第五章数据分析(梅长林)习题
- 格式:docx
- 大小:78.16 KB
- 文档页数:9
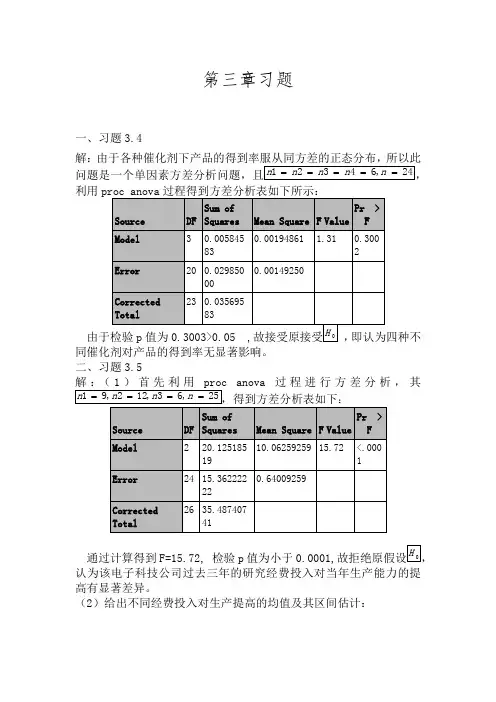
第三章习题一、习题3.4解:由于各种催化剂下产品的得到率服从同方差的正态分布,所以此利用proc anova过程得到方差分析表如下所示:同催化剂对产品的得到率无显著影响。
二、习题3.5anova过程进行方差分析,其通过计算得到F=15.72, 检验p值为小于0.0001,认为该电子科技公司过去三年的研究经费投入对当年生产能力的提高有显著差异。
(2)给出不同经费投入对生产提高的均值及其区间估计:为95%的置信区间为:95%的Bonferroni 同时置信区间为:Bonferroni 同时置信区间都位于负值区间可知随着三年科研经费的投入越高,当年生产能力的改善越显著。
三、习题3.6解:(1)首先利用SAS 的proc anova 过程的means 语句,求出各水平的均值和标准差:如下所示:由上表可知,(a1,b1)组合和(a1,b3)组合的标准差分别为2.030875、2.8067751与其他组合的标准差相差较大,所以我认为假定误差的等方差性不太合理。
故不能直接进行方差分析。
(2)由(1)可知直接进行方差分析是不合理的,所以对观测数据做对数变换,首先来分析个水平组合是否是方差齐性的。
由以上结果可以看出各组合水平上的标准差趋于一致,各组之间的标准差差异比较小。
说明各组合的离散程度比较接近。
故可以利用变换之后的数据在进行方差分析。
(3)由SAS系统的proc anova过程对进行自然对数变换后的数据进行方差分析,得到如下的误差分析表:x1*x2的影响是不显著的,检验P=0.3143>0.05,即两种铁离子残留量的百分比差异在不同剂量水平下可认为是相同的。
而由因素A和因素B对残留量的百分比的影响均显著,检验P值分别为0.0161和<.0001,所以两种铁离子残留量的百分比是有显著差异的,不同剂量水平下残留量的百分比也是有显著差异的。
(4)求出各因素在不同水平下的均值以及估计区间:SAS系统的proc anova过程对数据进行方差分析,得到各因素两两的Bonferroni同时置信区间为:均值之差的置信度为95%(注:可编辑下载,若有不当之处,请指正,谢谢!)。

习题4.5实验报告一、实验目的问题描述:在习题1.5表1.9中,列出了历年人口出生率、死亡率和自然增长率(单位:%)。
设对应于人口出生率、人口死亡率、自然增长率的数据变量分别为x1,x2,x3。
(1)分别从样本协方差矩阵S及样本相关矩阵R出发,求x1,x2,x3的样本主成分y1,y2,计算各样本主成分的贡献率。
(2)分别从样本协方差矩阵S及样本相关矩阵R出发,将第一样本主成分y1从小到大排序,并给与分析。
二、所用方法及工具(1)主成分分析法与贡献率:主成分分析法即构造原变量的一系列线性组合,使各线性组合在彼此不相关的前提下尽可能多地反映原变量的信息,即使其方差最大。
求的各主成分,等价于求它的协方差矩阵的各特征值及相应的正交单位化特征向量.按特征值由大到小所对应的正交单位化特征向量为组合系数的X,Xz ,…,X,的线性组合分别为X的第一,第二、直至第p个主成分,而各主成分的方差等于相应的特征值。
(2)SAS编程:SAS语言是一种专用的数据管理与分析语言,它提供了一种完善的编程语言。
类似于计算机的高级语言,SAS用户只需要熟悉其命令、语句及简单的语法规则就可以做数据管理和分析处理工作。
因此,掌握SAS编程技术是学习SAS的关键环节。
在SAS中,把大部分常用的复杂数据计算的算法作为标准过程调用,用户仅需要指出过程名及其必要的参数。
这一特点使得SAS编程十分简单。
三、实验内容本次实验采用SAS编程实现,代码如下:data a;set sjfx.rk1;run;proc princomp n=2 cov out=out1;var x1 x2 x3;run;proc sort data=out1 out=a1;by prin1;run;proc print data=a1;run;proc princomp n=2 out=out2;var x1 x2 x3;run;proc sort data=out2 out=a2;by prin1;run;proc print data=a2;run;实验结果:PRINCOMP 过程。
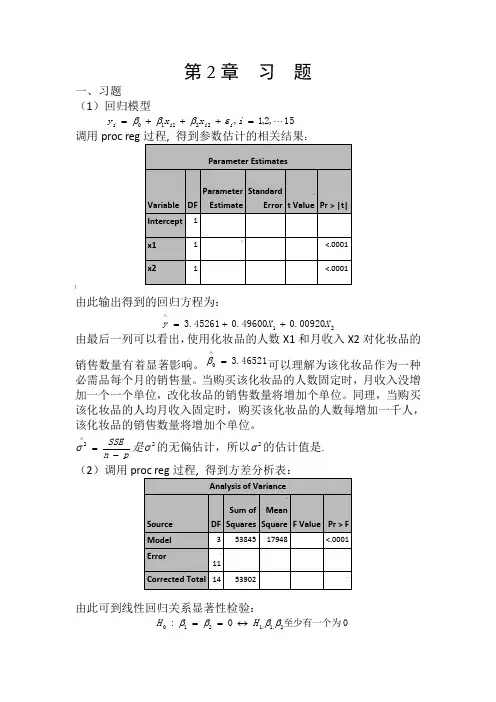
第2章 习 题一、习题(1)回归模型15,2,1,22110 =+++=i x x y i i i i εβββ调用proc reg:]由此输出得到的回归方程为:2100920.049600.045261.3X X y ++=∧由最后一列可以看出,使用化妆品的人数X1和月收入X2对化妆品的销售数量有着显著影响。
46521.30=∧β可以理解为该化妆品作为一种必需品每个月的销售量。
当购买该化妆品的人数固定时,月收入没增加一个一个单位,改化妆品的销售数量将增加个单位。
同理,当购买该化妆品的人均月收入固定时,购买该化妆品的人数每增加一千人,该化妆品的销售数量将增加个单位。
pn SSE-=∧2σ是2σ的无偏估计,所以2σ的估计值是. (2)调用由此可到线性回归关系显著性检验:0至少有一个为0:2,1:1210ββββH H ↔==的统计量/(1)/()SSR p MSRF SSE n p MSE-==-的观测值47.56790=F ,检验的p 值0001.0)(000<>==F F p p H另外9989.053902538452===SST SSR R ,2R 描述了由自由变量的线性关系函数值所能反映的Y 的总变化量的比例。
2R 越大,表明线性关系越明显。
这些结果均表明Y 与X1,X2之间的回归关系高度显著。
(3)若置信水平05.0=α,由17881.2)12(975.0=t ,利用参数估计值得到21,0,βββ的置信区间分别为:对,0β2942.54516.343065.21781.245216.3±=⨯±,即)7458.8,8426.1(-) 对1β:01318.049600.000605.01781.249600.0±=⨯±,即)50198.0,48282.0( )2β:0021.000920.00009681.01781.200920.0±=⨯±,即)00113.0,0071.0(-(4)首先检验X1对Y 是否有显著性影:假设其约简模型为:15,2,1,220 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得:88137.484)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f由[()()]()()/R F FSSE R SSE F f f F SSE F f --=求得检验统计量的值为:3.9012/88357.5688357.5688137.4840=-=F05.0))13,1(()(0000<>==>==F F P F F p p H由此拒绝原假设,所以x2对Y 有显著影响。

数据分析答案梅长林【篇一:1.1一维数据数字特征】013学年第一学期主讲教师李晓燕课程名称数据分析课程类别专业限选课学时及学分 68;4授课班级信息101 102使用教材《数据分析方法》系(院.部) 数理系教研室(实验室) 信息和计算科学教研室数据分析总学时:68 理论38.上机28 适用专业:信息和计算科学内容:? sas软件介绍 3学时 ? 数据的描述性分析10学时 ? 线性回归分析 13学时 ? 方差分析 10学时 ? 主成分分析和典型相关分析8学时? 判别分析 8学时 ? 聚类分析 8学时 ? 学生报告 8学时教材:《数据分析方法》,梅长林、范金城编,高等教育出版社.2006. 参考资料:《实用统计方法》,梅长林编,科学出版社;《使用多元统计分析》,高惠璇编,北京大学出版社,2005;《使用统计方法和sas系统》,高惠璇编,北京大学出版社,2001;《多元统计分析》(二版),何晓群编,中国人民大学出版社,2008;《使用回归分析》(二版),何晓群编,中国人民大学出版社,2007;《统计建模和r软件》,薛毅编著,清华大学出版社,2007. 考核:期末成绩(闭卷测试+上机测试):70%。
平时成绩(平时作业+考勤+大报告):30%。
课程作业(1)作业题目在网络教学平台公布,按格式要求,以电子版方式通过平台提交。
(2)大报告:2-3人一组,每组一个选题,成员按相同的成绩计分。
收集数据,撰写小论文,做ppt讲解。
每组讲10-20分钟,提问环节。
同学打分。
课时授课计划课次序号: 01一、课题:1.1 一维数据的数字特征及相关系数二、课型:新授课三、目的要求:1.掌握数据的数字特征(均值、方差等);2.掌握几种描述性分析的sas过程和作图过程计算这些数字特征及进行描述性分析.四、教学重点:均值、方差等数字特征.教学难点:基本概念的理解.五、教学方法及手段:传统教学和上机实验相结合.六、参考资料:1.《实用统计方法》,梅长林,周家良编,科学出版社;2.《sas统计分析使用》,董大钧主编,电子工业出版社.七、作业:1.1八、授课记录:九、授课效果分析:0 绪论0.1 课程内涵数据分析(即多元统计学statistics):是以数据为依据,以统计方法为理论、计算机及软为工具,研究多变量问题、挖掘数据的统计规律的学科. 通过收集数据、整理数据、分析数据和由数据得出结论的一组概念、原则和方法。
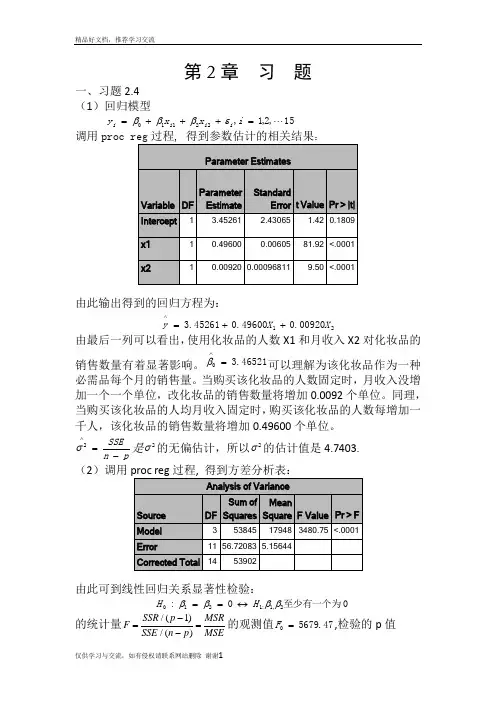
第2章 习 题一、习题2.4 (1)回归模型15,2,1,22110 =+++=i x x y i i i i εβββ调用:由此输出得到的回归方程为:2100920.049600.045261.3X X y ++=∧由最后一列可以看出,使用化妆品的人数X1和月收入X2对化妆品的销售数量有着显著影响。
46521.30=∧β可以理解为该化妆品作为一种必需品每个月的销售量。
当购买该化妆品的人数固定时,月收入没增加一个一个单位,改化妆品的销售数量将增加0.0092个单位。
同理,当购买该化妆品的人均月收入固定时,购买该化妆品的人数每增加一千人,该化妆品的销售数量将增加0.49600个单位。
pn SSE-=∧2σ是2σ的无偏估计,所以2σ的估计值是4.7403. (2)调用由此可到线性回归关系显著性检验:0至少有一个为0:2,1:1210ββββH H ↔== 的统计量/(1)/()SSR p MSRF SSE n p MSE-==-的观测值47.56790=F ,检验的p 值0001.0)(000<>==F F p p H另外9989.053902538452===SST SSR R ,2R 描述了由自由变量的线性关系函数值所能反映的Y 的总变化量的比例。
2R 越大,表明线性关系越明显。
这些结果均表明Y 与X1,X2之间的回归关系高度显著。
(3)若置信水平05.0=α,由17881.2)12(975.0=t ,利用参数估计值得到21,0,βββ的置信区间分别为:对,0β2942.54516.343065.21781.245216.3±=⨯±,即)7458.8,8426.1(-) 对1β:01318.049600.000605.01781.249600.0±=⨯±,即)50198.0,48282.0( 2β:0021.000920.00009681.01781.200920.0±=⨯±,即)00113.0,0071.0(-(4)首先检验X1对Y 是否有显著性影:假设其约简模型为:15,2,1,220 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得:88137.484)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f由[()()]()()/R F FSSE R SSE F f f F SSE F f --=求得检验统计量的值为:3.9012/88357.5688357.5688137.4840=-=F05.0))13,1(()(0000<>==>==F F P F F p p H由此拒绝原假设,所以x2对Y 有显著影响。

第五单元数据分析与人工智能5.1走近数据分析一、学习目标:课本P1181、了解数据分析的几种常用方法2、体验对比分析和平均分析的一般分析过程3、了解大数据的含义,认识大数据分析在信息社会的重要作用。
二、知识梳理:1.数据分析:课本P119数据分析是指用恰当的统计分析方法对收集来的大量数据进行分析,提取有用信息,并形成结论的过程。
2.数据分析的方法:课本P119对比分析:指将两个或两个以上的数据进行比较,分析它们的差异,从而揭示这些数据所代表的事物发展变化情况和规律。
对比分为横向对比和纵向对比。
平均分析:是运用计算平均值的方法,来反映总体在一定时间、地点条件下某一数量特征的一般水平。
3.数据可视化表达:课本P120以图形、图像和动画等方式更加直观生动地呈现数据及数据分析结果,揭示数据之间的关系、趋势和规律等的表达方式称为数据可视化表达图表是最常用的数据可视化表达方式之一。
基本的图表类型有:柱形图、饼图和折线图.常用图表制作方法:选定表格的数据区域——插入图表——应用“图表向导”工具,根据需要选择不同类型的图表4.数据分析报告:数据分析报告是项目研究结果的展示,也是数据分析结论的有效承载形式. 课本P121数据分析报告的一般结构:分析报告标题分析目的、背景和来源分析思路、方法和模型分析过程、结论和建议5.大数据:课本P122大数据的特点:容量大、类型多、存取速度快、应用价值高大数据的意义:大数据的意义在于,我们有可能从如此庞大的数据中挖掘出有价值的数据,并运用于管理、农业、金融、医疗和教育等各个社会领域,为社会发展服务。
课本P123三、例题分析:选择题:1、某公司根据对上一年各个季度原材料供应商A 送货量及时率的分析及建模,预测本季度该供应商的订单履约率下降2%。
该过程最有可能用到的数据分析方法有?( )A.平均分析B.纵向对比分析C.横向对比分析D.一般分析2、要直观地展示某同学高二学年连续几次考试成绩的变化的情况,最合适的图表类型是(C)A.条形图B.柱状图C.饼图D.折线图3、数据分析的过程不包括()A.首先要根据分析的目标提出假设B.然后选择恰当的分析方法进行分析C.验证假设是否正确D.根据分析直接得出相应的结论填空题:4.大数据是以① 大、② 多、③快、④高为主要特征的数据集合,它正快速发展为对数量巨大、来源分散、格式多样的数据进行⑤、⑥和⑦,从中发现新知识,创造新价值、提升新能力的新一代信息技术和服务业态。

2022年数据分析培训考试题
1.平均指标表示方法有哪些?(). *
A. 均值(正确答案)
B. 中位数(正确答案)
C. 众数(正确答案)
D.以上答案均不正确
答案解析: ABC
2.变异指标表示方法有哪些?() *
A.极差(正确答案)
B.峰度(正确答案)
C.偏移度(正确答案)
D.标偏(正确答案)
E.标准误差。
(正确答案)
答案解析: ABCDE
3.数据对称分布时() [单选题] *
A.均值
B.均值=中位数=众数(正确答案)
C.均值>中位数>众数
答案解析: B
4. 反映总体各单位标志值差异程度的指标称为变异指标,也叫标志变动度。
变异指标反映数据的离散程度;作用:说明平均数的代表性大小 ,说明现象变动的()或稳定性程度。
[单选题] *
A.大小
B.峰度
C.偏移度
D.均匀性(正确答案)
答案解析: D
5. ()是总体中最大标志值与最小标志值之差;说明标志值的最大变动范围;不能全面准确地反映一组数据的离散程度。
[单选题] *
A.极差(正确答案)
B.标准差
C.误差
D.标准误差。
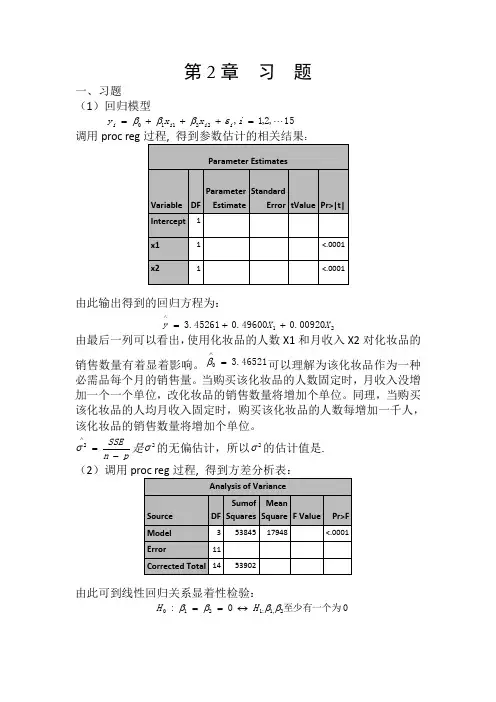
第2章 习 题一、习题(1)回归模型15,2,1,22110 =+++=i x x y i i i i εβββ调用proc reg :由此输出得到的回归方程为:2100920.049600.045261.3X X y ++=∧由最后一列可以看出,使用化妆品的人数X1和月收入X2对化妆品的销售数量有着显着影响。
46521.30=∧β可以理解为该化妆品作为一种必需品每个月的销售量。
当购买该化妆品的人数固定时,月收入没增加一个一个单位,改化妆品的销售数量将增加个单位。
同理,当购买该化妆品的人均月收入固定时,购买该化妆品的人数每增加一千人,该化妆品的销售数量将增加个单位。
pn SSE-=∧2σ是2σ的无偏估计,所以2σ的估计值是. (2)调用由此可到线性回归关系显着性检验:0至少有一个为0:2,1:1210ββββH H ↔==的统计量/(1)/()SSR p MSRF SSE n p MSE-==-的观测值47.56790=F ,检验的p 值0001.0)(000<>==F F p p H另外9989.053902538452===SST SSR R ,2R 描述了由自由变量的线性关系函数值所能反映的Y 的总变化量的比例。
2R 越大,表明线性关系越明显。
这些结果均表明Y 与X1,X2之间的回归关系高度显着。
(3)若置信水平05.0=α,由17881.2)12(975.0=t ,利用参数估计值得到21,0,βββ的置信区间分别为:对,0β2942.54516.343065.21781.245216.3±=⨯±,即)7458.8,8426.1(-) 对1β:01318.049600.000605.01781.249600.0±=⨯±,即)50198.0,48282.0( 2β:0021.000920.00009681.01781.200920.0±=⨯±,即)00113.0,0071.0(-(4)首先检验X1对Y 是否有显着性影:假设其约简模型为:15,2,1,220 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得:88137.484)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f由[()()]()()/R F FSSE R SSE F f f F SSE F f --=求得检验统计量的值为:3.9012/88357.5688357.5688137.4840=-=F05.0))13,1(()(0000<>==>==F F P F F p p H由此拒绝原假设,所以x2对Y 有显着影响。

管理信息系统-数据分析的基本方法习题
及答案
一、选择题
1. 数据分析的目的是什么?
A. 定位目标市场
B. 发现业务机会
C. 提供决策依据
D. 提升产品质量
答案:C
2. 以下哪项属于数据分析的基本步骤?
A. 数据清理
B. 数据可视化
C. 模型构建
D. 结果解释
答案:A
3. 数据预处理的目的是什么?
A. 去除数据中的错误
B. 减少数据维度
C. 提高数据可读性
D. 加速数据分析速度
答案:A
二、填空题
1. 数据分析的四个主要模式包括________、________、________、________。
答案:描述模式、判别模式、预测模式、关联模式。
2. 在数据可视化中,直方图主要用于________数据分布。
答案:展示。
3. 在数据挖掘中,决策树是一种________方法。
答案:分类。
三、简答题
1. 请简要解释数据清理的过程。
答:数据清理是数据分析的第一步,其过程包括识别并去除数
据中的错误、缺失值和异常值,以保证后续分析的准确性和可靠性。
2. 简要说明数据可视化对数据分析的重要性。
答:数据可视化是将数据以可视化的方式呈现出来,可以通过
图表、图形等形式表达数据的意义和关系,有助于发现数据的规律
和趋势,更好地理解数据,从而支持决策-makingprocess。
以上为管理信息系统-数据分析的基本方法习题及答案的文档。

第五章习题答案本章主要涉及多元统计基础,包括散点图、相关分析、回归分析以及方差分析等内容。
下面是本章部分习题的答案与解析。
1. 对于以下散点图,请判断变量之间的线性关系及相关系数大小。
答案:变量之间的线性关系:(1) 正相关(2) 弱负相关(3) 强正相关(4) 强负相关相关系数大小:(1) 0.82(2) -0.28(3) 0.96(4) -0.89解析:散点图是一种直观表示两个变量之间关系的图形,可以通过观察散点图的形状和位置来判断其相关性。
相关系数则是一种量化变量之间关系的方法,取值范围为-1到1,数值越接近 ±1,则相关性越强。
2. 请计算以下数据的相关系数,并判断相关性的方向和强度。
答案:相关系数:0.68相关性方向:正相关相关性强度:较强解析:相关系数为0.68,属于正相关,说明两个变量之间的关系呈现出一种正向趋势。
相关系数越接近1,则表明相关性越强,并且两个变量之间的关系越容易被预测和解释。
3. 请根据以下数据进行线性回归,并计算拟合优度和截距。
答案:回归分析结果:y = 2.5x + 5.5拟合优度:0.74截距:5.5解析:线性回归分析是一种用于探究变量之间关系的方法,通过拟合一条直线来表达变量之间的线性关系。
本题中,得到的回归方程为y = 2.5x + 5.5,即y的变化量与x成正比,斜率为2.5,截距为5.5。
同时,拟合优度为0.74,说明回归直线与数据点之间的拟合程度中等。
4. 在方差分析中,请简述组内变异与组间变异的概念以及作用。
答案:组内变异是指同一组内不同观测值之间的差异,反映了个体间的异质性和误差。
组间变异是指不同组之间观测值的差异,被用来衡量处理之间的区别和实验效应。
组内变异和组间变异在方差分析中具有不同的作用。
组内变异越小,则说明样本内部的方差较小,也就意味着各组之间的差异更大。
而组间变异越大,则意味着不同组之间的方差更大,也就是说各组之间的区分度更高,效应也越大。
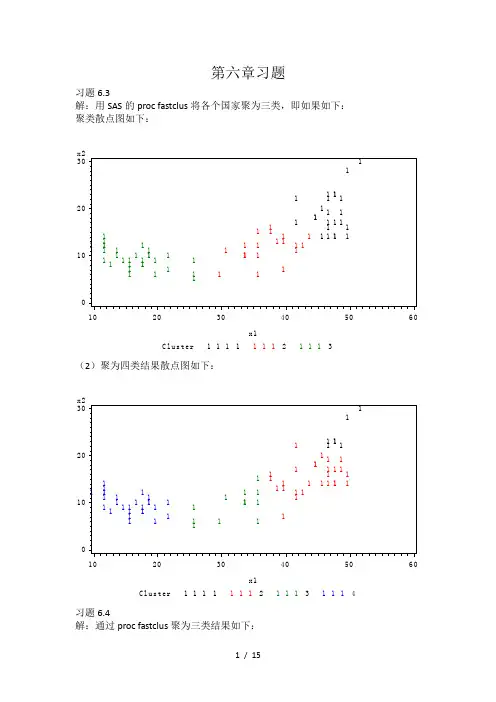
第六章习题习题6.3解:用SAS的proc fastclus将各个国家聚为三类,即如果如下:聚类散点图如下:(2)聚为四类结果散点图如下:习题6.4解:通过proc fastclus聚为三类结果如下:习题6.6解:(1)在proc cluster过程中取选项“method=single”,用最短距离法得到的聚类结果如下所示:上述聚类过程为:首先在最短距离为1的时候,将挪威语和丹麦语聚为一类,得新类CL10={丹麦语,挪威语},其中包含2个样本,这是全部类被分为10类;其次,将法语和意大利语聚为一类,CL9={法语,意大利语};其中包含两个样本,这是全部样本被分为9类,接着在最短距离为2的时候,波兰语被分到CL9当中,也即CL8={CL9,波兰语},然后英语被分到CL10中,的新类CL7={CL10,英语}={丹麦语,挪威语,英语},如此等等,最后在最短距离为8的时候,所有类并入CL2中,这样全部样品归为一类,系统聚类结束。
由谱系聚类法能够细致的看出由小到大的聚类过程,由合并时的距离水平可以看出样本之间的亲疏程度。
然后利用proc tree 过程可以画出最短距离谱系图如下所示:其中以E、N、Da、Du、G、Fr、S、I、P、H、Fi分别代表英语、挪威语、丹麦语、荷兰语、德语、法语、西班牙语、意大利语、波兰语、匈牙利语、芬兰语等11中语言。
(2)最长距离法。
在proc cluster过程中选取”method=conplete”,得到最长距离法聚类过程见下表:不同。
(3)类平均距离法。
在proc cluster过程中选取”method=average”,得到最长距离法聚类过程见下表:与最短距离法聚类过程相比,倒数第二步两种方法合并次序不同,在最长距离聚类中时将匈牙利语和芬兰语先合并为一类在和CL3聚为一类。
最长距离聚类法谱系图如下所示:(4)重心法。
在proc cluster过程中选取”method=centroid”,得到最长距离法聚类过程见下表:其谱系聚类结果如下所示:2.习题6.7解:(1)最长距离法。
数据分析方法梅长林数据分析是指通过收集、整理、加工和解释数据,以提取有用信息、评估假设和支持决策的过程。
数据分析方法是指在数据分析过程中使用的各种技术和工具。
下面将介绍几种常见的数据分析方法。
1. 描述统计分析:描述统计分析是对数据进行总结和描述的方法。
常用的描述统计量包括平均值、中位数、众数、标准差等。
通过描述统计分析,可以对数据的集中趋势、离散程度和分布形态有一个直观的了解。
2. 相关分析:相关分析用于研究变量之间的相关关系。
常见的相关分析方法包括皮尔逊相关系数和斯皮尔曼相关系数。
通过相关分析,可以了解变量之间的线性相关程度和相关方向。
3. 回归分析:回归分析是一种用来研究自变量和因变量之间关系的方法。
回归分析可以分为线性回归分析和非线性回归分析。
通过回归分析,可以估计出自变量对因变量的影响程度,并进行预测和解释。
4. 时间序列分析:时间序列分析主要用于研究随时间变化的数据。
常见的时间序列分析方法包括趋势分析、季节性分析和周期性分析。
时间序列分析可以揭示数据的长期趋势、季节性变化和周期性波动。
5. 聚类分析:聚类分析是一种用于将数据按照某种相似性进行分组的方法。
聚类分析可以帮助我们发现数据中的模式和规律,并进行分类和预测。
6. 因子分析:因子分析是一种用于研究变量之间的潜在结构的方法。
因子分析可以将多个观测指标归纳为几个潜在因子,从而简化数据分析过程,并找出变量之间的内在关系。
7. 假设检验:假设检验是一种用来检验统计推断的方法。
通过对样本数据进行假设检验,可以判断样本数据与总体参数之间是否存在显著差异,以及差异的程度。
以上只是几种常见的数据分析方法,实际数据分析过程中还有其他各种方法和技术。
选择适合的数据分析方法需要根据具体的问题和数据情况进行判断。
同时,数据分析方法的选择也需要结合统计学原理和分析目的,确保结果具有可靠性和实用性。
一、选择题1.反映一组数据变化范围的是( ) A .极差B .方差C .众数D .平均数2.某校规定学生的学期学业成绩由三部分组成:平时成绩占20%,期中成绩占30%,期末成绩占50%,小颖的平时、期中、期末成绩分别为85分、90分、92分,则她本学期的学业成绩为( ) A .85B .90C .92D .893.在5轮“中国汉字听写大赛”选拔赛中,甲、乙两位同学的平均分都是90分,甲的成绩方差是15,乙的成绩的方差是3,下列说法正确的是( ) A .甲的成绩比乙的成绩稳定 B .乙的成绩比甲的成绩稳定 C .甲、乙两人的成绩一样稳定D .无法确定甲、乙的成绩谁更稳定4.某学习小组的5名同学在一次数学文化节竞赛活动中的成绩分别是:92分,96分,90分,92分,85分,则下列结论正确的是( ) A .平均数是92B .中位数是90C .众数是92D .极差是75.一组数据中有m 个a ,n 个b ,k 个c ,那么这组数据的平均数为( )A .3a b c++ B .3m n k++ C .3ma nb kc++D .ma nb kcm n k++++6.今年上半年,我市某俱乐部举行山地越野车大赛,其中8名选手某项得分如下表:则这8名选手得分的平均数是( ) A .88B .87C .86D .857.下列说法正确的是( )A .中位数就是一组数据中最中间的一个数B . 8. 99,1010,11,,这组数据的众数是9 C .如果123,,,,n x x x x ⋯的平均数是1,那么()()()121110n x x x -+-+⋯+-= D .一组数据的方差是这组数据的极差的平方8.随着时代的进步,人们对 2.5PM (空气中直径小于等于2.5微米的颗粒)的关注日益密切.某市一天中 2.5PM 的值1y (3/ug m )随时间t (h )的变化如图所示,设2y 表示0时到t 时 2.5PM 的值的极差(即0时到t 时 2.5PM 的最大值与最小值的差),则2y 与t的函数关系大致是( )A.B.C.D.9.下表记录了甲、乙、丙、丁四名同学最近几次数学考试成绩的平均数与方差:要选择一名成绩好且发挥稳定的同学参加数学比赛,应该选择( )A.甲B.乙C.丙D.丁10.某公司全体职工的月工资如下:月工资(元)18000120008000600040002500200015001200人数1(总经理)2(副总经理)34102022126的普通员工最关注的数据是()A.中位数和众数B.平均数和众数C.平均数和中位数D.平均数和极差11.一组数据3,4,4,5,若添加一个数4,则发生变化的统计量是( )A.平均数B.众数C.中位数D.方差12.测试五位学生的“一分钟跳绳”成绩,得到五个各不相同的数据,在统计时出现了一处错误:将最高成绩写得更高了,则计算结果不受影响的是()A.中位数B.平均数C.方差D.极差二、填空题13.图中显示的是某商场日用品柜台10名售货员4月份完成销售额(单位:千元)的情况,根据统计图,我们可以计算出该柜台的人均销售额为___________千元.14.商店某天销售了11件衬衫,其领口尺寸统计如下表:领口尺寸(单位:cm)3839404142件数14312则这11件衬衫领口尺寸的中位数是________cm.15.若一组数据4,x,5,7,9的众数为5,则这组数据的方差为_____.16.我市5月份某一周每天的最高气温统计如下:最高气温28293031(℃)天数1132则这组数据(最高气温)的众数与中位数分别是_____、_____.17.已知一组数据-1,x,0,1,-2的平均数是0,这组数据的极差和标准差分别是_____18.已知一组数据x1,x2,x3,x4,x5的平均数是2,那么另一组数据3x1﹣2,3x2﹣2,3x3﹣2,3x4﹣2,3x5﹣2的平均数是_____.19.对一种环保电动汽车性能抽测,获得如下条形统计图.根据统计图可估计得被抽检电动汽车一次充电后平均里程数为______.20.如果一组数据-2,0,1,3,x的极差是7,那么x的值是___________.三、解答题21.在推进杭州市城乡生活垃圾分类的行动中,某校为了考察该校初中生掌握垃圾分类知识的情况,进行了一次测试,并随机抽取了若干名学生的测试成绩进行整理,绘制了如图所示不完整的频数直方图(每组含前一个边界值,不含后一个边界值)和扇形统计图.(1)求样本容量,并补充完整频数直方图.(2)在抽取的这些学生中,玲玲的测试成绩为85分,你认为85分一定是这些学生成绩的中位数吗?请简要说明理由.(3)若成绩在80分以上(包括80分)为优秀,请估计全校1400名学生中成绩优秀的人数.22.学校广播站要招聘一名播音员,考查形象、知识面、普通话三个项目(每个项目按百分制计分).若按形象占10%,知识面占40%,普通话占50%计算加权平均数,作为最后评定的总成绩.李颖和张明两位同学的各项成绩如表所示:项目形象知识面普通话选手李颖708088张明8075x(2)若张明同学要在总成绩上超过李颖同学,求x的范围.23.甲、乙两人在相同条件下各立定跳远5次,距离如下(单位:cm):甲:225,230,240,230,225;乙:220,235,225,240,230.(1)计算这两组数据的方差;(2)谁的跳远技术较稳定?为什么?24.某市射击队为从甲、乙两名运动员中选拔一人参加省比赛,对他们进行了六次测试,测试成绩如下表(单位:环):第1次第2次第3次第4次第5次第6次甲10988109乙101081079根据表格中的数据,可计算出甲、乙两人的平均成绩都是9环.(1)分别计算甲、乙六次测试成绩的方差;(2)根据数据分析的知识,你认为选______名队员参赛.25.某学校八年级开展英语拼写大赛,一班和二班根据初赛成绩,各选出5名选手参加复赛,两个班各选出的5名选手的复赛成绩如图所示:(1)根据图示填写下表班级中位数(分)众数(分)平均数(分)一班85二班10085(2)结合两班复赛成绩的平均数和中位数,分析哪个班级的复赛成绩比较好?(3)已知一班的复赛成绩的方差是70,请求出二班复试成绩的方差,并说明哪个班成绩比较稳定?26.某中学七、八年级各选10名同学参加“创全国文明城市”知识竞赛,计分10分制,选手得分均为整数,成绩达到6分或6分以上为合格,达到9分或9分以上为优秀,这次竞赛后,七、八年级两支代表队成绩分布的条形统计图和成绩分析表如下,其中七年级代表队得6分、10分选手人数分别为a,b.队列平均分中位数方差合格率优秀率七年级 6.7m 3.4190%n八年级7.17.5 1.6980%10%(1)根据图表中的数据,求a,b的值.(2)直接写出表中的m= ,n=.(3)你是八年级学生,请你给出两条支持八年级队成绩好的理由.【参考答案】***试卷处理标记,请不要删除一、选择题1.A解析:A【分析】根据极差是刻画数据离散程度的一个统计量.它能反映数据的波动范围大小解答.【详解】解:反映一组数据变化范围的是极差;故选:A.【点睛】本题考查了极差、方差、众数以及平均数的概念和意义,掌握极差是刻画数据离散程度的一个统计量.它能反映数据的波动范围是解题的关键.2.B解析:B【分析】根据加权平均数的计算方法可以得解.【详解】解:由题意得,小颖本学期的学业成绩为:⨯+⨯+⨯=++=(分),8520%9030%9250%17274690故选B.【点睛】本题考查加权平均数的计算,熟练掌握加权平均法的计算方法是解题关键.3.B解析:B【分析】根据方差的意义求解可得.【详解】∵乙的成绩方差<甲成绩的方差, ∴乙的成绩比甲的成绩稳定, 故选B. 【点睛】本题主要考查方差,方差是反映一组数据的波动大小的一个量.方差越大,则平均值的离散程度越大,稳定性也越小;反之,则它与其平均值的离散程度越小,稳定性越好.4.C解析:C 【分析】根据平均数、中位数、众数以及极差的定义、计算公式对各选项进行判断. 【详解】解:A .这组数据的平均分15×(85+90+92+92+96)=91分,所以A 选项错误; B 、这组数据按从小到大排列为:85、90、92、92、96,所以这组数据的中位数为92(分),所以B 选项错误;C 、这组数据的众数为92(分),所以C 选项正确;D .这组数据极差是96﹣85=11,所以D 选项错误; 故选C . 【点睛】本题查平均数,中位数,众数以及极差,解题关键是正确熟练运用公式.5.D解析:D 【分析】先求得这组数据的和和个数,再根据平均数的定义求解. 【详解】∵一组数据中有m 个a ,n 个b ,k 个c , ∴这组数据的和=ma+nb+kc ,数据的个数=m+n+k , ∴这组数据的平均数为:ma nb kcm n k++++.故选:D. 【点睛】考查了加权平均数的计算,解题关键是计算出这组数据的和和个数.6.B解析:B 【分析】由表可知,得分82的有1人,得分85的有2人,得分88的有3人,得分90的有2人.再根据平均数概念求解; 【详解】解:(82×1+85×2+88×3+90×2)÷8= 87(分),所以平均数是87分. 故选:B. 【点睛】本题考查加权平均数的概念和计算方法,解题关键是熟练掌握加权平均数的计算公式.7.C解析:C 【分析】根据中位数以及众数和平均数和极差、方差的定义分别判断得出即可. 【详解】A 、当数据是奇数个时,按大小排列后,中位数就是一组数据中最中间的一个数,数据个数为偶数个时,按大小排列后,最中间的两个的平均数是中位数,故此选项错误;B 、8,9,9,10,10,11这组数据的众数是9和10,故此选项错误;C 、如果x 1,x 2,x 3,…,x n 的平均数是x ,那么(x 1-x )+(x 2-x )+…+(x n -x )=x 1+x 2+x 3+…+x n -n x =0,故此选项正确;D 、一组数据的方差与极差没有关系,故此选项错误; 故选C . 【点睛】此题主要考查了中位数以及众数和平均数和极差、方差的定义,根据定义举出反例是解题关键.8.B解析:B 【分析】根据极差的定义,分别从0t =、010t <≤、1020t <≤及2024t <≤时,极差2y 随t 的变化而变化的情况,从而得出答案. 【详解】当0t =时,极差285850y =-=,当010t <≤时,极差2y 随t 的增大而增大,最大值为43; 当1020t <≤时,极差2y 随t 的增大保持43不变; 当2024t <≤时,极差2y 随t 的增大而增大,最大值为98; 故选B . 【点睛】本题主要考查极差,解题的关键是掌握极差的定义及函数图象定义与画法.9.C解析:C 【解析】 【分析】方差是反映一组数据的波动大小的一个量.方差越大,则平均值的离散程度越大,稳定性也越小;反之,则它与其平均值的离散程度越小,稳定性越好,选出方差最小,而且平均数较大的同学参加数学比赛.【详解】∵3.6<7.4<8.1,∴甲和丙的最近几次数学考试成绩的方差最小,发挥稳定,∵95>92,∴丙同学最近几次数学考试成绩的平均数高,∴要选择一名成绩好且发挥稳定的同学参加数学比赛,应该选择丙.故选C.【点睛】此题主要考查了方差的含义和求法,要熟练掌握,解答此题的关键是要明确:方差是反映一组数据的波动大小的一个量.方差越大,则平均值的离散程度越大,稳定性也越小;反之,则它与其平均值的离散程度越小,稳定性越好.10.A解析:A【分析】根据中位数、众数、平均数及极差的意义分别判断后即可得到正确的选项.【详解】∵数据的极差为16800,较大,∴平均数不能反映数据的集中趋势,∴普通员工最关注的数据是中位数及众数,故选A.【点睛】本题考查了统计量的选择的知识,解题的关键是了解有关统计量的意义,难度不大.11.D解析:D【分析】依据平均数、中位数、众数、方差的定义和公式分别计算新旧两组数据的平均数、中位数、众数、方差求解即可.【详解】原数据的3,4,4,5的平均数为3+4+4+5=44,原数据的3,4,4,5的中位数为4+4=24,原数据的3,4,4,5的众数为4,原数据的3,4,4,5的方差为14×[(3-4)2+(4-4)2×2+(5-4)2]=0.5;新数据3,4,4,4,5的平均数为3+4+4+4+5=45,新数据3,4,4,4,5的中位数为4, 新数据3,4,4,4,5的众数为4,新数据3,4,4,4,5的方差为15×[(3-4)2+(4-4)2×3+(5-4)2]=0.4; ∴添加一个数据4,方差发生变化, 故选D . 【点睛】本题主要考查的是众数、中位数、方差、平均数,熟练掌握相关概念和公式是解题的关键.12.A解析:A 【分析】根据中位数的定义解答可得. 【详解】解:因为中位数是将数据按照大小顺序重新排列,代表了这组数据值大小的“中点”,不受极端值影响,所以将最高成绩写得更高了,计算结果不受影响的是中位数, 故选A . 【点睛】本题主要考查方差、极差、中位数和平均数,解题的关键是掌握中位数的定义.二、填空题13.67【分析】首先根据题意求出销售额为5千元的人数由此进一步求出该柜台的人均销售额即可【详解】由题意得:销售额为5千元的人数为:(人)∴该柜台的人均销售额为:(千元)故答案为:【点睛】本题主要考查了平解析:6.7 【分析】首先根据题意求出销售额为5千元的人数,由此进一步求出该柜台的人均销售额即可. 【详解】 由题意得:销售额为5千元的人数为:1012214----=(人),∴该柜台的人均销售额为:()1324452812010 6.7⨯+⨯+⨯+⨯+⨯÷=(千元), 故答案为:6.7. 【点睛】本题主要考查了平均数的计算,熟练掌握相关概念是解题关键.14.40【分析】根据中位数的概念中位数是指将数据按大小顺序排列起来形成一个数列居于数列中间位置的那个数据再根据题中所给表格找出中位数【详解】将所卖衬衫按照领口尺寸从小到大排列后处于中间的衬衫领口尺寸为4解析:40【分析】根据中位数的概念,中位数,是指将数据按大小顺序排列起来,形成一个数列,居于数列中间位置的那个数据,再根据题中所给表格,找出中位数.【详解】将所卖衬衫按照领口尺寸从小到大排列后,处于中间的衬衫领口尺寸为40cm,此中位数是40cm故答案:40【点睛】本题首先要掌握中位数的概念,能看懂题中所给表格,根据中位数的概念来解答的. 15.【分析】根据众数的定义先判断出x是5再根据平均数的计算公式求出平均数为6然后代入方差公式即可得出答案【详解】解:∵数据4x579的众数为5∴x=5S2=(4﹣6)2+2×(5﹣6)2+(7﹣6)2+解析:16 5【分析】根据众数的定义先判断出x是5,再根据平均数的计算公式求出平均数为6,然后代入方差公式即可得出答案.【详解】解:∵数据4,x,5,7,9的众数为5,∴x=5,1(45579)65x=+++++=,S2=15[(4﹣6)2+2×(5﹣6)2+(7﹣6)2+(9﹣6)2]=165,故答案为165.【点睛】此题主要考查了平均数、众数、方差的统计意义.众数是一组数据中出现次数最多的数据,注意众数可以不止一个;平均数是指在一组数据中所有数据之和再除以数据的个数.熟练掌握方差的计算公式是解答本题的关键.16.3030【分析】根据众数和中位数的定义进行求解即可得【详解】在这一组数据中30是出现次数最多的故众数是30;处于这组数据中间位置的那个数是30那么由中位数的定义可知这组数据的中位数是30故这组数据的解析:30 30【分析】根据众数和中位数的定义进行求解即可得.【详解】在这一组数据中30是出现次数最多的,故众数是30;处于这组数据中间位置的那个数是30,那么由中位数的定义可知,这组数据的中位数是30,故这组数据的中位数与众数分别是30,30,故答案为:30,30.【点睛】本题考查了众数与中位数的意义,读懂表格,熟练掌握众数、中位数的定义及求解方法是解题的关键.17.4【解析】试题解析:4,2【解析】试题∵x=0-(-1+0-2+1),解得x=2,故极差为:2-(-2)=4,则方差s2=15[(-1-0)2+(2-0)2+(0-0)2+(1-0)2+(-2-0)2]=2,那么这组数据的标准差为2.18.4【解析】【分析】平均数的计算方法是求出所有数据的和然后除以数据的总个数先求数据x1x2x3x4x5的和然后再用平均数的定义求新数据的平均数【详解】一组数据x1x2x3x4x5的平均数是2有15(x解析:4【解析】【分析】平均数的计算方法是求出所有数据的和,然后除以数据的总个数.先求数据x1,x2,x3,x4,x5的和,然后再用平均数的定义求新数据的平均数.【详解】一组数据x1,x2,x3,x4,x5的平均数是2,有(x1+x2+x3+x4+x5)=2,那么另一组数据3x1-2,3x2-2,3x3-2,3x4-2,3x5-2的平均数是(3x1-2+3x2-2+3x3-2+3x4-2+3x5-2)=4.故答案是:4.【点睛】考查的是样本平均数的求法及运用,解题关键是记熟公式:.19.165125千米【解析】【分析】根据加权平均数的定义列式进行求解即可【详解】估计被抽检电动汽车一次充电后平均里程数为:165125(千米)故答案为165125千米【点睛】本题考查了条形统计图的知识以解析:165.125千米.【解析】【分析】根据加权平均数的定义列式进行求解即可.【详解】估计被抽检电动汽车一次充电后平均里程数为:150415510160161652017014175121804410162014124⨯+⨯+⨯+⨯+⨯+⨯+⨯=++++++165.125(千米), 故答案为165.125千米.【点睛】本题考查了条形统计图的知识以及加权平均数,能准确分析条形统计图并掌握加权平均数的计算公式是解此题的关键.20.5或-4【解析】【分析】根据极差的定义求解分两种情况:x 为最大值或最小值【详解】一组数据-2013x 的极差是7当x 为最大值时x-(-2)=7解得x=5;当x 是最小值时3-x=7解得:x=-4故答案为解析:5或-4,【解析】【分析】根据极差的定义求解.分两种情况:x 为最大值或最小值.【详解】一组数据-2,0,1,3,x 的极差是7,当x 为最大值时,x-(-2)=7,解得x=5;当x 是最小值时,3-x=7,解得:x=-4.故答案为:5或-4.【点睛】此题主要考查了极差的定义,正确理解极差的定义,能够注意到应该分两种情况讨论是解决本题的关键.三、解答题21.(1)50;见解析;(2)不一定;见解析;(3)728【分析】(1)由总人数为100可得m 的值,从而补全图形;(2)根据中位数的定义判断即可得;(3)样本中成绩在80分以上(包括80分)占调查人数的161050+,因此利用样本估计总体的方法列出算式1610140050+⨯,求解可得结果.解:(1)样本容量是:10÷20%=50.70≤a<80的频数是50−4−8−16−10=12(人),补全图形如下:(2)不一定是这些学生成绩的中位数.理由:将50名学生知识测试成绩从小到大排列,第25、26名的成绩都在分数段80≤a≤90中,他们的平均数不一定是85分,因为25、26的成绩的平均数才是整组数据的中位数.(3)全校1400名学生中成绩优秀的人数为:1610140072850+⨯=(人).【点睛】本题考查了条形统计图、用样本估计总体、统计量的选择,解答本题的关键是明确题意,找出所求问题需要的条件,利用数形结合的思想解答.22.(1)83;(2)90<x≤100【分析】(1)按照各项目所占比求得总成绩;(2)各项目所占比求得总成绩大于83分即可,列出不等式求解.【详解】(1)70×10%+80×40%+88×50%=83(分);(2)80×10%+75×40%+50%•x>83,∴x>90.∵每个项目按百分制计分∴90<x≤100∴李颖同学的总成绩是83分,张明同学要在总成绩上超过李颖同学,则他的普通话成绩应90<x≤100.【点睛】本题综合考查平均数的运用.解题的关键是正确理解题目的含义.23.(1)30;50(2)甲稳定;见解析.(1)根据平均数的计算公式先求出甲和乙的平均数,再代入方差公式()()()2221221=.....n S x x x x x x n ⎡⎤-+-++-⎢⎥⎣⎦,进行计算即可得出答案; (2)根据方差的意义,方差越小数据越稳定,即可得出答案.【详解】 解:(1)甲的平均数是:()1225+230+240+230+225=2305cm ⨯, 乙的平均数是:()1220+235+240+230+225=2305cm ⨯, 甲的方差是:()()()()()22222221=225230230230240230230230225230305S cm ⎡⎤⨯-+-+-+-+-=⎣⎦, 乙的方差是:()()()()()22222221=220230235230240230230230225230505S cm ⎡⎤⨯-+-+-+-+-=⎣⎦;(2)由(1)知,S 甲2<S 乙2,∴甲的跳远技术较稳定.【点睛】本题主要考查平均数与方差,熟练掌握方差及平均数的运算公式是解题的关键.24.(1)甲、乙六次测试成绩的方差分别是223S =甲,243S =乙;(2)甲 【分析】(1)根据方差的定义,利用方差公式分别求出甲、乙的方差即可;(2)根据平均数相同,利用(1)所求方差比较,方差小的成绩稳定,即可得答案.【详解】(1)甲、乙六次测试成绩的方差分别是: (222222212[(109)(99)(89)(89)(109)99)63S ⎤=⨯-+-+-+-+-+-=⎦甲, (222222214[(109)(109)(89)(109)(79)99)63S ⎤=⨯-+-+-+-+-+-=⎦乙, (2)推荐甲参加全国比赛更合适,理由如下:∵两人的平均成绩相等,∴两人实力相当;∵甲的六次测试成绩的方差比乙小,∴甲发挥较为稳定,∴推荐甲参加比赛更合适.故答案为:甲本题考查方差的求法及利用方差做决策,方差反映了一组数据的波动大小,方差越大,波动性越大,反之也成立;熟练掌握方差公式是解题关键.25.(1)85、85 80(2)一班成绩好些.因为两班平均数相等,一班的中位数高,所以一班成绩好些.(回答合理即可)(3)一班成绩较为稳定.【分析】(1)观察图分别写出一班和二班5名选手的复赛成绩,然后根据中位数的定义和平均数的求法以及众数的定义求解即可;(2)在平均数相同的情况下,中位数高的成绩较好;(3)根据方差公式计算即可:S 2=()()()222121n x x x x x x n ⎡⎤-+--⎣⎦(可简单记忆为“等于差方的平均数”)【详解】解:(1)由条形统计图可知一班5名选手的复赛成绩为:75、80、85、85、100, 二班5名选手的复赛成绩为:70、100、100、75、80,一班的众数为85,一班的平均数为(75+80+85+85+100)÷5=85,二班的中位数是80;(2)一班成绩好些.因为两班平均数相等,一班的中位数高,所以一班成绩好些.(回答合理即可)(3)S 二班2=()()()()()2222270851008510085758580851605-+-+-+-+-=因为S 一班2=70则S 一班2<S 二班2,因此一班成绩较为稳定.【点睛】本题考查了中位数、众数以及平均数的求法,同时也考查了方差公式,解题的关键是牢记定义并能熟练运用公式.26.(1)51a b =⎧⎨=⎩;(2)6m = 20%n =;(3)详见解析. 【分析】(1)根据七年级代表队的总人数为10人以及七年级的成绩的平均分为6.7,列方程组可求出a 与b 的值;(2)根据(1)a 与b 的值,确定出m 与n 的值即可;(3)从中位数,平均数,方差等角度考虑,给出两条支持八年级队成绩好的理由即可.解:(1)由题意,得101111 6.73167181911010a b a b +=----⎧⎪=⨯++⨯+⨯+⨯+⎨⎪⎩,即:661040a b a b +=⎧⎨+=⎩,解得:51a b =⎧⎨=⎩. (2)七年级成绩为3,6,6,6,6,6,7,8,9,10,中位数为6,即m=6; 优秀率为111=105+=20%,即n=20%; (3)答案不唯一.如:支持八年级队成绩好的理由有: ①八年级队的平均分比七年级队高,说明总成绩八年级好;②八年级队中位数是7.5,而七年级队中位数是6,说明八年级队半数以上的学生比七年级队半数以上成绩好【点睛】此题考查了条形统计图,以及中位数,平均数,以及方差,弄清概念是解题的关键.。
一、选择题1.已知5个数1a 、2a 、3a 、4a 、5a 的平均数是a ,则数据11a +、22a +、33a +、44a +、55a +的平均数为( )A .aB .3a +C .56a D .15a +2.为评估一种农作物的种植效果,选了8块地作试验田,这8块地的亩产量(单位:kg )分别为1x ,2x ,…,8x ,下面给出的指标中可以用来评估这种农作物亩产量稳定程度的是( )A .1x ,2x ,…,8x 的平均数B .1x ,2x ,…,8x 的方差C .1x ,2x ,…,8x 的中位数D .1x ,2x ,…,8x 的众数3.数据2-,1-,0,1,2的方差是( )A .0BC .2D .44.某市连续10天的最低气温统计如下(单位:℃):4,5,4,7,7,8,7,6,5,7,该市这10天的最低气温的中位数是( ) A .6℃B .6.5℃C .7℃D .7.5℃5.某校在体育健康测试中,有8名男生“引体向上”的成绩(单位:次)分别是:14,12,8,9,16,12,7,10,这组数据的中位数和众数分别是( ) A .10,12B .12,11C .11,12D .12,126.甲、乙两班举行电脑汉字输入比赛,参赛学生每分输入汉字的个数统计结果如下表:某同学分析上表后得到如下结论: ①甲、乙两班学生平均成绩相同;②乙班优秀的人数多于甲班优秀的人数(每分输入汉字个数150≥为优秀) ③甲班成绩的波动比乙班大. 上述结论中正确的是( ) A .①②③ B .①②C .①③D .②③7.某校在中国学生核心素养知识竞赛中,通过激烈角逐,甲、乙、丙、丁四名同学胜出,他们的成绩如表:平均分8.58.28.58.2方差 1.8 1.2 1.2 1.1最高分9.89.89.89.7如果要选出一个成绩较好且状态稳定的同学去参加市级比赛,应选()A.丁B.丙C.乙D.甲8.下列说法正确的是()A.为了解我国中学生课外阅读的情况,应采取全面调查的方式B.一组数据1、2、5、5、5、3、3的中位数和众数都是5C.若甲组数据的方差是003,乙组数据的方差是0.1,则甲组数据比乙组数据稳定D.抛掷一枚硬币100次,一定有50次“正面朝上”9.若a、b、c这三个数的平均数为2,方差为S2,则a+2,b+2,c+2的平均数和方差分别是()A.2,S2B.4,S2C.2,S2+2 D.4,S2+410.有一组数据:1,1,1,1,m.若这组数据的方差是0,则m为()A.4-B.1-C.0 D.111.下表记录了甲、乙、丙、丁四名同学最近几次数学考试成绩的平均数与方差:要选择一名成绩好且发挥稳定的同学参加数学比赛,应该选择( )A.甲B.乙C.丙D.丁12.为了帮助我市一名贫困学生,某校组织捐款,现从全校所有学生的捐款数额中随机抽取10名学生的捐款数统计如下表:捐款金额/20305090元人数2431A.10名学生是总体的一个样本B.中位数是40C.众数是90D.方差是400二、填空题13.小明这学期第一次数学考试得了72分,第二次数学考试得了86分,为了达到三次考试的平均成绩不少于80分的目标,他第三次数学考试至少得____分.14.据统计,某车间10名员工的日平均生产零件个数为8个,方差为2.5个2,引入新技术后,每名员工每天都比原先多生产1个零件,则现在日平均生产零件个数为______个,方差为______个2.15.数据-1,2,0,1,-2的方差是____.16.甲、乙两人参加某网站的招聘测试,测试由网页制作和语言两个项目组成,他们各自的成绩(百分制)如下表所示:应聘者网页制作语言甲8070乙7080该网站根据成绩在两人之间录用了甲,则本次招聘测试中权重较大的是_____项目.17.若一组数据1,2,a,3,5的平均数是3,则这组数据的标准差是______.18.小明用S2=110[(x1﹣3)2+(x2﹣3)2+…+(x10﹣3)2]计算一组数据的方差,那么x1+x2+x3+…+x10=______.19.在一次数学测验中,甲组4名同学的平均成绩是70分,乙组6名同学的平均成绩是80分,则这10名同学的平均成绩是______________.20.一组数据1,0,2,1的方差S2=_____.三、解答题21.某校需要选出一名同学去参加温州市“生活中的数学说题”比赛,现有5名候选人参加该校举办的模拟说题比赛,挑选出成绩最高者参加说题比赛.已知5名候选人模拟说题比赛成绩情况如表所示.某校5名候选人模拟说题比赛成绩情况(1)5名候选人模拟说题比赛成绩的中位数是;(2)由于C、E两名候选人成绩并列第一;所以学校决定根据两人平时成绩、任课老师打分、模拟说题比赛成绩按2:3:5的比例最后确定成绩,最终谁将参加说题比赛.已知C、E两名候选人平时成绩、任课老师打分情况如表所示.22.受疫情影响,某地无法按原计划正常开学.在延迟开学期间该地区组织了在线教学活动.开学后,某校针对各班在线教学的个性化落实情况,通过初评决定从甲、乙、丙三个班中推荐一个作为在线教学先进班级,下表是这三个班的五项指标的考评得分表(单位:分):根据统计表中的信息解答下列问题:(1)请确定如下的“五项指标的考评得分分析表”中的a、b、c的值:(2)如果学校把“课程设置”、“课程质量”、“在线答疑”、“作业情况”、“学生满意度”这五项指标得分按照2∶2∶3∶1∶2的比例确定最终成绩,请你通过计算判断应推荐哪个班为在线教学先进班级?23.某班级从甲、乙两位同学中选派一人参加知识竞赛,老师对他们的五次模拟成绩(单位:分)进行了整理,并计算出甲成绩的平均数是80分,甲、乙成绩的方差分别是320,40,但绘制的统计图表尚不完整.甲、乙两人模拟成绩统计表第一次第二次第三次第四次第五次甲成绩901009050a乙成绩8070809080甲、乙两人模拟成绩折线图根据以上信息,请你解答下列问题:(1)a(2)请完成图中表示甲成绩变化情况的折线;(3)求乙成绩的平均数;(4)从平均数和方差的角度分析,谁将被选中.24.八(2)班组织了一次经典朗读比赛,甲、乙两队各10人的比赛成绩如下表(单位:分):甲789710109101010乙10879810109109)甲队成绩的中位数是分,乙队成绩的众数是分;(2)计算乙队的平均成绩和方差;(3)已知甲队成绩的方差是1.4 分2,则成绩较为整齐的是队.25.为了了解某校初三学生每周平均阅读时间的情况,随机抽查了该校初三m名学生,对其每周平均课外阅读时间进行统计,绘制了条形统计图和扇形统计图.根据以上信息回答下列问题:(1)求m的值;(2)求扇形统计图中阅读时间为3小时的扇形圆心角的度数;(3)求出这组数据的平均数.(精确到0.1)26.山青养鸡场有2500只鸡准备对外出售.从中随机抽取了一部分鸡,统计了它们的质量(单位:kg),并绘制出如下的统计图1和图2.请根据以上信息解答下列问题:(1)图1中m的值为;(2)统计的这组数据的众数是;中位数是;(3)求出这组数据的平均数,并估计这2500只鸡的总质量约为多少kg.【参考答案】***试卷处理标记,请不要删除一、选择题 1.B 解析:B 【分析】根据数据11a +、22a +、33a +、44a +、55a +比数据1a 、2a 、3a 、4a 、5a 的和多15,可得数据11a +、22a +、33a +、44a +、55a +的平均数比a 多3,据此求解即可 【详解】解:a+()()24512345132+4+51+3+-+a a a a a a a a a a ++++++++⎡⎤⎣⎦ ÷5 =a+[1+2+3+4+5] ÷5 =a+15÷5 =a+3 故选:B 【点睛】此题主要考察了算术平均数的含义和求法,解题关键是判断出:数据11a +、22a +、33a +、44a +、55a +比数据1a 、2a 、3a 、4a 、5a 的平均数多3.2.B解析:B 【分析】根据方差的意义即可判断. 【详解】解:方差是反映一组数据的波动大小的一个量.方差越大,则平均值的离散程度越大,稳定性也越小;反之,则它与其平均值的离散程度越小,稳定性越好. 故选:B . 【点睛】本题考查方差,平均数,中位数,众数等知识,解题的关键是熟练掌握基本知识,属于中考常考题型.3.C解析:C 【分析】先计算平均数,再计算方差.方差的定义一般地设n 个数据,x 1,x 2,…x n 的平均数为x ,x =1n (x 1+x 2+…+x n ),则方差S 2=1n [(x 1-x )2+(x 2-x )2+…+(x n -x )2]. 【详解】解:平均数x=15(-2-1+0+1+2)=0,则方差S2=15[(-2-0)2+(-1-0)2+(0-0)2+(1-0)2+(2-0)2]=2.故选:C.【点睛】本题考查方差的定义:一般地设n个数据,x1,x2,…x n的平均数为x,x=1 n(x1+x2+…+x n),则方差S2=1n[(x1-x)2+(x2-x)2+…+(x n-x)2],它反映了一组数据的波动大小,方差越大,波动性越大,反之也成立.4.B解析:B【分析】由于10天天气,根据数据可以知道中位数是按从小到大排序,第5个与第6个数的平均数.【详解】解:10天的气温排序为:4,4,5,5,6,7,7,7,7,8,中位数为:6+72=6.5,故选B.【点睛】本题属于基础题,要明确定义,一些学生往往对这个概念掌握不清楚,计算方法不明确而误选其它选项,注意找中位数的时候一定要先排好顺序,然后再根据奇数和偶数个来确定中位数,如果数据有奇数个,则正中间的数字即为所求,如果是偶数个则找中间两位数的平均数.5.C解析:C【分析】先把原数据按由小到大排列,然后根据中位数和众数的定义求解.【详解】原数据按由小到大排列为:7,8,9,10,12,12,14,16,所以这组数据的中位数=12(10+12)=11,众数为12.故选:C.【点睛】此题考查众数,中位数的定义,解题关键在于掌握一组数据中出现次数最多的数据叫做众数.6.A解析:A【分析】平均水平的判断主要分析平均数;优秀人数的判断从中位数不同可以得到;波动大小比较方差的大小.【详解】从表中可知,平均字数都是135,①正确;甲班的中位数是149,乙班的中位数是151,比甲的多,而平均数都要为135,说明乙的优秀人数多于甲班的,②正确;甲班的方差大于乙班的,又说明甲班的波动情况大,所以③也正确.①②③都正确.故选:A.【点睛】此题考查平均数,中位数,方差的意义.解题关键在于掌握平均数表示一组数据的平均程度.中位数是将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(或最中间两个数的平均数);方差是用来衡量一组数据波动大小的量.7.B解析:B【分析】先比较平均数得到甲和丙成绩较好,然后比较方差得到丙的状态稳定,即可决定选丙去参赛.【详解】∵甲、丙的平均数比乙、丁大,∴甲和丙成绩较好,∵丙的方差比甲的小,∴丙的成绩比较稳定,∴丙的成绩较好且状态稳定,应选的是丙,故选:B.【点睛】本题考查了方差:一组数据中各数据与它们的平均数的差的平方的平均数,叫做这组数据的方差;方差是反映一组数据的波动大小的一个量,方差越大,则平均值的离散程度越大,稳定性也越小;反之,则它与其平均值的离散程度越小,稳定性越好.也考查了平均数的意义.8.C解析:C【分析】可根据调查的选择、中位数和众数的求法、方差及随机事件的意义,逐个判断得结论.【详解】解:因为我国中学生人数众多,其课外阅读的情况也不需要特别精确,所以对我国中学生课外阅读情况的调查,宜采用抽样调查,故选项A 不正确; 因为B 中数据按从小到大排列为1、2、3、3、5、5、5,位于中间的数是3,故该组数据的中位数为3, 所以选项B 说法不正确;因为0.003<0.1,方差越小,波动越小,数据越稳定, 所以甲组数据比乙组数据稳定,故选项C 说法正确;因为抛掷硬币属于随机事件,抛掷一枚硬币100次,不一定有50次“正面朝上” 故选项D 说法不正确. 故选:C . 【点睛】本题的关键在于掌握调查的选择、中位数和众数的求法、方差及随机事件的意义.9.B解析:B 【分析】方差是用来衡量一组数据波动大小的量,每个数都加了2,所以波动不会变,方差不变,平均数增加2. 【详解】由题意知,原来的平均数为2,每个数据都加上2,则平均数变为4;原来的方差221=(2)(2)(2)3S a b c ⎡⎤---⎣⎦22++ 现在的方差:222222111=(24)(24)(24)=(2)(2)(2)33S a b c a b c S ⎡⎤⎡⎤+-+-+-=---=⎣⎦⎣⎦22++++ 方差不变. 故选:B. 【点睛】本题考查了方差和平均数,当数据都加上一个数(或减去一个数)时,方差不变,即数据的波动情况不变.10.D解析:D 【分析】方差:一组数据中各数据与它们的平均数的差的平方的平均数,叫做这组数据的方差. 【详解】 依题意可得, 平均数:45mx∴224441555mmm解得m=1,故选D.【点睛】本题考查了方差,熟练运用方差公式是解题的关键.11.C解析:C【解析】【分析】方差是反映一组数据的波动大小的一个量.方差越大,则平均值的离散程度越大,稳定性也越小;反之,则它与其平均值的离散程度越小,稳定性越好,选出方差最小,而且平均数较大的同学参加数学比赛.【详解】∵3.6<7.4<8.1,∴甲和丙的最近几次数学考试成绩的方差最小,发挥稳定,∵95>92,∴丙同学最近几次数学考试成绩的平均数高,∴要选择一名成绩好且发挥稳定的同学参加数学比赛,应该选择丙.故选C.【点睛】此题主要考查了方差的含义和求法,要熟练掌握,解答此题的关键是要明确:方差是反映一组数据的波动大小的一个量.方差越大,则平均值的离散程度越大,稳定性也越小;反之,则它与其平均值的离散程度越小,稳定性越好.12.D解析:D【分析】根据样本、众数、中位数及方差的定义,结合表格分别进行解答,即可得出答案.【详解】A、10名学生的捐款数是总体的一个样本,故本选项错误;B、中位数是30,故本选项错误;C、众数是30,故本选项错误;D、平均数是:(20×2+30×4+50×3+90)÷10=40(元),则方差是:110×[2×(20﹣40)2+4×(30﹣40)2+3×(50﹣40)2+(90﹣40)2]=400,故本选项正确,故选D.【点睛】本题考查了中位数、方差、众数及样本的知识,掌握相关的定义以及求解方法是解题的关键.二、填空题13.82【分析】设第三次考试成绩为x 根据三次考试的平均成绩不少于80分列不等式求出x 的取值范围即可得答案【详解】设第三次考试成绩为x ∵三次考试的平均成绩不少于80分∴解得:∴他第三次数学考试至少得82分 解析:82【分析】设第三次考试成绩为x ,根据三次考试的平均成绩不少于80分列不等式,求出x 的取值范围即可得答案.【详解】设第三次考试成绩为x ,∵三次考试的平均成绩不少于80分, ∴7286803x ++≥, 解得:82x ≥, ∴他第三次数学考试至少得82分,故答案为:82【点睛】本题考查了一元一次不等式的应用.熟练掌握求平均数的方法,根据不等关系正确列出不等式是解题关键.14.925【分析】根据平均数与方差的定义计算即可得答案【详解】∵每名员工每天都比原先多生产1个零件∴现在日平均生产零件个数为=9设原先每人日生产零件的个数为:x1x2x3……x10∴原先的方差为=25∴解析:9 2.5【分析】根据平均数与方差的定义计算即可得答案.【详解】∵每名员工每天都比原先多生产1个零件,∴现在日平均生产零件个数为8101010⨯+=9, 设原先每人日生产零件的个数为:x 1、x 2、x 3、……x 10,∴原先的方差为22212101(8)(8)(8)10x x x ⎡⎤-+-+-⎣⎦…+=2.5, ∴现在的方差为22212101(19)(19)(19)10x x x ⎡⎤+-++-++-⎣⎦…+=22212101(8)(8)(8)10x x x ⎡⎤-+-+-⎣⎦…+=2.5, 故答案为:9,2.5【点睛】本题考查平均数与方差,熟练掌握定义与计算公式是解题关键.15.2【分析】先由平均数的公式计算出这组数的平均值再根据方差的公式S2=计算【详解】设这组数的平均值为则:∴方差S2=故答案为:2【点睛】本题考查的是方差:一般地设n 个数据x1x2…xn 的平均数为则方差解析:2【分析】先由平均数的公式计算出这组数的平均值,再根据方差的公式S 2=()()()()22221231n x x x x x x x x n ⎡⎤-+-+-++-⎣⎦计算. 【详解】 设这组数的平均值为x ,则: 1201205x -+++-== ∴方差S 2=()()()()()222221020001020215⎡⎤--+-+-+-+--=⎣⎦⨯ 故答案为:2.【点睛】本题考查的是方差:一般地设n 个数据x 1,x 2,…x n 的平均数为x ,则方差S 2=()()()()22221231n x x x x x x x x n ⎡⎤-+-+-++-⎣⎦,它反映了一组数据的波动大小,方差越大,波动性越大. 16.网页制作【分析】根据加权平均数的定义解答即可【详解】解:设网页制作的权重为a 语言的权重为b 则甲的分数为80a+70b 乙的分数为70a+80b 而甲的分数高所以80a+70b >70a+80b 解得a >b 则解析:网页制作【分析】根据加权平均数的定义解答即可.【详解】解:设网页制作的权重为a ,语言的权重为b ,则甲的分数为80a +70b ,乙的分数为70a +80b ,而甲的分数高,所以80a +70b >70a +80b ,解得a >b ,则本次招聘测试中权重较大的是网页制作项目.故答案为:网页制作.【点睛】本题考查了加权平均数的和解一元一次不等式的知识,属于基础题型,熟练掌握加权平均数的定义是关键.17.【分析】根据题意可得×(1+3+2+5+a)=3解这个方程就可以求出a 的值;根据标准差的计算公式即可求出样本标准差【详解】根据题意由平均数的定义得×(1+3+2+5+a)=3解得a=4所以方差为:S【分析】 根据题意可得15×(1+3+2+5+a)=3,解这个方程就可以求出a 的值;根据标准差的计算公式即可求出样本标准差.【详解】 根据题意 由平均数的定义得15×(1+3+2+5+a)=3, 解得,a=4.所以方差为:S 2=()()()()()2222213-1+3-3+3-2+3-5+3-4=5⎡⎤⨯⎣⎦2,.【点睛】此题考查平均数的概念,解题关键在于掌握计算公式.18.30【分析】根据计算方差的公式能够确定数据的个数和平均数从而求得所有数据的和【详解】解:∵S2=(x1﹣3)2+(x2﹣3)2+…+(x10﹣3)2∴平均数为3共10个数据∴x1+x2+x3+…+x解析:30【分析】根据计算方差的公式能够确定数据的个数和平均数,从而求得所有数据的和.【详解】解:∵S 2=110[(x 1﹣3)2+(x 2﹣3)2+…+(x 10﹣3)2], ∴平均数为3,共10个数据,∴x 1+x 2+x 3+…+x 10=10×3=30.故答案为30.【点睛】 本题考查了方差的知识,牢记方差公式是解答本题的关键,难度不大.19.76分;【解析】【分析】根据加权平均数的计算方法:先求出这10名同学的总成绩再除以10即可得出答案【详解】这10名同学的平均成绩为:=76(分)故答案为:76分【点睛】本题考查的是加权平均数的求法本解析:76分;【解析】【分析】根据加权平均数的计算方法:先求出这10名同学的总成绩,再除以10,即可得出答案.【详解】这10名同学的平均成绩为:70481060⨯+⨯=76(分), 故答案为:76分.【点睛】 本题考查的是加权平均数的求法.本题易出现的错误是对加权平均数的理解不正确,而求70、80这两个数的平均数.20.05【分析】利用方差的计算公式计算即可【详解】解:则故答案为05【点睛】本题考查的是方差的计算掌握方差的计算公式是解题的关键解析:0.5【分析】利用方差的计算公式计算即可.【详解】 解:1x (1021)14=+++=, 则222221(11)(01)(21)(11)0.54S ⎡⎤=-+-+-+-=⎣⎦, 故答案为0.5.【点睛】 本题考查的是方差的计算,掌握方差的计算公式()()()2222121n S x x x x x x n ⎡⎤=-+-+⋯+-⎣⎦是解题的关键. 三、解答题21.(1)85;(2)最终候选人E 将参加说题比赛【分析】(1)根据中位数的定义直接进行解答即可;(2)根据算术平均数的计算公式先求出C 、E 两名候选人的平均成绩,再进行比较,即可得出答案.【详解】解:(1)把这些数从小到大排列为:75,83,85,90,90,则名候选人模拟说题比赛成绩的中位数是85分;故答案为:85;(2)∵C 的平均成绩是:952803905235⨯+⨯+⨯++=88(分), E 的平均成绩是:852*********⨯+⨯+⨯++=89(分), ∴88<89,∴最终候选人E 将参加说题比赛.【点睛】本题考查中位数、平均数,加权平均数等知识,解题的关键是理解平均数的定义.22.(1)a=10,b=8,c=8.6;(2)推荐丙班级为网上教学先进班级.【分析】(1)直接根据中位数、众数、平均分的概念即可求解;(2)先根据各项得分的权重求得各班的最终成绩,然后比较即可判断.【详解】解:(1)∵甲班的五项指标得分由小到大重新排列为:6、7、10、10、10∴甲班的中位数为:10分;∵乙班的五项指标得分为:10、8、8、9、88分出现次数最多,∴乙班的众数是:8分;∵(9+10+8+7+9)÷5=8.6(分),∴丙班的平均分是:8.6分;∴a=10,b=8,c=8.6.(2)甲:10×20%+10×20%+6×30%+10×10%+7×20%=8.2(分)乙:10×20%+8×20%+8×30%+9×10%+8×20%=8.5(分)丙:9×20%+10×20%+8×30%+7×10%+9×20%=8.7(分),∴推荐丙班级为网上教学先进班级.【点睛】此题主要考查数据的统计和分析,正确理解每个概念是解题关键.23.(1)70;(2)详见解析;(3)80;(4)乙将被选中,理由详见解析【分析】(1)根据平均数公式即可求得a的值;(2)根据(1)计算的结果即可作出折线图;(3)利用平均数公式即可秋求解;(4)首先比较平均数,选择平均数大的,若相同,则比较方差,选择方差小,比较稳定的.【详解】解:(1)根据题意得:901009050805a++++=,解得:a=70.(2)完成图中表示甲成绩变化情况的折线如图:(3)()乙1=8070809080=805x ++++, (4)甲乙成绩的平均数相同,乙的方差小于甲的方差,乙比甲稳定,所以乙将被选中.【点睛】本题考查了折线图的意义和平均数的概念.平均数是指在一组数据中所有数据之和再除以数据的个数.平均数是表示一组数据集中趋势的量数,它是反映数据集中趋势的一项指标.解答平均数应用题的关键在于确定“总数量”以及和总数量对应的总份数.24.(1)9.5,10;(2)9分,1分2;(3)乙【分析】(1)根据中位数的定义求出最中间两个数的平均数;根据众数的定义找出出现次数最多的数即可;(2)先求出乙队的平均成绩,再根据方差公式进行计算;(3)先比较出甲队和乙队的方差,再根据方差的意义即可得出答案.【详解】(1)把甲队的成绩从小到大排列为:7,7,8,9,9,10,10,10,10,10,最中间两个数的平均数是(9+10)÷2=9.5(分),则中位数是9.5分;乙队成绩中10出现了4次,出现的次数最多,则乙队成绩的众数是10分;故答案为:9.5,10;(2)乙队的平均成绩是:()104827939110⨯+⨯++⨯=⨯(分), 则方差是:()()()()22224109211089793991⎡⎤⨯-+⨯-+-+⨯-=⎣⎦⨯(分2) ; (3)∵甲队成绩的方差是1.4,乙队成绩的方差是1,∴成绩较为整齐的是乙队;故答案为:乙.【点睛】本题考查方差、中位数和众数:中位数是将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(或最中间两个数的平均数),一般地设n 个数据x 1,x 2,…x n 的平均数为x ,则方差S 2=()()()()22221231n x x x x x x x x n ⎡⎤-+-+-++-⎣⎦,它反映了一组数据的波动大小,方差越大,波动性越大.25.(1)m=60;(2)120°;(3)2.8小时.【分析】 (1)根据2小时所占扇形的圆心角的度数确定其所占的百分比,然后根据条形统计图中2小时的人数求得m 的值; (2)先求出课外阅读3小时的人数,再用360°乘以阅读时间为3小时的人数所占的百分比即可;(3)利用平均数的计算公式进行计算即可.【详解】(1)∵课外阅读时间为2小时的所在扇形的圆心角的度数为90°,∴其所占的百分比为9013604=,∵课外阅读时间为2小时的有15人,∴m=15÷14=60;(2)课外阅读3小时的人数有:60﹣10﹣15﹣10﹣5=20(人),所以阅读时间为3小时的扇形圆心角的度数是2060×360°=120°;(3)这组数据的平均数为:1011522031045560⨯+⨯+⨯+⨯+⨯≈2.8小时.【点睛】此题考查条形统计图与扇形统计图的结合计算,能正确求样本的总数,求部分的数量及圆心角度数,掌握加权平均数的公式是解题的关键.26.(1)28;(2)1.8kg,1.5kg;(3)平均数是1.52kg,总质量约为3800kg.【分析】(1)根据各种质量的百分比之和为1可得m的值;(2)根据众数、中位数、加权平均数的定义计算即可;(3)根据平均数的计算公式求出这组数据的平均数,再乘以总只数即可得出鸡的总质量.【详解】(1)图①中m的值为100﹣(32+8+10+22)=28,故答案为:28;(2)∵1.8kg出现的次数最多,∴众数为1.8kg,把这些数从小到大排列,则中位数为1.5 1.52+=1.5(kg);故答案为:1.8kg,1.5kg;(3)这组数据的平均数是:151114164++++×(5×1+11×1.2+14×1.5+16×1.8+4×2),=150⨯(5+13.2+21+28.8+8),=1.52(kg),∴2500只鸡的总质量约为:1.52×2500=3800(kg),所以这组数据的平均数是1.52kg,2500只鸡的总质量约为3800kg.【点睛】此题考查统计计算,正确掌握部分百分比的计算方法,众数的定义、中位数的定义,平均数的计算方法是解题的关键.。
一、选择题1.八年级某班五个合作学习小组人数如下:5,7,6,x,7.已知这组数据的平均数是6,则x的值为()A.7 B.6 C.5 D.42.小王在清点本班为偏远贫困地区的捐款时发现,全班同学捐款的钞票情况如下:100元的3 张,50元的9张,10元的23张,5元的10张.在这些不同面额的钞票中,众数是()A.10 B.23 C.50 D.1003.近年来,我国持续大面积的雾霾天气让环保和健康问题成为焦点.为进一步普及环保和健康知识,我市某校举行了“建设宜居成都,关注环境保护”的知识竞赛,某班的学生成绩统计如下:成绩(分)60708090100人数4812115则该办学生成绩的众数和中位数分别是()A.70分,80分B.80分,80分C.90分,80分D.80分,90分4.某商场统计五个月来两种型号洗衣机的销售情况,制成了条形统计图,则在五个月中,下列说法正确的是()A.甲销售量比乙销售量稳定B.乙销售量比甲销售量稳定C.甲销售量与乙销售量一样稳定D.无法比较两种洗衣机销售量稳定性5.一组数据:3,2,5,3,7,5,x,它们的众数为5,则x ()A.2 B.3 C.5 D.76.甲、乙两班举行电脑汉字输入比赛,参赛学生每分输入汉字的个数统计结果如下表:班级参加人数中位数方差平均数甲55149 1.91135乙55151 1.10135某同学分析上表后得到如下结论:①甲、乙两班学生平均成绩相同;≥为优秀)②乙班优秀的人数多于甲班优秀的人数(每分输入汉字个数150③甲班成绩的波动比乙班大.上述结论中正确的是()A.①②③B.①②C.①③D.②③=,S2乙7.某次知识竞赛中,两组学生成绩如下表,通过计算可知两组的方差为S2甲172=,下列说法:256①两组的平均数相同;②甲组学生成绩比乙组学生成绩稳定;③甲组成绩的众数>乙组成绩的众数;④两组成绩的中位数均是80,但成绩≥80的人数甲比乙组多,从中位数来看,甲组成绩总体比乙组好;⑤成绩高于或等于90分的人数乙组比甲组多,高分段乙组成绩比甲组好.其中正确的有()个A.2 B.3 C.4 D.58.某校九年级模拟考试中,1班的六名学生的数学成绩如下:96,108,102,110,108,82.下列关于这组数据的描述不正确的是()A.众数是108 B.中位数是105C.平均数是101 D.方差是939.甲、乙、丙、丁四位选手各进行了10次射击,射击成绩的平均数和方差如下表:选手甲乙丙丁平均数(环)9.09.09.09.0方差0.25 1.00 2.50 3.00则成绩发挥最不稳定的是( )A.甲B.乙C.丙D.丁10.某班体育委员记录了第一小组七位同学定点投篮(每人投10次)的情况,投进篮筐的个数为6,9,5,3,4,8,4,这组数据的众数是()A.3 B.4 C.5 D.811.某中学九年级二班的8名女同学在一次仰卧起坐测试中的成绩如下(单位:个),135 138142144140147145145;则这组数据的中位数、平均数分别是()A.142,142 B.143,142 C.143,143 D.144,14312.下面的统计图表示某体校射击队甲、乙两名队员射击比赛的成绩,根据统计图中的信息,下列结论正确的是()A.甲队员成绩的平均数比乙队员的大B.乙队员成绩的平均数比甲队员的大C.甲队员成绩的中位数比乙队员的大D.甲队员成绩的方差比乙队员的大二、填空题13.甲、乙、丙三人进行飞镖比赛,已知他们每人五次投得的成绩如图6-Z-2所示,那么三人中成绩最稳定的是________.14.在一次数学测验中,甲组4名同学的平均成绩是70分,乙组6名同学的平均成绩是80分,则这10名同学的平均成绩是______________.15.甲、乙两个篮球队队员身高的平均数都为2.07米,方差分别是2S甲、2S乙,且22S S>甲乙,则队员身高比较整齐的球队是_____.16.甲、乙二人在相同情况下,各射靶10次,两人命中环数的平均数都是7,方差2S甲=2.8,2S乙=1.5,则射击成绩较稳定的是______.(填“甲”或“乙”)17.某班体育委员对本班所有学生一周锻炼时间(单位:小时)进行了统计,绘制了统计图,如图所示,根据统计图提供的信息,下列推断不正确的是__________________①该班学生共有44人;②.该班一周锻炼时间为10小时的学生最多;③该班学生一周锻炼时间的中位数是11;④该班学生一周锻炼的平均时间为910111213115++++=小时.18.已知x1,x2,x3的平均数x=10,方差s2=3,则2x1,2x2,2x3的平均数为__________,方差为__________.19.如图,在边长为4的等边ABC中,D,E分别为AB,BC的中点,EF AC于点F,G为EF的中点,连接DG,则DG的长为__________.20.春节期间,重庆某著名旅游景点成为热门景点,大量游客慕名前往,市旅游局统计了春节期间5天的游客数量,绘制了如图所示的折线统计图,则这五天游客数量的中位数为__.三、解答题21.甲、乙两位同学5次数学选拔赛的成绩统计如表,他们5次考试的总成绩相同,请同学们完成下列问题:第1次第2次第3次第4次第5次甲成绩8040705060乙成绩705070a70=,甲同学成绩的极差为;(2)小颖计算了甲同学的成绩平均数为60,方差是S甲2=15[(80﹣60)2+(40﹣60)2+(70﹣60)2+(50﹣60)2+(60﹣60)2]=200.请你求出乙同学成绩的平均数和方差;(3)从平均数和方差的角度分析,甲、乙两位同学谁的成绩更稳定.22.如图,在菱形ABCD中,对角线AC与BD交于点O.过点C作BD的平行线,过点D 作AC的平行线,两直线相交于点E.(1)求证:四边形OCED是矩形;(2)若CE=1,DE=2,ABCD的面积是.23.某市政府为了鼓励居民节约用水,计划调整居民生活用水收费方案:一户家庭的月均用水量不超过m (单位:t )的部分按平价收费,超出m 的部分按议价收费.为此拟召开听证会,以确定一个合理的月均用水量标准m .通过抽样,获得了前一年1000户家庭每户的月均用水量(单位:t ),将这1000个数据按照04x ≤<,48x ≤<,…,2832x ≤<分成8组,制成了如图所示的频数分布直方图.(1)写出a 的值,并估计这1000户家庭月均用水量的平均数;(同一组中的数据以这组数据所在范围的组中值作代表)(2)假定该市政府希望70%的家庭的月均用水量不超过标准m ,请判断若以(1)中所求得的平均数作为标准m 是否合理?并说明理由.24.为了解某校九年级学生的理化实验操作情况,随机抽查了 40 名同学实验操作的得分(满分10分).根据获取的样本数据,制作了如下的条形统计图和扇形统计图.请根据相关信息,解答下列问题:(1)扇形①的圆心角的大小是 ; (2)求这个样本的容量和样本数据的平均数;(3)若该校九年级共有 400 名学生,估计该校理化实验操作得满分的学生有多少人. 25.为了从甲、乙两名选手中选拔一个参加射击比赛,现对他们进行一次测验,两个人在相同条件下各射靶10次,为了比较两人的成绩,制作了如下统计图表: 甲乙射击成绩统计表平均数 中位数 方差 命中10环的次数 甲 7乙7.5 5.41甲乙射击成绩折线图(1)请补全上述图表(请直接在统计表中填空和补全折线图);(2)如果规定成绩较稳定者胜出,则_____胜出,理由是____________________;(3)如果希望(2)中的另一名选手胜出,根据图表中的信息,应该制定怎样的评判规则?说明理由.26.随着移动计算技术和无线网络的快速发展,移动学习方式越来越引起人们的关注.某校计划将这种学习方式应用到教育教学中,从各年级共1500名学生中随机抽取了部分学生,对其家庭中拥有的移动设备情况进行了调查,并绘制出如下的统计图①和图②,根据相关信息,解答下列问题:(1)本次接受随机抽样调查的学生人数为人,图①中m的值为.(2)求本次调查获取的样本数据的众数、中位数;(3)根据样本数据,估计该校学生家庭中;拥有3台移动设备的学生人数.【参考答案】***试卷处理标记,请不要删除一、选择题1.C解析:C【分析】根据平均数的计算公式列出算式,再进行计算即可得出x的值.【详解】解:∵5,7,6,x,7的平均数是6,∴15(5+7+6+x +7)=6, 解得:x =5; 故选:C . 【点睛】本题考查了算术平均数的知识,解题的关键是根据算术平均数求出数据总和.2.A解析:A 【分析】根据众数就是一组数据中,出现次数最多的数,即可得出答案. 【详解】∵100元的有3 张,50元的有9张,10元的有23张,5元的有10张,其中10元的最多,∴众数是10元. 故答案为A . 【点睛】本题考查众数的概念.,一组数据中出现次数做多的数叫做众数.3.B解析:B 【解析】试题分析:众数是在一组数据中,出现次数最多的数据,这组数据中80出现12次,出现的次数最多,故这组数据的众数为80分;中位数是一组数据从小到大(或从大到小)排列后,最中间的那个数(最中间两个数的平均数).因此这组40个按大小排序的数据中,中位数是按从小到大排列后第20,21个数的平均数,而第20,21个数都在80分组,故这组数据的中位数为80分. 故选B .考点:1.众数;2.中位数.4.B解析:B 【分析】根据方差的定义,方差越小数据越稳定,即可得出答案. 【详解】解:甲每月平均销售量是:1(13411)25++++=(百台), 乙每月平均销售量是:1(23221)25++++=(百台), 则甲的方差是:22213(12)(32)(42) 1.65⎡⎤⨯-+-+-=⎣⎦乙的方差是:22213(22)(32)(12)0.45⎡⎤⨯-+-+-=⎣⎦ ∵1.6>0.4,∴乙销售量比甲销售量稳定; 故选:B . 【点睛】本题考查了方差的意义.方差是用来衡量一组数据波动大小的量,方差越大,表明这组数据偏离平均数越大,即波动越大,数据越不稳定;反之,方差越小,表明这组数据分布比较集中,各数据偏离平均数越小,即波动越小,数据越稳定.5.C解析:C 【分析】根据众数的定义(一组数据中出现次数最多的数叫众数),直接写出x 的值即可得到答案. 【详解】解:∵一组数据:3,2,5,3,7,5,x ,它们的众数为5, ∴5出现的次数最多, 故5x =, 故选C . 【点睛】本题主要考查众数的基本概念,熟练掌握众数的基本概念是解题的关键,一组数据中出现次数最多的数据叫做众数.6.A解析:A 【分析】平均水平的判断主要分析平均数;优秀人数的判断从中位数不同可以得到;波动大小比较方差的大小. 【详解】从表中可知,平均字数都是135,①正确;甲班的中位数是149,乙班的中位数是151,比甲的多,而平均数都要为135,说明乙的优秀人数多于甲班的,②正确;甲班的方差大于乙班的,又说明甲班的波动情况大,所以③也正确. ①②③都正确. 故选:A . 【点睛】此题考查平均数,中位数,方差的意义.解题关键在于掌握平均数表示一组数据的平均程度.中位数是将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(或最中间两个数的平均数);方差是用来衡量一组数据波动大小的量.7.C解析:C 【分析】根据中位数、众数、方差、平均数的概念来解答. 【详解】解:①平均数:甲组:(50×2+60×5+70×10+80×13+90×14+100×6)÷50=80, 乙组:(50×4+60×4+70×16+80×2+90×12+100×12)÷50=80, ②S 甲2=172<S 乙2=256,故甲组学生成绩比乙组学生成绩稳定; ③甲组成绩的众数90>乙组成绩的众数70;④成绩≥80的人数甲组33人比乙组26人多;从中位数来看,甲组成绩80=乙组成绩80,故错误.⑤成绩高于或等于90分的人数乙组24人比甲组20人多,高分段乙组成绩比甲组好. 故①②③⑤正确. 故选:C . 【点睛】此题考查中位数和众数的定义.解题关键在于掌握各定义性质.8.D解析:D 【分析】把六名学生的数学成绩从小到大排列为:82,96,102,108,108,110,求出众数、中位数、平均数和方差,即可得出结论. 【详解】解:把六名学生的数学成绩从小到大排列为:82,96,102,108,108,110, ∴众数是108,中位数为1021081052+=,平均数为82961021081081101016+++++=,方差为()()()()()()222222182101961011021011081011081011101016⎡⎤-+-+-+-+-+-⎣⎦ 94.393≈≠;故选D . 【点睛】考核知识点:众数、中位数、平均数和方差;理解定义,记住公式是关键.9.D解析:D 【解析】 【分析】根据方差的定义,方差越小数据越稳定,反之波动越大. 【详解】 由表可知:丁的方差最大,这四个人中,发挥最不稳定的是丁故选:D【点睛】本题考查方差的意义,熟知方差越小数据越稳定,反之波动越大是解题关键. 10.B解析:B【解析】【分析】众数是出现次数最多的数,据此求解即可.【详解】∵数据4出现了2次,最多,∴众数为4,故选:B.【点睛】本题考查了众数的知识,解题的关键是了解有关的定义,属于基础题,难度不大.11.B解析:B【解析】【分析】把数据从小到大排序,第4,5个数的平均数是中位数;根据平均数的公式求值.【详解】中位数:142144=1432+平均数:135138142144140147145145=1428+++++++故选B【点睛】考核知识点:中位数,算术平均数.理解定义是关键.12.D解析:D【解析】【分析】根据平均数、中位数和方差的计算公式分别对每一项进行分析,即可得出答案.【详解】甲队员10次射击的成绩分别为6,7,7,7,8,8,9,9,9,10,则中位数882+=8,甲10次射击成绩的平均数=(6+3×7+2×8+3×9+10)÷10=8(环),乙队员10次射击的成绩分别为6,7,7,8,8,8,8,9,9,10,则中位数是8,乙10次射击成绩的平均数=(6+2×7+4×8+2×9+10)÷9=8(环),甲队员成绩的方差=110×[(6-8)2+3×(7-8)2+2×(8-8)3+3×(9-8)2+(10-8)2]=1.4;乙队员成绩的方差=110×[(6-8)2+2×(7-8)2+4×(8-8)3+2×(9-8)2+(10-8)2]=1.2,综上可知甲、乙的中位数相同,平均数相同,甲的方差大于乙的方差,故选D.【点睛】本题考查了平均数、中位数和方差的定义和公式,熟练掌握平均数、中位数、方差的计算是解题的关键.二、填空题13.乙【分析】通过图示波动的幅度即可推出【详解】通过图示可看出一至三次甲乙丙中乙最稳定波动最小四至五次三人基本一样故选乙【点睛】考查数据统计的知识点解析:乙【分析】通过图示波动的幅度即可推出.【详解】通过图示可看出,一至三次甲乙丙中,乙最稳定,波动最小,四至五次三人基本一样,故选乙【点睛】考查数据统计的知识点14.76分;【解析】【分析】根据加权平均数的计算方法:先求出这10名同学的总成绩再除以10即可得出答案【详解】这10名同学的平均成绩为:=76(分)故答案为:76分【点睛】本题考查的是加权平均数的求法本解析:76分;【解析】【分析】根据加权平均数的计算方法:先求出这10名同学的总成绩,再除以10,即可得出答案.【详解】这10名同学的平均成绩为:7048106⨯+⨯=76(分),故答案为:76分.【点睛】本题考查的是加权平均数的求法.本题易出现的错误是对加权平均数的理解不正确,而求70、80这两个数的平均数.15.乙【分析】根据方差的意义可作出判断方差是用来衡量一组数据波动大小的量方差越小表明这组数据分布比较集中各数据偏离平均数越小即波动越小数据越稳定【详解】解:∵∴队员身高比较整齐的球队是乙故答案为乙【点睛 解析:乙【分析】根据方差的意义可作出判断.方差是用来衡量一组数据波动大小的量,方差越小,表明这组数据分布比较集中,各数据偏离平均数越小,即波动越小,数据越稳定.【详解】解:∵22S S >甲乙,∴队员身高比较整齐的球队是乙,故答案为乙.【点睛】本题考查方差.解题关键在于知道方差是用来衡量一组数据波动大小的量16.乙【解析】【分析】直接利用方差的意义方差越小越稳定进而分析得出答案【详解】∵方差=1515<28∴射击成绩较稳定的是:乙故答案为:乙【点睛】此题主要考查了方差正确把握方差的意义是解题关键解析:乙【解析】【分析】直接利用方差的意义,方差越小越稳定,进而分析得出答案.【详解】∵方差222.8,S S =甲乙=1.5,1.5<2.8,∴射击成绩较稳定的是:乙.故答案为:乙.【点睛】此题主要考查了方差,正确把握方差的意义是解题关键.17.①②④【解析】【分析】根据统计图中的数据可以得到一共多少人然后根据平均数中位数和众数的定义即可求得这组数据的平均数中位数和众数【详解】由统计图可知锻炼9小时的有6人锻炼10小时的有9人锻炼11小时的 解析:①②④【解析】【分析】根据统计图中的数据可以得到一共多少人,然后根据平均数、中位数和众数的定义即可求得这组数据的平均数、中位数和众数.【详解】由统计图可知锻炼9小时的有6人,锻炼10小时的有9人,锻炼11小时的有10人,锻炼12小时的有8人,锻炼13小时的有7人,故该班学生共有6+9+10+8+7=40人,因此①错误;从统计图可以看出,该班一周锻炼时间为11小时的学生最多,因此②错误;该班学生一周锻炼时间的中位数是11小时,故③正确; 该班学生一周锻炼的平均时间为69+910+1110+128+137=11.02540⨯⨯⨯⨯⨯小时,故④错误.故错误的有①②④【点睛】题考查折线统计图、平均数、中位数和众数的定义,解答本题的关键是明确中位数的定义,利用数形结合的思想解答. 18.2012【解析】∵=10∴=10设222的方差为则=2×10=20∵∴==4×3=12故答案为20;12点睛:本题考查了当数据加上一个数(或减去一个数)时方差不变即数据的波动情况不变平均数也加或减这解析:20 12【解析】 ∵x =10, ∴1233x x x ++=10, 设21x ,22x ,23x 的方差为, 则1232223x x x y ++==2×10=20, ∵22221231(10)(10)(10)3s x x x ⎡⎤=-+-++⎣⎦ , ∴22221231(2)(2)(2)S x y x y x y n '⎡⎤=-+-+-⎣'⎦ =132221234(10)4(10)4(10)x x x ⎡⎤-+-++⎣⎦ =4×3=12.故答案为20;12. 点睛:本题考查了当数据加上一个数(或减去一个数)时,方差不变,即数据的波动情况不变,平均数也加或减这个数;当乘以一个数时,方差变成这个数的平方倍,平均数也乘以这个数.19.【解析】分析:连接DE 根据题意可得ΔDEG 是直角三角形然后根据勾股定理即可求解DG 的长详解:连接DE ∵DE 分别是ABBC 的中点∴DE ∥ACDE=AC ∵ΔABC 是等边三角形且BC=4∴∠DEB=60°2【解析】 分析:连接DE ,根据题意可得ΔDEG 是直角三角形,然后根据勾股定理即可求解DG 的长.详解:连接DE ,∵D 、E 分别是AB 、BC 的中点,∴DE ∥AC ,DE=12AC ∵ΔABC 是等边三角形,且BC=4∴∠DEB=60°,DE=2∵EF ⊥AC ,∠C=60°,EC=2∴∠FEC=30°,3∴∠DEG=180°-60°-30°=90°∵G 是EF 的中点,∴EG=32. 在RtΔDEG 中,22223192()2DE EG +=+= 192点睛:本题主要考查了等边三角形的性质,勾股定理以及三角形中位线性质定理,记住和熟练运用性质是解题的关键.20.234【解析】【分析】将折线统计图中的数据按从小到大进行排序然后根据中位数的定义即可确定【详解】从图中看出五天的游客数量从小到大依次为219224234249254则中位数应为234故答案为234【解析:23.4【解析】【分析】将折线统计图中的数据按从小到大进行排序,然后根据中位数的定义即可确定.【详解】从图中看出,五天的游客数量从小到大依次为21.9,22.4,23.4,24.9,25.4, 则中位数应为23.4,故答案为23.4.【点睛】本题考查了中位数的定义,熟知“中位数是将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(或最中间两个数的平均数)”是解题的关键.三、解答题21.(1)40,40;(2)平均数为60,方差160;(3)见解析.【分析】(1)由“他们5次考试的总成绩相同”可求得a 的值,利用极差的定义求解可得; (2)利用方差公式计算出乙的方差;(3)根据平均数与方差的意义进行判断,即可得出结论.【详解】解:(1)a =(80+40+70+50+60)﹣(70+50+70+70)=40,甲同学成绩的极差为:80﹣40=40,故答案为:40,40;(2)乙同学的成绩平均数为15×(70+50+70+40+70)=60, 方差S 乙2=15[(70﹣60)2+(50﹣60)2+(70﹣60)2+(40﹣60)2+(70﹣60)2]=160; (3)因为甲乙两位同学的平均数相同,S 甲2>S 乙2,所以乙同学的成绩更稳定.【点睛】本题主要考查平均数、方差,解题的关键是掌握方差、平均数、极差的计算方法和方差的意义.22.(1)证明见解析;(2)4.【解析】【分析】(1)欲证明四边形OCED 是矩形,只需推知四边形OCED 是平行四边形,且有一内角为90度即可;(2)由菱形的对角线互相垂直平分和菱形的面积公式解答.【详解】(1)∵四边形ABCD 是菱形,∴AC ⊥BD ,∴∠COD=90°.∵CE ∥OD ,DE ∥OC ,∴四边形OCED 是平行四边形,又∠COD=90°,∴平行四边形OCED 是矩形;(2)由(1)知,平行四边形OCED 是矩形,则CE=OD=1,DE=OC=2.∵四边形ABCD 是菱形,∴AC=2OC=4,BD=2OD=2,∴菱形ABCD 的面积为:12AC•BD=12×4×2=4, 故答案为4.【点睛】本题考查了矩形的判定与性质,菱形的性质,熟练掌握矩形的判定及性质、菱形的性质是解题的关键.23.(1)100,14.72;(2)不合理,见解析【分析】(1)先确定a 的值,然后求这些数据的加权平均数即可;(2)由14.72在1216x ≤<内,然后确定小于16t 的户数,再求出小于16t 的户数占样本的百分比,最后用这个百分比和70%相比即可说明.【详解】解:(1)依题意得a=(1000-40-180-280-220-60-20)÷2=100.这1000户家庭月均用水量的平均数为:2406100101801428018220221002660302014.721000x ⨯+⨯+⨯+⨯+⨯+⨯+⨯+⨯==, ∴估计这1000户家庭月均用水量的平均数是14.72.(2)不合理.理由如下:由(1)可得14.72在1216x ≤<内,∴这1000户家庭中月均用水量小于16t 的户数有40100180280600+++=(户),∴这1000户家庭中月均用水量小于16t 的家庭所占的百分比是600100%60%1000⨯=, ∴月均用水量不超过14.72t 的户数小于60%.∵该市政府希望70%的家庭的月均用水量不超过标准m ,而60%70%<,∴用14.72作为标准m 不合理.【点睛】本题考查了频数分布直方图、用样本估计总体、加权平均数,正确求得加权平均数是解答本题的关键.24.(1)36°;(2)40,8.3;(3)70人【分析】(Ⅰ)用1减去7、8、9、10分所占的扇形统计图中的百分比得①所占的百分比,再用360°乘以①所占的百分算即可得解;(2)根据题目信息知样本容量为40,根据平均数的定义求解样本数据的平均数; (3)用九年级总人数乘以满分的人数所占的份数计算即可得解.【详解】解::(Ⅰ)360°×(1-15%-27.5%-30%-17.5%)=360°×10%=36°,故答案为:36°;(2)根据题干信息,“随机抽查了 40 名同学实验操作的得分”,可知样本容量为40, 解样本数据的平均数:46671181297108.340x ⨯+⨯+⨯+⨯+⨯==, ∴样本数据的平均数为:8.3,故:样本容量为40,样本数据的平均数为8.3; (3)40017.5%70⨯=人,答:估计该校理化实验操作得满分的学生有70人.【点睛】本题考查的是条形统计图和扇形统计图的综合运用.读懂统计图,从不同的统计图中得到必要的信息是解决问题的关键.条形统计图能清楚地表示出每个项目的数据;扇形统计图直接反映部分占总体的百分比大小.25.(1)补全图表见解析;(2)甲,理由见解析;(3)可制定评判规则为:命中10环次数较多者胜出,理由见解析.【分析】(1)根据甲选手成绩的平均数可求出甲选手第8次命中的环数,即可补全折线图;然后根据平均数、中位数和方差的求法补全统计表;(2)根据方差的意义可得答案;(3)可根据乙选手命中10环1次,甲选手没有命中10环来制定评判规则.【详解】解:(1)甲选手第8次命中的环数为:7×10-(9+6+7+6+5+7+7+8+9)=6, 将甲选手的成绩从小到大排列为:5,6,6,6,7,7,7,8,9,9,中间两次的环数分别为:7,7,故中位数为7772+=, 2222221=5767377387972=1.610S 甲,乙选手成绩的平均数为:24687789910=710, 补全表格和折线图为: 平均数 中位数 方差命中10环的次数 甲7 7 1.6 0 乙 7 7.5 5.4 1(2)如果规定成绩较稳定者胜出,则甲胜出,理由:因为甲的方差小于乙的方差,所以甲的成绩比乙稳定,即甲胜出;(3)可制定评判规则为:命中10环次数较多者胜出,理由:因为乙选手命中10环1次,甲选手没有命中10环,所以乙胜出.【点睛】本题考查了折线统计图,平均数、中位数、方差的意义与求法,能够从图表中得出有用信息是解题的关键.26.(1)50,32;(2)众数为4;中位数是3;(3)420【分析】(1)根据2台的人数和所占百分比可求出调查的学生总人数,用4台的人数除以总人数可得m 的值;(2)根据众数和中位数的定义求解;(3)用1500乘以拥有3台移动设备的学生人数所占的百分比即可.【详解】解:(1)本次接受随机抽样调查的学生人数为:10÷20%=50(人),16%100%32%50m , ∴m =32,故答案为:50,32; (2)∵这组样本数据中,4出现了16次,出现次数最多,∴这组数据的众数为4;∵将这组数据从小到大排列,其中处于中间的两个数均为3,且332 =3, ∴这组数据的中位数是3;(3)1500×28%=420(人),答:估计该校学生家庭中;拥有3台移动设备的学生人数约为420人.【点睛】本题考查了条形统计图和扇形统计图的综合运用,众数和中位数的定义以及样本估计总体,能够从不同的统计图中获取有用信息是解题的关键.。
一、选择题1.为评估一种农作物的种植效果,选了8块地作试验田,这8块地的亩产量(单位:kg )分别为1x ,2x ,…,8x ,下面给出的指标中可以用来评估这种农作物亩产量稳定程度的是( )A .1x ,2x ,…,8x 的平均数B .1x ,2x ,…,8x 的方差C .1x ,2x ,…,8x 的中位数D .1x ,2x ,…,8x 的众数2.初三体育素质测试,某小组5名同学成绩如下所示,有两个数据遮盖,如图:A .35 2B .36 4C .35 3D .36 33.下表记录了甲、乙、丙、丁四名射击运动员最近几次选拔赛成绩的平均数和方差:根据表中数据,要从中选择一名成绩好且发挥稳定的运动员参加比赛,应选择( ) A .甲B .乙C .丙D .丁4.甲、乙、丙、丁四位同学五次数学测验成绩统计如右表所示,如果从这四位同学中,选出一位同学参加数学竞赛,那么应选___________去.A .甲B .乙C .丙D .丁5.甲、乙两班举行电脑汉字输入比赛,参赛学生每分输入汉字的个数统计结果如下表:某同学分析上表后得到如下结论: ①甲、乙两班学生平均成绩相同;②乙班优秀的人数多于甲班优秀的人数(每分输入汉字个数150≥为优秀) ③甲班成绩的波动比乙班大. 上述结论中正确的是( ) A .①②③B .①②C .①③D .②③6.一组数据,,,,,,a b c d e f g 的平均数是m ,极差是k ,方差是n ,则23,23,23,23,23,23------a b d e f g 的平均数、极差、和方差分别是( )A .222、、m k nB .23232m k n --、、C .232-、、4m k nD .2323--、、4m k n7.通过统计甲、乙、丙、丁四名同学某学期的四次数学测试成绩,得到甲、乙、丙、丁三明同学四次数学测试成绩的方差分别为S 甲2=17,S 乙2=36,S 丙2=14,丁同学四次数学测试成绩(单位:分).如下表:则这四名同学四次数学测试成绩最稳定的是( ) A .甲B .乙C .丙D .丁8.一次数学测试,某小组5名同学的成绩统计如下(有两个数据被遮盖):A .80,80B .81,80C .80,2D .81,2 9.一组数据3,4,4,5,若添加一个数4,则发生变化的统计量是( )A .平均数B .众数C .中位数D .方差10.为了解某校计算机考试情况,抽取了50名学生的计算机考试成绩进行统计,统计结果如表所示,则50名学生计算机考试成绩的众数、中位数分别为( )A .20,16B .l6,20C .20,l2D .16,l211.下面的统计图表示某体校射击队甲、乙两名队员射击比赛的成绩,根据统计图中的信息,下列结论正确的是( )A .甲队员成绩的平均数比乙队员的大B .乙队员成绩的平均数比甲队员的大C .甲队员成绩的中位数比乙队员的大D .甲队员成绩的方差比乙队员的大12.为了解某小区“全民健身”活动的开展情况,随机对居住在该小区的40名居民一周的体育锻炼时间进行了统计,结果如下表: 锻炼时间(时) 3 4 5 6 7 人数(人)6131452这40名居民一周体育锻炼时间的众数和中位数是( ) A .14,5B .14,6C .5,5D .5,6第II 卷(非选择题)请点击修改第II 卷的文字说明参考答案二、填空题13.已知一组数据a ,b ,c 的方差为2,那么数据a +3,b +3,c +3的方差是_____. 14.一组数据2,3,4,x ,6的平均数是4,则x 是_______. 15.数据-1,2,0,1,-2的方差是____.16.若一组数据3、4、5、x 、6的平均数是5,则这组数据的方差为_____17.某中学八年级人数相等的甲、乙两个班级参加了同一次数学测验,两班平均分和方差分别为x 甲=79,x 乙=79,2S 甲=101,2S 乙=235,则成绩较为整齐的是_________(填“甲班”或“乙班”).18.小林同学对甲、乙、丙三个市场某月份每天的白菜价格进行调查,计算后发现这个月三个市场的价格平均值相同,方差分别为2S 7.5=甲,2S 1.5乙=,2S 3.1=丙,那么该月份白菜价格最稳定的是______市场.19.设甲组数据:6,6,6,6,的方差为2s 甲,乙组数据:1,1,2的方差为2s 乙,则2s 甲与2s 乙的大小关系是________.20.一组数据3,2,3,4,x的平均数是3,则它的方差是_____.三、解答题21.在推进杭州市城乡生活垃圾分类的行动中,某校为了考察该校初中生掌握垃圾分类知识的情况,进行了一次测试,并随机抽取了若干名学生的测试成绩进行整理,绘制了如图所示不完整的频数直方图(每组含前一个边界值,不含后一个边界值)和扇形统计图.(1)求样本容量,并补充完整频数直方图.(2)在抽取的这些学生中,玲玲的测试成绩为85分,你认为85分一定是这些学生成绩的中位数吗?请简要说明理由.(3)若成绩在80分以上(包括80分)为优秀,请估计全校1400名学生中成绩优秀的人数.22.为了倡导“节约用水,从我做起”的活动,某市政府决定对市直机关500户家庭的用水情况作一次调查,调查小组随机抽查了其中100户家庭一年的月平均用水量(单位:吨).并将调查结果制成了如图所示的条形统计图.(1)这100个样本数据的平均数是、众数是和中位数是;(2)根据样本数据,估计该市直机关500户家庭中月平均用水量不超过12吨的约有多少户?23.某市射击队为从甲、乙两名运动员中选拔一人参加省比赛,对他们进行了六次测试,测试成绩如下表(单位:环):第1次第2次第3次第4次第5次第6次甲10988109乙101081079根据表格中的数据,可计算出甲、乙两人的平均成绩都是9环.(1)分别计算甲、乙六次测试成绩的方差;(2)根据数据分析的知识,你认为选______名队员参赛.24.甲、乙两名队员参加射击训练,成绩分别被制成下列两个统计图:根据以上信息,整理分析数据如下:平均成绩/环中位数/环众数/环方差甲a77 1.2乙7b8c(2)分别运用表中的四个统计量,简要分析这两名队员的射击训练成绩.若选派其中一名参赛,你认为应选哪名队员.25.八(2)班组织了一次经典朗读比赛,甲、乙两队各10人的比赛成绩如下表(单位:分):甲789710109101010乙10879810109109)甲队成绩的中位数是分,乙队成绩的众数是分;(2)计算乙队的平均成绩和方差;(3)已知甲队成绩的方差是1.4 分2,则成绩较为整齐的是队.26.下表是随机抽取的某公司部分员工的月收入资料.月收入/45000180001000055005000340030002000元(1)请计算样本的平均数和中位数;(2)甲乙两人分别用样本平均数和中位数来估计推断公司全体员工月收入水平,请你写出甲乙两人的推断结论;并指出谁的推断比较科学合理,能直实地反映公司全体员工月收入水平.【参考答案】***试卷处理标记,请不要删除一、选择题 1.B 解析:B 【分析】根据方差的意义即可判断. 【详解】解:方差是反映一组数据的波动大小的一个量.方差越大,则平均值的离散程度越大,稳定性也越小;反之,则它与其平均值的离散程度越小,稳定性越好. 故选:B . 【点睛】本题考查方差,平均数,中位数,众数等知识,解题的关键是熟练掌握基本知识,属于中考常考题型.2.B解析:B 【分析】根据平均数的计算公式先求出编号3的得分,再根据方差公式进行计算即可得出答案. 【详解】 解:这组数据的平均数是37,∴编号3的得分是:375(38343740)36⨯-+++=;方差是:222221[(3837)(3437)(3637)(3737)(4037)]45-+-+-+-+-=;故选:B . 【点睛】本题考查平均数和方差的定义,一般地设n 个数据,1x ,2x ,n x ⋯的平均数为x ,则方差2222121[()()()]n S x x x x x x n=-+-+⋯+-,它反映了一组数据的波动大小,方差越大,波动性越大,反之也成立.解析:D 【解析】【分析】首先比较平均数,平均数相同时选择方差较小的运动员参加. 【详解】∵==x x x x >乙丁甲丙, ∴从乙和丁中选择一人参加比赛,∵22S S >乙丁,∴选择丁参赛, 故选D .【点睛】本题考查了平均数和方差,正确理解方差与平均数的意义是解题关键.4.B解析:B 【分析】本题首先可通过四位同学的平均分比较,择高选取;继而根据方差的比较,择低选取求解本题. 【详解】通过四位同学平均分的比较,乙、丙同学平均数均为90,高于甲、丁同学,故排除甲、丁;乙、丙同学平均数相同,但乙同学方差更小,说明其发挥更为稳定,故选择乙同学. 故选:B . 【点睛】本题考查平均数以及方差,平均数表示其平均能力的高低;方差表示数据波动的大小,即稳定性高低,数值越小,稳定性越强,考查对应知识点时严格按照定义解题即可.5.A解析:A 【分析】平均水平的判断主要分析平均数;优秀人数的判断从中位数不同可以得到;波动大小比较方差的大小. 【详解】从表中可知,平均字数都是135,①正确;甲班的中位数是149,乙班的中位数是151,比甲的多,而平均数都要为135,说明乙的优秀人数多于甲班的,②正确;甲班的方差大于乙班的,又说明甲班的波动情况大,所以③也正确. ①②③都正确. 故选:A . 【点睛】此题考查平均数,中位数,方差的意义.解题关键在于掌握平均数表示一组数据的平均程度.中位数是将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(或最中间两个数的平均数);方差是用来衡量一组数据波动大小的量.解析:C【分析】根据平均数、极差和方差的变化规律即可得出答案.【详解】∵数据a、b、c、d、e、f、g的平均数是m,∴2a−3、2b−3、2c−3、2d−3、2e−3、2f−3、2g−3的平均数是2m−3;∵数据a、b、c、d、e、f、g的极数是k,∴2a−3、2b−3、2c−3、2d−3、2e−3、2f−3、2g−3的平均数是2k;∵数据a、b、c、d、e、f、g的方差是n,∴数据2a−3、2b−3、2c−3、2d−3、2e−3、2f−3、2g−3的方差是224n n;故选C.【点睛】此题考查方差、极差、算术平均数,解题关键在于掌握方差、极差、算术平均数变化规律即可.7.C解析:C【分析】求得丁同学的方差后与前三个同学的方差比较,方差最小的成绩最稳定.【详解】丁同学的平均成绩为:14⨯(80+80+90+90)=85;方差为S丁214=[2×(80﹣85)2+2×(90﹣85)2]=25,所以四个人中丙的方差最小,成绩最稳定.故选C.【点睛】本题考查了方差的意义及方差的计算公式,解题的关键是牢记方差的公式,难度不大.8.A解析:A【分析】根据平均数的计算公式先求出丙的得分,再根据方差公式进行计算即可得出答案.【详解】根据题意得:805(81778082)80⨯-+++=(分),则丙的得分是80分;众数是80,故选A.【点睛】考查了众数及平均数的定义,解题的关键是根据平均数求得丙的得分,难度不大.9.D解析:D【分析】依据平均数、中位数、众数、方差的定义和公式分别计算新旧两组数据的平均数、中位数、众数、方差求解即可.【详解】原数据的3,4,4,5的平均数为3+4+4+5=44,原数据的3,4,4,5的中位数为4+4=24,原数据的3,4,4,5的众数为4,原数据的3,4,4,5的方差为14×[(3-4)2+(4-4)2×2+(5-4)2]=0.5;新数据3,4,4,4,5的平均数为3+4+4+4+5=45,新数据3,4,4,4,5的中位数为4,新数据3,4,4,4,5的众数为4,新数据3,4,4,4,5的方差为15×[(3-4)2+(4-4)2×3+(5-4)2]=0.4;∴添加一个数据4,方差发生变化,故选D.【点睛】本题主要考查的是众数、中位数、方差、平均数,熟练掌握相关概念和公式是解题的关键.10.A解析:A【解析】【分析】找中位数要把数据按从小到大的顺序排列,位于最中间的一个数(或两个数的平均数)为中位数,众数是一组数据中出现次数最多的数据,注意众数可以不止一个.【详解】解:在这一组数据中20是出现次数最多的,故众数是20;将这组数据从大到小的顺序排列后,处于中间位置的数是16,16,那么这组数据的中位数16.故选:A.【点睛】本题为统计题,考查众数与中位数的意义,中位数是将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(最中间两个数的平均数),叫做这组数据的中位数.众数是一组数据中出现次数最多的数.11.D解析:D【解析】【分析】根据平均数、中位数和方差的计算公式分别对每一项进行分析,即可得出答案.【详解】甲队员10次射击的成绩分别为6,7,7,7,8,8,9,9,9,10,则中位数882=8,甲10次射击成绩的平均数=(6+3×7+2×8+3×9+10)÷10=8(环),乙队员10次射击的成绩分别为6,7,7,8,8,8,8,9,9,10,则中位数是8,乙10次射击成绩的平均数=(6+2×7+4×8+2×9+10)÷9=8(环),甲队员成绩的方差=110×[(6-8)2+3×(7-8)2+2×(8-8)3+3×(9-8)2+(10-8)2]=1.4;乙队员成绩的方差=110×[(6-8)2+2×(7-8)2+4×(8-8)3+2×(9-8)2+(10-8)2]=1.2,综上可知甲、乙的中位数相同,平均数相同,甲的方差大于乙的方差,故选D.【点睛】本题考查了平均数、中位数和方差的定义和公式,熟练掌握平均数、中位数、方差的计算是解题的关键.12.C解析:C【解析】【分析】众数是一组数据中出现次数最多的数据,中位数是将一组数据按大小依次排列,把处在最中间位置的一个数据或者最中间两个数据的平均数叫这组数据的中位数.本组数据中,把数据按照从大到小的顺序排列,最中间的两个数的平均数即为中位数.【详解】由统计表可知:体育锻炼时间最多的是5小时,故众数是5小时;统计表中是按从小到大的顺序排列的,最中间两个人的锻炼时间都是5小时,故中位数是5小时.故选C.【点睛】本题考查了确定一组数据的众数和中位数的能力.将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(最中间两个数的平均数),叫做这组数据的中位数.注意找中位数的时候一定要先排好顺序,然后再根据奇数和偶数个来确定中位数.如果数据有奇数个,则正中间的数字即为所求;如果是偶数,则找中间两位数的平均数.二、填空题13.2【分析】根据数据abc 的方差为2由方差为2可得出数据a+3b+3c+3的方差【详解】解:∵数据abc 的方差为2设平均数为m 则则数据a+3b+3c+3的平均数是m+3∴方差为:故答案为:2【点睛】本解析:2 【分析】根据数据a ,b ,c 的方差为2,由方差为2可得出数据a+3,b+3,c+3的方差. 【详解】解:∵数据a ,b ,c 的方差为2,设平均数为m ,则2222()()()23a mb mc m S -+-+-==,则数据a +3,b +3,c +3的平均数是m+3,∴方差为:2222(33)(33)(33)3a mb mc m S +--++--++--=222()()()23a mb mc m -+-+-==,故答案为:2. 【点睛】本题考查的是方差,熟记方差的定义是解答此题的关键.14.5【分析】根据用平均数的定义列出算式再进行计算即可得出答案【详解】解:∵数据234x6的平均数是4∴(2+3+4+x+6)÷5=4解得:x=5;故答案为:5【点睛】本题考查了平均数的概念平均数是指在解析:5 【分析】根据用平均数的定义列出算式,再进行计算即可得出答案. 【详解】解:∵数据2,3,4,x ,6的平均数是4, ∴(2+3+4+x+6)÷5=4, 解得:x=5; 故答案为:5. 【点睛】本题考查了平均数的概念.平均数是指在一组数据中所有数据之和再除以数据的个数.15.2【分析】先由平均数的公式计算出这组数的平均值再根据方差的公式S2=计算【详解】设这组数的平均值为则:∴方差S2=故答案为:2【点睛】本题考查的是方差:一般地设n 个数据x1x2…xn 的平均数为则方差解析:2 【分析】先由平均数的公式计算出这组数的平均值,再根据方差的公式S 2=()()()()22221231n x x x x x x x x n ⎡⎤-+-+-++-⎣⎦计算.【详解】设这组数的平均值为x ,则:1201205x -+++-==∴方差S 2=()()()()()222221020001020215⎡⎤--+-+-+-+--=⎣⎦⨯ 故答案为:2. 【点睛】本题考查的是方差:一般地设n 个数据x 1,x 2,…x n 的平均数为x ,则方差S 2=()()()()22221231n x x x x x x x x n ⎡⎤-+-+-++-⎣⎦,它反映了一组数据的波动大小,方差越大,波动性越大.16.2【分析】先根据平均数的定义求出x 然后运用方程公式求解即可【详解】解:根据题意得(3+4+5+x+6)=5×5解得:x =7则这组数据为34576的平均数为5所以这组数据的为s2=(3﹣5)2+(4﹣解析:2 【分析】先根据平均数的定义求出x ,然后运用方程公式求解即可. 【详解】解:根据题意得(3+4+5+x +6)=5×5, 解得:x =7,则这组数据为3,4,5,7,6的平均数为5, 所以这组数据的为s 2=15[(3﹣5)2+(4﹣5)2+(5﹣5)2+(7﹣5)2+(6﹣5)2]=2. 故答案为:2. 【点睛】本题考查了平均数的定义和方差公式,解答本题的关键是理解平均数的定义和掌握求方差的方法.17.甲班【分析】根据方差的意义(方差越小数据越稳定)进行判断【详解】∵=101=235∴<∴成绩较为整齐的是:甲班故答案是:甲班【点睛】本题考查了方差的意义方差是用来衡量一组数据波动大小的量方差越大表明解析:甲班 【分析】根据方差的意义(方差越小数据越稳定)进行判断. 【详解】∵2S 甲=101,2S 乙=235,∴2S 甲<2S 乙,∴成绩较为整齐的是:甲班. 故答案是:甲班. 【点睛】本题考查了方差的意义,方差是用来衡量一组数据波动大小的量,方差越大,表明这组数据偏离平均数越大,即波动越大,数据越不稳定;反之,方差越小,表明这组数据分布比较集中,各数据偏离平均数越小,即波动越小,数据越稳定.18.乙【分析】根据方差的定义方差越小数据越稳定即可得出答案【详解】该月份白菜价格最稳定的是乙市场;故答案为乙【点睛】本题考查了方差的意义方差是用来衡量一组数据波动大小的量方差越大表明这组数据偏离平均数越解析:乙 【分析】根据方差的定义,方差越小数据越稳定,即可得出答案. 【详解】2S 7.5=甲,2S 1.5乙=,2S 3.1=丙, 222S S S ∴>>甲乙丙,∴该月份白菜价格最稳定的是乙市场;故答案为乙. 【点睛】本题考查了方差的意义.方差是用来衡量一组数据波动大小的量,方差越大,表明这组数据偏离平均数越大,即波动越大,数据越不稳定;反之,方差越小,表明这组数据分布比较集中,各数据偏离平均数越小,即波动越小,数据越稳定.19.与【分析】根据方差的意义进行判断【详解】解:因为甲组的数据都相等没有波动而乙组数有波动所以s 甲2<s 乙2故答案为s 甲2<s 乙2【点睛】本题考查了方差:方差是反映一组数据的波动大小的一个量方差越大则平解析:2s 甲与2s <乙 【分析】根据方差的意义进行判断. 【详解】解:因为甲组的数据都相等,没有波动,而乙组数有波动, 所以s 甲2<s 乙2. 故答案为s 甲2<s 乙2. 【点睛】本题考查了方差:方差是反映一组数据的波动大小的一个量.方差越大,则平均值的离散程度越大,稳定性也越小;反之,则它与其平均值的离散程度越小,稳定性越好.20.04【解析】【分析】根据数据2334x 的平均数是3先利用平均数的计算公式可求出x 然后利用方差的计算公式进行求解即可【详解】∵数据2334x 的平均数是3∴∴∴故答案为【点睛】本题主要考查了平均数和方差解析:0.4 【解析】 【分析】根据数据2、3、3、4、x 的平均数是3,先利用平均数的计算公式可求出x ,然后利用方差的计算公式进行求解即可. 【详解】∵数据2、3、3、4、x 的平均数是3, ∴2334x 35++++=⨯, ∴x 3=,∴(2222221S [(33)(23)(33)(43)33)0.45⎤=⨯-+-+-+-+-=⎦, 故答案为0.4.【点睛】本题主要考查了平均数和方差的计算,解题的关键是熟练掌握平均数和方差的计算公式.三、解答题21.(1)50;见解析;(2)不一定;见解析;(3)728 【分析】(1)由总人数为100可得m 的值,从而补全图形; (2)根据中位数的定义判断即可得;(3)样本中成绩在80分以上(包括80分)占调查人数的161050+,因此利用样本估计总体的方法列出算式1610140050+⨯,求解可得结果. 【详解】解:(1)样本容量是:10÷20%=50. 70≤a <80的频数是50−4−8−16−10=12(人), 补全图形如下:(2)不一定是这些学生成绩的中位数.理由:将50名学生知识测试成绩从小到大排列,第25、26名的成绩都在分数段80≤a≤90中,他们的平均数不一定是85分,因为25、26的成绩的平均数才是整组数据的中位数.(3)全校1400名学生中成绩优秀的人数为:1610140072850+⨯=(人).【点睛】本题考查了条形统计图、用样本估计总体、统计量的选择,解答本题的关键是明确题意,找出所求问题需要的条件,利用数形结合的思想解答.22.(1)11.6吨,11吨,11吨;(2)约有350户.【分析】(1)根据平均数的计算公式、众数与中位数的定义即可得;(2)先求出月平均用水量不超过12吨的户数占比,再乘以500即可得.【详解】(1)这100个样本数据的平均数是1020114012101320141011.6100⨯+⨯+⨯+⨯+⨯=(吨),因为11吨出现的次数最多,所以众数是11吨,由中位数的定义得:将这100个样本数据按从小到大进行排序后,第50个和第51个数据的平均数即为中位数,则中位数是1111112+=(吨),故答案为:11.6吨,11吨,11吨;(2)月平均用水量不超过12吨的户数占比为204010100%70% 100++⨯=,则70%500350⨯=(户),答:500户家庭中月平均用水量不超过12吨的约有350户.【点睛】本题考查了平均数的计算公式、众数与中位数的定义、用样本估计总体,熟练掌握数据分析的相关知识是解题关键.23.(1)甲、乙六次测试成绩的方差分别是223S =甲,243S =乙;(2)甲【分析】(1)根据方差的定义,利用方差公式分别求出甲、乙的方差即可;(2)根据平均数相同,利用(1)所求方差比较,方差小的成绩稳定,即可得答案. 【详解】(1)甲、乙六次测试成绩的方差分别是:(222222212[(109)(99)(89)(89)(109)99)63S ⎤=⨯-+-+-+-+-+-=⎦甲, (222222214[(109)(109)(89)(109)(79)99)63S ⎤=⨯-+-+-+-+-+-=⎦乙, (2)推荐甲参加全国比赛更合适,理由如下: ∵两人的平均成绩相等, ∴两人实力相当;∵甲的六次测试成绩的方差比乙小, ∴甲发挥较为稳定,∴推荐甲参加比赛更合适. 故答案为:甲 【点睛】本题考查方差的求法及利用方差做决策,方差反映了一组数据的波动大小,方差越大,波动性越大,反之也成立;熟练掌握方差公式是解题关键. 24.(1)a=7,b=7.5,c=4.2;(2)派乙队员参赛,理由见解析 【分析】(1)根据加权平均数的计算公式,中位数的确定方法及方差的计算公式即可得到a 、b 、c 的值;(2)根据平均数、中位数、众数、方差依次进行分析即可得到答案. 【详解】 (1)5162748291712421a ⨯+⨯+⨯+⨯+⨯==++++,将乙射击的环数重新排列为:3、4、6、7、7、8、8、8、9、10,∴乙射击的中位数787.52b +==, ∵乙射击的次数是10次,∴2222222(37)(47)(67)2(77)3(87)(97)(107)c ⎡⎤=-+-+-+⨯-+⨯-+-+-⎣⎦=4.2;(2)从平均成绩看,甲、乙的成绩相等,都是7环;从中位数看,甲射中7环以上的次数小于乙;从众数看,甲射中7环的次数最多,而乙射中8环的次数最多;从方差看,甲的成绩比乙稳定,综合以上各因素,若派一名同学参加比赛的话,可选择乙参赛,因为乙获得高分的可能性更大. 【点睛】此题考查数据的统计计算,根据方程作出决策,掌握加权平均数的计算公式,中位数的计算公式,方差的计算公式是解题的关键. 25.(1)9.5,10;(2)9分,1分2;(3)乙 【分析】(1)根据中位数的定义求出最中间两个数的平均数;根据众数的定义找出出现次数最多的数即可;(2)先求出乙队的平均成绩,再根据方差公式进行计算;(3)先比较出甲队和乙队的方差,再根据方差的意义即可得出答案. 【详解】(1)把甲队的成绩从小到大排列为:7,7,8,9,9,10,10,10,10,10,最中间两个数的平均数是(9+10)÷2=9.5(分),则中位数是9.5分;乙队成绩中10出现了4次,出现的次数最多,则乙队成绩的众数是10分; 故答案为:9.5,10; (2)乙队的平均成绩是:()104827939110⨯+⨯++⨯=⨯(分), 则方差是:()()()()22224109211089793991⎡⎤⨯-+⨯-+-+⨯-=⎣⎦⨯(分2) ;(3)∵甲队成绩的方差是1.4,乙队成绩的方差是1, ∴成绩较为整齐的是乙队; 故答案为:乙. 【点睛】本题考查方差、中位数和众数:中位数是将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(或最中间两个数的平均数),一般地设n 个数据x 1,x 2,…x n 的平均数为x ,则方差S 2=()()()()22221231n x x x x x x x x n ⎡⎤-+-+-++-⎣⎦,它反映了一组数据的波动大小,方差越大,波动性越大.26.(1)平均数:6150元;中位数:3200元;(2)乙推断比较科学合理,答案见解析. 【分析】(1)要求平均数只要求出各个数据之和再除以数据个数即可;对于中位数,因图中是按从小到大的顺序排列的,所以只要找出最中间的一个数(或最中间的两个数)即可; (2)甲从员工平均工资水平的角度推断公司员工月收入,乙从员工中间工资水平的角度推断公司员工的收入; 【详解】 解:(1)平均数:450001180001100001550035000634001300011200026150111361112⨯+⨯+⨯+⨯+⨯+⨯+⨯+⨯=+++++++(元) 中位数:这组数据共有26个,第13 、14个数据分别为3400,3000,所以样本的中位数为:3400300032002+=(元) (2)甲:由样本平均数为6150元,估计全体员工的月平均收入大约为6150元;乙:由样本中位数为3200元,估计全体大约有一半的员工月收入超过3200元,有一半员工月收入不足3200元,乙推断比较科学合理.由题意可知,样本中的26名员工,只有3位员工的收入在6150以上,原因是该样本数据极差较大,所以平均数不能真实的反映实际情况. 【点睛】本题考查的知识点是平均数与中位数,掌握平均数与中位数的求法是解此题的关键.。
数据的分析姓名一、选择题:1.数据0、1、2、3、x的平均数是2,则这组数据的方差是()A.2 B C.10 D2.一城市准备选购一千株高度大约为2m的某种风景树来进行街道绿化,有四个苗圃生产基地投标(单株树的价格都一样).采购小组从四个苗圃中都任意抽查了20株树苗的高度,得到的数据如下:请你帮采购小组出谋划策,应选购( )A.甲苗圃的树苗B.乙苗圃的树苗;C.丙苗圃的树苗D.丁苗圃的树苗3.将一组数据中的每一个数减去50后,所得新的一组数据的平均数是2,则原来那组数据的平均数是()A.50 B.52 C.48 D.24.一个射手连续射靶22次,其中3次射中10环,7次射中9环,9次射中8环,3次射中7环.则射中环数的中位数和众数分别为()A.8,9 B.8,8 C.8.5,8 D.8.5,95.为鼓励市民珍惜每一滴水,某居委会表扬了100个节约用水模范户,8月份节约用水的情况如下表:那么,8月份这100户平均节约用水的吨数为(精确到0。
01t)()A.1.5t B.1。
20t C.1。
15t D.1t6.已知一组数据-2,—2,3,-2,-x,-1的平均数是-0。
5,•那么这组数据的众数与中位数分别是( )A.-2和3 B.—2和0.5 C.—2和-1 D.—2和—1。
57.方差为2的是()A.1,2,3,4,5 B.0,1,2,3,5C.2,2,2,2,2 D.2,2,2,3,38.对于数据3,3,2,3,6,3,10,3,6,3,2.①这组数据的众数是3;②这组数据的众数与中位数的数值不等;③这组数据的中位数与平均数的数值相等;④这组数据的平均数与众数的数值相等,其中正确的结论有()9.某校把学生的纸笔测试、实践能力、成长纪录三项成绩分别按50%、20%、30%的比例计入学期总评成绩,90分以上为优秀.甲、乙、丙三人的各项成绩如下表(单位:分),学期总评成绩优秀的是()纸笔测试实践能力成长记录甲90 83 95乙98 90 95丙80 88 90A.甲B.乙丙C.甲乙D.甲丙10.甲、乙两班举行电脑汉字输入速度比赛,参赛学生每分钟输入汉字的个数经统计计算后结果如下表:班级参加人数中位数方差平均数甲55 149 191 135乙55 151 110 135某同学根据上表分析得出如下结论:(1)甲、乙两班学生成绩的平均水平相同;(2)乙班优秀的人数多于甲班优秀的人数;(每分钟输入汉字≥150个为优秀)(3)甲班成绩的波动情况比乙班成绩的波动小上述结论中正确的是()A.(1)(2)(3)B.(1)(2)C.(1)(3)D.(2)(3)二、填空题11.下图是根据某地近两年6月上旬日平均气温情况绘制的折线统计图,通过观察图形,可以判断这两年6月上旬气温比较稳定的年份是_____年.12.某学校把学生的纸笔测试、实践能力两项成绩分别按60%、40%的比例计入学期总成绩.小明实践能力这一项成绩是81分,若想学期总成绩不低于90分,则纸笔测试的成绩至少是分.13.在演唱比赛中,8位评委给一名歌手的演唱打分如下:9.3,9.5,9。
第五章习题
1.习题5.1
解:假定两总体服从正态分布,且协方差矩阵21∑=∑,误判损失相同又先验概
即:0.4285711=P 0.571422=P 又计算可得:
(1)(2)25.31622.025,2.416 1.187x x ⎡⎤⎡⎤==--⎢⎥⎢⎥⎣⎦⎣⎦
并且:-2.38145ln =S 计算广义平方距离函数:
2()1()
()()()ln 2ln j T j j j
j j d p -=--+-x x x S x x S 并计算后验概率:
22
2
ˆˆ0.5()0.5()1
ˆ(|)e e j
k d d j
k P G --==∑x x x 1,2j =
回代判别结果如下:
由此可见误判的回代估计:
0.07141/14*
==r P
若按照交叉确认法,定义广义平方距离如下:
2()1()
()()()()()()()ln 2ln j j j T j j x x x x j d p -=--+-x x x S x x S
逐个剔除, 交叉判别,后验概率按下式计算:
2
2
2
ˆˆ0.5()0.5()1
ˆ(|)e e j k d d j
k P G --==∑x x x 1,2j =
通过SAS 计算得到表所示结果。
发现同样也是属于G1的4号被误判为G2,因此误判率的交
叉确认估计为*
ˆ1/140.0714c p
==
*121p p p ΦΦ⎛⎫
=+- ⎪⎝⎭
其中(1)(2)1(1)(2)ˆ()()T λ
-=--x x S x x =12.1138, 2
1(1|2)ln
(2|1)c p d c p =,又因为(1|2)(2|1)c c c ==,所以288.0ln 1
2==P P d ,
最后可得后验概率p 为:0.048709
习题5.3
解:(1)在21∑≠∑并且先验概率相同的的假设前提下,建立矩离判别的线性判别函数。
利用SAS 的proc discrim 过程首先计算得到总体的协方差矩阵,如表:
各个总体的马氏平方距离见表:
8
765
432118
765
43211909.0465.13054.1581.400.263-702.03.0698.269-176.33030916.1578.9046.0670.5818.1389.0179.2006.71995.121x x x x x x x x W x x x x x x x x W ++++-++=++++--++-=
得到训练样本回判法判别结果如表:
(2)假设两总体服从正态分布,先验概率按比例分配且误判损失相同,在两总体协方差矩阵相同,即21∑=∑的条件下进行Bayes 判别分析,通过SAS discrim 过程得到结果:
在21∑≠∑,并且先验概率按比例分配的假设前提下利用SAS 的proc discrim 过程进行Bays 判别分析,这时以个总体的训练样本单独估计各总体的协方差矩阵,可到的训练样本的回判和交叉确认结果: 回判结果:
交叉确认判别结果:
(3)在不同的假设前提,采用不同判别方法得到待判样本的判别结果:
3在协方差不同矩阵相同的前提下,Bayes对西藏、上海、广东的判别结果:
3.习题5.4
解:(1)假设两总体服从正态分布且在两总体协方差矩阵相同,即21∑=∑,先验概率按相同的条件下进行Bayes 判别分析,通过SAS discrim 过程得到结果:
首先得到线性判别函数:
7
65
432117
65
43211259.0337.85065.01.395227.00.152-29.878-95.000312.0102.108589.0952.1789.0152.0351.308475.98x x x x x x x W x x x x x x x W --++-+=--+---+-=
回代误判结果:
交叉确认判别结果:由计算发现总共有四个样本被判错,分别是9、28、29、35号样品。
累计误判率为10.69%
(1)假设两总体服从正态分布且在两总体协方差矩阵相同,即21∑=∑,先验概率按比例分配且误判损失相同的条件下进行Bayes 判别分析,通过SAS discrim 过程得到结果: 首先得到线性判别函数:
回代误判结果。