聚类分析应用范例
- 格式:doc
- 大小:360.08 KB
- 文档页数:15

聚类分析的应用案例聚类分析是一种常用的数据分析方法,它可以帮助我们对数据进行分类和分组,发现数据中的潜在模式和规律。
在现实生活和工作中,聚类分析有着广泛的应用,下面我们将介绍几个聚类分析的应用案例。
首先,聚类分析在市场营销领域有着重要的应用。
在市场营销中,我们常常需要对顾客进行分类,以便针对不同类别的顾客制定不同的营销策略。
通过聚类分析,我们可以根据顾客的消费行为、偏好等特征将顾客进行分类,从而更好地理解顾客群体的特点,并针对性地开展营销活动,提高营销效果。
其次,聚类分析在医学领域也有着重要的应用。
在医学研究中,我们常常需要对疾病患者进行分类,以便更好地了解不同类型患者的病情特点和治疗效果。
通过聚类分析,我们可以根据患者的临床表现、病情指标等特征将患者进行分类,从而更好地指导临床诊断和治疗方案的制定,提高治疗效果和患者生存率。
此外,聚类分析还在推荐系统中有着重要的应用。
在电子商务平台和社交媒体平台上,推荐系统可以根据用户的行为和偏好向其推荐商品、信息等内容。
而聚类分析可以帮助推荐系统对用户进行分类,从而更好地理解用户的兴趣和偏好,提高推荐的准确性和个性化程度,增强用户体验。
最后,聚类分析还在金融领域有着重要的应用。
在金融风控和信用评估中,我们常常需要对客户进行分类,以便更好地评估客户的信用风险和制定个性化的信贷方案。
通过聚类分析,我们可以根据客户的财务状况、信用记录等特征将客户进行分类,从而更好地了解客户的信用状况,提高风险控制的精准度和效果。
总之,聚类分析在各个领域都有着重要的应用,它可以帮助我们更好地理解数据和问题的本质,发现数据中的潜在规律和价值信息,为决策提供科学依据。
随着数据科学和人工智能技术的不断发展,相信聚类分析的应用领域会越来越广泛,对我们的生活和工作产生越来越大的影响。

聚类分析案例范文聚类分析是一种无监督机器学习算法,它通过将数据集中的观测值分成不同的组或簇来发现数据之间的内在结构和相似性。
这种方法可以帮助我们理解数据集,发现隐藏的模式和关联性,并且可以应用于各种领域,包括市场细分、社交网络分析、生物信息学和图像处理等。
以下是一个关于使用聚类分析方法的案例研究,该案例介绍了如何使用聚类分析来帮助一家电商企业在众多商品中挖掘潜在的市场细分。
背景介绍:电商企业销售了大量商品,这些商品拥有不同的特征和属性。
该企业希望利用这些数据来了解他们的客户,并为不同的产品类型制定个性化的推广和营销策略。
为了实现这一目标,他们决定使用聚类分析方法来将客户细分成不同的群组,并理解他们的相似性和差异性。
数据收集:该企业从其销售系统中收集了一份包含多个属性的数据集。
这些属性包括:年龄、性别、购买历史、购买频率、平均订单金额等。
这些属性可以反映客户的购买行为和偏好。
数据预处理:在进行聚类分析之前,需要对数据进行预处理。
这包括对缺失值进行处理、进行数值归一化等。
然后,根据业务需求,选择适当的聚类算法和合适的距离度量方法。
聚类分析过程:在本案例中,采用了一种常见的聚类方法--K均值聚类算法,该算法通过计算数据点之间的欧氏距离来度量它们之间的相似度。
首先,选择合适的K值(聚类簇的个数)。
然后,在初始阶段,随机选择K个点作为聚类中心。
再通过计算每个数据点与聚类中心的距离,并将其归类到最近的聚类簇。
接下来,根据已经分配到每个聚类中的数据点,重新计算新的聚类中心。
这个过程将迭代,直到达到停止准则,如聚类中心不再变化或达到最大迭代次数。
聚类结果分析:在完成聚类过程后,可以根据每个聚类中心的特征和属性,对数据集进行可视化和解释。
这将帮助企业理解各个群组的特征和差异,并从中提取有价值的洞察力。
进而,企业可以根据不同群组的特征制定个性化的营销策略,提高销售和客户满意度。
总结:通过使用聚类分析方法,该电商企业成功地将其客户细分为几个不同的群组。

聚类分析案例聚类分析是一种常见的数据分析方法,它能够将数据集中的观测值划分为若干个类别,使得同一类别内的观测值相似度较高,不同类别之间的观测值相似度较低。
聚类分析在市场细分、社交网络分析、医学图像分析等领域都有着广泛的应用。
本文将以一个实际的案例来介绍聚类分析的应用过程。
案例背景:某电商平台希望对其用户进行细分,以便更好地了解用户需求,精准推荐商品。
为此,他们收集了用户的浏览、购买、评价等行为数据,希望通过聚类分析将用户分成不同的群体。
数据准备:首先,我们需要对数据进行清洗和整理。
去除缺失值、异常值,对数据进行标准化处理,以便消除不同维度之间的量纲影响。
然后,我们可以利用主成分分析(PCA)等方法对数据进行降维,以便更好地展现数据的内在结构。
模型选择:在数据准备完成后,我们需要选择合适的聚类算法。
常见的聚类算法包括K均值聚类、层次聚类、密度聚类等。
在本案例中,我们选择了K均值聚类算法,因为该算法简单易实现,并且适用于大规模数据。
聚类分析:经过数据准备和模型选择后,我们开始进行聚类分析。
首先,我们需要确定聚类的数量K。
这里我们可以采用肘部法则、轮廓系数等方法来确定最佳的K值。
然后,我们利用K均值聚类算法对数据进行分组,得到每个用户所属的类别。
结果解释:得到聚类结果后,我们需要对每个类别进行解释和分析。
通过对每个类别的特征进行比较,我们可以揭示出不同类别用户的行为特点和偏好。
比如,某一类用户可能更倾向于购买高价值商品,而另一类用户更注重商品的品质和口碑。
应用建议:最后,我们可以根据聚类结果给出相应的应用建议。
比如,对于高价值用户群体,电商平台可以加大对其的推荐力度,提供更多的个性化服务;对于偏好品质和口碑的用户群体,可以加强品牌营销和口碑传播,以吸引更多类似用户。
总结:通过本案例的介绍,我们可以看到聚类分析在用户细分和个性化推荐方面的重要作用。
通过对用户行为数据的聚类分析,电商平台可以更好地了解用户需求,提供更精准的推荐服务,从而提升用户满意度和交易量。


聚类分析应用案例
简介
聚类分析是一种无监督研究方法,旨在将数据样本划分为具有相似特征的群组或类别。
在许多领域中,聚类分析被广泛应用于数据分析、模式识别和信息检索等任务。
本文将介绍聚类分析在实际应用中的一些案例。
零售行业中的市场细分
零售行业需要了解其客户群体的特征以制定有效的营销策略。
通过聚类分析,可以将顾客细分为不同的群组,例如消费惯相似的群体、购买力相近的群体等。
基于这些细分结果,零售商可以有针对性地开展宣传活动、提供个性化服务,从而提高市场竞争力。
医疗领域中的疾病分类
在医疗领域,聚类分析可以用于疾病分类和诊断。
通过对患者的症状、体征和病史等信息进行聚类,可以将患者群体划分为具有相似疾病特征的子群。
这有助于医生进行更精确的诊断和制定个性化的治疗方案。
社交媒体分析中的用户群体划分
在社交媒体分析中,聚类分析可用于划分用户群体,了解不同用户的兴趣、行为模式和需求。
以这些群体为基础,企业可以更好地理解目标用户,并设计出更精准的推广活动和产品策略。
金融领域中的风险管理
在金融领域,聚类分析可以用于风险管理。
通过对客户的财务信息、投资偏好和风险承受能力等进行聚类,可以将客户划分为不同的风险群体。
这可以帮助金融机构识别高风险客户,并采取相应的风险控制措施。
总结
聚类分析是一种强大而灵活的数据分析工具,在各个领域都有广泛的应用。
本文介绍了其在零售行业、医疗领域、社交媒体分析和金融领域中的应用案例。
聚类分析可以帮助我们理解数据的内在结构、找到相似的群体,并基于这些群体进行个性化的决策和策略制定。

聚类分析的应用案例聚类分析是一种常用的数据分析方法,它可以将数据集中的对象分成不同的类别或簇,使得同一类内的对象相似度较高,而不同类别之间的对象相似度较低。
聚类分析广泛应用于市场分析、社交网络分析、生物信息学、医学诊断等领域。
本文将介绍几个聚类分析的应用案例,以便更好地理解聚类分析在实际问题中的应用。
首先,聚类分析在市场分析中的应用。
在市场营销中,企业需要了解消费者的偏好和行为,以便更好地制定营销策略。
通过对消费者数据进行聚类分析,可以将消费者分成不同的群体,从而更好地理解他们的需求和行为模式。
例如,一家零售商可以通过聚类分析将消费者分成价格敏感型、品牌忠诚型、功能导向型等不同的群体,从而有针对性地进行促销活动和产品定位。
其次,聚类分析在社交网络分析中的应用。
随着社交网络的兴起,人们在社交网络上的行为数据变得越来越丰富。
通过对社交网络数据进行聚类分析,可以发现不同的社交群体和用户行为模式。
例如,一家社交网络平台可以通过聚类分析将用户分成信息分享型、社交互动型、内容创作型等不同的群体,从而更好地满足用户需求,提高用户留存和活跃度。
再次,聚类分析在生物信息学中的应用。
生物信息学是研究生物学数据的计算机科学领域,其中大量的生物数据需要进行分析和挖掘。
通过对生物数据进行聚类分析,可以发现不同的基因型、蛋白质结构等生物特征。
例如,通过对癌症患者的基因数据进行聚类分析,可以发现不同的癌症亚型和治疗方案,为临床诊断和治疗提供重要参考。
最后,聚类分析在医学诊断中的应用。
在医学诊断中,医生需要根据患者的症状和检查数据进行疾病诊断。
通过对患者数据进行聚类分析,可以发现不同的疾病类型和临床表现。
例如,通过对心脏病患者的临床数据进行聚类分析,可以发现不同的心脏病亚型和治疗方案,为临床诊断和治疗提供重要参考。
综上所述,聚类分析在市场分析、社交网络分析、生物信息学、医学诊断等领域都有重要的应用价值。
通过对不同领域的应用案例进行分析,可以更好地理解聚类分析的原理和方法,为实际问题的解决提供重要参考。

聚类分析法经典案例
聚类分析是一种常用的数据分析方法,它能够将相似的观察对象分为一组,并将不相似的对象分为不同的组。
下面将介绍一个经典的聚类分析案例。
在电信行业,客户流失是一个非常重要的问题。
为了降低客户流失率,一家电信公司希望通过聚类分析来识别客户流失的特征,以便进行有针对性的营销策略。
首先,该公司收集了一些客户数据,如客户的年龄、性别、月平均消费金额、通话时长等。
然后,利用聚类分析方法,将客户分为不同的组。
在这个案例中,我们可以采用k-means聚类算法。
通过聚类分析,该公司发现了三个客户群体。
第一组客户是高消费高通话客户,他们的平均消费金额和通话时长都很高。
第二组客户是低消费低通话客户,他们的平均消费金额和通话时长都很低。
第三组客户是高消费低通话客户,他们的平均消费金额很高,但通话时长很低。
利用聚类分析的结果,该公司能够采取有针对性的营销策略。
对于高消费高通话客户,他们可能是该公司的忠诚客户,可以通过提供一些优惠或奖励来保持他们的忠诚度。
对于低消费低通话客户,可以通过提供更具吸引力的套餐或增加服务内容来激发他们的消费需求。
对于高消费低通话客户,可以通过了解他们的通话行为,推出更适合他们的通话套餐,以增加他们的通话时长。
通过这个案例,我们可以看到聚类分析在客户流失预测和营销策略中的重要作用。
它可以帮助企业快速识别不同类型的客户,有针对性地制定相应的营销策略,提高客户满意度和忠诚度,降低客户流失率。
聚类分析还可以应用于其他领域,如金融、医疗等,具有广泛的应用前景。
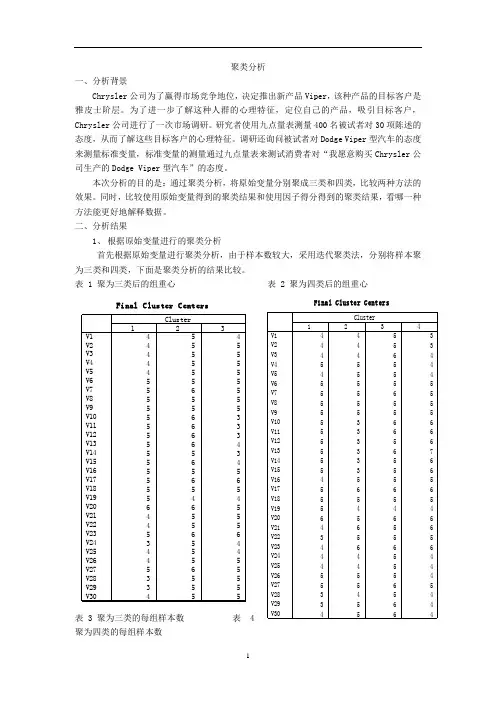
聚类分析一、分析背景Chrysler公司为了赢得市场竞争地位,决定推出新产品Viper,该种产品的目标客户是雅皮士阶层。
为了进一步了解这种人群的心理特征,定位自己的产品,吸引目标客户,Chrysler公司进行了一次市场调研。
研究者使用九点量表测量400名被试者对30项陈述的态度,从而了解这些目标客户的心理特征。
调研还询问被试者对Dodge Viper型汽车的态度来测量标准变量,标准变量的测量通过九点量表来测试消费者对“我愿意购买Chrysler公司生产的Dodge Viper型汽车”的态度。
本次分析的目的是:通过聚类分析,将原始变量分别聚成三类和四类,比较两种方法的效果。
同时,比较使用原始变量得到的聚类结果和使用因子得分得到的聚类结果,看哪一种方法能更好地解释数据。
二、分析结果1、根据原始变量进行的聚类分析首先根据原始变量进行聚类分析,由于样本数较大,采用迭代聚类法,分别将样本聚为三类和四类,下面是聚类分析的结果比较。
表 1 聚为三类后的组重心表 2 聚为四类后的组重心表 3 聚为三类的每组样本数表聚为四类的每组样本数表5 聚为三类后组重心之间的距离 表 6 聚为四类后组重心之间的距离由方差分析的结果(结果略)可知,在聚为三类和四类的分析中,V8,V9,V18,V19,V20和V27的组间差异均大于0.05,结果不显著。
2、 根据因子得分进行的聚类分析以下是根据因子得分,采用迭代法将样本聚为三类和四类的结果:表7 聚为三类后的组重心-.45298 .16364 .29950 .36038 -.22794 -.15239 .28739 -.32881 .00765 .25444 .70915 -.87203 .52946 -.29355 -.26021 .18363 .11953 -.28471 .00228 .20936 -.18616 .56772-.64844.01414消费因子 时尚因子 社会因子 爱国因子 期望因子 偏好因子 个性因子 家庭因子12 3 Cluster表 8 聚为三类时的样本数 137.000 123.000 140.000 400.000 .0001 2 3ClusterValidMissing以下是根据因子得分聚为四类的结果:从以上用因子得分的结果可以看出,聚为三类和四类时八个因子的组间差异都很显著。

机器学习中的聚类分析应用案例在机器学习领域,聚类分析是一种无监督学习方法,用于发现数据中的隐藏结构和模式。
通过对数据进行分组,聚类分析可以帮助我们理解数据集的内在特性。
在本文中,我们将探讨机器学习中聚类分析的应用案例。
一、电商产品分类在电商行业中,存在大量的产品和商品信息,如何对这些产品进行有效的分类和组织是一个重要的问题。
聚类分析可以帮助我们将相似的产品分组,并为电商平台提供更好的用户体验。
例如,假设我们有大量的电子产品信息,包括手机、笔记本电脑、平板电脑等。
利用聚类分析,我们可以将这些产品根据其特征进行分组,比如处理器型号、内存大小、价格等。
通过这种方式,用户可以更方便地浏览和比较同一类别的产品,并找到最适合自己的商品。
二、社交媒体用户分析社交媒体平台上的用户数量庞大,而且用户间的兴趣和关系错综复杂。
聚类分析可以帮助我们理解不同用户之间的相似性,并为社交媒体平台提供个性化推荐和精准广告投放。
以微博为例,如果我们想要将用户分成不同的兴趣群体,可以使用聚类算法来发现用户之间的相似性。
通过分析用户的发帖内容、点赞和评论等信息,我们可以将用户分成运动爱好者、美食爱好者、电影迷等不同的类别。
这样,我们可以为不同兴趣群体提供个性化的内容推荐和广告投放。
三、医疗诊断在医疗领域,聚类分析可以帮助医生和研究人员对疾病进行分类和诊断。
通过对患者的病历和检查结果进行聚类分析,可以找出不同疾病之间的关联和区别。
举个例子,假设我们有一批乳腺癌患者的病历数据,包括肿瘤大小、淋巴结转移情况、年龄等特征。
通过聚类分析,我们可以将这些患者分成不同的组群,每个组群代表一种不同的乳腺癌类型。
这样,医生可以根据患者所属的组群来进行个性化的治疗和诊断。
四、客户细分在市场营销中,了解客户的需求和偏好对于提供定制化的产品和服务至关重要。
聚类分析可以帮助企业将客户分成不同的细分市场,以更好地满足客户的需求。
以银行业为例,通过对客户的消费行为、借贷记录、资产状况等数据进行聚类分析,可以将客户分成不同的细分市场,例如高净值客户、中产阶级客户、学生群体等。

聚类分析法经典案例聚类分析法是一种常用的数据分析方法,它通过对数据进行分类和分组,帮助我们发现数据中的内在规律和特征。
在实际应用中,聚类分析法被广泛运用于市场营销、社交网络分析、医学诊断、图像处理等领域。
下面,我们将介绍一些聚类分析法的经典案例,帮助大家更好地理解和应用这一方法。
首先,我们来看一个市场营销领域的案例。
某公司想要对其客户进行分类,以便更好地制定营销策略。
他们收集了客户的消费行为、年龄、性别、地理位置等数据,并利用聚类分析法对客户进行了分组。
通过分析,他们发现客户可以被分为三大类,高消费高端用户、中等消费稳定用户和低消费新用户。
有了这些分类信息,公司可以针对不同类型的客户制定不同的营销策略,提高市场营销效率。
其次,我们来看一个社交网络分析的案例。
一家社交媒体公司希望了解用户在平台上的行为和兴趣,以便更好地推荐内容和广告。
他们利用用户的浏览记录、点赞行为、评论信息等数据,通过聚类分析法将用户分为几个群体。
通过分析,他们发现用户可以被分为电影爱好者、音乐迷、美食达人等不同类型的群体。
有了这些分类信息,社交媒体公司可以更精准地为用户推荐内容和广告,提高用户满意度和广告点击率。
再次,我们来看一个医学诊断的案例。
医院收集了患者的临床症状、实验室检查结果、病史等数据,希望通过聚类分析法对患者进行分类,以便更好地制定治疗方案。
通过分析,他们发现患者可以被分为几个病情严重程度不同的群体。
有了这些分类信息,医生可以更好地制定个性化的治疗方案,提高治疗效果和患者生存率。
最后,我们来看一个图像处理的案例。
一家无人驾驶车辆公司希望通过图像识别技术对道路上的车辆和行人进行分类,以便更好地进行交通管理和安全预警。
他们利用摄像头采集的图像数据,通过聚类分析法将道路上的车辆和行人进行分类。
通过分析,他们可以更准确地识别不同类型的车辆和行人,并做出相应的交通管理和安全预警措施。
通过以上经典案例的介绍,我们可以看到聚类分析法在不同领域的广泛应用。
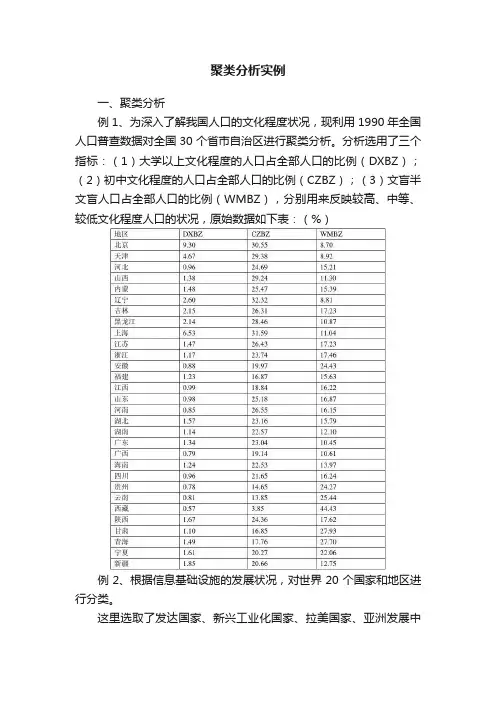
聚类分析实例一、聚类分析例1、为深入了解我国人口的文化程度状况,现利用1990年全国人口普查数据对全国30个省市自治区进行聚类分析。
分析选用了三个指标:(1)大学以上文化程度的人口占全部人口的比例(DXBZ);(2)初中文化程度的人口占全部人口的比例(CZBZ);(3)文盲半文盲人口占全部人口的比例(WMBZ),分别用来反映较高、中等、较低文化程度人口的状况,原始数据如下表:(%)例2、根据信息基础设施的发展状况,对世界20个国家和地区进行分类。
这里选取了发达国家、新兴工业化国家、拉美国家、亚洲发展中国家、转型国家等不同类型的20个国家作聚类分析。
描述信息基础设施的变量主要的有六个:call——千人拥有电话号码,movecall——每千户居民蜂窝移动电话,fee——高峰时期每三分钟国际电话成本,computer——每千人拥有的计算机数,mips——每千人中计算机功率,net——每千人互联网例3、为了研究1982年全国各地区农民家庭收支的分布规律,根据抽样调查资料进行分类处理,共抽取28个省、市、自治区的样本,每个样本有六个指标,这六个指标反映了平均每人生活消费的支出情况,其原始数据见表3。
例4为了研究世界各国森林、草原资源的分布规律,共抽取了21个国家的数据,每个国家例5 若要从沪市的蒲发银行、齐鲁石化、东北高速、武钢股份、东风汽车等53家上市公司中优选适合开放式基金组合投资的10只股票,我们以总股本和流通股本为分类标志,根据这53家公司的总股本和A股流通股本数据(见表5.3),用聚类分析法将它们分成若干类,再从各类公司中选出比较活跃的股票建立股票池。
表5.3 53家上市公司股本资料单位:十万股例6沪市上市公司2001年末总股本在10000—12000万股、流通股本在3600—5050万股之间共有23家(对于股本结构在其它范围内的上市公司,用雷同的方法,可以建立相应的每股收益预测模型),各公司2000年及2001年有关的财务数据见表。
聚类分析的应用案例聚类分析是一种常用的数据挖掘技术,它可以将数据集中的对象按照其相似性进行分类,从而找出数据中的潜在模式和结构。
聚类分析在各个领域都有着广泛的应用,例如市场营销、医学诊断、社交网络分析等。
本文将介绍几个聚类分析在实际应用中的案例,帮助读者更好地理解和应用这一技术。
首先,聚类分析在市场营销中的应用案例。
假设一个公司希望对其客户进行细分,以便更好地定制营销策略。
通过聚类分析,可以将客户按照其购买行为、偏好等特征进行分类,从而识别出不同的客户群体。
比如,通过聚类分析可以将客户分为价值型客户、潜在客户、忠诚客户等不同的群体,然后针对不同的群体制定相应的营销策略,提高营销效果。
其次,聚类分析在医学诊断中的应用案例也非常广泛。
医学领域的数据往往包含大量的特征和变量,通过聚类分析可以将患者按照其症状、生理指标等特征进行分类,从而辅助医生进行诊断和治疗。
例如,通过聚类分析可以将患者分为不同的疾病类型或病情严重程度,帮助医生更好地制定个性化的治疗方案,提高治疗效果。
另外,聚类分析在社交网络分析中也有着重要的应用价值。
随着社交网络的快速发展,人们在社交网络上产生了大量的数据,通过聚类分析可以将用户按照其兴趣、行为等特征进行分类,从而挖掘出不同的用户群体和社交圈子。
这对于社交网络平台来说,可以帮助他们更好地推荐好友、内容等,提高用户的粘性和使用体验。
综上所述,聚类分析在市场营销、医学诊断、社交网络分析等领域都有着重要的应用价值。
通过聚类分析,可以帮助人们更好地理解和利用数据,发现数据中的潜在模式和结构,为决策提供科学依据。
随着数据挖掘技术的不断发展,相信聚类分析在更多的领域将会有着更广泛的应用。
SPSS软件操作实例——某移动公司客户细分模型数据准备:数据来源于telco.sav,如图1所示,Customer_ID表示客户编号,Peak_mins表示工作日上班时期电话时长,OffPeak_mins表示工作日下班时期电话时长等。
图1 telco.sav数据分析目的:对移动手机用户进行细分,了解不同用户群体的消费习惯,以更好的对其进行定制性的业务推销,所以需要运用聚类分析。
操作步骤:1,从菜单中选择【文件】——【打开】——【数据】,在打开数据窗口中选择数据位置以及文件类型,将数据telco.sav导入SPSS软件中,如图2所示。
图2 打开数据菜单选项2,从菜单中选择【分析】——【描述统计】——【描述】,然后在描述性窗口中,将需要标准化的变量选到右边的“变量列表”,勾选“将标准化得分另存为变量”,点确定,如图3所示。
图3 数据标准化3,从菜单中选择【分析】——【分类】——【K-均值聚类】,在K-均值聚类分析窗口中将标准化之后的结果选入右边“变量列表”,客户编号选入“个案标记依据”,聚类数改为5。
点击迭代按钮,在迭代窗口将最大迭代次数改为100,点击继续。
点击保存按钮,在保存窗口勾选“聚类成员”、“与聚类中心的距离”,点击继续。
点击选项按钮,在选项窗口勾选“ANOV A表”、“每个个案的聚类信息”,点击继续。
点击确定按钮,运行聚类分析,如图4所示。
图4 聚类分析操作结果分析表1 最终聚类中心聚类1 2 3 4 5Zscore: 工作日上班时期电话时长 1.60559 -.78990 .61342 -.33584 .37303 Zscore: 工作日下班时期电话时长.46081 -.58917 -.49365 1.18873 -.29014 Zscore: 周末电话时长-.14005 -.15010 .35845 -.02375 -.40407 Zscore: 国际电话时长 1.68250 -.64550 .04673 .02351 -.04415 Zscore: 总通话时长 1.62690 -.94040 .41420 .10398 .21627 Zscore: 平均每次通话时长-.06590 -.14835 -.05337 -.14059 4.87718由最终聚类中心表可得最终分成的5个类它们各自的均值。
基于产品的聚类例子
1. 哎呀呀,你看那超市里的饮料区,不就是一个基于产品的聚类嘛!各种可乐放在一起,那就是一个小群体嘛,百事可乐、可口可乐,它们就像一群快乐的小伙伴聚在一起!
2. 你想想看,电子产品店里不同品牌的手机,这不就是很明显的聚类吗?苹果手机在一块儿,华为手机在一块儿,它们就像是不同门派的高手在各自的地盘呢!
3. 走在服装店里,那不同款式的衣服分类摆放,这不就是基于产品的聚类例子嘛!运动装一堆,正装一堆,运动装就像是活力四射的运动员,正装就像沉稳干练的白领呀!
4. 去逛家居市场的时候,各种家具的分区多清楚呀!沙发区就是沙发们的聚集地,它们像一群慵懒的家伙在那休息呢,这就是聚类呀,多有意思!
5. 嘿,文具店里的笔也有聚类呢!钢笔在一块儿,圆珠笔在一块儿,它们就好像是不同性格的文具朋友呢!
6. 看看菜市场里,蔬菜区域不就是聚类嘛!青菜一堆,萝卜一堆,青菜像朝气蓬勃的小朋友,萝卜像敦实可爱的小胖子,这不是很形象吗?
7. 大型商场的美妆区,各种品牌的化妆品也是聚类呢!口红在一个区域闪耀着,眼影在另一个区域散发着魅力,它们就像是一群爱美的精灵在展示自己!
我觉得基于产品的聚类真的是无处不在呀,它让我们购物和生活都更加方便和有趣呢!。
聚类分析例子Word版案例数据源:有20种12盎司啤酒成分和价格的数据,变量包括啤酒名称、热量、钠含量、酒精含量、价格。
【一】问题一:选择那些变量进行聚类?——采用“R型聚类”1、现在我们有4个变量用来对啤酒分类2、先确定用相似性来测度,度量标准选用pearson系数,聚类方法选最远元素,将来的相似性矩阵里的数字为相关系数。
若果有某两个变量的相关系数接近1或-1,说明两个变量可互相替代。
3、只输出“树状图”就可以了,从proximity matrix表中可以看出热量和酒精含量两个变量相关系数0.903,最大,二者选其一即可,没有必要都作为聚类变量,导致成本增加。
至于热量和酒精含量选择哪一个作为典型指标来代替原来的两个变量,可以根据专业知识或测定的难易程度决定。
(与因子分析不同,是完全踢掉其中一个变量以达到降维的目的。
)这里选用酒精含量,至此,确定出用于聚类的变量为:酒精含量,钠含量,价格。
【二】问题二:20中啤酒能分为几类?——采用“Q型聚类”1、现在开始对20中啤酒进行聚类。
开始不确定应该分为几类,暂时用一个3-5类范围来试探,这一回用欧式距离平方进行测度。
2、主要通过树状图和冰柱图来理解类别。
最终是分为4类还是3类,这是个复杂的过程,需要专业知识和最初的目的来识别。
我这里试着确定分为4类。
选择“保存”,则在数据区域内会自动生成聚类结果。
【三】问题三:用于聚类的变量对聚类过程、结果又贡献么,有用么?——采用“单因素方差分析”1、聚类分析除了对类别的确定需讨论外,还有一个比较关键的问题就是分类变量到底对聚类有没有作用有没有贡献,如果有个别变量对分类没有作用的话,应该剔除。
2、这个过程一般用单因素方差分析来判断。
注意此时,因子变量选择聚为4类的结果,而将三个聚类变量作为因变量处理。
方差分析结果显示,三个聚类变量sig值均极显著,我们用于分类的3个变量对分类有作用,可以使用,作为聚类变量是比较合理的。
聚类分析案例聚类分析是一种数据分析方法,用于将数据集中的对象分成不同的群组,使得群组内的对象相似度较高,而不同群组之间的相似度较低。
以下是一个聚类分析的案例。
假设一个公司试图了解他们的客户群体,以便更好地进行市场细分和定位。
该公司采集了一系列与客户相关的特征,比如年龄、性别、购买行为等。
他们打算使用聚类分析来将这些客户划分为不同的群组,以便更好地了解每个群组的特征和需求。
首先,该公司需要对数据进行预处理。
他们将删除一些不相关或重复的特征,并对缺失数据进行填充。
然后,他们需要选择一个合适的聚类算法来检测潜在的群组结构。
在这个案例中,他们选择了k-means算法,因为它是一个简单而高效的方法,适用于大规模数据集。
接下来,他们需要选择聚类的数量。
为了确定最佳的聚类数量,他们使用了“肘部法则”。
该方法计算了不同聚类数量下的聚类误差平方和(SSE),并绘制了一个聚类数量和SSE的折线图。
根据折线图,他们选择了一个聚类数量,使得SSE的降幅明显减缓的那个点。
在这个案例中,他们选择了5个聚类。
最后,他们使用选定的聚类数量运行k-means算法,并获取每个客户所属的聚类。
然后,他们对每个聚类进行分析,比如计算平均年龄、男女比例、购买偏好等。
通过对聚类结果的比较,他们可以发现不同群组之间的差异和相似之处,从而得出关于每个群组的特征和需求的结论。
通过这个聚类分析,该公司发现客户群体可以分为以下几个群组:青年女性购买群体、中年男性购买群体、中老年女性购买群体、青年男性购买群体和普通购买群体。
他们发现不同群组的平均年龄、男女比例和购买偏好存在显著差异,这为他们的市场细分和推广战略提供了有力的支持。
综上所述,聚类分析是一个有用的数据分析方法,可以帮助企业了解客户群体的特征和需求,从而更好地进行市场细分和定位。
通过对数据的预处理、选择合适的聚类算法和聚类数量,以及对聚类结果的分析,企业可以获得有关客户群体的深入洞察,并为营销决策提供有力的支持。
聚类分析的算法及应用共3篇聚类分析的算法及应用1聚类分析的算法及应用聚类分析(Cluster Analysis)是一种数据分析方法,它根据数据的相似度和差异性,将数据分为若干个组或簇。
聚类分析广泛应用于数据挖掘、文本挖掘、图像分析、生物学、社会科学等领域。
本文将介绍聚类分析的算法及应用。
聚类分析的算法1. 基于距离的聚类分析基于距离的聚类分析是一种将数据点归类到最近的中心点的方法。
该方法的具体实现有单链接聚类(Single-Linkage Clustering)、完全链接聚类(Complete-Linkage Clustering)、平均链接聚类(Average-Linkage Clustering)等。
其中,单链接聚类是将每个点最近的邻居作为一个簇,完全链接聚类是将所有点的最小距离作为簇间距离,平均链接聚类是将每个点和其他点的平均距离作为簇间距离。
2. 基于密度的聚类分析基于密度的聚类分析是一种将数据点聚集在高密度区域的方法。
该方法的主要算法有密度峰(Density Peak)、基于DBSCAN的算法(Density-Based Spatial Clustering of Applications with Noise)等。
其中,密度峰算法是通过计算每个点在距离空间中的密度,找出具有局部最大密度的点作为聚类中心,然后将其余点分配到聚类中心所在的簇中。
而基于DBSCAN的算法则是将高密度点作为聚类中心,低密度点作为噪声,并将边界点分配到不同的聚类簇中。
3. 基于层次的聚类分析基于层次的聚类分析是通过不断将相似的点合并为一个组或将簇一分为二的方法。
该方法的主要算法有自顶向下层次聚类(Top-Down Hierarchical Clustering)和自底向上层次聚类(Bottom-Up Hierarchical Clustering)。
其中,自顶向下层次聚类从所有数据点开始,将数据点分为几个组,并不断通过将组合并为更大的组的方式,直到所有的数据点都被合并。
安徽工程大学本科课程设计(论文)专业:题目:基于聚类分析方法的农村消费状况探索作者姓名: ***指导老师:成绩:年月日摘要多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法。
近30年来,随着计算机应用技术的发展和科研生产的迫切需要,多元统计分析被广泛应用于自然学科和社会科学的各个学科,已经成为人们解决实际问题不可或缺的重要工具。
我国是一个农业大国,农民约占全国总人口的70%以上,是最大的消费群体,进行研究时要处理大量的复杂信息,因此运用统计方法探索农村消费状况有着重要的实际意义。
本文首先从我国农村消费现状入手,采用聚类分析方法对我国各地区农村消费支出结构水平进行分类比较研究,以得出各因素对农村消费状况影响程度,进而得出了相应的结论并提出增加我国农村居民消费的对策:一是增加农村居民收入;二是提高消费者素质;三是改善农村居民的消费环境;四是完善农村社会保障;五是统筹协调发展。
本文所研究的农村消费状况就受多种因素支配,各种因素之间也常存在着一定的内在联系和相互制约。
需要分析哪些是主要的,本质的,哪些是次要的,片面的,他们之间是什么样的关系等问题,多元统计分析正是解决这些问题的有力工具。
因而利用统计方法中的聚类分析有着重要的应用价值。
关键词:农村;消费;聚类分析引 言经过改革开放三十年的风雨历程,在投资、消费和出口三驾马车的拉动下,我国经济飞速发展,人民生活水平日益提高,居民收入不断增长,全面建设小康社会取得重大进展,实现了人民生活由温饱不足向总体小康的历史性跨越。
十七届三中全会提出“到2020年,农村改革发展基本目标任务是:农村经济体制更加健全,城乡经济社会发展一体化体制机制基本建立;现代农业建设取得显著进展,农业综合生产能力明显提高,国家粮食安全和主要农产品供给得到有效保障;农民人均纯收入比2008年翻一番,消费水平大幅提升,绝对贫困现象基本消除[1]。
”党中央正式把提升农村居民消费水平作为未来我国经济发展的目标,不仅体现了改革开放给农村居民生活所带来的显著变化,更体现了整个中国居民的整体消费水平的增长,借此稳定中国的经济基础,实现国民经济的可持续发展的长远规划。
随着党中央对农村消费的重视,社会各界对农村居民消费的关注程度不断增加,出现了大量对农村居民消费的研究成果。
朱信凯、雷海章和王宏伟,采用了相对收入理论研究我国农村居民消费行为。
刘建国和李锐、项海荣在弗里德曼的持久收入假说消费理论框架下,对我国农村居民消费倾向进行研究。
汪宏驹、张慧莲从流动性约束角度剖析了我国农村居民消费行为。
西方经济学的消费理论一般突出收入是影响消费的主要因素。
凯恩斯的绝对收入假说认为,消费是由收入唯一决定的,消费和收入之间存在稳定的函数关系。
杜森贝利的相对收入假说认为,消费者的消费支出水平不仅受当前收入水平的影响。
也受自己历史上曾经实现的消费水平的影响,这种现象被称为消费的“不可逆性”。
毫无疑问,国内有关此类问题的研究还处于理论阶段,与国外相比仍有很大差距,有待进一步扩展和深入。
评价指标的选取:探索农村消费状况,必须建立适当的指标体系。
但由于消费指标的复杂性和多样性,各指标的选取要遵循以下原则: (1) 选取的指标能客观地反映农村消费状况主要方面;(2) 指标之间基本上相互独立; (3) 尽量选取相对指标。
本文选取了食品(1X )、衣着(2X )、居住(3X )、家庭设备及服务(4X )、交通和通讯(5X )、文教娱乐用品及服务(6X )、医疗保健(7X )、其他商品及服务(8X )[2]。
第1章绪论1.1选题背景改革开放30多年来,我国经济一直保持高速增长。
伴随着经济的高增长,我国居民的总体收入水平也相应大幅提高,人民生活质量已基本达到小康水平,同时收入分配的格局发生了重大变化,个人收入来源日趋多样化。
但是随着个人收入取得的市场化程度提高,出现了个人收入分配差距过大的情况,而且这种趋势越来越显著。
在经过2008年重大自然灾害后,我国又面临着国际金融危机的蔓延和巨大冲击。
近十年来,我国的经济规模不断扩大。
2008年GDP总量已超过30万亿元,居世界第三位。
然而,虽然经济蛋糕做大了,但国内居民享用的份额却在不断下降,其突出的特征是投资率和消费率的变化。
我国近十年平均投资率在20%以上,比世界平均投资率(20% 左右)高出近20 个百分点;近十年平均最终消费率为36.6%,比世界平均消费率(78%左右)低20多个百分点。
我国的消费率不仅大大低于世界平均水平,并长期呈下降趋势。
目前我国最终消费率过低,在很大程度上是由于居民消费持续走低造成的。
我国居民消费率从1998 年的76% 下降到2007年的72.7%,达到历史最低水平;与此同时,城乡居民消费差距持续扩大。
在居民消费支出构成中,城镇居民和农村居民的消费比重比十年前年分别提高和下降11.3个百分点。
由于最终消费率长期偏低,国内居民消费需求增长缓慢,经济增长过份依赖投资和出口。
三大需求对GDP增长的贡献率,近十年投资的贡献率由1998 年的26.2% 上升到2007 年的20.9%,而消费的贡献率则由37.1% 下降到39.2%,投资对GDP 增长的拉动作用明显增强,而消费的拉动作用明显减弱,导致了我国现阶段经济增长动力不足,国内经济形势严峻。
1.2研究意义作为一个发展中国家,拉动经济增长的最主要力量仍然是国内需求,而扩大国内需求的一个重要举措是刺激国内消费,而农民作为中国广大的消费群体,其消费水平和消费需求的变化直接关系到内需的政策的效果。
目前,农民生活水平虽然有显著提高,但是农民消费仍然不足。
长期以来农村消费市场启而不动、发展缓慢,这已经影响到整个国民经济的健康发展。
同时,我国投资与消费的长期失衡孕育着经济运行的巨大风险消费率偏低,投资率过高,往往造成产能过剩,产品供过于求矛盾突出,导致企业效益下降,失业率增加;还造成内需不足后国内企业为求出路只能寻求海外市场,从而导致出口压力增大,人民币升值压力加大,外部风险加大;更为严重的是,居民消费率持续过低,不但使投资行为有可能偏离目标,即投资为了创造财富,最终为了消费而且终将使投资行为缺乏最终消费的强力支持而难以为继,进而造成经济的大起大落[3]。
因此研究中国农村居民消费状况,对于我国制定完善经济政策,改善农村居民消费结构,促进消费水平,进一步提高农民消费质量有重要的意义。
第2章 聚类分析2.1 基本思想聚类分析的基本思想是认为研究的样本或变量之间存在着程度不同的相似性,根据一批样本的多个观测指标,具体找出一些能够度量样本或指标之间相似程度的统计量,以这些统计量为划分类型的依据,把一些相似程度较大的样本(或变量)聚合为一类,把另外一些彼此之间相似程度较大的样本(变量)也聚合为一类,关系密切的聚合到一个小的分类单位,关系疏远的聚合到一个大的分类单位,直到把所有的样本(或变量)都聚合完毕,把不同的类型一一划分出来,形成一个由小到大的分类系统;最后再把整个分类系统画成一张图,将亲疏关系表示出来[2]。
2.2 系统聚类法就聚类分析的内容而言,可分为系统聚类法、有序样品聚类法、动态聚类法和模糊聚类法。
这里主要介绍系统聚类法。
系统聚类法的聚类过程如下:首先将所研究的每个事物对象自己看作一个类,计算相互之间的接近程度后,将最相近的先合并为一类。
然后,进一步计算类与类之间的距离,再合并相近的类,直至将所有对象合并为一个大类。
也就是说,系统聚类的过程实际上给出了从最细的分类(每个对象自己为一类)到最粗的分类(所有的对象归为一类)之间的所有分类结果。
最后,根据问题需要,可以将对象分为若干类,即选择聚类过程中的一个分类结果。
设有n 个样品,每个样品测得p 项指标(变量),原始资料阵为12 11121121222212pX X X p p n n np n x x x x x x x x X x x x x ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦(2-1) 其中(1,,;1,,)ij x i n j p ==为第i 个样品的第j 个指标的观测数据。
第i 个样品i x 为矩阵x 的第i 行所描述,所以任何两个样品k x 与L x 之间的相似性,可以通过矩阵x 中的第K 行与第L 行的相似程度来刻划;任何两个变量k X 与L X 之间的相似性,可以通过第K 列与第L 列的相似程度来刻画。
23 点与点之间距离的度量方法点与点之间的距离包括欧式距离(Euclideam distance )、欧式距离的平方(Squared Euclidean distance )、切比雪夫(Chebychev )距离、绝对值距离(Block )、明氏距离(Minkowski ),同时SPSS 还给出了一个自定义(Customized )的距离,它是一个绝对幂的度量,即变量之差绝对值的q 次幂之和的r 次根,q 与r 由用户指定。
另外还有相似系数Cosine (变量矢量的余弦)和Pearson correlation (皮尔森相关系数)。
距离和相似系数计算公式如下:欧式距离:(,)K L d x x =(2-2)欧式距离的平方: 21(,)()p K L Kj Lj j d x x x x ==-∑ (2-3)变量矢量的余弦:(,)pKj Lj K L xxCOSINE x x =∑ (2-2)皮尔森相关系数:()()pK L KjLj KJ xx x x r --=∑ (2-3)切比雪夫距离: 1(,)max K L Kj Lj j pd x x x x ≤≤=- (2-6) 绝对值距离: 1(,)pK L Kj Lj j d x x x x ==-∑ (2-7)明氏距离:(,)pK L j d x x == (2-8)自定义距离:1(,)pK L j d x x == (2-9)2.2 类之间距离的度量方法类与类之间的距离定义不同,就产生了8种不同的系统聚类方法:最短距离法(Nearest neighbor )、最长距离法(Furthest neighbor )、重心法(Centroid clustering )、中间距离法(Median clustering )、类平均法(Within-groups linkage )、可变类平均法(Between-groups )、离差平方和法(Ward )和可变法。
SPSS 给出了前7种,系统默认为可变类平均法。
这样由于所选择的聚类方法不同,往往聚类的结果会有些差异。
因此在应用中可以多选择几种方法聚类,找出共性的结果对一些有争议的可以使用判别分析解决。
下面列出了SPSS 的上述7种系统聚类方法及其类与类之间距离的定义。
其中ijd 表示类p G 的任意样品i X 与类q G 的任意样品j X 之间的距离;pq D 表示类p G 与q G 之间的距离;类r G 是由类p G 与q G 合并而成的新类,任意其他类k G 到类r G 的距离自然就记为kr D 。