子空间聚类Sparse Subspace Clustering SSC
- 格式:doc
- 大小:49.00 KB
- 文档页数:2

基于多级结构的深度子空间聚类方法作者:***来源:《现代信息科技》2022年第06期摘要:提出了一种新的深度子空间聚类方法,使用了卷积自编码器将输入图像转换为位于线性子空间上的表示。
通过结合自编码器提取的低阶和高阶信息来促进特征学习过程,在编码器的不同层级生成多组自我表示和信息表示。
将得到的多级信息融合得到统一的系数矩阵并用于后续的聚类。
通过多组实验验证了上述创新的有效性,在三个经典数据集:Coil20,ORL 和Extended Yale B上,聚类精度分别达到95.38%、87.25%以及97.58%。
相较于其他主流方法,能有效提高聚类准确性,并具有较强的鲁棒性。
关键词:子空间聚类;多级结构;自编码器中图分类号:TP181 文献标识码:A文章编号:2096-4706(2022)06-0100-04Deep Subspace Clustering Method Based on the Multi-level StructureYU Wanrong(School of Artificial Intelligence and Computer Science, Jiangnan University, Wuxi 214122, China)Abstract: A new deep subspace clustering method that uses a convolutional autoencoder to transform an input image into a representation that lies on a linear subspace is proposed. The feature learning process is facilitated by combining low-order and high-order information extracted by the autoencoders, and multiple sets of self-representations and information representations are generated at different levels of the encoder. The obtained multi-level information is fused to obtain a unified coefficient matrix and use it for subsequent clustering. The effectiveness of the above innovations is verified through multiple experiments on three classic datasets, including Coil20, ORL and Extended Yale B. And the clustering accuracies reach 95.38%, 87.25% and 97.58% respectively.Compared with other mainstream methods, this method can effectively improve the clustering accuracy and it has strong robustness.Keywords: subspace clustering; multi-level structure; autoencoder0 引言高維数据处理已成为机器学习和模式识别领域具有代表性的任务之一。

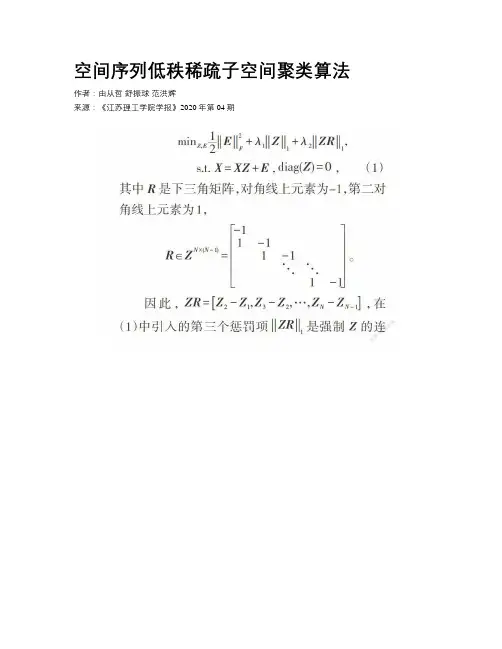
空间序列低秩稀疏子空间聚类算法作者:由从哲舒振球范洪辉来源:《江苏理工学院学报》2020年第04期摘要:研究序列数据的子空间聚类问题,具体来说,给定从一组序列子空间中提取的数据,任务是将这些数据划分为不同的不相交组。
基于表示的子空间聚类算法,如SSC和LRR 算法,很好地解决了高维数据的聚类问题,但是,这类算法是针对一般数据集进行开发的,并没有考虑序列数据的特性,即相邻帧序列的样本具有一定的相似性。
针对这一问题,提出了一种新的低秩稀疏空间子空间聚类方法(Low Rank and Sparse Spatial Subspace Clustering for Sequential Data,LRS3C)。
该算法寻找序列数据矩阵的稀疏低秩表示,并根据序列数据的特性,在目标函数中引入一个惩罚项来加强近邻数据样本的相似性。
提出的LRS3C算法充分利用空间序列数据的时空信息,提高了聚类的准确率。
在人工数据集、视频序列数据集和人脸图像数据集上的实验表明:提出的方法LRS3C与传统子空间聚类算法相比具有较好的性能。
关键词:低秩表示;稀疏表示;子空间聚类;序列数据中图分类号:TP391.4 文献标识码:A 文献标识码:2095-7394(2020)04-0078-08序列数据特别是视频数据往往具有高维属性,利用传统聚类算法进行分析处理时,往往会遇到“维数灾难”的问题,于是研究人员提出了一系列基于表示的子空间聚类算法,如稀疏表示子空间聚类算法(SSC)和低秩表示算法(LRR),较好地解决了高维数据聚类的问题,从而得到了广泛的关注,并在众多领域得到成功的应用。
但是,这类算法是针对一般数据集设计开发的,在许多实际场景中,数据通常具有顺序或有序的属性,例如视频、动画或其他类型的时间序列数据。
然而,传统的方法假设数据点独立于多个子空间,而忽略了时间序列数据中的连续关系。
如何充分利用空间序列数据这一特性提高聚类性能,是计算机视觉领域中一个重要但又具有挑战性的问题。







子空间聚类概述
子空间聚类是一种在高维数据中发现隐含的低维子空间结构的聚类方法。
与传统的聚类算法不同,子空间聚类考虑到了数据在不同的属性子空间中可能具有不同的聚类结构。
它将数据投影到不同的子空间中进行聚类分析,以发现数据在各个子空间中的聚类特征。
子空间聚类算法通常具有以下步骤:
1. 子空间选择:选择要进行聚类的属性子空间。
可以通过特征选择、主成分分析等方法来选择合适的子空间。
2. 子空间投影:将数据投影到选择的子空间中,得到在每个子空间中的投影结果。
3. 聚类分析:在每个子空间中使用传统的聚类算法(如
k-means、DBSCAN等)进行聚类分析,得到每个子空间中的聚类结果。
4. 融合聚类结果:将各个子空间中的聚类结果进行融合,得到最终的聚类结果。
子空间聚类的优势在于可以处理高维数据中存在的低维子空间结构,能够更好地挖掘数据的潜在模式和关联信息。
它适用于许多领域,如图像处理、文本挖掘、生物信息学等。
然而,子空间聚类也面临着一些挑战,如选择合适的子空间、处理噪音和异常值等问题,需要根据具体应用场景进行算法选择和参数调优。

第42卷第9期自动化学报Vol.42,No.9 2016年9月ACTA AUTOMATICA SINICA September,2016基于密度峰值的聚类集成褚睿鸿1王红军1杨燕1李天瑞1摘要聚类集成的目的是为了提高聚类结果的准确性、稳定性和鲁棒性.通过集成多个基聚类结果可以产生一个较优的结果.本文提出了一个基于密度峰值的聚类集成模型,主要完成三个方面的工作:1)在研究已有的各聚类集成算法和模型后发现各基聚类结果可以用密度表示;2)使用改进的最大信息系数(Rapid computation of the maximal information coefficient, RapidMic)表示各基聚类结果之间的相关性,使用这种相关性来衡量原始数据在经过基聚类器聚类后相互之间的密度关系;3)改进密度峰值(Density peaks,DP)算法进行聚类集成.最后,使用一些标准数据集对所设计的模型进行评估.实验结果表明,相比经典的聚类集成模型,本文提出的模型聚类集成效果更佳.关键词聚类集成,近邻传播,密度峰值,相似性矩阵引用格式褚睿鸿,王红军,杨燕,李天瑞.基于密度峰值的聚类集成.自动化学报,2016,42(9):1401−1412DOI10.16383/j.aas.2016.c150864Clustering Ensemble Based on Density PeaksCHU Rui-Hong1WANG Hong-Jun1YANG Yan1LI Tian-Rui1Abstract Clustering ensemble aims to improve the accuracy,stability and robustness of clustering results.A good ensemble result is achieved by integrating multiple base clustering results.This paper proposes a clustering ensemble model based on density peaks.First,this paper discovers that the base clustering results can be expressed with density after studying and analyzing the existing clustering algorithms and models.Second,rapid computation of the maximal information coefficient(RapidMic)is introduced to represent the correlation of the base clustering results,which is then used to measure the density of these original datasets after base clustering.Third,the density peak(DP)algorithm is improved for clustering ensemble.Furthermore,some standard datasets are used to evaluate the proposed model. Experimental results show that our model is effective and greatly outperforms some classical clustering ensemble models. Key words Clustering ensemble,affinity propagation,density peaks,similarity matrixCitation Chu Rui-Hong,Wang Hong-Jun,Yang Yan,Li Tian-Rui.Clustering ensemble based on density peaks.Acta Automatica Sinica,2016,42(9):1401−14121绪论1.1研究背景和研究意义类簇可以描述为一个包含密度相对较高的点集的多维空间中的连通区域,一个类簇内的实体是相收稿日期2015-12-25录用日期2016-04-18Manuscript received December25,2015;accepted April18, 2016国家科技支撑计划课题(2015BAH19F02),国家自然科学基金(61262058,61572407),教育部在线教育研究中心在线教育研究基金(全通教育)(2016YB158),西南交通大学中央高校基本科研业务费专项基金(A0920502051515-12)资助Supported by National Science and Technology Support Pro-gram(2015BAH19F02),National Natural Science Foundation of China(61262058,61572407),Online Education Research Cen-ter of the Ministry of Education Online Education Research Fund(Full Education)(2016YB158)and Fundamental Research Funds for the Central Universities of Southwest Jiaotong Uni-versity(A0920502051515-12)本文责任编委王立威Recommended by Associate Editor WANG Li-Wei1.西南交通大学信息科学与技术学院成都6117561.School of Information Science and Technology,Southwest Jiaotong University,Chengdu611756似的,不同类簇的实体是不相似的,同一类簇任意两个点间的距离小于不同类簇任意两个点间的距离[1].近几年,有不少新的聚类算法被提出.周晨曦等[2]设计出一种基于动态更新约束的半监督凝聚层次聚类方法,其更新过程可以保证最终结果的有效性.为了处理混合属性的数据,陈晋音等[3]提出了基于自动确定密度聚类中心的聚类算法.王卫卫等[4]提出了SSC(Sparse subspace clustering),能够揭示高维数据真实子空间结构的表示模型.Ta¸s demir等[5]通过对高空间分辨率遥感影像进行无监督聚类来识别土地覆盖.Parvin等[6]提出了一种模糊加权聚类算法(Fuzzy weighted locally adaptive clustering, FWLAC),能够处理不平衡的聚类.单一的聚类方法普遍存在局限性,例如聚类结果很大程度上取决于参数及其初始化,无法准确判断数据集的真实类簇个数等.另外,真实的数据集往往具有不同的结构和大小,因此,任何一种聚类方法都无法在全部的数据集上获得好的聚类效果.1402自动化学报42卷集成学习是指通过集成多个不同学习器来解决同一问题.Strehl等[7]最早明确提出聚类集成:通过计算和比较多个基聚类结果的相关关系以及信息熵,集成多个基聚类结果可以获得一个综合性的结果.聚类集成有很多优点,不仅能够提高聚类结果的准确性、稳定性和鲁棒性,还能并行处理数据集[7−9].近年来,聚类集成在原有的基础上获得了极大的发展,技术也日趋成熟,越来越多的方法被应用到数据挖掘、生物信息、医学等领域.与此同时,一些问题也显露出来,例如从不同结构的数据源中获得的基聚类结果往往具有不同的结构,如何确定最具代表性的聚类结构或是构建一个新的聚类集成结构显得尤为重要[10−11].本文在对各类已有的聚类集成算法和模型研究的基础上,分析基聚类算法对原始数据进行聚类后其数据结构上的改变.探索了基聚类结果是否可以用原始数据的密度关系进行表示.尝试用改进的密度峰值(Density peaks,DP)算法[12]进行聚类集成.1.2主要研究内容本文主要有三个方面的研究内容:1)本文把基聚类结果看成是原始数据的新增属性,研究结果发现只使用这些新增属性就可以发现数据的密度关系;2)采用改进的最大信息系数(Rapid com-putation of the maximal information coefficient, RapidMic)[13−14]来表示这些数据的密度关系,通过计算数据之间的相关关系矩阵,可以把基聚类结果转换成一个最大相关系数矩阵;3)改进DP算法,确定聚类数量这一参数,自动选取峰值最大的K个点作为聚类中心,然后使用这个改进的DP算法对前面得到的最大相关系数矩阵进行聚类集成.最后,使用标准的数据集对所设计的聚类集成算法和经典的聚类集成算法、以及K均值(K-means)算法进行比较,采用准确率和纯度值这两个评价指标对聚类集成结果进行评价,并对评价结果进行统计检验等工作.在上述研究内容中,本文有两个方面的创新:1)对聚类结果进行分析,使用RapidMic进行运算,发现基聚类结果可以表示成为原始数据的密度关系,通过这个密度关系可以得到一个最大相关系数矩阵;2)改进了DP算法,增加了DP算法的一个参数K,然后使用这个改进的DP算法进行聚类集成.1.3本文内容安排本文的其余部分安排如下.第2节介绍聚类集成的相关工作.第3节首先例证基聚类结果可以表示成为原始数据的密度关系,随后介绍了基于改进的DP算法的聚类集成方法.第4节展示实验步骤及实验结果.第5节得出结论,并介绍了未来可能的工作.2相关工作近年来,集成学习获得越来越多的关注.大多数集成学习方法可分为三类:监督学习、半监督学习以及无监督学习.无监督学习方法的集成,也就是聚类集成,其基本思想是用多个独立的基聚类器分别对原始数据集进行聚类,然后使用某种集成方法进行处理,获得一个最终的集成结果[15].这类算法在第一阶段应尽可能地使用多种方式来获取基聚类结果,第二阶段应选择一个最合适的集成解决方案来处理这些结果.依据算法中解决问题的重点不同,现有的聚类集成方法可大致分为三类.第一类侧重于设计新的聚类集成方法.为了改善最终单聚类算法的结果,Strehl等[7]提出基于三种集成技术的聚类集成框架.Fred等[16]提出了EAC(Evidence accumulation clustering)算法. Topchy等[17]提出了EM(Expectation maximiza-tion)算法并通过对比其他算法分析了其在聚类集成中的性能表现.Ayad等[18]提出了基于累积投票方法的聚类集成框架.Zheng等[19]设计出一种在分层聚类过程中考虑超度量距离分层的聚类集成框架.Wang等[20]在聚类集成框架中引入贝叶斯理论,并设计出基于贝叶斯网络的聚类集成方法.周林等[21]提出了基于谱聚类的聚类集成算法,既能利用谱聚类算法的优越性能,又能避免精确选择尺度参数的问题.Banerjee等[22]提出了一种能够为EM算法产生更好聚类参数近似值的聚类集成算法. Lingras等[23]提出了一种基于粗糙集的聚类集成方法用以维护固有的聚类顺序.Wahid等[24]提出了一种基于SPEA(Strength pareto evolutionary algorithm)的新的多目标聚类集成方法:SPEA-II.结合不同的聚类集成方法,Goswami等[25]提出了一种基于遗传算法的聚类集成算法.Wei等[26]设计出一个能够同时考虑成对约束和度量学习的半监督聚类集成框架.Liu等[27]提出一种选择性的聚类集成算法以及自适应加权策略.Hao等[28]设计的算法能够用以改善基于链接相似性度量的数据聚类关联矩阵.Huang等[29]通过在聚类集成中引入超对象的概念,提出一种新的方法:ECFG(Ensemble clustering using factor graph).第二类主要探索聚类集成方法的属性.9期褚睿鸿等:基于密度峰值的聚类集成1403Kuncheva等[30]研究了聚类的多样性与准确性之间的关系.Kuncheva等[31]探索出如何利用合适的多样性提高聚类准确性.Topchy等[32]重点研究了聚类集成方法的收敛性.Amasyali等[33]就不同因素对聚类集成性能的影响进行了研究.Zhang等[34]提出了一个广义调整的兰德指数来衡量数据集中两个基分区之间的一致性.Wang[35]设计出基于CA 树的分层数据聚类结构,可加速聚类形成,提升聚类集成效率.为了提高聚类集成算法的鲁棒性,Zhou 等[36]提出在捕获到稀疏和对称的错误后,将其整合到强大和一致的框架下用以学习低秩矩阵.Zhong 等[37]认为证据积累是一种有效的框架能够将基分区转换为关联矩阵,从而充分利用每个基分区的集群结构信息.Wahid等[38]研究出的聚类集成方法能够解决两个不同但相互关联的问题:从数据集中产生多个聚类集成结果,同时产生一个最终的聚类集成结果.第三类聚类集成方法主要探索其应用领域.通过检测基因表达数据集的基础聚类结构,Yu等[39]提出的聚类集成框架可用于发现癌症基因.Zhang 等[40]提出的聚类集成方法可应用于SAR图像分割.Hu等[41]研究了如何使用聚类集成从基因表达数据集中确定基因簇的问题.徐森等[42]在聚类集成中引入谱聚类思想,以解决文本聚类问题.Ye等[43]融合了聚类集成框架与领域知识,用以实现恶意软件的自动分类.Zhang等[44]探索出基于聚类集成对流数据进行数据挖掘的方法.Yu等[45]借助新的聚类集成方法BAE(Bagging-Adaboost ensemble)实现了对真核细胞蛋白质磷酸化位点的预测.在从基因表达数据集发现癌症的过程中,为了降低噪声基因的影响,Yu等[46]提出两种新的共识聚类框架:三谱聚类为基础的共识聚类(SC3)和双谱聚类为基础的共识聚类(SC2).Ammour等[47]提出的聚类集成方法可应用于图像分割领域,方法中包含了模糊C均值聚类(Fuzzy C-means,FCM)算法和具有不同邻居效应值的本地信息FCM算法FCM S1, FCM S2.为了解决大规模社会媒体网络中的隐身术检测问题,Li等[48]提出了高阶共同特征和聚类集成的方法.受Chameleon理念的启发,Xiao等[49]设计出一种半监督的聚类集成模型用于高速列车行进过程中传动装置的故障诊断.Teng等[50]提出用基于数据处理分组方法的聚类集成框架(Cluster ensemble framework based on the group method of data handling,CE-GMDH)提升数据处理技术.本文提出一种基于改进的DP算法的聚类集成模型,获得基聚类结果后,使用RapidMic衡量各基聚类结果之间的相关性,通过计算得到最大相关系数矩阵后,使用改进的DP算法进行聚类集成,获得最终的聚类集成结果.3基于改进的DP算法的聚类集成3.1聚类集成问题聚类集成可以分为两个步骤进行.第一步是使用基聚类器对原始数据集进行多次聚类,得到多个基聚类结果.这一步可选择两种方式达成:1)使用某一种算法重复运算多次获得基聚类结果;2)选用多种不同的算法进行运算获得基聚类结果.第二步是基聚类结果集成,选取一种适当的聚类集成方法或者框架,使之能够最大限度地分析这些结果,得到一个对原始数据集最好的集成结果.3.2基聚类结果的产生近邻传播(Affinity propagation,AP)[51]算法是2007年在Science上被提出的.本文选用AP 算法作为基聚类算法,与其他算法不同,AP算法不需要在一开始指定聚类个数,所有的数据点均作为潜在的聚类中心.通过计算原始数据集的相似度矩阵,使用AP算法进行聚类,产生基聚类结果.假设原始数据集有n个数据点,选用欧式距离作为相似度的测度指标,则任意两点之间的相似度为两点距离平方的负数,例如对于点x i和点x k,有G(i,k)=− x i−x k 2.通过计算所有数据点的相似度,得到n×n维的相似度矩阵G.AP算法初始设定所有G(k,k)为相同值p.通过参考度p的值来判断某个点是否能成为聚类中心,参考度p直接影响了最终的聚类数量.AP算法传递两种类型的消息:吸引度值(Re-sponsibility)和归属度值(Availability).吸引度值r(i,k)表示从点i发送到候选聚类中心k的数值消息,反映了k点是否适合作为i点的聚类中心.而归属度值a(i,k)表示从候选聚类中心k发送到i的数值消息,反映了i点是否选择k作为其聚类中心. r(i,k)与a(i,k)越强,k点作为聚类中心的可能性就越大,并且i点隶属于以k点为聚类中心的聚类的可能性也越大.算法运行过程中,通过迭代过程不断更新每一个点的吸引度值和归属度值,直到产生K个高质量的聚类中心,随后将其余的数据点分配到相应的聚类中.通过选取不同的p值,重复使用AP算法计算次,最终可获得m个不同的基聚类结果P=[P1,P2,P3,···,P m].P为一个n×m维的矩阵,矩阵的每一行代表每一个数据点在m种不同1404自动化学报42卷聚类算法中被分配到的类别标签,而矩阵的每一列则代表一次基聚类运算的结果(对应某个参考度p).3.3基聚类结果的相似性矩阵互信息(Mutual information)是信息论里一种有用的信息度量,可以看成是一个随机变量中包含的关于另一个随机变量的信息量.两个变量之间的互信息越大,说明两者的相关性越大.反之,则越小.衡量简单的离散变量之间的关联度大小可以通过计算互信息实现,然而,互信息无法衡量混合类型数据之间的相关性.2011年,最大信息系数(Maximalinformation coefficient,MIC)被提出[13],MIC能够对不同类型的庞大数据集进行关联关系的评估.其算法原理是:通过计算一个数据集中两两变量之间的互信息,找出每两个变量之间互信息最大的值,通过归一化后构成一个特征矩阵.与互信息相比,MIC有下面两大优势:1)除了能够对本身是离散型的数据进行处理以外,还能够通过对连续型数据进行离散处理,实现对混合类型数据的处理.2)通过构建互信息特征矩阵来寻找变量之间的最大信息系数,可以更精确地表示出数据属性间关联性的大小.本文使用改进的MIC,也就是RapidMic[14]算法计算基聚类结果的相关性.基聚类过程中计算得到的n×m维的矩阵P包含所有的基聚类结果.P中有n个数据点,把基聚类结果看成是原始数据的新增属性,每个数据点有m种属性.计算新的数据对象之间的互信息.可以用I(αi,αj)表示αi和αj之间的互信息,其中,H(αi)表示变量αi的熵,I(αi,αj)的值没有上界限.为了更好地比较变量之间的相关性,可以采用标准化的I(αi,αj)值,范围在0到1之间,0表示两个变量互相独立,而1表示两个变量有无噪的关系.已有的几种标准化方法以I(αi,αj)≤min(H(αi),H(αj))为依据,需要计算H(αi)和H(αj)的算术和几何平均数.标准化后,当i=j时,H(αi)=I(αi,αj),且是在Hilbert空间中对数据进行标准化的,所以一般更倾向于采用几何平均值的方法来对数据进行标准化.归一化互信息(Normalized mutual information,NMI)公式如式(1)所示:NMI(αi,αj)=I(αi,αj)H(αi)H(αj)(1)根据式(1)可以计算出新的数据对象之间的互信息大小.在得到所有的互信息值后,构建n×n维特征矩阵S.该相似性矩阵为一个对称阵,主对角线上的值是属性自身的互信息,值为1,其余的为两两属性间的互信息值,即NMI(αi,αj).3.4基聚类结果的密度关系Isomap算法[52]是一种非线性降维方法,首先创建能够正确表达数据邻域结构的邻域图,接着用最短路径法计算各数据点间的最短路径,逼近相应的测地距离,最后使用经典的多维标度分析(Multi-dimensional scaling,MDS)算法在低维可视空间重建数据.本文使用Iris数据集进行例证,Iris有150个数据点,即n取值150,每个数据点4种维度.实验中以AP算法作为基聚类器,重复运算30次,即m 取值30,得到包含所有基聚类结果的n×m维的P 矩阵.接着使用RapidMic算法获得基聚类结果的相似性矩阵S.最后通过Isomap算法获得原始数据的基聚类结果的二维关系映射.具体过程如图1所示,最终结果如图2所示.将这些基聚类结果从150维降到2维之后,得到一个二维关系映射图,观察图片可以发现,基聚类结果的二维映射以某种规律聚成了几类.由此推论,如果把基聚类结果看成是原始数据的新增属性,那么只使用这些新增属性就可以发现数据的密度关系.3.5改进基于密度峰值的DP算法用于聚类集成DP算法是2014年在Science上被提出的聚类图1基于基聚类结果获取原始数据二维关系映射图的过程Fig.1The process of obtaining the two-dimensional relational mapping of original dataset based onclustering results9期褚睿鸿等:基于密度峰值的聚类集成1405图2原始数据的基聚类结果的二维关系映射Fig.2The two-dimensional relational mapping of the base clustering results of original dataset算法,算法有很好的鲁棒性并且对于各种数据集都能达到很好的聚类效果[12].DP算法基于的假设是:类簇中心被具有较低局部密度的邻居点包围,且与具有更高密度的任何点有相对较大的距离.对于每一个数据点i,要计算两个量:数据点的局部密度ρi和该点到具有更高局部密度的点的距离δi,而这两个值都取决于数据点间的距离d ij,d c是一个截断距离.数据点i的局部密度ρi如式(2)所示:ρi=jχ(d ij−d c)(2)其中,令x=d ij−d c,如果x<0,那么χ(x)=1;否则χ(x)=0.基本上,ρi等于与点i的距离小于d c的点的个数.算法只对不同点的ρi的相对大小敏感,这意味着对于大数据集,分析结果对于d c的选择有很好的鲁棒性.δi是数据点i到任何比其密度大的点的距离的最小值,计算公式如式(3)所示:δi=minj:ρj>ρi(d ij)(3)对于密度最大的点,我们可以得到δi=min j(d ij).只有具有高δ和相对较高ρ的点才是类簇中心.而有高δ值和低ρ值的,往往就是异常点.类簇中心找到后,剩余的每个点被归属到有更高密度的最近邻所属类簇.类簇分配只需一步即可完成,不像其他算法要对目标函数进行迭代优化.本文改进了经典的DP算法,在原有的算法中增加了一个参数K,具体的修改方法见算法1.经过改进之后,算法能够自动选取拥有最大密度峰值的前K个点作为聚类中心.接着使用这个改进的DP 算法进行聚类集成,将相似性矩阵S n×n作为目标数据输入算法,计算出局部密度ρi和该点到具有更高局部密度的点的距离δi,自动选取具有高δ和相对较高ρ的点作为类簇中心,将其余的数据点归到各个类簇,要求分配到的类簇与比其密度高并且与其距离近的节点所属的类一样.最终的聚类集成结果可以看成是针对原始数据集所获得的最好聚类结果.整个聚类集成过程如图3所示.图3基于改进的DP算法的聚类集成过程Fig.3The process of cluster ensembling based onimproved DP algorithm3.6算法描述根据图3展示的聚类集成过程,算法1描述如下:算法1.DP ensemble输入.实验数据集αn×q,基聚类器运算次数m,实验数据集的总类簇数K输出.α的聚类集成标签L步骤1.重复运算m次AP算法获得数据集α的基聚类结果P n×m.步骤2.根据式(1)使用RapidMic计算P n×m的相似性矩阵S n×n.步骤3.使用改进的DP算法对S n×n进行聚类集成:1)根据式(2)和(3)计算S中每个数据点的局部密度ρi和该点到具有更高局部密度的点的距离δi(本文使用的是RapidMic算法,取值范围是0到1.相似度越大,表示距离越近,具体转换关系是:距离=1–相似度);2)自动选取具有高δi和相对较高ρi的前K个点作为类簇中心;3)对除类簇中心外的所有数据点进行划分,获得α的聚类集成标签L.1406自动化学报42卷4实验4.1数据集和评价标准本文使用UCI(University of CaliforniaIrvine)机器学习库中的20个数据集作为实验数据集.表1列出了数据集的样本、属性和类别数量.有很多标准可以用来衡量聚类集成算法,本文以这些数据的真实类别标签为标准,选用Micro-precision(MP)[53−54]标准和Purity[55]标准来衡量聚类结果的好坏.表1实验数据集的样本、属性和类别数量Table1The number of instances,features and classes ofdatasetsID Datasets Number of Number of Number ofinstances features classes1Aerosol90589232Amber88089233Ambulances93089234Aquarium92289235Balloon83089236Banner86089237Baobab90089238Basket89289239Bateau900892310Bathroom924892311Bed888892312Beret876892313Beverage873892314Bicycle844892315Birthdaycake932892316Blog943892317Blood866892318Boat857892319Bonbon874892320Bonsai8678923MP标准的计算如式(4)所示:MP=1nKh=1a h(4)其中,a h表示对数据某一类分类正确的数量,n表示数据集中数据对象的数量,K表示此数据集中类别的数量.MP值越大,代表聚类的准确率越高.为了获得更好的准确率需要进行重复的实验,采用平均MP值来衡量结果将更精确.具体计算公式如式(5)所示:AMP=1m×nmt=1Kh=1a h(5)其中,m为重复实验的次数,本文在基聚类中m为10,在聚类集成中m为3.Purity标准的计算如式(6)所示:Purity=1nrk=1max1<l<qn lk(6)其中,n l k是原始类簇的样本数.一个较大的纯度值代表较好的聚类性能.4.2实验步骤和实验结果本文选取AP作为基聚类器算法,通过选取10个不同的参考度p值,使用AP算法重复运算10次,获得基聚类结果P=[P1,P2,P3,···,P10].随后使用CSPA(Cluster-based similarity parti-tioning algorithm)[7]、HGPA(Hypergraph parti-tioning algorithm)[7]、MCLA(Meta-clustering al-gorithm)[7]、DP、EM和QMI(Quadratic mutual information)[9]六种算法对基聚类结果的相似性矩阵进行聚类集成,获得最终的聚类集成标签.最后将这些标签与数据集的真实标签进行对比,采用准确率和纯度值标准进行评价.此外,同时使用经典的K-means算法对数据集进行聚类,获取标签,对比真实标签后,采用准确率和纯度值标准进行评价.使用K-means与各聚类集成算法进行比照实验,是为了证明本文所提出的聚类集成算法是有效的,实际上并没有太大的意义,因为聚类集成更关注在已有的基聚类基础上的效果的提升,而非进行单一聚类算法的比较.表2展示了实验结果的准确率及其标准差.表中第一列数据给出了实验中用到的数据集ID.第二列和第三列给出了使用基聚类器AP算法对20个数据集进行10次聚类之后得到的平均准确率AP-average、最大准确率AP-max,之后的六列则依次给出使用CSPA、HGPA、MCLA、DP、EM和QMI六种聚类算法对基聚类结果的相似性矩阵进行集成运算,以及使用K-means进行聚类获得的准确率.从表2可以观测得到以下结论:1)从AP-average和AP-max两列数据可以看出,使用AP算法对20个数据集进行聚类运算,准确率极低,平均准确率仅为0.023.正确率极低的原因在于,AP算法产生的聚类标签与真实的标签很不一样,某种程度上来说,这两列结果是无意义的.9期褚睿鸿等:基于密度峰值的聚类集成1407表2平均准确率和标准差(每个数据集的最大准确率加粗显示.)Table2Average MPs and standard deviations(The highest MP among different algorithms oneach dataset is bolded.)ID AP-average AP-max CSPA HGPA MCLA DP EM QMI K-means 10.022±0.0150.113±0.0720.379±0.0200.384±0.0030.395±0.0200.484±0.0190.354±0.0040.466±0.0530.369±0.008 20.023±0.0160.111±0.0540.472±0.0450.502±0.0200.493±0.0040.571±0.0010.387±0.0250.526±0.0500.595±0.008 30.026±0.0160.119±0.0560.392±0.0260.394±0.0210.384±0.0080.596±0.0410.370±0.0220.497±0.0190.442±0.029 40.021±0.0130.095±0.0400.401±0.0130.394±0.0270.381±0.0260.653±0.0420.353±0.0110.580±0.0570.361±0.006 50.026±0.0200.161±0.1180.410±0.0370.468±0.0170.393±0.0090.554±0.0100.358±0.0320.541±0.0350.445±0.004 60.027±0.0170.124±0.0580.346±0.0020.365±0.0100.346±0.0040.805±0.1580.358±0.0040.791±0.1120.462±0.001 70.018±0.0150.108±0.0980.432±0.0260.474±0.0080.427±0.0170.534±0.0680.389±0.0500.482±0.0240.503±0.004 80.022±0.0170.133±0.0990.362±0.0180.394±0.0200.394±0.0080.538±0.0250.357±0.0230.483±0.0490.409±0.000 90.028±0.0180.135±0.0660.401±0.0200.445±0.0390.423±0.0230.511±0.0500.367±0.0170.510±0.0200.441±0.003 100.019±0.0120.088±0.0450.351±0.0140.369±0.0010.361±0.0140.756±0.0590.355±0.0110.662±0.0310.394±0.001 110.035±0.0210.173±0.0450.371±0.0020.401±0.0250.382±0.0240.617±0.0460.347±0.0060.542±0.0290.459±0.004 120.020±0.0120.101±0.0480.368±0.0050.372±0.0180.373±0.0170.629±0.0150.354±0.0070.575±0.0940.417±0.009 130.031±0.0230.173±0.1010.419±0.0140.425±0.0190.400±0.0130.531±0.0270.353±0.0040.511±0.0150.396±0.000 140.020±0.0150.113±0.0890.410±0.0200.412±0.0250.407±0.0060.522±0.0170.357±0.0080.478±0.0280.452±0.008 150.017±0.0130.092±0.0630.392±0.0440.446±0.0320.450±0.0140.576±0.0080.372±0.0050.563±0.0420.491±0.001 160.023±0.0150.119±0.0560.347±0.0050.383±0.0100.369±0.0060.685±0.0690.357±0.0030.627±0.0770.411±0.001 170.018±0.0110.088±0.0250.349±0.0110.352±0.0130.375±0.0030.776±0.0590.354±0.0170.687±0.0950.473±0.004 180.022±0.0140.106±0.0520.388±0.0070.368±0.0200.377±0.0120.587±0.0380.354±0.0080.537±0.0250.404±0.001 190.016±0.0110.090±0.0490.397±0.0220.411±0.0190.402±0.0120.508±0.0120.357±0.0130.481±0.0200.465±0.002 200.021±0.0120.095±0.0320.383±0.0050.385±0.0240.355±0.0110.642±0.0450.380±0.0390.587±0.0510.443±0.003 AVG0.023±0.0150.117±0.0630.389±0.0180.407±0.0190.394±0.0120.604±0.0400.362±0.0160.556±0.0460.442±0.0052)从CSPA、HGPA、MCLA、DP、EM和QMI 六列数据可以观测到,这六种算法的聚类集成准确率都超过0.340.说明聚类集成算法可以获得比单纯聚类更好的结果.3)最高的准确率已在表中加粗显示,在所有的聚类集成算法中,DP获得的准确率最高,平均准确率超过0.600.准确率越高,说明聚类效果越好,实验中,DP获得了最好的聚类效果.4)表2中各准确率的标准差相对都比较小,绝大部分不超过0.100.标准差越小,说明结果越稳定,实验中,各算法均具有良好的稳定性.5)对比K-means和DP两列数据可以发现,比起单纯使用K-means进行聚类运算,使用DP进行聚类集成能够获得更高的准确率.表3展示了实验结果的纯度值及其标准差.表中第一列数据给出了实验中用到的数据集ID.第二列和第三列给出了使用基聚类器AP算法对20个数据集进行10次聚类之后得到的平均纯度值AP-average、最大纯度值AP-max,之后的六列则依次给出使用CSPA、HGPA、MCLA、DP、EM和QMI 六种聚类算法对基聚类结果的相似性矩阵进行集成运算,以及使用K-means进行聚类获得的纯度值.从表3可以观测得到以下结论:1)从AP-average和AP-max两列数据可以看到,使用AP算法对20个数据集进行聚类获得的平均纯度值较低,仅为0.277,而最大纯度值却很高,达到0.672.纯度值不高,且波动很大的原因在于AP 算法产生的聚类标签与真实的标签很不一样,某种程度上来说,这两列结果是无意义的.2)从CSPA、HGPA、MCLA、DP、EM和QMI 六列数据可以观测到,这六种算法的聚类集成纯度值远远高于基聚类结果的平均纯度值,说明聚类集成算法可以获得比单纯聚类算法更好的结果.3)最高的纯度值已在表中加粗显示,在所有的聚类集成算法中,DP和EM获得的纯度值最高,两者在20个数据集上的平均纯度值均超过0.740.纯度值越高,说明聚类效果越好.实验中,DP和EM 能够获得较好的聚类效果.4)表中除了AP-average和AP-max的标准差比较大,六种聚类集成算法的纯度值的标准差都比较小,特别是DP和EM两种算法,平均标准差不到0.010,标准差越小,说明结果越稳定.实验中,聚。
Sparse subspace clustering:Algorithm,theory,and Application稀疏子空间聚类(SSC)的算法,理论和应用参考文献:1、E. Elhamifar and R. Vidal. Sparse subspace clustering: Algorithm,theory,and Application. IEEE Transactions on Pattern Analysis and Machine Intelligence,20132、E. Elhamifar and R. Vidal. Sparse subspace clustering. In CVPR, 20092013年的这篇论文写得比09年那篇容易懂一些,讨论和实验也更详细。
2013年的这篇可以看成是09那篇会议的扩展版。
一、算法数据没有损坏,求解模型(5)获得矩阵C:数据有损坏(noise and sparse outlying entries),求解模型(13)获得矩阵C:仿射子空间模型:二、理论1、independent子空间设rank(Yi)=di,Yi表示从第i个子空间Si抽取的Ni个样本构成的矩阵,di 表示Si的维数。
论文的定理1表明,模型(5)的解C*是一个块对角矩阵,属于同一个子空间的数据间的cij可能非零,不属于同一个子空间的数据间的cij=0.2、disjoint子空间对于disjoint子空间,除了满足条件rank(Yi)=di外,还需要满足公式(21):则可获得与independent子空间下类似的结论:三、应用segmenting multiple motionsin videos: Hopkins 155 datasetclustering images of human faces: Extended Yale B dataset通过计算每对子空间的最小主角(principal angle)小于一给定值的比例,每对子空间中的数据的k近邻至少有一个在其他子空间的比例,可以帮助我们更好地知道两个数据库子空间聚类的挑战和各个算法的性能差别。
稀疏子空间聚类算法与模型建立稀疏子空间聚类是一种基于谱聚类的子空间聚类方法,基本思想:假设高位空间中的数据本质上属于低维子空间,能够在低维子空间中进行线性表示,能够揭示数据所在的本质子空间, 有利于数据聚类.基本方法是, 对给定的一组数据建立子空间表示模型,寻找数据在低维子空间中的表示系数, 然后根据表示系数矩阵构造相似度矩阵, 最后利用谱聚类方法如规范化割(Normalized cut, Ncut)[22] 获得数据的聚类结果。
基本原理稀疏子空间聚类[32] 的基本思想是: 将数据 αS x i ∈表示为所有其他数据的线性组合, j ij ij i x Z x ∑≠= (1)并对表示系数施加一定的约束使得在一定条件下对所有的αS x j ∉, 对应的0=ij Z 。
将所有数据及其表示系数按一定方式排成矩阵 ,则式(1)等价于 XZ X = (2)且系数矩阵N N R Z ⨯∈ 满足: 当i x 和j x 属于不同的子空间时, 有0=ij Z . 不同于用一组基或字典表示数据, 式(2)用数据集本身表示数据, 称为数据的自表示. 若已知数据的子空间结构, 并将数据按类别逐列排放, 则在一定条件下可使系数矩阵Z 具有块对角结构, 即⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=k Z Z Z Z 00000021 (3) 这里),,1(k Z =αα 表示子空间αS 中数据的表示系数矩阵; 反之, 若Z 具有块对角结构, 这种结构揭示了数据的子空间结构. 稀疏子空间聚类就是通过对系数矩阵Z 采用不同的稀疏约束, 使其尽可能具有理想结构, 从而实现子空间聚类.Elhamifar 等[32] 基于一维稀疏性提出了稀疏子空间聚类(Sparse subspace clustering,SSC) 方法, 其子空间表示模型为1min Z Z 0,..==ii Z XZ X t s (4)该模型利用稀疏表示(SR) 迫使每个数据仅用同一子空间中其他数据的线性组合来表示. 在数据所属的子空间相互独立的情况下, 模型(4) 的解Z 具有块对角结构, 这种结构揭示了数据的子空间属性: 块的个数代表子空间个数, 每个块的大小代表对应子空间的维数, 同一个块的数据属于同一子空间. 注意, 模型中的约束0=ii Z 是为了避免平凡解, 即每个数据仅用它自己表示, 从而Z 为单位矩阵的情形. 稀疏子空间聚类综述 王卫卫1 李小平1 冯象初1 王斯琪132 Elhamifar E, Vidal R. Sparse subspace clustering. In: Pro-ceedings of the 2009 IEEE Computer Society Conferenceon Computer Vision and Pattern Recognition (CVPR).Miami, FL, USA: IEEE, 2009. 2790¡2797稀疏最优化模型位于线性或仿射子空间集合的高维数据可以稀疏地被同一个子空间的点线性或者仿射表示。
基于隐空间的低秩稀疏子空间聚类刘建华【摘要】提出了一种基于隐空间的低秩稀疏子空间聚类算法,在聚类的过程中可以对高维数据进行降维,同时在低维空间中利用稀疏表示和低秩表示对数据进行聚类,大大降低了算法的时间复杂度。
在运动分割和人脸聚类问题上的实验证明了算法的有效性。
%T his paper proposed a novel algorithm named low‐rank sparse subspace clustering in latent space (LatLRSSC ) , it can reduce the dimension and cluster the data lying in a union of subspaces simultaneously . The main advatages of our method is that it is computationally efficient . The effectiveness of the algorithm is demonstrated through experiments on motion segmentation and face clustering .【期刊名称】《西北师范大学学报(自然科学版)》【年(卷),期】2015(000)003【总页数】5页(P49-53)【关键词】子空间聚类;稀疏表示;低秩表示;运动分割;人脸聚类【作者】刘建华【作者单位】浙江工商职业技术学院电子与信息工程学院,浙江宁波 315012【正文语种】中文【中图分类】TP391过去的几十年人们见证了数据的爆炸式增长,这对于数据的处理工作提出了巨大的挑战,特别是这些数据集通常都是高维数据.数据的高维特性不仅增加了计算时间,而且由于噪声和环境空间降低了算法的性能.实际上,这些数据的内在尺度往往比实际空间中小得多,这就促使人们运用一些技术发现高维数据的低维表示,比如低秩近似和稀疏表示等[1-3].实际上,在许多问题中,高维空间中的数据往往可以用低维子空间进行表示.子空间聚类算法就是挖掘数据低维子空间的一种聚类算法[4],它已经被广泛地应用在许多领域,如计算机视觉中的运动分割和人脸聚类,控制领域的混合系统辨识,社交网络中的社区集群.为了解决高维数据聚类问题,目前已经提出了很多聚类算法,如混合高斯模型、NMF和一些代数方法(如k-subspace)、混合概率主成分分析(MPPCA)、多阶段学习与RANSAC.这些方法取得了一定的效果,但是还有很多局限性,如计算复杂度太高,对噪音敏感等.最近,利用稀疏表示和低秩表示进行子空间聚类的研究得到了广泛的关注,研究人员提出了一系列相关的新型子空间聚类算法,如稀疏子空间聚类(SSC)[5,6]、低秩表示(LRR)[4,7]、低秩子空间聚类(LRSC)[8]和低秩稀疏子空间聚类(LRSSC)[9],这些方法的本质是每一个数据点可以通过其他数据点稀疏表示或者低秩表示得到.尽管稀疏子空间聚类(SSC)和低秩表示(LRR)取得了巨大的成功,仍然有很多问题没有解决.特别是稀疏表示和低秩表示的计算复杂度相当高,尤其是当数据的维数很高的时候[6].为了解决这个问题,通常的做法是在应用这类聚类算法之前对数据进行降维预处理.一些降维方法如主成分分析(PCA)或者随机投影(RP)可以有效降低数据维数.然而,一个良好学习的投影矩阵可以在更低的数据维度上得到更好的聚类效果.基于低维隐空间的稀疏表示已经有学者提出了一些方法[10,11],但是这些方法都是为分类问题进行设计,而非针对聚类问题.基于上述问题,文中提出一种基于低维隐空间的低秩稀疏子空间聚类方法(LatLRSSC),在数据降维的同时,发掘数据的稀疏和低秩表示.首先算法学习得到数据从原始空间到低维隐空间的变换矩阵,同时在这个低维的隐空间中得到数据的稀疏和低秩系数,最后利用谱聚类算法对数据样本进行分割.为了验证文中提出方法的有效性,分别在HOPKINS 155 数据集和extended Yale B 数据集上进行运动分割和人脸聚类的实验,实验结果表明,文中提出的LatLRSSC算法具有较好的聚类性能.根据文献[5,6],每一个数据点可以表示为其他数据点的稀疏线性组合,通过这些稀疏系数构造清河矩阵进行子空间聚类.也就是说,给定一个数据集X,希望找到一个系数矩阵C,满足X=XC并且diag(C)=0.可以通过求解(1)式得到解.当数据集被噪声G污染时,SSC算法假设每个数据点可以表示为X=XC+G,可以通过求解凸优化问题(2)得到解.1.2 低秩表示(LRR)低秩表示(LRR)算法和稀疏子空间聚类(SSC)算法非常类似,区别在于LRR算法的目标是寻找数据的低秩表示,而SSC算法在于寻找数据的稀疏表示.LRR通过求解凸优化问题(3)得到解.当数据集被噪声G污染时,LRR通过求解凸优化问题(4)得到解.最后,通过得到的稀疏矩阵(利用SSC或者LRR),构造亲和矩阵,在这个亲和矩阵上利用谱聚类算法,就可以得到最终的聚类结果.不同于传统的稀疏子空间聚类算法(SSC)和低秩表示(LRR),文中将数据映射到一个低维的隐空间中,同时在这个低维空间中寻求数据的低秩稀疏系数.令P∈Rt×D为一个线性变换矩阵,它将数据从原始空间RD映射到一个维数为t的隐空间中.通过目标函数的最小化,可以同时得到变换矩阵和数据集的低秩稀疏系数:其中(6)式的第一项为求取数据集的低秩系数;第二项为求取数据集的稀疏系数;第三项的主要目的是去除噪声影响;最后一项是类似于PCA的正则项,主要目的是保证映射变换不能过多丢失一些原始空间的信息;λ1和λ2为非负常数.另外,要求P正交并且归一化,这样就避免了解的退化,并且保证了优化方法的计算效率.可以注意到,(6)式是能够进行扩展的,这样就可以对位于仿射子空间中的数据进行处理.可以对优化问题(5)增加一个约束条件得到2.1 优化问题求解根据上面的定义,有下面的命题.命题1 优化问题(5)存在一个最优化的解P*,对于某些Ψ∈RN×t,N为数据样本数,P*具有以下形式直观上,命题1是说投影变换可以写成数据样本的一个线性组合.文献[12]中,这个形式已经被应用在字典学习的框架中.基于命题1,目标函数(6)可以写为其中K=YTY.约束条件变为所以,优化问题(5)可表示为其中这样,可分别通过Ψ和C来求解这个优化问题.首先固定C,目标函数就变为其中Q=ΨΨT∈RN×N.由约束条件ΨTKΨ=I可得到新的约束条件ΨΨTKΨΨT=ΨΨT或者QKQT=Q,目标函数(12)可以进一步简化为使用同样的约束条件,并且知tr(K)为一个常数,利用K=VSVT的特征值分解,得到 ,其中Ψ.这样(13)式就可以表示为利用ΨTKΨ=MTM和变换得到等价于问题(11)的优化问题:优化问题(14)就是经典的最小特征值问题.它的解就是与Δ的前l个最小特征值相关联的l个特征向量.一旦得到了最优的M*,那么最优的Ψ*就可以利用(5)式得到: 2.3 C的优化步骤固定Ψ,通过求解下列优化问题来得到C其中B=ΨTK.接下来,推导了一个解决优化问题(16)的有效方法.在ADMM框架下,引入两个辅助变量C=C1=C2来区分两个不同的范数,引入J来保证每一步都得到闭合解: 则增广拉格朗日方程为其中μ1和μ2为可调参数.每一步中,通过分别求解J,C1和C2的梯度,更新对偶变量Λ1和Λ2,可以得到ADMM每一步的迭代公式.分别定义一个软阈值操作符和奇异值软阈值操作符Πβ(X)=Uπβ(Σ)VT,其中UΣVT为B=ΨTK的瘦型奇异值分解.得到C1和C2的更新规则如下:Λ1和Λ2的更新规则如下:求解完上述优化问题后,可以得到系数矩阵C,则亲和矩阵定义为T,最后利用谱聚类算法即可得到最终聚类结果.分别验证文中提出的LatLRSSC算法在运动分割和人脸聚类两种问题上的性能.对于运动分割问题,采用Hopkins 155数据集,包含155个视屏序列.对于人脸聚类问题,采用Extended Yale B数据集,包含38类人脸图像数据.实验中,采用聚类错误率来评价聚类算法的性能:聚类错误率.对比算法采用了LRR,LRSC,SSC和LRSSC这4种应用较为广泛的子空间聚类算法.运动分割是指从视频序列中对于不同的刚体运动提取一组二维点轨迹,对这些轨迹进行聚类,实现不同运动物体的分割.这里,数据集X为2F×N维,其中N为二维轨迹的数目,F为视频的帧数.在仿射投影模型中,这些与刚体运动相关联的二维轨迹位于维数为1,2或3的仿射子空间R2F中.实验中,采用Hopkins 155运动分割数据集,其中120个视频序列由2个运动构成,35个视频序列由3个运动构成.平均来说,每一个包含2个运动的视频序列包含N=256个特征轨迹和F=30帧画面,而每一个包含3个运动的视频序列包含N=398个特征轨迹和F=29帧画面.对于每一个视频序列,这些二维轨迹通过跟踪器自动提取,并且噪音点已经手动去除.表1比较了不同算法在Hopkins 155数据集上的聚类表现.实验中,除了文中提出的算法,对于其他算法,利用PCA进行预处理,将数据集降维到4n维(n为子空间数目).从表1 可以看出,对于2个或3个运动,文中提出的算法LatLRSSC相较于其他4种方法具有较好的聚类性能,说明LatLRSSC对于运动分割问题具有很好的效果.对比其他算法可知,相对于直接采用PCA进行降维操作,LatLRSSC通过对数据集的学习能够得到更加合理的映射矩阵.给定多个人在同一角度、不同光照的人脸图像,希望将不同的人脸图像划分开来(图1).在Lambertian假设下,物体图像在固定角度、不同光照条件下位于一个近似的9维子空间中,因此,采集的多个人的人脸图像也位于这样的9维子空间中. 采用Extended Yale B数据集,数据集包含n=38个人的人脸图像(192×168像素),每个人有Ni=64张在不同光照条件下的正面图像.为了降低计算成本和存储代价,将每幅人脸图像采样到48×42像素,并将图像向量化为2 016维,因此维度D=2 016.实验中,除了文中提出的算法,对于其他算法,依然利用PCA进行降维预处理.为了研究这些算法对不同聚类数目的聚类性能,将38类人脸分成4组,前3组分别包含1~10,11~20,21~30个人的人脸图像,第四组包含31~38个人的人脸图像.对于前3组,取n∈{2,3,5,8,10};对最后一组,取n∈{2,3,5,8}.实验结果如表2所示.从表2可以看出,文中提出的LatLRSSC对不同的聚类数目均得到了更低的聚类错误率,说明了该算法优于其他算法.文中提出了一种基于隐空间的低秩稀疏子空间聚类算法.本算法是稀疏子空间聚类和低秩表示的一种扩展,该算法在聚类的过程中可以对高维数据进行降维,同时在低维空间中利用稀疏表示和低秩表示对数据进行聚类.在运动分割和人脸聚类上的实验表明,该算法具有很好的聚类性能.与大多数子空间聚类算法一样,文中假设子空间是线性的,如何将本算法在非线性子空间上进行扩展是接下来需要继续研究的工作.。
改进的稀疏子空间聚类算法张彩霞;胡红萍;白艳萍【摘要】在现有的稀疏子空间聚类算法理论基础上提出一个改进的稀疏子空间聚类算法:迭代加权的稀疏子空间聚类.稀疏子空间聚类通过解决l1最小化算法并应用谱聚类把高维数据点聚类到不同的子空间,从而聚类数据.迭代加权的l1算法比传统的l1算法有更公平的惩罚值,平衡了数据数量级的影响.此算法应用到稀疏子空间聚类中,改进了传统稀疏子空间聚类对数据聚类的性能.仿真实验对Yale B人脸数据图像进行识别分类,得到了很好的聚类效果,证明了改进算法的优越性.%Based on the existing theory of sparse subspace clustering algorithm,a modified sparse subspace clustering algorithm is put forward:iterative weighted sparse subspace clustering algorithm.In order to cluster data,sparse subspace clustering algorithm clusters high-dimensional data to different subspaces by solving minimization algorithm and applying spectralclustering.Iterative algorithm has more fair punishment value then the traditional algorithm,with balancing the influence of magnitude ofdata.The algorithm is applied to the sparse subspace clustering to improve the traditional sparse subspace clustering performance for data. Simulation experiment recognizing and classify Yale B face data image.The clustering effect is very good,proving the superiority of the improved algorithm.【期刊名称】《火力与指挥控制》【年(卷),期】2017(042)003【总页数】5页(P75-79)【关键词】稀疏子空间聚类;迭代加权;谱聚类算法;人脸识别【作者】张彩霞;胡红萍;白艳萍【作者单位】中北大学理学院,太原 030051;中北大学理学院,太原 030051;中北大学理学院,太原 030051【正文语种】中文【中图分类】TP301.6在很多实际应用中,高维数据无处不在,如计算机视觉,图像处理,运动分割,人脸识别等。
稳健的软子空间聚类算法郑素佩;封建湖【期刊名称】《西安理工大学学报》【年(卷),期】2013(29)2【摘要】Aiming at the problems that soft subspace clustering algorithm (SSC) is sensitive to noise,and based on a non-Euclidean metric,a robust soft subspace clustering algorithm (RSSC) clustering algorithm is presented.By endowing each feature of data points with a weighting function,RSSC can estimate the clustering center more accurately in noisy environment,and the robuatness of algorithm is further improved.The experimental results show that RSSC can not only select the local features of data effectively but also be robust to noise.%针对软子空间聚类算法(Soft Subspace Clustering,SSC)对噪声敏感的问题,基于非欧氏距离,提出稳健的软子空间聚类(Robust Soft Subspace Clustering,RSSC)算法.RSSC通过在数据点每一维特征上赋予数据点权函数来提高算法在噪声环境中对聚类中心估计的准确性,进而提高算法的稳健性.实验结果表明,RSSC不仅能有效地选取数据的局部特征,而且具有良好的抗噪声性.【总页数】8页(P221-227,237)【作者】郑素佩;封建湖【作者单位】长安大学理学院,陕西西安710064;长安大学理学院,陕西西安710064【正文语种】中文【中图分类】TP181【相关文献】1.特征加权优化软子空间聚类算法比传统算法的优越性分析 [J], 陈晓洁;王雯娟2.不平衡数据软子空间聚类算法在临床医学中的应用与研究 [J], 程铃钫; 陈黎飞; 赖晓燕; 林燕3.头脑风暴算法优化的乳腺MR图像软子空间聚类算法 [J], 范虹;史肖敏;姚若侠4.随机学习萤火虫算法优化的模糊软子空间聚类算法 [J], 张曦;李璠;付雪峰;谭德坤;赵嘉5.基于迁移学习的软子空间聚类算法 [J], 王丽娟;丁世飞;丁玲因版权原因,仅展示原文概要,查看原文内容请购买。