超效率DEA MATLAB代码
- 格式:docx
- 大小:14.79 KB
- 文档页数:1
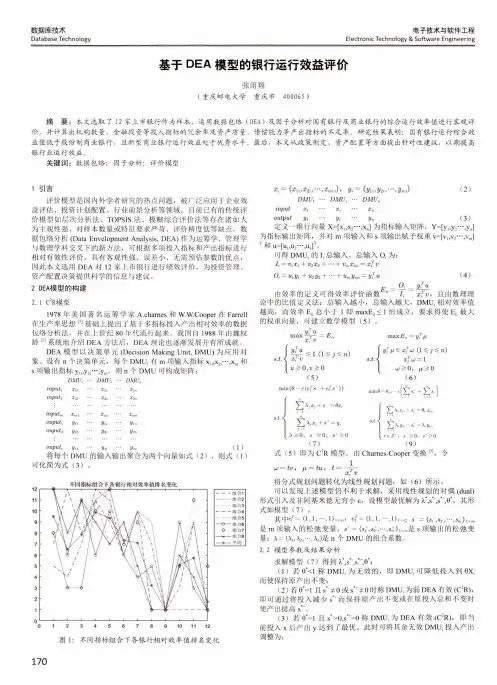
数据库技术Database Technology电子技术与软件工程Electronic Technology & Software Engineering基于DEA 模型的银行运行效益评价张雨翔(重庆邮电大学重庆市400065 )摘 要:本文选取了 12家上市银行作为样本,运用数据包络(DEA )及因子分析对国有银行及商业银行的综合运行效率值进行客观评 价,并计算出机构数量、金融投资等投入指标的冗余率及资产质量、债偿能力等产出指标的不足率。
研究结果表明:国有银行运行综合效益值低于股份制商业银行,且新型商业银行运行效益处于优秀水平。
最后,本文从政策制定、资产配置等方面提出针对性建议,以期提高银行业运行效益。
关键词:数据包络;因子分析;评价模型1引言评价模型是国内外学者研究的热点问题,被广泛应用于企业效 益评估、投资计划配置、行业前景分析等领域。
目前已有的传统评 价模型如层次分析法、TOPSIS 法、模糊综合评价法等存在诸如人 为主观性强、对样本数量或特征要求严苛、评价精度低等缺点,数 据包络分析(Data Envelopment Analysis, DEA)作为运筹学、管理学 与数理学科交叉下的新方法,可根据多项投入指标和产出指标进行 相对有效性评价,具有客观性强、误差小、无需预估参数的优点,因此本文选用DEA 对12家上市银行进行绩效评价,为投资管理、 资产配置决策提供科学的信息与建议。
2 DEA 模型的构建2. 1 C'R 模型1978年美国著名运筹学家A.chames 和W.W.Cooper 在Farrell 在生产率思想⑴基础上提出了基于多指标投入产出相对效率的数据包络分析法,并在上世纪80年代流行起来。
我国自1988年由魏权 龄121系统地介绍DEA 方法后,DEA 理论也逐渐发展并有所成就。
DEA 模型以决策单元(Decision Making Unit, DMU)为应用对 象。

Matlab代码的分析、优化和加速Profile(分析)在加速你的matlab程序之前,你需要知道你的代码哪一部分运行最慢。
matlab提供个简单的机制,让你能够知道你的代码的某一部分运行所占用CPU时间。
通过在代码段开始添加tic,及在结束添加toc;matlab就能计算出这一代码段的运行时间。
Tic和toc方法存在两个问题:(1)显示的时间是运行时间“wall clock”。
这个时间受你在运行你的代码时,你的计算机是否同时运行其它别的程序。
(2)你需要不断地压缩计时范围来查找你代码运行最慢的位置。
一个最好的方法是利用matlab 内嵌的代码分析器。
在你的程序前面通过添加命令profile on;及在程序结束添加profile viewer;并运行你的程序。
当程序正常运行结束时,代码分析器窗口将弹出,并显示分析结果。
它包含的信息有:Function Name :函数名;Calls :函数被调用次数;Total Time :执行该函数的CPU总用时,包含任何其它被它调用的函数的CPU时间。
Self Time :执行该函数的CUP总用时,不包含任何其它被它调用的函数的CUP时间。
Total Time Plot :时间用时的曲线图。
以上信息可进行各种排序和详细查看。
注意:当你完成你的代码分析后,请删除profile on和profile viewer,因为嵌入代码分析器会使用的程序运行变慢。
标准提示☆有问题找帮助文档。
学会使用帮助文档,学会针对待解决的问题检索文档资料。
☆性能查看MATLAB->Programming->Improving Performace and Memory Usage;或MATLAB->Programming Fundamentals->Performace->Techniques for Improveing Performace。
多线程如果你使用的是多核心的计算机,那么你就可以让Matlab同时运行多个线程,Matlab 程序中一些底层的函数(Low-level function)就有可能采用并行计算的方法。

DEA算法学习笔记系列(三)一次性求解CCR模型所有DMU参数——效率、规模效益、有效性特征、调整值的matlab代码目录1 编写目的 (4)1.1E XCEL一次只能计算一个DMU (4)1.2M A TLAB编程一次性计算所有DMU的效率、有效性、调整值 (5)2 MATLAB求解线性规划 (5)2.1系统函数说明 (5)2.1.1 调用格式: (5)2.1.2 输入参数说明 (5)2.1.3 返回值说明 (6)2.2简单例子,用代码求解 (7)2.2.1 例1 (7)2.2.2 例2: (8)2.2.3 例题3(无解的例子) (9)2.2.4 例4(需要标准化的例子,一个等式的例子) (10)2.2.5 例5 (11)2.2.6 例子6:松弛变量为基变量——用等式重解例1 (13)2.3自定义M A TLAB函数求解线性规划(从EXCEL读数据) (14)2.3.1 简单版:MyLinprog——读取给定文件中数据,返回计算结果 (14)3 DEA模型之CCR简介 (16)3.1CCR理论模型 (16)4 CCR模型计算过程——一个决策单元的计算过程 (18)4.1例题说明 (18)4.2基于理论构建模型——湖南省 (19)4.3调整形式,以利于线性规划函数求解 (19)4.4按照自定义函数,构造EXCEL文件 (20)4.4.1 矩阵A的格式和说明 (20)4.4.2 价值向量系数矩阵C的格式和说明 (20)4.4.3 资源限制矩阵b的格式和说明 (21)4.4.4 X取值条件的限制 (21)4.5调用自定义函数(M Y L INPROG)求解指定决策单元模型 (22)4.6计算结果评价 (22)4.6.1 最优值 (22)4.6.2 各变量的值 (23)4.6.3 模型效率分析 (24)4.7调整方案 (24)5 计算CCR模型的MATLAB函数——所有决策单元 (25)5.1程序代码(可直接运行) (25)5.2存放数据的EXCEL文件格式说明 (27)5.2.1 第一个:投入产出数据 (27)5.2.2 第二个数据:价值变量系数矩阵(不需准备) (27)5.2.3 第三个数据:资源限制矩阵(不需要准备) .................................................................. 28 5.2.4 第四个数据:决策变量的取值范围(不需要准备) ...................................................... 28 5.2.5 范例数据 .............................................................................................................................. 28 5.3 计算所有DMU 的函数 .............................................................................................................. 28 5.3.1 函数输入参数 ...................................................................................................................... 28 5.3.2 返回参数1:每个DMU 效率、规模效益、是否弱有效 ................................................ 28 5.3.3 返回参数2:每个DMU 的所有值 (29)5.3.4 返回参数3:增加的松弛变量 ........................................................................................... 29 5.3.5 返回参数4:非DEA 有效DMU 调整后的投入产出矩阵 .............................................. 29 5.3.6 返回参数5:非DEA 有效DMU 各个指标调整值 .......................................................... 29 5.4 返回参数例子 ............................................................................................................................. 29 5.4.1 返回参数1:每个DMU 效率、规模效益、是否弱有效 ................................................ 29 5.4.2 返回参数2:每个DMU 的所有值 (30)5.4.3 返回参数3:增加的松弛变量 ........................................................................................... 30 5.4.4 返回参数4:非DEA 有效DMU 调整后的投入产出矩阵 .............................................. 30 5.4.5 返回参数5:非DEA 有效DMU 各个指标调整值 .......................................................... 30 6 补充知识 ............................................................................................................................................ 30 6.1 自定义MA TLAB 函数 .................................................................................................................. 30 6.2 M A TLAB 向量操作 ....................................................................................................................... 32 6.2.1 读取矩阵第一列 .................................................................................................................. 32 6.3 M A TLAB 操作EXCEL 数据 ........................................................................................................... 32 6.3.1 读入excel 数据 .................................................................................................................... 32 6.3.2 写内容到xls ........................................................................................................................ 33 6.4 M A TLAB 的FOR 循环语句............................................................................................................ 35 7 参考资料 .. (35)λλ1 编写目的1.1 Excel 一次只能计算一个DMUDEA 的CCR 模型,他的对偶模型如下图:⎪⎪⎪⎪⎪⎩⎪⎪⎪⎪⎪⎨⎧≥=-+++=-+++=++++=++++=++++=++---无约束θθθθθλλλλλλλλλλλλλλλλλλλλλ,004.165921.266204.165922.93009.219620.144410.18120.144760.4929.17920.443000.46120.44320.24980.40131.84940.144431.84964.58145.98084.93656.130684.93608.58366.932..min 2432114321343212432114321jDs s s s s Vt s 很多人通过EXCEL 提供的一个插件进行计算,如下图所示:但是,这种方法有以下不足:(1)每次只能计算一个DMU ,如果有多个DMU ,那么需要人工重复计算过程多次;(2)通过Excel 计算,只能得到θ,没法得到各个,所以,也无法直接判断是规模效益递增还是递减;λ(3)没发直接得到ss ii、+-的值,也无法直接判断DMU 是弱DEA 有效,还是DEA 有效1.2 Matlab 编程一次性计算所有DMU 的效率、有效性、调整值文章通过编写Matlab 程序,实现一次性对所有DMU 计算效率θ、有效性(根据θ以及所有的汇总值)、调整值(根据ss ii、+-)。

如何优化Matlab代码效率一、引言Matlab是一种广泛用于科学计算和工程数据分析的编程语言和环境。
尽管Matlab具有易学易用的优势,但在处理大规模数据和复杂算法时,其执行效率可能受到限制。
本文旨在探讨如何优化Matlab代码的效率,以提高程序执行速度和资源利用率。
二、算法优化在编写Matlab代码时,合理选择和设计算法是提高效率的关键。
以下是一些常见的算法优化方法:1. 向量化操作:利用Matlab对向量和矩阵运算的优化支持,尽量避免使用循环。
通过向量化操作,可以将多个操作并行执行,减少运算次数。
2. 预分配内存空间:在循环中频繁使用动态分配内存的操作会导致效率下降。
可以通过预先分配足够的内存空间来避免频繁的内存分配和释放操作。
3. 减少不必要的计算:分析算法流程,去除不必要的计算步骤和重复计算,减少程序运行时间。
4. 选择高效的数据结构:根据实际需求选择合适的数据结构,例如使用矩阵代替多维数组,使用稀疏矩阵进行存储和计算等。
5. 并行计算:利用Matlab的并行计算工具箱,将计算任务分解为多个子任务,并利用多核或集群资源并行执行,以加速程序运行。
三、内存管理合理的内存管理是优化Matlab代码效率的重要一环。
以下是一些内存管理的技巧:1. 及时释放不再使用的变量:及时清除不再使用的变量,以释放内存空间,避免因内存不足而引起的性能下降。
2. 使用稀疏矩阵:对于大规模的稀疏数据,使用稀疏矩阵可以大幅减少内存占用和计算时间。
3. 内存预分配:通过预估计算所需内存空间,提前分配足够的内存,减少内存分配的开销。
4. 尽量避免频繁的复制操作:在Matlab中,大部分变量传递和复制都是按值传递,会占用额外的内存。
在处理大规模数据时,尽量避免频繁的变量复制操作,以减少内存开销。
四、调试和性能分析工具Matlab提供了一系列的调试和性能分析工具,可以帮助开发者发现代码中的潜在性能瓶颈。
以下是一些常用的工具:1. Profiler:通过运行Profiler,可以收集代码的性能数据,包括函数的执行时间、内存占用等信息。

最优化程序MATLAB 代码程序1.目标任务分别用最速下降法、FR 共轭梯度法、DFP 法和BFGS 法求解无约束最值问题:22112212min f (x)x 2x x 4x x 3x =-++-取初始点(1)T x (1,1)=和 (2)T x (2,2)=,分别通过Matlab 编程实现求解过程。
2.程序实现(程序文件见附件)2.1公用函数1)function f= fun( X ) %所求问题目标函数f=X(1)^2-2*X(1)*X(2)+4*X(2)^2+X(1)-3*X(2); end2) function g= gfun( X )%所求问题目标函数梯度g=[2*X(1)-2*X(2)+1,-2*X(1)+8*X(2)-3]; end3) function He = Hess( X )%所求问题目标函数Hesse 矩阵 n=length(X); He=zeros(n,n); He=[2,-2; -2,4];End2.2其他函数图2.2 函数程序文件图1) 最速下降法的文件名为 :grad.m 。
2) FR 共轭梯度法的文件名为 :frcg.m 。
3) DFP 法的文件名为 :dfp.m 。
4)BFGS 法的文件名为 :bfgs.m 。
3.程序运行结果3.1最速下降法3.1.1 初值为(1)T x (1,1)图3.1.1.1 最速下降法求解最小值输出结果图图3.1.1.2最速下降法求解最小值过程图3.1.2初值为(2)T x (2,2)图3.1.2.1最速下降法求解最小值输出结果图图3.1.2.2最速下降法求解最小值过程图3.2 FR 共轭梯度法3.2.1 初值为(1)T x (1,1)图3.2.1.1 FR 共轭梯度法求解最小值输出结果图图3.2.1.2 FR 共轭梯度法求解最小值过程图3.2.2初值为(2)T x (2,2)图3.2.2.1 FR 共轭梯度法求解最小值输出结果图图3.2.2.2 FR 共轭梯度法求解最小值过程图3.3 DFP 法3.3.1 初值为(1)T x (1,1)图3.3.1.1 DFP 法求解最小值输出结果图图3.3.1.2 DFP法求解最小值过程图图3.3.1.2 DFP法求解最小值过程图(3.3.2初值为(2)T x (2,2)图3.3.2.1 DFP 法求解最小值输出结果图图3.3.2.2 DFP 法求解最小值过程图3.4 BFGS 法3.4.1 初值为(1)T x (1,1)图3.4.1.1 BFGS 法求解最小值输出结果图图3.4.1.2 BFGS 法求解最小值过程图3.4.2初值为(2)T x (2,2)图3.4.2.1 BFGS 法求解最小值输出结果图图3.4.2.2 BFGS 法求解最小值输出过程图。

以下是一篇关于"deabcc matlab代码"的文章:
DEABCC是一种MATLAB代码形式,用于处理数据分析和可视化。
它具有强大的功能和灵活性,可以帮助用户更好地理解和分析数据。
DEABCC代码的编写非常简单,只需几行代码即可完成数据分析和可视化任务。
首先,我们需要将数据导入到MATLAB中,可以使用readtable函数或csvread函数来实现。
接下来,我们可以使用一系列的函数来对数据进行处理,例如统计描述函数、回归分析函数、图表绘制函数等。
统计描述函数可以帮助我们了解数据的分布情况,包括均值、中位数、标准差等。
回归分析函数可以帮助我们建立回归模型,预测因变量与自变量之间的关系。
图表绘制函数可以将数据可视化,例如绘制柱状图、折线图、散点图等,以帮助我们更直观地理解数据。
DEABCC代码还提供了一些高级功能,例如数据聚类分析、主成分分析等。
这些功能可以帮助用户更深入地挖掘数据中的规律和关联性。
总的来说,DEABCC代码是一种强大且易于使用的工具,适用于各种数据分析和可视化任务。
无论是学术研究、商业分析还是工程设计,DEABCC代码都可以帮助用户更好地理解和利用数据。
通过合理运用DEABCC代码,我们可以从数据中发现有价值的信息,并做出准确的决策。

30个智能算法matlab代码以下是30个使用MATLAB编写的智能算法的示例代码: 1. 线性回归算法:matlab.x = [1, 2, 3, 4, 5];y = [2, 4, 6, 8, 10];coefficients = polyfit(x, y, 1);predicted_y = polyval(coefficients, x);2. 逻辑回归算法:matlab.x = [1, 2, 3, 4, 5];y = [0, 0, 1, 1, 1];model = fitglm(x, y, 'Distribution', 'binomial'); predicted_y = predict(model, x);3. 支持向量机算法:matlab.x = [1, 2, 3, 4, 5; 1, 2, 2, 3, 3];y = [1, 1, -1, -1, -1];model = fitcsvm(x', y');predicted_y = predict(model, x');4. 决策树算法:matlab.x = [1, 2, 3, 4, 5; 1, 2, 2, 3, 3]; y = [0, 0, 1, 1, 1];model = fitctree(x', y');predicted_y = predict(model, x');5. 随机森林算法:matlab.x = [1, 2, 3, 4, 5; 1, 2, 2, 3, 3]; y = [0, 0, 1, 1, 1];model = TreeBagger(50, x', y');predicted_y = predict(model, x');6. K均值聚类算法:matlab.x = [1, 2, 3, 10, 11, 12]; y = [1, 2, 3, 10, 11, 12]; data = [x', y'];idx = kmeans(data, 2);7. DBSCAN聚类算法:matlab.x = [1, 2, 3, 10, 11, 12]; y = [1, 2, 3, 10, 11, 12]; data = [x', y'];epsilon = 2;minPts = 2;[idx, corePoints] = dbscan(data, epsilon, minPts);8. 神经网络算法:matlab.x = [1, 2, 3, 4, 5];y = [0, 0, 1, 1, 1];net = feedforwardnet(10);net = train(net, x', y');predicted_y = net(x');9. 遗传算法:matlab.fitnessFunction = @(x) x^2 4x + 4;nvars = 1;lb = 0;ub = 5;options = gaoptimset('PlotFcns', @gaplotbestf);[x, fval] = ga(fitnessFunction, nvars, [], [], [], [], lb, ub, [], options);10. 粒子群优化算法:matlab.fitnessFunction = @(x) x^2 4x + 4;nvars = 1;lb = 0;ub = 5;options = optimoptions('particleswarm', 'PlotFcn',@pswplotbestf);[x, fval] = particleswarm(fitnessFunction, nvars, lb, ub, options);11. 蚁群算法:matlab.distanceMatrix = [0, 2, 3; 2, 0, 4; 3, 4, 0];pheromoneMatrix = ones(3, 3);alpha = 1;beta = 1;iterations = 10;bestPath = antColonyOptimization(distanceMatrix, pheromoneMatrix, alpha, beta, iterations);12. 粒子群-蚁群混合算法:matlab.distanceMatrix = [0, 2, 3; 2, 0, 4; 3, 4, 0];pheromoneMatrix = ones(3, 3);alpha = 1;beta = 1;iterations = 10;bestPath = particleAntHybrid(distanceMatrix, pheromoneMatrix, alpha, beta, iterations);13. 遗传算法-粒子群混合算法:matlab.fitnessFunction = @(x) x^2 4x + 4;nvars = 1;lb = 0;ub = 5;gaOptions = gaoptimset('PlotFcns', @gaplotbestf);psOptions = optimoptions('particleswarm', 'PlotFcn',@pswplotbestf);[x, fval] = gaParticleHybrid(fitnessFunction, nvars, lb, ub, gaOptions, psOptions);14. K近邻算法:matlab.x = [1, 2, 3, 4, 5; 1, 2, 2, 3, 3]; y = [0, 0, 1, 1, 1];model = fitcknn(x', y');predicted_y = predict(model, x');15. 朴素贝叶斯算法:matlab.x = [1, 2, 3, 4, 5; 1, 2, 2, 3, 3]; y = [0, 0, 1, 1, 1];model = fitcnb(x', y');predicted_y = predict(model, x');16. AdaBoost算法:matlab.x = [1, 2, 3, 4, 5; 1, 2, 2, 3, 3];y = [0, 0, 1, 1, 1];model = fitensemble(x', y', 'AdaBoostM1', 100, 'Tree'); predicted_y = predict(model, x');17. 高斯混合模型算法:matlab.x = [1, 2, 3, 4, 5]';y = [0, 0, 1, 1, 1]';data = [x, y];model = fitgmdist(data, 2);idx = cluster(model, data);18. 主成分分析算法:matlab.x = [1, 2, 3, 4, 5; 1, 2, 2, 3, 3]; coefficients = pca(x');transformed_x = x' coefficients;19. 独立成分分析算法:matlab.x = [1, 2, 3, 4, 5; 1, 2, 2, 3, 3]; coefficients = fastica(x');transformed_x = x' coefficients;20. 模糊C均值聚类算法:matlab.x = [1, 2, 3, 4, 5; 1, 2, 2, 3, 3]; options = [2, 100, 1e-5, 0];[centers, U] = fcm(x', 2, options);21. 遗传规划算法:matlab.fitnessFunction = @(x) x^2 4x + 4; nvars = 1;lb = 0;ub = 5;options = optimoptions('ga', 'PlotFcn', @gaplotbestf);[x, fval] = ga(fitnessFunction, nvars, [], [], [], [], lb, ub, [], options);22. 线性规划算法:matlab.f = [-5; -4];A = [1, 2; 3, 1];b = [8; 6];lb = [0; 0];ub = [];[x, fval] = linprog(f, A, b, [], [], lb, ub);23. 整数规划算法:matlab.f = [-5; -4];A = [1, 2; 3, 1];b = [8; 6];intcon = [1, 2];[x, fval] = intlinprog(f, intcon, A, b);24. 图像分割算法:matlab.image = imread('image.jpg');grayImage = rgb2gray(image);binaryImage = imbinarize(grayImage);segmented = medfilt2(binaryImage);25. 文本分类算法:matlab.documents = ["This is a document.", "Another document.", "Yet another document."];labels = categorical(["Class 1", "Class 2", "Class 1"]);model = trainTextClassifier(documents, labels);newDocuments = ["A new document.", "Another new document."];predictedLabels = classifyText(model, newDocuments);26. 图像识别算法:matlab.image = imread('image.jpg');features = extractFeatures(image);model = trainImageClassifier(features, labels);newImage = imread('new_image.jpg');newFeatures = extractFeatures(newImage);predictedLabel = classifyImage(model, newFeatures);27. 时间序列预测算法:matlab.data = [1, 2, 3, 4, 5];model = arima(2, 1, 1);model = estimate(model, data);forecastedData = forecast(model, 5);28. 关联规则挖掘算法:matlab.data = readtable('data.csv');rules = associationRules(data, 'Support', 0.1);29. 增强学习算法:matlab.environment = rlPredefinedEnv('Pendulum');agent = rlDDPGAgent(environment);train(agent);30. 马尔可夫决策过程算法:matlab.states = [1, 2, 3];actions = [1, 2];transitionMatrix = [0.8, 0.1, 0.1; 0.2, 0.6, 0.2; 0.3, 0.3, 0.4];rewardMatrix = [1, 0, -1; -1, 1, 0; 0, -1, 1];policy = mdpPolicyIteration(transitionMatrix, rewardMatrix);以上是30个使用MATLAB编写的智能算法的示例代码,每个算法都可以根据具体的问题和数据进行相应的调整和优化。

链式网络DEA与matlab应用:二阶段附加投入的DEA链式网络DEA包括2阶段、3阶段等多阶段,我们考虑2阶段附加投入的DEA模型。
网络DEA 模型的形式是我们把决策单元分解为K 个子过程,每个子过程都有相应的投入变量和输出变量,同时还有中间变量,中间变量既是上一子系统输出的变量,又是下一子系统输入的变量,我们把各个过程依照流程的次序排列好,上一子过程的中间产出变量要由下一个过程进行消费,通过相关中间变量,紧密联系决策单元各子过程。
对应的一般模型为,DEA模型如下:第一阶段CCR模型:不仅考虑到要求保证第一阶段的效率值小于 1,同时考虑附加约束即第二阶段的效率值阈值为 1,计算第一阶段的最佳效率,记为0max 1θ。
所以,第一阶段的效率值 01θ的约束条件为00max 11[0,]θθ∈。
根据 Charnes -Cooper 变换,将第一阶段模型转换为线性方程,θ=同理根据 Charnes -Cooper 变换,1,01max θθ==⋅∑sr r r u yclear;clc;M=xlsread('C:\MATLAB74\work\new','Sheet1','A2:G28');%第一阶段3个投入M的1-2列,产出为M的3列;%第二阶段的新投入为M的4-5列,产出为M的6-7列X1=M(:,1:2);%第一阶段初始投入矩阵X1,列数为DMU的个数n,行数为投入种类m Z=M(:,3:3); %第一阶段产出矩阵Z,列数为DMU的个数n,行数为产出种类DX2=M(:,4:5);%第二阶段追加投入x2,列数为DMU的个数n,行数为附加投入种类H Y=M(:,6:7);%第二阶段最终产出矩阵Y,列数为DMU的个数n,行数为最终产出种类sn=size(X1,1);m=size(X1,2);D=size(Z,2);H=size(X2,2);s=size(Y,2);theta1=zeros(n,1);theta2=zeros(n,1);w=cell(n,1);v=w;Q=w;u=w;options=optimset('display','off');for i=1:n%% 第一次线性规划f=-[Z(i,:),zeros(1,(m+H+s))];A=[Z,-X1,zeros(n,(H+s));-Z,zeros(n,m),-X2,Y];b=zeros(2*n,1);Aeq=[zeros(1,D),X1(i,:),zeros(1,(H+s))];beq=1;lb=zeros(1,(D+m+H+s));ub=inf*ones(1,(D+m+H+s));[w1,feval]=linprog(f,A,b,Aeq,beq,lb,ub,[],options);theta1(i)=-feval;%% 第二次线性规划theta0=linspace(0,theta1(i));THETA=zeros(1,100);for j=1:100f=-theta0(j)*[zeros(1,m),zeros(1,D),zeros(1,H),Y(i,:)];A=[-X1,Z,zeros(n,H),zeros(n,s);zeros(n,m),-Z,-X2,Y];b=zeros(2*n,1);Aeq=[zeros(1,m),Z(i,:),X2(i,:),zeros(1,s);-theta0(j)*X1(i,:),Z(i,:),zeros(1,H),zeros(1,s)];beq=[1;0];lb=zeros(1,(m+D+H+s));ub=inf*ones(1,(m+D+H+s));[w2,feval]=linprog(f,A,b,Aeq,beq,lb,ub,[],options);THETA(j)=-feval;end%[~,j]=max(THETA);f=-theta0(j)*[zeros(1,m),zeros(1,D),zeros(1,H),Y(i,:)];A=[-X1,Z,zeros(n,H),zeros(n,s);zeros(n,m),-Z,-X2,Y];b=zeros(2*n,1);Aeq=[zeros(1,m),Z(i,:),X2(i,:),zeros(1,s);-theta0(j)*X1(i,:),Z(i,:),zeros(1,H),zeros(1,s)];beq=[1;0];lb=zeros(1,(m+D+H+s));ub=inf*ones(1,(m+D+H+s));[x,feval]=linprog(f,A,b,Aeq,beq,lb,ub,[],options);theta2(i)=-feval;v{i}=x(1:m);w{i}=x(m+1:m+D);Q{i}=x(m+D+1:m+D+H);u{i}=x(m+D+H+1:end);endB=[theta1,theta2./theta1,theta2];。


中国区域碳排放绩效评价与差异分析李雷鸣;孙梁平;刘丙泉【摘要】建立考虑资源禀赋限制的全要素指标体系,运用超效率DEA模型,对中国28个省(市、自治区)“十一五”期间碳排放绩效予以评价,在此基础上梳理各区域碳排放绩效演化特征,进而把握各区域内部及区域之间差异变化规律.研究发现:“十一五”期间,中国整体碳排放绩效保持较高水平,但提升速度相对较缓慢;三大地区中,东部地区绩效最高,西部地区提升速度最快;全国各省(市、自治区)间在2006-2009年差异较稳定,之后呈发散态势,东部地区与全国情况基本一致,中部地区发生α收敛,西部地区差异变动较大,三大地区间的差异变动较小.【期刊名称】《中国石油大学学报(社会科学版)》【年(卷),期】2013(029)005【总页数】5页(P38-42)【关键词】超效率DEA;碳排放绩效;差异【作者】李雷鸣;孙梁平;刘丙泉【作者单位】中国石油大学经济管理学院,山东青岛266580;中国石油大学经济管理学院,山东青岛266580;中国石油大学经济管理学院,山东青岛266580【正文语种】中文【中图分类】F205;X24一、引言目前,碳排放绩效已引起国内外学者的广泛关注,学者们提出了不同的指标体系与研究方法,从多角度对碳排放绩效予以评价。
在指标选取方面,早期研究认为,碳排放主要来源于能源消耗,因而大多数研究主要利用能源强度(单位GDP能源消费量)[1]、碳指数(单位能源消耗碳排放量)[2]来衡量碳排放绩效;另一部分学者认为经济发展对于碳排放产生根本性的影响,碳强度(单位GDP碳排放量)[3]更能反映一地区碳排放水平。
上述研究多以碳排放量与某一要素的比值来衡量碳排放绩效,具有明显的“单要素”特征。
然而碳排放绩效是能源、劳动力、资本等多投入要素共同作用的结果,具有“全要素”特点,并且要素间有不容忽视的替代性,而单要素研究结果对碳减排措施提出作用不大,因此建立全要素指标体系更加合理。
DEA算法学习笔记系列(三)一次性求解CCR模型所有DMU参数——效率、规模效益、有效性特征、调整值的matlab代码目录1 编写目的 (4)1.1E XCEL一次只能计算一个DMU (4)1.2M A TLAB编程一次性计算所有DMU的效率、有效性、调整值 (5)2 MATLAB求解线性规划 (5)2.1系统函数说明 (5)2.1.1 调用格式: (5)2.1.2 输入参数说明 (5)2.1.3 返回值说明 (6)2.2简单例子,用代码求解 (7)2.2.1 例1 (7)2.2.2 例2: (8)2.2.3 例题3(无解的例子) (9)2.2.4 例4(需要标准化的例子,一个等式的例子) (10)2.2.5 例5 (11)2.2.6 例子6:松弛变量为基变量——用等式重解例1 (13)2.3自定义M A TLAB函数求解线性规划(从EXCEL读数据) (14)2.3.1 简单版:MyLinprog——读取给定文件中数据,返回计算结果 (14)3 DEA模型之CCR简介 (16)3.1CCR理论模型 (16)4 CCR模型计算过程——一个决策单元的计算过程 (18)4.1例题说明 (18)4.2基于理论构建模型——湖南省 (19)4.3调整形式,以利于线性规划函数求解 (19)4.4按照自定义函数,构造EXCEL文件 (20)4.4.1 矩阵A的格式和说明 (20)4.4.2 价值向量系数矩阵C的格式和说明 (20)4.4.3 资源限制矩阵b的格式和说明 (21)4.4.4 X取值条件的限制 (21)4.5调用自定义函数(M Y L INPROG)求解指定决策单元模型 (22)4.6计算结果评价 (22)4.6.1 最优值 (22)4.6.2 各变量的值 (23)4.6.3 模型效率分析 (24)4.7调整方案 (24)5 计算CCR模型的MATLAB函数——所有决策单元 (25)5.1程序代码(可直接运行) (25)5.2存放数据的EXCEL文件格式说明 (27)5.2.1 第一个:投入产出数据 (27)5.2.2 第二个数据:价值变量系数矩阵(不需准备) (27)5.2.3 第三个数据:资源限制矩阵(不需要准备) .................................................................. 28 5.2.4 第四个数据:决策变量的取值范围(不需要准备) ...................................................... 28 5.2.5 范例数据 .............................................................................................................................. 28 5.3 计算所有DMU 的函数 .............................................................................................................. 28 5.3.1 函数输入参数 ...................................................................................................................... 28 5.3.2 返回参数1:每个DMU 效率、规模效益、是否弱有效 ................................................ 28 5.3.3 返回参数2:每个DMU 的所有值 (29)5.3.4 返回参数3:增加的松弛变量 ........................................................................................... 29 5.3.5 返回参数4:非DEA 有效DMU 调整后的投入产出矩阵 .............................................. 29 5.3.6 返回参数5:非DEA 有效DMU 各个指标调整值 .......................................................... 29 5.4 返回参数例子 ............................................................................................................................. 29 5.4.1 返回参数1:每个DMU 效率、规模效益、是否弱有效 ................................................ 29 5.4.2 返回参数2:每个DMU 的所有值 (30)5.4.3 返回参数3:增加的松弛变量 ........................................................................................... 30 5.4.4 返回参数4:非DEA 有效DMU 调整后的投入产出矩阵 .............................................. 30 5.4.5 返回参数5:非DEA 有效DMU 各个指标调整值 .......................................................... 30 6 补充知识 ............................................................................................................................................ 30 6.1 自定义MA TLAB 函数 .................................................................................................................. 30 6.2 M A TLAB 向量操作 ....................................................................................................................... 32 6.2.1 读取矩阵第一列 .................................................................................................................. 32 6.3 M A TLAB 操作EXCEL 数据 ........................................................................................................... 32 6.3.1 读入excel 数据 .................................................................................................................... 32 6.3.2 写内容到xls ........................................................................................................................ 33 6.4 M A TLAB 的FOR 循环语句............................................................................................................ 35 7 参考资料 .. (35)λλ1 编写目的1.1 Excel 一次只能计算一个DMUDEA 的CCR 模型,他的对偶模型如下图:⎪⎪⎪⎪⎪⎩⎪⎪⎪⎪⎪⎨⎧≥=-+++=-+++=++++=++++=++++=++---无约束θθθθθλλλλλλλλλλλλλλλλλλλλλ,004.165921.266204.165922.93009.219620.144410.18120.144760.4929.17920.443000.46120.44320.24980.40131.84940.144431.84964.58145.98084.93656.130684.93608.58366.932..min 2432114321343212432114321jDs s s s s Vt s 很多人通过EXCEL 提供的一个插件进行计算,如下图所示:但是,这种方法有以下不足:(1)每次只能计算一个DMU ,如果有多个DMU ,那么需要人工重复计算过程多次;(2)通过Excel 计算,只能得到θ,没法得到各个,所以,也无法直接判断是规模效益递增还是递减;λ(3)没发直接得到ss ii、+-的值,也无法直接判断DMU 是弱DEA 有效,还是DEA 有效1.2 Matlab 编程一次性计算所有DMU 的效率、有效性、调整值文章通过编写Matlab 程序,实现一次性对所有DMU 计算效率θ、有效性(根据θ以及所有的汇总值)、调整值(根据ss ii、+-)。
MATLAB在超效率DEA模型中的应用作者:刘展屈聪来源:《经济研究导刊》2014年第03期摘要:利用数学软件MATLAB编写了便于使用超效率DEA模型的计算程序,并利用该程序对河南省2002—2011年财政科技投入的超效率进行计算与分析,实证分析表明该MATLAB计算程序十分的方便、有效。
关键词:MATLAB;超效率DEA模型;财政科技投入中图分类号:F22 文献标志码:A 文章编号:1673-291X(2014)03-0086-03随着时代的发展,超效率数据包络分析模型(SE-DEA)也随之被提出,并被运用得越来越广泛,相应的求解软件的开发也在不断的向前推进。
目前主要有DEA Solver pro、Pioneer、EMS、DEA Excel Solver、等专门用于求解SE-DEA模型的软件,但获得这些软件不太容易,在一般的网站无法下载与购买,需要通过一些专门的渠道。
MATLAB是一门功能强大、简单易学且应用广泛的编程语言,而且MATLAB软件的下载与购买相对来说比较容易。
文献[1]给出了数据包络分析模型(DEA)的基本模型C2R模型的MATLAB计算程序,但对于超效率数据包络分析模型的MATLAB计算程序,目前尚未有文献报道。
本文在文献[1]的基础上,编写超效率数据包络分析模型的计算程序,并进行实证分析。
一、超效率DEA模型超效率数据包络分析模型(Super Efficiency DEA,SE-DEA)是由Andersen&Petersen根据传统DEA模型所提出的新模型。
传统DEA模型如最基本的C2R模型对决策单元规模有效性和技术有效性同时进行评价,BC2模型用于专门评价决策单元技术有效性,但C2R模型和BC2模型只能区别出有效率与无效率的决策单元,无法进行比较和排序。
超效率DEA模型与C2R模型的不同之处在于评价某个决策单元时将其排除在决策单元集合之外,这样使得C2R 模型中相对有效的决策单元仍保持相对有效,同时不会改变在C2R模型中相对无效决策单元在超效率DEA模型中的有效性,可以弥补传统DEA模型的不足,计算出的效率值不再限制在0~1的范围内,而是允许效率值超过1,可以对各决策单元进行比较和排序。
MATLAB在DEA-Malmquist分析中的应用作者:***来源:《计算机时代》2021年第07期摘要: DEA-Malmquist分析需要巨大的运算量,MATLAB软件集成多个经过优化的工具箱,能够降低DEA-Malmquist分析的时间开销。
文章基于Inmaculada C. Álvarez等人编写的开源MATLAB工具箱,进行DEA-Malmquist分析。
程序运行结果表明,MATLAB软件能够胜任DEA-Malmquist的分析工作,可以为经济与管理学的研究提供强大的支持。
关键词: MATLAB; 数据包络分析(DEA); Malmquist指数; 线性规划中图分类号:O221.1,TP311.1 文献标识码:A 文章编号:1006-8228(2021)07-42-04Application of MATLAB in DEA-Malmquist analysisLi Jianxiong(Supervision and Audit Office, Sihui Prison of Guangdong, Sihui, Guangdong 526237,China)Abstract: DEA-Malmquist analysis requires a huge amount of calculations. MATLAB software integrates multiple optimized toolboxes, which can reduce the time overhead of DEA-Malmquist analysis. Based on the open source MATLAB toolbox written by Inmaculada C. Álvarez and others,this paper conduct a DEA-Malmquist analysis. The operation results show that the MATLAB software is competent for DEA-Malmquist's analysis work and can provide the researches on economics and management with a strong support.Key words: MATLAB; Data Envelopment Analysis (DEA); Malmquist; linear programming0 引言数据包络分析(Data Envelopment Analysis, DEA)是一种以多个指标为输入变量,衡量不同决策单元(Decision-Making Unit)的绩效的一种分析方法,被广泛应用于绩效和效益的评价中[1-2];Malmquist指数是由StenMalmquist于1953年提出[3],最初用于消费分析。
基于超效率DEA方法的公路运输效率评价与分析李洁;左毅刚【摘要】超效率DEA方法是基于传统DEA方法改进的1种方法,它可以解决传统DEA方法在运输效率评价方面无法对DEA有效(效率值为1)的决策单位进行进一步排序的弊端.以江苏省为例,分别运用DEA方法、超效率DEA方法,从投入、产出的8个效率角度对13个辖市的公路运输业进行了运输效率分析,通过计算得到了各个城市公路运输业的DEA值与超效率DEA值,并按照超效率DEA值对各个城市的公路运输效率进行排序、分析,结果显示,江苏省公路运输效率存在明显的地域差异,并对改善江苏省公路运输效率低地区的发展提出建议.【期刊名称】《交通信息与安全》【年(卷),期】2015(033)001【总页数】6页(P127-132)【关键词】公路交通运输;评价;超效率DEA;运输效率【作者】李洁;左毅刚【作者单位】广州华工信息软件有限公司广州510517;东南大学交通学院南京210096【正文语种】中文【中图分类】U4910 引言公路运输是国民经济发展的基础性产业,在社会发展和经济建设中起着举足轻重的作用。
随着公路运输市场的开放和管理机制的改革,公路运输市场的主题已经具备可自主经营、自负盈亏、自我发展的能力。
公路运输作为1个地方经济支柱性行业,运输效率的高低是衡量1个区域交通运输能力和区域经济发展状况的主要标志。
公路运输产业的效率评价可以对投入和产出进行分析,从而能够进一步地把握公路产业的投资方向,对于提高公路资源的利用效率具有很高的指导意义。
传统的数据包络分析法(data envelopment analysis,DEA)作为评价公路运输效率的1种工具,其实质就是对具有多个输入、输出的决策单元(decision making unit,DMU)间的相对有效性进行评价.主要特点是不需要对输入和输出指标赋予相对权重,脱离了评价中的主观性约束,因此DEA方法能够反映出决策单元所处的实际客观状态[1]。
模型((P 的模型C2 R)的MATLAB 程序clearX=[]; %用户输入多指标输入矩阵XY=[]; %用户输入多指标输出矩阵Yn=size(X',1); m=size(X,1); s=size(Y,1); A=[-X' Y'];b=zeros(n, 1);LB=zeros(m+s,1);UB=[];for i=1:n;f= [zeros(1,m) -Y(:,i)'];Aeq=[X(:,i)' zeros(1,s)];beq=1;w(:,i)=LINPROG(f,A,b,Aeq,beq,LB,UB); %解线性规划,得DMU;的最佳权向量w; E(i, i)=Y(:,i)'*w(m+1:m+s,i); %求出DMUi 的相对效率值Eiiendw %输出最佳权向量E %输出相对效率值EiiOmega=w(1:m,:) %输出投入权向量。
mu=w(m+1:m+s,:) %输出产出权向量。
模型(Dε的模型C 2R)的MA TLAB 程序clearX=[]; %用户输入多指标输入矩阵XY=[]; %用户输入多指标输出矩阵Yn=size(X',1); m=size(X,1); s=size(Y,1);epsilon=10^-10; %定义非阿基米德无穷小=10^-10f=[zeros(1,n) -epsilon*ones(1,m+s) 1]; %目标函数的系数矩阵:的系数为0,s-,s+的系数为-e,的系数为1;A=zeros(1,n+m+s+1); b=0; %<=约束;LB=zeros(n+m+s+1,1); UB=[]; %变量约束;LB(n+m+s+1)= -Inf; %-Inf 表示下限为负无穷大。
for i=1:n;Aeq=[X eye(m) zeros(m,s) -X(:,i)Y zeros(s,m) -eye(s) zeros(s,1)];beq=[zeros(m, 1 )Y(:,i)];w(:,i)=LINPROG (f,A,b,Aeq,beq,LB,UB); %解线性规划,得DMU 的最佳权向量w;endw %输出最佳权向量lambda=w(1:n,:) %输出s_minus=w(n+1:n+m,:) %输出ss_plus=w(n+m+1:n+m+s,:) %输出s+ theta=w(n+m+s+1,:) %输出w=1.0000 0.0000 0.0000 0.00000.0000 1.0000 0.0000 0.07130.0000 0.0000 1.0000 0.24950.0000 0.0000 0.0000 0.00000.0000 0.0000 0.0000 0.00000.0000 0.0000 0.0000 0.00000.0000 0.0000 0.0000 0.00000.0000 0.0000 0.0000 28.50970.0000 0.0000 0.0000 0.00001.0000 1.0000 1.0000 0.8553lambda =1.0000 0.0000 0.0000 0.00000.0000 1.0000 0.0000 0.07130.0000 0.0000 1.0000 0.24950.0000 0.0000 0.0000 0.0000s_minus =0.0000 0.0000 0.0000 0.00000.0000 0.0000 0.0000 0.00000.0000 0.0000 0.0000 0.00000.0000 0.0000 0.0000 28.5097s_plus =1.0e-005 *0.0000 0.0010 0.0037 0.1474theta = 1.0000 1.0000 1.0000 0.8553面对外需乏力的局面,中国经济增长的动力责无旁贷地落在了内需上,而作为中国最大内需潜力所在的城镇化,则迫切需解决效率不高的问题。
DEA的模型:SBM,RAM,动态网络DEA (Dynamic Network DEA)DEA-CRS、VRS,有代表性的:CCR,BCC,FG,ST模型。
扩展形式:如超效率DEA模型、DEA-Tobit模型、DEA-SBM模型CCR:前提是规模报酬不变,以线性规划法估计生产前沿,对每个决策单元(DMU)的相对效率进行评估。
结果将每一个决策单元分为有效率和无效率两类,可能会出现多个决策单元同时效率值为1,会出现无法比较决策单元的情况。
超效率DEA:可以对同时有效的决策单元进行排序的模型。
将决策单位效率值为1的部分再次进行评价,弥补了CCR模型无法比较的有效决策单元的缺陷。
Malmquist指数模型:DEA-solverI:投入导向O:产出导向C:CRSV:VRS可以使用动态DEA和网络DEA,可以评估多个时期框架内的网络DMUDEA的matlab程序1、基于DEA模型北京林业投入产出效率分析BCC-DEA模型;结论:平均综合效率值,DEA有效状态、无效状态,每个维度变化对投出产出效率的影响相对大小。
本文主要采用C2R-DEA 模型和BC2-DEA 模型。
其中,C2R模型假设规模报酬不变,即所有决策单元( Decision making unit,DMU) 都在最优规模条件下运行。
当DMU 没有在最优规模条件下运行时,C2R-DEA 模型可能会出现技术效率的测度受规模效率影响的情况。
因此,本文选取考虑规模收益的BC2-DEA 模型,它可以排除规模效率对测度结果的影响。
选取投入指标3,产出指标3。
2、基于DEA-Malmquist方法的中国区域排污费征管效率分析本文利用数字包络分析方法( DEA 模型) 和Malmquist 指数对我国排污费征管效率进行实证研究。
基于面板数据对我国31 个省市自治区2005 -2010 年的排污费征管效率变化状况进行测算,分析排污费征管效率的变化情况以及影响因素,并测算征管效率对排污费增长的贡献率。