springhibernatejpa联表查询复杂查询
- 格式:doc
- 大小:21.56 KB
- 文档页数:31

SpringDataJPA复杂多条件组合分页查询话不多说,请看代码:public Map<String, Object> getWeeklyBySearch(final Map<String, String> serArgs,String pageNum, String pageSize) throws Exception {// TODO Auto-generated method stubMap<String,Object> resultMap=new HashMap<String, Object>();// 判断分页条件pageNum = TextUtils.isNotBlank(pageNum) ? pageNum : "1";pageSize = TextUtils.isNotBlank(pageSize) ? pageSize : "10";// 分页时的总页数、每页条数、排序⽅式、排序字段Pageable StuPageable = PageUtils.buildPageRequest(Integer.valueOf(pageNum),Integer.valueOf(pageSize), new Sort(Direction.DESC, new String[] { "xmzbsj","lstProinfo.proId"})); // 按照条件进⾏分页查询,根据StuPageable的分页⽅式 Page<Weekly> StuPage = proWeeklyDao.findAll(new Specification<Weekly>() {public Predicate toPredicate(Root<Weekly> root, CriteriaQuery<?> query, CriteriaBuilder cb) {List<Predicate> lstPredicates = new ArrayList<Predicate>();if (TextUtils.isNotBlank(serArgs.get("xmmc"))) {lstPredicates.add(cb.like(root.get("lstProinfo").get("xmmc").as(String.class), "%" + serArgs.get("xmmc") + "%"));}if (TextUtils.isNotBlank(serArgs.get("xmzbqssj"))) {lstPredicates.add(cb.greaterThanOrEqualTo(root.get("xmzbsj").as(String.class),serArgs.get("xmzbqssj")));}if (TextUtils.isNotBlank(serArgs.get("xmzbjzsj"))) {lstPredicates.add(cb.lessThanOrEqualTo(root.get("xmzbsj").as(String.class),serArgs.get("xmzbjzsj")));}Predicate[] arrayPredicates = new Predicate[lstPredicates.size()];return cb.and(lstPredicates.toArray(arrayPredicates));}}, StuPageable); // 按照条件进⾏分页查询resultMap = PageUtils.getPageMap(StuPage);return resultMap;}buildPageRequest()⽅法,导⼊的包,下⾯是⾃⼰写的⽅法import org.springframework.data.domain.Page;import org.springframework.data.domain.PageRequest;import org.springframework.data.domain.Sort;import org.springframework.data.domain.Sort.Direction;* @param pageNum 当前页* @param pageSize 每页条数* @param sortType 排序字段* @param direction 排序⽅向*/public static PageRequest buildPageRequest(int pageNum, int pageSize, String sortType, String direction) {Sort sort = null;if (!TextUtils.isNotBlank(sortType)) {return new PageRequest(pageNum - 1, pageSize);} else if (TextUtils.isNotBlank(direction)) {if (Direction.ASC.equals(direction)) {sort = new Sort(Direction.ASC, sortType);} else {sort = new Sort(Direction.DESC, sortType);}return new PageRequest(pageNum - 1, pageSize, sort);} else {sort = new Sort(Direction.ASC, sortType);return new PageRequest(pageNum - 1, pageSize, sort);}} public static PageRequest buildPageRequest(int pageNum, int pageSize, String sortType) { return buildPageRequest(pageNum, pageSize, sortType, null); }getPageMap()⽅法:JPA的Page也是集合,获取Page集合⾥的值,最后获取到的这些(key,value)/*** 封装分页数据到Map中。

springdatajpa实现多条件查询(分页和不分页) ⽬前的spring data jpa已经帮我们⼲了CRUD的⼤部分活了,但如果有些活它⼲不了(CrudRepository接⼝中没定义),那么只能由我们⾃⼰⼲了。
这⾥要说的就是在它的框架⾥,如何实现⾃⼰定制的多条件查询。
下⾯以我的例⼦说明⼀下:业务场景是我现在有张订单表,我想要⽀持根据订单状态、订单当前处理⼈和订单⽇期的起始和结束时间这⼏个条件⼀起查询。
先看分页的,⽬前spring data jpa给我们做分页的Repository是PagingAndSortingRepository,但它满⾜不了⾃定义查询条件,只能另选JpaRepository。
那么不分页的Repository呢?其实还是它。
接下来看怎么实现: Repository:import com.crocodile.springboot.model.Flow;import org.springframework.data.domain.Page;import org.springframework.data.domain.Pageable;import org.springframework.data.jpa.domain.Specification;import org.springframework.data.jpa.repository.JpaRepository;import java.util.List;public interface FlowRepository extends JpaRepository<Flow, Long> {Long count(Specification<Flow> specification);Page<Flow> findAll(Specification<Flow> specification, Pageable pageable);List<Flow> findAll(Specification<Flow> specification);} Service:/*** 获取结果集** @param status* @param pageNo* @param pageSize* @param userName* @param createTimeStart* @param createTimeEnd* @return*/public List<Flow> queryFlows(int pageNo, int pageSize, String status, String userName, Date createTimeStart, Date createTimeEnd) {List<Flow> result = null;// 构造⾃定义查询条件Specification<Flow> queryCondition = new Specification<Flow>() {@Overridepublic Predicate toPredicate(Root<Flow> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {List<Predicate> predicateList = new ArrayList<>();if (userName != null) {predicateList.add(criteriaBuilder.equal(root.get("currentOperator"), userName));}if (status != null) {predicateList.add(criteriaBuilder.equal(root.get("status"), status));}if (createTimeStart != null && createTimeEnd != null) {predicateList.add(criteriaBuilder.between(root.get("createTime"), createTimeStart, createTimeEnd));}return criteriaBuilder.and(predicateList.toArray(new Predicate[predicateList.size()]));}};// 分页和不分页,这⾥按起始页和每页展⽰条数为0时默认为不分页,分页的话按创建时间降序try {if (pageNo == 0 && pageSize == 0) {result = flowRepository.findAll(queryCondition);} else {result = flowRepository.findAll(queryCondition, PageRequest.of(pageNo - 1, pageSize, Sort.by(Sort.Direction.DESC, "createTime"))).getContent();}} catch (Exception e) {LOGGER.error("--queryFlowByCondition-- error : ", e);}return result;} 上⾯我们可以看到,套路很简单,就是两板斧:先通过Specification对象定义好⾃定义的多查询条件,我这⾥的条件是当传了当前⽤户时,那么将它加⼊到查询条件中,不传该参数⾃然就不加,同理,传了订单状态的话那是通过相等来判断,最后,如果传了起始和结束时间,通过between来查在起始和结束之间的数据;第⼆板斧调⽤我们在Repository中定义好的findAll⽅法,如果分页就⽤带Pageable分页对象参数的⽅法,不分页不带该参数即可。

springdata-jpa⼋种查询⽅法使⽤:maven+Spring+jpa+Junit4查询⽅式:SQL,JPQL查询,Specification多条件复杂查询返回类型:list<POJO>,list<Stinrg>,list<Object>,Page<Object>1. Pom.xml<project xmlns="/POM/4.0.0" xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/POM/4.0.0 /maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.litblack</groupId><artifactId>SpringData_jpa</artifactId><packaging>war</packaging><version>0.0.1-SNAPSHOT</version><name>SpringData_jpa Maven Webapp</name><url></url><properties><spring.version>4.3.4.RELEASE</spring.version></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>3.8.1</version><scope>test</scope></dependency><!-- jpa --><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-core</artifactId><version>4.3.8.Final</version><exclusions><exclusion><groupId>org.javassist</groupId><artifactId>javassist</artifactId></exclusion></exclusions></dependency><!-- <dependency><groupId>org.hibernate.javax.persistence</groupId><artifactId>hibernate-jpa-2.0-api</artifactId><version>1.0.1.Final</version></dependency> --><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-entitymanager</artifactId><version>4.3.11.Final</version><exclusions><exclusion><groupId>org.javassist</groupId><artifactId>javassist</artifactId></exclusion></exclusions></dependency><!-- oracle --><dependency><groupId>ojdbc</groupId><artifactId>ojdbc6</artifactId><version>11.2.0.4</version></dependency><!-- mysql --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.6</version></dependency><!-- ali 数据源连接 --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.0.31</version></dependency><dependency><groupId>javassist</groupId><artifactId>javassist</artifactId><version>3.12.1.GA</version></dependency><!-- Test --><dependency><groupId>org.springframework</groupId><artifactId>spring-test</artifactId><version>${spring.version}</version><scope>test</scope></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-oxm</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-orm</artifactId><version>${spring.version}</version></dependency><!-- springdata --><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-jpa</artifactId><version>1.11.1.RELEASE</version></dependency><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-commons-core</artifactId><version>1.4.1.RELEASE</version></dependency></dependencies><build><finalName>SpringData_jpa</finalName></build></project>pom.xml2. Spring-config.xml<?xml version="1.0" encoding="UTF-8"?><beans xmlns="/schema/beans"xmlns:xsi="/2001/XMLSchema-instance" xmlns:context="/schema/context" xmlns:aop="/schema/aop" xmlns:tx="/schema/tx"xmlns:p="/schema/p" xmlns:cache="/schema/cache"xmlns:jpa="/schema/data/jpa"xsi:schemaLocation="/schema/beans/schema/beans/spring-beans-3.1.xsd/schema/context/schema/context/spring-context-3.1.xsd/schema/aop/schema/aop/spring-aop-3.1.xsd/schema/tx/schema/tx/spring-tx-3.1.xsd/schema/cache/schema/cache/spring-cache-3.1.xsd/schema/data/jpa/schema/data/jpa/spring-jpa.xsd/schema/data/repository/schema/data/repository/spring-repository-1.5.xsd"><context:component-scan base-package="com.litblack.jpa"></context:component-scan><!-- 配置Spring Data JPA扫描⽬录, repository 包 --><jpa:repositories base-package="com.litblack.jpa" /><!-- 定义实体管理器⼯⼚ --><bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"><property name="dataSource" ref="dataSource" /><!-- 扫描pojo --><property name="packagesToScan" value="com.litblack.jpa" /><property name="persistenceProvider"><bean class="org.hibernate.ejb.HibernatePersistence" /></property><property name="jpaVendorAdapter"><bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"><property name="generateDdl" value="true" /><property name="database" value="MYSQL" /><!-- <property name="database" value="ORACLE" /> --><!-- <property name="databasePlatform" value="org.hibernate.dialect.MySQL5InnoDBDialect" /> --><property name="showSql" value="true" /></bean></property><property name="jpaDialect"><bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect" /></property><property name="jpaPropertyMap"><map><entry key="hibernate.generate_statistics" value="false" /><!-- 关闭打印的⽇志 --><entry key="hibernate.query.substitutions" value="true 1, false 0" /><entry key="hibernate.default_batch_fetch_size" value="16" /><entry key="hibernate.max_fetch_depth" value="2" /><entry key="e_reflection_optimizer" value="true" /><entry key="e_second_level_cache" value="false" /><entry key="e_query_cache" value="false" /></map></property></bean><!-- 数据源 --><bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <property name="driverClassName" value="com.mysql.jdbc.Driver" /><property name="url" value="jdbc:mysql://localhost:3306/cyd?useUnicode=true&characterEncoding=UTF-8" /> <property name="username" value="root" /><property name="password" value="root" /></bean><!-- 配置事务管理器 --><bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager"><property name="entityManagerFactory" ref="entityManagerFactory" /></bean><!-- 启⽤ annotation事务 --><tx:annotation-driven transaction-manager="transactionManager" /></beans>Spring-config.xml3. UserBean.javapackage com.litblack.jpa;import java.util.Date;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.Id;import javax.persistence.Table;import org.hibernate.annotations.GenericGenerator;import ponent;@Table(name = "cyd_sys_user")@Entitypublic class UserBean {@Id@GeneratedValue(generator = "system_uuid")@GenericGenerator(name = "system_uuid", strategy = "uuid")private String id;@Column(name="user_name")private String userName;@Column(name="create_time")private Date createTime;public String getId() {return id;}public void setId(String id) {this.id = id;}public String getUserName() {return userName;}public void setUserName(String userName) {erName = userName;}public Date getCreateTime() {return createTime;}public void setCreateTime(Date createTime) {this.createTime = createTime;}@Overridepublic String toString() {return "UserBean [id=" + id + ", userName=" + userName + ", createTime=" + createTime + "]";}}POJO4. UserBeanRepository.javapackage com.litblack.jpa;import java.util.List;import java.util.Map;import org.springframework.data.domain.Page;import org.springframework.data.domain.Pageable;import org.springframework.data.jpa.repository.JpaRepository;import org.springframework.data.jpa.repository.JpaSpecificationExecutor;import org.springframework.data.jpa.repository.Query;/*** SQL,JPQL查询* 返回:list<POJO>,list<Stinrg>,list<Object>,Page<Object>* 不能返回MAP* @author chenyd* 2018年1⽉10⽇*/public interface UserBeanRepository extends JpaRepository<UserBean, Long>, JpaSpecificationExecutor<UserBean>{ UserBean findByUserName(String username);@Query("from UserBean where userName =?1")List<UserBean> find_Jpql_list_obj(String username);@Query("select userName from UserBean where userName =?1")List<String> find_Jpql_list_one(String username);@Query("select userName,createTime from UserBean where userName =?1")List<Object> find_Jpql_list_morefield(String username);@Query("select userName,createTime from UserBean ")List<Object> find_Jpql_list_pojo_morefield();/*** 若返回类型为POJO,必须是所有POJO的所有字段,不能只查询某个字段*/@Query(value="select * from cyd_sys_user",nativeQuery=true)List<UserBean> find_SQL_pojo();@Query(value="select user_name,name from cyd_sys_user,t_user",nativeQuery=true)List<Object> find_SQL_obj(); @Query(value = "select new map(userName,createTime) from UserBean")List<Map<String,Object>> find_SQL_obj_map();/*** 分页需要 #pageable 标识* NativeJpaQuery* @param pageable* @return*/@Query(value="select user_name,name from cyd_sys_user,t_user /*#pageable*/ ",countQuery="select count(*) from cyd_sys_user,t_user",nativeQuery=true) Page<Object> find_SQL_obj(Pageable pageable);}5. BaseJunit4Test.javapackage com.litblack.jpa;import java.util.Date;import java.util.List;import java.util.Map;import javax.persistence.criteria.CriteriaBuilder;import javax.persistence.criteria.CriteriaQuery;import javax.persistence.criteria.Expression;import javax.persistence.criteria.Order;import javax.persistence.criteria.Predicate;import javax.persistence.criteria.Root;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.domain.Page;import org.springframework.data.domain.PageRequest;import org.springframework.data.domain.Pageable;import org.springframework.data.domain.Sort;import org.springframework.data.domain.Sort.Direction;import org.springframework.data.jpa.domain.Specification;import org.springframework.test.context.ContextConfiguration;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration(locations = { "classpath*:/spring-config.xml" })public class BaseJunit4Test {@Autowiredprivate UserBeanRepository userRepository;/*** 保存*/public void save_obj() {System.out.println(userRepository);for (int i = 0; i < 100; i++) {UserBean entity = new UserBean();entity.setUserName("user_" + i);entity.setCreateTime(new Date());userRepository.save(entity);}}/*** 查询-所有*/public void get_ALL_obj(){List<UserBean> list=userRepository.findAll();for (int i = 0; i < list.size(); i++) {UserBean obj = list.get(i);System.out.println(obj.getCreateTime());}}/*** 查询-one-obj,⾃定义接⼝*/public void get_one_obj(){UserBean obj = userRepository.findByUserName("user_1");System.out.println(obj.toString());}/*** 根据JQPL查询,获取⼀个包含所有字段的OBJ* 返回: ⼀个pojo 集合*/public void get_jqpl_obj(){List<UserBean> list=userRepository.find_Jpql_list_obj("user_2");for (int i = 0; i < list.size(); i++) {UserBean obj = list.get(i);System.out.println(obj.toString());}}/*** 根据JQPL查询,获取⼀个字段,* 返回:⼀个字段*/public void get_jqpl_onestr(){List<String> list=userRepository.find_Jpql_list_one("user_2");for (int i = 0; i < list.size(); i++) {String obj = list.get(i);System.out.println(obj.toString());}}/*** 根据JQPL查询,⼀⾏数据,获取多个字段* 返回:object 不是POJO,不是string[]。

springdatajpa关联查询(⼀对⼀、⼀对多、多对多) 在实际过往的项⽬中,常⽤的查询操作有:1、单表查询,2、⼀对⼀查询(主表和详情表)3、⼀对多查询(⼀张主表,多张⼦表)4、多对多查询(如权限控制,⽤户、⾓⾊多对多)。
做个总结,所以废话不多说。
使⽤idea构建springboot项⽬,引⼊依赖如下:dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>com.h2database</groupId><artifactId>h2</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies> 使⽤h2数据库做测试⽤,application.yml配置如下:spring:jpa:generate-ddl: truehibernate:ddl-auto: updateproperties:hibenate:format_sql: falseshow-sql: true ⾸先,⼀对⼀有好⼏种,这⾥举例的是常⽤的⼀对⼀双向外键关联(改造成单向很简单,在对应的实体类去掉要关联其它实体的属性即可),并且配置了级联删除和添加,相关类如下:package io.powerx;import lombok.*;import javax.persistence.*;/*** Created by Administrator on 2018/8/15.*/@Getter@Setter@Entitypublic class Book {@Id@GeneratedValueprivate Integer id;private String name;@OneToOne(cascade = {CascadeType.PERSIST,CascadeType.REMOVE})@JoinColumn(name="detailId",referencedColumnName = "id")private BookDetail bookDetail;public Book(){super();}public Book(String name){super(); =name;}public Book(String name, BookDetail bookDetail) {super(); = name;this.bookDetail = bookDetail;}@Overridepublic String toString() {if (null == bookDetail) {return String.format("Book [id=%s, name=%s, number of pages=%s]", id, name, "<EMPTY>");}return String.format("Book [id=%s, name=%s, number of pages=%s]", id, name, bookDetail.getNumberOfPages()); }}package io.powerx;import lombok.Getter;import lombok.Setter;import javax.persistence.*;@Getter@Setter@Entity(name = "BOOK_DETAIL")public class BookDetail {@Id@GeneratedValueprivate Integer id;@Column(name = "NUMBER_OF_PAGES")private Integer numberOfPages;@OneToOne(mappedBy = "bookDetail")private Book book;public BookDetail() {super();}public BookDetail(Integer numberOfPages) {super();this.numberOfPages = numberOfPages;}@Overridepublic String toString() {if (null == book) {return String.format("Book [id=%s, name=%s, number of pages=%s]", id, "<EMPTY>");}return String.format("Book [id=%s, name=%s, number of pages=%s]", id,book.getId(),book.getName());}}package io.powerx;import org.springframework.data.jpa.repository.JpaRepository;/*** Created by Administrator on 2018/8/15.*/public interface BookRepository extends JpaRepository<Book,Integer> {Book findByName(String name);}package io.powerx;import org.springframework.data.jpa.repository.JpaRepository;/*** Created by Administrator on 2018/8/15.*/public interface BookDetailRepository extends JpaRepository<BookDetail, Integer>{BookDetail findByNumberOfPages(Integer numberOfPages);}package io.powerx;import org.junit.After;import org.junit.Before;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.test.context.junit4.SpringRunner;import java.util.Arrays;import static org.junit.Assert.assertThat;@RunWith(SpringRunner.class)@SpringBootTestpublic class OnetooneApplicationTests {@Autowiredprivate BookRepository bookRepository;@Autowiredprivate BookDetailRepository bookDetailRepository;@Beforepublic void init() {Book bookA = new Book("Spring in Action", new BookDetail(208));Book bookB = new Book("Spring Data in Action", new BookDetail(235)); Book bookC = new Book("Spring Boot in Action");bookRepository.saveAll(Arrays.asList(bookA, bookB, bookC));}@Afterpublic void clear() {bookRepository.deleteAll();}@Testpublic void find() {Book book = bookRepository.findByName("Spring in Action");System.err.println(book.toString());}@Testpublic void save() {Book book = new Book("springboot");BookDetail bookDetail = new BookDetail(124);book.setBookDetail(bookDetail);bookRepository.save(book);}@Testpublic void delete() {bookRepository.deleteById(31);}@Testpublic void findbook(){BookDetail bd = bookDetailRepository.findByNumberOfPages(235);System.err.println(bd.toString());}} ⼀对多双向,相关类如下:package io.powerx;import lombok.Data;import lombok.Getter;import lombok.Setter;import javax.persistence.*;@Getter@Setter@Entitypublic class Book {@Id@GeneratedValueprivate Integer id;private String name;@ManyToOne@JoinColumn(name="publishId")private Publisher publisher;@Overridepublic String toString() {return "Book{" +"id=" + id +", name='" + name + '\'' +", publisher=" + publisher.getName() +'}';}public Book(String name) { = name;}public Book() {}}package io.powerx;import lombok.Data;import lombok.Getter;import lombok.Setter;import javax.persistence.*;import java.util.HashSet;import java.util.Set;/*** Created by Administrator on 2018/8/16.*/@Getter@Setter@Entitypublic class Publisher {@Id@GeneratedValueprivate Integer id;private String name;@OneToMany(cascade = CascadeType.ALL,fetch = FetchType.EAGER)@JoinColumn(name="publishId",referencedColumnName = "id")private Set<Book> books;public Publisher() {super();}public Publisher(String name) {super(); = name;}@Overridepublic String toString() {return "Publisher{" +"id=" + id +", name='" + name + '\'' +", books=" + books.size() +'}';}}package io.powerx;import org.springframework.data.jpa.repository.JpaRepository;/*** Created by Administrator on 2018/8/16.*/public interface BookRepository extends JpaRepository<Book,Integer>{Book findByName(String name);}package io.powerx;import org.springframework.data.jpa.repository.JpaRepository;/*** Created by Administrator on 2018/8/16.*/public interface PublisherRepository extends JpaRepository<Publisher,Integer> { Publisher findByName(String name);}package io.powerx;import org.junit.After;import org.junit.Before;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.test.context.junit4.SpringRunner;import java.util.HashSet;import java.util.Set;@RunWith(SpringRunner.class)@SpringBootTestpublic class OnetomanyApplicationTests {@Autowiredprivate PublisherRepository publisherRepository;@Autowiredprivate BookRepository bookRepository;@Beforepublic void init() {Book book1 = new Book("spring");Book book2 = new Book("mvc");Book book3 = new Book("mybatis");Publisher publisher = new Publisher("zhonghua");Set<Book> set = new HashSet<Book>();set.add(book1);set.add(book2);set.add(book3);publisher.setBooks(set);publisherRepository.save(publisher);}@Afterpublic void clear() {publisherRepository.deleteAll();}@Testpublic void find() {Publisher publisher = publisherRepository.findByName("zhonghua"); System.out.println(publisher);}@Testpublic void find2() {Book book = bookRepository.findByName("mvc");System.out.println(book);}} 多对多双向,相关代码如下:package io.powerx;import lombok.Getter;import lombok.Setter;import lombok.ToString;import javax.persistence.*;import java.util.Set;@Getter@Setter@Entitypublic class Author {@Id@GeneratedValueprivate Integer id;private String name;@ManyToMany(mappedBy = "authors",fetch = FetchType.EAGER) private Set<Book> books;public Author() {super();}public Author(String name) {super(); = name;}@Overridepublic String toString() {return "Author{" +"id=" + id +", name='" + name + '\'' +", books=" + books.size() +'}';}}package io.powerx;import lombok.Getter;import lombok.Setter;import lombok.ToString;import javax.persistence.*;import java.util.HashSet;import java.util.Set;@Getter@Setter@Entitypublic class Book {@Id@GeneratedValueprivate Integer id;private String name;@ManyToMany(cascade = CascadeType.ALL,fetch = FetchType.EAGER)@JoinTable(name = "BOOK_AUTHOR", joinColumns = {@JoinColumn(name = "BOOK_ID", referencedColumnName = "ID")}, inverseJoinColumns = { @JoinColumn(name = "AUTHOR_ID", referencedColumnName = "ID")})private Set<Author> authors;public Book() {super();}public Book(String name) {super(); = name;this.authors = new HashSet<>();}public Book(String name, Set<Author> authors) {super(); = name;this.authors = authors;}@Overridepublic String toString() {return "Book{" +"id=" + id +", name='" + name + '\'' +", authors=" + authors.size() +'}';}}package io.powerx;import org.springframework.data.jpa.repository.JpaRepository;import java.util.List;public interface AuthorRepository extends JpaRepository<Author, Integer> {Author findByName(String name);List<Author> findByNameContaining(String name);}package io.powerx;import org.springframework.data.jpa.repository.JpaRepository;import java.util.List;public interface BookRepository extends JpaRepository<Book, Integer> {Book findByName(String name);List<Book> findByNameContaining(String name);} 在调试过程中,注意实体类的tostring⽅法的重写,避免相互引⽤;此外如果超过两张表的关联查询,建议使⽤⾃定义sql,建⽴相应的pojo来接收查询结果。

SpringHibernateJPA联表查询复杂查询今天刷⽹,才发现:1)如果想⽤hibernate注解,是不是⼀定会⽤到jpa的?是。
如果hibernate认为jpa的注解够⽤,就直接⽤。
否则会弄⼀个⾃⼰的出来作为补充。
2)jpa和hibernate都提供了Entity,我们应该⽤哪个,还是说可以两个⼀起⽤?Hibernate的Entity是继承了jpa的,所以如果觉得jpa的不够⽤,直接使⽤hibernate的即可正⽂:⼀、Hibernate VS Mybatis1、简介Hibernate对数据库结构提供了较为完整的封装,Hibernate的O/R Mapping实现了POJO 和数据库表之间的映射,以及SQL 的⾃动⽣成和执⾏。
程序员往往只需定义好了POJO 到数据库表的映射关系,即可通过Hibernate 提供的⽅法完成持久层操作。
程序员甚⾄不需要对SQL 的熟练掌握, Hibernate/OJB 会根据制定的存储逻辑,⾃动⽣成对应的SQL 并调⽤JDBC 接⼝加以执⾏。
iBATIS 的着⼒点,则在于POJO 与SQL之间的映射关系。
然后通过映射配置⽂件,将SQL所需的参数,以及返回的结果字段映射到指定POJO。
相对Hibernate“O/R”⽽⾔,iBATIS 是⼀种“Sql Mapping”的ORM实现2、开发对⽐Hibernate的真正掌握要⽐Mybatis来得难些。
Mybatis框架相对简单很容易上⼿,但也相对简陋些。
个⼈觉得要⽤好Mybatis还是⾸先要先理解好Hibernate。
针对⾼级查询,Mybatis需要⼿动编写SQL语句,以及ResultMap。
⽽Hibernate有良好的映射机制,开发者⽆需关⼼SQL 的⽣成与结果映射,可以更专注于业务流程3、系统调优对⽐Hibernate调优⽅案:1. 制定合理的缓存策略;2. 尽量使⽤延迟加载特性;3. 采⽤合理的Session管理机制;4. 使⽤批量抓取,设定合理的批处理参数(batch_size);5. 进⾏合理的O/R映射设计Mybatis调优⽅案:MyBatis在Session⽅⾯和Hibernate的Session⽣命周期是⼀致的,同样需要合理的Session管理机制。
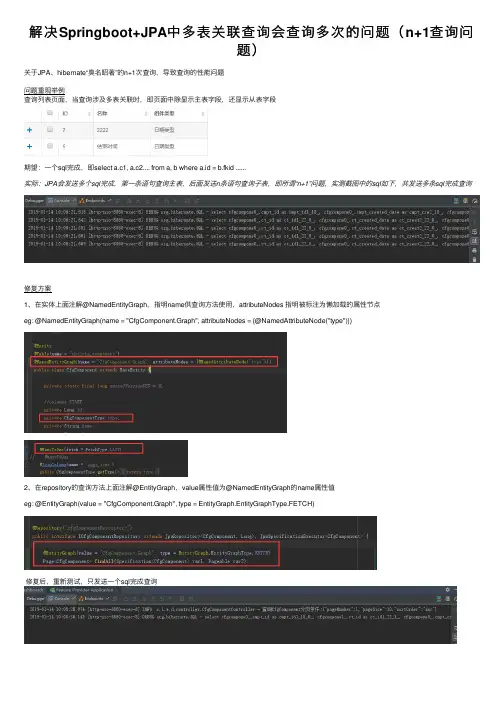
解决Springboot+JPA中多表关联查询会查询多次的问题(n+1查询问
题)
关于JPA、hibernate“臭名昭著”的n+1次查询,导致查询的性能问题
问题重现举例
查询列表页⾯,当查询涉及多表关联时,即页⾯中除显⽰主表字段,还显⽰从表字段
期望:⼀个sql完成,即select a.c1, a.c2.... from a, b where a.id = b.fkid ......
实际:JPA会发送多个sql完成,第⼀条语句查询主表,后⾯发送n条语句查询⼦表,即所谓“n+1”问题,实测截图中的sql如下,共发送多条sql完成查询
修复⽅案
1、在实体上⾯注解@NamedEntityGraph,指明name供查询⽅法使⽤,attributeNodes 指明被标注为懒加载的属性节点
eg: @NamedEntityGraph(name = "CfgComponent.Graph", attributeNodes = {@NamedAttributeNode("type")})
2、在repository的查询⽅法上⾯注解@EntityGraph,value属性值为@NamedEntityGraph的name属性值
eg: @EntityGraph(value = "CfgComponent.Graph", type = EntityGraph.EntityGraphType.FETCH)
修复后,重新测试,只发送⼀个sql完成查询。

Hibernate对多表关联查询由于公司项目的需要,我对Hibernate对多表关联查询研究了一下,现总结如下,供朋友参考。
一、Hibernate简介Hibernate是一个JDO工具。
它的工作原理是通过文件(一般有两种:xml文件和properties文件)把值对象和数据库表之间建立起一个映射关系。
这样,我们只需要通过操作这些值对象和Hibernate提供的一些基本类,就可以达到使用数据库的目的。
例如,使用Hibernate的查询,可以直接返回包含某个值对象的列表(List),而不必向传统的JDBC访问方式一样把结果集的数据逐个装载到一个值对象中,为编码工作节约了大量的时间。
Hibernate提供的HQL是一种类SQL语言,它和EJBQL 一样都是提供对象化的数据库查询方式,但HQL在功能和使用方式上都非常接近于标准的SQL.二、Hibernate与JDBC的区别Hibernate与JDBC的主要区别如下:1、Hibernate是JDBC的轻量级的对象封装,它是一个独立的对象持久层框架,和App Server,和EJB没有什么必然的联系。
Hibernate可以用在任何JDBC可以使用的场合,从某种意义上来说,Hibernate在任何场合下取代JDBC.2、Hibernate是一个和JDBC密切关联的框架,所以Hibernate的兼容性和JDBC驱动,和数据库都有一定的关系,但是和使用它的Java程序,和App Server没有任何关系,也不存在兼容性问题。
3、Hibernate是做为JDBC的替代者出现的,不能用来直接和Entity Bean做对比。
三、Hibernate 进行多表关联查询Hibernate对多个表进行查询时,查询结果是多个表的笛卡尔积,或者称为“交叉”连接。
例如:from Student,Book from Student as stu,Book as boo from Student stu,Book boo注意:让查询中的Student和Book均是表student和book对应的类名,它的名字一定要和类的名字相同,包括字母的大小写。

Hibernate是典型的OPM工具,它将每一个物理表格(Table)映射成为对象(Object),这发挥了面向对象的优势,使设计和开发人员可以从面向对象的角度来进行对数据库的管理。
在设计到多表操作时,Hibernate提供了与数据库表关系相对应的对象映射关系,一对一、一对多和多对多在这里都可以通过Hibernate的对象映射关系(Set等)来实现。
这为一般情况下的数据库多表操作提供了便捷途径。
关于这方面的介绍已经很多,在这里不再复述。
但是,在有些情况下的多表操作,比如一个统计顾客在2005年的消费总金额的SQL操作如下:select , count(a.fee) mix(a.chargeBeginTime) max(a.chargeEndTime) from charge a, customer b where a.idCustomer = b.idCustomer and a.chargeBeginTime >='2005-01-01' and a.chargeEndTime < '2005-12-31' gourp by a.idCustomercustomer表和charge结构如下:customer表结构:+------------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+------------+-------------+------+-----+---------+-------+| IdCustomer | varchar(32) | | PRI | | || Name | varchar(30) | | | | |+------------+-------------+------+-----+---------+-------+charge表结构:+-----------------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-----------------+-------------+------+-----+---------+-------+| IdCharge | varchar(32) | | PRI | | || Fee | double | YES | | NULL | || ChargeTimeBegin | datetime | YES | | NULL | || ChargeTimeEnd | datetime | YES | | NULL | |+-----------------+-------------+------+-----+---------+-------+在Hibernate的自带文档中有类似下面的多表查询操作提示:“select new OjbectC(field1, field2,...) from ObjectA a, ObjectB b ...”,分析一下可以看出这个操作有两个缺点:1)必须声明并创建类ObjectC,根据Hibernate的特点,需要写一个ObjectC.hbm.XML 的PO映射,在只用到创建查询结果的新对象的时候,这个映射可以是个虚的,即可以没有一个真正的数据库表和ObjectC对应,但是这样的一个虚设的逻辑显然已经违背了Hibernate的思想初衷;2)这个办法只能查询出但条结果记录并只能创建单个的ObjectC对象,这是很局限的,因此在某些情况下根本不能使用(比如本例)。

Springdatajpa的使⽤与详解(复杂动态查询及分页,排序)⼀、使⽤Specification实现复杂查询(1)什么是SpecificationSpecification是springDateJpa中的⼀个接⼝,他是⽤于当jpa的⼀些基本CRUD操作的扩展,可以把他理解成⼀个spring jpa的复杂查询接⼝。
其次我们需要了解Criteria 查询,这是是⼀种类型安全和更⾯向对象的查询。
⽽Spring Data JPA⽀持JPA2.0的Criteria查询,相应的接⼝是JpaSpecificationExecutor。
⽽JpaSpecificationExecutor这个接⼝基本是围绕着Specification接⼝来定义的,Specification接⼝中只定义了如下⼀个⽅法:Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder cb);Criteria查询基本概念:Criteria 查询是以元模型的概念为基础的,元模型是为具体持久化单元的受管实体定义的,这些实体可以是实体类,嵌⼊类或者映射的⽗类。
CriteriaQuery接⼝:代表⼀个specific的顶层查询对象,它包含着查询的各个部分,⽐如:select 、from、where、group by、order by等注意:CriteriaQuery对象只对实体类型或嵌⼊式类型的Criteria查询起作⽤。
Root:代表Criteria查询的根对象,Criteria查询的查询根定义了实体类型,能为将来导航获得想要的结果,它与SQL查询中的FROM⼦句类似。
Root实例是类型化的,且定义了查询的FROM⼦句中能够出现的类型。
root代表查询的实体类,query可以从中得到root对象,告诉jpa查询哪⼀个实体类,还可以添加查询条件,还可以结合EntityManager对象得到最终查询的 TypedQuery对象。

SpringBootDataJPA关联表查询的⽅法SpringBoot Data JPA实现⼀对多、多对⼀关联表查询开发环境1. IDEA 2017.12. Java1.83. SpringBoot 2.04. MySQL5.X功能需求通过关联关系查询商店Store中所有的商品Shop,商店对商品⼀对多,商品对商店多对⼀,外键 store_id存在于多的⼀⽅。
使⽤数据库的内连接语句。
表结构tb_shoptb_store实体类,通过注解实现1.商店类Store.javapackage com.gaolei.Entity;import javax.persistence.*;import java.util.HashSet;import java.util.Set;/*** Created by GaoLei on 2018/6/25.*/@Entity@Table(name = "tb_store")public class Store {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Integer id;//商铺号private String name;//商铺姓名private String address;//商铺地址private int tel ;//商铺联系private String info;//商铺信息@OneToMany(cascade = CascadeType.ALL,mappedBy = "store")private Set<Shop> shops = new HashSet<Shop>();// 省略set()和get()⽅法;}商品类Shop.javapackage com.gaolei.Entity;import javax.persistence.*;import java.util.HashSet;import java.util.Set;/*** Created by GaoLei on 2018/6/25.*/@Entity@Table(name = "tb_shop")public class Shop {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Integer id ; //商品idprivate String name;//商品名private int price;// 商品价格private int num;//商品数量private String info;//商品信息@ManyToOne@JoinColumn(name = "store_id")//外键private Store store;// 省略set()和get()⽅法;}StoreDao.javaCrudRepository 接⼝继承于 Repository 接⼝,并新增了简单的增、删、查等⽅法。

第四章使用QueryDSL与SpringDataJPA实现多表关联查询对于业务逻辑复制的系统来说都存在多表关联查询的情况,查询的返回对象内容也是根据具体业务来处理的,我们本章主要是针对多表关联根据条件查询后返回单表对象,在下一章我们就会针对多表查询返回自定义的对象实体。
本章目标基于SpringBoot框架平台完成SpringDataJPA与QueryDSL多表关联查询返回单表对象实例,查询时完全采用QueryDSL语法进行编写。
构建项目我们使用idea工具先来创建一个SpringBoot项目,添加的依赖跟一致。
为了方便分离文章源码,我们创建完成后把第三章的application.yml配置文件以及pom.xml依赖内容复制到本章项目中(配置内容请参考第三章)。
创建数据表我们先来根据一个简单的业务逻辑来创建两张一对多关系的表,下面我们先来创建商品类型信息表,代码如下:-- ---------------------------- -- Table structure for good_types -- ---------------------------- D ROP TABLE IF EXISTS `good_types`; CREATE TABLE `good_types` ( `tgt_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键自增', `tgt_name` varchar(30) CHA RACTER SET utf8 DEFAULT NULL COMMENT '类型名称', `tgt_is_show` char(1) DEF AULT NULL COMMENT '是否显示', `tgt_order` int(2) DEFAULT NULL COMMENT '类型排序', PRIMARY KEY (`tgt_id`) ) ENGINE=MyISAM AUTO_INCREMENT=4 DEFA ULT CHARSET=latin1;接下来我们再来创建一个商品基本信息表,表结构如下代码所示:-- ---------------------------- -- Table structure for good_infos -- ---------------------------- D ROP TABLE IF EXISTS `good_infos`; CREATE TABLE `good_infos` ( `tg_id` int(11) NO T NULL AUTO_INCREMENT COMMENT '主键自增', `tg_title` varchar(50) CHARACT ER SET utf8 DEFAULT NULL COMMENT '商品标题', `tg_price` decimal(8,2) DEFAUL T NULL COMMENT '商品单价', `tg_unit` varchar(20) CHARACTER SET utf8 DEFAUL T NULL COMMENT '单位', `tg_order` varchar(255) DEFAULT NULL COMMENT '排序', `tg_type_id` int(11) DEFAULT NULL COMMENT '类型外键编号', PRIMARY KEY (`tg_id`), KEY `tg_type_id` (`tg_type_id`) ) ENGINE=MyISAM AUTO_INCREMENT=4 DEFAULT CHARSET=latin1;创建实体我们对应上面两张表的结构创建两个实体并添加对应的SpringDataJPA注解配置,商品类型实体如下所示:商品基本信息实体如下所示:构建QueryDSL查询实体创建控制器下面我们来创建一个控制器,我们在控制器内直接编写QueryDSL查询代码,这里就不去根据MVC模式进行编程了,在正式环境下还请大家按照MVC模式来编码。
JPA多条件复杂SQL动态分页查询概述 ORM映射为我们带来便利的同时,也失去了较⼤灵活性,如果SQL较复杂,要进⾏动态查询,那必定是⼀件头疼的事情(也可能是lz还没发现好的⽅法),记录下⾃⼰⽤的三种复杂查询⽅式。
环境springBootIDEA2017.3.4JDK8pom.xml<?xml version="1.0" encoding="UTF-8"?><project xmlns="/POM/4.0.0" xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/POM/4.0.0 /xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.6.RELEASE</version><relativePath/><!-- lookup parent from repository --></parent><groupId>com.xmlxy</groupId><artifactId>seasgame</artifactId><version>0.0.1-SNAPSHOT</version><name>seasgame</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!--数据库连接--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><!-- 热启动等 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><!--Java bean 实体--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><!--swagger2 API 测试⼯具 --><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.8.0</version></dependency><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger-ui</artifactId><version>2.8.0</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional></dependency><!--安全框架认证--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</artifactId></dependency><dependency><groupId>net.sf.json-lib</groupId><artifactId>json-lib</artifactId><version>2.2.2</version><classifier>jdk15</classifier></dependency><!--汉字转拼⾳--><dependency><groupId>com.belerweb</groupId><artifactId>pinyin4j</artifactId><version>2.5.1</version></dependency><!-- thymeleaf模板 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency><!--<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>移除嵌⼊式tomcat插件<exclusions><exclusion><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-tomcat</artifactId></exclusion></exclusions></dependency>--><dependency><groupId>javax.servlet</groupId><artifactId>javax.servlet-api</artifactId><version>3.1.0</version><scope>provided</scope></dependency></dependencies><packaging>war</packaging><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>1.8</source><target>1.8</target></configuration></plugin></plugins><finalName>seasgame</finalName><pluginManagement><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><encoding>${project.build.sourceEncoding}</encoding><source>1.7</source><target>1.7</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><configuration><testFailureIgnore>true</testFailureIgnore></configuration></plugin></plugins></pluginManagement></build></project>@Query当⼀个SQL较为复杂时,第⼀个想到的就是原⽣的SQL语句。
SpringDataJpA复杂查询实现⾃定义排序需求:列表页⾯实现按合同状态⾃定义排序private Specification<TblContractPre> whereClause(final TblContractPre entity) {return new Specification<TblContractPre>() {@Overridepublic Predicate toPredicate(Root<TblContractPre> root, CriteriaQuery<?> query, CriteriaBuilder cb) {List<Predicate> list = new ArrayList<Predicate>();if (entity.getId() != null) {list.add(cb.equal(root.get("id").as(Long.class), entity.getId()));}if ("1".equals(entity.getFrom())) {UserObject user = UserObjectHelper.currentUserObject();List<String> ids = DataUtil.findAuditByCurUser(user, WorkflowType.HB_CONTRACT_ONLINE);if (ids.isEmpty()) {list.add(root.get("id").as(Long.class).in(0));} else {list.add(root.get("id").as(Long.class).in(UtilPublic.strArrToListLong(ids.toArray(new String[] {}))));}}if (StringUtils.isNotBlank(entity.getHouseName())) {list.add(cb.like(root.get("houseName").as(String.class), "%" + entity.getHouseName() + "%"));}if (StringUtils.isNotBlank(entity.getDeedsn())) {list.add(cb.equal(root.get("deedsn").as(String.class), entity.getDeedsn()));}if (entity.getDeptId() != null) {list.add(root.get("deptId").as(Integer.class).in(DataUtil.findSubDeptIds(entity.getDeptId())));}if (StringUtils.isNotBlank(entity.getSalesmanName())) {list.add(cb.equal(root.get("salesmanName").as(String.class), entity.getSalesmanName()));}UserObject user = UserObjectHelper.currentUserObject();if (user != null) {if (user.isSales()) {list.add(cb.equal(root.get("salesmanName").as(String.class), user.getUserCode()));} else if (user.isBus()) {list.add(root.get("deptId").as(Integer.class).in(user.getDeptIdList()));}}if (entity.getContractStatus() != null) {list.add(cb.equal(root.get("contractStatus").as(Byte.class), entity.getContractStatus()));}if (StringUtils.isNotBlank(entity.getDateType())) {if (entity.getDeedsnStart() != null) {list.add(cb.greaterThanOrEqualTo(root.get(entity.getDateType()).as(Date.class), entity.getDeedsnStart())); }if (entity.getDeedsnEnd() != null) {list.add(cb.lessThanOrEqualTo(root.get(entity.getDateType()).as(Date.class), entity.getDeedsnEnd()));}}if (entity.getCompanyType() != null) {list.add(cb.equal(root.get("companyType").as(CompanyType.class), entity.getCompanyType()));}List<Order> orders = new ArrayList<>();orders.add(cb.asc(cb.selectCase().when(cb.equal(root.get("contractStatus").as(Byte.class), 2), 1).when(cb.equal(root.get("contractStatus").as(Byte.class), 4), 2).when(cb.equal(root.get("contractStatus").as(Byte.class), 1), 3).when(cb.equal(root.get("contractStatus").as(Byte.class), 3), 4).otherwise(10)));orders.add(cb.desc(root.get("createDate")));query.orderBy(orders);Predicate[] p = new Predicate[list.size()];return query.where(cb.and(list.toArray(p))).getGroupRestriction(); }};}。
springbootjpa表关联查询分组groupby去重使⽤jpa操作多张表进⾏关联查询时,有重复数据需要分组去重1)确定主表:将有重复数据的表格作为主表,表明关系public class AttendanceRuleTypeItem implements Serializable {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long itemId;private String name;private Integer code;private String dictionaryCode;@OneToMany@JoinColumn(name = "typesCode",referencedColumnName = "code")private List<AttendanceRuleModel> attendanceRules;}2.副表两张public class AttendanceRuleModel {@Id@GenericGenerator(name = "guid", strategy = "guid")@GeneratedValue(generator = "guid")private String id;//规则类型codeprivate Integer ruleCode;//请假类型codeprivate Integer typesCode;//扣罚天数codeprivate Integer resultNumberCode;private String rankName;@OneToOne@JoinColumn(name = "resultNumberCode", referencedColumnName = "code", insertable = false, updatable = false,foreignKey = @ForeignKey(value =ConstraintMode.NO_CONSTRAINT ))private AttendanceRuleTypeItem resultNumber;@OneToMany(cascade = {CascadeType.PERSIST,CascadeType.REFRESH,CascadeType.MERGE})@JoinColumn(name = "rule_id",referencedColumnName = "id",foreignKey = @ForeignKey(value =ConstraintMode.NO_CONSTRAINT ))private List<RelationAttendanceDepartment> departmentRelation;@OneToMany(cascade = {CascadeType.PERSIST,/*CascadeType.REMOVE,*/CascadeType.REFRESH})@JoinColumn(name = "attendance_rule_id",referencedColumnName = "id",foreignKey = @ForeignKey(value =ConstraintMode.NO_CONSTRAINT ))private List<RelationAttendanceRank> relationAttendanceRanks;}public class RelationAttendanceDepartment extends BaseEntity {@Id@GeneratedValue(generator = "guid")@GenericGenerator(strategy = "guid",name = "guid")private String ruleDeptId;@Column(name = "rule_id")private String ruleId;private Integer departmentId;public RelationAttendanceDepartment(Integer departmentId) {this.departmentId = departmentId;}public RelationAttendanceDepartment(String ruleId, Integer departmentId) {this.ruleId = ruleId;this.departmentId = departmentId;}}3)。
SpringBootJPA实现查询多值JPA是java Persistence API简称,中⽂名:java持久层API,JPA是JCP组织发布的J2EE标准之⼀1.创建DataSource连接池对象<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><!-- 数据库驱动 --><dependency><groupId>com.oracle</groupId><artifactId>ojdbc6</artifactId><version>11.2.0.3</version></dependency>2.在pom.xml中定义spring-boot-starter-data-jpa<!-- 定义spring-boot-starter-data-jpa --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>3.根据数据库表定义实体类package cn.xdl.entity;import java.io.Serializable;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.Id;import javax.persistence.Table;@Entity@Table(name="EMP") //通常和@Entity配合使⽤,只能标注在实体的class定义处,表⽰实体对应的数据库表的信息public class Emp implements Serializable{/****/private static final long serialVersionUID = 1L;@Id //定义了映射到数据库表的主键的属性,⼀个实体只能有⼀个属性被映射为主键置于getXxxx()前@Column(name="EMPNO") //name表⽰表的名称默认地,表名和实体名称⼀致,只有在不⼀致的情况下才需要指定表名 private Integer empno;@Column(name="ENAME")private String ename;@Column(name="JOB")private String job;@Column(name="MGR")private int mgr;public Integer getEmpno() {return empno;}public void setEmpno(Integer empno) {this.empno = empno;}public String getEname() {return ename;}public void setEname(String ename) {this.ename = ename;}public String getJob() {return job;}public void setJob(String job) {this.job = job;}public int getMgr() {return mgr;}public void setMgr(int mgr) {this.mgr = mgr;}@Overridepublic String toString() {return "Emp [empno=" + empno + ", ename=" + ename + ", job=" + job + ", mgr=" + mgr + "]"; }}4.定义Dao接⼝,继承JPA功能接⼝package cn.xdl.jpa;import org.springframework.data.jpa.repository.JpaRepository;import cn.xdl.entity.Emp;//JpaRepository:JPA资源库/*** 1.所有继承该接⼝的都被spring所管理,改接⼝作为标识接⼝,功能就是⽤来控制domain模型的 * 2.Spring Data可以让我们只定义接⼝,只要遵循spring data的规范,⽆需写实现类。
springdatajpaSpecification复杂查询+分页查询当Repository接⼝继承了JpaSpecificationExecutor后,我们就可以使⽤如下接⼝进⾏分页查询:/*** Returns a {@link Page} of entities matching the given {@link Specification}.** @param spec can be {@literal null}.* @param pageable must not be {@literal null}.* @return never {@literal null}.*/Page<T> findAll(@Nullable Specification<T> spec, Pageable pageable);结合jpa-spec可以很容易构造出Specification:public Page<Person> findAll(SearchRequest request) {Specification<Person> specification = Specifications.<Person>and().eq(StringUtils.isNotBlank(request.getName()), "name", request.getName()).gt(Objects.nonNull(request.getAge()), "age", 18).between("birthday", new Date(), new Date()).like("nickName", "%og%", "%me").build();return personRepository.findAll(specification, new PageRequest(0, 15));}单表查询确实很简单,但对复杂查询,就复杂上些了:public List<Phone> findAll(SearchRequest request) {Specification<Phone> specification = Specifications.<Phone>and().eq(StringUtils.isNotBlank(request.getBrand()), "brand", "HuaWei").eq(StringUtils.isNotBlank(request.getPersonName()), "", "Jack").build();return phoneRepository.findAll(specification);}这⾥主表是phone,使⽤了person的name做条件,使⽤⽅法是。
SpringDataJPA连表动态条件查询多表查询在spring data jpa中有两种实现⽅式,第⼀种是利⽤hibernate的级联查询来实现(使⽤较为复杂,查询不够灵活),第⼆种是使⽤原⽣sql查询。
JPA原⽣SQL连表查询@Repositorypublic class SqlQueryRepository implements BaseQueryRepository {private static final String COUNT_REPLACEMENT_TEMPLATE = "select count(%s) $5$6$7";/*** 匹配第三组,换成count(*),⽬前只⽤到simple*/private static final String SIMPLE_COUNT_VALUE = "$3*";/*** 复杂查询,count(主对象)*/private static final String COMPLEX_COUNT_VALUE = "$3$6";private static final Pattern COUNT_MATCH;private static final String IDENTIFIER = "[\\p{Alnum}._$]+";private static final String IDENTIFIER_GROUP = String.format("(%s)", IDENTIFIER);@PersistenceContextprivate EntityManager entityManager;// (select\s+((distinct )?(.+?)?)\s+)?(from\s+[\p{Alnum}._$]+(?:\s+as)?\s+)([\p{Alnum}._$]+)(.*)static {StringBuilder builder = new StringBuilder();// from as starting delimiterbuilder.append("(?<=from)");// at least one space separatingbuilder.append("(?: )+");// Entity name, can be qualified (anybuilder.append(IDENTIFIER_GROUP);// exclude possible "as" keywordbuilder.append("(?: as)*");// at least one space separatingbuilder.append("(?: )+");// the actual aliasbuilder.append("(\\w*)");builder = new StringBuilder();builder.append("(select\\s+((distinct )?(.+?)?)\\s+)?(from\\s+");builder.append(IDENTIFIER);builder.append("(?:\\s+as)?\\s+)");builder.append(IDENTIFIER_GROUP);builder.append("(.*)");COUNT_MATCH = compile(builder.toString(), CASE_INSENSITIVE);}/*** 封装原⽣sql分页查询,⾃动⽣成countSql** @param pageable 分页参数* @param querySql 查询sql,不包含排序* @param orderSql 排序sql* @param paramMap 参数列表* @param clazz 返回对象class* @param <T> 返回对象* @return PageImpl*/@Overridepublic <T> Page<T> queryPageable(String querySql, String orderSql, Map<String, Object> paramMap, Pageable pageable, Class<T> clazz) {String countSql = createCountQuery(querySql);Query countQuery = (Query)this.entityManager.createNativeQuery(countSql);Query query = (Query)this.entityManager.createNativeQuery(querySql + orderSql);// 设置参数if (paramMap != null && paramMap.size() > 0) {for (Map.Entry<String, Object> entry : paramMap.entrySet()) {countQuery.setParameter(entry.getKey(), entry.getValue());query.setParameter(entry.getKey(), entry.getValue());}}BigInteger totalCount = (BigInteger) countQuery.getSingleResult();query.setFirstResult((int) pageable.getOffset());query.setMaxResults(pageable.getPageSize());// 不使⽤hibernate转bean,存在数据类型问题//query.setResultTransformer(Transformers.aliasToBean(clazz));query.setResultTransformer(Transformers.ALIAS_TO_ENTITY_MAP);List<T> resultList = JSON.parseArray(JSON.toJSONString(query.getResultList(), SerializerFeature.WriteMapNullValue), clazz); return new PageImpl<>(resultList, pageable, totalCount.longValue());}/*** 根据查询sql⾃动⽣成countSql,正则匹配** @param sql 查询sql* @return countSql*/public String createCountQuery(String sql) {Matcher matcher = COUNT_MATCH.matcher(sql);return matcher.replaceFirst(String.format(COUNT_REPLACEMENT_TEMPLATE, SIMPLE_COUNT_VALUE));}}使⽤⽰例@Repositorypublic class UserInfoDaoImpl implements UserInfoNativeDao {@Autowiredprivate BaseQueryRepository baseQueryRepository;@Overridepublic Page<UserInfo> getUserInfoPageable(String userId, QueryObj queryObj, PageRequest pageable) {// 拼接查询sqlStringBuilder selectSql = new StringBuilder();selectSql.append("SELECT rc.xxx xxx, rc.yyy yyy ");selectSql.append("FROM table_a rs,table_b rc ");selectSql.append("WHERE er_id = :userId ");HashMap<String, Object> paramMap = new HashMap<>(16);paramMap.put("userId", userId);StringBuilder whereSql = new StringBuilder();// 企业名称模糊筛选if (StringUtils.isNotBlank(queryObj.getCompanyName())) {whereSql.append(" AND pany_name like :companyName ");paramMap.put("companyName", "%" + queryObj.getCompanyName() + "%");}// 风险类型筛选 inif (!CollectionUtils.isEmpty(queryObj.getRiskTypes())) {whereSql.append(" AND rc.risk_type in :riskType ");paramMap.put("riskType", queryObj.getRiskTypes());}// 添加排序String orderSql = " ORDER BY xxx desc, yyy desc ";String querySql = selectSql.append(whereSql).toString();return baseQueryRepository.queryPageable(querySql, orderSql, paramMap, pageable, UserInfo.class);}}。
Spring Hibernate JPA 联表查询复杂查询今天刷网,才发现:1)如果想用hibernate注解,是不是一定会用到jpa的?是。
如果hibernate认为jpa的注解够用,就直接用。
否则会弄一个自己的出来作为补充。
2)jpa和hibernate都提供了Entity,我们应该用哪个,还是说可以两个一起用?Hibernate的Entity是继承了jpa的,所以如果觉得jpa的不够用,直接使用hibernate的即可正文:一、Hibernate VS Mybatis1、简介Hibernate对数据库结构提供了较为完整的封装,Hibernate的O/R Mapping实现了POJO 和数据库表之间的映射,以及SQL 的自动生成和执行。
程序员往往只需定义好了POJO 到数据库表的映射关系,即可通过Hibernate 提供的方法完成持久层操作。
程序员甚至不需要对SQL 的熟练掌握,Hibernate/OJB 会根据制定的存储逻辑,自动生成对应的SQL 并调用JDBC 接口加以执行。
iBATIS 的着力点,则在于POJO 与SQL之间的映射关系。
然后通过映射配置文件,将SQL所需的参数,以及返回的结果字段映射到指定POJO。
相对Hibernate“O/R”而言,iBATIS 是一种“Sql Mapping”的ORM实现2、开发对比Hibernate的真正掌握要比Mybatis来得难些。
Mybatis 框架相对简单很容易上手,但也相对简陋些。
个人觉得要用好Mybatis还是首先要先理解好Hibernate。
针对高级查询,Mybatis需要手动编写SQL语句,以及ResultMap。
而Hibernate有良好的映射机制,开发者无需关心SQL的生成与结果映射,可以更专注于业务流程3、系统调优对比Hibernate调优方案:制定合理的缓存策略;尽量使用延迟加载特性;采用合理的Session管理机制;使用批量抓取,设定合理的批处理参数(batch_size);进行合理的O/R映射设计Mybatis调优方案:MyBatis在Session方面和Hibernate的Session生命周期是一致的,同样需要合理的Session管理机制。
MyBatis 同样具有二级缓存机制。
MyBatis可以进行详细的SQL优化设计。
SQL优化方面:Hibernate的查询会将表中的所有字段查询出来,这一点会有性能消耗。
Hibernate也可以自己写SQL来指定需要查询的字段,但这样就破坏了Hibernate开发的简洁性。
而Mybatis的SQL是手动编写的,所以可以按需求指定查询的字段。
Hibernate HQL语句的调优需要将SQL打印出来,而Hibernate的SQL被很多人嫌弃因为太丑了。
MyBatis的SQL是自己手动写的所以调整方便。
但Hibernate具有自己的日志统计。
Mybatis本身不带日志统计,使用Log4j进行日志记录。
4、缓存机制对比Hibernate缓存:Hibernate一级缓存是Session缓存,利用好一级缓存就需要对Session的生命周期进行管理好。
建议在一个Action操作中使用一个Session。
一级缓存需要对Session进行严格管理。
Hibernate二级缓存是SessionFactory级的缓存。
SessionFactory的缓存分为内置缓存和外置缓存。
内置缓存中存放的是SessionFactory对象的一些集合属性包含的数据(映射元素据及预定SQL语句等),对于应用程序来说,它是只读的。
外置缓存中存放的是数据库数据的副本,其作用和一级缓存类似.二级缓存除了以内存作为存储介质外,还可以选用硬盘等外部存储设备。
二级缓存称为进程级缓存或SessionFactory级缓存,它可以被所有session共享,它的生命周期伴随着SessionFactory的生命周期存在和消亡。
Mybatis缓存:MyBatis 包含一个非常强大的查询缓存特性,它可以非常方便地配置和定制。
MyBatis 3 中的缓存实现的很多改进都已经实现了,使得它更加强大而且易于配置。
默认情况下是没有开启缓存的,除了局部的session 缓存,可以增强变现而且处理循环依赖也是必须的。
要开启二级缓存,你需要在你的SQL 映射文件中添加一行:<cache/>字面上看就是这样。
这个简单语句的效果如下:映射语句文件中的所有select 语句将会被缓存。
映射语句文件中的所有insert,update 和delete 语句会刷新缓存。
缓存会使用Least Recently Used(LRU,最近最少使用的)算法来收回。
根据时间表(比如no Flush Interval,没有刷新间隔), 缓存不会以任何时间顺序来刷新。
缓存会存储列表集合或对象(无论查询方法返回什么)的1024 个引用。
缓存会被视为是read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
所有的这些属性都可以通过缓存元素的属性来修改。
5、总结Mybatis:小巧、方便、高效、简单、直接、半自动Hibernate:强大、方便、高效、复杂、绕弯子、全自动二、Hibernate & JPA1、JPA全称Java Persistence API,通过JDK 5.0注解或XML 描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
JPA的出现有两个原因:其一,简化现有Java EE和Java SE应用的对象持久化的开发工作;其二,Sun希望整合对ORM技术,实现持久化领域的统一。
JPA提供的技术:1)ORM映射元数据:JPA支持XML和JDK 5.0注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中;2)JPA 的API:用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发者从繁琐的JDBC 和SQL代码中解脱出来。
3)查询语言:通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。
2、JPA & Hibernate 关系JPA是需要Provider来实现其功能的,Hibernate就是JPA Provider中很强的一个。
从功能上来说,JPA现在就是Hibernate功能的一个子集。
可以简单的理解为JPA是标准接口,Hibernate是实现。
Hibernate主要是通过三个组件来实现的,及hibernate-annotation、hibernate-entitymanager 和hibernate-core。
1)hibernate-annotation是Hibernate支持annotation方式配置的基础,它包括了标准的JPA annotation以及Hibernate自身特殊功能的annotation。
2)hibernate-core是Hibernate的核心实现,提供了Hibernate所有的核心功能。
3)hibernate-entitymanager实现了标准的JPA,可以把它看成hibernate-core和JPA之间的适配器,它并不直接提供ORM的功能,而是对hibernate-core进行封装,使得Hibernate符合JPA的规范。
总的来说,JPA是规范,Hibernate是框架,JPA是持久化规范,而Hibernate实现了JPA。
三、JPA 概要1、概述JPA在应用中的位置如下图所示:JPA维护一个Persistence Context(持久化上下文),在持久化上下文中维护实体的生命周期。
主要包含三个方面的内容:ORM元数据。
JPA支持annotion或xml两种形式描述对象-关系映射。
实体操作API。
实现对实体对象的CRUD操作。
查询语言。
约定了面向对象的查询语言JPQL(Java Persistence Query Language。
JPA的主要API都定义在javax.persistence包中。
如果你熟悉Hibernate,可以很容易做出对应:org.hibernatejavax.persistence说明cfg.ConfigurationPersistence读取配置信息SessionFactoryEntityManagerFactory用于创建会话/实体管理器的工厂类SessionEntityManager提供实体操作API,管理事务,创建查询TransactionEntityTransaction管理事务QueryQuery执行查询2、实体生命周期实体生命周期是JPA中非常重要的概念,描述了实体对象从创建到受控、从删除到游离的状态变换。
对实体的操作主要就是改变实体的状态。
JPA中实体的生命周期如下图:New,新创建的实体对象,没有主键(identity)值Managed,对象处于Persistence Context(持久化上下文)中,被EntityManager管理Detached,对象已经游离到Persistence Context之外,进入Application DomainRemoved, 实体对象被删除3、实体关系映射(ORM)1)基本映射ClassTable@Entity@Table(name="tablename")propertycolumn–@Column(name = "columnname")propertyprimary key@Id@GeneratedValue 详见ID生成策略propertyNONE@Transient对象端数据库端annotion可选annotion2)映射关系JPA定义了one-to-one、one-to-many、many-to-one、many-to-many 4种关系。
对于数据库来说,通常在一个表中记录对另一个表的外键关联;对应到实体对象,持有关联数据的一方称为owning-side,另一方称为inverse-side。
为了编程的方便,我们经常会希望在inverse-side也能引用到owning-side的对象,此时就构建了双向关联关系。
在双向关联中,需要在inverse-side定义mappedBy属性,以指明在owning-side是哪一个属性持有的关联数据。
对关联关系映射的要点如下:关系类型Owning-SideInverse-Sideone-to-one@OneToOne@OneToOne(mappedBy="othersideName")one-to-many / many-to-one@ManyToOne@OneToMany(mappedBy="xxx")many-to-many@ManyToMany@ManyToMany(mappedBy ="xxx")其中many-to-many关系的owning-side可以使用@JoinTable声明自定义关联表,比如Book和Author之间的关联表:@JoinTable(name = "BOOKAUTHOR", joinColumns ={ @JoinColumn(name = "BOOKID", referencedColumnName = "id") }, inverseJoinColumns = { @JoinColumn(name = "AUTHORID", referencedColumnName = "id") })关联关系还可以定制延迟加载和级联操作的行为(owning-side和inverse-side可以分别设置):通过设置fetch=ZY 或fetch=FetchType.EAGER来决定关联对象是延迟加载或立即加载。