ORC基本理论
- 格式:ppt
- 大小:1.99 MB
- 文档页数:33
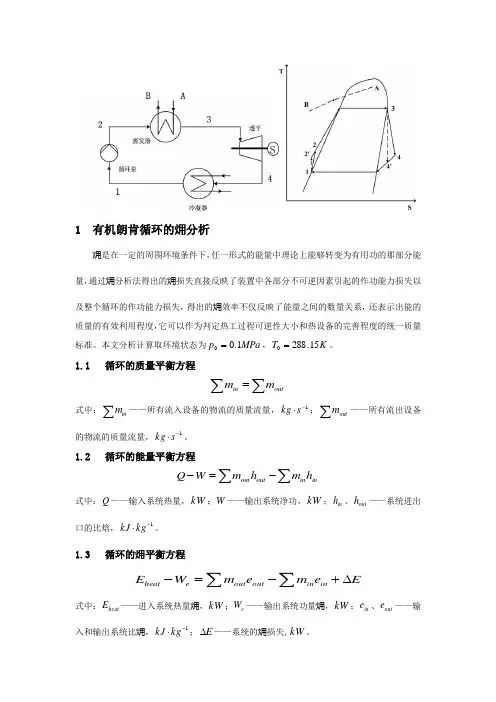
1 有机朗肯循环的㶲分析㶲是在一定的周围环境条件下,任一形式的能量中理论上能够转变为有用功的那部分能量,通过㶲分析法得出的㶲损失直接反映了装置中各部分不可逆因素引起的作功能力损失以及整个循环的作功能力损失,得出的㶲效率不仅反映了能量之间的数量关系,还表示出能的质量的有效利用程度,它可以作为判定热工过程可逆性大小和热设备的完善程度的统一质量标准。
本文分析计算取环境状态为MPa p 1.00=,K T 15.2880=。
1.1 循环的质量平衡方程∑∑=outinm m式中:∑inm——所有流入设备的物流的质量流量,1-⋅skg ;∑outm——所有流出设备的物流的质量流量,1-⋅s kg 。
1.2 循环的能量平衡方程∑∑-=-inin out out h m h m W Q式中:Q ——输入系统热量,kW ;W ——输出系统净功,kW ;in h 、out h ——系统进出口的比焓,1-⋅kg kJ 。
1.3 循环的㶲平衡方程E e m e mW E in in out oute heat ∆+-=-∑∑式中:heat E ——进入系统热量㶲,kW ;e W ——输出系统功量㶲,kW ;in e 、out e ——输入和输出系统比㶲,1-⋅kg kJ ;E ∆——系统的㶲损失,kW 。
()∑-=Q T T E heat 01()000s s T h h e ---=1.4循环的㶲分析指标利用1.3部分介绍的㶲平衡及计算,对ORC 中的各个设备进行㶲分析,评价指标计算式列于下表。
其中,㶲损失I 是工质在设备内部经历不可逆过程的内部㶲损失和由于泄漏、散热等造成的外部㶲损失的总和。
同时,以㶲效率e η来评定设备的热力学完善程度。
假定各设备与环境之间的换热量忽略不计,系统在稳态稳流状态下运行。
表1 循环各部件㶲效率关系式Tab.1 The relationship of the cycle parts exergy efficiency部件/系统㶲损失㶲损率㶲效率蒸发器Q E E E E I +-=32 Q EE I QEe E E E +=23,η 透平T T W E E I --=43 Q TE I 43,E E W TT e -=η冷凝器C C E E E I +-=14Q CE I C C e E E E +=41,η循环泵P P W E E I +-=21 QPE I PP e W E E 12,-=ηORCP C T E ORC I I I I I +++=Q ORC E I QPT ORC e E W W -=,η 表中:B A Q E E E -=——微燃机沼气发电产生的烟气㶲值,kW ;()43h h m W T -=——透平产生的功,kW ;0=C E ——冷凝器的热量㶲,kW ,因工质在冷凝器中未对外输出功,且向环境介质放热,故热量㶲为零;()12h h m W P -=——循环泵消耗的功,kW 。

化学热力学方法对有机工质热稳定性的预测与实验验证摘要利用150~350℃热源范围的中高温有机朗肯循环在可再生能源和工业余热利用领域具有广泛的应用前景。
但是在中高温热源温度下,有机工质可能会发生热分解,因此热稳定性成为中高温有机朗肯循环工质筛选的首要限制条件。
由于适合于有机朗肯循环的工质多达上百种,对其一一进行热稳定性实验是不现实的,因此本文提出一种化学热力学方法来对有机工质的热稳定性进行预测。
首先通过理论分析给出可能的反应途径;再选择吉布斯函数作为指标,计算各反应中△G=0时的温度,以最小值T g作为表征热稳定性的参数。
通过与已有的实验结果比较,发现不同有机工质T g值的相对大小关系与热分解温度的相对大小关系基本一致。
使用化学热力学方法对正己烷和R152a两种工质的热分解温度范围进行预测并设计实验进行验证,实验结果与预测结果相符合。
关键词:有机朗肯循环;热稳定性;化学热力学;吉布斯函数0 前言有机朗肯循环(Organic Rankine Cycle,ORC)是一种具有广泛应用价值的热电转换技术,目前在太阳能、地热、生物质能和工业余热利用等领域都有着良好的应用前景[1~4]。
有机朗肯循环适用的热源温度范围很广,当热源温度比较低时,系统的热效率会受到热源温度的限制,从而造成整个系统的经济性的下降。
因此目前利用150~350℃热源范围的中高温有机朗肯循环受到广泛的关注,被认为是有机朗肯循环技术今后发展的重要方向之一。
但是在较高的热源温度下,有机工质就可能会发生热分解。
工质一旦在系统中发生分解,产生的不凝性气体可能造成冷凝压力的提高,引起系统输出的下降;产生的固态产物可能会覆盖在换热器表面影响换热,甚至可能堵塞管道或者损毁活动部件,影响系统的安全运行[5]。
因此在中高温有机朗肯循环的工质筛选研究中,有机工质的热稳定性应该是首先要考虑的筛选条件。
目前针对有机工质热稳定性的研究,主要集中在热分解实验方面。
Calderazzi 等[6]以不同温度下有机工质的压力变化和反应前后饱和蒸汽压的变化作为是否发生热分解的判断依据,对R134a、R141b、R13I1、R7146和R125等有机工质的热稳定性进行了实验研究。

orc存储原理摘要:1.ORC 存储原理概述2.ORC 文件格式与数据存储结构3.ORC 存储的优势与应用场景4.ORC 的未来发展趋势正文:【ORC 存储原理概述】ORC(Optimized Row Columnar)存储原理是一种面向列存储的高效数据存储技术。
与传统的行存储格式相比,ORC 存储原理可以大幅提高数据压缩率和查询性能,特别是在数据仓库和大数据分析领域具有广泛的应用前景。
【ORC 文件格式与数据存储结构】ORC 文件格式是一种高效的列式存储格式,其主要特点包括:1.列式存储:数据按照列的方式进行存储,可以减少数据在查询过程中的I/O 操作,提高查询效率。
2.数据压缩:ORC 支持多种数据压缩算法,可以在存储过程中对数据进行压缩,降低存储成本和提高查询性能。
3.数据编码:ORC 支持多种数据编码方式,如字典编码、位图编码等,可以有效减少存储空间和提高查询速度。
4.存储属性:ORC 文件中可以存储有关表结构、数据统计信息等元数据,方便数据分析和查询。
【ORC 存储的优势与应用场景】ORC 存储原理具有以下优势:1.高压缩率:ORC 文件格式支持多种压缩算法,可以在保证数据完整性的前提下实现较高的压缩率。
2.快速查询:ORC 存储原理采用列式存储结构,可以减少查询过程中的I/O 操作,提高查询速度。
3.节省存储空间:通过数据压缩和编码技术,ORC 文件格式可以有效降低存储成本。
ORC 存储原理在以下场景中具有较好的应用前景:1.数据仓库:在数据仓库中,ORC 存储原理可以提高数据压缩率和查询性能,降低存储成本。
2.大数据分析:在大数据分析场景中,ORC 存储原理可以加速数据处理和分析过程,提高分析效率。
3.云计算:在云计算环境中,ORC 存储原理可以有效降低存储成本,提高云计算资源的利用率。
【ORC 的未来发展趋势】随着大数据和人工智能技术的发展,ORC 存储原理在未来将面临更多的应用场景和挑战。


低温余热发电(ORC)综述作者:李刚来源:《科技尚品》2017年第07期摘要:低温余热发电技术在提高能源再利用的有效方法之一,有机朗肯循环(ORC)技术是是低温余热发电技术之一,本文主要介绍了ORC循环的系统的结构和工质的选择方法,为ORC技术研究提供参考。
关键词:低温余热发电;有机朗肯循环;系统结构;有机工质1 前言由于世界人口的增长和全球经济的快速发展,能源消耗日渐增长。
为了保护环境、維护人类良好的生存环境,开发新能源和提高能量利用效率是亟须解决的问题。
可利用再生能源如:太阳能、风能及地热能,在满足能源需求起了越来越多的作用。
而提高能源再利用有效的方法之一就是利用中低温热源的有机郎肯循环。
有机朗肯循环(organic rankine cycle,简称ORC)是低温余热发电技术之一,ORC是使用具有较低临界温度的有机物作为循环工质的朗肯循环。
2 研究现状国外有机郎肯循环主要应用在地热、太阳能、烟气余热回收等工业余热,多数文献根据热力学定律建立模型,计算不同工质和温度下的循环热效率和介绍工质的选择方法,并介绍了有机郎肯循环中的重要设备——蒸汽膨胀做功的设备的选择和设计。
工质均为饱和曲线斜率为负值或者无穷大的干流体和等熵流体。
文献中工质的选择大多为各种CFC(含氯、氟、碳的完全卤代烃)等对环境有一定破坏的有机工质,如R113、R245fa、R123等等。
个别采用氨、烷烃等对环境有好的工质。
而且文献中对工质的选择局限在某一特定的温度范围内。
追求最优系统,工质被加热到饱和状态后在膨胀做功的热效率最高,过热或者未饱和使得不可逆损失和成本增加,降低热效率和经济性。
文献还对有机郎肯循环的系统结构做了详细的介绍,对于温度较高的低温热源,为了提高能源利用率,采用常规的有机郎肯循环已不能满足需求,所以对常规ORC系统结构做了一些改进,如多级或单级抽汽回热ORC和抽汽再热ORC,并对这两种循环方式分别进行了热力分析和计算。

细胞周期的调控与控制复杂的生命体系中,各种细胞按照特定的节奏执行生长、分裂等过程,这就是所说的细胞周期。
它是生物学中一项非常重要的基础性研究领域,深入探究其调控和控制机制具有重要的理论和实践意义。
一、细胞周期的基本特征细胞周期是指细胞在其生命周期中,从一次分裂开始,到进行下一次分裂所经历的一系列生理和生化过程。
一般可以分为G1期、S期、G2期和M期四个阶段。
在其中,S期是DNA合成期,G1、G2期是生长和备份DNA的阶段,M期则是有丝分裂阶段。
细胞周期可以被分为四个主要的阶段,这四个阶段被精确地调控着,每个阶段都有特定的生物学和生化过程。
这些过程与身体生长、组织修复以及癌症等疾病的发生都有关系。
二、细胞周期的调控机制细胞周期是由众多分子机器驱动的精确的生物化学过程,是优美协调的现象。
这些过程是由一系列的细胞周期调控相互作用实现的,这些相互作用保证着细胞周期的协调和有效性。
为了高度的调控细胞周期,细胞周期过程中的分子必须精确的被正常激活和关闭。
这些激活和关闭的过程受到多种不同的因素的影响,包括蛋白质激酶,蛋白酶,细胞周期调控蛋白(CDKs),细胞周期负调控蛋白(CKIs)等。
其中CDKs是控制整个准确细胞周期的主要激酶,它们必须通过与其拮抗的抑制分子来被调节。
CDKs的活性是至关重要的,因为过度激活会导致癌症等疾病的发生。
三、细胞周期的控制机制细胞周期的控制机制是指在细胞周期过程中,一系列生物过程中发生的分子和细胞间的相互作用和控制机制。
在舒适的细胞环境中,成年细胞周期大多数时间都停留在G1期。
在逐渐接受到生长信号的情况下,细胞就开始进入周期。
这些信号由多种分子和信号途径控制,包括细胞因子、生长因子、激素、细胞-细胞相互作用等。
一旦细胞进入S期,DNA合成就会开启。
这一过程是由复制起始重复(ORC)、螺旋蛋白复合物(CMG)和DNA聚合酶等复杂的细胞分子完成的,并能够通过调节离子控制因子(ICFs)和干扰素相关的因子(IRFs)等机制受到调控。

基于有机朗肯循环的ORC低温余热发电技术伴随国际能源价格持续上涨,及对可再生能源、清洁能源的呼声日益升高,有机工质朗肯循环(Organic Rankine Cycle简称ORC)低温发电技术在国际电力工业市场已经成为一个异军突起的黑马。
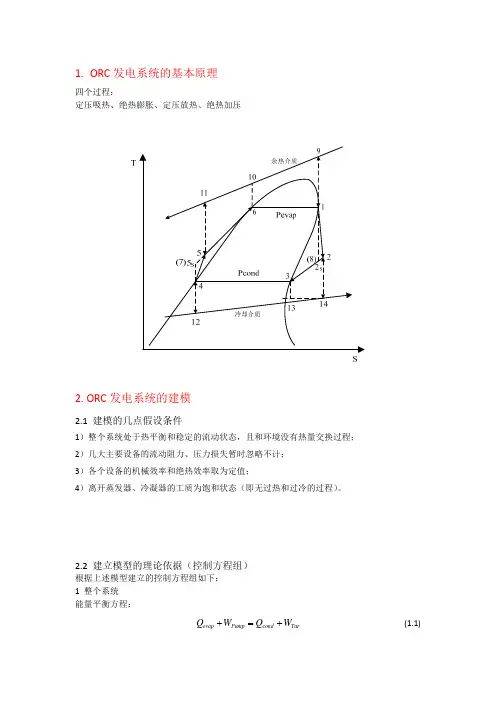
典型的蒸汽动力发电系统,其工作循环可以理想化为由两个可逆定压过程和两个可逆绝热过程组成的理想循环,包括以下四个热力学过程:第一步:定压吸热过程,第二步:绝热膨胀过程,第三步:定压放热过程,第四步:绝热加压过程。
该热力循环理论是由19世纪苏格兰工程师W.J.M.Rankine提出,为纪念其取得的成就,蒸汽动力装置的基本循环亦称为为朗肯循环(Rankine Cycle)。
有机工质朗肯循环专指以低沸点(蒸发温度38度,正戊烷)氟碳氢化合物为循环工质的热力系统,ORC低温发电技术就是基于这一工作过程的发电系统,也称有机工质朗肯循环发电。
ORC低温发电技术,这里低温泛指的温度小于150度但大于90度的热源,其低温热源是工业过程废热、太阳能、海洋温差、地热等清洁能源,技术突破点在于研究更低的热源温度以驱动透平做功发电,以适应更多的工况条件。
尽管发电效率低于传统火电,但由于使用的是清洁能源及工业过程中被废弃的低品质余热,因此在国际能源市场发展迅速。
常规的化石燃料发电技术(火力发电),即利用煤炭、重油或天然气等燃料燃烧时产生的热能来加热水,使水变成高温、高压水蒸气,然后再由水蒸气冲转汽轮机驱动发电机来发电。
这个系统中的循环工质是除盐水,由于水的物理性质(一个大气压,100度蒸发),因此传统电力工业追求的是更高的温度计压力,以提高发电效率,如:超临界、超超临界等。
但是提高发电效率的同时,也带来了环境污染、粉尘、气候变化等负面因素。
因此在低温发电领域,ORC与传统的发电技术相比,具备以下几个优势:1)有机工质具有良好的热力学性质,低的沸点及高的蒸气压力使0RC方法比水蒸气朗肯循环具有较高的热效率,对较低温度热源的利用有更高的效率。

一、名词解释1.临界荷载:指允许地基产生一定范围塑性变形区所对应的荷载。
(02、07、09、11、13)2.临塑荷载:是指基础边缘地基中刚要出现塑性变形时基底单位面积上所承受的荷载,是相当于地基土中应力状态从压密阶段过度到剪切阶段的界限荷载。
(03、04、05、06、08、10)3.最佳含水量:在一定击实功作用下,土被击实至最大干重度,达到最大压实效果时土样的含水量。
(02-13)4.临界水头梯度:土开始发生流沙现象时的水力梯度。
(02、03、04、06、08、10、11)i cr=5.砂流现象:土体在向上渗流力的作用下,颗粒间有效应力为零,颗粒发生悬浮移动的现象。
(05、07、09、13)6.灵敏度:以原状土的无侧限抗压强度与同一土经过重塑后(完全扰动,含水量不变)的无侧限抗压强度之比。
(02)S t=7.地基土的容许承载力:保证地基稳定的条件下,建筑物基础或者土工建筑物路基的沉降量不超过允许值(考虑一定安全储备后的)的地基承载力。
(03)8.主动土压力:当挡土墙向离开土体方向偏移至土体达到极限平衡状态时,作用在墙上的土压力。
(04、10)9.有效应力原理:1 土的有效应力σ′总是等于总应力σ减去孔隙水压力U2 土的有效应力控制了土的变形及强度性质。
(05-13)10.先期固结压力:土层历史上曾经承受的最大固结压力,也就是土体在固结过程中所承受的最大有效应力。
(03)11.正常固结土:土的自重应力(P0)等于土层先期固结压力(Pc)。
也就是说,土自重应力就是该土层历史上受过的最大有效应力。
(ORC=1)(04、07、09、11、13)12.超固结土:土的自重应力小于先期固结压力。
也就是说,该土层历史上受过的最大有效应力大于土自重应力。
(ORC>1)(05、08)13.欠固结土:土层的先期固结压力小于土层的自重应力。
也就是说该土层在自重作用下的固结尚未完成。
(ORC<1)(02、06、10)14.土层的固结度:在某一深度z处,有效应力σzt’与总应力p的比值,也即超静空隙水压力的消散部分与起始超空隙水压力的比值。
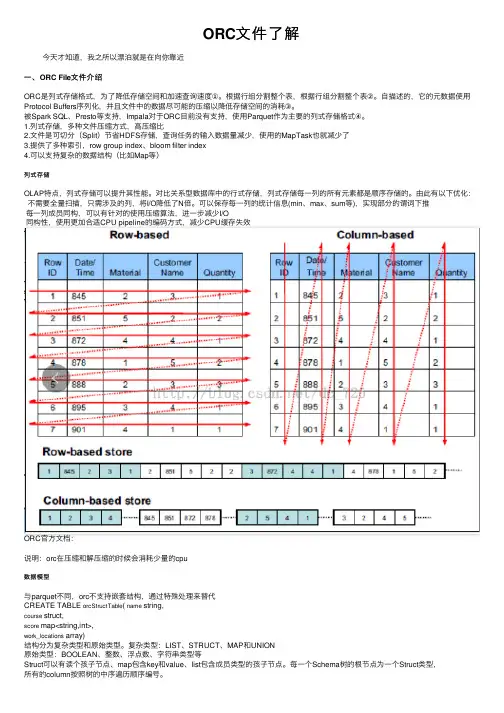
ORC⽂件了解今天才知道,我之所以漂泊就是在向你靠近⼀、ORC File⽂件介绍ORC是列式存储格式,为了降低存储空间和加速查询速度①。
根据⾏组分割整个表,根据⾏组分割整个表②。
⾃描述的,它的元数据使⽤Protocol Buffers序列化,并且⽂件中的数据尽可能的压缩以降低存储空间的消耗③。
被Spark SQL、Presto等⽀持,Impala对于ORC⽬前没有⽀持,使⽤Parquet作为主要的列式存储格式④。
1.列式存储,多种⽂件压缩⽅式,⾼压缩⽐2.⽂件是可切分(Split)节省HDFS存储,查询任务的输⼊数据量减少,使⽤的MapTask也就减少了3.提供了多种索引,row group index、bloom filter index4.可以⽀持复杂的数据结构(⽐如Map等)列式存储OLAP特点,列式存储可以提升其性能。
对⽐关系型数据库中的⾏式存储,列式存储每⼀列的所有元素都是顺序存储的。
由此有以下优化: 不需要全量扫描,只需涉及的列,将I/O降低了N倍。
可以保存每⼀列的统计信息(min、max、sum等),实现部分的谓词下推每⼀列成员同构,可以有针对的使⽤压缩算法,进⼀步减少I/O同构性,使⽤更加合适CPU pipeline的编码⽅式,减少CPU缓存失效ORC官⽅⽂档:说明:orc在压缩和解压缩的时候会消耗少量的cpu数据模型与parquet不同,orc不⽀持嵌套结构,通过特殊处理来替代CREATE TABLE orcStructTable( name string,course struct,score map<string,int>,work_locations array)结构分为复杂类型和原始类型。
复杂类型:LIST、STRUCT、MAP和UNION原始类型:BOOLEAN、整数、浮点数、字符串类型等Struct可以有读个孩⼦节点、map包含key和value、list包含成员类型的孩⼦节点。

扫描的文档可以转换为可编辑word文档扫描文字.结果以图片格式(.bmp)存入电脑.然后使用ORC识别系统进行转换.最终用WORD进行修改编辑.下面教你如何使用ORC:OCR是英文Optical Character Recognition的缩写.翻译成中文就是通过光学技术对文字进行识别的意思. 是自动识别技术研究和应用领域中的一个重要方面.它是一种能够将文字自动识别录入到电脑中的软件技术.是与扫描仪配套的主要软件.属于非键盘输入范畴.需要图像输入设备主要是扫描仪相配合.现在OCR主要是指文字识别软件.在1996年清华紫光开始搭配中文识别软件之前.市场上的扫描仪和OCR软件一直是分开销售的。
扫描仪厂商现在已把专业的OCR软件搭配自己生产的扫描仪出售.OCR技术的迅速发展与扫描仪的广泛使用是密不可分的.近两年随着扫描仪逐渐普及和OCR技术的日臻完善.OCR己成为绝大多数扫描仪用户的得力助手.一.OCR技术的发展历程自20世纪60年代初期出现第一代OCR产品开始.经过30多年的不断发展改进.包括手写体的各种OCR技术的研究取得了令人瞩目的成果.人们对OCR产品的功能要求也从原来的单纯注重识别率.发展到对整个OCR系统的识别速度.用户界面的友好性.操作的简便性.产品的稳定性.适应性.可靠性和易升级性.售前售后服务质量等各方面提出更高的要求.IBM公司最早开发了OCR产品.1965年在纽约世界博览会上展出了IBM公司的OCR产品--IBMl287.当时的这款产品只能识别印刷体的数字.英文字母及部分符号.并且必须是指定的字体.20世纪60年代末.日立公司和富士通公司也分别研制出各自的OCR产品.全世界第一个实现手写体邮政编码识别的信函自动分拣系统是由日本东芝公司研制的.两年后NEC公司也推出了同样的系统.到了1974年.信函的自动分拣率达到92%左右.并且广泛地应用在邮政系统中.发挥着较好的作用.1983年日本东芝公司发布了其识别印刷体日文汉字的OCR系统OCRV595.其识别速度为每秒70-100个汉字.识别率为99.5%.其后东芝公司又开始了手写体日文汉字识别的研究工作.中国在OCR技术方面的研究工作相对起步较晚.在20世纪70年代才开始对数字.英文字母及符号的识别技术进行研究.20世纪70年代末开始进行汉字识别的研究.1986年.国家863计划信息领域课题组织了清华大学.北京信息工程学院.沈阳自动化所三家单位联合进行中文OCR软件的开发工作.至*****.清华大学率先推出了国内第一套中文OCR软件--清华文通TH-OCR1.0版.至此中文OCR正式从实验室走向了市场.清华OCR印刷体汉字识别软件其后又推出了TH-OCR 92高性能实用简/繁体.多字体.多功能印刷汉字识别系统.使印刷体汉字识别技术又取得重大进展.到1994年推出的TH-OCR 94高性能汉英混排印刷文本识别系统.则被专家鉴定为[是国内外首次推出的汉英混排印刷文本识别系统.总体上居国际领先水平".上个世纪90年代中后期.清华大学电子工程系提出并进行了汉字识别综合研究.使汉字识别技术在印刷体文本.联机手写汉字识别.脱机手写汉字识别和脱机手写数字符号识别等领域全面地取得了重要成果.具有代表性的成果是TH-OCR 97综合集成汉字识别系统.它可以完成多文种(汉.英.日)印刷文本.联机手写汉字.脱机手写汉字和手写数字的识别输入.几年来.除清华文通TH-OCR外.其它如尚书SH-OCR等各具风格的OCR软件也相继问世.中文OCR市场稳步扩大.用户遍布世界各地.可以说目前印刷体OCR的识别技术已经达到较高水平.OCR产品已由早期的只能识别指定的印刷体数字.英文字母和部分符号.发展成为可以自动进行版面分析.表格识别.实现混合文字.多字体.多字号.横竖混排识别的强大的计算机信息快速录入工具.对印刷体汉字的识别率达到98%以上.即使对印刷质量较差的文字其识别率也达到95%以上.可识别宋体.黑体.楷体.仿宋体等多种字体的简.繁体.并且可以对多种字体.不同字号混合排版进行识别.对手写体汉字的识别率达到70%以上.特别是我国的汉字OCR技术经过十几年的努力.克服了起步晚.汉字字符集异常庞大等困难.单字的识别速度(指在单位时间内所完成的从特征提取到识别结果输出的字数)可以达到70字/秒以上.由于印刷体OCR汉字识别技术已经比较成熟.所以OCR产品被广泛地应用在新闻.印刷.出版.图书馆.办公自动化等各个行业.专业型OCR产品多是面向特定的行业.即适用于每天需处理大量表格信息录入的部门.如邮政.税务.海关.统计等等.这种面向特定行业的专业型OCR系统.格式较为固定.识别的字符集相对较小.经常与专用的输入设备结合使用.因此具有速度快.效率高等特点.比如邮件自动分拣系统等.手写文稿的识别直到1996.1997年才开始有产品问世.而且是作为印刷文稿识别产品的一项附加功能提供的.由于人写字的习惯千差万别.实现自由手写体识别相当困难.所以手写体OCR技术的使用领域是联机手写体识别.即人一边写.计算机一边识别.是一种实时识别方式.二.OCR的基本原理简单地说.OCR的基本原理就是通过扫描仪将一份文稿的图像输入给计算机.然后由计算机取出每个文字的图像.并将其转换成汉字的编码.其具体工作过程是.扫描仪将汉字文稿通过电荷耦合器件CCD将文稿的光信号转换为电信号.经过模拟/数字转换器转化为数字信号传输给计算机.计算机接受的是文稿的数字图像.其图像上的汉字可能是印刷汉字.也可能是手写汉字.然后对这些图像中的汉字进行识别.对于印刷体字符.首先采用光学的方式将文档资料转换成原始黑白点阵的图像文件.再通过识别软件将图像中的文字转换成文本格式.以便文字处理软件的进一步加工.其中文字识别是OCR的重要技术.1.OCR识别的两种方式与其它信息数据一样.在计算机中所有扫描仪捕捉到的图文信息都是用0.1这两个数字来记录和进行识别的.所有信息都只是以0.1保存的一串串点或样本点.OCR 识别程序识别页面上的字符信息.主要通过单元模式匹配法和特征提取法两种方式进行字符识别.单元模式匹配识别法(Pattern Matching)是将每一个字符与保存有标准字体和字号位图的文件进行不严格的比较.如果应用程序中有一个已保存字符的大数据库.则应用程序会选取合适的字符进行正确的匹配.软件必须使用一些处理技术.找出最相似的匹配.通常是不断试验同一个字符的不同版本来比较.有些软件可以扫描一页文本.并鉴别出定义新字体的每一个字符.有些软件则使用自己的识别技术.尽其所能鉴别页面上的字符.然后将不可识别的字符进行人工选择或直接录入.特征提取识别法(Feature Extraction)是将每个字符分解为很多个不同的字符特征.包括斜线.水平线和曲线等.然后.又将这些特征与理解(识别)的字符进行匹配.举个简单的例子.应用程序识别到两条水平横线.它就会[认为"该字符可能是[二".特征提取法的优点是可以识别多种字体.例如中文书法体就是采用特征提取法实现字符识别的.多数OCR应用软件都加入了语法智能检查功能.这种功能进一步提高了识别率.它主要通过上下文检查法实现拼写和语法的纠正.在文字识别时.OCR应用程序会做多次的上下文衔接性检查.根据程序中已经存在的词组.固定的用词顺序.对应的检查字符串的用词字.比较高级的应用软件会自动用它[认为"正确的词语替换错误词语.纠正语句意思.2.文字识别的几个步骤文字识别包括以下几个步骤:图文输入.预处理.单字识别和后处理等.(1)图文输入是指通过输入设备将文档输入到计算机中.也就是实现原稿的数字化.现在用得比较普遍的设备是扫描仪.文档图像的扫描质量是OCR软件正确识别的前提条件.恰当地选择扫描分辨率及相关参数.是保证文字清楚.特征不丢失的关键.此外.文档尽可能地放置端正.以保证预处理检测的倾斜角小.在进行倾斜校正后.文字图像的变形就小.这些简单的操作.会使系统的识别正确率有所提高.反之.由于扫描设置不当.文字的断笔过多可能会分检出半个文字的图像.文字断笔和笔画粘连会造成有些特征丢失.在将其特征与特征库比较时.会使其特征距离加大.识别错误率上升.(2)预处理扫描一幅简单的印刷文档的图像.将每一个文字图像分检出来交给识别模块识别.这一过程称为图像预处理.预处理是指在进行文字识别之前的一些准备工作.包括图像净化处理.去掉原始图像中的显见噪声(干扰).主要任务是测量文档放置的倾斜角.对文档进行版面分析.对选出的文字域进行排版确认.对横.竖排版的文字行进行切分.每一行的文字图像的分离.标点符号的判别等.这一阶段的工作非常重要.处理的效果直接影响到文字识别的准确率.版面分析是对文本图像的总体分析.是将文档中的所有文字块分检出来.区分出文本段落及排版顺序.以及图像.表格的区域.将各文字块的域界(域在图像中的始点.终点坐标).域内的属性(横.竖排版方式)以及各文字块的连接关系作为一种数据结构.提供给识别模块自动识别.对于文本区域直接进行识别处理.对于表格区域进行专用的表格分析及识别处理.对于图像区域进行压缩或简单存储.行字切分是将大幅的图像先切割为行.再从图像行中分离出单个字符的过程.(3)单字识别单字识别是体现OCR文字识别的核心技术.从扫描文本中分检出的文字图像.由计算机将其图形.图像转变成文字的标准代码.是让计算机[认字"的关键.也就是所谓的识别技术.就像人脑认识文字是因为在人脑中已经保存了文字的各种特征.如文字的结构.文字的笔画等.要想让计算机来识别文字.也需要先将文字的特征等信息储存到计算机里.但要储存什么样的信息及怎样来获取这些信息是一个很复杂的过程.而且要达到非常高的识别率才能符合要求.通常采用的做法是根据文字的笔画.特征点.投影信息.点的区域分布等进行分析.中国汉字常用的就有几千.识别技术就是特征比较技术.通过和识别特征库的比较.找到特征最相似的字.提取该文字的标准代码.即为识别结果.比较是人们认识事物的一种基本方法.汉字识别也是通过比较找出汉字之间的相同.相似.相异.把握其量和质的关系.以及时间与空间的关系等.对于大字符集的汉字一般采用多级分类.多特征.全方位动态匹配求相似集.以保证分类率高.适应性强.稳定性好,细分类重点在于对相似集求异匹配.加权处理.结构判别.定量.定性分析.以及前后联接词的关系.最后进行判别.汉字识别实质上是比较科学或认知科学在人工智能方面的应用.其关键技术是识别特征库.计算机有了这样的一个特征库.才能完成认字的功能.在图像文档的版面中.除了有文字.图片.有时还会有表格存在.为了使识别后的表格数字化.需要在版面分析过程中.对表格域进行特殊的处理.它包括对表格线的结构信息的提取.对表格内文字域的分检.完成对表格线和对文字域的识别.并根据表格线的数字化生成不同的文件格式.由于文档中的表格随意性大.格式多样.有封闭式的.也有开放式的.特别是表格中的斜线.给表格分析造成一定的困难.(4)后处理后处理是指对识别出的文字或多个识别结果采用词组方式进行上下匹配.即将单字识别的结果进行分词.与词库中的词组进行比较.以提高系统的识别率.减少误识率.汉字字符识别是文字识别领域最为困难的问题.它涉及模式识别.图像处理.数字信号处理.自然语言理解.人工智能.模糊数学.信息论.计算机.中文信息处理等学科.是一门综合性技术.近几年来.印刷汉字识别系统的单字识别正确率已经超过95%.为了进一步提高系统的总体识别率.扫描图像.图像的预处理以及识别后处理等方面的技术也都得到了深入的研究.并取得了长足的进展.有效地提高了印刷汉字识别系统的总体性能.清华大学在此方面的研究成果突出.已经成为世界上的最具权威的机构之一.目前.清华紫光的全系列扫描仪中都配装了清华OCR千禧版软件.它在识别率.表格识别甚至规范手写体的识别方面.均达到了较高水平.三.OCR文字识别技巧在最近几年中.OCR识别技术随着扫描仪的普及得到了飞速的发展.扫描.识别软件的性能不断强大并向智能化不断升级发展.但是要想快速地获取正确的扫描结果.得到高效率的文字录入.必须认真学习有关知识.结合实践经验.摸索出自己的全套解决方案.有时我们在作文字识别工作时识别率非常低.根本达不到软件所说的95%以上.请先不要责怪硬件或软件.其实这是没有掌握好扫描及OCR识别技巧的原因.下面是文字识别操作中经常用到了一些方法和技巧.1.分辨率的设置是文字识别的重要前提.一般来讲.扫描仪提供较多的图像信息.识别软件比较容易得出识别结果.但也不是扫描分辨率设得越高识别正确率就越高.选择300dpi或400dpi分辨率.适合大部分文档扫描.注意文字原稿的扫描识别.设置扫描分辨率时千万不要超过扫描仪的光学分辨率.不然会得不偿失.下面是部分典型设置.仅供参考.(1)1.2.3号字的文章段.推荐使用200dpi.(2)4.小4.5号字的文章段.推荐使用300dpl(3)小5.6号字的文章段.推荐使用400dpl(4)7.8号字的文章段.推荐使用600dpi.2. 扫描时适当地调整好亮度和对比度值.使扫描文件黑白分明.这对识别率的影响最为关键.扫描亮度和对比度值的设定以观察扫描后的图像中汉字的笔画较细但又不断开为原则.进行识别前.先看看扫描得到的图像中文字质量如何.如果图像存在黑点或黑斑时或文字线条很粗很黑.分不清笔画时.说明亮度值太小了.应该增加亮度值在试试,如果文字线条凹凸不平.有断线甚至图像中汉字轮廓严重残缺时.说明亮度值太大了.应减小亮度后再试试.3.选好扫描软件.选一款好的适合自己的OCR软件是作好文字识别工作的基础.一般不要使用扫描仪自带的OEM软件.OEM的OCR软件的功能少.效果差.有的甚至没有中文识别.经过比较.我认为清华紫光OCR2003专业版和尚书OCR6.0文本自动识别输入系统的识别能力与使用功能更突出一些.再选一个图像软件.OCR软件不是有扫描接口吗?为什么还找图像软件?第一.OCR软件不能识别所有的扫描仪,第二.也是最关键的.利用图像软件的扫描接口扫描出来的图像便于处理,一般选用PHOTOSHOP.4.如果要进行的文本是带有格式的.如粗体.斜体.首行缩进等.部分OCR软件识别不出来.会丢失格式或出现乱码.如果必须扫描带有格式的文本.事先要确保使用的识别软件是否支持文字格式的扫描.也可以关闭样式识别系统.使软件集中注意力查找正确的字符.不再顾及字体和字体格式.。
flume orc 格式一、介绍Flume和ORC格式Flume是一个可靠、可扩展且可管理的分布式日志收集、聚合和传输系统。
它可以帮助用户快速地将大量的数据从各种数据源(如Web服务器、数据库等)中收集起来,并将其传输到目标位置(如Hadoop HDFS、HBase等)。
Flume的主要特点包括:高度可靠性、高度可扩展性、易于管理和配置等。
ORC(Optimized Row Columnar)格式是一种面向列的二进制文件格式,它旨在提高Hadoop上的数据处理效率。
与传统的行式存储方式不同,ORC会将数据按列存储,这样可以更好地利用压缩算法和编码技术来提高存储效率和查询性能。
二、Flume与ORC格式的结合Flume可以与Hadoop生态系统中的多个组件集成,其中包括HDFS、HBase等。
当使用Flume将数据传输到这些组件时,通常需要选择合适的数据格式来存储数据。
在这里,我们介绍一种将Flume与ORC格式结合使用的方法。
1. Flume配置首先,需要在Flume中配置一个Source来指定要收集哪些日志数据,并将其发送到一个Channel中。
然后,在Channel中配置一个Sink来指定要将日志写入哪个目标位置(如HDFS)。
在Sink中,需要指定使用ORC格式来存储数据。
以下是一个Flume配置文件的示例:```# Define a sourceagent.sources = mysourceagent.sources.mysource.type = execmand = tail -F /var/log/messages# Define a channelagent.channels = mychannelagent.channels.mychannel.type = memoryagent.channels.mychannel.capacity = 10000# Define a sinkagent.sinks = mysinkagent.sinks.mysink.type = hdfsagent.sinks.mysink.hdfs.path = /user/flume/logs/agent.sinks.mysink.hdfs.filePrefix = logs-agent.sinks.mysink.hdfs.fileSuffix = .orcagent.sinks.mysink.hdfs.rollInterval = 3600# Bind the source and sink to the channelagent.sources.mysource.channels = mychannelagent.sinks.mysink.channel = mychannel```在上述配置文件中,我们使用了一个exec Source来收集/var/log/messages文件中的日志数据,并将其发送到一个memory Channel中。
基于有机朗肯循环的发动机余热回收技术郭丽华;覃峰;陈江平;刘杰【摘要】Eight kinds of cycle media in organic Rankine cycle (ORC) were compared during the thermodynamic process. Considering the systemic, reliable and environmental factors, R245fa was the optimum selection for ORC. For the application of Cummins heavy duty vehicle engine, the power generation system with the waste heat recovery was designed. Recovering the heat from charge air, tail pipe gas and exhaust gas, the power generation was realized. The efficiency of waste heat recovery in the system was 10. 4%.%通过比较8种循环工质在有机朗肯循环(ORC)系统中的热力过程,从系统性能、可靠性、环保等角度综合考虑,验证了R245fa用于ORC循环工质的优势.以康明斯某重型车用发动机为应用目标,设计了一套余热回收发电系统,通过回收增压空气、尾管废气、发动机废气的热量,用于发电.经过计算,该系统的余热回收效率为10.4%.【期刊名称】《车用发动机》【年(卷),期】2012(000)002【总页数】5页(P30-34)【关键词】有机朗肯循环;余热回收;循环工质;换热器;膨胀机【作者】郭丽华;覃峰;陈江平;刘杰【作者单位】浙江银轮机械股份有限公司,浙江天台 317200;浙江银轮机械股份有限公司,浙江天台 317200;上海交通大学制冷与低温工程研究所,上海200240;上海交通大学制冷与低温工程研究所,上海200240【正文语种】中文【中图分类】TK427据统计[1],化石燃料在内燃机中燃烧产生的能量仅有大约1/3转化为有用功,剩余部分都通过废气、冷却水等介质直接排向大气,在造成能源浪费的同时,也污染了环境。
低温地热水O R C发电一、地热资源丰富地热能是指地球内部蕴藏的能量,一般集中分布在构造板块边缘一带,起源于地球的熔融岩浆和放射性物质的衰变。
据估算,距地壳深度5km以内蕴藏的热量约为1.46×1026J。
若其中的1%可供开采,则该深度的地热能将提供 1.46×1024J的能量,而目前全世界的每年的能量消耗约为 4.18×1020J ,理论上来讲,这部分能量将可供人类使用3500年。
如果能经济的开发这部分资源做发电利用,部分替代以化石能源为燃料的发电方式,对于促进可再生能源开发利用,减小化石能源消耗和CO2、SO2、NOx等温室气体和环境污染物的排放,实现可持续发展,具有重要意义。
全球地热资源中32%的地热温度高于130℃,而68%的地热温度低于130℃。
二、地热资源的划分通常,地热资源可以按温度来划分,地热温度高于150℃为高温,地热温度低于90℃为低温,而地热温度处于90~150℃为中温。
三、地热发电的负荷率地热能是绿色能源,也是可再生能源。
世界上已有24个国家利用地热能发电,其中有5个国家的地热发电量占国家总发电量的15%~22%。
从BP公司(世界最大的能源公司之一)的统计数字显示,截止2008年底,全球地热发电总装机容量已达到10469 MW。
地热能是一种环境友好型能源,与化石燃料能源相比,在开发利用过程中几乎没有废气排放,且废水排入地下。
在已知的新能源中,地热能发电不受季节影响,因此它是稳定、可靠的能源,可用于带基本负荷运行的电站。
BP能源公司2009年世界能源统计:地热发电的负荷率高达90%;太阳能发电负荷率为20%;风力发电负荷率为25%。
四、地热发电运行成本美国能源部(DOE)在2009 年的地热能技术报告中指出,地热能发电的每MWh 发电成本(Levelized Energy Cost 或者LEC)为42-69 美元,其经济性优于风能发电、太阳能热发电、光伏太阳能发电等其他可再生能源发电利用方式。
低温地热水ORC发电一、地热资源丰富地热能是指地球内部蕴藏的能量,一般集中分布在构造板块边缘一带,起源于地球的熔融岩浆和放射性物质的衰变。
据估算,距地壳深度5km以内蕴藏的热量约为1.46×1026J。
若其中的1%可供开采,则该深度的地热能将提供 1.46×1024J的能量,而目前全世界的每年的能量消耗约为 4.18×1020J ,理论上来讲,这部分能量将可供人类使用3500年。
如果能经济的开发这部分资源做发电利用,部分替代以化石能源为燃料的发电方式,对于促进可再生能源开发利用,减小化石能源消耗和CO2、SO2、NOx 等温室气体和环境污染物的排放,实现可持续发展,具有重要意义。
全球地热资源中32%的地热温度高于130℃,而68%的地热温度低于130℃。
二、地热资源的划分通常,地热资源可以按温度来划分,地热温度高于150℃为高温,地热温度低于90℃为低温,而地热温度处于90~150℃为中温。
三、地热发电的负荷率地热能是绿色能源,也是可再生能源。
世界上已有24个国家利用地热能发电,其中有5个国家的地热发电量占国家总发电量的15%~22%。
从BP公司(世界最大的能源公司之一)的统计数字显示,截止2008年底,全球地热发电总装机容量已达到10469 MW。
地热能是一种环境友好型能源,与化石燃料能源相比,在开发利用过程中几乎没有废气排放,且废水排入地下。
在已知的新能源中,地热能发电不受季节影响,因此它是稳定、可靠的能源,可用于带基本负荷运行的电站。
BP能源公司2009年世界能源统计:地热发电的负荷率高达90%;太阳能发电负荷率为20%;风力发电负荷率为25%。
四、地热发电运行成本美国能源部(DOE)在2009 年的地热能技术报告中指出,地热能发电的每MWh 发电成本(Levelized Energy Cost 或者LEC)为42-69 美元,其经济性优于风能发电、太阳能热发电、光伏太阳能发电等其他可再生能源发电利用方式。
ORACLE 基本知识培训教材前言本教材主要是介绍 ORACLE 的基本知识,目的是为了让新员工快速了解 ORACLE 的基本知识, 本教材培训及学习时间为一天,培训方式采用课堂讲课、自己学习、考试的方式。
本书只作为入门指南,另附有一些专题学习书,供大家进阶学习用。
ORACLE 的环境介绍每一个 Oracle 数据库都是一个数据的集合,这些数据包含在一个或多个文件中。
数 据库有物理和逻辑两种结构。
在开发应用程序的过程中,用户创建表和索以便于数据进行保存和快速检索。
用户 可以为对象的名称创建方便的同义词,通过将数据库链接到不同的数据库中查看对 象,并且能够限制对象的访问权限。
用户还可以使用外部表访问当前数据库之外的文件中的数据,就像访问表中的数据 一样。
Oracle 实例由被称为系统全局区(system global area,SGA)的内存区域和相应的 后台进程组成。
这些后台进程负责 SGA 和数据库磁盘文件之间的交互。
在 Oracle RAC 中,可以有多个实例同时使用同一个数据库。
这些实例通常位于不 同的服务器上,并且保持着高速互联。
数据库中的所有逻辑结构都必须存储在数据库中的某个地方。
Oracle 系统提供 了一个记录与所有对象(对象所有者、定义、相关的优先级等)相关的元数据的 数据字典。
对于需要物理空间保存的对象, Oracle 系统会在一个表空间中为其 分配空间。
表空间由一个或多个文件组成,数据文件可能是表空间的全部,也可能是一个 表空间的一部分。
为了支持事务,Oracle 系统能够动态地创建、管理、撤销数据段。
Oracle Database 10g 系统提出的回收站概念,使得表空间和数据文件对空间 的需求发生了变化。
在 Oracle 系统的体系结构中,有许多不同的内存区域。
不同的内存区域用于 不同的目的。
Oracle 的服务器进程和许多后台进程负责在内存区域中写入、 更 新、读取和删除数据。
orc格式表ORC格式表是一种用于存储结构化数据的文件格式,全称为Optimized Row Columnar。
它是由Apache Hadoop项目开发的一种列式存储格式,主要用于大数据处理和分析。
ORC格式表的主要特点有以下几点:1. 高效的压缩:ORC文件采用了多种压缩算法,如Lempel-Ziv-Welch(LZW)、Snappy、Gzip等,可以有效地减小文件大小,提高存储和查询效率。
2. 列式存储:与传统的行式存储相比,ORC文件采用列式存储结构,可以更高效地读取和查询某一列的数据。
这对于大数据分析中的聚合操作和筛选操作非常有利。
3. 元数据信息:ORC文件包含了丰富的元数据信息,如表结构、列类型、分区信息等。
这些信息可以帮助用户更好地理解和使用数据。
4. 支持复杂数据类型:ORC文件支持多种复杂的数据类型,如数组、映射、枚举等。
这使得用户可以在ORC文件中存储更丰富的数据。
5. 跨平台兼容:ORC格式表可以在多种操作系统和数据库平台上使用,如Hadoop、Spark、Hive等。
要创建一个ORC格式表,可以使用以下步骤:1. 准备数据:首先需要将原始数据转换为适合存储在ORC文件中的格式。
这通常需要对数据进行清洗、转换和格式化等操作。
2. 创建表:使用Hive或其他支持ORC格式的数据库工具,创建一个新表,并指定其存储为ORC格式。
例如,在Hive中,可以使用以下语句创建一个名为“orc_table”的表,并将其存储为ORC格式:sqlCREATE TABLE orc_table (id INT,name STRING,age INT,address STRING) STORED AS ORC;3. 加载数据:将准备好的数据加载到新创建的ORC表中。
这可以通过INSERT语句或LOAD DATA语句实现。
例如,在Hive中,可以使用以下语句将数据加载到`orc_table`表中:sqlLOAD DATA INPATH '/path/to/your/data' INTO TABLE orc_table;4. 查询数据:使用SQL语句对ORC表中的数据进行查询和分析。