第三章 多元线性回归分析1
- 格式:doc
- 大小:902.50 KB
- 文档页数:14

简介多元线性回归分析是一种统计技术,用于评估两个或多个自变量与因变量之间的关系。
它被用来解释基于自变量变化的因变量的变化。
这种技术被广泛用于许多领域,包括经济学、金融学、市场营销和社会科学。
在这篇文章中,我们将详细讨论多元线性回归分析。
我们将研究多元线性回归分析的假设,它是如何工作的,以及如何用它来进行预测。
最后,我们将讨论多元线性回归分析的一些限制,以及如何解决这些限制。
多元线性回归分析的假设在进行多元线性回归分析之前,有一些假设必须得到满足,才能使结果有效。
这些假设包括。
1)线性。
自变量和因变量之间的关系必须是线性的。
2)无多重共线性。
自变量之间不应高度相关。
3)无自相关性。
数据集内的连续观测值之间不应该有任何相关性。
4)同质性。
残差的方差应该在自变量的所有数值中保持不变。
5)正态性。
残差应遵循正态分布。
6)误差的独立性。
残差不应相互关联,也不应与数据集中的任何其他变量关联。
7)没有异常值。
数据集中不应有任何可能影响分析结果的异常值。
多重线性回归分析如何工作?多元线性回归分析是基于一个简单的数学方程,描述一个或多个自变量的变化如何影响因变量(Y)的变化。
这个方程被称为"回归方程",可以写成以下形式。
Y = β0 + β1X1 + β2X2 + ... + βnXn + ε 其中Y是因变量;X1到Xn是自变量;β0到βn是系数;ε是代表没有被任何自变量解释的随机变化的误差项(也被称为"噪音")。
系数(β0到βn)表示当所有其他因素保持不变时(即当所有其他自变量保持其平均值时),每个自变量对Y的变化有多大贡献。
例如,如果X1的系数为0.5,那么这意味着当所有其他因素保持不变时(即当所有其他独立变量保持其平均值时),X1每增加一单位,Y就会增加0.5单位。
同样,如果X2的系数为-0.3,那么这意味着当所有其他因素保持不变时(即所有其他独立变量保持其平均值时),X2每增加一个单位,Y就会减少0.3个单位。



第三节 多元线性相关与回归分析一、标准的多元线性回归模型上一节介绍的一元线性回归分析所反映的是1个因变量与1个自变量之间的关系。
但是,在现实中,某一现象的变动常受多种现象变动的影响。
例如,消费除了受本期收入水平的影响外,还会受以往消费和收入水平的影响;一个工业企业利润额的大小除了与总产值多少有关外,还与成本、价格等有关。
这就是说,影响因变量的自变量通常不是一个,而是多个。
在许多场合,仅仅考虑单个变量是不够的,还需要就一个因变量与多个自变量的联系来进行考察,才能获得比较满意的结果。
这就产生了测定与分析多因素之间相关关系的问题。
研究在线性相关条件下,两个和两个以上自变量对一个因变量的数量变化关系,称为多元线性回归分析,表现这一数量关系的数学公式,称为多元线性回归模型。
多元线性回归模型是一元线性回归模型的扩展,其基本原理与一元线性回归模型相类似,只是在计算上比较麻烦一些而已。
限于本书的篇幅和程度,本节对于多元回归分析中与一元回归分析相类似的内容,仅给出必要的结论,不作进一步的论证。
只对某些多元回归分析所特有的问题作比较详细的说明。
多元线性回归模型总体回归函数的一般形式如下:t kt k t t u X X Y ++⋯++=βββ221 (7.51)上式假定因变量Y 与(k-1)个自变量之间的回归关系可以用线性函数来近似反映.式中,Y t 是变量Y 的第t个观测值;X jt 是第j 个自变量X j 的第t个观测值(j=1,2,……,k);u t 是随机误差项;β1,β2,… ,βk 是总体回归系数。
βj 表示在其他自变量保持不变的情况下,自变量X j 变动一个单位所引起的因变量Y 平均变动的数额,因而又叫做偏回归系数。
该式中,总体回归系数是未知的,必须利用有关的样本观测值来进行估计。
假设已给出了n个观测值,同时1ˆβ,2ˆβ…,k βˆ为总体回归系数的估计,则多元线性回归模型的样本回归函数如下:t kt k t t e X X Y ++⋯++=βββˆˆˆ221 (7.52)(t =1,2,…,n)式中,e t 是Y t 与其估计t Y ˆ之间的离差,即残差。

一、邹式检验(突变点检验、稳定性检验)1.突变点检验1985—2002年中国家用汽车拥有量(t y ,万辆)与城镇居民家庭人均可支配收入(t x ,元),数据见表。
表 中国家用汽车拥有量(t y )与城镇居民家庭人均可支配收入(t x )数据年份 t y (万辆) t x (元)年份 t y (万辆) t x (元)1985 1994 1986 1995 4283 1987 1996 1988 1997 1989 1998 1990 1999 5854 1991 2000 6280 1992 2001 19932002下图是关于t y 和t x 的散点图:从上图可以看出,1996年是一个突变点,当城镇居民家庭人均可支配收入突破元之后,城镇居民家庭购买家用汽车的能力大大提高。
现在用邹突变点检验法检验1996年是不是一个突变点。
:两个字样本(1985—1995年,1996—2002年)相对应的模型回归参数相等HH:备择假设是两个子样本对应的回归参数不等。
1在1985—2002年样本范围内做回归。
在回归结果中作如下步骤(邹氏检验):1、 Chow 模型稳定性检验(lrtest)用似然比作chow检验,chow检验的零假设:无结构变化,小概率发生结果变化* 估计前阶段模型* 估计后阶段模型* 整个区间上的估计结果保存为All* 用似然比检验检验结构没有发生变化的约束得到结果如下;(如何解释)2.稳定性检验(邹氏稳定性检验)以表为例,在用1985—1999年数据建立的模型基础上,检验当把2000—2002年数据加入样本后,模型的回归参数时候出现显著性变化。
* 用F-test作chow间断点检验检验模型稳定性* chow检验的零假设:无结构变化,小概率发生结果变化* 估计前阶段模型* 估计后阶段模型* 整个区间上的估计结果保存为All* 用F 检验检验结构没有发生变化的约束*计算和显示 F 检验统计量公式,零假设:无结构变化然后 dis f_test 则 得到结果;* F 统计量的临界概率然后 得到结果* F 统计量的临界值然后 得到结果(如何解释)二、似然比(LR )检验有中国国债发行总量(t DEBT ,亿元)模型如下:0123t t t t t DEBT GDP DEF REPAY u ββββ=++++其中t GDP 表示国内生产总值(百亿元),t DEF 表示年财政赤字额(亿元),t REPAY 表示年还本付息额(亿元)。


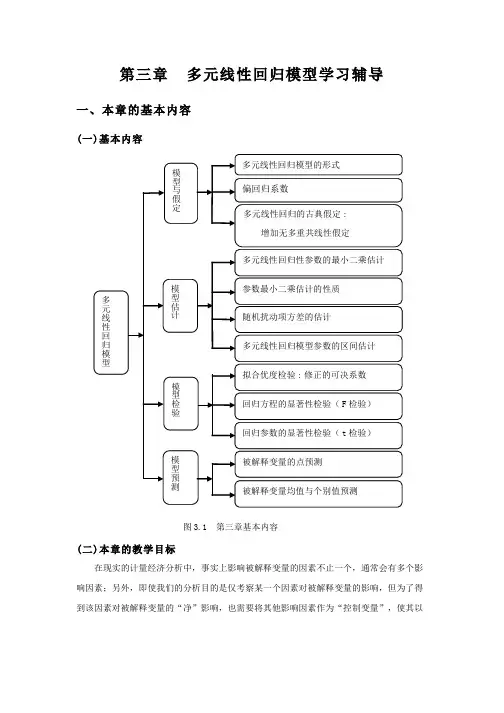
第三章 多元线性回归模型学习辅导一、本章的基本内容(一)基本内容图3.1 第三章基本内容(二)本章的教学目标在现实的计量经济分析中,事实上影响被解释变量的因素不止一个,通常会有多个影响因素;另外,即使我们的分析目的是仅考察某一个因素对被解释变量的影响,但为了得到该因素对被解释变量的“净”影响,也需要将其他影响因素作为“控制变量”,使其以显性形式出现在模型中,以提高模型估计精度。
因此,在对现实经济问题进行计量经济分析时,通常需要建立包含两个及两个以上解释变量的计量模型,此类模型称为多元回归模型。
多元回归模型是在简单回归模型理论基础上的扩展,其建模的理论基础、基本思路、模型估计等与一元回归模型基本一致,只是因解释变量增多,从而带来一些新的内容,比如模型整体显著性检验(F 检验)、修正的可决系数(2R )以及解释变量之间多重共线性等问题。
本章的教学目标是:深刻理解建立多元回归模型的目的;掌握多元线性回归模型估计、检验的理论与方法;熟练掌握多元线性回归EViews 输出结果的解释。
二、重点与难点分析1.对多元线性回归模型参数意义的理解多元线性回归模型的参数与简单线性回归模型的参数有重要区别。
在多元线性回归模型中,解释变量对应的参数是偏回归系数,表达的是控制其他解释变量不变的条件下,该解释变量的单位变动对被解释变量平均值的“净”影响。
为了更深刻理解偏回归系数,可以两个解释变量的多元线性回归模型为例加以说明1。
例如,被解释变量Y 与解释变量2X 和3X 都有关,如果分别建立模型:多元线性回归: 12233i i i i Y X X u b b b =+++简单线性回归 : 1221i i i Y a a X u =++由于Y 与3X 有关,可以作回归:1332i i i Y b b X u =++,若用OLS 估计其参数,并计算残差213333ˆˆˆi i i i i e Y b b X y b x =--=-,这里的2i e 表示除去3i X 影响后的i Y 。


第三章 多元线性回归模型一、名词解释1、多元线性回归模型:在现实经济活动中往往存在一个变量受到其他多个变量影响的现象,表现在线性回归模型中有多个解释变量,这样的模型被称做多元线性回归模型,多元是指多个解释变量2、调整的可决系数2R :又叫调整的决定系数,是一个用于描述多个解释变量对被解释变量的联合影响程度的统计量,克服了2R 随解释变量的增加而增大的缺陷,与2R 的关系为2211(1)1n R R n k -=----。
3、偏回归系数:在多元回归模型中,每一个解释变量前的参数即为偏回归系数,它测度了当其他解释变量保持不变时,该变量增加1单位对被解释变量带来的平均影响程度。
4、正规方程组:采用OLS 方法估计线性回归模型时,对残差平方和关于各参数求偏导,并令偏导数为0后得到的方程组,其矩阵形式为ˆX X X Y β''=。
5、方程显著性检验:是针对所有解释变量对被解释变量的联合影响是否显著所作的检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出判断。
二、单项选择题1、C :F 统计量的意义2、A :F 统计量的定义3、B :随机误差项方差的估计值1ˆ22--=∑k n e iσ4、A :书上P92和P93公式5、C :A 参看导论部分内容;B 在判断多重共线等问题的时候,很有必要;D 在相同解释变量情况下可以衡量6、C :书上P99,比较F 统计量和可决系数的公式即可7、A :书P818、D :A 截距项可以不管它;B 不考虑beta0;C 相关关系与因果关系的辨析 9、B :注意!只是在服从基本假设的前提下,统计量才服从相应的分布10、D :AB 不能简单通过可决系数判断模型好坏,还要考虑样本量、异方差等问题;三、多项选择题1、ACDE :概念性2、BD :概念性3、BCD :总体显著,则至少一个参数不为04、BC :参考可决系数和F 统计量的公式5、AD :考虑极端情况,ESS=0,可发现CE 错四、判断题、 1、√2、√3、×4、×:调整的可决系数5、√五、简答题 1、 答:多元线性回归模型与一元线性回归模型的区别表现在如下几个方面:一是解释变量的个数不同;二是模型的经典假设不同,多元线性回归模型比一元线性回归模型多了个“解释变量之间不存在线性相关关系”的假定;三是多元线性回归模型的参数估计式的表达更为复杂。
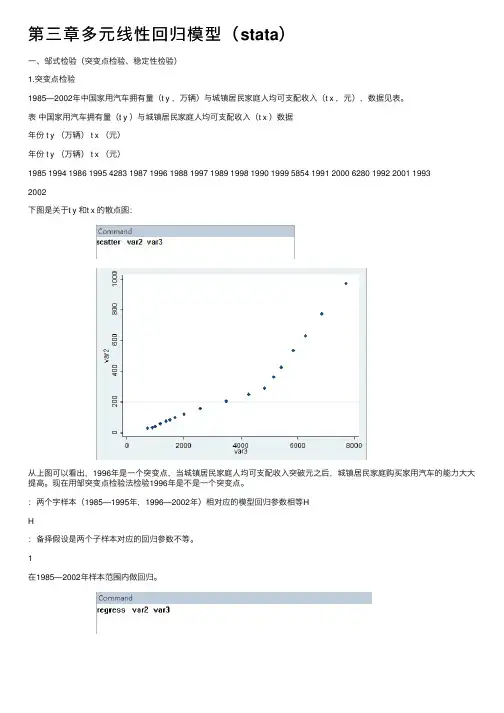
第三章多元线性回归模型(stata)⼀、邹式检验(突变点检验、稳定性检验)1.突变点检验1985—2002年中国家⽤汽车拥有量(t y ,万辆)与城镇居民家庭⼈均可⽀配收⼊(t x ,元),数据见表。
表中国家⽤汽车拥有量(t y )与城镇居民家庭⼈均可⽀配收⼊(t x )数据年份 t y (万辆) t x (元)年份 t y (万辆) t x (元)1985 1994 1986 1995 4283 1987 1996 1988 1997 1989 1998 1990 1999 5854 1991 2000 6280 1992 2001 19932002下图是关于t y 和t x 的散点图:从上图可以看出,1996年是⼀个突变点,当城镇居民家庭⼈均可⽀配收⼊突破元之后,城镇居民家庭购买家⽤汽车的能⼒⼤⼤提⾼。
现在⽤邹突变点检验法检验1996年是不是⼀个突变点。
:两个字样本(1985—1995年,1996—2002年)相对应的模型回归参数相等HH:备择假设是两个⼦样本对应的回归参数不等。
1在1985—2002年样本范围内做回归。
在回归结果中作如下步骤(邹⽒检验):1、 Chow 模型稳定性检验(lrtest)⽤似然⽐作chow检验,chow检验的零假设:⽆结构变化,⼩概率发⽣结果变化* 估计前阶段模型* 估计后阶段模型* 整个区间上的估计结果保存为All* ⽤似然⽐检验检验结构没有发⽣变化的约束得到结果如下;(如何解释)2.稳定性检验(邹⽒稳定性检验)以表为例,在⽤1985—1999年数据建⽴的模型基础上,检验当把2000—2002年数据加⼊样本后,模型的回归参数时候出现显著性变化。
* ⽤F-test作chow间断点检验检验模型稳定性* chow检验的零假设:⽆结构变化,⼩概率发⽣结果变化* 估计前阶段模型* 估计后阶段模型* 整个区间上的估计结果保存为All* ⽤F 检验检验结构没有发⽣变化的约束*计算和显⽰ F 检验统计量公式,零假设:⽆结构变化然后 dis f_test 则得到结果;* F 统计量的临界概率然后得到结果* F 统计量的临界值然后得到结果(如何解释)⼆、似然⽐(LR )检验有中国国债发⾏总量(t DEBT ,亿元)模型如下:0123t t t t t DEBT GDP DEF REPAY u ββββ=++++其中t GDP 表⽰国内⽣产总值(百亿元),t DEF 表⽰年财政⾚字额(亿元),t REPAY 表⽰年还本付息额(亿元)。
第三章 多元线性回归分析主要内容:⏹ 多元线性回归模型⏹ 多元线性回归模型的参数估计 ⏹ 多元线性回归模型的统计检验 ⏹ 多元线性回归模型的预测 ⏹ 案例3.1 多元线性回归模型一、多元线性回归模型多元线性回归模型:表现在线性回归模型中的解释变量有多个。
一般表现形式:i ki k i i i u X X X Y +++++=ββββ 22110 i=1,2,…,n其中:k 为解释变量的数目,j β称为回归参数(regression coefficient )。
ki k i i ki i i i X X X X X X Y E ββββ+⋅⋅⋅+++=2211021),,|(经济解释:j β也被称为偏回归系数,表示在其他解释变量保持不变的情况下,j X 每变化1个单位时,Y 的均值E(Y)的变化;或者说j β给出了j X 的单位变化对Y 均值的“直接”或“净”(不含其他变量)影响。
样本回归函数:用来估计总体回归函数i =1,2…,n其随机表示式:i e 称为残差或剩余项(residuals),可看成是总体回归函数中随机扰动项i u 的近似替代。
i ki ki i i i e X X X Y +++++=ββββˆˆˆˆ22110 ki ki i i i X X X Y ββββˆˆˆˆˆ22110++++=§3.2 多元线性回归模型的估计一、普通最小二乘估计对于随机抽取的n 组观测值对样本回归函数:i=1,2…n根据最小二乘原理,参数估计值应该是下列方程组的解∑∑∑===+⋅⋅⋅+++-=-==⎪⎪⎪⎪⎪⎪⎪⎩⎪⎪⎪⎪⎪⎪⎪⎨⎧=∂∂=∂∂=∂∂=∂∂ni kik i i i n i ni ii ik X X X Y Y Y e Q Q Q Q Q 12221101122210))ˆˆˆˆ(()ˆ(0ˆ0ˆ0ˆ0ˆββββββββ其中即 Y X X X '='βˆ)(由于X X '满秩,故有 Y X X X ''=-1)(ˆβ随机误差项μ的方差σ的无偏估计可以证明,随机误差项u 的方差的无偏估计量为二、参数估计量的性质在满足基本假设的情况下,其结构参数β的普通最小二乘估计、最大或然估计及矩估计仍具有:线性性、无偏性、有效性。
1、 线性CY Y X X X =''=-1)(ˆβ其中,C =X X X ''-1)( 为一仅与固定的X 有关的行向量 2、无偏性3、有效性(最小方差性)参数估计量βˆ的方差-协方差矩阵 βμX X X βμX βX X X Y X X X β11=''+=+''=''=---)()())()(())(()ˆ(1E E E E 11ˆ22--'=--=∑k n k n eie e σKi ki i i i X X X Y ββββˆˆˆˆˆ22110++++= kj n i X Y ji i ,2,1,0,,,2,1),,(==其中利用了 μβμββX X X X X X X Y X X X ''+=+''=''=---111)()()()(ˆ 和 I E 2)(σμμ='三、多元线性回归模型的参数估计实例 例题3.1Y : 某商品需求量 X1:该商品价格 X2:消费者平均收入下图(图3.1) Yˆ= 113.83 - 8.36 X 1 + 0.18 X 2 (4.0) (-3.6) (0.9)R 2 =0.88, F =26.4, n =10图3.1§3.3 多元线性回归模型的统计检验多元线性回归模型的基本假定假设1,解释变量是非随机的或固定的,且各X 之间互不相关(无多重共线性)。
假设2,随机误差项具有零均值、同方差及不序列相关性假设3,解释变量与随机项不相关假设4,随机项满足正态分布一、拟合优度检验1、可决系数与调整的可决系数记 2)(∑-=Y YT S S i总离差平方和2)ˆ(∑-=Y Y ESS i 回归平方和 2)ˆ(∑-=ii Y Y RSS 剩余平方和 则可决系数该统计量越接近于1,模型的拟合优度越高。
问题:在应用过程中发现,如果在模型中增加一个解释变量,2R 往往增大。
这就给人一个错觉:要使得模型拟合得好,只要增加解释变量即可。
但是,现实情况往往是,由增加解释变量个数引起的R2的增大与拟合好坏无关,R2需调整。
调整的可决系数(adjusted coefficient of determination ) 在样本容量一定的情况下,增加解释变量必定使得自由度减少,所以调整的思路是:将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响:)1/(T SS 1/(12----=n k n RSS R )其中:n-k -1为残差平方和的自由度,n -1为总体平方和的自由度。
2R 与2R 之间存在如下关系:11)1(122-----=k n n R RTSS RSSTSS ESS R -==12ESS RSS Y Y Y Y TSS ii i +=-+-=∑∑22)ˆ()ˆ(2222)ˆ()ˆ)(ˆ(2)ˆ())ˆ()ˆ(()(Y Y Y Y Y Y Y Y Y Y Y Y Y Y TSS i i i i i i ii i i -∑+--∑+-∑=-+-∑=-∑=二、方程的显著性检验(F 检验)方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。
1、方程显著性的F 检验 即检验模型i ki k i i i u X X X Y +++++=ββββ 22110 n i ,,2,1 =中的参数j β是否总体显著不为0。
可提出如下原假设与备择假设: H0:021====k βββ H1:j β不全为0F 检验的思想来自于总离差平方和的分解式:TSS=ESS+RSS如果这个比值较大,则X 的联合体对Y 的解释程度高,可认为总体存在线性关系,反之总体上可能不存在线性关系。
因此,可通过该比值的大小对总体线性关系进行推断。
在原假设0H 成立的条件下,统计量 )1/(/--=k n R S S kE S SF 服从自由度为(k , n -k -1)的F 分布。
给定显著性水平α,可得到临界值αF (k,n-k-1),由样本求出统计量F 的数值,通过F >αF (k,n-k-1) 或 F ≤αF (k,n-k-1)来拒绝或接受原假设0H ,以判定原方程总体上的线性关系是否显著成立。
2、关于拟合优度检验与方程显著性检验关系的讨论 由 )1/(T SS 1/(12----=n k n RSS R ) 与 )1/(/--=k n RSS kESS F可推出:kF k n n R +----=1112或 )1/()1(/22---=k n R kR F F 与2R 同向变化:当2R =0时间,F =0;2R 越大,F 值也越大;当2R =1时,F 为无穷大。
三、变量的显著性检验(t 检验)方程的总体线性关系显著≠每个解释变量对被解释变量的影响都是显著的因此,必须对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。
这一检验是由对变量的 t 检验完成的。
1、t 统计量由于12)()ˆ(-'=X X Cov σβ由于回归平方和∑=2ˆi yESS 是解释变量X 的联合体对被解释变量Y 的线性作用的结果,考虑比值∑∑=22ˆ/ii eyRSS ESS以ii c 表示矩阵1)(-'X X 主对角线上的第i 个元素,于是参数估计量的方差为:iic Var 2)ˆ(σβ= 其中2σ为随机误差项的方差,在实际计算时,用它的估计量代替:11ˆ22--'=--=∑k n ee k n eiσ易知βˆ服从如下正态分布 ),(~ˆ2iii i c N σββ 因此,可构造如下t 统计量)1(~1ˆˆˆ----'--=k n t k n ee c S t iii i i i iβββββ2、t 检验设计原假设与备择假设::0:10≠=i i H H ββ),,2,1(k i =给定显著性水平α,可得到临界值)1(2/--k n t α,由样本求出统计量t 的数值,通过|t|>)1(2/--k n t α 或 |t|≤)1(2/--k n t α来拒绝或接受原假设0H ,从而判定对应的解释变量是否应包括在模型中。
注意:一元线性回归中,t 检验与F 检验一致一方面,t 检验与F 检验都是对相同的原假设0:10=βH 进行检验; 另一方面,两个统计量之间有如下关系:看下一页图(例题3.1)四、参数的置信区间参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。
在变量的显著性检验中已经知道:)1(~1ˆˆˆ----'--=k n t k n ee c S t iii i i i iβββββ222212221222122212212ˆ)2(ˆ)2(ˆ)2(ˆ)2(ˆt x n e x n ex n e n e x n e yF i ii ii i i ii i=⎪⎪⎭⎫ ⎝⎛⋅-=⎪⎪⎪⎭⎫ ⎝⎛-=-=-=-=∑∑∑∑∑∑∑∑∑∑ββββ容易推出:在(1-α)的置信水平下i β的置信区间是其中,2/αt 为显著性水平为α 、自由度为n -k -1的临界值。
如何才能缩小置信区间?• 增大样本容量n ,因为在同样的样本容量下,n 越大,t 分布表中的临界值越小,同时,增大样本容量,还可使样本参数估计量的标准差减小;• 提高模型的拟合优度,因为样本参数估计量的标准差与残差平方和呈正比,模型优度越高,残差( , ) ββααββi i t s t s ii-⨯+⨯22平方和越小。
•提高样本观测值的分散度,一般情况下,样本观测值越分散,(X’X)-1的分母的|X’X|的值越大,致使区间缩小。
§3.4 多元线性回归模型的预测样本内10点与样本外1点预测小结⏹多元线性回归模型⏹多元线性回归模型的参数估计⏹多元线性回归模型的统计检验⏹多元线性回归模型的预测预测的评价指标例题3.1预测评价指标的应用建模过程中应注意的问题(1) 研究经济变量之间的关系要剔除物价变动因素。
注意:价格指数应该用定基价格指数。
(2) 依照经济理论以及对具体经济问题的深入分析初步确定解释变量。
例:我国粮食产量 = f (耕地面积、农机总动力、施用化肥量、农业人口等)。
5000100001500020000250003000080818283848586878889909192GDP GDP(f)例:关于食用油消费量模型(3) 当引用现成数据时,要注意数据的定义是否与所选定的变量定义相符。