存储过程与用户自定义函数
- 格式:doc
- 大小:86.00 KB
- 文档页数:5


存储过程和函数的区别 存储过程和函数的区别你想知道吗?下⾯是店铺给⼤家整理的存储过程和函数的区别,供⼤家参阅! 存储过程和函数的区别 存储过程和函数的不同之处在于: 函数必须有⼀个且必须只有⼀个返回值,并且还要制定返回值的数值类型。
存储过程可以有返回值,也可以没有返回值,甚⾄可以有多个返回值,所有的返回值必须由输⼊IN或者是输出OUT参数进⾏指定。
两者赋值的⽅式不同: 函数可以采⽤select ...into ...⽅式和set值得⽅式进⾏赋值,只能⽤return返回结果集。
过程可以使⽤select的⽅式进⾏返回结果集。
使⽤⽅法不同: 函数可以直接⽤在sql语句当中,可以⽤来拓展标准的sql语句。
存储过程,需要使⽤call进⾏单独调⽤,不可以嵌⼊sql语句当中。
函数中函数体的限制较多,不能使⽤显式或隐式⽅式打开transaction、commit、rollback、set autocommit=0等。
但是存储过程可以使⽤⼏乎所有的失sql语句。
存储过程种类 1系统存储过程 以sp_开头,⽤来进⾏系统的各项设定.取得信息.相关管理⼯作。
2本地存储过程 ⽤户创建的存储过程是由⽤户创建并完成某⼀特定功能的存储过程,事实上⼀般所说的存储过程就是指本地存储过程。
3临时存储过程 分为两种存储过程: ⼀是本地临时存储过程,以井字号(#)作为其名称的第⼀个字符,则该存储过程将成为⼀个存放在tempdb数据库中的本地临时存储过程,且只有创建它的⽤户才能执⾏它; ⼆是全局临时存储过程,以两个井字号(##)号开始,则该存储过程将成为⼀个存储在tempdb数据库中的全局临时存储过程,全局临时存储过程⼀旦创建,以后连接到服务器的任意⽤户都可以执⾏它,⽽且不需要特定的权限。
4远程存储过程 在SQL Server2005中,远程存储过程(Remote Stored Procedures)是位于远程服务器上的存储过程,通常可以使⽤分布式查询和EXECUTE命令执⾏⼀个远程存储过程。



DB2常⽤sql语句转DB2 提供了关连式资料库的查询语⾔sql(structured query language),是⼀种⾮常⼝语化、既易学⼜易懂的语法。
此⼀语⾔⼏乎是每个资料库系统都必须提供的,⽤以表⽰关连式的操作,包含了资料的定义(ddl)以及资料的处理(dml)。
sql原来拼成sequel,这语⾔的原型以"系统 r"的名字在 ibm 圣荷西实验室完成,经过ibm内部及其他的许多使⽤性及效率测试,其结果相当令⼈满意,并决定在系统r 的技术基础发展出来 ibm 的产品。
⽽且美国国家标准学会(ansi)及国际标准化组织(iso)在1987遵循⼀个⼏乎是以 ibm sql 为基础的标准关连式资料语⾔定义。
⼀、资料定义 DDL(data definition language)资料定语⾔是指对资料的格式和形态下定义的语⾔,他是每个资料库要建⽴时候时⾸先要⾯对的,举凡资料分哪些表格关系、表格内的有什麽栏位主键、表格和表格之间互相参考的关系等等,都是在开始的时候所必须规划好的。
1、建表格:create table table_name(column1 datatype [not null] [not null primary key],column2 datatype [not null],...)说明:datatype --是资料的格式,详见表。
nut null --可不可以允许资料有空的(尚未有资料填⼊)。
primary key --是本表的主键。
2、更改表格 alter table table_nameadd column column_name datatype说明:增加⼀个栏位(没有删除某个栏位的语法。
alter table table_nameadd primary key (column_name)说明:更改表得的定义把某个栏位设为主键。
alter table table_namedrop primary key (column_name)说明:把主键的定义删除。



sql 存储过程中调用自定义函数自定义函数在SQL存储过程中的调用SQL存储过程是一段预定义的SQL代码集合,可以在数据库中进行重复使用。
而自定义函数是一段可重用的SQL代码,用于执行特定功能并返回一个值。
在SQL存储过程中,我们可以调用自定义函数来实现更加复杂的逻辑和计算。
我们需要创建一个自定义函数。
在SQL中,可以使用CREATE FUNCTION语句来定义一个函数,指定函数的名称、参数和返回值的数据类型,以及函数的主体逻辑。
例如,我们可以创建一个自定义函数来计算两个数的和:```CREATE FUNCTION calculate_sum(a INT, b INT)RETURNS INTBEGINDECLARE result INT;SET result = a + b;RETURN result;END;```在上述代码中,我们定义了一个名为calculate_sum的函数,它接受两个整数参数a和b,并返回一个整数类型的结果。
函数的主体逻辑是将a和b相加,并将结果赋值给变量result,然后通过RETURN语句返回结果。
接下来,我们可以在SQL存储过程中调用这个自定义函数。
在存储过程中,可以使用SELECT语句来调用函数并获取返回值。
例如,我们可以创建一个存储过程来计算两个数的和并输出结果:```CREATE PROCEDURE calculate_and_output_sum(a INT, b INT) BEGINDECLARE sum_result INT;SET sum_result = (SELECT calculate_sum(a, b));SELECT 'The sum of ' || a || ' and ' || b || ' is ' || sum_result; END;```在上述代码中,我们定义了一个名为calculate_and_output_sum 的存储过程,它接受两个整数参数a和b。

触发器、存储过程和函数三者有何区别四什么时候用存储过程?存储过程就是程序,它是经过语法检查和编译的SQL语句,所以运行特别快。
触发器是特殊的存储过程,存储过程需要程序调用,而触发器会自动执行;你所说的函数是自定义函数吧,函数是根据输入产生输出,自定义只不过输入输出的关系由用户来定义。
在什么时候用触发器?要求系统根据某些操作自动完成相关任务,比如,根据买掉的产品的输入数量自动扣除该产品的库存量。
什么时候用存储过程?存储过程就是程序,它是经过语法检查和编译的SQL语句,所以运行特别快。
存储过程和用户自定义函数具体的区别先看定义:存储过程存储过程可以使得对数据库的管理、以及显示关于数据库及其用户信息的工作容易得多。
存储过程是SQL 语句和可选控制流语句的预编译集合,以一个名称存储并作为一个单元处理。
存储过程存储在数据库内,可由应用程序通过一个调用执行,而且允许用户声明变量、有条件执行以及其它强大的编程功能。
存储过程可包含程序流、逻辑以及对数据库的查询。
它们可以接受参数、输出参数、返回单个或多个结果集以及返回值。
可以出于任何使用SQL 语句的目的来使用存储过程,它具有以下优点:·可以在单个存储过程中执行一系列SQL 语句。
·可以从自己的存储过程内引用其它存储过程,这可以简化一系列复杂语句。
·存储过程在创建时即在服务器上进行编译,所以执行起来比单个SQL 语句快。
用户定义函数函数是由一个或多个Transact-SQL 语句组成的子程序,可用于封装代码以便重新使用。
Microsoft? SQL Server? 2000 并不将用户限制在定义为Transact-SQL 语言一部分的内置函数上,而是允许用户创建自己的用户定义函数。
可使用CREATE FUNCTION 语句创建、使用ALTER FUNCTION 语句修改、以及使用DROP FUNCTION 语句除去用户定义函数。
每个完全合法的用户定义函数名(database_name.owner_name.function_name) 必须唯一。
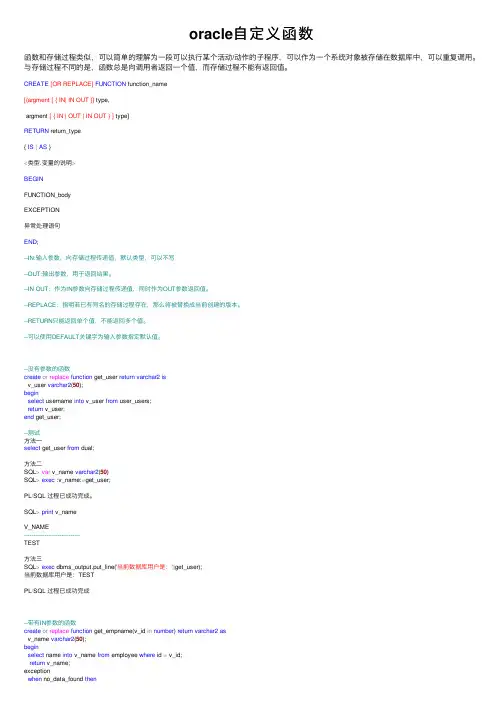
oracle⾃定义函数函数和存储过程类似,可以简单的理解为⼀段可以执⾏某个活动/动作的⼦程序,可以作为⼀个系统对象被存储在数据库中,可以重复调⽤。
与存储过程不同的是,函数总是向调⽤者返回⼀个值,⽽存储过程不能有返回值。
CREATE[OR REPLACE]FUNCTION function_name[(argment [ { IN| IN OUT }] type,argment [ { IN | OUT | IN OUT } ] type]RETURN return_type{ IS|AS }<类型.变量的说明>BEGINFUNCTION_bodyEXCEPTION异常处理语句END;--IN:输⼊参数,向存储过程传递值,默认类型,可以不写--OUT:输出参数,⽤于返回结果。
--IN OUT:作为IN参数向存储过程传递值,同时作为OUT参数返回值。
--REPLACE:指明若已有同名的存储过程存在,那么将被替换成当前创建的版本。
--RETURN只能返回单个值,不能返回多个值。
--可以使⽤DEFAULT关键字为输⼊参数指定默认值。
--没有参数的函数create or replace function get_user return varchar2isv_user varchar2(50);beginselect username into v_user from user_users;return v_user;end get_user;--测试⽅法⼀select get_user from dual;⽅法⼆SQL>var v_name varchar2(50)SQL>exec :v_name:=get_user;PL/SQL 过程已成功完成。
SQL>print v_nameV_NAME------------------------------TEST⽅法三SQL>exec dbms_output.put_line('当前数据库⽤户是:'||get_user);当前数据库⽤户是:TESTPL/SQL 过程已成功完成--带有IN参数的函数create or replace function get_empname(v_id in number) return varchar2asv_name varchar2(50);beginselect name into v_name from employee where id = v_id;return v_name;exceptionwhen no_data_found thenraise_application_error(-20001, '你输⼊的ID⽆效!');end get_empname;函数的调⽤:把函数作为PL/SQL中的表达式调⽤例如:假如函数getID()可以返回值,可以这样调⽤:SELECT * FROM table WHERE id=getID()创建⼀个变量⽤于接收函数的返回值例如:VARIABLE id NUMBER;EXECUTE :id := getID();PRINT(id);调⽤函数的位置:l SELECT 语句的列表部分,eg: SELECT fun(..)….l WHERE 或 HAVING 字句 eg:WHERE id=fun(…)…l ORDER BY 、CONNECT BY、START WITH、GROUP BY 字句l INSERT 语句的VALUES部分 INSERT INTO table VALUES(..,fun(),..)l UPDATE 语句的SET部分 eg:UPDATE table SET name=fun(…)l PL/SQL块要让函数可以在SQL表达式中调⽤,必须满⾜以下条件:1. 应该是stored function2. 只接收IN参数3. 传⼊参数和返回值都必须是SQL⽀持的类型,不能是PL/SQL中的特殊类型(例如boolean)函数调⽤限制1、SQL语句中只能调⽤存储函数(服务器端),⽽不能调⽤客户端的函数。
MySQL中的自定义函数与存储过程的开发与调试1. 引言在数据库开发中,自定义函数和存储过程是非常重要的工具。
它们可以简化复杂的业务逻辑,提高查询和处理数据的效率。
本文将通过介绍MySQL中自定义函数和存储过程的开发与调试,帮助读者深入了解和掌握这两个功能的使用方法。
2. 自定义函数的开发与调试自定义函数是MySQL中的一个强大特性,它允许开发者自己定义并使用自己的函数。
在开发过程中,我们可以使用一些内置函数,如COUNT、SUM等,但有时候我们需要实现一些特定的功能,这时自定义函数就派上用场了。
在MySQL中,自定义函数的开发主要包括以下几个步骤:2.1 创建函数在MySQL中,可以使用CREATE FUNCTION语句来创建函数。
例如,我们希望实现一个函数,计算两个整数的和,可以使用以下语句: CREATE FUNCTION addTwoIntegers(a INT, b INT) RETURNS INTBEGINDECLARE result INT;SET result = a + b;RETURN result;END;在上述代码中,我们创建了一个名为addTwoIntegers的函数,它接受两个整数类型的参数,并返回一个整数类型的值。
函数体部分采用BEGIN...END包围起来,其中使用DECLARE语句声明了一个变量result,并使用SET语句给result 赋值。
最后,使用RETURN语句返回计算结果。
2.2 调用函数完成函数的创建后,我们可以通过SELECT语句来调用这个函数。
例如,我们想计算两个整数10和20的和,可以使用以下语句:SELECT addTwoIntegers(10, 20);执行以上语句后,MySQL会返回计算结果30。
2.3 调试函数在函数开发的过程中,我们可能会遇到一些错误或逻辑问题。
为了方便调试,MySQL提供了一些调试工具和技巧。
例如,我们可以使用SELECT语句打印中间变量的值,以检查函数的执行过程。
存储过程、触发器和用户自定义函数实验实验内容一练习教材中存储过程、触发器和用户自定义函数的例子。
教材中的BookSales数据库,在群共享中,文件名为。
实验内容二针对附件1中的教学活动数据库,完成下面的实验内容。
1、存储过程(1)创建一个存储过程,该存储过程统计“高等数学”的成绩分布情况,即按照各分数段统计人数。
(2)创建一个存储过程,该存储过程有一个参数用来接收课程号,该存储过程统计给定课程的平均成绩。
(3)创建一个存储过程,该存储过程将学生选课成绩从百分制改为等级制(即 A、B、C、D、E)。
(4)创建一个存储过程,该存储过程有一个参数用来接收学生姓名,该存储过程查询该学生的学号以及选修课程的门数。
(5)创建一个存储过程,该存储过程有两个输入参数用来接收学号和课程号,一个输出参数用于获取相应学号和课程号对应的成绩。
2、触发器(1)为study表创建一个UPDATE触发器,当更新成绩时,要求更新后的成绩不能低于原来的成绩。
(2)为study表创建一个DELETE触发器,要求一次只能从study表中删除一条记录。
(3)为course表创建一个INSERT触发器,要求插入的课程记录中任课教师不能为空。
3、用户自定义函数(1)创建一个返回标量值的用户定义函数 RectangleArea:输入矩形的长和宽就能计算矩形的面积。
create function RectangleArea(@a int,@b int)returns intasbeginreturn@a*@bend(2)创建一个用户自定义函数,功能为产生一张有关学生成绩统计的报表。
该报表显示每一门课程的课程号、课程名、选修人数、本门最高分、最低分和平均分。
调用这个函数,生成相应的报表并给用户浏览。
create function student_table()returns tableasreturn(select课程号,课程名,COUNT选修人数,max最高分,min最低分,avg平均分from student_course,coursewhere=group by,)实验数据库说明教学活动数据库包括student、course和study三个基本表,三个基本表的结构说明和数据如下:(1)学生表(student)说明:sno为主键,age的范围为15~35之间,sex只能为“男”或“女”。
PostgreSQL存储过程PostgreSQL存储过程⼏年前写过很多,但是⼏年不碰⼜陌⽣了,今天给客户写了⼀个存储过程,查了⼀些资料,记录⼀下:--创建测试表create table student (id integer, name varchar(64));create table employees (id integer, age integer);--table_new 需要在外部创建create table table_new (id integer, name varchar(64), age integer);--插⼊测试数据insert into student select generate_series(1, 100), 'lili_'||cast(random()*100as varchar(2));insert into employees select generate_series(1, 50), random()*100;select count(*) from student;select count(*) from employees;--存储过程create or replace function P_DWA_ERP_LEDGER_JQ_MONTH_NEW( v_mouth varchar(8), out v_retcode text, out v_retinfo text, out v_row_num integer) AS$BODY$declarebegininsert into table_new(id, name, age) select t.id, , m.age from student t, employees m where t.id=m.id;GET DIAGNOSTICS V_ROW_NUM := ROW_COUNT;-- 执⾏成功后的返回信息V_RETCODE :='SUCCESS';V_RETINFO :='结束';--异常处理EXCEPTIONWHEN OTHERS THENV_RETCODE :='FAIL';V_RETINFO := SQLERRM;end;$BODY$language plpgsql;--调⽤存储过程select*from P_DWA_ERP_LEDGER_JQ_MONTH_NEW('12');--查看结果select count(*) from table_new;delete from table_new;vacuum table_new;create or replace function test() returns integerAS$BODY$declarev_mouth varchar(8);v_retcode text;v_retinfo text;v_row_num integer;beginv_mouth :=12;select*from P_DWA_ERP_LEDGER_JQ_MONTH_NEW(v_mouth) into v_retcode, v_retinfo, v_row_num;raise notice 'P_DWA_ERP_LEDGER_JQ_MONTH_NEW result is: %, %, %, %', v_mouth, v_retcode, v_retinfo, v_row_num;return0;end;$BODY$language plpgsql;select test();⼀、写法⽰例/blog/2194815PostgreSQL的存储过程简单⼊门存储过程事物PL/pgSQL - SQL存储过程语⾔postgreSQL存储过程写法⽰例结构PL/pgSQL是⼀种块结构的语⾔,⽐较⽅便的是⽤pgAdmin III新建Function,填⼊⼀些参数就可以了。
mysql的存储过程和函数MySQL的存储过程和函数是数据库中非常重要的两个概念,它们可以帮助我们更加高效地管理和操作数据库。
在本文中,我们将详细介绍MySQL的存储过程和函数,包括它们的定义、使用方法以及优缺点等方面。
一、MySQL的存储过程1. 定义MySQL的存储过程是一组预编译的SQL语句,它们被存储在数据库中,并可以被多次调用。
存储过程可以接受参数,并且可以返回结果集或者输出参数。
2. 使用方法创建存储过程的语法如下:CREATE PROCEDURE procedure_name ([IN|OUT|INOUT] parameter_name data_type [, ...])BEGIN-- 存储过程的SQL语句END;其中,procedure_name是存储过程的名称,parameter_name是存储过程的参数名称,data_type是参数的数据类型。
IN表示输入参数,OUT表示输出参数,INOUT表示既是输入参数又是输出参数。
调用存储过程的语法如下:CALL procedure_name ([parameter_value, ...]);其中,procedure_name是存储过程的名称,parameter_value是存储过程的参数值。
3. 优缺点存储过程的优点在于:(1)提高了数据库的性能,因为存储过程是预编译的,可以减少SQL语句的解析和编译时间。
(2)提高了数据库的安全性,因为存储过程可以控制对数据库的访问权限。
(3)提高了代码的可维护性,因为存储过程可以被多次调用,可以减少代码的重复性。
存储过程的缺点在于:(1)需要学习存储过程的语法和使用方法。
(2)存储过程的调试和测试比较困难。
二、MySQL的函数1. 定义MySQL的函数是一段预编译的代码,它们可以接受参数,并且可以返回一个值。
函数可以被多次调用,并且可以嵌套使用。
2. 使用方法创建函数的语法如下:CREATE FUNCTION function_name ([parameter_name data_type [, ...]])RETURNS return_typeBEGIN-- 函数的SQL语句END;其中,function_name是函数的名称,parameter_name是函数的参数名称,data_type是参数的数据类型,return_type是函数的返回值类型。
数据库的⼀些基本概念(视图,存储过程,函数,触发器)⼀、视图视图定义视图是从⼀个或⼏个基本表(或视图)中导出的虚拟的可视化的表。
在系统的数据字典中仅存放了视图的定义,不存放视图对应的数据。
视图特点安全:有的数据是需要保密的,如果直接把表给出来进⾏操作会造成泄密,那么可以通过创建视图把相应视图的权限给出来即可保证数据的安全。
⾼效:复杂的连接查询,每次执⾏时效率⽐较低,可以考虑新建视图,每次从视图中获取,将会提⾼效率。
定制数据:将常⽤的字段放置在视图中。
使⽤视图不会加快数据查询速度。
⼆、存储过程存储过程(Stored Procedure)是在⼤型数据库系统中,⼀组为了完成特定功能的SQL 语句集,存储在数据库中,经过第⼀次编译后调⽤不需要再次编译,⽤户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执⾏它。
存储过程是数据库中的⼀个重要对象。
优点存储过程的能⼒⼤⼤增强了SQL语⾔的功能和灵活性。
可保证数据的安全性和完整性。
通过存储过程可以使没有权限的⽤户在控制之下间接地存取数据库,从⽽保证数据的安全。
存储过程可以使相关的动作在⼀起发⽣,从⽽可以维护数据库的完整性。
在运⾏存储过程前,数据库已对其进⾏了语法和句法分析,并给出了优化执⾏⽅案。
这种已经编译好的过程可极⼤地改善SQL语句的性能。
可以降低⽹络的通信量。
使体现企业规则的运算程序放⼊数据库服务器中,以便集中控制。
三、函数在数据库中都有函数,这些函数属于系统函。
除此之外⽤户也可以编写⽤户⾃定义函数。
⽤户定义函数是存储在数据库中的代码块,可以把值返回到调⽤程序。
调⽤时如同系统函数⼀样,如max(value)函数,其value被称为参数。
函数⼀般功能⽐较简单,对于mysql函数只有传⼊参数,不像存储过程⼀样,有输⼊输出参数。
数据库函数特点如下:存储函数将向调⽤者返回⼀个且仅返回⼀个结果值。
存储函数嵌⼊在sql中使⽤的,可以在select中调⽤,就像内建函数⼀样,⽐如cos()、hex()。
--存储过程的定义默认inCreate or Replace Procedure 过程名(变量名[in,out,inout] 数据类型)[is,as]--自定义变量BeginEnd [过程名];--自定义函数的定义默认inCreate or Replace Function 函数名(变量名[in,out,inout] 数据类型)Return 数据类型[is,as]自定义变量BeginReturn 值;End [函数名];Create function XXX(saljia number) return numberAsBegin…………………Sal+20endselect XXX(sal) from emp;函数调用限制1、SQL语句中只能调用函数2、SQL只能调用带有输入参数,不能带有输出,输入输出函数3、SQL不能使用PL/SQL的特有数据类型(boolean,table,record等)4、SQL语句中调用的函数不能包含INSERT,UPDATE和DELETE语句异常错误处理一个优秀的程序都应该能够正确处理各种出错情况,并尽可能从错误中恢复。
ORACLE 提供异常情况(EXCEPTION)和异常处理(EXCEPTION HANDLER)来实现错误处理。
1.1 异常处理概念异常情况处理(EXCEPTION)是用来处理正常执行过程中未预料的事件,程序块的异常处理预定义的错误和自定义错误,由于PL/SQL程序块一旦产生异常而没有指出如何处理时,程序就会自动终止整个程序运行.有三种类型的异常错误:1.预定义( Predefined )错误ORACLE预定义的异常情况大约有24个。
对这种异常情况的处理,无需在程序中定义,由ORACLE自动将其引发。
2.非预定义( Predefined )错误即其他标准的ORACLE错误。
对这种异常情况的处理,需要用户在程序中定义,然后由ORACLE自动将其引发。
3.用户定义(User_define) 错误程序执行过程中,出现编程人员认为的非正常情况。
实验报告
课程名称:数据库系统概论实验时间:2012.5.10
学号:姓名:班级:
一、实验题目:存储过程与用户自定义函数
二、实验目的:
1)掌握SQLServer中存储过程的使用方法。
2)掌握SQLServer中用户自定义函数的使用方法。
三、实验内容:(记录每个实验步骤内容、命令、截屏结果)
(一)存储过程
1、对学生课程数据库,编写2个存储过程,分别完成下面功能:
1)统计某一门课的成绩分布情况,即按照各分数段统计人数,要求使用游标。
create proc TotalByCnoNum
(
@cno varchar(6)
)
as
begin
declare @num1 int,@num2 int, @num3 int,@num4 int,@num5 int,@grade
int,@cname char(20)
select @num1=0,@num2=0,@num3=0,@num4=0,@num5=0
declare cur_cno cursor for select grade from sc where cno=@cno
open cur_cno
fetch next from cur_cno into @grade
while@@fetch_status=0
begin
if @grade between 90 and 100
set @num1=@num1+1
else if @grade between 80 and 89
set @num2=@num2+1
else if @grade between 70 and 79
set @num3=@num3+1
else if @grade between 60 and 69
set @num4=@num4+1
else
set @num5=@num5+1
fetch next from cur_cno into @grade
end
close cur_cno
deallocate cur_cno
select @cname=cname from course where cno=@cno
print'课程:'+@cname
print'分数段人数统计'
print'=========================='
print' 90-100 : '+convert(varchar(3),@num1)
print' 80-89 : '+convert(varchar(3),@num2)
print' 70-79 : '+convert(varchar(3),@num3)
print' 60-69 : '+convert(varchar(3),@num4)
print' 不及格: '+convert(varchar(3),@num5)
print'=========================='
end
执行以下语句,显示课程号为3的成绩情况:
exec TotalByCnoNum '3'
运行结果如下:
2)将学生选课成绩从百分制改为等级制(即A、B、C、D、E五级)。
create proc ChangeGrade
as
begin
declare @dj char(1),@cname char(20),@cno char(6),@sno char(9), @grade int
declare cur_cno cursor for select grade,cno,sno from sc
open cur_cno
fetch next from cur_cno into @grade,@cno,@sno
print'学号课程号等级'
print'=========================='
while@@fetch_status=0
begin
if @grade between 90 and 100
set @dj='A'
else if @grade between 80 and 89
set @dj='B'
else if @grade between 70 and 79
set @dj='C'
else if @grade between 60 and 69
set @dj='D'
else
set @dj='E'
print @sno+' '+@cno+' '+@dj
print'--------------------------'
fetch next from cur_cno into @grade,@cno,@sno
end
print'========================='
close cur_cno
deallocate cur_cno
end
执行:
exec ChangeGrade
运行结果为:
2、对SPJ数据库,
1)创建一个存储过程ins_s_count,功能为根据提供的供应商号,供应商名,供应商所在地等信息,往S表中插入数据,并返回插入该记录之后,S表中的记录数。
create proc ins_s_count
(
@sno char(6),
@sname char(20),
@status char(10),
@city char(20)
)
as
begin
declare @num int
i nsert into s (sno,sname,status,city)values(@sno,@sname,@status,@city)
print'你添加的记录是:'
print'=================================================='
print'供应商号供应商名状态供应商所在地'
print' '+@sno+@sname+@status+@city
select @num=count(*)from s
print''
print'=================================================='
print'共有'+convert(varchar,@num)+'条记录'
end
在s表中添加如下数据:
exec ins_s_count 'S7','一建','120','杭州'
结果为:
2)调用该存储过程实现往S表中插入一条记录(‘S6’,’天盛’,‘40’‘福州’),并显示
插入该记录之后,S表中的记录数。
数据库脚本如第(1)题:
exec ins_s_count 'S6','天盛','40','福州'
(二)用户自定义函数
1.创建一个返回标量值的用户定义函数RectangleArea:输入矩形的长和宽就能计算矩形的面积。
调用该函数。
create function RectangleArea
(
@width int,
@length int
)
returns int
as
begin
return@width*@length
end
测试语句:
select dbo.RectangleArea (5,7)'面积'
2.创建一个用户自定义函数,功能为产生一张有关学生成绩统计的报表。
该报表
显示每一门课程的课程号、课程名、选修人数、本门最高分、最低分和平均分。
调用这个函数,生成相应的报表并给用户浏览。
create function totalC()
returns table
as
return
(
select o,ame,aa.num,aa.maxgrade,aa.mingrade,aa.avggrade from (
select cno,count(*)'num',max(grade)'maxgrade',min(grade)'mingrade',avg(grade) 'avggrade'
from sc group by cno
)aa,course
where o=o
)
执行:
select*from dbo.totalC()
四、实验报告书写要求
实验内容的脚本。
五、实验总结
本次实验主要巩固了存储过程的使用方法和用户自定义函数的使用方法,尤其是对游标的使用。