solr使用手册
- 格式:docx
- 大小:2.09 MB
- 文档页数:27

Solr安装使⽤教程⼀、安装1.1 安装jdksolr是基于lucene⽽lucene是java写的,所以solr需要jdk----当前安装的solr-7.5需要jdk-1.8及以上版本,下载安装jdk并设置JAVA_HOME即可。
jdk下载地址:1.2 安装solr下载solr,然后解压即可,windows和linux都可以下.tgz(.tgz本质是.tar.gz)和.zip解压出来都⼀样的。
solr下载地址:要注意图中的链接是下载页⾯的链接并不是solr⽂件的链接,直接wget链接就报gzip: solr-7.5.0.tgz: not in gzip format或End-of-central-directory signature not found.了。
1.3 设置系统资源限制设置最⼤进程数t和打开⽂件数为65000(可能其他⼀些资源也要修改但我安装时没见有其他问题,⽂档也没看到专门说明)ulimit -u 65000ulimit -n 65000⼆、solr基本⽤法对于没⽤过的新⼿⽽⾔,⾸先最关⼼的是怎么运⾏起来看这东西长什么样其他什么⾼级⽤法后⽽再说,这⾥我们就来做这件事。
2.1 启停进⼊解压后⽂件的bin⽬录,执⾏:# 启动./solr start# 停⽌./solr stopsolr默认拒绝以root⾝份启动,root加-force选项可以启动,但后续进⾏操作(如创建核⼼等)还是会有问题,推荐使⽤普通⽤户动。
启动完成后默认监听8983端⼝,访问可见界⾯如下2.2 solr核⼼(core)创建与删除在上⾯启动起来的页⾯可以看到solr就是就是这么⼀个界⾯简陋的东西----页⾯简单(没⼏个页⾯)加布局丑陋。
solr中⼀个核⼼(core)相当于⼀个搜索引擎,然后上传⽂件时也是上传到指定核⼼;solr可以建⽴多个solr。
solr默认没有core,我们先来创建⼀个core。
通过命令创建和删除core:# 创建core,-c指定创建的core名./solr create -c test_core1# 删除core,-c指定删除的core名./solr delete -c test_core1完成后回刷新solr界⾯,点击下拉“Core Selector”即可看到刚才建⽴的core,选择core即可进⼊core的管理界⾯,如下图。

Solr的原理及使⽤1.Solr的简介Solr是⼀个独⽴的企业级搜索应⽤服务器,它对外提供类似于Web-service的API接⼝。
⽤户可以通过http请求,向搜索引擎服务器提交⼀定格式的XML⽂件,⽣成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
2.⼯作原理solr是基于Lucence开发的企业级搜索引擎技术,⽽lucence的原理是倒排索引。
那么什么是倒排索引呢?接下来我们就介绍⼀下lucence倒排索引原理。
假设有两篇⽂章1和2:⽂章1的内容为:⽼超在卡⼦门⼯作,我也是。
⽂章2的内容为:⼩超在⿎楼⼯作。
由于lucence是基于关键词索引查询的,那我们⾸先要取得这两篇⽂章的关键词。
如果我们把⽂章看成⼀个字符串,我们需要取得字符串中的所有单词,即分词。
分词时,忽略”在“、”的“之类的没有意义的介词,以及标点符号可以过滤。
我们使⽤Ik Analyzer实现中⽂分词,分词之后结果为:⽂章1:⽂章2:接下来,有了关键词后,我们就可以建⽴倒排索引了。
上⾯的对应关系是:“⽂章号”对“⽂章中所有关键词”。
倒排索引把这个关系倒过来,变成: “关键词”对“拥有该关键词的所有⽂章号”。
通常仅知道关键词在哪些⽂章中出现还不够,我们还需要知道关键词在⽂章中出现次数和出现的位置,通常有两种位置:a.字符位置,即记录该词是⽂章中第⼏个字符(优点是关键词亮显时定位快);b.关键词位置,即记录该词是⽂章中第⼏个关键词(优点是节约索引空间、词组(phase)查询快),lucene中记录的就是这种位置。
加上出现频率和出现位置信息后,我们的索引结构变为:实现时,lucene将上⾯三列分别作为词典⽂件(Term Dictionary)、频率⽂件(frequencies)、位置⽂件 (positions)保存。
其中词典⽂件不仅保存有每个关键词,还保留了指向频率⽂件和位置⽂件的指针,通过指针可以找到该关键字的频率信息和位置信息。

Solr部署及开发一、部署1 环境要求JDK 1.6及以上版本,Tomcat 6及以上,Solr发布版本4.X。
如果使用较低版本,请查看Solr版本支持的JDK版本。
2安装步骤首先安装JDK 1.7和Tomcat 7,配置好环境变量,并下载最新版Solr,目前版本为4.6.0。
如有必要可手动修改Tomcat端口号。
为了支持中文,需要修改tomcat中conf目录下的server.xml文件,在connector 节点中添加字符编码属性URIEncoding,如下:<Connector port="8086" protocol="HTTP/1.1"connectionTimeout="20000" URIEncoding="UTF-8"redirectPort="8443" />◆运行在jetty服务器Solr可以运行在自带的jetty服务器,可按如下步骤运行起来:1、解压solr-4.6.0.zip到你想到存放的路径,比如:d:/solr2、cmd打开命令行窗口,进入d:/solr/example目录3、执行命令:java -jar start.jar4、通过第三步以后,系统会启动solr自带的jetty服务器,通过http://localhost:8983/solr/便可访问solr。
此时,solr已成功启动。
◆运行在Tomcat服务器1、solr.4.6.0.zip解压到指定的目录中,如d:/solr-4.6.0。
2、将d:/solr-4.6.0/example/webapps下的solr.war拷贝到tomcat–>weapps中。
3、新建文件夹d:/sorl_home,将d:/solr-4.6.0/example/solr目录拷贝至d:/sorl_home中,如果要配置为多核应用,可以将solr-4.6.0\example下的multicore拷贝到d:/sorl_home中,这样就会有就会有core0和core1两个应用。

Solr系列六:solr搜索详解优化查询结果(分⾯搜索、搜索结果⾼亮、查询建议、折叠展开结。
⼀、分⾯搜索1. 什么是分⾯搜索?分⾯搜索:在搜索结果的基础上进⾏按指定维度的统计,以展⽰搜索结果的另⼀⾯信息。
类似于SQL语句的group by分⾯搜索的⽰例:2. Solr中⽀持的分⾯查询字段分⾯、区间分⾯、决策树分⾯、查询分⾯2.1 字段分⾯执⾏搜索时,根据查询请求返回特定分⾯字段中找到的唯⼀值以及找到的⽂档数。
通⽤查询参数:facet:true/false 对当前搜索是否启⽤分⾯facet.query:指定⼀个额外的分⾯查询语句字段分⾯查询参数:facet.field:指定对哪个字段进⾏分⾯计算。
该参数可以多次指定以返回多个字段⽅⾯。
字段需是索引字段。
facet.sort:分⾯结果的排序⽅式:count:根据统计数量排,index:索引的词典顺序facet.limit:确定每个分⾯返回多少个唯⼀分⾯值。
可取值:整数>=-1,-1表⽰不限制,默认100。
facet.offset:对分⾯值进⾏分页,指定页偏移。
>=0 默认0。
facet.prefix:指定限制字段分⾯值必须以xxx开头,⽤以筛选分⾯值。
facet.missing:true/false,是否在分⾯字段中返回所有不包含值(值为缺失)的⽂档计数。
facet.mincount:指定分⾯结果中的分⾯值的统计数量>=mincount的才返回⽰例:sort、limit、offset、prefix、missing、mincount 可根据字段指定: f.filedname.facet.sort=count2.2 区间分⾯区间分⾯将数值或时间字段值分成⼀些区间段,按区间段进⾏统计。
区间分⾯查询参数:facet.range:指定对哪个字段计算区间分⾯。
可多次⽤该参数指定多个字段。
facet.range=price&facet.range=agefacet.range.start:起始值f.price.facet.range.start=0.0&f.age.facet.range.start=10stModified_dt.facet.range.start=NOW/DAY-30DAYSfacet.range.end:结束值f.price.facet.range.end=1000.0&f.age.facet.range.start=99stModified_dt.facet.range.end=NOW/DAY+30DAYSfacet.range.gap:间隔值,创建⼦区间。

Solr全文检索技术1.Solr介绍 152.Solr安装配置-SolrCore配置 153.Solr安装配置-Solr工程部署 104.Solr安装配置-Solr工程测试 155.Solr安装配置-多SorlCore配置 106.Solr入门--schema 207.Solr入门-安装中文分词器 158.Solr入门-自定义业务系统Field 209.Solr入门-SolrJ介绍1010.Solr入门-SolrJ索引维护 2011.Solr入门-数据导入处理器2012.Solr入门-搜索语法 1013.Solr入门-SolrJ-搜索 2014.Solr案例-需求分析 1015.Solr案例-架构设计 1516.Solr案例-Service 2017.Solr案例-Controller 2018.Solr案例-主体调试 2019.Solr案例-功能完善1【Solr介绍】1.1S olr是什么Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务。
Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引。
Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。
Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
1.2S olr与Lucene的区别Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。

Solr使用教程目录一、软件版本 (2)二、安装教程 (2)1、Solr安装教程 (2)2、solr环境搭建 (4)3、业务字段的实际配置 (7)4、dataimport 导入数据库数据 (8)5、solrj的使用 (10)6、电商平台的应用 (14)一、软件版本Solr版本号:solr-5.5.5jdk版本号:jdk1.8以上Tomcat版本号:Tomcat8.0以上二、安装教程1、Solr安装教程1.创建solrhome以及solrcore(mysolrhome、mycore 名字可以任意指定)1.1在指定的目录下新建文件夹solrhome如:D:\mysolrhome1.2将solr-5.5.4\server\solr\solr.xml拷贝至D:\mysolrhome1.3在solrhome下新建文件夹solrcore如D:\mysolrhome\mycore1.4将solr-5.5.4\server\solr\configsets\basic_configs\conf完整目录拷贝至D:\mysolrhome\mycore\下2.部署到Tomcat2.1将solr-5.5.4\server\solr-webapp\webapp 完整目录复制到Apache Tomcat 8.0.27\webapps下并重命名为solr2.2在Apache Tomcat 8.0.27\webapps\solr\WEB-INF下新建classes文件夹2.3将solr-5.5.4/server/resource/log4j.properties 拷贝至上一步创建的classes2.4把solr-5.5.4/server/lib/ext/目录下的所有jar文件复制到Apache Tomcat 8.0.27/webapp/solr/WEB-INF/lib/中3.配置solrcore3.1修改Apache Tomcat 8.0.27-solr\webapps\solr\WEB-INF\web.xml 新增<env-entry>标签,将你的solrhome配置进去。

Solr全文检索服务1企业站内搜索技术选型在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。
1.1单独使用Lucene实现单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
1.2使用Google或Baidu接口通过第三方搜索引擎提供的接口实现站内搜索,这样和第三方引擎系统依赖紧密,不方便扩展,不建议采用。
1.3使用Solr实现基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为S olr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
2什么是Solr什么是SolrSolr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。
Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引。
Solr搜索只需要发送 HTTP GET 请求,然后对 Solr返回Xml、json等格式的查询结果进行解析,组织页面布局。
Solr不提供构建UI 的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Solr与Lucene的区别Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。

solr使用手册Solr全文检索服务一、企业站内搜索技术选型在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。
1.使用Lucene实现?什么是Lucene ?Lucene是一个基于Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。
Lucene目前是Apache Jakarta(雅加达) 家族中的一个开源项目。
也是目前最为流行的基于Java开源全文检索工具包。
目前已经有很多应用程序的搜索功能是基于Lucene ,比如Eclipse 帮助系统的搜索功能。
Lucene能够为文本类型的数据建立索引,所以你只要把你要索引的数据格式转化的文本格式,Lucene 就能对你的文档进行索引和搜索●单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
2.使用Google或Baidu接口?●通过第三方搜索引擎提供的接口实现站内搜索,这样和第三方引擎系统依赖紧密,不方便扩展,不建议采用。
3.使用Solr实现? Solr是什么?Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。
Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引。
Solr 搜索只需要发送HTTP GET 请求,然后对Solr返回Xml、json等格式的查询结果进行解析,组织页面布局。
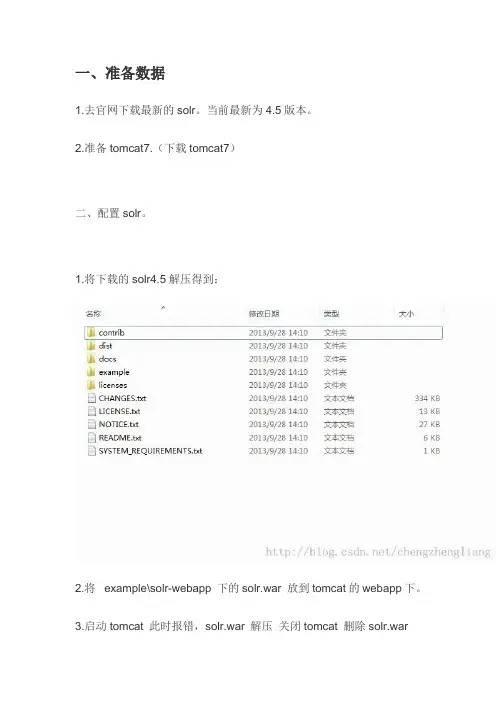
一、准备数据1.去官网下载最新的solr。
当前最新为4.5版本。
2.准备tomcat7.(下载tomcat7)二、配置solr。
1.将下载的solr4.5解压得到:2.将example\solr-webapp 下的solr.war 放到tomcat的webapp下。
3.启动tomcat 此时报错,solr.war 解压关闭tomcat 删除solr.war4.得到solr 项目5.配置solr_home :将下载的solr包中解压的example/solr 文件夹copy到d:/solr/solr_home(路径可以任意修改)。
6.打开tomcat下的webapp\solr\WEB-INF 下的web.xml,修改添加如下代码:<env-entry><env-entry-name>solr/home</env-entry-name><env-entry-value>D:/solr/solr_home</env-entry-value><env-entry-type>ng.String</env-entry-type></env-entry>7.其中<env-entry-value> 中的值即为第5步中配置的路径。
8.copy 下载包中的example\lib\ext 下的jar包全部放到tomcat 的lib 目录下。
9设置solr/collection/conf/中的solrconfig.xml 中jar包路径,将路径该对就可以了。
10.将C:\app\solr-4.5.0\solr-4.5.0\example\resources下的log4j.properties拷贝到C:\Program Files\Apache Software Foundation\Tomcat 7.0\webapps\solr\WEB-INF\classes下。

开源企业搜索引擎SOLR的应用教程2010-10目录1概述 (4)1.1企业搜索引擎方案选型 (4)1.2Solr的特性 (4)1.2.1Solr使用Lucene并且进行了扩展 (4)1.2.2Schema(模式) (5)1.2.3查询 (5)1.2.4核心 (5)1.2.5缓存 (5)1.2.6复制 (6)1.2.7管理接口 (6)1.3Solr服务原理 (6)1.3.1索引 (6)1.3.2搜索 (7)1.4源码结构 (8)1.4.1目录结构说明 (8)1.4.2Solr home说明 (9)1.4.3solr的各包的说明 (10)1.5版本说明 (11)1.5.1 1.3版本 (11)1.5.2 1.4版本 (12)1.6分布式和复制Solr 架构 (12)2Solr的安装与配置 (13)2.1在Tomcat下Solr安装 (13)2.1.1安装准备 (13)2.1.2安装过程 (13)2.1.3验证安装 (14)2.2中文分词配置 (15)2.2.1mmseg4j (15)2.2.2paoding (19)2.3多核(MultiCore)配置 (22)2.3.1MultiCore的配置方法 (22)2.3.2为何使用多core ? (23)2.4配置文件说明 (23)2.4.1schema.xml (24)2.4.2solrconfig.xml (25)3Solr的应用 (29)3.1SOLR应用概述 (29)3.1.1Solr的应用模式 (29)3.1.2SOLR的使用过程说明 (30)3.2一个简单的例子 (30)3.2.1Solr Schema 设计 (30)3.2.2构建索引 (30)3.2.3搜索测试 (31)3.3搜索引擎的规划设计 (32)3.3.1定义业务模型 (32)3.3.2定制索引服务 (34)3.3.3定制搜索服务 (34)3.4搜索引擎配置 (34)3.4.1Solr Schema 设计(如何定制索引的结构?) (34)3.5如何进行索引操作? (36)3.5.1基本索引操作 (36)3.5.2批量索引操作 (37)3.6如何进行搜索 (39)3.6.1搜索语法 (39)3.6.2排序 (42)3.6.3字段增加权重 (42)3.6.4Solr分词器、过滤器、分析器 (42)3.6.5Solr高亮使用 (46)4SolrJ的用法 (46)4.1搜索接口的调用实例 (46)4.2Solrj的使用说明 (47)4.2.1Adding Data to Solr (47)4.2.2Directly adding POJOs to Solr (49)4.2.3Reading Data from Solr (51)4.3创建查询 (51)4.4使用SolrJ 创建索引 (52)4.5Solrj包的结构说明 (53)4.5.1CommonsHttpSolrServer (53)4.5.2Setting XMLResponseParser (53)4.5.3Changing other Connection Settings (53)4.5.4EmbeddedSolrServer (54)5Solr的实际应用测试报告 (54)5.1线下压力测试报告 (54)5.2线上环境运行报告 (54)6solr性能调优 (55)6.1Schema Design Considerations (55)6.1.1indexed fields (55)6.1.2stored fields (55)6.2Configuration Considerations (55)6.2.1mergeFactor (55)6.2.2mergeFactor Tradeoffs (56)6.3Cache autoWarm Count Considerations (56)6.4Cache hit rate(缓存命中率) (56)6.5Explicit Warming of Sort Fields (56)6.6Optimization Considerations (56)6.7Updates and Commit Frequency Tradeoffs (56)6.8Query Response Compression (57)6.9Embedded vs HTTP Post (57)6.10RAM Usage Considerations(内存方面的考虑) (57)6.10.1OutOfMemoryErrors (57)6.10.2Memory allocated to the Java VM (57)7FAQ (58)7.1出现乱码或者查不到结果的排查方法: (58)1 概述1.1 企业搜索引擎方案选型由于搜索引擎功能在门户社区中对提高用户体验有着重在门户社区中涉及大量需要搜索引擎的功能需求,目前在实现搜索引擎的方案上有集中方案可供选择:1)基于Lucene自己进行封装实现站内搜索。

solr使用方法Solr是一种开源的搜索平台,基于Apache Lucene构建而成。
它提供了强大的全文检索功能和高性能的分布式搜索能力,广泛应用于各种大型网站和企业应用中。
本文将介绍Solr的使用方法,包括安装配置、数据导入、搜索查询等方面。
一、安装配置1. 下载Solr:访问官方网站,下载最新版本的Solr压缩包。
2. 解压缩:将下载的压缩包解压到指定目录。
3. 启动Solr:进入解压后的目录,执行启动命令,等待Solr启动成功。
4. 访问Solr管理界面:打开浏览器,输入Solr的地址和端口号,进入Solr的管理界面。
二、数据导入1. 创建Core:在Solr管理界面中,创建一个Core,用于存储和管理数据。
2. 定义Schema:在Core中定义Schema,指定数据的字段类型、索引配置等。
3. 导入数据:将数据准备好,使用Solr提供的数据导入工具,将数据导入到Core中。
三、搜索查询1. 构建查询请求:使用Solr提供的查询语法,构建查询请求。
2. 发送查询请求:将查询请求发送给Solr服务器,等待返回结果。
3. 解析查询结果:解析返回的结果,获取需要的信息。
四、高级功能1. 分页查询:通过设置start和rows参数,实现分页查询功能。
2. 排序:通过设置sort参数,实现结果的排序。
3. 过滤查询:通过设置fq参数,实现对结果的过滤。
4. 高亮显示:通过设置hl参数,实现搜索关键词的高亮显示。
5. 聚合统计:通过设置facet参数,实现对搜索结果的聚合统计。
五、性能优化1. 索引优化:通过优化索引结构、字段配置等,提升索引的性能。
2. 查询优化:通过合理使用缓存、调整查询参数等,提升查询的性能。
3. 集群部署:将Solr部署到多台服务器上,实现分布式搜索,提升系统的吞吐量和可用性。
六、常见问题解决1. 乱码问题:通过设置字符集、使用适当的分词器等,解决乱码问题。
2. 性能问题:通过调整配置参数、优化查询语句等,解决性能问题。
Java搜索服务Solr操作指南Java搜索服务Solr操作指南 (1)1. 什么是Solr (3)2. Solr服务器搭建与配置 (3)2.1. 服务器搭建 (3)2.2. 配置业务域 (4)2.3. 删除所有数据(扩充,可不了解) (5)3. Java中SolrJ的使用 (6)3.1. SolrJ使用前配置 (6)3.2. 添加文档 (6)3.3. 删除文档 (7)3.3.1. 根据id删除 (7)3.3.2. 根据查询删除 (7)3.3. 查询索引库 (8)3.3.1. 简单查询 (8)3.3.2. 带高亮显示查询 (9)4. 关于Solr集群SolrCloud (10)5. Solr集群的搭建 (11)5.1. Zookeeper集群搭建 (11)5.2. Solr集群的搭建 (13)5.3. Solr集群分片与删除处理 (14)6. 使用SolrJ操作集群 (14)6.1. SolrJ使用前配置 (14)6.2. 添加文档 (15)6.3. 查询文档 (15)1. 什么是SolrSolr是一个独立的基于全文检索的企业级搜索应用服务器。
将文档通过Http 利用XML加载到Solr的搜索集合中;然后用户通过Http Get操作发送查找请求,并得到搜索的返回结果。
2. Solr服务器搭建与配置2.1. 服务器搭建Solr是由Java开发的,所以服务器的搭建需要Java环境,同时这里介绍在Linux系统中采用Tomcat进行Solr服务搭建步骤。
步骤如下:第一步:准备Tomcat压缩包和Solr压缩包第二步:上传到Linux系统,并解压两个压缩包。
第三步:找到Solr解压包目录中的/example/webapps/solr.war文件复制到tomcat解压包目录中的/webapps文件夹下,然后cd到tomcat的bin目录,运行tomcat,将会自动把solr.war文件进行解压。
第四步:将Solr解压包目录/example/lib/ext/中的所有jar包复制到刚刚解压的solr工程目录路径/WEB-INF/lib/的文件夹下面。
SOLR使用手册1.SolrCloud安装和使用SolrCloud安装1、首先解压solr-4.4.0压缩文件,复制solr.war到tomcat的webapps下。
2、启动tomcat,用来解压solr.war文件,然后关闭tomcat。
3、拷贝solr-4.4.0\example\lib\ext下的jar到webapps\solr\WEB-INFO\lib下。
webapps\solr\WEB-INFO下新建classes文件夹,将solr-4.4.0\example\resources的log4j.properties拷贝到classes下。
4、在webapps\solr下新建solr_home文件夹,把solr-4.4.0\example\solr下的所有内容拷贝到solr_home下。
为了理解的方便,可以把webapps\solr\solr_home\collection1\conf移到webapps\solr\solr_home下。
5、修改\webapps\solr\WEB-INFO\web.xml文件。
添加如下内容。
<env-entry><env-entry-name>solr/home</env-entry-name><env-entry-value>D:/java/apache-tomcat-6.0.32/webapps/solr/solr_home</env-entry-value><en v-entry-type>ng.String</env-entry-type></env-entry>6、上传solr配置文件java -classpath d:\lib\*;d:\lib\apache-solr-solrj-4.0.0.jar org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost 127.0.0.1:2181,192.168.1.207:2181,192.168.1.208:2181 -confdir E:\tomcatcluster\collection1\conf -confname testconfclasspath:参数总是报错找不到solrj.jar,干脆把其加入classpath中;lib目录中包含solr.war 中的lib包所有内容zkhost:zookeeper的服务器地址列表;confdir:solr的配置文件目录,包含schema,solrconfig等文件;confname:起个名,下面有用单机例子:java -classpath D:\java\apache-tomcat-6.0.32\webapps\solr\WEB-INF\lib\*;D:\java\apache-tomcat-6.0.32\weba pps\solr\WEB-INF\lib\solr-solrj-4.6.1.jar org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost 127.0.0.1:2181 -confdir D:\java\apache-tomcat-6.0.32\webapps\solr\solr_home\conf -confname testconfjava -classpath D:\java\apache-tomcat-6.0.32\webapps\solr\WEB-INF\lib\*;D:\java\apache-tomcat-6.0.32\weba pps\solr\WEB-INF\lib\solr-solrj-4.4.0.jar org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost 127.0.0.1:2181 -confdir D:\java\apache-tomcat-6.0.32\webapps\solr\solr_home\conf -confname testconf7、将上传的配置文件和collection联系起来java -classpath d:\lib\*;d:\lib\apache-solr-solrj-4.0.0.jar org.apache.solr.cloud.ZkCLI -cmd linkconfig -collection europe-collection -confname testconf -zkhost 127.0.0.1:2181,192.168.1.207:2181,192.168.1.208:2181collection:collection的名字,后面有用,要记住单机例子:java -classpath D:\java\apache-tomcat-6.0.32\webapps\solr\WEB-INF\lib\*;D:\java\apache-tomcat-6.0.32\weba pps\solr\WEB-INF\lib\solr-solrj-4.6.1.jar org.apache.solr.cloud.ZkCLI -cmd linkconfig -collection mycollection -confname testconf -zkhost 127.0.0.1:2181java -classpath D:\java\apache-tomcat-6.0.32\webapps\solr\WEB-INF\lib\*;D:\java\apache-tomcat-6.0.32\weba pps\solr\WEB-INF\lib\solr-solrj-4.4.0.jar org.apache.solr.cloud.ZkCLI -cmd linkconfig -collection mycollection -confname testconf -zkhost 127.0.0.1:21818、Solrcloud和zookeeper启动时绑定1、tomcat\bin下新建一个setenv.bat文件,配置启动项第一台服务器:set JAVA_OPTS=-Dbootstrap_confdir=../webapps/solr/solr_home/conf -Dcollection.configName=testconf -Dhost=localhost -Djetty.port=8080 -DzkHost=localhost:2181 -DnumShards=2 -Xms512m -Xmx1024mecho %JAVA_OPTS%后续tomcat服务器:export JAVA_OPTS="-Dhost=107.252.142.195 -Dport=28080 -Dcollection.configName=collection1 -DzkHost=107.252.142.195:2181"添加中文分词。
solr查询参数使用说明q –查询字符串,必须的。
Solr 中用来搜索的查询。
有关该语法的完整描述,请参阅参考资料中的“Lucene QueryParser Syntax”。
可以通过追加一个分号和已索引且未进行断词的字段的名称来包含排序信息。
默认的排序是score desc,指按记分降序排序。
q=myField:Java AND otherField:developerWorks; date asc此查询搜索指定的两个字段并根据一个日期字段对结果进行排序。
start –返回第一条记录在完整找到结果中的偏移位置,0开始,一般分页用。
rows –指定返回结果最多有多少条记录,配合start 来实现分页。
sort –排序,格式:sort=<fieldname>+<desc|asc>[,<fieldname>+<desc|asc>]…。
示例:(inStock desc, price asc)表示先“inStock”降序, 再“price”升序,默认是相关性降序。
wt –(writer type)指定输出格式,可以有xml, json, php, phps, 后面solr 1.3增加的,要用通知我们,因为默认没有打开。
fq –(filter query)过虑查询,作用:在q 查询符合结果中同时是fq查询符合的,fl- field作为逗号分隔的列表指定文档结果中应返回的Field 集。
默认为“*”,指所有的字段。
“score”指还应返回记分。
例如*,score将返回所有字段及得分。
用solrj的bean时,得在query中指定query.set("fl", "*,score");q.op –覆盖schema.xml的defaultOperator(有空格时用"AND"还是用"OR"操作逻辑),一般默认指定df –默认的查询字段,一般默认指定qt –(query type)指定那个类型来处理查询请求,一般不用指定,默认是standard。
Solr使用入门指南Solr使用入门指南1.引言1.1 Solr简介1.2 Solr的主要特性1.3 Solr的应用场景2.安装和配置2.1 系统要求2.2 Solr2.3 安装Solr2.4 配置Solr3.索引和查询数据3.1 创建索引3.2 添加和更新文档3.3 查询和过滤数据3.4 排序和分页3.5 删除文档和索引3.6 事务和并发控制4.Schema和字段类型4.1 Schema.xml文件4.2 字段类型4.3 动态字段4.4 字段属性5.过滤器和分析器5.1 Tokenizer和TokenFilter 5.2 内置的过滤器和分析器5.3 自定义过滤器和分析器6.查询解析器6.1 自然语言查询解析器6.2 布尔查询解析器6.3 Phrase查询解析器6.4 范围查询解析器6.5 多关键词查询解析器7.高级搜索功能7.1 Faceted Search7.2 Spatial Search7.3 拼写检查7.4 查询建议8.分布式Solr8.1 分片和副本8.2 集群配置8.3 分布式索引和查询9.性能调优9.1 索引性能优化9.2 查询性能优化9.3 缓存调优9.4 硬件优化10.监控和管理10.1 Solr的监控工具 10.2 日志管理10.3 Solr的安全机制10.4 Solr的备份和恢复11.示例应用11.1 e-commerce应用11.2 新闻搜索应用11.3 电子图书馆应用12.附件本文档涉及附件。
法律名词及注释:- Solr:一种开源搜索平台,基于Apache Lucene构建,提供强大的全文搜索、分布式搜索和大数据处理能力。
- Schema:Solr中定义索引结构的配置文件,用于指定字段类型、字段属性等。
- Tokenizer:将输入文本拆分为单词或单个词组的组件。
- TokenFilter:对输入单词进行处理的组件,例如大小写转换、词根化等。
- Faceted Search:分层搜索,允许用户根据多个分类维度进行搜索。
Solr⼊门实战(4)--Java操作Solr本⽂主要介绍使⽤ Java 来操作 Solr,⽂中所使⽤到的软件版本:Java 1.8.0_191、Solr 8.9.0。
1、定义 Schema 信息假设⼀个描述诗⼈信息的⽂档包含如下字段:字段描述id唯⼀主键age年龄name姓名poems诗歌about简介success成就定义的 schema 信息如下:<field name="about" type="text_ik" uninvertible="true" indexed="true" stored="true"/><field name="age" type="pint" uninvertible="true" indexed="true" stored="true"/><field name="content" type="text_ik" uninvertible="true" indexed="true" stored="true" multiValued="true"/><field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/><field name="name" type="text_ik" uninvertible="true" indexed="true" stored="true"/><field name="poems" type="text_ik" uninvertible="true" indexed="true" stored="true"/><field name="success" type="text_ik" uninvertible="true" indexed="true" stored="true"/>2、Java 操作 Solr2.1、引⼊依赖<dependency><groupId>org.apache.solr</groupId><artifactId>solr-solrj</artifactId><version>8.9.0</version></dependency><dependency><groupId>org.apache.solr</groupId><artifactId>solr-core</artifactId><version>8.9.0</version></dependency>2.2、编写 demo2.2.1、增加/更新⽂档@Testpublic void update() throws IOException, SolrServerException {SolrInputDocument document = new SolrInputDocument();document.addField("id", "123456");document.addField("age", 30);document.addField("name", "李⽩2");document.addField("poems", "望庐⼭瀑布");document.addField("about", "字太⽩");document.addField("success", "创造了古代浪漫主义⽂学⾼峰、歌⾏体和七绝达到后⼈难及的⾼度");SolrInputDocument document2 = new SolrInputDocument();document2.addField("id", "123457");document2.addField("age", 31);document2.addField("name", "杜甫");document2.addField("poems", "望岳");document2.addField("about", "字⼦美");document2.addField("success", "唐代伟⼤的现实主义⽂学作家,唐诗思想艺术的集⼤成者");solrClient.add(coreName, document);solrClient.add(coreName, document2);mit(coreName, true,true);}还可以通过实体类来增加/更新⽂档:@Testpublic void update2() throws IOException, SolrServerException {PoetInfo info = new PoetInfo("123456", 40, "李⽩", "望庐⼭瀑布", "字太⽩", "创造了古代浪漫主义⽂学⾼峰、歌⾏体和七绝达到后⼈难及的⾼度"); solrClient.addBean(coreName, info);mit(coreName, true,true);}2.2.2、查询⽂档/*** 通过 MapSolrParams 查询*/@Testpublic void query() throws IOException, SolrServerException {Map<String, String> map = new HashMap<>();//查询条件map.put("q", "*:*");//要显⽰的内容map.put("fl", "id,age,name,poems");//排序⽅式map.put("sort", "id asc");MapSolrParams solrParams = new MapSolrParams(map);QueryResponse queryResponse = solrClient.query(coreName, solrParams); SolrDocumentList documents = queryResponse.getResults();("查询到{}个⽂档!", documents.getNumFound());for (SolrDocument document : documents) {String id = (String)document.getFieldValue("id");Integer age = (Integer)document.getFieldValue("age");String name = (String)document.getFieldValue("name");String poems = (String)document.getFieldValue("poems");("id={},age={},name={},poems={}", id, age, name, poems);}}/*** 通过 solrQuery 查询*/@Testpublic void query2() throws IOException, SolrServerException {SolrQuery solrQuery = new SolrQuery("*:*");solrQuery.addField("id");solrQuery.addField("age");solrQuery.addField("name");solrQuery.addField("poems");solrQuery.addSort("id", SolrQuery.ORDER.asc);//设置返回的⾏数solrQuery.setRows(10);QueryResponse queryResponse = solrClient.query(coreName, solrQuery); SolrDocumentList documents = queryResponse.getResults();("查询到{}个⽂档!", documents.getNumFound());for (SolrDocument document : documents) {String id = (String)document.getFieldValue("id");Integer age = (Integer)document.getFieldValue("age");String name = (String)document.getFieldValue("name");String poems = (String)document.getFieldValue("poems");("id={},age={},name={},poems={}", id, age, name, poems);}}/*** 查询返回实例类对象*/@Testpublic void query3() throws IOException, SolrServerException {SolrQuery solrQuery = new SolrQuery("*:*");solrQuery.addField("id");solrQuery.addField("age");solrQuery.addField("name");solrQuery.addField("poems");solrQuery.addField("about");solrQuery.addField("success");solrQuery.addSort("id", SolrQuery.ORDER.asc);//设置返回的⾏数solrQuery.setRows(10);QueryResponse queryResponse = solrClient.query(coreName, solrQuery); List<PoetInfo> list = queryResponse.getBeans(PoetInfo.class);("查询到{}个⽂档!", list.size());for (PoetInfo info : list) {(info.toString());}}2.2.3、删除⽂档/*** 根据id删除⽂档*/@Testpublic void delete() throws IOException, SolrServerException {solrClient.deleteById(coreName, "123456");mit(coreName, true,true);}/*** 根据查询删除⽂档*/@Testpublic void delete2() throws IOException, SolrServerException {solrClient.deleteByQuery(coreName, "name:杜甫");mit(coreName, true,true);}2.2.4、完整代码package com.abc.demo.general.solr;import org.apache.solr.client.solrj.beans.Field;public class PoetInfo {@Fieldprivate String id;@Fieldprivate Integer age;@Fieldprivate String name;@Fieldprivate String poems;@Fieldprivate String about;@Fieldprivate String success;public PoetInfo() {}public PoetInfo(String id, Integer age, String name, String poems, String about, String success) { this.id = id;this.age = age; = name;this.poems = poems;this.about = about;this.success = success;}@Overridepublic String toString() {return "Info{" +"id='" + id + '\'' +", age=" + age +", name='" + name + '\'' +", poems='" + poems + '\'' +", about='" + about + '\'' +", success='" + success + '\'' +'}';}public String getId() {return id;}public void setId(String id) {this.id = id;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public String getName() {return name;}public void setName(String name) { = name;}public String getAbout() {return about;}public void setAbout(String about) {this.about = about;}public String getSuccess() {return success;}public void setSuccess(String success) {this.success = success;}}PoetInfopackage com.abc.demo.general.solr;import org.apache.solr.client.solrj.SolrQuery;import org.apache.solr.client.solrj.SolrServerException;import org.apache.solr.client.solrj.impl.HttpSolrClient;import org.apache.solr.client.solrj.response.QueryResponse;import mon.SolrDocument;import mon.SolrDocumentList;import mon.SolrInputDocument;import mon.params.MapSolrParams;import org.junit.After;import org.junit.Before;import org.junit.Test;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.IOException;import java.util.HashMap;import java.util.List;import java.util.Map;public class SolrCase {private static Logger logger = LoggerFactory.getLogger(SolrCase.class);private HttpSolrClient solrClient;private String coreName = "new_core";@Beforepublic void before() {solrClient = new HttpSolrClient.Builder("http://10.40.100.69:8983/solr").withConnectionTimeout(10000).withSocketTimeout(60000).build();}@Afterpublic void after() throws IOException {solrClient.close();}@Testpublic void update() throws IOException, SolrServerException {SolrInputDocument document = new SolrInputDocument();document.addField("id", "123456");document.addField("age", 30);document.addField("name", "李⽩2");document.addField("poems", "望庐⼭瀑布");document.addField("about", "字太⽩");document.addField("success", "创造了古代浪漫主义⽂学⾼峰、歌⾏体和七绝达到后⼈难及的⾼度"); SolrInputDocument document2 = new SolrInputDocument();document2.addField("id", "123457");document2.addField("age", 31);document2.addField("name", "杜甫");document2.addField("poems", "望岳");document2.addField("about", "字⼦美");document2.addField("success", "唐代伟⼤的现实主义⽂学作家,唐诗思想艺术的集⼤成者");solrClient.add(coreName, document);solrClient.add(coreName, document2);mit(coreName, true,true);}@Testpublic void update2() throws IOException, SolrServerException {PoetInfo info = new PoetInfo("123456", 40, "李⽩", "望庐⼭瀑布", "字太⽩", "创造了古代浪漫主义⽂学⾼峰、歌⾏体和七绝达到后⼈难及的⾼度"); solrClient.addBean(coreName, info);mit(coreName, true,true);}/*** 通过 MapSolrParams 查询*/@Testpublic void query() throws IOException, SolrServerException {Map<String, String> map = new HashMap<>();//查询条件map.put("q", "*:*");//要显⽰的内容map.put("fl", "id,age,name,poems");//排序⽅式map.put("sort", "id asc");MapSolrParams solrParams = new MapSolrParams(map);QueryResponse queryResponse = solrClient.query(coreName, solrParams);SolrDocumentList documents = queryResponse.getResults();("查询到{}个⽂档!", documents.getNumFound());for (SolrDocument document : documents) {String id = (String)document.getFieldValue("id");Integer age = (Integer)document.getFieldValue("age");String name = (String)document.getFieldValue("name");String poems = (String)document.getFieldValue("poems");("id={},age={},name={},poems={}", id, age, name, poems);}}/*** 通过 solrQuery 查询*/@Testpublic void query2() throws IOException, SolrServerException {SolrQuery solrQuery = new SolrQuery("*:*");solrQuery.addField("id");solrQuery.addField("age");solrQuery.addField("name");solrQuery.addField("poems");solrQuery.addSort("id", SolrQuery.ORDER.asc);//设置返回的⾏数solrQuery.setRows(10);QueryResponse queryResponse = solrClient.query(coreName, solrQuery);SolrDocumentList documents = queryResponse.getResults();("查询到{}个⽂档!", documents.getNumFound());for (SolrDocument document : documents) {String id = (String)document.getFieldValue("id");Integer age = (Integer)document.getFieldValue("age");String name = (String)document.getFieldValue("name");String poems = (String)document.getFieldValue("poems");("id={},age={},name={},poems={}", id, age, name, poems);}}/*** 查询返回实例类对象*/@Testpublic void query3() throws IOException, SolrServerException {SolrQuery solrQuery = new SolrQuery("*:*");solrQuery.addField("id");solrQuery.addField("age");solrQuery.addField("name");solrQuery.addField("poems");solrQuery.addField("about");solrQuery.addField("success");solrQuery.addSort("id", SolrQuery.ORDER.asc);//设置返回的⾏数solrQuery.setRows(10);QueryResponse queryResponse = solrClient.query(coreName, solrQuery);List<PoetInfo> list = queryResponse.getBeans(PoetInfo.class);("查询到{}个⽂档!", list.size());for (PoetInfo info : list) {(info.toString());}}/*** 根据id删除⽂档*/@Testpublic void delete() throws IOException, SolrServerException {solrClient.deleteById(coreName, "123456");mit(coreName, true,true);}/*** 根据查询删除⽂档*/@Testpublic void delete2() throws IOException, SolrServerException {solrClient.deleteByQuery(coreName, "name:杜甫");mit(coreName, true,true);}}SolrCase3、Java 操作 SolrCloudJava 操作 SolrCloud 与 Java 操作 Solr 很类似,主要区别有:1、连接使⽤的类不同,连接 Solr 使⽤的是 HttpSolrClient,连接 SolrColud 使⽤的是 CloudHttp2SolrClient。
Solr学习文档1.Solr的安装部署a)下载Apache-Solr-1.4b)解压文件,在dist下载拿到Solr.war文件c)把Solr文件放在Tomcat/WebApps下面d)再把解压文件exsmplex下的solr放在一个特定位置。
然后记录其路径e)然后Tomcat会根据Solr.war生成一个Solr文件夹,在这个文件夹里面找到web.xmlf)更改web.xml里面的配置<env-entry><env-entry-name>solr/home</env-entry-name><env-entry-value>exsmplex下solr存放的路径</env-entry-value><env-entry-type>ng.String</env-entry-type></env-entry>g)然后进行访问。
出现“Welcome to Solr”2.中文分词a)下载mmseg4j-1.8.3.zipb)配置Solr下的Schema.xmlc)添加fieldType以及field3.配置文件a)Schema.xml 这个相当于数据表配置文件,它定义了加入索引的数据的数据类型的i.在fields结点内定义具体的字段(类似数据库中的字段),就是filed,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否有多个值)等等。
<fields><field name="content"type="text"indexed="true"stored="false"/><field name="keywords"type="keyword_text"indexed="true"stored="false"multiValued="true"/><field name="all"type="text"indexed="true"stored="false"multiValued="true"/></fields>b)SolrConfig配置Solr一些基本信息4.Solr Multicore新特性:一个Tomcat配置多个Solr<?xml version="1.0"encoding="UTF-8"?><solr persistent="false"><cores adminPath="/admin/cores"><core name="core0"instanceDir="core0"/><core name="core1"instanceDir="core1"/></cores></solr>5.通过httpClient建立索引public static final String SOLR_URL="http://localhost/solr/core0";public static void commit(){Date date=new Date();SolrServer solr=new CommonsHttpSolrServer(SOLR_URL);SolrInputDocument sid=new SolrInputDocument();sid.addField("id",i);solr.add(sid);mit();6.Solr查询参数说明在做solr查询的时候,solr提供了很多参数来扩展它自身的强大功能!以下是使用频率最高的一些参数!具体请看1.常用q - 查询字符串,必须的。
Solr全文检索服务一、企业站内搜索技术选型⏹在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。
1.使用Lucene实现?什么是Lucene ?⏹Lucene是一个基于Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。
Lucene目前是Apache Jakarta(雅加达) 家族中的一个开源项目。
也是目前最为流行的基于Java开源全文检索工具包。
目前已经有很多应用程序的搜索功能是基于Lucene ,比如Eclipse 帮助系统的搜索功能。
Lucene能够为文本类型的数据建立索引,所以你只要把你要索引的数据格式转化的文本格式,Lucene 就能对你的文档进行索引和搜索●单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
2.使用Google或Baidu接口?●通过第三方搜索引擎提供的接口实现站内搜索,这样和第三方引擎系统依赖紧密,不方便扩展,不建议采用。
3.使用Solr实现? Solr是什么?⏹Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。
Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
⏹Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引。
Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr返回Xml、json等格式的查询结果进行解析,组织页面布局。
Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
●基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为Solr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
●Solr的特点:1.基于标准的开放接口:Solr搜索服务器支持通过XML、JSON和HTTP查询和获取结果。
2.易管理:Solr可以通过HTML页面管理,Solr配置通过XML完成。
3.可伸缩性:能够有效地复制到另外一个Solr搜索服务器。
4.灵活的插件体系:新功能能够以插件的形式方便的添加到Solr服务器上。
5.强大的数据导入功能:数据库和其他结构化数据源现在都可以导入、映射和转化。
⏹Solr 与Lucene的架构图⏹Solr与 Lucene的区别1. Solr与Lucene 并不是竞争对立关系,恰恰相反Solr 依存于Lucene,因为Solr底层的核心技术是使用Lucene 来实现的。
2. Solr和Lucene的本质区别有以下三点:搜索服务器,企业级和管理。
Lucene本质上是搜索库,不是独立的应用程序,而Solr是。
Lucene专注于搜索底层的建设,而Solr专注于企业应用。
Lucene不负责支撑搜索服务所必须的管理,而Solr负责。
所以说,一句话概括Solr是Lucene面向企业搜索应用的扩展。
二、Solr的安装配置下载solr的解压包并解压/solr/此教程使用的是solr5.0bin:solr的运行脚本contrib:solr的软件/插件,用于增强solr的功能。
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
docs:solr的API文档example:solr工程的例子目录:example/solr:该目录是一个包含了默认配置信息的Solr的Core目录。
example/multicore:该目录包含了在Solr的multicore中设置的多个Core目录。
licenses:solr相关的一些许可信息server:solr的服务配置信息以及solr的实例项目。
⏹运行环境1.solr 需要运行在一个Servlet容器中,Solr5.0要求jdk使用1.7以上,Solr默认提供Jetty(java写的Servlet容器),本教程使用Tocmat作为Servlet容器,环境如下●Solr : solr5.0●Jdk :jdk1.7.0_72●Tomcat:apache-tomcat-7.0.53⏹Solr与tomcat整合加载solr在启动时依赖jar(jar包就在contrib与dist文件夹中)1.SolrHome是Solr运行的主目录,目录中包括了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore,一个SolrHome可以包括多个SolrCore (Solr实例),每个SolrCore提供单独的搜索和索引服务。
说明:Cmfz_solr:叫做一个Solr运行实例SolrCore,SolrCore名称不固定,一个solr 运行实例对外单独提供索引和搜索接口。
solrHome中可以创建多个solr运行实例SolrCore。
一个solr的运行实例对应一个索引目录。
conf是SolrCore的配置文件目录。
data目录存放索引文件需要创建。
◆手动创建solr实例(cmfz_solr)◆Solrconfig.xml,在cmfz_solr的conf目录下,它是SolrCore运行的配置文件solr工程部署1. 拷贝jar包2. 拷贝日志配置文件3. 修改tomcat webapps下的webapp\solr\WEB-INF\web.xml文件a) 配置solrhome启动tomcat,访问http:localhost:9999/solr 进入solr管理页面Solr core 介绍1.Analysis(重点)2.Dataimporta)可以定义数据导入处理器,从关系数据库将数据导入到Solr索引库中。
3.Document(重点)a)通过此菜单可以创建索引、更新索引、删除索引等操作,界面如下:/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
/delete 表示删除索引4.Query(重点)通过/select执行搜索索引,必须指定“q”查询条件方可搜索。
三、Solr的索引⏹Scheam.xml1.schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。
主要包括FieldTypes、Fields和其他的一些缺省设置。
⏹FieldType域类型定义1.下边“text_general”是Solr默认提供的FieldType,通过它说明FieldType定义的内容:FieldType子结点包括:name,class,positionIncrementGap等一些参数:Name: 是FieldType的名字Class:是Solr提供的包solr.TextField,solr.TextField 允许用户通过分析器来定制索引和查询,分析器包括一个分词器(tokenizer)和多个过滤器(filter)positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误,此值相当于Lucene的短语查询设置slop值,根据经验设置为100。
在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤搜索分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,这里还用到了solr.SynonymFilterFactory同义词过滤器。
2.Field定义在fields结点内定义具体的Field,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否存储多个值)等属性。
如下:<field name="name" type="text_general" indexed="true" stored="true"/><field name="features" type="text_general" indexed="true" stored="true" mu ltiValued="true"/>multiValued:该Field如果要存储多个值时设置为true,solr允许一个Field存储多个值,比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图),通过使用solr查询要看出返回给客户端是数组。
a)uniqueKey:Solr中默认定义唯一主键key为id域,如下:Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。
注意在创建索引时必须指定唯一约束。
b)copyField复制域:copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索:比如,输入关键字搜索title标题内容content,定义title、content、text 的域:根据关键字只搜索text域的内容就相当于搜索title和content,将title和content复制到text中,如下:(注意:该field的mutiValued 必须为true)c)dynamicField(动态字段)动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个dynamicField,name 为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
···⏹创建索引1.通过solr的管理页面操作⏹搜索索引1.通过solr的管理页面操作索引维护使用/update进行索引维护,进入Solr管理界面SolrCore下的Document下:⏹删除索引四、Analyzer 中文分词器⏹安装中文分词器1.下载ik相关jarsolr-analyzer-extra-5.1.0.jar注意:ext.dic和stopword.dic必须保存成无BOM的utf-8类型。