编译原理--有限自动机
- 格式:ppt
- 大小:786.00 KB
- 文档页数:104


【编译原理】词法分析:正则表达式与有限⾃动机基础引⾔: 编译语⾔设计的精髓在于⾃动化过程,即如果要设计⼀门编程语⾔,那么⼀定要设计⼀个⾃动化系统,能够⾃⾏读⼊分析程序员写⼊的程序,将其翻译为机器能够识别的指令等信息。
当然⾼级语⾔的编译不是⼀蹴⽽就的,⽽是通过若⼲步的分解、规约、转换、优化,最后得到⽬标程序。
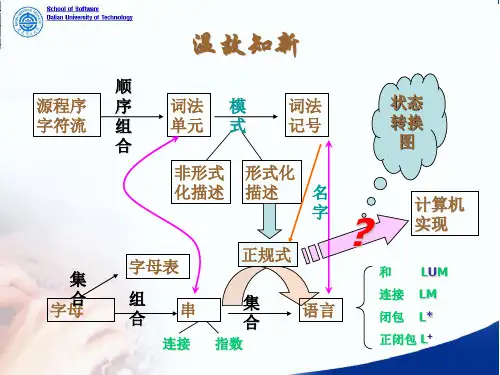
具体的编译步骤如下: 源程序就是我们写⼊的⾼级语⾔,编译的第⼀步叫做“词法分析”。
词法分析的本质,就是要拆解出语句的每⼀个单词,然后对这个单词的类型进⾏辨识。
⾸先拿中⽂来举例。
⽐如有⼀句话是“我喜欢你”,那么⾸先我们要把这句话拆成“我”、“喜欢”、“你”,然后再逐个分析他们的类型,得到“我”->主语;“喜欢”->谓语;“你”->宾语。
这样我们就把这句话每个单词都分析出来了,也就完成了中⽂的“词法分析”。
那么回到编程语⾔,它的词法分析就是将字符序列转换为单词(Token)序列的过程。
翻译成俗话,就是把我们写的⼤⽚语⾔⽂本分解为⼀个⼀个单词,再输出每个单词的类型。
举⼀个例⼦:int p = 3 + a; 这个语句⾮常简单,即定义⼀个变量p,它的初值为变量a与3的加和。
那么接下来我们要对这个语句进⾏词法分析,⾸先我们要把这段⽂本拆解成单词,拆出来就是'int'、'p'、'='、'3'、'+'、'a'、';'。
对这些单词再进⾏类型的辨识,那么就得到以下结果:语素语⾔类型int关键字p标识符=运算符3数字+运算符a标识符 这样我们就把这段⽂本中的每个单词的类型都分析出来了。
乍⼀看⾮常简单对不对,对于⼈类⽽⾔你只需要⽤⾁眼就可以轻松观察出来每个单词的类型,但对于计算机⽽⾔,它可没有⼈类那样的智能。
如果想要计算机能够识别并分析语素的类型,那就需要我们⼈类来为它构造⼀个⾃动化输⼊和分析的系统。

编译原理-题库1、关于有限自动机叙述正确的是()A、有限自动机分为确定的有限自动机和不确定的有限自动机B、有限自动机可由状态转换图表达C、有限自动机可由状态转换矩阵表达D、有限自动机可以识别正规集答案:ABCD2、编译原理各阶段的工作都涉及到()A、表格管理B、语法分析C、出错处理D、代码优化答案:AC3、程序语言一般分为()和()A、高级语言B、专用程序语言C、低级语言D、通用程序语言答案:AC4、高级语言的翻译方式有()和()A、汇编方式B、模拟方式C、解释方式D、编译方式答案:CD5、语法分析器的常用方法是()A、自顶向下B、自底向上C、自左向右D、自右向左答案:AB6、请说明你使用的语法分析方法()A、LL1B、OPGC、LRD、YACC答案:ABCD7、数据的逻辑结构有哪些()A、集合结构B、线性结构C、树形结构D、图形结构答案:ABCD8、NFA与DFA的不同之处()A、初态定义不同B、字母表定义不同C、转换函数定义不同D、终态定义不同答案:AC9、A、B、C、D、答案:A 10、A、B、C、D、答案:C 11、A、是B、不是C、无法判断D、可能答案:A12、A、上下文有关B、上下文无关C、正则D、0型答案:C13、A、B、C、D、答案:D14、A、B、C、D、答案:D15、LL(1)文法的充要条件是( )。
A、B、该文法对应的LL(1)分析表中每个项目最多只有一条产生式。
C、A和BD、都不是答案:B16、文法A->aAb|ab生成的语言是( )。
A、{ab}B、{aAb}C、D、答案:C17、以下说法中正确的是( )A、B、C、D、答案:B18、8. 正则式的“*”读作( )。
A、并且B、连接C、正则闭包D、闭包答案:D19、一个LR(0)文法一定是SLR(1)文法。
答案:正确20、在类型声明文法中,类型属性type是继承属性。
答案:正确21、在构造递归下降伪代码时,将非终结符A翻译为一个匹配过程match(A)。




nfa转换为dfa编译原理 c++有限自动机(NFA)和确定有限自动机(DFA)是计算机科学中有限状态自动机的两种形式。
NFA可以接受多个转移状态,而DFA则只能有一个转移状态。
NFA到DFA的转换是一个重要的编译原理问题。
以下是NFA转换为DFA的步骤:1. 确定NFA的开始状态和接受状态。
2. 对于每个输入符号,确定NFA的转换规则和转换后的状态。
3. 重复第二步,直到我们不能获得新的状态。
4. 标记DFA中的状态,即从NFA的多个状态中派生出的状态。
5. 为DFA添加开始状态和接受状态。
开始状态是NFA的开始状态的ε闭包。
6. 对于每个输入符号,使用NFA的转移规则来定义DFA中的转移。
7. 扫描DFA的状态表,并删除不可到达的状态。
下面是在C++中实现的NFA到DFA转换过程的伪代码://定义状态类class State{public:string name;unordered_map<char, set<string>> transitions;bool is_final_state;};//定义NFA类class NFA{public:State start_state;set<State> final_states;unordered_set<State> all_states;};//定义DFA类class DFA{public:State start_state;set<State> final_states;unordered_set<State> all_states;};//NFA转换为DFADFA ConvertToDFA(NFA nfa){//创建DFA对象DFA dfa;//确定开始状态dfa.start_state = nfa.start_state;//确定接受状态dfa.final_states = nfa.final_states;//添加开始状态到DFA的所有状态dfa.all_states.insert(dfa.start_state);while (有新的状态可以加入DFA){//从DFA中选择一个未标记的状态State current_state = 选择一个未标记的状态;for (每个输入符号a){//根据当前状态的a过渡创建新状态State new_state = 创建新状态;//从当前状态开始,获得状态a的ε闭包set<State> epsilon_closure = current_state.获取状态a的ε闭包;//通过NFA的规则从当前状态和ε闭包中跳转到新状态set<State> transition_states = 通过NFA规则从当前状态和ε闭包中跳转到新状态;//确定新状态是否应该成为DFA的接受状态bool is_final_state = 确定新状态应该成为DFA的接受状态;//设置新状态的属性new_ = 新状态的名称;new_state.transitions = 转移函数;new_state.is_final_state = is_final_state;//将状态添加到DFA中dfa.all_states.insert(new_state);}}return dfa;}这是将NFA转换为DFA的基本伪代码。



编译原理dfa编译原理DFA。
有限自动机(DFA)是编译原理中的重要概念,它在词法分析和语法分析中扮演着重要的角色。
在编译原理中,DFA用于识别和分析输入的字符序列,帮助编译器理解源代码的结构和含义。
本文将介绍DFA的基本概念、原理和应用,以及它在编译原理中的重要作用。
DFA的基本概念。
DFA是有限自动机(Deterministic Finite Automaton)的缩写,它是一种抽象的数学模型,用于描述有限个状态和在这些状态之间转移的输入字符序列。
DFA由五元组(Q, Σ, δ, q0, F)组成,其中:Q是有限状态集合;Σ是输入字符的有限集合;δ是状态转移函数,描述了状态之间的转移关系;q0是初始状态;F是接受状态集合。
DFA的原理。
DFA的工作原理是通过状态转移函数δ来识别和分析输入字符序列。
编译器将源代码转换为字符流,然后通过DFA进行词法分析,将字符流转换为标记流。
在词法分析过程中,DFA根据输入字符的转移关系,逐步从初始状态转移到接受状态,从而识别出源代码中的各种标记,如关键字、标识符、常量和运算符等。
DFA的应用。
DFA在编译原理中有着广泛的应用,它是词法分析器和语法分析器的核心组成部分。
在词法分析阶段,编译器利用DFA识别并提取源代码中的各种标记,为后续的语法分析和语义分析提供输入。
在语法分析阶段,DFA可以帮助编译器理解源代码的结构和语法,从而生成抽象语法树(AST)或中间代码。
此外,DFA还可以应用于模式匹配、文本搜索和自动机器人等领域。
在模式匹配和文本搜索中,DFA可以帮助我们快速地识别和匹配目标字符串;在自动机器人中,DFA可以帮助我们设计和实现自动化的决策系统。
DFA在编译原理中的重要作用。
在编译原理中,DFA是词法分析和语法分析的基础,它可以帮助编译器理解源代码的结构和含义。
通过DFA的识别和分析,编译器可以将源代码转换为抽象语法树(AST)或中间代码,为后续的优化和代码生成提供基础。
编译原理DFA(有限确定⾃动机)的构造原题:1、⾃⼰定义⼀个简单语⾔或者⼀个右线性正规⽂法⽰例如(仅供参考) G[S]:S→aU|bV U→bV|aQV→aU|bQ Q→aQ|bQ|e2、构造其有穷确定⾃动机,如3、利⽤有穷确定⾃动机M=(K,Σ,f, S,Z)⾏为模拟程序算法,来对于任意给定的串,若属于该语⾔时,该过程经有限次计算后就会停⽌并回答“是”,若不属于,要么能停⽌并回答“不是”K:=S;c:=getchar;while c<>eof do{K:=f(K,c);c:=getchar; };if K is in Z then return (‘yes’)else return (‘no’)开始编程!1.状态转换式构造类:current——当前状态next——下⼀状态class TransTile{public:char current;char next;char input;TransTile(char C,char I,char Ne){current = C;next = Ne;input = I;}};2.DFA的构造类此处包括DFA的数据集,字母表,以及过程P的定义。
包括了初始化,遍历转换,以及最终的字符串识别。
class DFA{public://构造状态集各个元素string States;char startStates;string finalStates;string Alphabets;vector <TransTile> Tile;DFA(){init();}void init(){cout << "输⼊有限状态集S:" << endl;cin >> States;cout << "输⼊字符集A:" << endl;cin >> Alphabets;cout << "输⼊状态转换式(格式为:状态-输⼊字符-下⼀状态,输⼊#结束):" << endl;cout << "例如:1a1 \n 1a0 \n 2a1 \n #" << endl;int h = 0;//while (cin>>input){// TransTile transval(input[0], input[1], input[2]);// Tile.push_back(transval);//}while(true){char input[4];cin>>input;if(strcmp(input,"#")==0)break;TransTile transval(input[0],input[1],input[2]);Tile.push_back(transval);}cout << "输⼊初态:" << endl;cin >> startStates;cout << "输⼊终态:" << endl;cin >> finalStates;}//遍历转换表char move(char P,char I){for (int i = 0; i < Tile.size(); i++){if (Tile[i].current == P&&Tile[i].input == I){return Tile[i].next;}}return'E';}//识别字符串函数void recognition(){string str;cout << "输⼊需要识别的字符串:" << endl;cin >> str;int i = 0;char current = startStates;while (i < str.length()){current = move(current, str[i]);if (current == 'E'){break;}i++;}if (finalStates.find(current) != finalStates.npos){cout << "该⾃动机识别该字符串!" << endl;}else{cout << "该⾃动机不能识别该字符串!" << endl;}}};3.测试Main函数int main(){DFA dfa;bool tag;while(1){cout<<"你想要继续吗?是请输⼊1,否输⼊0:"<<endl; cin>>tag;if(tag){dfa.recognition();}elsebreak;}return0;}。