Kdump和Crash的配置方法与内核故障原因分析介绍
- 格式:pdf
- 大小:1.68 MB
- 文档页数:23

crash 配置规则Crash 配置规则在软件工程中,Crash 是指软件在运行过程中由于各种原因而发生的异常终止或崩溃。
为了提高软件的稳定性和可靠性,开发者需要针对不同的场景制定适当的 Crash 配置规则。
本文将详细介绍Crash 配置规则的相关内容。
一、Crash 配置规则的重要性Crash 是软件开发过程中难以避免的问题,它可能导致用户数据丢失、程序功能异常以及用户体验降低等严重后果。
因此,制定合理的 Crash 配置规则可以帮助开发者快速定位和解决问题,提高软件的稳定性和用户满意度。
二、Crash 配置规则的制定原则1. 异常类型分类:根据异常类型的不同,制定相应的配置规则。
常见的异常类型包括空指针异常、数组越界异常、内存泄漏等。
针对不同的异常类型,可以采取不同的处理策略,比如捕获异常并输出日志、进行错误处理或者重新启动应用程序等。
2. 异常频率判定:根据异常发生的频率,制定相应的配置规则。
如果某个异常频率很高,可以将其设置为致命异常,立即终止程序运行并输出详细的日志信息。
而对于一些偶发的异常,可以设置为非致命异常,只输出简略的日志信息,以便定位问题。
3. 异常捕获机制:在制定 Crash 配置规则时,需要考虑异常捕获的机制。
可以通过在关键代码块中使用 try-catch 语句来捕获异常,并在 catch 块中输出详细的日志信息。
此外,还可以使用线程异常处理器(Thread.UncaughtExceptionHandler)来捕获线程中的异常。
4. 日志信息记录:在配置规则中,应该明确要求日志信息的记录方式和格式。
日志信息应包括异常类型、异常发生的位置、异常发生的时间以及相关的堆栈信息等。
同时,为了方便定位问题,可以在日志中添加关键变量的值,以便更好地分析异常的原因。
三、Crash 配置规则的实施步骤1. 分析需求:首先,开发团队需要对软件的需求进行全面的分析和了解,明确软件的功能模块和关键代码块。

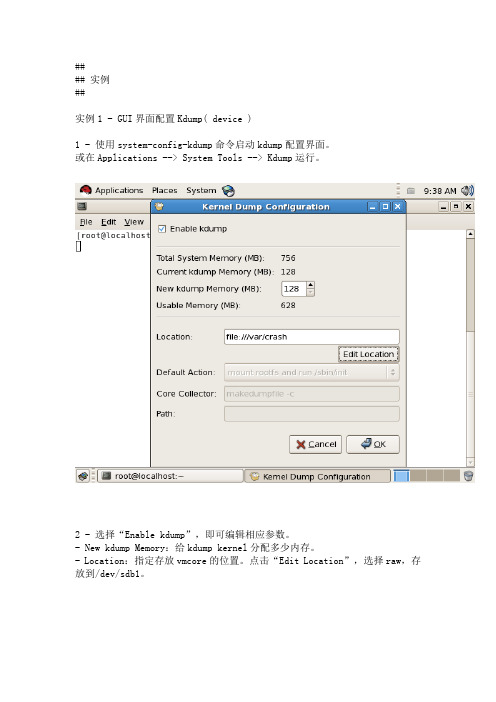
#### 实例##实例1 - GUI界面配置Kdump( device )1 - 使用system-config-kdump命令启动kdump配置界面。
或在Applications --> System Tools -->Kdump运行。
2 - 选择“Enable kdump”,即可编辑相应参数。
- New kdump Memory:给kdump kernel分配多少内存。
- Location:指定存放vmcore的位置。
点击“Edit Location”,选择raw,存放到/dev/sdb1。
3 - 配置完毕后,会提示重启系统,载入新的设定。
4 - 由于Kdump配置未生效,所以提示kdump启动失败,请忽略此FAILED,重启系统即可。
5 - 检查/boot/grub/grub.conf文件,发现在kernel后会自动添加上crashkernel=128M@16M。
6 - 检查/etc/kdump.conf文件,在文件尾部添加raw /dev/sdb1,所以此文件指定存储vmcore的方式。
7 - 检查Kdump服务状态。
8 - 系统重启之后,检查kdump服务。
9 - Testing Kdump- cache中的数据输出到磁盘# sync- 触发crash dump# echo c > /proc/sysrq-trigger- 服务器自动重启后,在服务器端查询vmcore - 在/var/log/messages下有如下信息。
实例2 - GUI界面配置Kdump( file on disk )1 - 使用system-config-kdump命令启动kdump配置界面。
或在Applications --> System Tools -->Kdump运行。
2 - 选择“Enable kdump”,即可编辑相应参数。
- New kdump Memory:给kdump kernel分配多少内存。

kdump原理kdump是一个用于系统崩溃时自动采集内核转储(dump)信息的工具。
在Linu某系统中,当系统遇到严重故障导致崩溃时,会生成一个内核转储文件,也被称为"vmcore"或"crash dump",用于分析故障原因。
kdump的原理是在系统崩溃时,将系统的转储信息保存到一个预定义的磁盘分区或者网络文件共享中,以便在系统重启后进行分析和调试。
1. 配置:在系统启动过程中,通过修改内核启动参数来指定kdump的配置信息。
主要设置包括转储保存的位置、转储文件名、触发转储的方式、转储前清理缓存的策略等。
2. 内存快照:当系统崩溃时,kdump首先捕获当前系统的内存快照。
这个过程称为"crash capture"。
kdump使用了一种特殊的机制,即通过在宕机过程中建立一个专用的内存分区,将内核和存储在内存中的关键信息复制到该分区中。
这个分区通常被称为"crashkernel"。
3. 内存复制:一旦内存快照被捕获,kdump会将这个快照的内容复制到指定的转储位置。
在复制过程中,kdump会排除一些不必要的信息,以减小转储文件的大小并提高分析效率。
4. 重启:在完成内存复制后,kdump会触发系统重启。
这个重启被称为"crash reboot"。
5. 分析:在系统重启后,可以使用特定的工具(如crash命令)来分析转储文件的内容,进一步了解崩溃原因。
分析可以包括查看进程状态、显示日志、检查系统资源和硬件状态等,以定位故障原因。
总结起来,kdump是Linu某系统中用于协助故障诊断和调试的一种工具,它通过在系统崩溃时自动采集内核转储信息并保存到指定位置,方便后续分析。
通过kdump,可以快速定位和解决系统崩溃的原因,提高系统的可靠性和稳定性。

关于centos启动报错:FailedtostartCrashrecoverykernel。
在VMware中安装了centos,重启时报错:Failed to start Crash recovery kernel arming本质是kdump服务启动失败先来说⼀下,什么是kdumpKdump是⼀个内核崩溃转储机制,在系统崩溃的时候,Kdump将捕获系统信息,这对于针对崩溃的原因⾮常有帮助。
注意,Kdump需要预留⼀部分系统内存,⽽且这部分内存对于其他⽤户是不可⽤的。
启动失败的原因查看 /etc/grub.conf⽂件,发现crashkernel=auto,问题就出在这⼉:注:centos7后为:vi /etc/grub2.cfg系统对crashkernel=auto的定义为:如果系统的内存 <= 8 GB 对kdump kernel不会保留任何内容;也就是说,crashkernel=auto 等于关掉了机器上的kdump功能;如果系统的内存> 8 GB 但是<= 16 GB,crashkernel=auto会保留256M,等同于crashkernel=256M;如果系统内存> 16GB,crashkernel=auto会保留512M,等同于crashkernel=512M。
安装虚拟机时,给虚拟机设置的内存为1G,所以说系统关掉了kdump功能,造成了kdump服务启动失败。
找到了原因,重新给crashkernel设置参数即可:在 kdump 的配置中,往往困惑于 crashkernel 的设置。
“crashkernel=X@Y”,X 应该多⼤? Y⼜应该设在哪⾥呢?实际我们可以完全省略“@Y”这⼀部分,这样,kernel 会为我们⾃动选择⼀个起始地址。
⽽对于 X 的⼤⼩,般对 i386/x86_64 的系统,设为 128M 即可;对于 powerpc的系统,则要设为 256M。

KernelPanic常见原因以及解决⽅法Technorati 标签:出现原因1. Linux在中断处理程序中,它不处于任何⼀个进程上下⽂,如果使⽤可能睡眠的函数,则系统调度会被破坏,导致kernel panic。
因此,在中断处理程序中,是不能使⽤有可能导致睡眠的函数(例如信号量等)。
在中断发起的软中断中,其上下⽂环境有可能是中断上下⽂,同理,也不能调⽤可能导致睡眠的函数。
软中断执⾏时,全局中断是打开的,⽽中断程序执⾏时,全局中断是禁⽌的。
软中断除了系统调度进⼊点,当软中断数量频繁时,内核中有⼀个专门的软中断的后台程序daemon来处理其事务。
2. 内核堆栈溢出,或者指针异常访问时,会出现kernel panic。
堆栈溢出:程序循环或者多层嵌套的深度过多时,可能会导致栈溢出。
参考3. 除0异常、内存访问越界、缓冲区溢出等错误时,当这些事件发⽣在应⽤程序时,Linux内核的异常处理机制可以对这些由应⽤程序引起的情况予以处理。
当应⽤程序出现不可恢复性错误时,Linux内核可以仅仅终⽌产⽣错误的应⽤程序,⽽不影响其他程序。
如果上述操作发⽣在内核空间,就会引起kernel panic。
4. 内核陷⼊死锁状态,⾃旋锁有嵌套使⽤的情况。
5. 在内核线程中,存在死循环的操作。
解决⽅法1. 全部排查内核中可能造成睡眠的函数调⽤地⽅。
如果是⾃⼰写的模块,则在调⽤睡眠函数之前打印出特征⽇志,以备查验。
在内核代码中的特定位置加⼊printk调试调⽤,直接把需要关⼼的信息打印到屏幕上,从⽽得知程序执⾏的路径。
2. 在可疑的地⽅,调⽤dump_stack()函数或者__backtrace(),打印当前CPU的堆栈调⽤函数。
3. 打开Linux内核的崩溃转储机制(kdump机制,⽣产vmcore⽂件),当系统crash时,将内存内容保存到磁盘,或者通过⽹络发送到故障服务器,或者直接使⽤内核调试器。
crash⼯具⽤于调试内核崩溃转储⽂件。
kdump原理范文1. 内核崩溃触发机制:当内核发生严重错误或异常时,通常会导致系统崩溃。
例如,内核空指针访问、内核死锁、内存溢出等。
kdump通过监测内核崩溃信号,以及注册dump-capture内存的回调函数来感知内核的崩溃状态。
2. 分析和捕获内核转储:一旦kdump感知到内核崩溃,它会触发一个新的处理流程来收集并保存内核转储文件。
这涉及到几个步骤:- kdump首先会启动一个专用的kdump内核,该内核是在系统正常运行期间预先加载的。
- kdump内核会安装一个新的页表,并将当前的物理内存和虚拟内存映射到新的页表。
- kdump内核通过启动第二个内核实例(崩溃内核),并将其内存状态保存到磁盘上的转储文件中。
- 转储文件通常存储在专门的kdump分区、NFS共享目录或本地磁盘中。
3.崩溃转储文件的恢复:一旦内核转储文件生成,可以将其传输到另一台机器进行进一步分析和调试。
恢复过程如下:- kdump可以通过PXE(预启动执行环境)引导重新启动机器,并指定磁盘上的内核转储文件。
- 转储文件将被加载到一个新的kdump内核中,并通过分析工具(如crash、gdb等)进行分析。
-分析工具可提供有关崩溃的堆栈跟踪、内核寄存器和内存转储等信息,帮助开发人员定位问题。
4. 可靠性和可用性:kdump的设计目标之一是在系统崩溃时仍能正常工作,以确保内核转储文件的正确捕获。
为了实现这一目标,kdump采用以下机制:- 内核转储过程中,kdump内核运行在一个独立的地址空间中,不会受到崩溃内核的影响。
- kdump内核采用专用的中断处理和页分配机制,以避免与崩溃内核的冲突。
- kdump内核会禁用对一些设备的访问和一些驱动程序来确保稳定性。
总的来说,kdump通过监测和捕获内核崩溃信号,并将内核和相关数据转储到磁盘上,以实现对内核崩溃的分析和调试。
它采用独立的kdump内核运行环境和专用的处理机制,以确保在系统崩溃时仍能正常工作,并保证转储文件的可用性和可靠性。
Kdump之kdump分析Kdump之kdump分析 (2011-10-04 15:43)分类:Kernel说Kexec是基于kexec机制工作的,但关于Kdump到底是怎么实现的,比如将第二个内核怎么加载到具体的保留位置,第一个内核crash 后怎么传需要的elfcorehdr和memmap参数给第二个内核,另外第二个内核是怎么调用makdedumpfile来过滤压缩页的,网上一些资料给的都太概括了,还没找到相关分析的,看了下代码,有了个大概,可能部分理解有误,欢迎拍砖和探讨.先看一张图,这个是网上找到的Vivek Goyal的PPT中两幅图,这里合成一张了KEXEC的设计是用新内核去覆盖原内核位置;而KDUMP是预留一块内存来加载第二个内核(和相关数据),Crash后第二个内核在原位置运行(不然就达不到相关目的了),收集第一个内核的相关内存信息。
在KDUMP中Kexec算是一个引导器,类似GRUB(2). 真正的实现是在kexec-tools中,对于RH系列,相关的kexec-tools RPM包中除了封装相关程序外,还有个/etc/rc.d/init.d/kdump shell脚本来负责将相关工具粘在一起下面来说下大致流程:1).第一个内核以crashkernel启动后,内核解析此crashkernel命令行选项并将此选项值放到crash_res中,并预留相关内存区域/etc/init.d/kdump start启动时(只摘录部分相关的)if[-z "$kdump_path"]; thencoredir="/var/crash/`date +"%Y-%m-%d-%H:%M"`"elsecoredir="${kdump_path}/`date +"%Y-%m-%d-%H:%M"`"fimkdir-p $coredircp --sparse=always /proc/vmcore $coredir/vmcore-incompleteexitcode=$?if[$exitcode== 0 ]; thenmv $coredir/vmcore-incomplete $coredir/vmcore$LOGGER"saved a vmcore to $coredir"else$LOGGER"failed to save a vmcore to $coredir"fireturn$exitcode}function load_kdump(){if[-z "$KDUMP_COMMANDLINE"]thenKDUMP_COMMANDLINE=`cat /proc/cmdline`fiARCH=`uname -m`if["$ARCH"=="ppc64"]thenMEM_RESERVED=`grep"crashkernel=[0-9]\+[MmKkGg]@[0-9]\+[MmGgKk]"/proc/cmdline`elseMEM_RESERVED=`grep"Crash kernel"/proc/iomem | grep-v "00000000-00000000"`fiif[-z "$MEM_RESERVED"]then$LOGGER"No crashkernel parameter specified for running kernel"return 1fiif["$ARCH"=="i686"-o "$ARCH"=="i386"]thenneed_64bit_headersif[$?== 1 ]thenFOUND_ELF_ARGS=`echo $KEXEC_ARGS|grep elf32-core-headers`if[-n "$FOUND_ELF_ARGS"]thenecho -n "Warning: elf32-core-headers overrides correct elf64 setting"warningechoelseKEXEC_ARGS="$KEXEC_ARGS --elf64-core-headers"fielseFOUND_ELF_ARGS=`echo $KEXEC_ARGS|grep elf64-core-headers`if[-z "$FOUND_ELF_ARGS"]thenKEXEC_ARGS="$KEXEC_ARGS --elf32-core-headers"fififiKDUMP_COMMANDLINE=`echo $KDUMP_COMMANDLINE|sed -e 's/crashkernel=[0-9]\+[MmKkGg]@[0-9]\+[MmGgKk]//'`KDUMP_COMMANDLINE=`echo $KDUMP_COMMANDLINE|sed -e's/mem=[0-9]\+[GMKgmk]* *//'`KDUMP_COMMANDLINE=`echo $KDUMP_COMMANDLINE|sed -e's/hugepages=[0-9]\+ */ /g'-e's/hugepagesz=[0-9]\+[kKmMgG]* *//g'`KDUMP_COMMANDLINE="${KDUMP_COMMANDLINE}${KDUMP_COMMANDLINE_APPEND}"avoid_cdrom_driveKDUMP_COMMANDLINE="${KDUMP_COMMANDLINE}${KDUMP_IDE_NOPROBE_COMMANDLINE}"#最主要的是这部分KEXEC_OUTPUT=`$KEXEC$KEXEC_ARGS$standard_kexec_args \--command-line="$KDUMP_COMMANDLINE" \--initrd=$kdump_initrd$kdump_kernel 2>&1` if[$?== 0 ]; then$LOGGER"kexec: loaded kdump kernel"return 0else$LOGGER$KEXEC_OUTPUT$LOGGER"kexec: failed to load kdump kernel"return 1fi}function start(){#TODO check raw partition for core dump imagestatusrc=$?if[$rc== 2 ]; thenecho -n "Kdump is not supported on this kernel"; failure; echoreturn 1;elseif[$rc== 0 ]; thenecho -n "Kdump already running"; success; echoreturn 0fificheck_configif[$?!= 0 ]; thenecho -n "Starting kdump:"; failure; echo$LOGGER"failed to start up, config file incorrect"return 1fiload_kdumpif[$?!= 0 ]; thenecho -n "Starting kdump:"; failure; echo$LOGGER"failed to start up"return 1fiecho -n "Starting kdump:"; success; echo$LOGGER"started up"}case "$1" instart)if[-s /proc/vmcore ]; then #第二个内核启动后走此步!run_kdump_presave_corerun_kdump_post $?do_final_actionelse#刚开始走此步!startfi;;最后是调用如下形式这个就到了上次分析kexec的代码了,注意此处是以-p来调用的int elf_x86_load(int argc,char**argv,const char*buf, off_t len, struct kexec_info *info)//******************{struct mem_ehdr ehdr;const char*command_line;char*modified_cmdline;int command_line_len;int modified_cmdline_len;const char*ramdisk;unsigned long entry, max_addr;int arg_style;#define ARG_STYLE_ELF 0#define ARG_STYLE_LINUX 1#define ARG_STYLE_NONE 2int opt;#define OPT_APPEND (OPT_ARCH_MAX+0)#define OPT_REUSE_CMDLINE (OPT_ARCH_MAX+1)#define OPT_RAMDISK (OPT_ARCH_MAX+2)#define OPT_ARGS_ELF (OPT_ARCH_MAX+3)#define OPT_ARGS_LINUX (OPT_ARCH_MAX+4)#define OPT_ARGS_NONE (OPT_ARCH_MAX+5)static const struct option options[]={//参见/blog/tag/getopt_long/ noted by peter.guoKEXEC_ARCH_OPTIONS{"command-line",1,NULL, OPT_APPEND },{"append",1,NULL, OPT_APPEND },{"reuse-cmdline",1,NULL, OPT_REUSE_CMDLINE },{"initrd",1,NULL, OPT_RAMDISK },{"ramdisk",1,NULL, OPT_RAMDISK },{"args-elf",0,NULL, OPT_ARGS_ELF },{"args-linux",0,NULL, OPT_ARGS_LINUX },{"args-none",0,NULL, OPT_ARGS_NONE },{ 0,0,NULL, 0 },};static const char short_options[]= KEXEC_OPT_STR "";/** Parse the command line arguments*/arg_style = ARG_STYLE_ELF;command_line = 0;modified_cmdline = 0;modified_cmdline_len = 0;ramdisk = 0;while((opt = getopt_long(argc, argv, short_options, options, 0))!=-1){//属于gnu体系switch(opt){default:/* Ignore core options */if(opt < OPT_ARCH_MAX){break;}case'?':usage();return-1;case OPT_APPEND://进入此!command_line = optarg;break;case OPT_REUSE_CMDLINE:command_line = get_command_line();break;case OPT_RAMDISK://进入此!ramdisk = optarg;break;case OPT_ARGS_ELF:arg_style = ARG_STYLE_ELF;break;case OPT_ARGS_LINUX://进入此!arg_style = ARG_STYLE_LINUX;break;case OPT_ARGS_NONE:#ifdef __i386__arg_style = ARG_STYLE_NONE;#elsedie("--args-none only works on arch i386\n");#endifbreak;}}command_line_len = 0;if(command_line){command_line_len =strlen(command_line)+1;}/* Need to append some command line parameters internally in case of* taking crash dumps.*/if(info->kexec_flags & (KEXEC_ON_CRASH|KEXEC_PRESERVE_CONTEXT)){modified_cmdline =xmalloc(COMMAND_LINE_SIZE);//分配一个新的空间来盛命令行!memset((void*)modified_cmdline,0, COMMAND_LINE_SIZE);if(command_line){strncpy(modified_cmdline, command_line,COMMAND_LINE_SIZE);modified_cmdline[COMMAND_LINE_SIZE -1]= '\0';}modified_cmdline_len =strlen(modified_cmdline);}/* Load the ELF executable */elf_exec_build_load(info,&ehdr,buf,len, 0);//========================>entry = ehdr.e_entry;max_addr = elf_max_addr(&ehdr);/* Do we want arguments? */if(arg_style != ARG_STYLE_NONE){//=====>/* Load the setup code *///===========>pay more attention to purgatoryelf_rel_build_load(info,&info->rhdr,(char*) purgatory, purgatory_size,0,ULONG_MAX, 1, 0);}if(arg_style == ARG_STYLE_NONE){info->entry =(void*)entry;}else if(arg_style == ARG_STYLE_ELF){unsigned long note_base;struct entry32_regs regs;uint32_t arg1, arg2;/* Setup the ELF boot notes */note_base = elf_boot_notes(info, max_addr,(unsigned char*)command_line, command_line_len);/* Initialize the stack arguments */arg2 = 0;/* No return address */arg1 = note_base;elf_rel_set_symbol(&info->rhdr,"stack_arg32_1", &arg1,sizeof(arg1));elf_rel_set_symbol(&info->rhdr,"stack_arg32_2", &arg2,sizeof(arg2));/* Initialize the registers */elf_rel_get_symbol(&info->rhdr,"entry32_regs", ®s,sizeof(regs));regs.eip = entry;/* The entry point */regs.esp =elf_rel_get_addr(&info->rhdr, "stack_arg32_2");elf_rel_set_symbol(&info->rhdr,"entry32_regs", ®s,sizeof(regs));if(ramdisk){die("Ramdisks not supported with generic elf arguments");}}else if(arg_style ==ARG_STYLE_LINUX){//=====>got itstruct x86_linux_faked_param_header *hdr;unsigned long param_base;const unsigned char*ramdisk_buf;off_t ramdisk_length;struct entry32_regs regs;int rc = 0;/* Get the linux parameter header */hdr = xmalloc(sizeof(*hdr));/* Hack: With some ld versions, vmlinux program headers show* a gap of two pages between bss segment and data segment* but effectively kernel considers it as bss segment and* overwrites the any data placed there. Hence bloat the* memsz of parameter segment to 16K to avoid being placed* in such gaps.* This is a makeshift solution until it is fixed in kernel*/param_base =add_buffer(info,hdr,sizeof(*hdr), 16*1024,16, 0, max_addr, 1);/* Initialize the parameter header */memset(hdr, 0,sizeof(*hdr));init_linux_parameters(&hdr->hdr);/* Add a ramdisk to the current image */ramdisk_buf =NULL;ramdisk_length = 0;if(ramdisk){ramdisk_buf =(unsigned char*) slurp_file(ramdisk,&ramdisk_length);}/* If panic kernel is being loaded, additional segments need* to be created. */if(info->kexec_flags & (KEXEC_ON_CRASH|KEXEC_PRESERVE_CONTEXT)){/*Command line: ro root=LABEL=/ rhgb quiet irqpoll maxcpus=1 reset_devicesmemmap=exactmap memmap=640K@0K memmap=5264K@16384Kmemmap=125152K@22288K elfcorehdr=147440K (0x8ffc000)memmap=56K#1834688K memmap=136K#1834744K memmap=128K#1834880K memmap=1024K$4193280K //红色部分'#'代表specific memory forACPI data. '$'代表specific memory as reserved. 没在代码中查找到?/此处得到相关的memmap和elfcorehdr参数并存入新的命令行参数中*/rc =load_crashdump_segments(info, modified_cmdline,max_addr, 0);if(rc < 0)return-1;/* Use new command line. */command_line = modified_cmdline;command_line_len =strlen(modified_cmdline) + 1;}/* Tell the kernel what is going on */setup_linux_bootloader_parameters(info,&hdr->hdr, param_base,offsetof(structx86_linux_faked_param_header, command_line),command_line, command_line_len,ramdisk_buf,ramdisk_length);//======>got it/* Fill in the information bios calls would usually provide */setup_linux_system_parameters(&hdr->hdr,info->kexec_flags);/* Initialize the registers */elf_rel_get_symbol(&info->rhdr,"entry32_regs", ®s,sizeof(regs));regs.ebx = 0;/* Bootstrap processor */regs.esi =param_base;/* Pointer to the parameters */regs.eip = entry;/* The entry point */regs.esp =elf_rel_get_addr(&info->rhdr, "stack_end");/* Stack, unused */elf_rel_set_symbol(&info->rhdr,"entry32_regs", ®s,sizeof(regs));}else{die("Unknown argument style\n");}return 0;}/* Loads additional segments in case of a panic kernel is being loaded.* One segment for backup region, another segment for storing elf headers* for crash memory image.*/int load_crashdump_segments(struct kexec_info *info,char* mod_cmdline,unsigned long max_addr,unsigned long min_base){void*tmp;unsigned long sz, elfcorehdr;int nr_ranges, align = 1024;struct memory_range *mem_range,*memmap_p;if(get_crash_memory_ranges(&mem_range,&nr_ranges,info->kexec_flags)< 0)return-1;/** if the core type has not been set on command line, set it here* automatically*/if(arch_options.core_header_type == CORE_TYPE_UNDEF){arch_options.core_header_type =get_core_type(info,mem_range, nr_ranges);}/* 1.Memory regions which panic kernel can safely use to boot into */sz =(sizeof(struct memory_range)*(KEXEC_MAX_SEGMENTS + 1));memmap_p = xmalloc(sz);memset(memmap_p, 0, sz);add_memmap(memmap_p,BACKUP_SRC_START, BACKUP_SRC_SIZE);//第一块!sz = crash_reserved_mem.end - crash_reserved_mem.start +1;add_memmap(memmap_p, crash_reserved_mem.start, sz);//第二块!/* 2.Create a backup region segment to store backup data*/if(!(info->kexec_flags & KEXEC_PRESERVE_CONTEXT)){sz =(BACKUP_SRC_SIZE + align - 1)&~(align - 1);tmp = xmalloc(sz);memset(tmp, 0, sz);info->backup_start = add_buffer(info, tmp, sz, sz, align,0, max_addr,-1);dbgprintf("Created backup segment at 0x%lx\n",info->backup_start);if(delete_memmap(memmap_p,info->backup_start, sz)< 0)return-1;}/* 3.Create elf header segment and store crash image (1st or 2nd)data. */if(arch_options.core_header_type == CORE_TYPE_ELF64){if(crash_create_elf64_headers(info,&elf_info64,crash_memory_range, nr_ranges,&tmp,&sz,ELF_CORE_HEADER_ALIGN)< 0)return-1;}else{if(crash_create_elf32_headers(info,&elf_info32,crash_memory_range, nr_ranges,&tmp,&sz,ELF_CORE_HEADER_ALIGN)< 0)//哪里定义的noted by peter.guoreturn-1;}/* Hack: With some ld versions (GNU ld version 2.14.90.0.4 20030523),* vmlinux program headers show a gap of two pages between bss segment* and data segment but effectively kernel considers it as bss segment* and overwrites the any data placed there. Hence bloat (使膨胀)the memsz of* elf core header segment to 16K to avoid being placed in such gaps.* This is a makeshift solution until it is fixed in kernel.*/elfcorehdr =add_buffer(info,tmp,sz,16*1024,align, min_base,max_addr, -1);dbgprintf("Created elf header segment at 0x%lx\n", elfcorehdr);if(delete_memmap(memmap_p, elfcorehdr, sz)< 0)return-1;。
linux在启动的时候提示说memory for crash kernel(0*0 to 0*0)notwithin permissible range解决办法:这个信息由于没有配置kdump服务的原因,并没有什么危害可以忽略。
kdump是一个新的,而且非常可信赖的内核崩溃转储机制。
崩溃转储数据可以从一个新启动的内核的上下文中获取,而不是从已经崩溃的内核的上下文。
当系统崩溃时,kdump使用kexec启动到第二个内核。
第二个内核通常叫做捕获内核(capture kernel),以很小内存启动,并且捕获转储镜像。
方法一,在图形模式下配置:我们可以采用下面的图形界面进行配置和启用,步骤如下:----配置kdump。
选择菜单“Applications”——“system tools”——“kdump”,弹出“Kernel Dump Configuration”窗口,选中Enable kdump,设置New kdump Memory(MB): 128MB(推荐大小)----重新启动系统。
方法二:编辑/etc/grub.conf,在内核行的末尾添加crashkernel=128@16M。
举例:kernel /boot/vmlinuz-2.6.17-1.2519.4.21.el5 ro root=LABEL=/ rhgb quiet crashkernel=128M@16M修改之后,重启系统。
128M内存(从16M开始)不被正常的系统使用,为捕获内核保留。
现在,保留内存已经设置了,打开kdump初始脚本,启动服务:# chkconfig kdump on# service kdump start安装kdump服务:kexec是一个快速启动机制,允许通过已经运行的内核的上下文启动一个Linux 内核,不需要经过BIOS。
BIOS可能会消耗很多时间,特别是带有众多数量的外设的大型服务器。
这种办法可以为经常启动机器的开发者节省很多时间。
linux kdump 实现原理kdump是一种在Linux系统中实现内核转储(crash dump)的机制。
通过kdump,当系统发生严重错误导致宕机时,可以将当前内核的内存转储到硬盘中,以便开发人员对宕机时的内核状态进行分析和调试。
本文将介绍kdump的实现原理,包括其工作原理、内存镜像的生成和转储、以及kdump的配置和使用。
1. kdump的工作原理:kdump是通过利用Linux内核的kexec功能实现的。
kexec是一种Linux内核中的系统调用,可以直接启动一个新的内核镜像而无需重新引导硬件。
kdump利用kexec功能,在系统内核崩溃时,通过加载一个特殊的内核映像,再次启动一个小型的第二内核,这个第二内核称为crash内核。
2.内存镜像的生成和转储:在宕机之前,首先需要生成一个内存映像文件。
kdump通过使用原始内核的/proc/vmcore文件实现此目的。
当系统崩溃时,原始内核暂停所有正在运行的任务,然后通过kexec工具加载crash内核,并将crash内核的入口点和参数传递给它。
然后crash内核启动,将原始内核的物理内存转储到磁盘上的/proc/vmcore文件中。
这个过程叫做转储(crash dumping)。
3. kdump的配置和使用:在Linux系统中配置和使用kdump需要以下步骤:a.安装kexec-tools软件包:kexec-tools是一组用户空间工具,用于加载第二内核映像。
b.确保系统有足够的空闲内存:kdump需要一定数量的内存用于存储crash内核。
c.配置kdump内核参数:需要编辑/etc/default/kdump文件,设置crash内核的路径、内存大小、转储方式等参数。
d.配置grub文件并重启:需要编辑boot loader(如GRUB)的配置文件,启用kdump并设置重启后启动crash内核。
e.测试kdump:重启系统后,可以通过执行`sysctl -wkernel.panic_on_oops=1`命令来模拟系统崩溃并测试kdump的效果。
文件编号:文件名:Kdump和Crash的配置方法与内核故障原因分析保密级别:核心资料授权给:曙光信息产业(北京)有限公司在职员工Kdump和Crash的配置方法与内核故障原因分析作者:侯雪峰单位:曙光信息产业(北京)有限公司部门:解决方案中心日期:20130520关键词:Kdump、Crash、kernel panic法律条款1.对本文档的任何使用均被视为完全理解并接受本文档列举的所有法律条款。
2.本文档的所有权利归作者所有,作者保留所有权利。
3.若本文档的保密级别为“公开发布”,允许学术使用,未经作者书面授权,禁止商业使用。
若本文档的保密级别为“内部资料”,仅授权曙光信息产业(北京)有限公司的在职员工使用。
若本文档的保密级别为“核心资料”,未经作者书面授权,禁止任何形式的使用。
4.对本文档的使用形式包括但不限于存储、出版、复制、传播、展示、引用、编辑。
使用过程中不得对本文档作任何增减编辑,引用时需注明出处。
商业使用是指在商业活动中或有商业目的活动中的使用。
学术使用是指以技术交流或学术研究为目的的使用。
5.实施任何侵权行为的法人或自然人都必须向作者支付赔偿金,赔偿金计算方法为:赔偿金= 涉案人次×涉案时长(天)×涉案文档份数×受众人次×基数×1元人民币,涉案人次、涉案时长、涉案文档份数、受众人次小于1时,按1计算。
若保密级别为“公开发布”,基数为100;若保密级别为“内部资料”,基数为1000;若保密级别为“核心资料”,基数为10000.6.对举报侵权行为、提供有价值证据的自然人或法人,作者承诺奖励案件实际赔偿金的50%.7.作者不保证文档内容的正确性。
对文档的使用后果,作者不承担任何责任。
8.涉及本文档的法律纠纷由作者所在地法院裁决。
9.本文档所列举法律条款的最终解释权归作者所有。
修改记录20130520;侯雪峰;创建文件。
目录修改记录.......................................................................................................................................... I II1 Kdump简介 (1)2 Kdump的安装配置(以RHEL6.2为例) (1)3 Crash简介 (2)4 Crash的配置和初步使用 (2)5 使用Crash分析内核崩溃的原因 (4)5.1 实际分析示例一: (5)5.2 实际分析示例二: (9)5.3 实际分析示例三: (12)5.4 实际分析示例四: (13)5.5 实际分析示例五: (14)5.6 实际分析示例六: (16)5.7 实际分析示例七: (18)6 结论 (19)摘要:本文介绍了Kdump和Crash的配置方法,并通过Crash对内存镜像转储文件做了一些分析,推断和研究了系统发生故障的原因。
1Kdump简介Linux的内核十分稳定,但仍不可避免地会遇到崩溃的情况,获取内核崩溃时的内存镜像,有助于分析系统在崩溃前发生了什么,分析原因并修复错误,进而改进系统的稳定性。
Kdump用于对内存镜像的转储,它不但可以转储内存镜像到本地硬盘,还可以将内存镜像通过NFS,SSH等协议转储到不同机器的设备上。
Kdump分为两个组件:Kexec和Kdump。
Kexec是一种内核的快速启动工具,可以使新的内核在正在运行的内核(生产内核)的上下文中启动,而不需要通过耗时的BIOS检测,方便内核开发人员对内核进行调试。
Kdump是一种有效的内存转储工具,启用Kdump后,生产内核将会保留一部分内存空间,用于在内核崩溃时通过Kexec快速启动到新的内核,这个过程不需要重启系统,因此可以转储崩溃的生产内核的内存镜像。
2Kdump的安装配置(以RHEL6.2为例)1. 在安装操作系统时会提示是否启用Kdump,选择启用,并设置保留的内存大小(一般建议设置为128M)。
2. 如安装系统时禁用了Kdump,可按照下面步骤操作:rpm -qa | grep kexec-tools # 查看是否安装了kexec工具,如没有安装需要装好在/boot/grub/grub.conf文件中添加内核参数:crashkernel=auto (或者指定使用内存的大小,如crashkernel=128M)3. 配置Kdump的一些参数:kdump默认将文件存放在本地硬盘的/var/crash/目录下,该位置可以是本地文件系统的某个目录,或者某个块设备,或者通过网络存储在其他机器上,可以修改文件:vim /etc/kdump.conf#raw /dev/sda5 (如果写到裸设备上,取消该行的注释)#ext4 /dev/sda3 (指定写入设备的文件系统类型和分区)#ext4 LABEL=/boot (支持LABEL以及UUID来标识设备)#ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937#net :/export/tmp (NFS方式)#net user@ (SSH方式)#path /var/crash (内存镜像文件的保存路径)#core_collector makedumpfile -c --message-level 1 -d 31此行设置保存内存镜像内容的级别,-c表示使用makedumpfile压缩数据,--message-level 1表示提示信息的级别(1表示只显示进度信息)-d 31表示不复制所有可以去掉的内存页(包括zero page, cache page,cache private, user data, free page等)。
#default shell此行表示如果kdump转储内存镜像失败后的执行的动作,默认为挂载根文件系统并执行/sbin/init进程,可以更改为:reboot, halt, poweroff,shell等。
例如,如果将内存镜像通过SSH协议转储到集群中管理节点挂载的共享存储上,并按最大的压缩内容保存,如果失败,则重启机器,放弃转储内存镜像,则/etc/kdump.conf文件可以配置为:net root@adminpath /var/crashcore_collector makedumpfile -c --message-level 1 -d 31default reboot4. 将kdump服务设置为开机自启动:chkconfig kdump on/etc/init.d/kdump start5. 可使用一下命令触发内核的崩溃,并检验Kdump是否配置成功,如成功,会在指定目录下生成内核镜像文件:echo 1 > /proc/sys/kernel/sysrqecho c > /proc/sysrq-trigger系统将会进入内存转储过程,完成后会重启到生产内核。
3Crash简介Crash是由David Anderson开发维护的分析内存转储文件的工具,目前最新版本为7.0.0,RHEL6.2集成的版本为crash-5.1.8-1,它可以分析多种工具产生的内存转储文件。
4Crash的配置和初步使用首先确保操作系统安装了一下rpm包:rpm –ivh kernel-debuginfo-common-x86_64-2.6.32-220.el6.x86_64.rpm rpm -ivh kernel-debuginfo-2.6.32-220.el6.x86_64.rpm使用如下命令即可开始使用Crash分析内存转储文件;crash /var/crash/127.0.0.1-2013-04-02-13\:47\:32/vmcore/usr/lib/debug/lib/modules/2.6.32-220.el6.x86_64/vmlinux其中第一个参数为某次崩溃产生的内存转储文件,第二个参数为带有调试信息的内核。
进入Crash后显示的信息一般如下图所示:Crash常用的命令有如下几个:help #查看命令的帮助信息,也可用man命令h #查看历史命令,相当于shell下的historylog #该命令用于打印出内存的日志信息bt #该命令用于获取当前线程的调用堆栈foreach bt #该命令用于获取所有线程的调用堆栈ps #该命令用于查看内核崩溃时的进程信息vm #该命令用于查看当前的内核上下文的虚拟内存信息files #该命令用于查看当前的内核上下文中打开的文件exit or q #退出CrashCrash还提供dis(反汇编),strcut(查看数据结构)等更深入分析内核崩溃原因的命令,这些分析需要对内核源码及内核的运行机制理解较深,这里不做分析。
Crash还提供非交互的使用方式,所有命令由inputfile导入,结果信息可输入到outputfile 中:crash /var/crash/127.0.0.1-2013-04-02-13\:47\:32/vmcore/usr/lib/debug/lib/modules/2.6.32-220.el6.x86_64/vmlinux< inputfile > outputfileInputfile的文件名可以自行选定,但最后一行必须为exit或q命令,示例如下:cat inputfilelogbtpsexit # 必须以退出命令结尾5使用Crash分析内核崩溃的原因以下是进入Crash后得到的内存转储镜像的基本信息:其中各项参数的意义为:KERNEL: 表示调试用内核的位置和版本信息;DUMPFILE: 表示所分析的内存转储镜像CPUS: 表示本机的CPU数目;DATE: 表示内核崩溃发生的时间;UPTIME: 表示内核已正常运行的时间;LOAD AVERAGE: 表示内核崩溃时系统的负载;TASKS: 表示内核崩溃时系统运行的任务数;NODENAME: 表示内核崩溃的机器的主机名;RELEASE: 表示内核的发布版本;VERSION: 表示内核的其他版本信息MACHINE: 表示CPU的架构和主频信息;MEMORY: 表示发生内核崩溃的系统的内存大小;PANIC: 表示内核崩溃的类型;这里可能有SysRq(即通过系统请求造成的内核崩溃,如上面测试用的命令即是),Oops(表示内核发生了不可预期的或不正确的行为,这时会杀死相应的进程,内核可能恢复正常,也可能处于一种不确定的状态,并进而导致内核的Panic),以及Panic(内核崩溃,即发生了严重且不可修复的错误,如发生了非法的地址访问,强制加载或卸载内核模块,以及硬件错误等等)。