西安电子科技大学考研复试编译原理复习
- 格式:ppt
- 大小:776.00 KB
- 文档页数:54
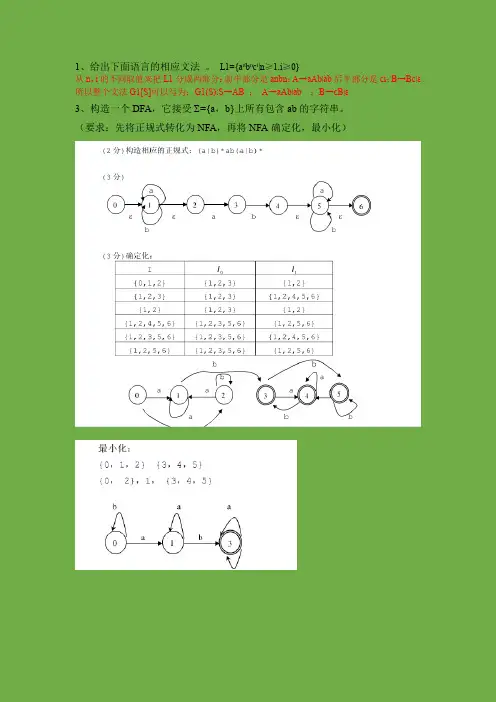
1、给出下面语言的相应文法。
L1={a n b n c i|n≥1,i≥0}从n,i的不同取值来把L1分成两部分:前半部分是anbn:A→aAb|ab后半部分是ci:B→Bc|ε所以整个文法G1[S]可以写为:G1(S):S→AB ;A→aAb|ab ;B→cB|ε3、构造一个DFA,它接受 ={a,b}上所有包含ab的字符串。
(要求:先将正规式转化为NFA,再将NFA确定化,最小化)4、对下面的文法G:E →TE’ E’→+E|ε T →FT’ T’→T|εF →PF’ F’ →*F’|ε P →(E)|a|b|∧(1)证明这个文法是LL(1)的。
(2)构造它的预测分析表。
(1)FIRST(E)={(,a,b,^}FIRST(E')={+,ε}FIRST(T)={(,a,b,^}FIRST(T')={(,a,b,^,ε} FIRST(F)={(,a,b,^}FIRST(F')={*,ε}FIRST(P)={(,a,b,^}FOLLOW(E)={#,)}FOLLOW(E')={#,)}FOLLOW(T)={+,),#}FOLLOW(T')={+,),#}FOLLOW(F)={(,a,b,^,+,),#} FOLLOW(F')={(,a,b,^,+,),#}FOLLOW(P)={*,(,a,b,^,+,),#} (2)考虑下列产生式:'→+'→'→'→E E T T F F P E a b ||*|()|^||εεεFIRST(+E)∩FIRST(ε)={+}∩{ε}=φ FIRST(+E)∩FOLLOW(E')={+}∩{#,)}=φ FIRST(T)∩FIRST(ε)={(,a,b,^}∩{ε}=φ FIRST(T)∩FOLLOW(T')={(,a,b,^}∩{+,),#}=φ FIRST(*F')∩FIRST(ε)={*}∩{ε}=φFIRST(*F')∩FOLLOW(F')={*}∩{(,a,b,^,+,),#}=φ FIRST((E))∩FIRST(a) ∩FIRST(b) ∩FIRST(^)=φ 所以,该文法式LL(1)文法. (3)+ * ( ) a b ^ # EE TE →'E TE →' E TE →' E TE →'E' '→+E E'→E ε'→E εTT F T →' T F T →' T F T →' T F T →' T' '→T ε'→T T '→T ε '→T T '→T T '→T T '→T εFF P F →'F P F →' F P F →' F P F →'F' '→F ε '→'F F * '→F ε '→F ε '→F ε '→F ε '→F ε '→F εPP E →() P a → P b → P →^5、考虑文法: S →AS|b A →SA|a (1)列出这个文法的所有LR(0) 项目。

编译原理复习重点含答案编译原理复习重点编译原理是计算机科学中的一门重要课程,它研究的是如何将高级语言程序转化为机器语言的过程。
在编译原理的学习中,我们需要掌握一些重要的概念和技术,以便能够理解和应用编译器的工作原理。
本文将重点介绍编译原理的几个重要主题,并提供相应的答案供参考。
一、词法分析词法分析是编译器的第一个阶段,它的任务是将输入的字符序列划分为一个个有意义的词素(token)。
词法分析器通常使用有限自动机(DFA)来实现,其工作原理是将输入字符序列逐个读入,并根据事先定义好的词法规则进行匹配和识别。
常见的词法单元包括关键字、标识符、常量、运算符等。
常见的词法规则包括:1. 关键字:例如if、while、for等。
2. 标识符:由字母、数字和下划线组成,且以字母或下划线开头。
3. 常量:包括整数常量、浮点数常量、字符常量和字符串常量等。
4. 运算符:例如加法运算符+、减法运算符-等。
5. 分隔符:例如逗号、分号等。
词法分析的结果是一个个词法单元,每个词法单元包含一个词素和对应的词法单元类型。
例如,对于输入程序"int a = 10;",词法分析的结果可能是[("int", "关键字"), ("a", "标识符"), ("=", "运算符"), ("10", "整数常量"), (";", "分隔符")]。
二、语法分析语法分析是编译器的第二个阶段,它的任务是将词法分析器输出的词法单元序列转化为抽象语法树(AST)。
语法分析器通常使用上下文无关文法(CFG)来描述语言的语法结构,并使用递归下降、LL(1)分析、LR分析等算法进行分析。
常见的语法规则包括:1. 表达式:例如算术表达式、布尔表达式等。


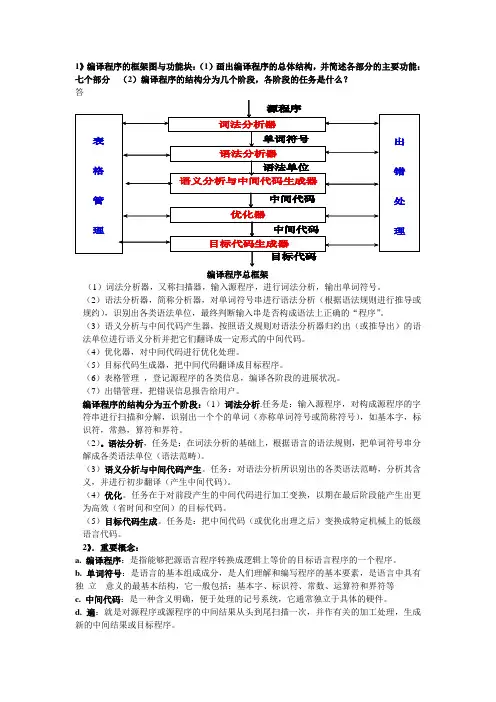
1》编译程序的框架图与功能块:(1)画出编译程序的总体结构,并简述各部分的主要功能:七个部分(2)编译程序的结构分为几个阶段,各阶段的任务是什么?答编译程序总框架(1)词法分析器,又称扫描器,输入源程序,进行词法分析,输出单词符号。
(2)语法分析器,简称分析器,对单词符号串进行语法分析(根据语法规则进行推导或规约),识别出各类语法单位,最终判断输入串是否构成语法上正确的“程序”。
(3)语义分析与中间代码产生器,按照语义规则对语法分析器归约出(或推导出)的语法单位进行语义分析并把它们翻译成一定形式的中间代码。
(4)优化器,对中间代码进行优化处理。
(5)目标代码生成器,把中间代码翻译成目标程序。
(6)表格管理,登记源程序的各类信息,编译各阶段的进展状况。
(7)出错管理,把错误信息报告给用户。
编译程序的结构分为五个阶段:(1)词法分析.任务是:输入源程序,对构成源程序的字符串进行扫描和分解,识别出一个个的单词(亦称单词符号或简称符号),如基本字,标识符,常熟,算符和界符。
(2)。
语法分析,任务是:在词法分析的基础上,根据语言的语法规则,把单词符号串分解成各类语法单位(语法范畴)。
(3)语义分析与中间代码产生。
任务:对语法分析所识别出的各类语法范畴,分析其含义,并进行初步翻译(产生中间代码)。
(4)优化。
任务在于对前段产生的中间代码进行加工变换,以期在最后阶段能产生出更为高效(省时间和空间)的目标代码。
(5)目标代码生成。
任务是:把中间代码(或优化出理之后)变换成特定机械上的低级语言代码。
2》.重要概念:a. 编译程序:是指能够把源语言程序转换成逻辑上等价的目标语言程序的一个程序。
b. 单词符号:是语言的基本组成成分,是人们理解和编写程序的基本要素,是语言中具有独立意义的最基本结构,它一般包括:基本字、标识符、常数、运算符和界符等c. 中间代码:是一种含义明确,便于处理的记号系统,它通常独立于具体的硬件。





第一章:编译过程的六个阶段:词法分析,语法分析,语义分析,中间代码生成,代码优化,目标代码生成解释程序:把某种语言的源程序转换成等价的另一种语言程序——目标语言程序,然后再执行目标程序。
解释方式是接受某高级语言的一个语句输入,进行解释并控制计算机执行,马上得到这句的执行结果,然后再接受下一句。
编译程序:就是指这样一种程序,通过它能够将用高级语言编写的源程序转换成与之在逻辑上等价的低级语言形式的目标程序(机器语言程序或汇编语言程序)。
解释程序和编译程序的根本区别:是否生成目标代码第三章:Chomsky对文法中的规则施加不同限制,将文法和语言分为四大类:0型文法(PSG)◊ 0型语言或短语结构语言文法G的每个产生式α→β中:若α∈V*VNV*, β∈(VN∪VT)* ,则G是0型文法,即短语结构文法。
1型文法(CSG)◊ 1型语言或上下文有关语言在0型文法的基础上:若产生式集合中所有|α|≤|β|,除S→ε(空串)外,则G是1型文法,即:上下文有关文法另一种定义:文法G的每一个产生式具有下列形式:αAδ→αβδ,其中α、δ∈V*,A∈VN,β∈V+;2型文法(CFG)◊ 2型语言或上下文无关语言文法G的每个产生式A→α,若A∈VN ,α∈(VN∪VT)*,则G是2型法,即:上下文无关文法。
3型文法(RG)◊ 3型语言或正则(正规)语言若A、B∈VN,a∈VT或ε,右线性文法:若产生式为A→aB或A→a左线性文法:若产生式为A→Ba或A→a都是3型文法(即:正规文法)最左(最右)推导在推导的任何一步α⇒β,其中α、β是句型,都是对α中的最左(右)非终结符进行替换规范推导:即最右推导。
规范句型:由规范推导所得的句型。
句子的二义性(这里的二义性是指语法结构上的。
)文法G[S]的一个句子如果能找到两种不同的最左推导(或最右推导),或者存在两棵不同的语法树,则称这个句子是二义性的。
文法的二义性一个文法如果包含二义性的句子,则这个文法是二义文法,否则是无二义文法。