清华大学移动通信教程第06讲-信源编码
- 格式:ppt
- 大小:192.50 KB
- 文档页数:26

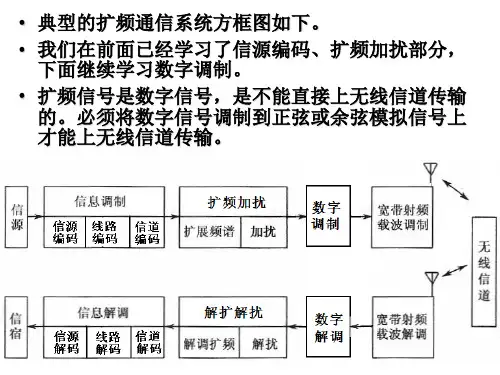

信源编码的基本原理及其应用信源编码的基本原理及其应用课程名称通信原理Ⅱ专业通信工程班级 *******学号 ******学生姓名 *****论文成绩指导教师 ***********信源编码的基本原理及其应用信息论的理论定义是由当代伟大的数学家美国贝尔实验室杰出的科学家香农在他1948 年的著名论文《通信的数学理论》所定义的,它为信息论奠定了理论基础。
后来其他科学家,如哈特莱、维纳、朗格等人又对信息理论作出了更加深入的探讨。
使得信息论到现在形成了一套比较完整的理论体系。
信息通过信道传输到信宿的过程即为通信,通信中的基本问题是如何快速、准确地传送信息。
要做到既不失真又快速地通信,需要解决两个问题:一是不失真或允许一定的失真条件下,如何提高信息传输速度(如何用尽可能少的符号来传送信源信息);二是在信道受到干扰的情况下,如何增加信号的抗干扰能力,同时又使得信息传输率最大(如何尽可能地提高信息传输的可靠性)。
这样就对信源的编码有了要求,如何通过对信源的编码来实现呢?通常对于一个数字通信系统而言,信源编码位于从信源到信宿的整个传输链路中的第一个环节,其基本目地就是压缩信源产生的冗余信息,降低传递这些不必要的信息的开销,从而提高整个传输链路的有效性。
在这个过程中,对冗余信息的界定和处理是信源编码的核心问题,那么首先需要对这些冗余信息的来源进行分析,接下来才能够根据这些冗余信息的不同特点设计和采取相应的压缩处理技术进行高效的信源编码。
简言之,信息的冗余来自两个主要的方面:首先是信源的相关性和记忆性。
这类降低信源相关性和记忆性编码的典型例子有预测编码、变换编码等;其次是信宿对信源失真具有一定的容忍程度。
这类编码的直接应用有很大一部分是在对模拟信源的量化上,或连续信源的限失真编码。
可以把信源编码看成是在有效性和传递性的信息完整性(质量)之间的一种折中有段。
信源编码的基本原理:信息论的创始人香农将信源输出的平均信息量定义为单消息(符号)离散信源的信息熵:香农称信源输出的一个符号所含的平均信息量为 为信源的信息熵。

信源编码概述信源编码是信息论的一个重要概念,用于将源信号转换成一系列编码的比特流。
在通信系统中,信源编码被广泛用于提高信息的传输效率和可靠性。
本文将介绍信源编码的基本概念、常见的信源编码方法和应用。
基本概念信源在通信系统中,信源是指产生信息的原始源头。
信源可以是任何可以生成离散或连续信号的设备或系统,比如人的语音、文本、图像等等。
信源编码信源编码是指将信源产生的原始信号转换成一系列编码的比特流。
它的主要目的是通过消除冗余、提高信号的压缩率以及提高传输的可靠性。
码字信源编码中的最小单位被称为码字(codeword)。
码字由编码器根据特定规则生成,每个码字可以表示一个或多个原始信号。
码长码长是指每个码字中的比特数。
它决定了编码器产生的每个码字传输所需的比特数,码长越短,传输效率就越高。
码率码率是指信源编码中每秒传输的码字数量。
它可以用比特/秒(bps)来表示,码率越高表示每秒传输的信息量越大。
常见的信源编码方法均匀编码均匀编码是一种简单的信源编码方法,它将每个原始信源符号映射到固定长度的码字上。
均匀编码适用于信源符号概率分布均匀的情况,例如二进制信源。
霍夫曼编码霍夫曼编码是一种基于信源符号概率分布的编码方法。
它通过将频率较高的信源符号映射到较短的码字,频率较低的信源符号映射到较长的码字来实现压缩。
高斯混合模型编码高斯混合模型编码是一种适用于连续信源的编码方法。
它假设源信号是由多个高斯分布组成的,通过对这些高斯分布进行建模来实现有效的压缩。
游程编码游程编码是一种用于压缩离散信号的编码方法,它基于信源连续出现相同符号的特性。
游程编码将连续出现的相同符号替换为一个计数符号和一个重复符号,从而实现压缩。
信源编码的应用数据压缩信源编码在数据压缩中起着关键作用。
通过使用有效的信源编码方法,可以大大减少传输数据的比特数,从而提高数据传输的效率和速率。
影音编码在数字媒体领域,信源编码常用于音频和视频的压缩。
通过采用适当的信源编码方法,可以减小音频和视频文件的大小,从而节省存储空间和传输带宽。





信源编码知识点总结一、引言信源编码是数字通信中的一个重要环节,它的作用是将源符号序列转换为码字序列,以便能够方便地存储、传输和解码。
在实际应用中,不同的信源编码算法有不同的适用领域,可以根据实际情况选择合适的编码算法。
二、基本概念1. 信源:信源是指产生消息的实体,它可以是声音、图像、文本等各种形式的信息。
2. 符号:符号是信源所产生的基本单位,它可以是0/1比特、字母、数字或其它形式的符号。
3. 离散信源和连续信源:离散信源是指符号集合有限的信源,可以通过一定的方式对其信号进行采样和量化;而连续信源是指符号集合是无限的信源,信号无法进行离散化处理。
三、信息熵信息熵是度量信源信息量大小的一种方法,它描述了信息的不确定度。
信息熵越大,表示信息的不确定度越大;而信息熵越小,表示信息的不确定度越小。
信息熵的计算公式为:H(X) = -Σp(x)log2p(x)其中,H(X)表示信源的信息熵,p(x)表示信源符号x出现的概率。
四、香农定理香农定理是描述信源编码极限的理论基础,它指出了信源编码的极限压缩率。
其中,信源编码的极限压缩率为信源的信息熵和编码方法的平均码长之间的关系:R ≥ H(X)其中,R表示平均码长。
五、熵编码熵编码是一种利用符号出现概率来确定码字长度的编码方法。
常见的熵编码方法有霍夫曼编码、算术编码等。
熵编码的特点是能够达到香农定理的极限压缩率,因此在实际应用中有着广泛的应用。
六、字典编码字典编码是一种通过查表来实现编码的方法,它可以根据出现频率的不同来确定码字的长度。
常见的字典编码算法有静态字典编码和动态字典编码。
字典编码的特点是在一定程度上可以实现压缩,但通常达不到熵编码的效率。
七、变长编码变长编码是一种根据符号出现概率来确定码字长度的编码方法。
它的特点是可以根据符号出现概率确定码字长度,从而达到一定的压缩效果。
变长编码方法包括前缀编码、霍夫曼编码等。
八、无损编码和有损编码无损编码是一种通过编码解码过程中不损失信息的编码方法,它对信源进行了完全可逆的编码。

