《单周期CPU设计》实验报告
- 格式:doc
- 大小:1.63 MB
- 文档页数:29

1个时钟周期 Clock 电子科技大学计算机科学与工程学院标 准 实 验 报 告(实验)课程名称: 计算机组成原理实验 电子科技大学教务处制表电 子 科 技 大 学 实 验 报 告学生姓名: 郫县尼克杨 学 号: 2014 指导教师:陈虹 实验地点: 主楼A2-411 实验时间:12周-15周一、 实验室名称:主楼A2-411二、 实验项目名称:单周期CPU 的设计与实现。
三、 实验学时:8学时四、 实验原理:(一) 概述单周期(Single Cycle )CPU 是指CPU 从取出1条指令到执行完该指令只需1个时钟周期。
一条指令的执行过程包括:取指令→分析指令→取操作数→执行指令→保存结果。
对于单周期CPU 来说,这些执行步骤均在一个时钟周期内完成。
(二) 单周期cpu 总体电路本实验所设计的单周期CPU 的总体电路结构如下。
(三) MIPS 指令格式化MIPS 指令系统结构有MIPS-32和MIPS-64两种。
本实验的MIPS 指令选用MIPS-32。
以下所说的MIPS 指令均指MIPS-32。
MIPS 的指令格式为32位。
下图给出MIPS 指令的3种格式。
本实验只选取了9条典型的MIPS 指令来描述CPU 逻辑电路的设计方法。
下图列出了本实验的所涉及到的9条MIPS 指令。
五、 实验目的1、掌握单周期CPU 的工作原理、实现方法及其组成部件的原理和设计方法,如控制器、运算器等。
?2、认识和掌握指令与CPU 的关系、指令的执行过程。
?3、熟练使用硬件描述语言Verilog 、EDA 工具软件进行软件设计与仿真,以培养学生的分析和设计CPU 的能力。
六、 实验内容(一)拟定本实验的指令系统,指令应包含R 型指令、I 型指令和J 型指令,指令数为9条。
(二)CPU 各功能模块的设计与实现。
(三)对设计的各个模块的仿真测试。
(四)整个CPU 的封装与测试。
七、 实验器材(设备、元器件):(一)安装了Xilinx ISE Design Suite 13.4的PC 机一台(二)FPGA 开发板:Anvyl Spartan6/XC6SLX45(三)计算机与FPGA 开发板通过JTAG (Joint Test Action Group )接口连接,其连接方式如图所示。

MIPS-CPU设计实验报告实验名称:32位单周期MIPS-CPU设计姓名学号:刘高斯11072205实验日期:2014年12月19日目录前言MIPS简介------------------------------------------------------------- 3 实验目的------------------------------------------------------------- 3第一部分VERILOG HDL 语言实现部分实验内容------------------------------------------------------------- 4 试验环境------------------------------------------------------------- 4 模块简介------------------------------------------------------------- 4 实验截图------------------------------------------------------------- 5 实验感想------------------------------------------------------------- 5 实验代码------------------------------------------------------------- 6第二部分LOGISIM 语言实现部分实验内容------------------------------------------------------------- 16 实验环境------------------------------------------------------------- 16模块设计------------------------------------------------------------- 16 试验感想------------------------------------------------------------- 23前言一、MIPS简介MIPS是世界上很流行的一种RISC处理器。
MIPS-CPU设计实验报告实验名称:32位单周期MIPS-CPU设计姓名学号:刘高斯11072205实验日期:2014年12月19日目录前言MIPS简介------------------------------------------------------------- 3 实验目的------------------------------------------------------------- 3第一部分VERILOG HDL 语言实现部分实验内容------------------------------------------------------------- 4 试验环境------------------------------------------------------------- 4 模块简介------------------------------------------------------------- 4 实验截图------------------------------------------------------------- 5 实验感想------------------------------------------------------------- 5 实验代码------------------------------------------------------------- 6第二部分LOGISIM 语言实现部分实验内容------------------------------------------------------------- 16 实验环境------------------------------------------------------------- 16模块设计------------------------------------------------------------- 16 试验感想------------------------------------------------------------- 23前言一、MIPS简介MIPS是世界上很流行的一种RISC处理器。

《计算机组成原理实验》实验报告(实验二)学院名称:专业(班级):学生姓名:学号:时间:2017 年11 月25 日成绩 :实验二:单周期CPU设计与实现一.实验目的(1) 掌握单周期CPU数据通路图的构成、原理及其设计方法;(2) 掌握单周期CPU的实现方法,代码实现方法;(3) 认识和掌握指令与CPU的关系;(4) 掌握测试单周期CPU的方法;(5) 掌握单周期CPU的实现方法。
二.实验内容设计一个单周期的MIPSCPU,使其能实现下列指令:==> 算术运算指令说明:以助记符表示,是汇编指令;以代码表示,是机器指令功能:rd←rs + rt。
reserved为预留部分,即未用,一般填“0”。
符号扩展再参加“加”运算。
(3)sub rd , rs , rt功能:rd←rs - rt==> 逻辑运算指令(4)ori rt , rs ,immediate功能:rt←rs | (zero-extend)immediate;immediate做“0”扩展再参加“或”运算。
(5)and rd , rs , rt功能:rd←rs & rt;逻辑与运算。
功能:rd←rs | rt;逻辑或运算。
==>移位指令==>比较指令功能:if (rs<rt) rd =1 else rd=0, 具体请看表2 ALU运算功能表,带符号==> 存储器读/写指令(9)sw rt ,immediate(rs) 写存储器功能:memory[rs+ (sign-extend)immediate]←rt;immediate符号扩展再相加。
即将rt寄存器的内容保存到rs寄存器内容和立即数符号扩展后的数相加作为地址的内存单元中。
(10) lw rt , immediate(rs) 读存储器功能:rt ← memory[rs + (sign-extend)immediate];immediate符号扩展再相加。

单周期CPU设计实验报告一、引言计算机是现代信息社会必不可少的工具,而CPU作为计算机的核心部件,承担着执行指令、进行运算和控制系统资源的任务。
随着科技的进步和计算能力的需求,CPU的设计也趋于复杂和高效。
本次实验旨在设计一种单周期CPU,探究其设计原理和实现过程,并通过实验验证其正确性和性能。
二、理论基础1.单周期CPU概述单周期CPU即每个时钟周期内只完成一条指令的处理,它包括指令取址阶段(IF)、指令译码阶段(ID)、执行阶段(EX)、访存阶段(MEM)和写回阶段(WB)等多个阶段。
每条指令都顺序地在这些阶段中执行,而不同的指令所需的时钟周期可能不同。
2.控制信号单周期CPU需要根据不同的指令类型产生不同的控制信号来控制各个阶段的工作。
常见的控制信号包括时钟信号(clk)、使能信号(En)、写使能信号(WE)和数据选择信号(MUX)等。
这些信号的产生需要通过译码器、控制逻辑电路和时序逻辑电路等来实现。
三、实验设计本次实验采用的单周期CPU包括以下五个阶段:指令取址阶段、指令译码阶段、执行阶段、访存阶段和写回阶段。
每个阶段的具体操作如下:1.指令取址阶段(IF)在IF阶段,通过计数器实现程序计数器(PC)的自增功能,并从存储器中读取指令存储地址所对应的指令码。
同时,设置PC使能信号,使其可以更新到下一个地址。
2.指令译码阶段(ID)在ID阶段,对从存储器中读取的指令码进行解码,确定指令的操作类型和操作数。
同时,根据操作类型产生相应的控制信号,如使能信号、写使能信号和数据选择信号等。
3.执行阶段(EX)在EX阶段,根据ID阶段产生的控制信号和操作数,进行相应的算术逻辑运算。
这里可以包括加法器、乘法器、逻辑运算器等。
4.访存阶段(MEM)在MEM阶段,根据EX阶段的结果,进行数据存储器的读写操作。
同时,将读取的数据传递给下一个阶段。
5.写回阶段(WB)在WB阶段,根据MEM阶段的结果,将数据传递给寄存器文件,并将其写入指定的寄存器。

单周期CPU设计总结单周期CPU⼀、设计思路1、CPU的意义CPU是计算机的核⼼,因为它是计算机指令的处理单元。
计算机体系结构包含两个⽅⾯,⼀个⽅⾯是指令集,⼀个⽅⾯是硬件实现。
指令集是计算机被定义拥有的执⾏指令,计算机通过⽀持指令集的运⾏,来完成计算⼯作并为程序员编程服务。
硬件实现则是具体的硬件去实现指令集,这个硬件实现的核⼼就是CPU的设计。
这⾥写的CPU的设计是32位机器的CPU,指令和数据均为32位。
⽀持指令为简化mips指令集。
2、CPU的设计CPU的设计包含数据通路的设计和控制器的设计。
数据通路是执⾏指令必须的硬件(ALU、IM、DM、GRF等),控制器则是根据指令产⽣相应控制信号,来控制相应硬件以⽀持多条指令。
数据通路设计CPU的功能是⽀持指令集,因此硬件设计是为了执⾏指令。
设计CPU的结构的⽅法:先选择⼀条需要经过最多硬件的指令,来为它构建数据通路。
再依据其他指令在已有数据通路上添加硬件或线路,直到数据通路⽀持所有指令。
控制器设计在已有的数据通路基础上,针对每⼀条指令,列出其所需要的控制信号,每⼀组控制信号对应⼀种指令的全部执⾏。
将指令相应字段和部分计算结果作为控制器的输⼊,控制信号作为输出,依据上述映射关系(真值表)设计控制器。
⼆、实际操作0、设计说明CPU架构的设计是没有很多约束的,基本要求就是能够⽀持指令集,基于不同的考量可以有不同的设计。
举例来说:对于beq指令是否跳转的判断,可以借⽤ALU的减法计算,也可以直接增设CMP⽐较器得出,两种⽅式都可以,因为功能正确。
为了提⾼吞吐量,或者为了节省成本,会选择⼀些特别的设计,这⼀点在流⽔线CPU 的设计上可以明显地看出。
CPU具体设计的⽅法是我下⾯进⾏的⼏步:列出所需指令,写出功能模块,连接模块,构造控制器,全部连接起来。
这些表格对最终代码实现⼗分重要,因为代码量较⼤,先从表格检查起,再依据表格写码可以减少bug。
1、⽀持指令列出⽀持指令并将其分类:str ld cal_r cal_i lui b_type j jr jal jalr shamtsw lw addu ori beq sllsubu slti sraslt addiu srlsllvsravsrlv2、功能模块先按照lw指令列出所需功能模块(lw经过模块最多),再依次检查现有模块是否⽀持其余指令,若不能⽀持,则添加相应模块。
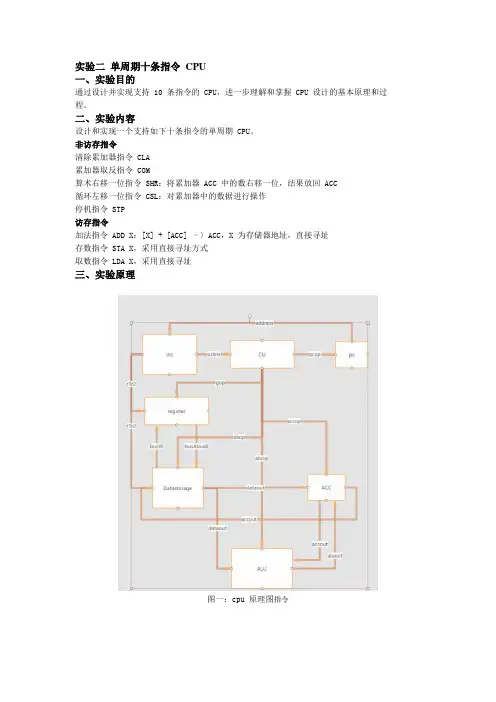
实验二单周期十条指令CPU一、实验目的通过设计并实现支持 10 条指令的 CPU,进一步理解和掌握 CPU 设计的基本原理和过程。
二、实验内容设计和实现一个支持如下十条指令的单周期 CPU。
非访存指令清除累加器指令 CLA累加器取反指令 COM算术右移一位指令 SHR:将累加器 ACC 中的数右移一位,结果放回 ACC循环左移一位指令 CSL:对累加器中的数据进行操作停机指令 STP访存指令加法指令 ADD X:[X] + [ACC] –〉ACC,X 为存储器地址,直接寻址存数指令 STA X,采用直接寻址方式取数指令 LDA X,采用直接寻址三、实验原理图一:cpu 原理图指令四、实验步骤4.1 CPU 各模块Verilog 实现1) PC 模块表 4.1 PC 功能描述Verilog 关键代码:2) 指令存储器模块表 4.2 指令存储器模块功能描述Verilog 关键代码:3) 寄存器堆表 4.3 寄存器堆模块功能描述Verilog 关键代码:4)ALU表 4.4 ALU 模块功能描述Verilog 关键代码:5) 控制单元表 4.5 控制单元模块功能描述Verilog 关键代码:4.2 CPU 顶层文件封装实现通过根据图 2 将以上定义的模块进行连接、封装就得到了目标 CPU,该 CPU 的输入为系统时钟信号 clk 和重置信号 reset,输出 pc 是为了调试方便。
Verilog 关键代码:4.3 CPU 模拟仿真为了仿真验证所实现的 CPU,需要定义测试文件并在测试文件中对指令存储器和寄存器堆中的相应寄存器的值进行初始化,并通过仿真波形图查看是否指令得到了正确执行。
1)TestBench 关键代码指令寄存器以 PC 给出的值为地址给出指令,因此再测试文件中只需要完成 PC 的控制就可以了,clk 和 rst 定义为 1 后再延迟 30ns 是为了对 PC 进行初始化。
2)ModelSim 仿真及分析由于十条测试指令都没有用到寄存器堆,所以均无数据最初的PC 给出的是h00 是为了启动。

实验六—单周期CPU设计实验报告姓名:孙铖学号:3080101552 专业:软件工程课程名称:计算机组成实验同组学生姓名:实验时间:2010-11-20 实验地点:曹西301 指导老师:蒋方炎一、实验目的和要求1.理解单周期CPU的原理与实现2.通过对单周期CPU运行状况的观察,获得更深入的理解二、实验内容和原理2.1 内容1.实现单周期CPU,能运行常用的MIPS指令2.编程验证该单周期CPU运行结果的正确性2.2 原理图表1 CPU内部结构1.本实验将实现单时钟数据通道的五条(种)指令:R型、LW、SW、BEQ、J2.单周期CPU的主要部件有:●CPU控制器●ALU及控制器●寄存器文件●指令存储器●数据存储器●调试模块以上各模块基本都在前面实验中涉及过,都将在实验步骤详细解释2.3模块结构组织图图表2 工程中各文件各模块的结构组织三、主要仪器设备1.Spartan-3开发板1套2.装有ISE的PC机1台四、操作方法与实验步骤1.创建工程cpu.ise2.工程所需的模块文件(.v文件):·定义头文件`define ALU_AND 3'b000`define ALU_OR 3'b001`define ALU_ADD 3'b010`define ALU_SUB 3'b110`define ALU_SLT 3'b111`define INSTR_LW 6'b100011`define INSTR_SW 6'b101011`define INSTR_BEQ 6'b000100`define INSTR_RTYPE 6'b000000`define INSTR_JUMP 6'b000010`define RTYPE_ADD 6'b100000`define RTYPE_SUB 6'b100010`define RTYPE_SLT 6'b101010`define RTYPE_AND 6'b100100`define RTYPE_OR 6'b100101`define RTYPE_XOR 6'b100110`define RTYPE_NOR 6'b100111`define RTYPE_ADDU 6'b100001`define RTYPE_SLTU 6'b101011misc.v文件(包含一些小组件):二选一数据选择器module single_mux(A, B, Ctrl, S);parameter N; //参数N,指定二选一选择器的位数input wire[N-1:0] A, B;output wire[N-1:0] S;assign S = (Ctrl == 1’b0) ? A : B;endmodulePC+4module single_pc_plus_4(i_pc, o_pc); //由于采用32 位存储器,每条指令占一个地址input wire[8:0] i_pc;output wire[8:0] o_pc;assign o_pc[8:0] = i_pc[8:0] + 1;endmodulePCmodule single_pc(clk, rst, i_pc, o_pc);parameter N;intput wire clk, rst;input wire[N-1:0] i_pc;output wire[N-1:0] o_pc;reg[N-1:0] t_pc;assigno_pc = rst ? {N{1’b1}}:t_pc;always @(posedgeclk)t_pc<= i_pc;endmodule符号位扩展module single_signext(i_16, o_32);input wire[15:0] i_16;output reg [31:0] o_32;always @(i_16)o_32 <= {{16{i_16[15]}}, i_16[15:0]};endmodule32位加法module single_signext(i_16, o_32);input wire[15:0] i_16;output reg [31:0] o_32;always @(i_16)o_32 <= {{16{i_16[15]}}, i_16[15:0]};endmoduleCPU控制器文件single_ctrl.v文件single_ctrlmodule single_ctl( rst,i_instr,o_regdst,o_jump,o_branch,o_memread, o_memtoreg,o_aluop, o_memwrite,o_alusrc, o_regwrite);input [5:0] i_instr;input rst;output [1:0] o_aluop;output o_regdst;output o_branch;output o_jump;output o_memread;output o_memtoreg;output o_memwrite;output o_alusrc;output o_regwrite;assign o_regdst = (~i_instr[5] & ~i_instr[4] & ~i_instr[3] & ~i_instr[2] & ~i_instr[1] & ~i_instr[0]) & ~rst;assign o_branch = (~i_instr[5] & ~i_instr[4] & ~i_instr[3] &i_instr[2] & ~i_instr[1] & ~i_instr[0]) & ~rst;assign o_jump = (~i_instr[5] & ~i_instr[4] & ~i_instr[3] & ~i_instr[2] &i_instr[1] & ~i_instr[0]) & ~rst;assign o_memread = (i_instr[5] & ~i_instr[4] & ~i_instr[3] & ~i_instr[2] &i_instr[1] &i_instr[0]) & ~rst;assign o_memtoreg = (i_instr[5] & ~i_instr[4] & ~i_instr[3] & ~i_instr[2] &i_instr[1] &i_instr[0]) & ~rst;assign o_aluop[1] = (~i_instr[5] & ~i_instr[4] & ~i_instr[3] & ~i_instr[2] &~i_instr[1] & ~i_instr[0]) & ~rst;assign o_aluop[0] = (~i_instr[5] & ~i_instr[4] & ~i_instr[3] &i_instr[2] & ~i_instr[1] & ~i_instr[0]) & ~rst;assign o_memwrite = (i_instr[5] & ~i_instr[4] &i_instr[3] & ~i_instr[2] &i_instr[1] &i_instr[0]) & ~rst;assign o_alusrc = (i_instr[5] & ~i_instr[4] & ~i_instr[2] &i_instr[1] &i_instr[0]) & ~rst;assign o_regwrite = (~i_instr[4] & ~i_instr[3] & ~i_instr[2]) & ~rst;endmodulealu及alu控制器文件single_alu.vsingle_alumodule single_alu(i_r,i_s,i_aluc,o_zf,o_alu);input [31:0] i_r; //i_r: r inputinput [31:0] i_s; //i_s: s inputinput [2:0] i_aluc; //i_aluc: ctrl inputoutput o_zf; //o_zf: zero flag outputoutput [31:0] o_alu; //o_alu: alu result outputrego_zf;reg [31:0] o_alu;always @(i_aluc or i_r or i_s) begincase (i_aluc)`ALU_AND: begino_zf = 0;o_alu = i_r&i_s;end`ALU_OR: begino_zf = 0;o_alu = i_r | i_s;end`ALU_ADD: begino_zf = 0;o_alu = i_r + i_s;end`ALU_SUB: begino_alu = i_r - i_s;o_zf = (o_alu == 0);end`ALU_SLT: begino_zf = 0;if (i_s<i_r)o_alu = 1;elseo_alu = 0;enddefault: begino_alu = 0;o_zf = 0;endendcaseendendmodulesingle_alu_ctrlmodule single_aluc(aluop, func, aluc);input [1:0] aluop;input [5:0] func;output [2:0] aluc;reg [2:0] aluc;always @(aluop or func) begincase (aluop)2'b00: beginaluc = `ALU_ADD; //lw | swend2'b01: beginaluc = `ALU_SUB; //beqend2'b10: begincase (func)`RTYPE_ADD: aluc = `ALU_ADD;`RTYPE_SUB: aluc = `ALU_SUB;`RTYPE_SLT: aluc = `ALU_SLT;`RTYPE_AND: aluc = `ALU_AND;`RTYPE_OR: aluc = `ALU_OR;default: aluc = 3'b000;endcaseenddefault: beginaluc=3'b000;endendcaseendendmodule寄存器组文件single_gpr.vmodule single_gpr(rst,//resetclk,//clocki_adr1,//register index 1i_adr2,//register index 2i_adr3,//register index 3i_wreg,//register to writei_wdata,//data to writei_wen,//write enableo_op1,//read data1, outo_op2,//read data2, outo_op3//read data3, out);input clk;input rst;input [4:0] i_adr1;input [4:0] i_adr2;input [4:0] i_adr3;input [31:0] i_wdata;input [4:0] i_wreg;input i_wen;output [31:0] o_op1;output [31:0] o_op2;output [31:0] o_op3;reg [31:0] mem[31:0];assign o_op1 = mem[i_adr1];assign o_op2 = mem[i_adr2];assign o_op3 = mem[i_adr3];always @(posedgeclk or posedgerst) beginif (rst == 1) beginmem[0] <= 32'h00000000;endelse if (i_wen) beginmem[i_wreg] <= (i_wreg == 5'b00000) ? 32'h00000000 : i_wdata;endendendmoduledebug显示模块debug_out.vmodule debug_out(disp_clk_cnt,i_clk_cnt,i_reg_dat,i_pc,i_disp_sel, o_seg, o_sel);input [1:0] disp_clk_cnt; //disp_clk_cnt: decides which digit to displayinput [15:0] i_clk_cnt; //i_clk_cnt: clock number to displayinput [31:0] i_reg_dat; //i_reg_dat: register to displayinput [8:0] i_pc; //i_pc: pc to displayinput [5:0] i_disp_sel; //i_disp_sel: selects which data to displayoutput [7:0] o_seg; //o_seg digitsoutput [3:0]o_sel; //o_sel: which digit?single_ledsx_single_leds(disp_clk_cnt,(i_disp_sel == 6'b100001) ? {{5'b00000},i_pc} : ((i_disp_sel == 6'b100010)? i_clk_cnt : i_reg_dat[15:0]),o_seg,o_sel); endmodule单时钟数码显示模块single_leds.vmodule single_leds(disp_clk_cnt,i_number,o_seg,o_sel);input [1:0] disp_clk_cnt;input [15:0] i_number;output [7:0] o_seg;output [3:0] o_sel;reg [7:0] o_seg;reg [3:0] o_sel;reg [3:0] t_num;always @(disp_clk_cnt or i_number or t_num) begincase (disp_clk_cnt)2'b00: begino_sel<=4'b0111;t_num<=i_number[15:12];end2'b01: begino_sel<=4'b1011;t_num<=i_number[11:8];end2'b10: begino_sel<=4'b1101;t_num<=i_number[7:4];end2'b11: begino_sel<=4'b1110;t_num<=i_number[3:0];enddefault:;endcasecase (t_num)4'b0000:o_seg<=8'b11000000;4'b0001:o_seg<=8'b11111001;4'b0010:o_seg<=8'b10100100;4'b0011:o_seg<=8'b10110000;4'b0100:o_seg<=8'b10011001;4'b0101:o_seg<=8'b10010010;4'b0110:o_seg<=8'b10000010;4'b0111:o_seg<=8'b11111000;4'b1000:o_seg<=8'b10000000;4'b1001:o_seg<=8'b10010000;4'b1010:o_seg<=8'b10001000;4'b1011:o_seg<=8'b10000011;4'b1100:o_seg<=8'b11000110;4'b1101:o_seg<=8'b10100001;4'b1110:o_seg<=8'b10000110;4'b1111:o_seg<=8'b10001110;default:;endcaseendendmoduletop模块top.vmodule top(clk, rst, disp_sel, disp_clk, o_seg, o_sel, o_instr);input rst;input clk;input [5:0] disp_sel;input disp_clk;output [7:0]o_seg;output [3:0] o_sel;output [5:0] o_instr;wire [8:0] pc_out;wire [8:0] pc_in;wire [8:0] pc_plus_4;wire [4:0] reg3_out;wire [31:0] wdata_out;wire [31:0] instr_out;wire regwrite;wire alusrc;wire [1:0] aluop;wire memwrite;wire memtoreg;wire memread;wire branch;wire jump;wire regdst;wire [31:0] reg1_dat;wire [31:0] reg2_dat;wire [2:0] alu_ctrl;wire [31:0] signext_out;wire [31:0] mux_to_alu;wire [31:0] alu_out;wire alu_zero;wire [31:0] mem_dat_out;wire and_out;wire [31:0] branch_addr_out;wire [31:0] branch_mux_out;wire [31:0] gpr_disp_out;wire [4:0] tmp_sel;reg [15:0] clk_cnt;reg [15:0] tmp_cnt;reg [1:0] disp_clk_cnt;always @(posedgeclk or posedgerst) beginif (rst == 1)clk_cnt = 16'h0000;else beginclk_cnt = clk_cnt + 1;endendalways @(posedgedisp_clk or posedgerst) beginif (rst==1) begindisp_clk_cnt=2'b00;tmp_cnt=0;endelse begintmp_cnt=tmp_cnt+1;if (tmp_cnt==16'h0000)disp_clk_cnt=disp_clk_cnt+1;endendassign o_instr = instr_out[31:26];assign tmp_sel[4:0] = disp_sel[4:0];//assign pc_in = jump ?instr_out[8:0] : branch_mux_out[8:0];debug_outx_debug_out(disp_clk_cnt,clk_cnt,gpr_disp_out,pc_out,disp_sel,o_seg,o_sel);single_pcx_single_pc(clk,rst,pc_in,pc_out);c_instr_memx_c_instr_mem(pc_out,disp_clk,instr_out);single_pc_plus4 x_single_pc_plus4(pc_out,pc_plus_4);single_mux5 x_single_mux5(instr_out[20:16],instr_out[15:11],regdst,reg3_out);single_gprx_single_gpr(rst,clk,instr_out[25:21],instr_out[20:16],tmp_sel,reg3_out,wdata_out,regwrite,reg1_dat,reg2_dat,gpr_disp_out);single_alucx_single_aluc(aluop,instr_out[5:0],alu_ctrl);single_signextx_single_signext(instr_out[15:0],signext_out);single_mux32 x_single_mux32(reg2_dat,signext_out,alusrc,mux_to_alu);single_alux_single_alu(reg1_dat,mux_to_alu,alu_ctrl,alu_zero,alu_out);c_dat_memx_c_dat_mem(alu_out[8:0],disp_clk,reg2_dat,mem_dat_out,memwrite);single_mux32 x_single_mux32_2(alu_out,mem_dat_out,memtoreg,wdata_out);assign and_out = alu_zero& branch;single_addx_single_add(signext_out,{{23'b00000000000000000000000},pc_plus_4},branch_addr_out);single_mux32 x_single_mux32_3({{23'b00000000000000000000000},pc_plus_4},branch_addr_out,and_out,branch_mux_out);single_mux9 x_single_mux11(branch_mux_out[8:0], instr_out[8:0], jump, pc_in);single_ctlx_single_ctl(rst,instr_out[31:26],regdst,jump,branch,memread,memtoreg,aluop,memwrite,alusrc,regwrite);endmodule3.生成Memeorydat_block_dat_block.coe文件(文本文件)MEMORY_INITIALIZATION_RADIX=2;MEMORY_INITIALIZATION_VECTOR=10001100000000010000000000000000,10001100000000100000000000000100,10001100000001000000000000000001,00000000001000100001100000100000,00000000011000100001000000100000,00000000011000010001100000100000,00010000011001000000000000000001,00001000000000000000000000000100,10101100000000100000000000000010,00000000001001000011000000101010,00000000100000010011000000101010,00000000000000000000000000000000,……instr_block_instr_block.coeMEMORY_INITIALIZATION_RADIX=2;MEMORY_INITIALIZATION_VECTOR=10001100000000010000000000000000,10001100000000100000000000000100,10001100000001000000000000000001,00000000001000100001100000100000,00000000011000100001000000100000,00000000011000010001100000100000,00010000011001000000000000000001,00001000000000000000000000000100,10101100000000100000000000000010,00000000001001000011000000101010,00000000100000010011000000101010,00000000000000000000000000000000,00000000000000000000000000000000,00000000000000000000000000000000,……生成.xco文件图表3 生成xco Memory 4.数据存储单元与指令存储单元数据存储单元c_dat_mem.vmodule c_dat_mem(addr,clk,din,dout,we);input [8 : 0] addr;input clk;input [31 : 0] din;output [31 : 0] dout;input we;BLKMEMSP_V6_2 #(.c_addr_width(9),.c_default_data("0"),.c_depth(512),.c_enable_rlocs(0),.c_has_default_data(0),.c_has_din(1),.c_has_en(0),.c_has_limit_data_pitch(0),.c_has_nd(0),.c_has_rdy(0),.c_has_rfd(0),.c_has_sinit(0),.c_has_we(1),.c_limit_data_pitch(18),.c_mem_init_file("c_dat_mem.mif"),.c_pipe_stages(0),.c_reg_inputs(0),.c_sinit_value("0"),.c_width(32),.c_write_mode(0),.c_ybottom_addr("0"),.c_yclk_is_rising(1),.c_yen_is_high(1),.c_yhierarchy("hierarchy1"),.c_ymake_bmm(0),.c_yprimitive_type("16kx1"),.c_ysinit_is_high(1),.c_ytop_addr("1024"),.c_yuse_single_primitive(0),.c_ywe_is_high(1),.c_yydisable_warnings(1))inst (.ADDR(addr),.CLK(clk),.DIN(din),.DOUT(dout),.WE(we),.EN(),.ND(),.RFD(),.RDY(),.SINIT());endmodule指令存储单元c_instr_mem.vmodule c_instr_mem(addr,clk,dout);input [8 : 0] addr;input clk;output [31 : 0] dout;BLKMEMSP_V6_2 #(.c_addr_width(9),.c_default_data("0"),.c_depth(512),.c_enable_rlocs(0),.c_has_default_data(0),.c_has_din(0),.c_has_en(0),.c_has_limit_data_pitch(0),.c_has_nd(0),.c_has_rdy(0),.c_has_rfd(0),.c_has_sinit(0),.c_has_we(0),.c_limit_data_pitch(18),.c_mem_init_file("c_instr_mem.mif"),.c_pipe_stages(0),.c_reg_inputs(0),.c_sinit_value("0"),.c_width(32),.c_write_mode(0),.c_ybottom_addr("0"),.c_yclk_is_rising(1),.c_yen_is_high(1),.c_yhierarchy("hierarchy1"),.c_ymake_bmm(0),.c_yprimitive_type("16kx1"),.c_ysinit_is_high(1),.c_ytop_addr("1024"),.c_yuse_single_primitive(0),.c_ywe_is_high(1),.c_yydisable_warnings(1))inst (.ADDR(addr),.CLK(clk),.DOUT(dout),.DIN(),.EN(),.ND(),.RFD(),.RDY(),.SINIT(),.WE());endmodule5.创建UCF引脚约束文件top.ucfNET "o_seg<0>" LOC = "E14" ;NET "o_seg<1>" LOC = "G13" ;NET "o_seg<2>" LOC = "N15" ;NET "o_seg<3>" LOC = "P15" ;NET "o_seg<4>" LOC = "R16" ;NET "o_seg<5>" LOC = "F13" ;NET "o_seg<6>" LOC = "N16" ;NET "o_seg<7>" LOC = "P16" ;NET "o_sel<0>" LOC = "D14" ;NET "o_sel<1>" LOC = "G14" ;NET "o_sel<2>" LOC = "F14" ;NET "o_sel<3>" LOC = "E13" ;NET "disp_clk" LOC = "T9" ;NET "o_instr[0]" LOC = "K12";NET "o_instr[1]" LOC = "P14";NET "o_instr[2]" LOC = "L12";NET "o_instr[3]" LOC = "N14";NET "o_instr[4]" LOC = "P13";NET "o_instr[5]" LOC = "N12";NET "rst" LOC = "L14";NET "clk" LOC = "L13";NET "disp_sel[0]" LOC = "F12";NET "disp_sel[1]" LOC = "G12";NET "disp_sel[2]" LOC = "H14";NET "disp_sel[3]" LOC = "H13";NET "disp_sel[4]" LOC = "J14";NET "disp_sel[5]" LOC = "J13";6.生成cpu.bit文件,下载到spartan3实验板上,进行测试7.最终工程文件结构图五、实验结果与分析1.先按复位键,按指令键三次,查看各寄存器内容图表4 load之后各个寄存器结果2.继续按键,查看状态PC(10_xxxxxx)显示数为4,5,6,7,4,5,6,7,4,……分析:由于第八条指令为j 4,无条件转移到4,所以在$3未到达$1的值(101)时,就会跳到第四条指令。

MIPS单周期CPU实验报告一、实验目的本实验旨在设计一个基于MIPS指令集架构的单周期CPU,具体包括CPU的指令集设计、流水线的划分与控制信号设计等。
通过本实验,可以深入理解计算机组成原理中的CPU设计原理,加深对计算机体系结构的理解。
二、实验原理MIPS(Microprocessor without Interlocked Pipeline Stages)是一种精简指令集(RISC)架构的处理器设计,大大简化了指令系统的复杂性,有利于提高执行效率。
MIPS指令集由R、I、J三种格式的指令组成,主要包括算术逻辑运算指令、存储器访问指令、分支跳转指令等。
在单周期CPU设计中,每个指令的执行时间相同,每个时钟周期只执行一个指令。
单周期CPU的主要部件包括指令内存(IM)、数据存储器(DM)、寄存器文件(RF)、运算单元(ALU)、控制器等。
指令执行过程主要分为取指、译码、执行、访存、写回等阶段。
三、实验步骤1.设计CPU指令集:根据MIPS指令集的格式和功能,设计符合需求的指令集,包括算术逻辑运算指令、存储器访问指令、分支跳转指令等。
2.划分CPU流水线:将CPU的执行过程划分为取指、译码、执行、访存、写回等阶段,确定每个阶段的功能和控制信号。
3.设计控制器:根据CPU的流水线划分和指令集设计,设计控制器实现各个阶段的控制信号生成和时序控制。
4.集成测试:进行集成测试,验证CPU的指令执行功能和正确性,调试并优化设计。
5.性能评估:通过性能评估指标,如CPI(平均时钟周期数)、吞吐量等,评估CPU的性能优劣,进一步优化设计。
四、实验结果在实验中,成功设计了一个基于MIPS指令集架构的单周期CPU。
通过集成测试,验证了CPU的指令执行功能和正确性,实现了取指、译码、执行、访存、写回等阶段的正常工作。
同时,通过性能评估指标的测量,得到了CPU的性能参数,如CPI、吞吐量等。
通过性能评估,发现了CPU的性能瓶颈,并进行了相应的优化,提高了CPU的性能表现。

《计算机组成原理实验》实验报告(实验三)学院名称:数据科学与计算机学院专业(班级):学生姓名:学号:时间:2019 年11 月8 日成绩:实验三:单周期CPU设计与实现一.实验目的(1) 掌握单周期CPU数据通路图的构成、原理及其设计方法;(2) 掌握单周期CPU的实现方法,代码实现方法;(3) 认识和掌握指令与CPU的关系;(4) 掌握测试单周期CPU的方法。
二.实验内容设计一个单周期CPU,该CPU至少能实现以下指令功能操作。
指令与格式如下:==> 算术运算指令加“加”运算。
加“加”运算。
==> 逻辑运算指令加“与”运算。
功能:GPR[rt] ←GPR[rs] or zero_extend(immediate)。
==>移位指令==>比较指令==> 存储器读/写指令==> 分支指令else pc ←pc + 4特别说明:offset是从PC+4地址开始和转移到的指令之间指令条数。
offset符号扩展之后左移2位再相加。
为什么要左移2位?由于跳转到的指令地址肯定是4的倍数(每条指令占4个字节),最低两位是“00”,因此将offset放进指令码中的时候,是右移了2位的,也就是以上说的“指令之间指令条数”。
else pc ←pc + 4(16)bltz rs, offsetelse pc ←pc + 4。
==>跳转指令(17)j addr说明:由于MIPS32的指令代码长度占4个字节,所以指令地址二进制数最低2位均为0,将指令地址放进指令代码中时,可省掉!这样,除了最高6位操作码外,还有26位可用于存放地址,事实上,可存放28位地址,剩下最高4位由pc+4最高4位拼接上。
==> 停机指令功能:停机;不改变PC的值,PC保持不变。
三.实验原理单周期CPU指的是一条指令的执行在一个时钟周期内完成,然后开始下一条指令的执行,即一条指令用一个时钟周期完成。
电平从低到高变化的瞬间称为时钟上升沿,两个相邻时钟上升沿之间的时间间隔称为一个时钟周期。

《计算机组成原理实验》实验报告(实验二)学院名称:专业(班级):学生姓名:学号:时间:2017 年11 月25 日成绩:实验二:单周期CPU设计与实现一.实验目的(1) 掌握单周期CPU数据通路图的构成、原理及其设计方法;(2) 掌握单周期CPU的实现方法,代码实现方法;(3) 认识和掌握指令与CPU的关系;(4) 掌握测试单周期CPU的方法;(5) 掌握单周期CPU的实现方法。
二.实验内容设计一个单周期的MIPSCPU,使其能实现下列指令:==> 算术运算指令(1)add rd , rs, rt(说明:以助记符表示,是汇编指令;以代码表示,是机器指令)功能:rd←rs + rt。
reserved为预留部分,即未用,一般填“0”。
(2)addi rt , rs ,immediate功能:rt←rs + (sign-extend)immediate;immediate符号扩展再参加“加”运算。
(3)sub rd , rs , rt功能:rd←rs - rt==> 逻辑运算指令(4)ori rt , rs ,immediate功能:rt←rs | (zero-extend)immediate;immediate做“0”扩展再参加“或”运算。
(5)and rd , rs , rt功能:rd←rs & rt;逻辑与运算。
(6)or rd , rs , rt功能:rd←rs | rt;逻辑或运算。
==>移位指令(7)sll rd, rt,sa功能:rd<-rt<<(zero-extend)sa,左移sa位,(zero-extend)sa==>比较指令(8)slt rd, rs, rt 带符号数功能:if (rs<rt) rd =1 else rd=0, 具体请看表2 ALU运算功能表,带符号==> 存储器读/写指令(9)sw rt ,immediate(rs) 写存储器功能:memory[rs+ (sign-extend)immediate]←rt;immediate符号扩展再相加。
信息科学与工程学院课程设计报告课程名称:计算机组成原理与结构题目:单周期CPU逻辑设计年级/专业: XXXXXXXXXXXXXXX X 学生姓名:王侠侠、李怀民学号: XXXXXXXXXXXXXXXXXXX指导老师: XXXX开始时间:2016年9月15日结束时间:2016年11月15日摘要一、设计目的与目标1.1 设计目的1.2 设计目标二、课程设计器材2.1 硬件平台2.2 软件平台三、CPU逻辑设计总体方案3.1 指令模块3.2 部件模块四、模块详细设计4.1 指令设计模块4.2 部件设计模块五、实验数据5.1 初始数据5.2 指令数据六、结论和体会七、参考文献本CPU设计实验以Quartus II 9.0为软件设计平台,以Cyclone 采III型号EP3C16F484C6为FPGA实测板。
此CPU设计采用模块化设计方案,首先设计指令格式模块,此模块决定CPU各个部件的接口数据容量及数量,再对CPU各个部件独立设计实现,主要涉及的部件有:寄存器组、控制器、存储器、PC计数器、数据选择器、ALU单元以及扩展单元。
分部件的设计通过软件平台模拟仿真各部件的功能,在确保各部件功能正确的情况下,将所有部件模块整合在一起实现16位指令的CPU功能。
再按照指令格式设计的要求,设计出一套能完整运行的指令,加载到指令存储器中,最终通过在FPGA实测板上实现了加2减1的循环运算效果,若要实现其他效果,也可更改指令存储器或数据存储器的数据而不需要对内部部件进行更改元件。
关键词:CPU设计、16位指令格式、模块化设计、Quartus软件、CPU各部件一、设计目的与目标1.1设计目的1)了解Quartus II软件的使用,学习软件环境下设计CPU的基本过程;2)在Quartus II平台上完成各个单元的设计,加深对每个单元(控制器、寄存器、存储器等)工作原理的理解;3)对各个单元组合而成的CPU进行指令测试,配合使用模拟仿真,了解指令和数据在各个单元中的传输过程及方向。
■=・NINGBO UNIVERSITY短学期综合实验报告实验名称:单周期CPU设计院系:信息科学与工程学院专业:计算机科学与技术组员: XXXXXXXXXXXXXXXXXXXXXX指导老师:XXXXXXX _____________二o—一年七月八日摘要中央处理器(CPU)是计算机取指令和执行指令的部件,它是由算术逻辑单元(ALU)、寄存器和控制器组成,简称处理器(或CPU), CPU 是计算机系统的核心部件,在各类信息终端中得到了广泛的应用。
处理器的设计及制造技术也是计算机技术的核心之一。
CPU设计的第一步应当根据指令系统来建立数据路径,再定义各个部件的控制信号,确定时钟周期,完成控制器的设计。
然后建立数据路径,进而可以进行数字设计、电路设计,最后完成物理实现。
而在本次试验中,我们研究的重点是数据路径的建立和控制器的实现。
一个机器的性能由三个关键因素决定:指令数、时钟周期,以及执行每条指令所需的时钟周期数(CPI)。
然而不论是时钟周期,还是每条指令所需的时钟周期数目,都是由处理器的实现情况决定的。
在本次试验中,我们构造了单周期的数据路径和组合逻辑实现的控制器。
本次试验屮,我们运用Quartus II 8.0软件设计出了一个拥有6 条指令的单周期CPU,并对它进行了简单的测试,最终完成了一个正确的单周期CPU的设计。
关键词:数据路径,控制器,控制信号,单周期AbstractCentral processing unit (CPU) is a computer instraction fetch and execution ofcomponents, it is an arithmetic logic unit (ALU), registers and a controller, referred to as the processor (or CPU), CPU is the core component of computer systems in all type information terminal has been widely used・Processor design and manufacturing technology is one of the core computer technology.The first step should be based on CPU design instraction to create a data path, and then define the various components of the control signals to determine the clock cycle, the controller design. Then set up a data path, and then can be digital design, circuit design, physical implementation finalized. In this experiment, the focus of our research is to establish the data path and controller implementation.The performance of a machine consists of three key factors: the number of instructions, clock cycles to execute each instruction as well as the required number of clock cycles (CPI). Whether it be a clock cycle, each instruction or the number of clock cycles required are determined by the achievement of the processor. In this study, we constructed single-cycle data path and the combinational logic to achieve the controller.This experiment, we use Quartiis II 8.0 software to design a single-cycle instruction with 6 CPU, and it conducted a simple test, thefinal completion of a proper single-cycle CPU design.Keywords:Data path, Controller, Control Signal,Single-cycle实验内容:1、通过实验的学习,基本熟悉quarters II软件的使用,并能熟练运用试验所需元件。
一、实验目的1. 了解单周期CPU的基本原理和设计方法。
2. 掌握单周期CPU的数据通路结构及其实现过程。
3. 熟悉单周期CPU的指令集和指令格式。
4. 通过实验验证单周期CPU的功能和性能。
二、实验内容1. 单周期CPU的数据通路结构单周期CPU的数据通路主要由以下几个部分组成:(1)指令寄存器(IR):存储从内存中取出的指令。
(2)程序计数器(PC):存储下一条指令的地址。
(3)寄存器文件(RF):用于存储操作数和中间结果。
(4)算术逻辑单元(ALU):执行指令中的算术运算和逻辑运算。
(5)数据内存(DM):存储数据和指令。
(6)控制单元:根据指令操作码生成相应的控制信号。
2. 单周期CPU的指令集和指令格式本实验所采用的指令集包括以下几种:(1)算术运算指令:如加法、减法、乘法、除法等。
(2)逻辑运算指令:如与、或、非等。
(3)数据传输指令:如将寄存器中的数据传送到内存或寄存器中。
(4)跳转指令:改变程序计数器的值,实现程序跳转。
指令格式如下:| 操作码 | 操作数1 | 操作数2 | 目标寄存器 ||--------|--------|--------|------------|| 5位 | 5位 | 5位 | 5位 |3. 单周期CPU的设计与实现(1)硬件设计根据实验要求,设计单周期CPU的硬件结构,包括各个模块的连接和功能实现。
(2)软件设计编写指令译码程序,根据指令操作码生成相应的控制信号,控制各个模块执行指令。
4. 实验验证(1)编译测试程序将测试程序编译成机器码,存入数据内存。
(2)运行测试程序通过程序计数器逐条取出指令,执行指令,观察结果。
(3)分析实验结果根据实验结果,分析单周期CPU的功能和性能。
三、实验结果与分析1. 单周期CPU能够正确执行指令,实现算术运算、逻辑运算、数据传输和跳转等功能。
2. 单周期CPU的数据通路结构简单,指令执行速度快,但资源利用率较低。
3. 实验结果表明,单周期CPU具有较高的性能,但在实际应用中,需要根据具体需求进行优化设计。
MIPS单周期CPU实验报告一、实验目标本次实验的主要目标是设计并实现一个基于MIPS单周期CPU的计算机系统。
具体要求如下:1.能够识别并执行MIPS指令集中的常见指令,包括算术逻辑运算、分支跳转和存取指令等。
2.实现基本的流水线结构,包括指令译码阶段、执行阶段、访存阶段和写回阶段。
3.能够在基本结构的基础上添加异常处理和浮点数运算支持。
二、实验环境三、实验过程1.确定CPU的基本组成部分,包括指令存储器、数据存储器、寄存器、ALU和控制单元等,并进行电路设计。
2.编写MIPS汇编程序,并使用MARS进行仿真调试,验证指令的正确性和计算结果的准确性。
3.将MIPS汇编程序烧录到指令存储器中,并将数据存储器中的初始数据加载进去。
4.运行程序,观察CPU的工作状态,并进行时序仿真,验证CPU设计的正确性。
5.对CPU进行性能测试,包括执行时间、指令吞吐量和时钟周期等指标的测量。
四、实验结果经过实验和测试,我们成功地设计并实现了一个基于MIPS单周期CPU的计算机系统。
该系统能够正确执行MIPS指令集中的常见指令,并支持流水线结构、异常处理和浮点数运算。
1.指令执行的正确性:通过在MARS中进行调试和仿真,我们发现CPU能够正确地执行各种指令,包括算术逻辑运算、分支跳转和存取指令等。
并且,在时序仿真中,CPU的各个组件的信号波形也符合预期。
2.流水线结构的实现:我们根据MIPS指令的特点和处理流程,设计了基本的流水线结构,并在MARS中进行了时序仿真。
仿真结果表明,各个流水线级的操作都能够正确无误地进行,并且能够顺利地在一个时钟周期内完成。
3.异常处理和浮点数运算的支持:通过在MIPS汇编程序中加入异常处理和浮点数运算的指令,我们验证了CPU对这些功能的支持。
在异常处理时,CPU能够正确地转入异常处理程序,并根据异常类型进行相应的处理。
在浮点数运算时,CPU能够正确地进行浮点数的加减乘除等运算,并将结果正确地写回寄存器。
___单周期性CPU设计课设报告引言本报告旨在介绍___单周期性CPU设计课设的背景、目的以及报告所涵盖的内容。
单周期性CPU设计课设是一个重要的任务,通过该任务的完成,我们可以深入了解CPU的架构和设计原理,提升对计算机体系结构的理解和应用能力。
在本次报告中,我们将首先讨论课设背景与目的,以帮助读者了解为什么进行单周期性CPU设计的课程任务,并明确我们的目标和愿望。
随后,我们将概述报告的内容,介绍每个部分的主要内容和重点。
通过阅读本报告,读者将对单周期性CPU设计的过程和相关知识有一个清晰的认识,为未来的研究和应用奠定基础。
请继续阅读以下内容,以了解更多关于___单周期性CPU设计课设报告的相关信息。
CPU(Central Processing Unit)是计算机的核心部件,负责执行指令、进行数据处理和控制计算机的各种操作。
功能CPU具有以下主要功能:数据处理:CPU能够执行各种算术和逻辑操作,包括加减乘除、比较、位逻辑运算等。
指令执行:CPU能够解码和执行指令,根据指令的要求对数据进行操作。
数据存储:CPU能够将数据存储在内部的寄存器中,以便后续的处理和计算。
结构CPU主要包括以下几个部分:数据通路(Data Path):数据通路是CPU中负责执行指令的部分,包括算术逻辑单元(ALU)用于执行算术和逻辑操作,寄存器用于暂存数据,数据选择器用于选择需要处理的数据等。
控制单元(Control Unit):控制单元是CPU中负责控制指令执行的部分,它根据指令中的操作码来决定执行什么操作,以及执行操作的顺序和方式。
寄存器(Registers):寄存器是CPU中的存储单元,用于存储和暂存数据。
CPU通常包括多个寄存器,不同寄存器有不同的功能和用途,例如通用寄存器用于存储中间结果和计算过程中需要的数据,程序计数器(PC)用于存储下一条指令的地址等。
以上是CPU的基本原理,包括其功能和结构,通过数据通路和控制单元的配合以及寄存器的存储,CPU能够实现指令的执行和数据的处理。
计算机组成实验报告实验名称:单周期CPUVerilog实现实验日期:2011.4.12-2011.4.19实验人员:同组者:一、主要实验内容将已做好的各个模块进行模块合并,实现单周期CPU的各项指令,(注:由于此次设计只是利用verilog硬件编程语言实现具体功能,因此数据寄存器和存储器部件内的内容需由程序设计者自己给出,并不能从计算机中直接读取),下面对各个子模块进行简单的介绍。
二、各个子模块的简单介绍此程序将数据通路(SingleDataLoad)设定为顶层模块,下面的模块包括:算术逻辑运算单元(ALU)、数据存储器(DataStore)、数据寄存器(Registers)、取指令部件(GetCode)、总控制器(Control),通过顶层模块对各个子模块的调用从而实现了整个单周期CPU。
1)数据通路(SingleDataLoad):进行数据的运算、读取以及存储功能,通过总控制器产生的各个控制信号,进而实现对数据的各项操作。
2)算术逻辑运算单元(ALU):数据通路调用此模块,根据得到的控制信号对输入数据进行处理,处理功能有:addu、add、or、subu、sub、sltu、slt等。
3)数据存储器(DataStore):当WrEn控制信号为1时,此时就将输入数据存储到此存储器中,当WrEn为0时,则根据输入的地址,找到地址对应的单元将单元中的数据输出。
4)数据寄存器(Registers):在此程序中功能和实现基本和数据存储器相同,但在实际CPU当中使用的逻辑器件及获取数据的方式还是有所区别的。
5)取指令部件(GetCode):指根据PC所提供的地址从指令寄存器中取出要执行的指令,再根据各控制信号,得出下一次要执行的指令的地址。
(注:指令寄存器中存放的就是一个程序或一段代码所需要执行的指令,这里也是程序设计者自己给出的一些指令的值。
)6)总控制器(Control):总控制器通过从取指令部件获得的指令,进而产生各个控制信号,并将控制信号返回个数据通路,就此实现各项功能。
《计算机组成原理与接口技术实验》实验报告学院名称:学生姓名:学号:专业(班级):合作者:时间:2016年4月25日成绩:实验二:一.实验目的1.掌握单周期CPU数据通路图的构成、原理及其设计方法;2.掌握单周期CPU的实现方法,代码实现方法;3.认识和掌握指令与CPU的关系;4.掌握测试单周期CPU的方法。
二.实验内容设计一个单周期CPU,该CPU至少能实现以下指令功能操作。
需设计的指令与格式如下:==> 算术运算指令(1)add rd , rs, rt(说明:以助记符表示,是汇编指令;以代码表示,是机器指令)功能:rd←rs + rt。
reserved为预留部分,即未用,一般填“0”。
(2)addi rt , rs ,immediate功能:rt←rs + (sign-extend)immediate;immediate符号扩展再参加“加”运算。
(3)sub rd , rs , rt完成功能:rd←rs - rt==> 逻辑运算指令(4)ori rt , rs ,immediate功能:rt←rs | (zero-extend)immediate;immediate做“0”扩展再参加“或”运算。
(5)and rd , rs , rt功能:rd←rs & rt;逻辑与运算。
(6)or rd , rs , rt功能:rd←rs | rt;逻辑或运算。
==> 传送指令(7)move rd , rs功能:rd←rs + $0 ;$0=$zero=0。
==> 存储器读/写指令(8)sw rt ,immediate(rs) 写存储器功能:memory[rs+ (sign-extend)immediate]←rt;immediate 符号扩展再相加。
(9) lw rt , immediate(rs) 读存储器功能:rt ← memory[rs + (sign-extend)immediate];immediate 符号扩展再相加。
==> 分支指令(10)beq rs,rt,immediate功能:if(rs=rt) pc←pc +4 + (sign-extend)immediate <<2;特别说明:immediate是从PC+4地址开始和转移到的指令之间指令条数。
immediate符号扩展之后左移2位再相加。
为什么要左移2位由于跳转到的指令地址肯定是4的倍数(每条指令占4个字节),最低两位是“00”,因此将immediate放进指令码中的时候,是右移了2位的,也就是以上说的“指令之间指令条数”。
==> 停机指令(11)halt功能:停机;不改变PC的值,PC保持不变。
三.实验原理单周期CPU指的是一条指令的执行在一个时钟周期内完成,然后开始下一条指令的执行,即一条指令用一个时钟周期完成。
电平从低到高变化的瞬间称为时钟上升沿,两个相邻时钟上升沿之间的时间间隔称为一个时钟周期。
时钟周期一般也称振荡周期(如果晶振的输出没有经过分频就直接作为CPU的工作时钟,则时钟周期就等于振荡周期。
若振荡周期经二分频后形成时钟脉冲信号作为CPU的工作时钟,这样,时钟周期就是振荡周期的两倍。
)CPU在处理指令时,一般需要经过以下几个步骤:(1) 取指令(IF):根据程序计数器PC中的指令地址,从存储器中取出一条指令,同时,PC根据指令字长度自动递增产生下一条指令所需要的指令地址,但遇到“地址转移”指令时,则控制器把“转移地址”送入PC,当然得到的“地址”需要做些变换才送入PC。
(2) 指令译码(ID):对取指令操作中得到的指令进行分析并译码,确定这条指令需要完成的操作,从而产生相应的操作控制信号,用于驱动执行状态中的各种操作。
(3) 指令执行(EXE):根据指令译码得到的操作控制信号,具体地执行指令动作,然后转移到结果写回状态。
(4) 存储器访问(MEM):所有需要访问存储器的操作都将在这个步骤中执行,该步骤给出存储器的数据地址,把数据写入到存储器中数据地址所指定的存储单元或者从存储器中得到数据地址单元中的数据。
(5) 结果写回(WB):指令执行的结果或者访问存储器中得到的数据写回相应的目的寄存器中。
单周期CPU,是在一个时钟周期内完成这五个阶段的处理。
图1 单周期CPU指令处理过程MIPS32的指令的三种格式:R类型:31 26 25 21 20 16 15 11 106 5 06位 5位 5位 5位 5位6位I类型:31 26 25 21 20 16 156位 5位 5位 16位J类型:31 26 256位 26位其中,op:为操作码;rs:为第1个源操作数寄存器,寄存器地址(编号)是00000~11111,00~1F;rt:为第2个源操作数寄存器,或目的操作数寄存器,寄存器地址(同上);rd:为目的操作数寄存器,寄存器地址(同上);sa:为位移量(shift amt),移位指令用于指定移多少位;func:为功能码,在寄存器类型指令中(R类型)用来指定指令的功能;immediate:为16位立即数,用作无符号的逻辑操作数、有符号的算术操作数、数据加载(Laod)/数据保存(Store)指令的数据地址字节偏移量和分支指令中相对程序计数器(PC)的有符号偏移量; address:为地址。
图2 单周期CPU数据通路和控制线路图图2是一个简单的基本上能够在单周期上完成所要求设计的指令功能的数据通路和必要的控制线路图。
其中指令和数据各存储在不同存储器中,即有指令存储器和数据存储器。
访问存储器时,先给出地址,然后由读/写信号控制(1-写,0-读。
当然,也可以由时钟信号控制,但必须在图上标出)。
对于寄存器组,读操作时,先给出地址,输出端就直接输出相应数据;而在写操作时,在 WE使能信号为1时,在时钟边沿触发写入。
图中控制信号作用如表1所示,表2是ALU运算功能表。
表1 控制信号的作用相关部件及引脚说明:Instruction Memory:指令存储器,Iaddr,指令存储器地址输入端口IDataIn,指令存储器数据输入端口(指令代码输入端口)IDataOut,指令存储器数据输出端口(指令代码输出端口)RW,指令存储器读写控制信号,为1写,为0读Data Memory:数据存储器,Daddr,数据存储器地址输入端口DataIn,数据存储器数据输入端口DataOut,数据存储器数据输出端口RW,数据存储器读写控制信号,为1写,为0读Register File:(寄存器组)Read Reg1,rs寄存器地址输入端口Read Reg2,rt寄存器地址输入端口Write Reg,将数据写入的寄存器端口,其地址来源rt 或rd字段Write Data,写入寄存器的数据输入端口Read Data1,rs寄存器数据输出端口Read Data2,rt寄存器数据输出端口WE,写使能信号,为1时,在时钟上升沿写入ALU:result,ALU运算结果zero,运算结果标志,结果为0输出1,否则输出0表2 ALU运算功能表A B需要说明的是根据要实现的指令功能要求画出以上数据通路图,和确定ALU的运算功能(当然,以上指令没有完全用到提供的ALU所有功能,但至少必须能实现以上指令功能操作)。
从数据通路图上可以看出控制单元部分需要产生各种控制信号,当然,也有些信号必须要传送给控制单元。
从指令功能要求和数据通路图的关系得出以上表1,这样,从表1可以看出各控制信号与相应指令之间的相互关系,根据这种关系就可以得出控制信号与指令之间的关系表(留给学生完成),再根据关系表可以写出各控制信号的逻辑表达式,这样控制单元部分就可实现了。
指令执行的结果总是在下个时钟到来前开始保存到寄存器、或存储器中,PC的改变也是在这个时候进行。
另外,值得注意的问题,设计时,用模块化的思想方法设计,关于ALU设计、存储器设计、寄存器组设计等等,也是必须认真考虑的问题。
可以参考其他资料文档,里面有相应的设计方法介绍.四.实验器材电脑一台、Xilinx ISE 软件一套。
五.实验分析与设计模块分析:根据单周期CPU数据通路和控制线路图,大致可以将CPU分为右图七个模块,每个模块负责一个部分的功能:(代码存于code文件夹)(图的下方为各个模块的变量,在后图会出现,故省略)CPU:负责各模块之间的数据的传输,如同C语言中的头文件,将其他的子模块连接在一起,其中clk信号在此声明。
CU:CU负责指令的解析,即将由ROM读取的指令转化为操作发送给其他子模块进行操作。
PC:负责指令的计数,已经指令的向前或向后跳动,每个时钟周期计数加一。
ROM:即存储器,发送信息,CPU的指令文件即由ROM读取,只读,在电脑中表现为BIOS的数据文件。
RAM:内存,可读可写,用来保存临时数据,汇编语言中的$s的储存地点。
RF:寄存器,可读可写,数据由寄存器发送向ALU计算,汇编语言中的$t的储存地点。
SE:产生立即数,将发送过来的半数零拓展或符号拓展。
ALU:算术单元,加减乘除逻辑运算等等,都在这里计算。
测试数据输入00000000000000000000000000000000(不操作)可得到如上图,CPU正确运行实验测试:(根据实验内容指令表格)0,1,2,3 算术运算指令 4,5,6 逻辑运算指令7 传送指令 8,9 存储器读/写指令10,11 分支指令 14 停机指令因为都为0,没有变化如上表,$4为3$2 = $4 + 8 = 11$1 = $2 - $4 = 8$5 = $2 | 0000 0000 0000 1000 = 11$6 = $1 & $2 = 8$7 = $1 | $2 = 117.move$8 = $78.swregisterRAM$s15 = $110.beq 不相等情况由于这里两个寄存器不相等,立即数为0,即跳转到下1 + 0/4条指令,故这里进入下一条指令。
相等情况,跳过指令12跳转到13,$1没有变化13.halt停机,如图,下一条指令被锁测试完成六.实验心得本次实验的难度较第一次实验要高很多,很多问题都是半知半解的状态,尤其是CU部分,CU是按照实验资料中的页5中的表格生搬硬套的,有许多不理解,同学也帮助了很多。
实验有很多和图上是有区别的,主要表现在CPU的位数,基本没有算法,都是理解和想象的问题,有些模块要自己构想,不能通过看图就知道,但是图中给了很多的提示,每个部件的输入和输出基本上在图中都有显示。
CPU的难度也很大,主要是变量十分得多,很容易就造成错误,在写模块的时候很容易就造成错误。
最后就是运行的问题,一开始不知道如何导入指令,做出来全部显示的都是X,检查了几遍代码后才发现问题,从ROM中读取指令。