结构方程模型+验证性因素分析过程指标(优质严制)
- 格式:doc
- 大小:709.00 KB
- 文档页数:5

信度效度分析结构方程模型验证性因子分析信度效度分析结构方程模型是一种统计方法,用于评估一个测量工具(如问卷或量表)的信度和效度。
验证性因子分析是使用结构方程模型的一种方法,用于验证假设的因素结构。
本文将介绍信度效度分析结构方程模型和验证性因子分析的步骤和应用,以及一些相关的注意事项。
首先,我们将介绍信度效度分析结构方程模型的步骤。
该模型可以用于评估测量工具的信度和效度,以确定它是否能够准确地测量所需的概念。
1.确定研究目的和研究问题:在进行分析之前,需要明确研究目的和研究问题。
这将有助于确定所需的测量工具和相关的概念。
2.收集数据:然后,需要收集与研究问题相关的数据。
这可以通过调查问卷、观察或其他适当的方法来实现。
3. 选择合适的统计软件:进行信度效度分析结构方程模型分析时,选择合适的统计软件是很重要的。
一些常用的软件包括AMOS、Mplus和LISREL。
4.构建测量模型:根据所选择的测量工具,构建一个测量模型。
这个模型将包括所需的概念和相关的测量项目。
5. 评估信度:评估信度是评估测量工具的一致性和稳定性。
常用的信度分析方法包括内部一致性(如Cronbach's α系数)和重测信度(如测试-重新测试法)。
6.评估效度:评估效度是评估测量工具的有效性和准确性。
常用的效度分析方法包括内部效度(如因子分析)和外部效度(与其他测量工具或标准进行比较)。
7.进行结构方程模型:一旦信度和效度得到评估,可以进行结构方程建模。
这将用于验证因素结构和模型拟合。
8.评估模型拟合:评估模型拟合是验证性因子分析的关键一步。
常用的指标包括χ²值、自由度、比例指数(CFI)、增量拟合指数(IFI)、均方根误差逼近指数(RMSEA)等。
9.修正模型:如果模型拟合不佳,需要进行适当的修正。
这可能包括删除不显著的路径、修正误差项相关性等。
10.解释和报告结果:最后,需要解释和报告分析结果。
这将包括变量之间的关系、可信度和效度的指标以及任何必要的修正。

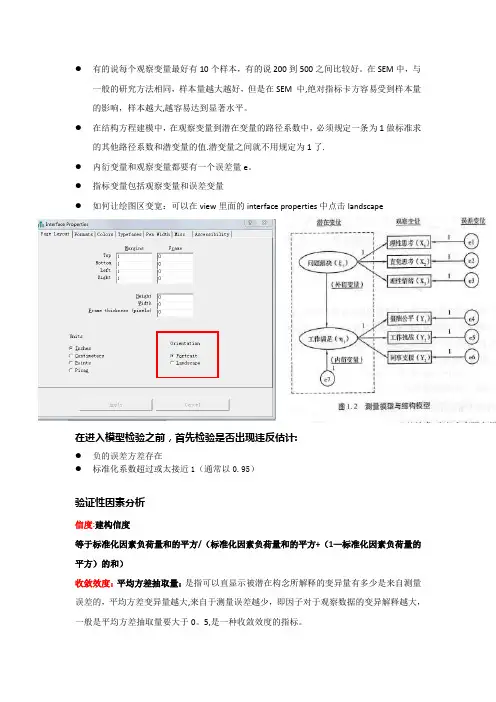
●有的说每个观察变量最好有10个样本,有的说200到500之间比较好。
在SEM中,与一般的研究方法相同,样本量越大越好,但是在SEM 中,绝对指标卡方容易受到样本量的影响,样本越大,越容易达到显著水平。
●在结构方程建模中,在观察变量到潜在变量的路径系数中,必须规定一条为1做标准求的其他路径系数和潜变量的值.潜变量之间就不用规定为1了.●内衍变量和观察变量都要有一个误差量e。
●指标变量包括观察变量和误差变量●如何让绘图区变宽:可以在view里面的interface properties中点击landscape在进入模型检验之前,首先检验是否出现违反估计:●负的误差方差存在●标准化系数超过或太接近1(通常以0.95)验证性因素分析信度:建构信度等于标准化因素负荷量和的平方/(标准化因素负荷量和的平方+(1—标准化因素负荷量的平方)的和)收敛效度:平均方差抽取量:是指可以直显示被潜在构念所解释的变异量有多少是来自测量误差的,平均方差变异量越大,来自于测量误差越少,即因子对于观察数据的变异解释越大,一般是平均方差抽取量要大于0。
5,是一种收敛效度的指标。
等于标准化因素负荷量的平方之和/题目数目验证性因素分析基本模型适配度检验摘要表:●是否没有负的误差变异量e1 e2 e3●因素负荷量(潜在变量与观察变量之间的标准化系数)是否介于0。
5到0。
95之间●Variances 是否没有很大的标准误(路径系数的标准误)整体模型适配度检验摘要表:绝对适配度指数●卡方值,p大于0。
05,说明数据本身的协方差矩阵和模型的协方差矩阵是匹配的.●RMR值小于0.05,●RMSEA小于0。
08(小于0。
05优良,若是小于0.08良好)●GFI大于0。
90,适配优度●AGFI 大于0。
90 (调整后的适配度)增值适配度指数●NFI大于0.90●RFI 大于0.90●IFI大于0。
90●TLI(也称为NNFI) 大于0.90●CFI大于0.90简约适配度指数:●PGFI 大于0.50●PNFI大于0。



结构方程模型指标介绍结构方程模型(Structural Equation Modeling, SEM)是一种统计分析方法,用于检验观测或测量指标与潜在变量之间的关系。
通过构建数学模型,结构方程模型可以帮助研究者了解变量之间的因果关系和测量指标之间的关联性。
本文将介绍结构方程模型的基本概念和常用指标。
一级标题2二级标题1在结构方程模型中,常用的指标包括: 1. 参数估计指标 - 确定性系数(R-squared) - 标准化系数(Standardized Coefficients) - 因素载荷(Factor Loadings) 2. 模型拟合度指标 - 卡方检验(Chi-Square Test) - 拟合优度指数(Goodness of Fit Index, GFI) - 修正拟合指数(Adjusted Goodness ofFit Index, AGFI) - 根均方误差逼近指数(Root Mean Square Error of Approximation, RMSEA) - 比较拟合指数(Comparative Fit Index, CFI) 3.判定系数(Coefficient of Determination) 4. 相对拟合指数(Relative Fit Index, RFI)二级标题2三级标题1参数估计指标可以帮助研究者了解变量之间的关系及其强度。
其中,确定性系数(R-squared)可以衡量模型解释因变量方差的能力,取值范围为0到1,越接近1表示模型解释能力越强。
标准化系数(Standardized Coefficients)可以衡量变量之间的关系强度,也可以用于比较不同变量对因变量的影响程度。
因素载荷(Factor Loadings)表示观测指标与潜在变量之间的关联性,取值范围为-1到1,绝对值越大表示关联程度越强。
三级标题2模型拟合度指标用于评估结构方程模型的拟合程度。
卡方检验(Chi-Square Test)可以检验实际观测数据与模型拟合数据之间的差异,一般情况下,卡方值越小越好。


收稿日期: 2007-09-23作者简介: 黄国稳(1983~),男,广西天等县人,广西师范大学数学科学学院硕士生,主要从事数学课程与教学论研究;周莹(1962~),女,浙江嵊州人,广西师范大学数学科学学院副教授、硕士生导师,主要从事数学课程与教学论研究。
结构方程模型及其在验证性分析中的应用黄国稳,周 莹(广西师范大学 数学科学学院,广西桂林 541004)摘 要: 结构方程模型是基于变量的协方差矩阵来分析变量间关系的一种统计方法,广泛应用于社会、行为科学研究领域。
文章先介绍结构方程模型的基本概念、基本结构、基本原理及其主要优点,然后结合一个具体的示例,说明这种方法在验证性分析中的应用。
关键词: 结构方程模型;验证性分析;应用分类号: O141.4 文献标识码: A 文章编号:1673-8233(2007)06-0049-041 引言在教育研究中,常常遇到一些不可直接测量的概念,如数学认识信念、元认知、自我效能、成就动机、数学焦虑等,需要采用多个指标来进行间接测量,而指标的构成常运用因素分析这一统计技术,它常用来从一堆项目中抽取一些共同因素,当共同因素被抽取出来之后,就可以获得每一个项目和每个因素间的因素负荷量,是用于代表项目测量共同因素的重要性指标,也可以从因素转轴后获得的指标来评价项目的优劣,以呈现潜在的理论建构。
但是,此分析结果只能作为量表编制过程中的初步结构探讨或理论形成之用,无法作为检验理论因素建构之用,而结构方程模型分析方法能够妥善地处理不可直接测量的变量,可以对理论所建构的指标与所收集资料间的符合程度进行检验,弥补了传统统计方法的不足。
本文在简述结构方程模型的基本概念、基本结构、基本原理及其主要优点基础上,结合一个具体的示例,以说明结构方程模型在验证性分析中的应用。
2 结构方程模型简述2.1 基本概念结构方程模型(Structural Equation M odel,简称SEM )是基于变量的协方差矩阵来分析变量之间关系的一种多元统计方法,也称协方差结构分析(covariance structure analy sis),它是基于已有的因果理论,用与之相应的线性方程,表示该因果理论的一种统计分析方法和技术,其目的在于探索事物间因果关系并将这种关系用因果模型、路径图等表述。

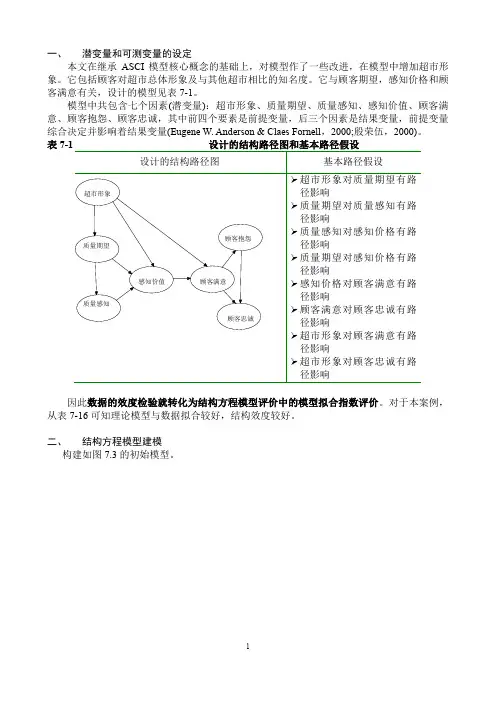
一、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
表因此数据的效度检验就转化为结构方程模型评价中的模型拟合指数评价。
对于本案例,从表7-16可知理论模型与数据拟合较好,结构效度较好。
二、结构方程模型建模构建如图7.3的初始模型。
图7-3 初始模型结构图7-4 Amos Graphics 初始界面图第一节 Amos 实现1一、Amos 模型设定操作 1 这部分的操作说明也可参看书上第七章第二节:Amos 实现。
1.模型的绘制在使用Amos进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图,并确定潜变量与可测变量的名称,以避免不必要的返工。
相关软件操作如下:第一步,使用建模区域绘制模型中的七个潜变量(如图7-6)。
为了保持图形的美观,可以使用先绘制一个潜变量,再使用复制工具绘制其他潜变量,以保证潜变量大小一致。
在潜变量上点击右键选择Object Properties,为潜变量命名(如图7-7)。
绘制好的潜变量图形如图7-8。
第二步设置潜变量之间的关系。
使用来设置变量间的因果关系,使用来设置变量间的相关关系。
绘制好的潜变量关系图如图7-9。
图7-7 潜变量命名图7-8 命名后的潜变量图7-9 设定潜变量关系第三步为潜变量设置可测变量及相应的残差变量,可以使用绘制,也可以使用和自行绘制(绘制结果如图7-10)。
在可测变量上点击右键选择Object Properties,为可测变量命名。
应用案例1第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
3见spss数据文件“处理后的数据.sav”。
2.1、顾客满意模型中各因素的具体范畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
问卷内容包括7个潜变量因子,24项可测指标,4正向的,采用Likert10级量度从“非常低”到“非常高”本次调查共发放问卷500份,收回有效样本436份。
应用案例1第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
表7-1 设计的结构路径图和基本路径假设1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
3见spss数据文件“处理后的数据.sav”。
、顾客满意模型中各因素的具体范畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
表7-2 模型变量对应表三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
二、要求(1)预调研(前175份问卷)信效度检验:分量表测量数据的信效度,信度达标,效度用验证性因子分析预信度分析企业属性量表信度系数值为0.906,大于0.9,因而说明研究数据信度质量很高。
针对“项已删除的α系数”,任意题项被删除后,信度系数并不会有明显的上升,因此说明题项不应该被删除处理。
针对“CITC值”,分析项的CITC值均大于0.4,说明分析项之间具有良好的相关关系,同时也说明信度水平良好。
综上所述,研究数据信度系数值高于0.9,综合说明数据信度质量高,可用于进一步分析。
经营状况信度系数值为0.700,大于0.6,因而说明研究数据信度质量可以接受。
针对“项已删除的α系数”,任意题项被删除后,信度系数并不会有明显的上升,因此说明题项不应该被删除处理。
针对“CITC值”,分析项的CITC值均大于0.4,说明分析项之间具有良好的相关关系,同时也说明信度水平良好。
综上所述,研究数据信度系数值高于0.6,综合说明数据信度质量可以接受。
应急能力信度系数值为0.879,大于0.8,因而说明研究数据信度质量高。
针对“项已删除的α系数”,任意题项被删除后,信度系数并不会有明显的上升,因此说明题项不应该被删除处理。
针对“CITC值”,分析项的CITC值均大于0.4,说明分析项之间具有良好的相关关系,同时也说明信度水平良好。
综上所述,研究数据信度系数值高于0.8,综合说明数据信度质量高,可用于进一步分析。
政策法规信度系数值为0.707,大于0.7,因而说明研究数据信度质量很良好。
针对“项已删除的α系数”,PR4如果被删除,信度系数会有较为明显的上升,因此可考虑对此项进行修正或者删除处理。
针对“CITC值”,由于PR4对应的CITC值小于0.2,说明其与其余分析项的关系很弱,可以考虑进行删除处理。
参与意愿信度系数值为0.876,大于0.8,因而说明研究数据信度质量高。
针对“项已删除的α系数”,任意题项被删除后,信度系数并不会有明显的上升,因此说明题项不应该被删除处理。
★结构方程模型要点一、结构方程模型的模型构成1、变量观测变量:能够观测到的变量(路径图中以长方形表示)潜在变量:难以直接观测到的抽象概念,由观测变量推估出来的变量(路径图中以椭圆形表示)内生变量:模型总会受到任何一个其他变量影响的变量(因变量;路径图会受到任何一个其他变量以单箭头指涉的变量)外生变量:模型中不受任何其他变量影响但影响其他变量的变量(自变量;路径图中会指向任何一个其他变量,但不受任何变量以单箭头指涉的变量)中介变量:当内生变量同时做因变量和自变量时,表示该变量不仅被其他变量影响,还可能对其他变量产生影响。
内生潜在变量:潜变量作为内生变量内生观测变量:内生潜在变量的观测变量外生潜在变量:潜变量作为外生变量外生观测变量:外生潜在变量的观测变量中介潜变量:潜变量作为中介变量中介观测变量:中介潜在变量的观测变量2、参数(“未知”和“估计”)潜在变量自身:总体的平均数或方差变量之间关系:因素载荷,路径系数,协方差参数类型:自由参数、固定参数自由参数:参数大小必须通过统计程序加以估计固定参数:模型拟合过程中无须估计(1)为潜在变量设定的测量尺度①将潜在变量下的各观测变量的残差项方差设置为1② 将潜在变量下的各观测变量的因子负荷固定为1(2)为提高模型识别度人为设定限定参数:多样本间比较(半自由参数)3、路径图(1)含义:路径分析的最有用的一个工具,用图形形式表示变量之间的各种线性关系,包括直接的和间接的关系。
(2)常用记号:①矩形框表示观测变量②圆或椭圆表示潜在变量③小的圆或椭圆,或无任何框,表示方程或测量的误差单向箭头指向指标或观测变量,表示测量误差单向箭头指向因子或潜在变量,表示内生变量未能被外生潜在变量解释的部分,是方程的误差④单向箭头连接的两个变量表示假定有因果关系,箭头由原因(外生)变量指向结果(内生)变量⑤两个变量之间连线的两端都有箭头,表示它们之间互为因果⑥弧形双箭头表示假定两个变量之间没有结构关系,但有相关关系⑦变量之间没有任何连接线,表示假定它们之间没有直接联系(3)路径系数含义:路径分析模型的回归系数,用来衡量变量之间影响程度或变量的效应大小(标准化系数、非标准化系数)类型:①反映外生变量影响内生变量的路径系数②反映内生变量影响内生变量的路径系数路径系数的下标:第一部分所指向的结果变量第二部分表示原因变量(4)效应分解①直接效应:原因变量(外生或内生变量)对结果变量(内生变量)的直接影响,大小等于原因变量到结果变量的路径系数②间接效应:原因变量通过一个或多个中介变量对结果变量所产生的影响,大小为所有从原因变量出发,通过所有中介变量结束于结果变量的路径系数乘积③总效应:原因变量对结果变量的效应总和总效应=直接效应+间接效应4、矩阵方程式X = A ^+8(1)y = A H+8n=B n+r&+C(1)和(2)是测量模型方程,(3)是结构模型方程测量模型:反映潜在变量和观测变量之间的关系结构模型:反映潜在变量之间因果关系5、结构方程模型的八种矩阵概念二、模型整体评价三、模型修正1、参考标准模型所得结果是适当的;所得模型的实际意义、模型变量间的实际意义和所得参数与实际假设的关系是合理的;参考多个不同的整体拟合指数;2、修正原则①省俭原则两个模型拟合度差别不大的情况下,应取两个模型中较简单的模型;拟合度差别很大,应采取拟合更好的模型,暂不考虑模型的简洁性;最后采用的模型应是用较少参数但符合实际意义,且能较好拟合数据的模型。
●有的说每个观察变量最好有10个样本,有的说200到500之间比较好。
在SEM中,与
一般的研究方法相同,样本量越大越好,但是在SEM 中,绝对指标卡方容易受到样本量的影响,样本越大,越容易达到显著水平。
●在结构方程建模中,在观察变量到潜在变量的路径系数中,必须规定一条为1做标准求
的其他路径系数和潜变量的值。
潜变量之间就不用规定为1了。
●内衍变量和观察变量都要有一个误差量e。
●指标变量包括观察变量和误差变量
●如何让绘图区变宽:可以在view里面的interface properties中点击landscape
在进入模型检验之前,首先检验是否出现违反估计:
●负的误差方差存在
●标准化系数超过或太接近1(通常以0.95)
验证性因素分析
信度:建构信度
等于标准化因素负荷量和的平方/(标准化因素负荷量和的平方+(1-标准化因素负荷量的平方)的和)
收敛效度:平均方差抽取量:是指可以直显示被潜在构念所解释的变异量有多少是来自测量误差的,平均方差变异量越大,来自于测量误差越少,即因子对于观察数据的变异解释越大,
一般是平均方差抽取量要大于0.5,是一种收敛效度的指标。
等于标准化因素负荷量的平方之和/题目数目
验证性因素分析基本模型适配度检验摘要表:
●是否没有负的误差变异量e1 e2 e3
●因素负荷量(潜在变量与观察变量之间的标准化系数)是否介于0.5到0.95之间●Variances 是否没有很大的标准误(路径系数的标准误)
整体模型适配度检验摘要表:
绝对适配度指数
●卡方值,p大于0.05,说明数据本身的协方差矩阵和模型的协方差矩阵是匹配的。
●RMR值小于0.05,
●RMSEA小于0.08(小于0.05优良,若是小于0.08良好)
●GFI大于0.90,适配优度
●AGFI 大于0.90 (调整后的适配度)
增值适配度指数
●NFI大于0.90
●RFI 大于0.90
●IFI大于0.90
●TLI(也称为NNFI) 大于0.90
●CFI大于0.90
简约适配度指数:
●PGFI 大于0.50
●PNFI大于0.50
●PCFI大于0.50
●CN 大于200
●卡方自由度比小于2.0,或者小于3.0
●AIC理论模型值小于独立模型值且二者同时小于饱和模型值
●CAIC同AIC
验证性因素分析的内在质量参数表
●所估计的参数均达到显著水平w e
●所有项目的信度均达到0.50以上
●潜在变量的平均抽取变量大于0.50
●潜在变量的建构信度(组合信度、构念信度)大于0.60
●标准化残差的绝对值小于2.58(标准化残差:协方差矩阵的残差)修正指标:
●修正指标表中MI小于5.0
是否符合正态性检验,检验是否有异常值。
根据P2的指标删除变异的case,先删除一个,逐步检验删除后的P2值。
直接效果和间接效果
如何操作。