用DBCCdbcc log(dbname,4) --(n=0,1,2,3,4)1 - 更多信息plus flags, tags, row length2 - 非常详细的信息plus object name, index name,page id, slot id3 - 每种操作的全部信息4 - 每种操作的全部信息加上该事务的16进制信息默认 type = 0要查看MSATER数据库的事务日志可以用以下命令:DBCC log (master)一直以来我都很困惑,不知道怎么解析SQL SERVER的日志,因为微软提供了fn_dblog(NULL,NULL)与DBCC LOG获取数据库日志的基本信息,但是都是二进制码,看不懂。
最近终于成功解析了SQL SERVER LOG信息在fn_dblog(NULL,NULL)输出结果中,获取表名是AllocUnitName字段。
具体获取方法:AllocUnitName like 'dbo.TEST%'操作类型是:Operation数据是:[RowLog Contents 0]字段内容如果是UPDATE操作:修改后数据存放在[RowLog Contents 1]字段内最基本3种操作类型:'LOP_INSERT_ROWS','LOP_DELETE_ROWS','LOP_MODIFY_ROW' 具体解析代码如下:--解析日志create function dbo.f_splitBinary(@s varbinary(8000))returns @t table(id int identity(1,1),Value binary(1))asbegindeclare @i int,@im intselect @i=1,@im=datalength(@s)while @i<=@imbegininsert into @t select substring(@s,@i,1)set @i=@i+1endreturnendGOcreate function dbo.f_reverseBinary(@s varbinary(128))returns varbinary(128)asbegindeclare @r varbinary(128)set @r=0xselect @r=@r+Value from dbo.f_splitBinary(@s) a order by id descreturn @rendGOcreate proc [dbo].[p_getLog](@TableName sysname,@c int=100)/*解析日志: p_getLog 'tablename';*/asset nocount ondeclare @s varbinary(8000),@s1 varbinary(8000),@str varchar(8000),@str1varchar(8000),@lb int,@le int,@operation varchar(128)declare @i int,@lib int,@lie int,@ib int,@ie int,@lenVar int,@columnname sysname,@length int,@columntype varchar(32),@prec int,@scale intdeclare @TUVLength int,@vc int,@tc int,@bitAdd int,@bitCount int,@count intselect ,b.length, typename,b.colid,b.xprec,b.xscale,case when not like '%var%' and not in ('xml','text','image') then 1 else 2 end p,row_number() over(partition bycase when not like '%var%' and not in ('xml','text','image') then 1 else 2 end order by colid) pidinto #tfrom sysobjects a inner join syscolumns b on a.id=b.id inner join systypes c on b.xtype=c.xusertype=@TableNameorder by b.colidSELECT top(@c) Operation,[RowLog Contents 0],[RowLog Contents 1],[RowLog Contents 2],[RowLog Contents 3],[Log Record],id=identity(int,1,1) into #t1from::fn_dblog (null, null)where AllocUnitName like'dbo.'+@TableName+'%'andOperation in('LOP_INSERT_ROWS','LOP_DELETE_ROWS','LOP_MODIFY_ROW' )AND Context not in ('LCX_IAM','LCX_PFS')order by [Current LSN] descselect @tc=count(*) from #tselect @lb=min(id),@le=max(id) from #t1while @lb<=@lebeginselect @operation=Operation,@s=[RowLog Contents 0],@s1=[RowLog Contents 1] from #t1 whereid=@lbAND [RowLog Contents 1] IS NOT NULLset @TUVLength=convert(int,dbo.f_reverseBinary(substring(@s,3,2)))+3select @i=5,@str='',@vc=0,@bitCount=0select @lib=min(pid),@lie=max(pid) from #t where p=1while @lib<=@liebeginselect@columnname=name,@length=length,@columntype=typename,@prec=xprec,@scale=xscale, @vc=colid-1 from #t where p=1 andpid=@lib-- if @columntype<>'bit'-- print rtrim(@i)+'->'+rtrim(@length)if dbo.f_reverseBinary(substring(@s,@TUVLength,1+((@tc-1)/8))) & power(2,@vc) <> 0beginif @columntype<>'bit'select@str=@str+@columnname+'=NULL,',@i=@i+@lengthelsebeginselect @str=@str+@columnname+'=NULL,'set @bitAdd = case when @bitCount=0 then @i else @bitAdd endset @bitCount = (@bitCount + 1)%8set @i=@i+case @bitCount when 1 then 1 else 0 end -- print rtrim(@bitAdd)+'->'+rtrim(@length)endendelse if @columntype='char'select@str=@str+@columnname+'='+convert(varchar(256),substring(@s,@i,@length))+',',@i =@i+@lengthelse if @columntype='nchar'select@str=@str+@columnname+'='+convert(nvarchar(256),substring(@s,@i,@length))+',',@ i=@i+@lengthelse if @columntype='datetime'select@str=@str+@columnname+'='+convert(varchar,dateadd(second,convert(int,dbo.f_reve rseBinary(substring(@s,@i,4)))/300,dateadd(day,convert(int,dbo.f_reverseBinary(sub string(@s,@i+4,4))),'1900-01-01')),120)+',',@i=@i+8else if @columntype='smalldatetime'select@str=@str+@columnname+'='+convert(varchar,dateadd(minute,convert(int,dbo.f_reve rseBinary(substring(@s,@i,2))),dateadd(day,convert(int,dbo.f_reverseBinary(sub string(@s,@i+2,2))),'1900-01-01')),120)+',',@i=@i+4else if @columntype='int'select@str=@str+@columnname+'='+rtrim(convert(int,dbo.f_reverseBinary(substring(@s,@i ,4))))+',',@i=@i+4else if @columntype='decimal'select @str=@str+@columnname+'=DECIMAL,',@i=@i+@length else if @columntype='bit'beginset @bitAdd = case when @bitCount=0 then @i else @bitAdd endset @bitCount = (@bitCount + 1)%8select@str=@str+@columnname+'='+rtrim(convert(bit,substring(@s,@bitAdd,1)&power(2,case @bitCount when 0 then 8 else @bitCount end-1)))+',',@i=@i+case @bitCount when 1 then 1 else 0 end -- print rtrim(@bitAdd)+'->'+rtrim(@length)endset @lib=@lib+1endset @i=convert(int,dbo.f_reverseBinary(substring(@s,3,2)))+4+((@tc-1)/8) set @lenVar=convert(int,dbo.f_reverseBinary(substring(@s,@i,2)))set @i=@i+2set @ib=@i + @lenVar*2set @ie=convert(int,dbo.f_reverseBinary(substring(@s,@i,2)))set @count=0select @lib=min(pid),@lie=max(pid) from #t where p=2while @lib<=@liebegin-- print rtrim(@ib)+'->'+rtrim(@ie)select@columnname=name,@length=length,@columntype=typename,@vc=colid-1 from #t where p=2 andpid=@libif dbo.f_reverseBinary(substring(@s,@TUVLength,1+((@tc-1)/8))) & power(2,@vc) <> 0beginselect @str=@str+@columnname+'=NULL,'select @ib=@ie+1,@i=@i+2if @count<@lenVarset@ie=convert(int,dbo.f_reverseBinary(substring(@s,@i,2)))endelse if @columntype='varchar'beginselect@str=@str+@columnname+'='+convert(varchar(256),substring(@s,@ib,@ie-@ib+1))+','select @ib=@ie+1,@i=@i+2set@ie=convert(int,dbo.f_reverseBinary(substring(@s,@i,2)))endelse if @columntype='nvarchar'beginselect@str=@str+@columnname+'='+convert(nvarchar(256),substring(@s,@ib,@ie-@ib+1))+', 'select @ib=@ie+1,@i=@i+2set@ie=convert(int,dbo.f_reverseBinary(substring(@s,@i,2)))endset @count=@count+1set @lib=@lib+1endset @str=left(@str,len(@str)-1)IF @operation ='LOP_MODIFY_ROW'BEGINset@TUVLength=convert(int,dbo.f_reverseBinary(substring(@s1,3,2)))+3 select @i=5,@str1='',@vc=0,@bitCount=0select @lib=min(pid),@lie=max(pid) from #t where p=1while @lib<=@liebeginselect@columnname=name,@length=length,@columntype=typename,@prec=xprec,@scale=xscale, @vc=colid-1 from #t where p=1 andpid=@lib-- if @columntype<>'bit'-- print rtrim(@i)+'->'+rtrim(@length)if dbo.f_reverseBinary(substring(@s1,@TUVLength,1+((@tc-1)/8))) & power(2,@vc) <> 0beginif @columntype<>'bit'select @str1=@str1+@columnname+'=NULL,',@i=@i+@lengthelsebeginselect @str1=@str1+@columnname+'=NULL,'set @bitAdd = case when @bitCount=0 then @i else @bitAdd endset @bitCount = (@bitCount + 1)%8set @i=@i+case @bitCount when 1 then 1 else 0 end-- print rtrim(@bitAdd)+'->'+rtrim(@length) endendelse if @columntype='char'select@str1=@str1+@columnname+'='+convert(varchar(256),substring(@s1,@i,@length))+',' ,@i=@i+@lengthelse if @columntype='nchar'select@str1=@str1+@columnname+'='+convert(nvarchar(256),substring(@s1,@i,@length))+', ',@i=@i+@lengthelse if @columntype='datetime'select@str1=@str1+@columnname+'='+convert(varchar,dateadd(second,convert(int,dbo.f_re verseBinary(substring(@s1,@i,4)))/300,dateadd(day,convert(int,dbo.f_reverseBinary(substring(@s1,@i+4,4))) ,'1900-01-01')),120)+',',@i=@i+8else if @columntype='smalldatetime'select@str1=@str1+@columnname+'='+convert(varchar,dateadd(minute,convert(int,dbo.f_re verseBinary(substring(@s1,@i,2))),dateadd(day,convert(int,dbo.f_reverseBinary(substring(@s1,@i+2,2))) ,'1900-01-01')),120)+',',@i=@i+4else if @columntype='int'select@str1=@str1+@columnname+'='+rtrim(convert(int,dbo.f_reverseBinary(substring(@s1 ,@i,4))))+',',@i=@i+4else if @columntype='decimal'select @str1=@str1+@columnname+'=DECIMAL,',@i=@i+@lengthelse if @columntype='bit'beginset @bitAdd = case when @bitCount=0 then @i else @bitAdd endset @bitCount = (@bitCount + 1)%8select@str1=@str1+@columnname+'='+rtrim(convert(bit,substring(@s1,@bitAdd,1)&power(2, case @bitCount when 0 then 8 else @bitCount end-1)))+',',@i=@i+case @bitCount when 1 then 1 else 0 end-- print rtrim(@bitAdd)+'->'+rtrim(@length) endset @lib=@lib+1endset @i=convert(int,dbo.f_reverseBinary(substring(@s1,3,2)))+4+((@tc-1)/8) set @lenVar=convert(int,dbo.f_reverseBinary(substring(@s1,@i,2)))set @i=@i+2set @ib=@i + @lenVar*2set @ie=convert(int,dbo.f_reverseBinary(substring(@s1,@i,2)))set @count=0select @lib=min(pid),@lie=max(pid) from #t where p=2while @lib<=@liebegin-- print rtrim(@ib)+'->'+rtrim(@ie)select @columnname=name,@length=length,@columntype=typename,@vc=colid-1 from #t where p=2 andpid=@libif dbo.f_reverseBinary(substring(@s1,@TUVLength,1+((@tc-1)/8))) & power(2,@vc) <> 0beginselect @str1=@str1+@columnname+'=NULL,'select @ib=@ie+1,@i=@i+2if @count<@lenVarset @ie=convert(int,dbo.f_reverseBinary(substring(@s1,@i,2))) endelse if @columntype='varchar'beginselect@str1=@str1+@columnname+'='+convert(varchar(256),substring(@s1,@ib,@ie-@ib+1))+ ','select @ib=@ie+1,@i=@i+2set @ie=convert(int,dbo.f_reverseBinary(substring(@s1,@i,2)))endelse if @columntype='nvarchar'beginselect@str1=@str1+@columnname+'='+convert(nvarchar(256),substring(@s1,@ib,@ie-@ib+1)) +','select @ib=@ie+1,@i=@i+2set @ie=convert(int,dbo.f_reverseBinary(substring(@s1,@i,2)))endset @count=@count+1set @lib=@lib+1endset @str1=left(@str1,len(@str1)-1)ENDIF @operation ='LOP_MODIFY_ROW'BEGINprint @operation+'修改前值:'+@strprint @operation+'修改后值:'+@str1ENDELSEBEGINprint @operation+':'+@strENDset @lb=@lb+1ENDdrop table #t,#t1GO因为目前解析SQL 2008会有很多错误,要是认识微软引擎组的人就好了!。

多个数据库事务的操作顺序
数据库事务的操作顺序可以分为以下几个步骤:
1. 开始事务,首先,要明确开始一个事务。
在大多数数据库管
理系统中,可以使用BEGIN TRANSACTION或START TRANSACTION语
句来开始一个新的事务。
2. 执行SQL语句,一旦事务开始,接下来就是执行SQL语句。
这些SQL语句可以是数据查询、插入、更新或删除操作,根据业务
需求来执行相应的操作。
3. 提交或回滚事务,在执行完所有需要的SQL语句后,可以选
择提交事务或者回滚事务。
如果所有的操作都执行成功并且符合业
务逻辑,那么就可以提交事务,使得所有的操作永久生效。
如果在
执行过程中出现了错误或者不符合业务逻辑的情况,就可以选择回
滚事务,使得所有的操作都不会生效。
4. 结束事务,最后,无论是提交还是回滚事务,都需要结束事务。
在大多数数据库管理系统中,可以使用COMMIT语句来提交事务,或者使用ROLLBACK语句来回滚事务。
在结束事务之后,数据库会恢
复到事务开始之前的状态。
总的来说,数据库事务的操作顺序包括开始事务、执行SQL语句、提交或回滚事务以及结束事务。
这些步骤保证了数据库操作的
一致性、隔离性、持久性和原子性,确保了数据的完整性和可靠性。

数据库事务处理常见问题解决指南数据库事务是保证数据库操作的一致性和完整性的重要机制。
然而,在实际应用中,由于各种原因,数据库事务可能会遇到各种问题和障碍。
本文旨在提供一个数据库事务处理常见问题的解决指南,帮助读者更好地理解和解决这些问题。
一、死锁问题死锁问题在数据库事务处理中经常遇到。
当多个事务互相等待对方释放资源时,就会出现死锁现象。
为了解决死锁问题,我们可以采取以下措施:1. 死锁检测和解除:数据库系统通常会自动检测死锁,并采取相应的解除策略,如回滚某个事务,释放相应的资源,以打破死锁循环。
我们可以在数据库配置文件中设置相应的参数来控制死锁检测和解除机制。
2. 优化事务执行顺序:合理安排事务的执行顺序,以最小化死锁的概率。
可以通过尽早申请资源,尽快释放资源的方式来减少死锁的发生。
二、并发控制问题在并发环境下,多个事务同时访问数据库,可能导致数据的不一致性。
为了解决并发控制问题,我们可以采取以下措施:1. 乐观并发控制:这是一种乐观的策略,在事务提交之前不对数据进行加锁,而是使用版本检测的方式解决并发冲突。
通过记录数据的版本号,并在更新时比较版本号来判断是否存在冲突。
2. 悲观并发控制:这是一种悲观的策略,通过对数据进行加锁来避免并发冲突。
可以使用行级锁或表级锁来控制并发访问。
三、事务隔离级别问题数据库事务的隔离级别决定了事务之间的可见性和并发控制的程度。
常见的隔离级别包括读未提交、读已提交、可重复读和串行化。
在选择隔离级别时,我们需要权衡数据的一致性和并发性能。
解决事务隔离级别问题,可以采取以下措施:1. 设置合适的隔离级别:根据应用需求合理选择隔离级别。
一般来说,读已提交和可重复读是比较常用的隔离级别,可以平衡一致性和并发性能。
2. 优化查询性能:对于一些只读查询,可以考虑将隔离级别设置为读未提交,以提高并发性能。
另外,可以使用索引、分区等方式优化查询性能,减少数据访问的冲突。
四、回滚和恢复问题数据库事务处理过程中,可能会遇到回滚和恢复的问题。

关于数据库事务隔离级别的介绍事务(Transaction)是并发控制的基本单位。
所谓的事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。
例如,银行转账工作:从一个账号扣款并使另一个账号增款,这两个操作要么都执行,要么都不执行。
所以,应该把它们看成一个事务。
事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。
针对上面的描述可以看出,事务的提出主要是为了解决并发情况下保持数据一致性的问题。
事务具有以下4个基本特征。
● Atomic(原子性):事务中包含的操作被看做一个逻辑单元,这个逻辑单元中的操作要么全部成功,要么全部失败。
● Consistency(一致性):只有合法的数据可以被写入数据库,否则事务应该将其回滚到最初状态。
● Isolation(隔离性):事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正确性和完整性。
同时,并行事务的修改必须与其他并行事务的修改相互独立。
● Durability(持久性):事务结束后,事务处理的结果必须能够得到固化。
数据库肯定是要被广大客户所共享访问的,那么在数据库操作过程中很可能出现以下几种不确定情况。
● 更新丢失(Lost update):两个事务都同时更新一行数据,但是第二个事务却中途失败退出,导致对数据的两个修改都失效了。
这是因为系统没有执行任何的锁操作,因此并发事务并没有被隔离开来。
● 脏读取(Dirty Reads):一个事务开始读取了某行数据,但是另外一个事务已经更新了此数据但没有能够及时提交。
这是相当危险的,因为很可能所有的操作都被回滚。
● 不可重复读取(Non-repeatable Reads):一个事务对同一行数据重复读取两次,但是却得到了不同的结果。
例如,在两次读取的中途,有另外一个事务对该行数据进行了修改,并提交。
● 两次更新问题(Second lost updates problem):无法重复读取的特例。

SqlServer查看事务锁及执⾏语句⼀、查看当前锁定的事务select spid 进程,STATUS 状态, 登录帐号=SUBSTRING(SUSER_SNAME(sid),1,30),⽤户机器名称=SUBSTRING(hostname,1,12),是否被锁住=convert(char(3),blocked),数据库名称=SUBSTRING(db_name(dbid),1,20),cmd 命令,waittype as等待类型,last_batch 最后批处理时间,open_tran 未提交事务的数量from master.sys.sysprocessesWhere status='sleeping'and waittype=0x0000and open_tran>0⼆、查看锁定的语句等select t1.resource_type [资源锁定类型],DB_NAME(resource_database_id) as数据库名,t1.resource_associated_entity_id 锁定对象,t1.request_mode as等待者请求的锁定模式,t1.request_session_id 等待者SID,t2.wait_duration_ms 等待时间,(select TEXT from sys.dm_exec_requests r cross applysys.dm_exec_sql_text(r.sql_handle) where r.session_id=t1.request_session_id) as等待者要执⾏的SQL,(select SUBSTRING(qt.text,r.statement_start_offset/2+1,(case when r.statement_end_offset=-1then DATALENGTH(qt.text) else r.statement_end_offset end-r.statement_start_offset)/2+1 )from sys.dm_exec_requests r cross apply sys.dm_exec_sql_text(r.sql_handle)qtwhere r.session_id=t1.request_session_id) 等待者正要执⾏的语句,t2.blocking_session_id [锁定者SID],(select TEXT from sys.sysprocesses p cross applysys.dm_exec_sql_text(p.sql_handle)where p.spid=t2.blocking_session_id) 锁定者执⾏语句from sys.dm_tran_locks t1,sys.dm_os_waiting_tasks t2where t1.lock_owner_address=t2.resource_address。
Mysql查询正在执⾏的事务以及等待锁的操作⽅式使⽤navicat测试学习:⾸先使⽤set autocommit = 0;(取消⾃动提交,则当执⾏语句commit或者rollback执⾏提交事务或者回滚)在打开⼀个执⾏update查询正在执⾏的事务:SELECT * FROM information_schema.INNODB_TRX根据这个事务的线程ID(trx_mysql_thread_id):从上图看出对应的mysql 线程:⼀个94362 (第⼆个正在等待锁)另⼀个是93847(第⼀个update 正在执⾏没有提交事务)可以使⽤mysql命令:kill线程id 杀掉线程期间如果并未杀掉持有锁的线程:则第⼆个update语句提⽰等待锁超时查询mysql数据库中还可以使⽤:查看正在锁的事务SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;查看等待锁的事务SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;查询mysql数据库中存在的进程[sql] view plain copyselect * from information_schema.`PROCESSLIST`(show processlist;)概念:mysql中database、instance、session。
mysql中建⽴⼀个会话,不是和具体的数据库相连接,⽽是跟instance建⽴会话(即在navicat上执⾏⼀个查询,可以查询端⼝下对应的多个数据库,查询时数据库名+数据表名即可)在⼀个物理机上可以建⽴多个instance,通过port来区分实例。
⽽⼀个实例可以建⽴多个数据库,即⼀个会话可以操作⼀个实例上的多个数据库。
jdbc协议连接数据库:jdbc:mysql://localhost:3306/test jdbc协议连接本地上端⼝为3306实例下的test数据库,则查询数据表时不需要加上数据库的名字。
数据库中的事务处理及其应用技巧事务处理是数据库管理系统(DBMS)中的一个重要概念,它是为了保证数据库中的数据操作的一致性、可靠性和完整性而提供的一种机制。
事务是指由一个或多个数据库操作所构成的逻辑工作单元,这些操作要么全部执行,要么全部不执行,没有中间状态。
事务具有以下特点:1. 原子性(Atomicity):一个事务被视为一个不可分割的最小工作单元,要么全部执行成功,要么全部不执行。
2. 一致性(Consistency):事务的执行不会破坏数据库的完整性约束。
3. 隔离性(Isolation):并发执行的事务之间相互隔离,每个事务对其他事务的操作结果是不可见的。
4. 持久性(Durability):一个事务成功提交后,它对数据库的修改将永久保存,即使系统崩溃也不会丢失。
在实际应用中,事务处理有着广泛的应用技巧,以下是一些常见的应用技巧:1.合理划分事务:将一系列数据库操作分组执行,使得每个事务尽可能简单,执行时间尽可能短。
这样可以减少锁冲突和资源竞争,提高并发性能。
2.设置适当的隔离级别:根据应用需求设置适当的隔离级别,如读未提交、读已提交、可重复读和串行化等。
不同的隔离级别会对并发性能和数据一致性产生不同的影响。
3.使用乐观并发控制:对于读多写少的场景,可以使用乐观并发控制机制,如版本号或时间戳来判断数据是否发生冲突,以减少锁的开销。
4.利用索引提高查询性能:在事务处理中,经常需要进行查询操作。
合理设计和使用索引可以提高查询性能,减少全表扫描的开销。
5.批处理操作:对于批量数据处理,可以将多个操作封装成一个事务,提高执行效率。
比如,批量插入、批量更新、批量删除等操作。
6.合理利用缓存:对于读多写少的场景,可以使用缓存来减少对数据库的访问,提高读取效率。
但同时需要考虑缓存与数据库的一致性问题。
7.异常处理和回滚:对于可能出现异常的操作,在事务处理中需要合理的异常处理机制和回滚机制,保证数据的一致性和完整性。
数据库事务、事务隔离级别以及锁机制详解以下主要以MySQL(InnoDB引擎)数据库为讨论背景,纯属个⼈学习总结,不对的地⽅还请指出!什么是事务?事务是作为⼀个逻辑单元执⾏的⼀系列操作,要么⼀起成功,要么⼀起失败。
⼀个逻辑⼯作单元必须有四个属性,称为 ACID(原⼦性、致性、隔离性和持久性)属性,只有这样才能成为⼀个事务。
数据库事物的四⼤特性(ACID):1)原⼦性:(Atomicity)务必须是原⼦⼯作单元;对于其数据修改,要么全都执⾏,要么全都不执⾏。
2)⼀致性:(Consistency)事务在完成时,必须使所有的数据都保持⼀致状态。
在相关数据库中,所有规则都必须应⽤于事务的修改,保持所有数据的完整性。
事务结束时,所有的内部数据结构(如 B 树索引或双向链表)都必须是正确的。
3)隔离线:(Isolation)由并发事务所作的修改必须与任何其它并发事务所作的修改隔离。
事务查看数据时数据所处的状态,要么另⼀并发事务修改它之前的状态,要么是另⼀事务修改它之后的状态,事务不会查看中间状态的数据。
这为可串⾏性,因为它能够重新装载起始数据,并且重播⼀系列事务,以使数据结束时的状态与原始事务执的状态相同。
4)持久性:(Durability)事务完成之后,它对于系统的影响是永久性的。
该修改即使出现系统故障也将⼀直保持。
事务并发时会发⽣什么问题?(在不考虑事务隔离情况下)1)脏读:脏读是指在⼀个事务处理过程⾥读取了另⼀个未提交的事务中的数据。
例:事务A修改num=123------事务B读取num=123(A操作还未提交时)事务A回滚此时就会出现B事务读到的num并不是数据库中真正的num的值,这种情况就叫“脏读”。
2)不可重读:不可重复读是指在对于数据库中的某个数据,⼀个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另⼀个事务修改并提交了。
例:事务A读取num=123(事务A并未结束)------事务B修改num=321,并提交了事务事务A再次读取num=321此时就会出现同⼀次事务A中两次读取num的值不⼀样,这种情况就叫“不可重读”。
数据库查询操作实例数据库查询是一项非常常见和重要的操作,用于从数据库中检索所需的数据。
下面是一些数据库查询操作的实例:1.简单查询:从数据库表中选择所有的数据sqlSELECT*FROM表名;2.条件查询:根据特定条件过滤数据sqlSELECT*FROM表名WHERE条件;例如,从名为`students`的表中选择所有年龄大于18岁的学生记录:sqlSELECT*FROMstudentsWHEREage>18;3.查询特定字段:只选择所需的字段,而不是全部字段sqlSELECT列1,列2FROM表名;例如,从名为`employees`的表中选择员工的姓名和工资:sqlSELECTname,salaryFROMemployees;4.查询结果排序:根据特定的列对结果进行排序sqlSELECT*FROM表名ORDERBY列名ASC/DESC;例如,从名为`products`的表中选择所有产品记录,并按价格降序排列:sqlSELECT*FROMproductsORDERBYpriceDESC;5.分组查询:根据特定的列对数据进行分组sqlSELECT列1,列2,聚合函数FROM表名GROUPBY列1,列2;例如,从名为`orders`的表中按客户ID分组,并计算每个客户总的订单数量:sqlSELECTcustomer_id,COUNT(*)FROMordersGROUPB Ycustomer_id;6.连接查询:将多个表的数据联合在一起查询sqlSELECT列1,列2FROM表1INNERJOIN表2ON表1.列=表2.列;例如,从名为`orders`和`customers`的表中选择订单信息,并显示对应的客户姓名:sqlSELECTorders.order_id,FROMordersINNERJOINcustomersONorders.customer_id=custo mers.customer_id;以上是一些常见的数据库查询操作的实例。
数据库事务处理的常见问题与解决方法数据库事务处理是现代软件开发中非常重要的一部分,它保证了数据的一致性以及并发操作的正确性。
然而,在实际应用中,我们经常会遇到一些与事务处理相关的问题,本文将讨论这些常见问题并提供解决方法。
一、数据库死锁在多用户并发访问数据库时,死锁是一个常见的问题。
当两个或多个事务互相等待对方释放资源时,就会发生死锁。
这会导致系统停顿,影响性能。
解决方法:1. 死锁检测与解除:数据库管理系统通常会提供死锁检测与解除机制,可以自动检测死锁并解除。
开发人员可以利用这些机制来解决死锁问题。
2. 合理设计数据库表结构:通过合理设计表结构,减少事务间的资源竞争,可以有效降低死锁的概率。
3. 设置超时时间:为每个事务设置超时时间,当超过设定时间后仍未完成,则自动释放锁资源,避免死锁的发生。
二、并发读写引发的数据不一致问题在并发读写的场景下,可能会出现数据不一致的问题。
比如读取到了其他事务尚未提交或已回滚的数据,导致了数据的错误。
解决方法:1. 使用事务隔离级别:数据库系统通常提供不同的事务隔离级别,可以通过设置适当的隔离级别来避免数据不一致的问题。
如Serializable(串行化)级别可以保证最高的隔离性,但性能较低。
2. 锁机制:通过使用数据库的锁机制,如行锁、表锁等,在读写操作前正确获取和释放锁,以保证数据的一致性。
3. 使用乐观锁或悲观锁:在对数据进行读写操作时,可以使用乐观锁或悲观锁机制来实现并发控制,确保数据的正确性。
三、事务处理失败导致数据丢失在事务处理过程中,如果发生故障或错误,可能会导致事务无法正常完成,从而造成数据丢失的问题。
解决方法:1. 日志与回滚:在数据库管理系统中,通常会有事务日志机制,记录每个事务的操作过程。
当事务处理失败时,可以通过回滚操作将数据恢复到之前的状态。
2. 定期备份与恢复:对于重要的数据库系统,可以定期进行备份,并建立数据恢复机制,以防数据丢失。
数据库查询操作方法
数据库查询操作方法有以下几种:
1. 使用SELECT语句查询数据:使用SELECT语句可以查询数据库中的数据。
基本语法如下:
SELECT 列名1, 列名2, ... FROM 表名WHERE 条件;
2. 使用WHERE子句进行条件查询:WHERE子句用于指定查询条件,只返回符合条件的数据。
3. 使用ORDER BY子句排序查询结果:ORDER BY子句用于对查询结果进行排序,默认是按升序排列。
4. 使用LIMIT子句限制查询结果数量:LIMIT子句用于限制查询结果的数量,可以指定返回的行数。
5. 使用JOIN操作连接多个表:JOIN操作可以在多个表之间建立关联关系,从而查询相关联的数据。
6. 使用聚合函数进行数据统计:聚合函数可以对查询结果中的数据进行统计操作,如求和、平均值、最大值、最小值等。
7. 使用GROUP BY子句进行分组查询:GROUP BY子句用于将查询结果按照指定的列进行分组,可以与聚合函数一起使用。
8. 使用HAVING子句进行分组条件过滤:HAVING子句用于对分组后的结果进行条件过滤。
9. 使用子查询查询嵌套数据:子查询可以在SELECT语句中嵌套其他查询语句,用于查询复杂的数据。
10. 使用索引提高查询性能:可以通过为查询字段创建索引来提高查询的执行速度。
以上是常用的数据库查询操作方法,根据具体需求可以选择适合的方法进行查询。