分布式系统原理与范型考试 2010 答案
- 格式:pdf
- 大小:124.01 KB
- 文档页数:3

Department Computer Science Distributed Systems VU University15.12.2009 MAKE SURE THAT YOUR HANDWRITING IS READABLE1a Explain what is meant by request-level and message-level interceptors in middleware.5pt Request-level interceptors are special local components to which an invocation request is passed before passing it to the underlying middleware.Such an interceptor is invocation aware in the sense that it knows with which invocation it is dealing,and for which server it is intended.Typically,such interceptors can be used to implement replicated calls.A message-level interceptor is a component that is logically placed between the middleware and the underlying operating system.It can thus handle only basic network messages,for example,by fragmenting them into smaller parts(and assembling these parts at the receiver side).1b Where does the need for adaptive middleware come from?5pt Middleware is intended to incorporate general-purpose,i.e.,application-independent,mechanisms for distributed computing.The problem is that for practical purposes,it is very difficult to separate policy from mechanism,with the effect that many middleware solutions are not right for specific applications.The result is the need to be able to tweak the middleware for the specific needs of an application.1c In the underlying feedback control loop,give an example of the analysis component in combination with the reference input.5ptAn example that is also discussed in the book,is analyzing whether measured performance is as good as it could have been when another replication scenario would have been used.In this case, the reference input is a cost function that needs to be minimized.2a What is the difference between transport-layer switching and content-aware request distribution?5pt With transport-layer switching,a front end to a server cluster accepts incoming TCP connections and hands these off to one of the back-end servers using only information that is available at the TCP-level:client address and destination port.In the case of content-aware request distribution,the switch can also inspect the content of requests(such as an HTTP URL)and use that information to decide to which back-end server the request should be forwarded.2b Explain how TCP handoff works and why it is difficult to apply to wide-area networks.5pt With TCP handoff,an incoming connection request is forwarded by a switch to a specific server, which then sends the response back directly to the client,using the network address of the switch.This last issue is problematic is a wide-area system,as it essentially involves spoofing the switch, which is often difficult to do across administrative domains.2c Explain how the content-aware request distribution can be combined with TCP handoff.5pt Your answer should explain what is happening in Figure12-9.Essential is that you mention the initial handoff to a distributor or dispatcher to decide what the best server could be based on content, after which the TCP connection is handed off to that server.The switch is subsequently informed.3a Traditional RPC mechanisms cannot handle pointers.What is the problem and how can it be ad-dressed?5pt The problem is that pointers passed as parameters refer to a memory location that is local to the caller.That location is not only often meaningless to the receipient,but more important is that the recipient will most likely not have the data structure in its memory that the caller has.There are not many things you can do about this,except copying the entire(dynamic data structure)from the caller to the callee when doing the RPC.An alternative is to replace pointers by global systemwide references,as is done with Java object references.3b Where does the need for at-least-once and at-most-once semantics come from?Why can’t we have exactly-once semantics?5pt The problem originates from having a(suspected)server crash,detected by the lack of a response in the case of an RPC.What the client-side software can do is either resend the request until itfinally gets a response(at-least-once semantics)or immediately reports the failure to the client application, thus providing at-most-once semantics.Guaranteeing exactly-once semantics is,in principle,impos-sible,because you cannot know in general whether the server crashed before or after executing the requested operation.3c Consider a client/server system based on RPC,and assume the server is replicated for performance.Sketch an RPC-based solution for hiding replication of the server from the client.5pt Simply take a client-side stub that replicates the call to the respective servers.It is essential that you mention that these calls should be done in parallel and that(for example)thefirst response is immediately passed to the client.Serializing the RPCs or waiting for all responses is OK for fault tolerance,but certainly not for performance.4a Resolve the following key lookups for the shown Chord-based P2P system:5ptsource key41542221302127201815@4:14–18;22@4:20–21–28;30@21:28–1;27@21:28;18@20:4–14–184b Adjust thefinger tables of nodes18and14when a node with ID24enters the ring.Also give the finger table of node24.5pt Node18:[20,20,24,28,4];Node14:[18,18,18,24,1];Node24:[28,28,28,1,9].4c Chord allows keys to be looked up recursively or iteratively.Explain the differences,as well as the main advantage of iterative over recursive lookup.5pt With recursive lookups,a message is forwarded from peer to peer until it reaches its destination.In contrast,with an iterative lookup,the requester is returned the next peer it should ask for the key.One can argue that in the case of Chord,iterative lookups are much better:recursive lookups do not have the advantage of proximity-awareness.Also,note that iterative lookups have the advantage of letting the client handle failures more easily.5a Explain how two-phase commit works.5pt Make sure that you explain(1)coordinator sends vote-request;(2)participants respond;(3)coordi-nator sends decision;(4)participants ack.5b Explain what happens when a participant,who is in the READY state,times out because it hasn’t received a response from the coordinator yet.5pt In that case,P can check whether any of the other particpants has made a transition to either ABORT or INIT(in which case P can abort)or COMMIT(and commit as well).The difficulty is when all others are in READY:they all need to wait until the coordinator recovers.5c If we use two-phase commit for a distributed transaction,can we allow a coordinator to issue two distributed transactions(involving the same participants)at the same time?5pt Yes:the local transaction managers at the participants will handle any concurrency issues.What is seen here is that the use of2PC is completely independent of the semantics of specific transactions.6a How can a Web hosting service help in handlingflash crowds?5pt Crucial for a correct answer is that you not only state that content is replicated,but that the origin server is assumed to be capable of redirecting requests,but perhaps no longer in also returning content-rich responses.Note that distributed request distribution is really tricky business.6b Akamai uses DNS-based redirection.Explain how resolution of the name would work.5pt The trick is that the regular DNS will resolve the name ,pointing to a DNS server that is controlled by Akamai.If we use iterative DNS name resolution,that server will know the IP address ot the requesting client,and be able to decide to which server(with logical name )it can forward the request.6c Explain the difference between content-aware and content-blind caching for Web applications by means of an example.5pt With content-aware caching,the cache has knowledge on the data model that is used by the Web application,and with that,can conduct query-containment procedures to see whether a query could possibly be addressed by the data that is already cached.For example,if an edge server had once received the query“select ALL FROM books WITH author=Irving”,it can cache that ter, when receiving a query“select ALL FROM books WITH author=Irving AND date<2008”,the edge server should be able to recognize that this is a subquery,and that it can thus look into its local cache.With content-blind caching,the cache simply attaches a unique id to an entire,specific query in order to check whether that exact query had been issued before.If so,it can possibly return the previously stored response from its cache.In our example,the two queries would each get a unqiue ID,which is then used to do a cache lookup.Grading:Thefinal grade is calculated by accumulating the scores per question(maximum:90points),and adding10bonus points.The maximum total is therefore100points.。

分布式系统基础考试(答案见尾页)一、选择题1. 分布式系统的定义是什么?A. 由多个计算机组成的系统,这些计算机通过网络进行通信和协调B. 一个提供分布式服务的计算机系统C. 一种软件技术,使得应用程序可以跨多个硬件和操作系统运行D. 一种允许多个用户同时访问和操作的系统2. 分布式系统中的“分布式”一词的含义是什么?A. 多个系统独立运行B. 数据存储在多个位置C. 系统具有高可用性和容错性D. 所有节点都可以独立完成任务3. 分布式系统的核心特性是什么?A. 并发性B. 透明性C. 可伸缩性D. 容错性4. 分布式系统中的节点可以是哪种类型?A. 服务器B. 桌面电脑C. 移动设备D. 所有这些都可能5. 分布式系统中的通信协议有哪些?A. HTTPB. TCP/IPC. UDPD. 所有这些都可能6. 分布式系统中的数据一致性是指什么?A. 所有节点上的数据完全相同B. 所有节点上的数据保持同步更新C. 所有节点上的数据在某个时间点相同D. 所有节点上的数据可以不同7. 分布式系统中的负载均衡是什么?A. 将请求平均分配到多个服务器B. 将流量限制到单个服务器C. 将流量分散到多个服务器D. 将流量全部转发到单个服务器8. 分布式系统中的复制是什么?A. 在多个节点上创建数据的副本B. 将数据存储在远程位置C. 将数据加密D. 将数据存储在本地9. 分布式系统中的CAP理论指的是什么?A. 一致性、可用性和分区容错性之间的权衡B. 一致性、可用性和性能之间的权衡C. 一致性、可用性和可伸缩性之间的权衡D. 一致性、可用性和安全性之间的权衡10. 分布式系统中的分布式事务是什么?A. 一种需要在多个节点上同步执行的事务B. 一种可以在多个节点上并行执行的事务C. 一种不能在多个节点上同步执行的事务D. 一种可以在多个节点上同步执行但不需要一致性的事务11. 分布式系统的定义是什么?A. 一组独立的计算机通过网络进行通信和协作B. 一个硬件和软件的组合,能够在多个处理器上运行C. 一个提供分布式服务的互联网D. 一个由多个服务器组成的系统,每个服务器都有自己的资源12. 分布式系统中的“分布式”一词意味着什么?A. 多个系统组件位于不同的地理位置B. 多个系统组件共同工作以完成一项任务C. 多个系统组件独立地运行并相互通信D. 多个系统组件共享数据和资源13. 分布式系统中的节点可以是哪种类型?A. 主节点B. 从节点C. 客户端D. 所有类型的节点14. 分布式系统中的数据复制是为了什么目的?A. 提高系统性能B. 防止数据丢失C. 提高数据的可用性D. 保证数据的一致性15. 分布式系统中的负载均衡是一种什么技术?A. 将请求分配到多个服务器以优化性能B. 将流量限制到特定的服务器以避免拥塞C. 将客户端的请求直接路由到正确的服务器D. 使用一种算法来决定哪个服务器应该处理哪个请求16. 分布式系统中的共识算法是什么?A. 一种确保所有节点对数据的一致性达成一致的技术B. 一种用于同步不同节点之间的数据状态的技术C. 一种用于检测和处理网络延迟的技术D. 一种用于管理分布式系统中的故障的技术17. 分布式系统中的容错机制是什么?A. 一种确保系统在部分组件失败时仍能正常运行的技术B. 一种用于检测和修复系统错误的技术C. 一种用于保护系统免受恶意攻击的技术D. 一种用于限制系统中的用户数量的技术18. 分布式系统中的数据分片是什么?A. 将数据分割成小块以便于存储在不同的位置B. 将数据分割成小块以便于在不同的硬件设备上存储C. 将数据分割成小块以便于在不同的网络上进行传输D. 将数据分割成小块以便于在不同的时间点进行访问19. 分布式系统中的消息传递机制是什么?A. 一种用于在节点之间传递消息的技术B. 一种用于在节点之间同步数据的技术C. 一种用于在节点之间交换数据的技术D. 一种用于在节点之间协调任务的技术20. 分布式系统中的安全性是指什么?A. 保护系统免受未经授权的访问B. 保护系统免受未经授权的修改C. 保护系统免受未经授权的数据泄露D. 保护系统免受所有上述威胁21. 分布式系统的定义是什么?A. 一组计算机通过互联网进行通信和协调的系统B. 一个硬件和软件集合,能够在有限时间内处理大量数据C. 一个提供分布式服务的互联网系统D. 一种允许多个用户访问和共享资源的网络架构22. 分布式系统中的“分布式”一词意味着什么?A. 多个系统独立运行B. 数据存储在多个位置C. 系统具有高可用性和可扩展性D. 所有节点共同工作以完成特定任务23. 分布式系统的核心特性包括哪些?A. 可靠性B. 可用性C. 并发性D. 容错性24. 在分布式系统中,通常使用哪种通信协议?A. HTTPB. TCP/IPC. UDPD. ICMP25. 分布式系统中的“容错性”是什么意思?A. 系统在部分组件失败时仍能继续运行的能力B. 系统能够自动恢复丢失的数据或进程的能力C. 系统能够自我调整以避免单点故障的能力D. 系统能够确保所有节点之间的同步性26. 分布式数据库的概念是什么?A. 一个包含多个数据副本的数据库,以提高数据可用性和性能B. 一个只有一个数据副本的数据库C. 一个动态调整数据分布的数据库D. 一个支持实时数据更新的数据库27. 分布式系统的设计原则之一是什么?A. 高度集权B. 高度分散C. 高度可伸缩性28. 在分布式系统中,什么是“微服务”?A. 一种特定的编程风格或架构模式,其中应用程序被拆分成一系列小型服务B. 一种分布式系统的实现技术C. 一种单一的、集中的服务D. 一种特定的数据存储技术29. 分布式系统中的“同步”和“异步”有什么区别?A. 同步是指多个进程或线程在同一时间访问同一资源B. 异步是指多个进程或线程在不同的时间访问同一资源C. 同步通常用于需要数据一致性的场景D. 异步通常用于需要提高系统性能的场景30. 分布式系统的发展历程及其在不同领域中的应用有哪些?A. 分布式系统的发展始于20世纪80年代B. 分布式系统广泛应用于大数据处理、云计算、物联网等领域C. 分布式系统的发展受到了计算机网络技术的影响D. 分布式系统是现代计算机系统的基本组成部分31. 分布式系统的定义是什么?A. 一组通过网络进行通信的计算机系统B. 一个硬件和软件的组合,可以在多个位置进行数据处理和存储C. 一种允许多个服务器共享资源和数据的系统D. 一种设计用于处理大量数据并保证数据一致性的系统32. 分布式系统中的“分布式”一词意味着什么?A. 多个系统独立运行B. 资源共享C. 数据备份D. 所有这些都正确33. 分布式系统的核心特性是什么?B. 高可用性C. 任务无关性D. 资源共享34. 分布式系统中的“并发”是指什么?A. 同时执行多个任务B. 同时访问同一资源C. 同时处理多个数据流D. 同时修改数据库35. 以下哪个选项不是分布式系统中的常见同步问题?A. 机器之间的网络延迟B. 任务执行的先后顺序C. 共享资源的访问冲突D. 数据一致性问题36. 分布式系统中的“透明性”是指什么?A. 用户感觉好像所有的系统组件都在本地运行B. 系统管理员可以远程管理所有组件C. 应用程序的数据和代码在主机之间是可移植的D. 所有这些都正确37. 以下哪个分布式算法不是CAP定理中提到的?A. 客户端-服务器算法B. 一致性算法C. 分区容错算法D. 内容分发算法38. 分布式系统中的“分区容错”是什么意思?A. 在网络故障时,系统仍然可以运行B. 在网络分区时,系统能够继续运行C. 在网络拥堵时,系统仍然可以运行D. 在网络配置错误时,系统能够继续运行39. 以下哪个选项不是分布式系统中的常见性能指标?A. 响应时间B. 可扩展性C. 容错性D. 资源利用率40. 分布式系统与传统集中式系统的最大区别是什么?A. 可靠性更高B. 可伸缩性更好C. 无需依赖中央控制点D. 所有这些都正确二、问答题1. 什么是分布式系统?请简述其基本特性。

分布式系统原理与范型分布式系统是由多台计算机通过网络连接,共同协作完成任务的系统。
它具有高性能、高可靠性、可扩展性等优点,被广泛应用于大规模的数据处理、并行计算、云计算等领域。
在分布式系统中,各个计算机之间彼此独立,通过消息传递进行通信和协调,没有共享内存。
分布式系统的原理主要包括:并发性、透明性、故障容错、可扩展性和一致性。
首先是并发性原理,分布式系统中的多个计算机并行地执行任务,能够提高系统的处理能力。
并发性可以通过多线程、多进程等方式来实现,并且需要解决同步、互斥、死锁等并发控制问题。
其次是透明性原理,分布式系统希望对用户来说,就像是一个单一的计算机系统,隐藏了分布式部署的复杂性。
透明性包括:访问透明性(用户无感知地访问分布式系统)、位置透明性(用户无需关心数据的物理位置)、迁移透明性(用户无需关心资源在系统中的迁移)、复制透明性(用户无需关心数据的副本)、并发透明性(用户无需关心并发访问的问题)等。
第三是故障容错原理,分布式系统中的计算机节点可能会发生故障,为了保证系统的可靠性,需要进行故障检测、故障恢复和容错处理。
例如,使用冗余备份、错误检测和纠错码等技术来检测和修复故障,确保系统可以继续正常运行。
第四是可扩展性原理,分布式系统需要能够方便地扩展计算资源,以应对数据量和任务量的增长。
可扩展性可以通过水平扩展和垂直扩展来实现。
水平扩展是增加计算机节点的数量,垂直扩展是增加单个计算机节点的处理能力。
最后是一致性原理,分布式系统中的数据可能被存储在不同的节点上,而多个节点之间需要保持一致的数据视图。
一致性可以通过强一致性和弱一致性来实现。
强一致性要求所有的节点都能观察到同样的数据视图,而弱一致性则容忍一定的数据不一致性。
分布式系统有多种范型,包括客户端-服务器模型、对等模型、发布-订阅模型等。
客户端-服务器模型是最常见的分布式系统范型,其中一台计算机作为服务器提供服务,而其他计算机作为客户端请求服务。

一、选择题概述1、下列哪项描述不是分布式系统的特性( C )A、透明性B、开放性C、易用性D、可扩展性3、下列描述正确的是( A )A、基于中间件的系统要比网络操作系统的透明性高√B、网络操作系统要比分布式操作系统的透明性高×C、基于中间件的系统要比分布式操作系统的透明性高×D、分布式操作系统可以运行在异构多计算机系统中4、从下面关于网络操作系统的原理图中可以看出( B )A、网络操作系统是紧耦合系统,因而只能运行在同构多计算机系统中×B、网络操作系统不要求各计算机上的操作系统同构√C、运行于网络操作系统之上的分布式应用程序可以取得很高的透明性×D、网络操作系统可以作为一个全局的单一的系统进行方便的管理×5、在网络操作系统之上采用中间件技术加入中间件层,主要可以( D )A、弥补网络操作系统在可扩展性方面的缺陷B、弥补网络操作系统在可开放性方面的缺陷C、提高网络操作系统的稳定性D、提高网络操作系统的透明性1、下列描述不是分布式系统目标的是( C )A、连接用户和资源B、透明性C、异构性D、开放性以及可扩展性。
2、下列系统中有共享内存的系统是( B )A、同构多计算机系统B、多处理器系统C、异构多计算机系统D、局域网系统3、下述系统中,能运行于同构多计算机系统的操作系统是( A )A、分布式操作系统B、网络操作系统C、中间件系统D、嵌入式操作系统4、多计算机系统的主要通信方式是( B )A、共享内存B、消息传递C、文件传输D、TCP/IP协议6、下列描述中,不属于C/S三层模型中是( C )A、用户界面层B、数据层C、通信层D、处理层2、透明度最高的操作系统是( A )A、多处理器分布式操作系统B、多计算机分布式操作系统C、网络操作系统D、基于中间件的操作系统3、下图所示典型C/S模型交互过程中,假设客户端是阻塞的,则其阻塞时间为( A? )A、T4-T1B、T4-T2C、T3-T2D、T3-T14、分布式系统的中间件协议位于网络通信协议体系的( D )A、传输层B、数据链路层C、网络层D、应用层6、C/S模型中,核心处理函数由哪一层实现( D )A、用户界面层B、数据层C、通信层D、中间层11、网络操作系统要求其管理的各计算机( B )A、硬件同构(不要求)B、通信协议一致或者相互兼容C、操作系统同构(不要求)D、安装相同的中间件1、分布式系统的透明性是指( B )A、用户不需要关心任何操作B、用户不需要关心系统实现的细节C、系统不需要关心用户的操作细节D、系统不需要关心用户的操作过程3、下列处理器与内存关系示意图中,属于多计算机系统结构的是( D?)A、B、C、D、4、中间件系统与分布式操作系统有比较好的 A ,与网络操作系统相比有比较好的 AA、可扩展性和开放性,透明性和易用性B、可扩展性和透明性,开放性和易用性C、透明性和易用性,可扩展性和开放性C、透明性和开放性,可扩展性和易用性17、透明度最高的系统是( C )A、网络操作系统B、中间件系统C、分布式操作系统D、松耦合系统5、中间件协议位于网络协议体系的( D )A、传输层B、会话层C、网络层D、应用层通信5、异步通信中,消息由客户进程首先送给( A? )A、服务器缓冲区B、服务器进程C、客户端缓冲区D、网络10、RPC中,客户调用的接口称为( A? )A、客户存根B、服务器存根C、远程对象接口D、消息接口14、电子邮件系统通信方式属于( B )A、暂时通信B、持久通信C、中间层通信D、RPC通信7、RPC通信过程中,服务器存根把服务器执行的结果打成消息包,提交给( A )A、服务器操作系统B、客户存根C、客户操作系统D、服务器( A? )6、RPC 通信中,客户存根和服务器存根都包含一组调用接口,它们是否包含这些接口的实现? ( D??? ) A 、客户存根包含,服务器存根不包含B 、都不包含C 、客户存根不包含,服务器存根包含D 、都包含进程8、下图为重复服务器与并发服务器组织方式。

分布式数据库系统考试(答案见尾页)一、选择题1. 分布式数据库系统的定义是什么?A. 一种将数据存储在多个地理位置的数据库系统中,通过分布式计算框架来管理和访问数据的一种技术。
B. 一种单一的集中式数据库系统,所有数据都存储在一个服务器上。
C. 一种将数据分割成多个部分,并分布存储在不同的服务器上的数据库系统。
D. 一种不依赖于单一服务器的数据库系统,数据可以跨多个服务器进行存储和访问。
2. 分布式数据库系统的优点包括哪些?A. 提高数据处理速度和效率。
B. 降低单点故障的风险。
C. 更好的数据冗余和容错能力。
D. 扩展性更强,可以更容易地添加新的数据和节点。
3. 以下哪个不是分布式数据库系统中的常见拓扑结构?A. 星形拓扑B. 环形拓扑C. 网状拓扑D. 树形拓扑4. 在分布式数据库系统中,什么是分片?A. 将整个数据库系统的数据分成多个部分,每个部分存放在一个单独的节点上。
B. 将数据库系统的一个或多个表按照某种规则分成多个部分。
C. 将数据库系统的数据按照某种规则分成多个部分,每个部分存放在一个单独的节点上。
D. 将数据库系统的一个或多个表按照某种规则分成多个部分,并存放在不同的节点上。
5. 在分布式数据库系统中,什么是复制?A. 将数据库系统的数据复制到多个节点上,以确保数据的可靠性和可用性。
B. 将数据库系统的数据存储在多个地理位置,以确保数据的可靠性和可用性。
C. 将数据库系统的数据按照某种规则分成多个部分,并存放在不同的节点上。
D. 将数据库系统的一个或多个表按照某种规则分成多个部分,并存储在不同的节点上。
6. 在分布式数据库系统中,什么是分布式事务?A. 一种需要在多个节点上同步更新数据的事务处理方式。
B. 一种可以在多个节点上并行处理的事务处理方式。
C. 一种需要确保数据的一致性和完整性的事务处理方式。
D. 一种可以在多个节点上同时执行的事务处理方式。
7. 分布式数据库系统中的数据一致性是指什么?A. 数据在多个节点上保持一致的状态。

分布式课后习题答案第⼀章分布式数据库系统概述1.1请⽤⾃⼰的语⾔定义下列分布式数据库系统中的术语:(1)局部数据:只提供本站点的局部应⽤所需要的数据。
全局数据:虽然物理上存储在个站点上,但是参与全局应⽤(2)全局/局部⽤户:局部⽤户:⼀个⽤户或⼀个应⽤如果只访问他注册的那个站点上的数据称为本地或局部⽤户或本地应⽤;全局⽤户:如果访问涉及两个或两个以上的站点中的数据,称为全局⽤户或全局应⽤。
全局/局部DBMS:1)LDBMS(Local DBMS):局部场地上的数据库管理系统,其功能是建⽴和管理局部数据库,提供场地⾃治能⼒,执⾏局部应⽤及全局查询的⼦查询。
(2)GDBMS(Global DBMS):全局数据库管理系统,主要功能是提供分布透明性,协调全局事物的执⾏,协调各局部DBMS 以完成全局应⽤,保证数据库的全局⼀致性,执⾏并发控制,实现更新同步,提供全局恢复功能等。
(3)全局外模式:全局应⽤的⽤户视图,也称全局视图。
从⼀个由各局部数据库组成的逻辑集合中抽取,即全局外模式是全局概念式的⼦集。
对全局⽤户⽽⾔,都可以认为在整个分布式数据库系统的各个站点上的所有数据库都如同在本站点上⼀样,只关⼼他们⾃⼰所使⽤的那部分数据(4)全局概念模式:描述分布式数据库中全局数据的逻辑结构和数据特性,是分布式数据库的全局概念视图。
采⽤关系模型的全局概念模式由⼀组全局关系的定义(如关系名、关系中的属性、每⼀属性的数据类型和长度等)和完整性定义(关系的主键、外键及完整性其他约束条件等)组成。
(5)分⽚模式:描述全局数据的逻辑划分。
每个全局关系可以通过选择和投影的关系操作被逻辑划分为若⼲⽚段。
分⽚模式描述数据分⽚或定义⽚段,以及全局关系与⽚段之间的映像。
这种映像是⼀对多的。
(6)分配模式:根据选定的数据分布策略,定义各⽚段的物理存放站点,即定义⽚段映像的类型,确定分布式数据库是冗余的还是⾮冗余的,以及冗余的程度。
如果⼀个⽚段分配在多个站点上,则⽚段的映像是⼀对多的,分布式数据库是冗余的,否则是不冗余的。

2010年全国自考数据库系统原理模拟试卷(六)及答案2010年全国自考数据库系统原理模拟试卷(六)一、单项选择题(本大题共15小题,每小题2分,共30分)在每小题列出的四个备选项中只有一个是符合题目要求的,请将其代码填写在题后的括号内。
错选、多选或未选均无分。
1.在定义分布式数据库的各种片段时,必须遵守的条件是:完备性条件,不相交条件和()A.安全性条件B.数据一致性条件C.重构条件D.数据完整性条件答案:C2.SQL的“CREATE UNIQUE INDEX…”语句中UNIQUE表示基本表中()A.索引键值不可分解B.索引键值都是惟一的C.没有重复元组D.没有重复列值答案:B3.()位于分片视图与分配视图之间。
A.分片透明性B.位置透明性C.局部数据模型透明性D.复制透明性答案:B4.在多用户共享系统中,并发操作的事务互相干扰,破坏了事务的()A.原子性B.一致性C.隔离性D.持久性答案:C5.SQL是介于()之间的一种关系查询语言。
A.关系代数和域演算B.元组演算和域演算C.关系代数和元组演算D.关系代数和集合运算答案:C6.假定学生关系是S(S#,SNAME,SEX,AGE),课程关系是C(C#,CNAME,TEACHER),学生选课关系是SC(S#,C#,GRADE)。
要查找选修“COMPUTER”课程的“女”学生姓名,将涉及到关系()A.SB.SC,CC.S,SCD.S,C,SC答案:D7.数据的管理方法主要有()A.批处理和文件系统B.文件系统和分布式系统C.分布式系统和批处理D.数据库系统和文件系统答案:D8.在E-R图和数据流图中都使用了方框,下列说法中有错误的是()A.在E-R图中表示实体B.在E-R图中表示属性C.在数据流图中表示起点D.在数据流图中表示终点答案:B9.超类与子类间的关系是()A.超类实体继承子类实体的所有属性B.子类实体继承超类实体的所有属性C.超类实体继承子类实体的主码D.子类实体继承超类实体的主码答案:B10.避免活锁采用的简单策略是()A.顺序封锁法B.依次封锁法C.按优先级确定服务顺序D.先来先服务答案:D11.在SQL语言中,()子句能够实现关系参照性规则。


关于分布式系统复习题与参考答案一、填空题(每题n分,答错个扣分,全错全扣,共计m分)1.下面特征分别属于计算机网络和分布式计算机系统,请加以区别:分布式计算机是指系统内部对用户是完全透明的;系统中的计算机即合作又自治;系统可以利用多种物理和逻辑资源,可以动态地给它们分配任务。
计算机网络是指互连的计算机是分布在不同地理位置的多台独立的“自治计算机”。
2.点到点通信子网的拓扑结构主要有以下几种:星型、环型、树型、网状型,请根据其特征填写相应结构。
网状型:结点之间的连接是任意的,没有规律。
环型:节点通过点到点通信线路连接成闭合环路。
星型:节点通过点到点通信线路与中心结点相连;树型:结点按层次进行连接。
3.分布式计算系统可以分为两个子组,它们是集群计算系统和网格计算系统。
4.分布式事务处理具有4个特性,原子性:对外部来说,事务处理是不可见的;一致性:事务处理不会违反系统的不变性;独立性:并发的事务处理不会相互干扰;持久性:事务处理一旦提交,所发生的改变是永久性的。
5.网络协议有三要素组成,时序是对事件实现顺序的详细说明;语义是指需要发出何种控制信息,以及要完成的动作与作出的响应;语法是指用户数据与控制信息的结构与格式6.根据组件和连接器的不同,分布式系统体系结构最重要的有4种,它们是:分层体系结构、基于对象的体系结构、以数据为中心的体系结构、基于事件的体系结构7.在客户-服务器的体系结构中,应用分层通常分为3层,用户接口层、处理层和数据层。
8.有两种类型的分布式操作系统,多处理器操作系统和多计算机操作系统。
9.软件自适应的基本技术有3种,一是要点分离、二是计算映像、三是基于组件的设计。
10.DCE本身是由多个服务构成的,常用的有分布式文件系统、目录服务、安全服务以及分布式时间服务等。
11.TCP/IP体系结构的传输层上定义的两个传输协议为传输控制协议(TCP)和用户数据报协议(UDP)。
12.Windows NT的结构借用了层次模型和客户/服务器两种模型。

分布式系统原理与范型课后习题答案专业专心专注第一章绪论1、中间件在分布式系统中扮演什么角色,答:中间件主要是为了增强分布式系统的透明性(这正是网络操作系统所缺乏的),换言之,中间件的目标是分布式系统的单系统视图。
2、解释(分布)透明性的含义,并且给出各种类型透明性的例子。
答:分布透明性是一种现象,即一个系统的分布情况对于用户和应用来说是隐藏的。
包括:访问透明、位置透明、移植透明、重定位透明、复制透明、并发透明、故障透明和持久性透明。
3、在分布式系统中,为什么有时难以隐藏故障的发生以及故障恢复过程,答:通常,要探测一个服务器是停止服务还是该服务器的反应变慢这些情况是不可能的。
因此,一个系统可能在服务响应变慢的时候报告该服务已经停止了。
4、为什么有时候要求最大程度地实现透明性并不好,答:最大程度地实现透明性可能导致相当大的性能损失,从而导致用户无法接受。
5、什么是开放的分布式系统,开放性带来哪些好处,答:开放的分布式系统根据明确定义的规则来提供服务。
开放系统能够很容易地与其它系统协作,同时也允许应用移植到同一个系统的不同实现中。
6、请对可扩展系统的含义做出准确描述答:一个系统的可扩展包含下面几个方面:组件的数量、几何尺寸、管理域的数量与尺寸,前提是这个系统可以在上面几个方面进行增加而不会导致不可接受的性能损失。
7、可以通过应用多种技术来取得可扩展性。
请说出这些技术。
答:可扩展性可以通过分布式、复制和缓存来获得。
8、多处理器系统与多计算机系统有什么不同,答:在多处理器系统中,多个CPU访问共享的主存储器。
在多计算机系统中没有共享存储器,CPU之间只能通过消息传递来进行通信。
9、在多计算机系统中的256个CPU组成了一个16 X 16的网格方阵。
在最坏的情况下,消息的延迟时间有多长(以跳(hop)的形式给出,跳是结点之间的逻辑距离),答:假设路由是最优的,最长的路由是从网格方阵的一个角落到对角的角落。
那么这个路由的长度是30跳。
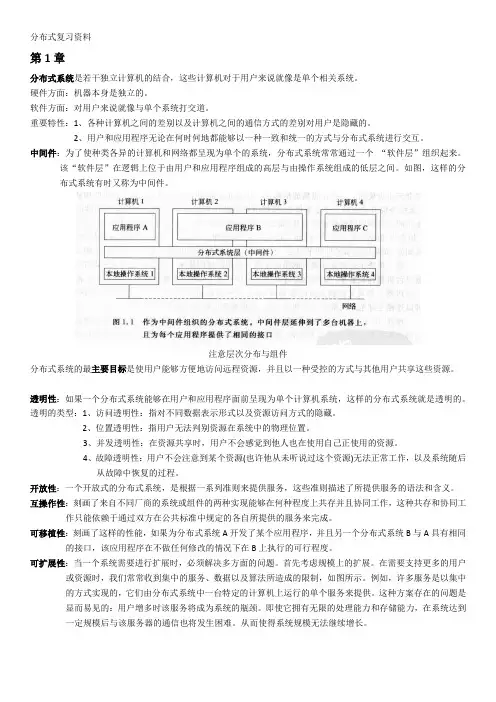
分布式复习资料第1章分布式系统是若干独立计算机的结合,这些计算机对于用户来说就像是单个相关系统。
硬件方面:机器本身是独立的。
软件方面:对用户来说就像与单个系统打交道。
重要特性:1、各种计算机之间的差别以及计算机之间的通信方式的差别对用户是隐藏的。
2、用户和应用程序无论在何时何地都能够以一种一致和统一的方式与分布式系统进行交互。
中间件:为了使种类各异的计算机和网络都呈现为单个的系统,分布式系统常常通过一个“软件层”组织起来。
该“软件层”在逻辑上位于由用户和应用程序组成的高层与由操作系统组成的低层之间。
如图,这样的分布式系统有时又称为中间件。
注意层次分布与组件分布式系统的最主要目标是使用户能够方便地访问远程资源,并且以一种受控的方式与其他用户共享这些资源。
透明性:如果一个分布式系统能够在用户和应用程序面前呈现为单个计算机系统,这样的分布式系统就是透明的。
透明的类型:1、访问透明性:指对不同数据表示形式以及资源访问方式的隐藏。
2、位置透明性:指用户无法判别资源在系统中的物理位置。
3、并发透明性:在资源共享时,用户不会感觉到他人也在使用自己正使用的资源。
4、故障透明性:用户不会注意到某个资源(也许他从未听说过这个资源)无法正常工作,以及系统随后从故障中恢复的过程。
开放性:一个开放式的分布式系统,是根据一系列准则来提供服务,这些准则描述了所提供服务的语法和含义。
互操作性:刻画了来自不同厂商的系统或组件的两种实现能够在何种程度上共存并且协同工作,这种共存和协同工作只能依赖于通过双方在公共标准中规定的各自所提供的服务来完成。
可移植性:刻画了这样的性能,如果为分布式系统A开发了某个应用程序,并且另一个分布式系统B与A具有相同的接口,该应用程序在不做任何修改的情况下在B上执行的可行程度。
可扩展性:当一个系统需要进行扩展时,必须解决多方面的问题。
首先考虑规模上的扩展。
在需要支持更多的用户或资源时,我们常常收到集中的服务、数据以及算法所造成的限制,如图所示。
DISTRIBUTED SYSTEMS PRINCIPLES AND PARADIGMS PROBLEM SOLUTIONS ANDREW S.TANENBAUM MAARTEN VAN STEEN Vrije Universiteit Amsterdam,The Netherlands PRENTICE HALL UPPER SADDLE RIVER,NJ 07458w w w .k h d a w .c o m 课后答案网SOLUTIONS TO CHAPTER 1PROBLEMS1.Q:What is the role of middleware in a distributed system?A:To enhance the distribution transparency that is missing in network operat-ing systems.In other words,middleware aims at improving the single-system view that a distributed system should have.2.Q:Explain what is meant by (distribution)transparency,and give examples of different types of transparency.A:Distribution transparency is the phenomenon by which distribution aspects in a system are hidden from users and applications.Examples include access transparency,location transparency,migration transparency,relocation tran-sparency,replication transparency,concurrency transparency,failure tran-sparency,and persistence transparency.3.Q:Why is it sometimes so hard to hide the occurrence and recovery from failures in a distributed system?A:It is generally impossible to detect whether a server is actually down,or that it is simply slow in responding.Consequently,a system may have to report that a service is not available,although,in fact,the server is just slow.4.Q:Why is it not always a good idea to aim at implementing the highest degree of transparency possible?A:Aiming at the highest degree of transparency may lead to a considerable loss of performance that users are not willing to accept.5.Q:What is an open distributed system and what benefits does openness pro-vide?A:An open distributed system offers services according to clearly defined rules.An open system is capable of easily interoperating with other open sys-tems but also allows applications to be easily ported between different imple-mentations of the same system.6.Q:Describe precisely what is meant by a scalable system.A:A system is scalable with respect to either its number of components,geo-graphical size,or number and size of administrative domains,if it can grow in one or more of these dimensions without an unacceptable loss of perfor-mance.7.Q:Scalability can be achieved by applying different techniques.What arethese techniques?A:Scaling can be achieved through distribution,replication,and caching.w w w .k h d a w .c o m 课后答案网2PROBLEM SOLUTIONS FOR CHAPTER 18.Q:What is the difference between a multiprocessor and a multicomputer?A:In a multiprocessor,the CPUs have access to a shared main memory.There is no shared memory in multicomputer systems.In a multicomputer system,the CPUs can communicate only through message passing.9.Q:A multicomputer with 256CPUs is organized as a 16×16grid.What is the worst-case delay (in hops)that a message might have to take?A:Assuming that routing is optimal,the longest optimal route is from one corner of the grid to the opposite corner.The length of this route is 30hops.If the end processors in a single row or column are connected to each other,the length becomes 15.10.Q:Now consider a 256-CPU hypercube.What is the worst-case delay here,again in hops?A:With a 256-CPU hypercube,each node has a binary address,from 00000000to 11111111.A hop from one machine to another always involves changing a single bit in the address.Thus from 00000000to 00000001is one hop.From there to 00000011is another hop.In all,eight hops are needed.11.Q:What is the difference between a distributed operating system and a net-work operating system?A:A distributed operating system manages multiprocessors and homogene-ous multicomputers.A network operating system connects different indepen-dent computers that each have their own operating system so that users can easily use the services available on each computer.12.Q:Explain how microkernels can be used to organize an operating system in a client-server fashion.A:A microkernel can separate client applications from operating system ser-vices by enforcing each request to pass through the kernel.As a consequence,operating system services can be implemented by (perhaps different)user-level servers that run as ordinary processes.If the microkernel has networking capabilities,there is also no principal objection in placing those servers on remote machines (which run the same microkernel).13.Q:Explain the principal operation of a page-based distributed shared memory system.A:Page-based DSM makes use of the virtual memory capabilities of an operating system.Whenever an application addresses a memory location thatis currently not mapped into the current physical memory,a page fault occurs,giving the operating system control.The operating system can then locate the referred page,transfer its content over the network,and map it to physical memory.At that point,the application can continue.w w w .k h d a w .c o m 课后答案网PROBLEM SOLUTIONS FOR CHAPTER 1314.Q:What is the reason for developing distributed shared memory systems?What do you see as the main problem hindering ef ficient implementations?A:The main reason is that writing parallel and distributed programs based on message-passing primitives is much harder than being able to use shared memory for communication.Ef ficiency of DSM systems is hindered by the fact,no matter what you do,page transfers across the network need to take place.If pages are shared by different processors,it is quite easy to get into a state similar to thrashing in virtual memory systems.In the end,DSM sys-tems can never be faster than message-passing solutions,and will generally be slower due to the overhead incurred by keeping track of where pages are.15.Q:Explain what false sharing is in distributed shared memory systems.What possible solutions do you see?A:False sharing happens when data belonging to two different and indepen-dent processes (possibly on different machines)are mapped onto the same logical page.The effect is that the page is swapped between the two processes,leading to an implicit and unnecessary dependency.Solutions include making pages smaller or prohibiting independent processes to share a page.16.Q:An experimental file server is up 3/4of the time and down 1/4of the time,due to bugs.How many times does this file server have to be replicated to give an availability of at least 99%?A:With k being the number of servers,we have that (1/4)k <0.01,expressing that the worst situation,when all servers are down,should happen at most 1/100of the time.This gives us k =4.17.Q:What is a three-tiered client-server architecture?A:A three-tiered client-server architecture consists of three logical layers,where each layer is,in principle,implemented at a separate machine.The highest layer consists of a client user interface,the middle layer contains the actual application,and the lowest layer implements the data that are being used.18.Q:What is the difference between a vertical distribution and a horizontal dis-tribution?A:Vertical distribution refers to the distribution of the different layers in a multitiered architectures across multiple machines.In principle,each layer is implemented on a different machine.Horizontal distribution deals with the distribution of a single layer across multiple machines,such as distributing asingle database.19.Q:Consider a chain of processes P 1,P 2,...,P n implementing a multitieredclient-server architecture.Process P i is client of process P i +1,and P i will return a reply to P i −1only after receiving a reply from P i +1.What are the w w w .k h d a w .c o m 课后答案网4PROBLEM SOLUTIONS FOR CHAPTER 1main problems with this organization when taking a look at the request-reply performance at process P 1?A:Performance can be expected to be bad for large n .The problem is that each communication between two successive layers is,in principle,between two different machines.Consequently,the performance between P 1and P 2may also be determined by n −2request-reply interactions between the other layers.Another problem is that if one machine in the chain performs badly or is even temporarily unreachable,then this will immediately degrade the per-formance at the highest level.w w w .k h d a w .c o m 课后答案网5SOLUTIONS TO CHAPTER 2PROBLEMS1.Q:In many layered protocols,each layer has its own header.Surely it would be more ef ficient to have a single header at the front of each message with all the control in it than all these separate headers.Why is this not done?A:Each layer must be independent of the other ones.The data passed from layer k +1down to layer k contains both header and data,but layer k cannot tell which is which.Having a single big header that all the layers could read and write would destroy this transparency and make changes in the protocol of one layer visible to other layers.This is undesirable.2.Q:Why are transport-level communication services often inappropriate for building distributed applications?A:They hardly offer distribution transparency meaning that application developers are required to pay signi ficant attention to implementing commun-ication,often leading to proprietary solutions.The effect is that distributed applications,for example,built directly on top of sockets are dif ficult to port and to interoperate with other applications.3.Q:A reliable multicast service allows a sender to reliably pass messages to a collection of receivers.Does such a service belong to a middleware layer,or should it be part of a lower-level layer?A:In principle,a reliable multicast service could easily be part of the trans-port layer,or even the network layer.As an example,the unreliable IP multi-casting service is implemented in the network layer.However,because such services are currently not readily available,they are generally implemented using transport-level services,which automatically places them in the middleware.However,when taking scalability into account,it turns out that reliability can be guaranteed only if application requirements are considered.This is a strong argument for implementing such services at higher,less gen-eral layers.4.Q:Consider a procedure incr with two integer parameters.The procedure adds one to each parameter.Now suppose that it is called with the same vari-able twice,for example,as incr (i ,i ).If i is initially 0,what value will it have afterward if call-by-reference is used?How about if copy/restore is used?A:If call by reference is used,a pointer to i is passed to incr .It will be incre-mented two times,so the final result will be two.However,with copy/restore,i will be passed by value twice,each value initially 0.Both will be incre-mented,so both will now be 1.Now both will be copied back,with the second copy overwriting the first one.The final value will be 1,not 2.w w w .k h d a w .c o m 课后答案网6PROBLEM SOLUTIONS FOR CHAPTER 25.Q:C has a construction called a union,in which a field of a record (called a struct in C)can hold any one of several alternatives.At run time,there is no sure-fire way to tell which one is in there.Does this feature of C have any implications for remote procedure call?Explain your answer.A:If the runtime system cannot tell what type value is in the field,it cannot marshal it correctly.Thus unions cannot be tolerated in an RPC system unless there is a tag field that unambiguously tells what the variant field holds.The tag field must not be under user control.6.Q:One way to handle parameter conversion in RPC systems is to have each machine send parameters in its native representation,with the other one doing the translation,if need be.The native system could be indicated by a code in the first byte.However,since locating the first byte in the first word is pre-cisely the problem,can this actually work?A:First of all,when one computer sends byte 0,it always arrives in byte 0.Thus the destination computer can simply access byte 0(using a byte instruc-tion)and the code will be in it.It does not matter whether this is the low-order byte or the high-order byte.An alternative scheme is to put the code in all the bytes of the first word.Then no matter which byte is examined,the code will be there.7.Q:Assume a client calls an asynchronous RPC to a server,and subsequently waits until the server returns a result using another asynchronous RPC.Is this approach the same as letting the client execute a normal RPC?What if we replace the asynchronous RPCs with asynchronous RPCs?A:No,this is not the same.An asynchronous RPC returns an acknowledge-ment to the caller,meaning that after the first call by the client,an additional message is sent across the network.Likewise,the server is acknowledged that its response has been delivered to the client.Two asynchronous RPCs may be the same,provided reliable communication is guaranteed.This is generally not the case.8.Q:Instead of letting a server register itself with a daemon as is done in DCE,we could also choose to always assign it the same endpoint.That endpoint can then be used in references to objects in the server ’s address space.What is the main drawback of this scheme?A:The main drawback is that it becomes much harder to dynamically allo-cate objects to servers.In addition,many endpoints need to be fixed,instead of just one (i.e.,the one for the daemon).For machines possibly having alarge number of servers,static assignment of endpoints is not a good idea.9.Q:Give an example implementation of an object reference that allows a client to bind to a transient remote object.w w w .k h d a w .c o m 课后答案网PROBLEM SOLUTIONS FOR CHAPTER 27A:Using Java,we can express such an implementation as the following class:public class Object reference {InetAddress server address;//network address of object’s server int server endpoint;//endpoint to which server is listening int object identifier;//identifier for this object URL client code;//(remote)file containing client-side stub byte[]init data;//possible additional initialization data }The object reference should at least contain the transport-level address ofthe server where the object resides.We also need an object identi fier as the server may contain several objects.In our implementation,we use a URL to refer to a (remote)file containing all the necessary client-side code.A generic array of bytes is used to contain further initialization data for that code.An alternative implementation would have been to directly put the client-code into the reference instead of a URL.This approach is followed,for example,in Java RMI where proxies are passed as reference.10.Q:Java and other languages support exceptions,which are raised when an error occurs.How would you implement exceptions in RPCs and RMIs?A:Because exceptions are initially raised at the server side,the server stub can do nothing else but catch the exception and marshal it as a special error response back to the client.The client stub,on the other hand,will have to unmarshal the message and raise the same exception if it wants to keep access to the server transparent.Consequently,exceptions now also need to be described in an interface de finition language.11.Q:Would it be useful to also make a distinction between static and dynamic RPCs?A:Yes,for the same reason it is useful with remote object invocations:it simply introduces more flexibility.The drawback,however,is that much of the distribution transparency is lost for which RPCs were introduced in the first place.12.Q:Some implementations of distributed-object middleware systems are entirely based on dynamic method invocations.Even static invocations are compiled to dynamic ones.What is the bene fit of this approach?A:Realizing that an implementation of dynamic invocations can handle all invocations,static ones become just a special case.The advantage is that onlya single mechanism needs to be implemented.A possible disadvantage is that performance is not always as optimal as it could be had we analyzed the static invocation.w w w .k h d a w .c o m 课后答案网8PROBLEM SOLUTIONS FOR CHAPTER 213.Q:Describe how connectionless communication between a client and a server proceeds when using sockets.A:Both the client and the server create a socket,but only the server binds the socket to a local endpoint.The server can then subsequently do a blocking read call in which it waits for incoming data from any client.Likewise,after creating the socket,the client simply does a blocking call to write data to the server.There is no need to close a connection.14.Q:Explain the difference between the primitives mpi bsend and mpi isend in MPI.A:The primitive mpi bsend uses buffered communication by which the caller passes an entire buffer containing the messages to be sent,to the local MPI runtime system.When the call completes,the messages have either been transferred,or copied to a local buffer.In contrast,with mpi isend ,the caller passes only a pointer to the message to the local MPI runtime system after which it immediately continues.The caller is responsible for not overwriting the message that is pointed to until it has been copied or transferred.15.Q:Suppose you could make use of only transient asynchronous communica-tion primitives,including only an asynchronous receive primitive.How would you implement primitives for transient synchronous communication?A:Consider a synchronous send primitive.A simple implementation is to send a message to the server using asynchronous communication,and subse-quently let the caller continuously poll for an incoming acknowledgement or response from the server.If we assume that the local operating system stores incoming messages into a local buffer,then an alternative implementation is to block the caller until it receives a signal from the operating system that a message has arrived,after which the caller does an asynchronous receive.16.Q:Now suppose you could make use of only transient synchronous commun-ication primitives.How would you implement primitives for transient asyn-chronous communication?A:This situation is actually simpler.An asynchronous send is implemented by having a caller append its message to a buffer that is shared with a process that handles the actual message transfer.Each time a client appends a mes-sage to the buffer,it wakes up the send process,which subsequently removes the message from the buffer and sends it its destination using a blocking call to the original send primitive.The receiver is implemented similarly by offer-ing a buffer that can be checked for incoming messages by an application.17.Q:Does it make sense to implement persistent asynchronous communicationby means of RPCs?A:Yes,but only on a hop-to-hop basis in which a process managing a queue passes a message to a next queue manager by means of an RPC.Effectively,w w w .k h d a w .c o m 课后答案网PROBLEM SOLUTIONS FOR CHAPTER 29the service offered by a queue manager to another is the storage of a message.The calling queue manager is offered a proxy implementation of the interface to the remote queue,possibly receiving a status indicating the success or failure of each operation.In this way,even queue managers see only queues and no further communication.18.Q:In the text we stated that in order to automatically start a process to fetchmessages from an input queue,a daemon is often used that monitors the input queue.Give an alternative implementation that does not make use of a dae-mon.A:A simple scheme is to let a process on the receiver side check for any incoming messages each time that process puts a message in its own queue.19.Q:Routing tables in IBM MQSeries,and in many other message-queuing systems,are con figured manually.Describe a simple way to do this automati-cally.A:The simplest implementation is to have a centralized component in which the topology of the queuing network is maintained.That component simply calculates all best routes between pairs of queue managers using a known routing algorithm,and subsequently generates routing tables for each queue manager.These tables can be downloaded by each manager separately.This approach works in queuing networks where there are only relatively few,but possibly widely dispersed,queue managers.A more sophisticated approach is to decentralize the routing algorithm,by having each queue manager discover the network topology,and calculate its own best routes to other managers.Such solutions are widely applied in com-puter networks.There is no principle objection for applying them to message-queuing networks.20.Q:How would you incorporate persistent asynchronous communication into a model of communication based on RMIs to remote objects?A:An RMI should be asynchronous,that is,no immediate results are expected at invocation time.Moreover,an RMI should be stored at a special server that will forward it to the object as soon as the latter is up and running in an object server.21.Q:With persistent communication,a receiver generally has its own local buffer where messages can be stored when the receiver is not executing.To create such a buffer,we may need to specify its size.Give an argument why this is preferable,as well as one against speci fication of the size.A:Having the user specify the size makes its implementation easier.The sys-tem creates a buffer of the speci fied size and is done.Buffer management becomes easy.However,if the buffer fills up,messages may be lost.The alternative is to have the communication system manage buffer size,starting w w w .k h d a w .c o m 课后答案网10PROBLEM SOLUTIONS FOR CHAPTER 2with some default size,but then growing (or shrinking)buffers as need be.This method reduces the chance of having to discard messages for lack of room,but requires much more work of the system.22.Q:Explain why transient synchronous communication has inherent scalabil-ity problems,and how these could be solved.A:The problem is the limited geographical scalability.Because synchronous communication requires that the caller is blocked until its message is received,it may take a long time before a caller can continue when the receiver is far away.The only way to solve this problem is to design the cal-ling application so that it has other useful work to do while communication takes place,effectively establishing a form of asynchronous communication.23.Q:Give an example where multicasting is also useful for discrete datastreams.A:Passing a large file to many users as is the case,for example,when updat-ing mirror sites for Web services or software distributions.24.Q:How could you guarantee a maximum end-to-end delay when a collectionof computers is organized in a (logical or physical)ring?A:We let a token circulate the ring.Each computer is permitted to send data across the ring (in the same direction as the token)only when holding the token.Moreover,no computer is allowed to hold the token for more than T seconds.Effectively,if we assume that communication between two adjacent computers is bounded,then the token will have a maximum circulation time,which corresponds to a maximum end-to-end delay for each packet sent.25.Q:How could you guarantee a minimum end-to-end delay when a collection of computers is organized in a (logical or physical)ring?A:Strangely enough,this is much harder than guaranteeing a maximum delay.The problem is that the receiving computer should,in principle,not receive data before some elapsed time.The only solution is to buffer packets as long as necessary.Buffering can take place either at the sender,the receiver,or somewhere in between,for example,at intermediate stations.The best place to temporarily buffer data is at the receiver,because at that point there are no more unforeseen obstacles that may delay data delivery.The receiver need merely remove data from its buffer and pass it to the applica-tion using a simple timing mechanism.The drawback is that enough buffering capacity needs to be provided.26.Q:Imagine we have a token bucket speci fication where the maximum dataunit size is 1000bytes,the token bucket rate is 10million bytes/sec,the token bucket size is 1million bytes,and the maximum transmission rate is 50mil-lion bytes/sec.How long can a burst of maximum speed last?w w w .k h d a w .c o m 课后答案网PROBLEM SOLUTIONS FOR CHAPTER 211A:Call the length of the maximum burst interval ∆t .In an extreme case,the bucket is full at the start of the interval (1million bytes)and another 10∆t comes in during that interval.The output during the transmission burst con-sists of 50∆t million bytes,which should be equal to (1+10∆t ).Consequently,∆t is equal to 25msec.w w w .khda w.com课后答案网12SOLUTIONS TO CHAPTER 3PROBLEMS1.Q:In this problem you are to compare reading a file using a single-threaded file server and a multithreaded server.It takes 15msec to get a request for work,dispatch it,and do the rest of the necessary processing,assuming that the data needed are in a cache in main memory.If a disk operation is needed,as is the case one-third of the time,an additional 75msec is required,during which time the thread sleeps.How many requests/sec can the server handle if it is single threaded?If it is multithreaded?A:In the single-threaded case,the cache hits take 15msec and cache misses take 90msec.The weighted average is 2/3×15+1/3×90.Thus the mean request takes 40msec and the server can do 25per second.For a mul-tithreaded server,all the waiting for the disk is overlapped,so every request takes 15msec,and the server can handle 662/3requests per second.2.Q:Would it make sense to limit the number of threads in a server process?A:Yes,for two reasons.First,threads require memory for setting up their own private stack.Consequently,having many threads may consume too much memory for the server to work properly.Another,more serious reason,is that,to an operating system,independent threads tend to operate in a chaotic manner.In a virtual memory system it may be dif ficult to build a rela-tively stable working set,resulting in many page faults and thus I/O.Having many threads may thus lead to a performance degradation resulting from page thrashing.3.Q:In the text,we described a multithreaded file server,showing why it is better than a single-threaded server and a finite-state machine server.Are there any circumstances in which a single-threaded server might be better?Give an example.A:Yes.If the server is entirely CPU bound,there is no need to have multiple threads.It may just add unnecessary complexity.As an example,consider a telephone directory assistance number (like 555-1212)for an area with 1mil-lion people.If each (name,telephone number)record is,say,64characters,the entire database takes 64megabytes,and can easily be kept in the server ’s memory to provide fast lookup.4.Q:Statically associating only a single thread with a lightweight process is not such a good idea.Why not?A:Such an association effectively reduces to having only kernel-levelthreads,implying that much of the performance gain of having threads in the first place,is lost.5.Q:Having only a single lightweight process per process is also not such a good idea.Why not?w w w .k h d a w .c o m 课后答案网PROBLEM SOLUTIONS FOR CHAPTER 313A:In this scheme,we effectively have only user-level threads,meaning that any blocking system call will block the entire process.6.Q:Describe a simple scheme in which there are as many lightweight processes as there are runnable threads.A:Start with only a single LWP and let it select a runnable thread.When a runnable thread has been found,the LWP creates another LWP to look for a next thread to execute.If no runnable thread is found,the LWP destroys itself.7.Q:Proxies can support replication transparency by invoking each replica,as explained in the text.Can (the server side of)an object be subject to a repli-cated invocation?A:Yes:consider a replicated object A invoking another (nonreplicated)object B .If A consists of k replicas,an invocation of B will be done by each replica.However,B should normally be invoked only once.Special measures are needed to handle such replicated invocations.8.Q:Constructing a concurrent server by spawning a process has some advan-tages and disadvantages compared to multithreaded servers.Mention a few.A:An important advantage is that separate processes are protected against each other,which may prove to be necessary as in the case of a superserver handling completely independent services.On the other hand,process spawn-ing is a relatively costly operation that can be saved when using mul-tithreaded servers.Also,if processes do need to communicate,then using threads is much cheaper as in many cases we can avoid having the kernel implement the communication.9.Q:Sketch the design of a multithreaded server that supports multiple proto-cols using sockets as its transport-level interface to the underlying operating system.A:A relatively simple design is to have a single thread T waiting for incom-ing transport messages (TPDUs).If we assume the header of each TPDU con-tains a number identifying the higher-level protocol,the tread can take the payload and pass it to the module for that protocol.Each such module has a separate thread waiting for this payload,which it treats as an incoming request.After handling the request,a response message is passed to T ,which,in turn,wraps it in a transport-level message and sends it to tthe proper desti-nation.10.Q:How can we prevent an application from circumventing a windowmanager,and thus being able to completely mess up a screen?A:Use a microkernel approach by which the windowing system including the window manager are run in such a way that all window operations are w w w .kh d a w .c o m 课后答案网。
分布式操作系统、分布式系统数据库[填空题]1什么是主从式多机操作系统?它有什么优缺点?参考答案:主从式多机操作系统的工作原理最简单,许多在单机系统上使用的软件都可以在此系统的管理下运行。
它的主要特点是监控管理程序始终由同一个主处理机执行,从机的任务分配完全由主机负责。
如果从机需要主机的服务,可向主机申请,等待主机执行相应的管理程序。
主从式操作系统对软硬件要求简单,适合于工作负荷较轻且比较明确的应用场合,特别是从机能力小于主机的非对称情况。
许多采用服务器——工作站类型的微机网络操作系统即属于主从式操作系统。
主从式系统要求系统具备一台主处理机和多台从机,缺乏灵活性,在控制和利用全部系统资源方面效率较低,而且主机故障会导致整个系统的停机。
[填空题]2什么是独立式多机操作系统?它有什么优缺点?参考答案:在这种方式下,各个处理机执行各自的监控程序和其它可执行模块,为自己的需要服务,其自治程度类似于多个单机系统。
独立式系统中各处理机控制各自的I/O设备,共享程度差,I/O设备的机构需要手工切换。
独立式系统自治程度高,不会因为个别处理机故障导致整个系统失效,但各处理机可能存在负载不平衡,而且故障的处理机重新启动并继续原来的工作往往是很困难的。
[填空题]3什么是分布式多机操作系统?它有什么优缺点?参考答案:这种方式的最初目标是最大限度地利用各个处理机,提高系统的整体处理能力。
在这种方式下,内存、I/O通道等资源都可以为系统所共享。
每个处理机都可以执行监控程序,并且可以多台同时执行,不存在固定的主从关系。
实际上,监控程序的执行者是浮动的。
当现行任务被中断或已完成时,接受新任务的调度都由各个处理机分别完成。
这样显然有利于加快系统响应,提高系统的处理能力。
采用这种方式容易实现故障状态下的降级运行,实现冗余和容错,提高系统的利用率,同时也容易做到各处理机的负载平衡,最充分地利用系统资源。
[填空题]4什么是“死锁”?出现死锁的条件有哪些?参考答案:单机系统当程序出错或某一外部条件始终不能满足时,就可能出现死循环或无休止的等待状态,即称为死锁。
(勤奋、求是、创新、奉献)2010学年第一学期期中考试试卷主考教师:程武山学院机械工程学院班级_0231041/0231042_ 姓名__________ 学号___________《分布式控制系统》课程试卷(本卷考试时间分钟)一、概念题(本题共6小题,每小题5分,共30分)1.试说明分布式控制系统(集散控制系统)的主要特点。
2. 简述分布式控制系统的可扩展性、可移植性。
4.简述超驰控制的特点5. 分布式控制系统为什么采用现场总线控制方式?6. 分布式控制系统为什么要采用冗余结构?二、论述题(本题共2小题,每小题7分,共14分)1. 简述选择性控制的基本原理,并用流程图形式画出锅炉蒸汽系统中蒸汽流量变小时系统调节过程。
2.试描述在分布式控制系统中如何实现前馈控制与反馈控制相结合的控制模式?三、根据要求给出控制原理图和控制电路图(本题共2小题,每小题8分,共16分)1. 试画出闪烁电路的波形图。
2.绘制PLC的工作原理图并简述其工作过程。
四、设计题(本题共2小题,每小题10分,共20分)1.试设计延时接通/延时断开电路。
要求有输入信号后,停一段时间输出信号才为ON;而输入信号OFF 后,输出信号延时一段时间才OFF,并画出波形图。
2.运料小车运行示意图如图所示。
系统启动后首先在原位进行装料。
15s后装料停止,小车右行。
右行至行程开关SQ2 处右行停止,进行卸料。
10s后,卸料停止,小车左行。
左行至行程开关SQ1处,左行停止,进行装料。
如此循环一直进行下去,直至停止工作。
试设计运料小车的控制逻辑图。
五、综合题(20分)在连锁控制中:当中间设备出现故障停机时上下游设备如何停机?给出操作画面和控制程序(ladder)。
分布式数据库系统原理与应用考试(答案见尾页)一、选择题1. 分布式数据库系统的定义及特点是什么?A. 分布式数据库系统是由多个物理数据库组成的,它们可以分布在不同的地理位置。
B. 分布式数据库系统提供了一个透明的、逻辑上集中、物理上分布的数据存储,使用户感觉好像数据只存储在一个数据库中。
C. 分布式数据库系统通过数据复制和分片技术实现数据的冗余和容错。
D. 分布式数据库系统的主要目标是提高数据访问性能和数据一致性。
2. 以下哪个选项不是分布式数据库系统的一致性策略?A. 串行处理B. 两阶段提交协议C. 检索优化D. 乐观并发控制3. 在分布式数据库系统中,如何实现数据分片?A. 通过范围分区B. 通过列表分区C. 通过哈希分区D. 通过目录分区4. 分布式数据库系统中的复制策略有哪些?A. 同步复制B. 异步复制C. 混合复制D. 并发复制5. 分布式数据库系统中的数据一致性是如何保证的?A. 通过分布式事务协议B. 通过分布式锁机制C. 通过数据复制和分片D. 通过备份和恢复机制6. 什么是分布式数据库系统的CAP理论?A. 一致性、可用性和分区容错性不能同时满足B. 一致性、可用性和分区容错性可以同时满足C. 一致性、可用性和分区容错性之间存在权衡D. 以上都不是7. 在分布式数据库系统中,如何实现数据镜像?A. 通过主从复制B. 通过分片C. 通过复制集D. 通过日志备份8. 分布式数据库系统中的分片有哪几种类型?A. 范围分片B. 列表分片C. 哈希分片D. 直接分片9. 什么是分布式数据库系统中的读写分离?A. 将读操作和写操作分开在不同的节点上执行B. 将读操作和写操作集中在同一个节点上执行C. 将写操作分散到多个节点上执行,而读操作集中在一个节点上执行D. 将写操作集中在一个节点上执行,而读操作分散到多个节点上执行10. 分布式数据库系统中的故障恢复策略有哪些?A. 主从复制恢复B. 副本恢复C. 分片恢复D. 重建恢复11. 以下哪个不是分布式数据库系统的常见分区策略?A. 节点分区B. 范围分区C. 距离分区D. 列分区12. 分布式数据库系统中,分布式事务的处理方式有哪几种?A. 两阶段提交(2PC)B. 三阶段提交(3PC)C. 检查点(Checkpoint)D. 分布式事务协议(DTCP)13. 什么是分布式数据库中的复制策略?有哪些常见的复制策略?A. 主从复制B. 并发复制C. 分片复制D. 混合复制14. 在分布式数据库系统中,如何实现数据的负载均衡?A. 数据库中间件B. 分布式缓存C. 负载均衡器D. 读写分离15. 分布式数据库系统中,如何保证数据的一致性和完整性?A. 两阶段提交(2PC)B. 三阶段提交(3PC)C. 检查点(Checkpoint)D. 四阶段提交(4PC)16. 以下哪个是分布式数据库系统中的分布式锁机制?A. 乐观锁B. 悲观锁C. 行级锁D. 页级锁17. 分布式数据库系统中,如何处理跨库查询?A. 使用SQL查询B. 使用中间表C. 使用分布式查询语言(DQL)D. 使用ETL工具18. 分布式数据库系统中,如何实现数据备份和恢复?A. 定期全量备份B. 增量备份C. 差量备份D. 主从备份19. 以下哪个是分布式数据库系统的发展趋势?A. 向规模更小的分布式数据库发展B. 向更高性能的分布式数据库发展C. 向更容易扩展的分布式数据库发展D. 向更强一致性的分布式数据库发展20. 以下哪个选项是分布式数据库系统中常用的数据复制技术?A. 主从复制B. 并发复制C. 混合复制D. 非阻塞复制21. 分布式数据库系统中的分片策略有哪几种?A. 范围分片B. 列分片C. 层次分片D. 索引分片22. 在分布式数据库系统中,如何实现数据的一致性?A. 通过分布式事务协议如两阶段提交(2PC)实现B. 通过分布式锁机制实现C. 通过分布式日志和重放技术实现D. 通过数据复制和分片实现23. 分布式数据库系统面临的主要挑战包括哪些?A. 数据复制的一致性问题B. 查询优化的复杂性C. 安全性和隐私保护问题D. 系统的可靠性和容错性24. 以下哪个选项是分布式数据库系统中常用的分片算法?A. 条件分片B. 基于范围的分片C. 基于哈希的分片D. 基于权重的分片25. 分布式数据库系统中的分布式事务处理有哪些类型?A. 两阶段提交(2PC)B. 三阶段提交(3PC)C. 这些选项都不是D. 没有分布式事务处理26. 以下哪个选项是分布式数据库系统中常用的负载均衡技术?A. 轮询负载均衡B. 权重负载均衡C. 简单轮询D. 加权轮询27. 分布式数据库系统中的数据迁移有以下几种类型?A. 结构迁移B. 非结构迁移C. 逻辑迁移D. 物理迁移28. 以下哪个选项是分布式数据库系统中常用的故障恢复技术?A. 回滚操作B. 前滚操作C. 数据重同步D. 数据复制恢复29. 分布式数据库系统的定义及其与传统数据库系统的区别是什么?A. 分布式数据库系统可以在多个节点上存储数据,而传统数据库系统通常在一个节点上存储所有数据。
分布式系统复习题库及答案1、计算机系统的硬件异构性、软件异构性主要表现在哪几方面?参考答案:计算机系统的硬件异构性主要有三个方面的表现,即:①计算机的指令系统不同。
这意味着一种机器上的程序模块不能在另一种不兼容的机器上执行,很显然,一种机器上的可执行代码程序不能在另一种不兼容的机器上执行。
②数据表示方法不同。
例如不同类型的计算机虽然都是按字节编址的,但是高字节和低字节的规定可能恰好相反。
浮点数的表示方法也常常不一样。
③机器的配置不同。
尽管机器的类型可能相同,其硬件配置也可以互不兼容。
计算机系统的软件异构性包括操作系统异构性和程序设计语言异构性。
操作系统异构性的三个主要表现方面为:①操作系统所提供的功能可能大不相同。
例如,不同的操作系统至少提供了不同的命令集。
②操作系统所提供的系统调用在语法、语义和功能方面也不相同。
③文件系统不同。
程序设计语言的异构性表现在不同的程序设计语言用不同方法在文件中存储数据。
2、由于分布计算系统包含多个(可能是不同种类的)分散的、自治的处理资源,要想把它们组织成一个整体,最有效地完成一个共同的任务,做到这一点比起传统的集中式的单机系统要困难得多,需要解决很多新问题。
这些问题主要表现在哪些方面?参考答案:①资源的多重性带来的问题。
由于处理资源的多重性,分布计算系统可能产生的差错类型和次数都比集中式单机系统多。
最明显的一个例子是部分失效问题:系统中某一个处理资源出现故障而其他计算机尚不知道,但单机系统任何一部分出现故障时将停止整个计算。
另一个例子是多副本信息一致性问题。
可见,资源多重性使得差错处理和恢复问题变得很复杂。
资源多重性还给系统资源管理带来新的困难。
②资源的分散性带来的问题。
在分布计算系统中,系统资源在地理上是分散的。
由于进程之间的通信采用的是报文传递的方式进行的,通信将产生不可预测的、有时是巨大的延迟,特别是在远程网络所组成的分布计算系统中更是这样。
例如使用卫星通信会产生270毫秒的延迟。
分布式系统 2010春季学期期末考试北京大学计算机系,2010年6月7日院系:学号:姓名:一、概念题(共15分)1.asynchronous RPC (3pt) (chap4)With asynchronous RPCs, the server immediately sends a reply back to the client the moment the PRC request is received, after which it calls the requested procedure. The reply acts as an acknowledgment to the client that the server is going to process the RPC. The client will continue without further blocking as soon as it has received the server’s acknowledgment.2.response failure, sate transition failure (3pt) (chap8)The server’s response is simply incorrect. Two kinds of response failures may happen. In the case of a value failure, a server simply provides the wrong reply to a request. The other type of response failure is known as a state transition failure. This kinds of failure happens when the server reacts unexpectedly to an incoming request.3.stateless server, soft state (3pt) (chap3)A stateless server does not keep information on the state of its clients, and can change its own state without having to inform any client.A particular form of a stateless design is where the server maintains what is known as soft sate. The server promises to maintain state on behalf of the client, but only for a limited time. After that time has expired, the server falls back to default behavior.4.totally-ordered multicast, causally-ordered multicasting (3pt) (chap6)A multicast operation by which all messages are delivered in the same order to each receiver.If two messages are not in any way related to each other, we do not care in which order they are delivered to applications. They may even be delivered in different order at different locations.5.Monotonic-read consistency (3pt) (chap7)If a process reads the value of a data item x, any successive read operation on x by that process will always return that same value or a more recent value. In other words, monotonic-read consistency guarantees that if a process has seen a value of x at time t, it will never see and older version of x at a later time.二、简答题(共35分)1. Q: 1) Resolve the following key lookups for the shown Chord-based P2P system: (5pt) (chap5)15@4: 14–18; 22@4: 20–21–28; 30@21: 28–1; 27@21: 28; 18@20: 4–14–182) Adjust the finger tables of nodes 18 and 14 when a node with ID 24 enters the ring. Also give the finger table of node 24. (5pt) (chap5)Node 18: [20,20,24,28,4]; Node 14: [18,18,18,24,1]; Node 24: [28,28,28,1,9].3) Chord allows keys to be looked up recursively or iteratively. Explain the differences, as well as the main advantage of iterative over recursive lookup. (5pt) (chap5)With recursive lookups, a message is forwarded from peer to peer until it reaches its destination. In contrast, with an iterative lookup, the requester is returned the next peer it should ask for the key. One can argue that in the case of Chord, iterative lookups are much better: recursive lookups do not have the advantage of proximity-awareness. Also, note that iterative lookups have the advantage of letting the client handle failures more easily.2. Q: What is a three-tiered client-server architecture? (5pt) (chap 2)A three-tiered client-server architecture consists of three logical layers, where each layer is, in principle, implemented at a separate machine. The highest layer consists of a client user interface, the middle layer contains the actual application, and the lowest layer implements the data that are being used.3. Q: Where does the need for at-least-once and at-most-once semantics come from? Why can’t we have exactly-once semantics? (5pt)The problem originates from having a (suspected) server crash, detected by the lack of a response in the case of an RPC. What the client-side software can do is either resend the request until it finally gets a response (at-least-once semantics) or immediately reports the failure to the client application, thus providing at-most-once semantics. Guaranteeing exactly-once semantics is, in principle, impossible, because you cannot know in general whether the server crashed before or after executing the requested operation.4. Q: 1) Explain how two-phase commit works. (5pt) (chap8)Make sure that you explain (1) coordinator sends vote-request; (2) participants respond; (3) coordinator sends decision; (4) participants ack.2) Explain what happens when a participant, who is in the READY state, times out because it hasn’t received a response from the coordinator yet. (5pt) (chap8)In that case, P can check whether any of the other participants has made a transition to either ABORT or INIT (in which case P can abort) or COMMIT (and commit as well). The difficulty is when all others are in READY: they all need to wait until the coordinator recovers.。