第25章 全字库在STemWin上的实现(GB2312编码
- 格式:pdf
- 大小:923.81 KB
- 文档页数:45

威尔取模软件使用介绍(V1.0)一、简介1.1 界面介绍二、我要取几个汉字的字模2.1 取模2.1.1 打开软件2.1.2 在中文字符集文本框中输入要取模的文字,比如“欢迎使用威尔取模软件”,如下图所示。
2.1.3 选择要取模的字体,比如我要取宋体的字模,就选择宋体。
如下图所示。
此处列出的是系统安装的所有字体,如果要取自己下载的字体的模,请先安装该字体。
2.1.4 添加我要取模的字号,宽度,高度等信息。
点击添加按钮,打开添加窗口,如下图所示。
在字号,宽度,高度框中输入你要取模的文字大小。
比如我要取16*16的点阵,就在宽度和高度中输入16、16。
然后计算字号,字号=0.75*宽度。
输入12。
点击添加。
点击添加以后回到主界面,你会发现主界面字号列表框里面就多了一种你刚刚添加的字号了。
这时候点击你刚刚添加的字号选中它,然后再在预览框中输入一个汉字,看看效果。
2.1.5 如果效果不错可以跳过这一步。
如果效果不好有以下两种情况。
1.文字太大或者太小,如下图两种情况所示。
这时候就需要重新设置字号了。
增大或者减小字号。
2.字符不居中,如下图所示。
这时候调节右下方的位置调整滑块,将文字调节居中,如下图所示。
2.1.6 选择要生成C语言格式还是二进制文件格式。
如果是C语言格式,还可以选择是否生成数组的数组名。
2.1.7 假如我只要取我刚刚设置的16*16点阵字体,那么就要选择“取选中字号”,并选中16*16那一列。
如下图所示。
2.1.8 假如我只要取中文字模,那么就勾上取模中文,同时去掉取模英文的勾,如下图所示。
2.1.9 好了,所有设置妥当,可以开始取模啦。
点击“开始取模”。
如果选择的是C语言格式则取模完成后自动弹出结果窗口,如下图所示。
三、我要取整个GBK字库或者GB2312字库的字模3.1 取模3.1.1 打开软件3.1.2 假如我要取整个GBK字库的字模,那么点击右侧“GBK字库”按钮,自动输入GBK字符集所有文字。


第18章汉字显示方式一(FontCvt的使用)本期教程主要跟大家介绍官方的小工具Font Converter的使用方法,使用官方的字体转换工具,字体的显示效果要比网上那些针对UCGUI设计的字体生成工具好非常多。
4位抗锯齿的显示效果更是非常棒。
在开头先跟大家强调两点,一个是这个字体小工具必须的使用STemWin软件包里面的,SEGGER官网下载的和MDK安装目录里面带的都是评估版,另一点是在教程中我会要求大家将要显示汉字的C文件转换为UTF-8编码,我仅仅是指的将这个显示汉字的C文件转换为UTF-8编码,这点要切记。
18. 1 使用FontCvt生成字库C文件的方法18. 2 在开发板上面实现中文显示18. 3 总结18.1使用FontCvt生成字库C文件的方法我们先讲如何用这个软件生成部分的汉字数据,这里就以“安富莱电子”五个字进行说明。
18.1.1第一步:打开选择Standard,16bit unicode18.1.2第二步:打开选择字体和字体大小18.1.3第三步:选择禁止所有的字符18.1.4第四步:用unicode软件转换函数用中文转unicode的小软件得到“安福莱电子”这5个字的unicode编码我这里在百度上面找了一个网页应用。
18.1.5第五步:在FontCvt上使能这个五个字的编码在Font Converter软件上面使能这个五个字的unicode编码,以“安”字为例它的unicode编码是5b89,这里有两种办法找这个字。
方法一:直接的在软件里面查找,根据左边的unicode编码。
方法二:通过限制范围查找。
18.1.6第六步:然后点击保存为C文件要将前面的五个字全部找到并使能以后再做保存。
18.2在开发板上面实现中文显示下面我们用18.1小节讲的汉字生成方式生成7中类型的字体。
前三种是Standard的宋体,大小是16,36和72.第四种是144*144点阵的,有没有这么大的字体,需要手动往大小选项里面填写144,并选择右侧的Pixels。




1、汉字编码原理到底怎么办到随机生成汉字的呢?汉字从哪里来的呢?是不是有个后台数据表,其中存放了所需要的所有汉字,使用程序随机取出几个汉字组合就行了呢?使用后台数据库先将所有汉字存起来使用时随机取出,这也是一种办法,但是中文汉字有这么多,怎么来制作呢?其实可以不使用任何后台数据库,使用程序就能做到这一切。
要知道如何生成汉字,就得先了解中文汉字的编码原理。
1980年,为了使每一个汉字有一个全国统一的代码,我国颁布了第一个汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,简称GB2312,这个字符集是我国中文信息处理技术的发展基础,也是国内所有汉字系统的统一标准。
到了后来又公布了国家标准GB18030-2000《信息交换用汉字编码字符集基本集的扩充》,简称GB18030,编程时如果涉及到编码和本地化的朋友应该对GB18030很熟悉。
这是是我国继GB2312-1980和GB13000-1993之后最重要的汉字编码标准,同时也是未来我国计算机系统必须遵循的基础性标准之一。
目前在中文WINDOWS操作系统中,.NET编程中默认的的代码页就是GB18030简体中文。
但是事实上如果生成中文汉字验证码只须要使用GB2312字符集就已经足够了。
字符集中除了我们平时大家都认识的汉字外,也包含了很多我们不认识平时也很少见到的汉字。
如果生成中文汉字验证码中有很多我们不认识的汉字让我们输入,对于使用拼音输入法的朋友来说可不是好事,五笔使用者还能勉强根据汉字的长相打出来,呵呵!所以对于GB2312字符集中的汉字我们也不是全都要用。
中文汉字字符可以使用区位码来表示,见汉字区位码表/view/3a63034c2e3f5727a5e96250.html汉字区位码代码表/view/908e17b91a37f111f1855be7.html其实这两个表是同一回事,只不过一个使用十六进制分区表示,一个使用区位所在的数字位置表示。
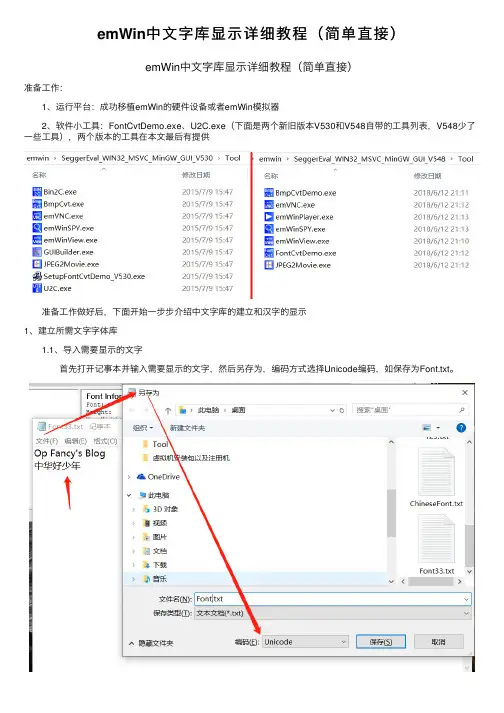
emWin中⽂字库显⽰详细教程(简单直接)emWin中⽂字库显⽰详细教程(简单直接)准备⼯作: 1、运⾏平台:成功移植emWin的硬件设备或者emWin模拟器 2、软件⼩⼯具:FontCvtDemo.exe、U2C.exe(下⾯是两个新旧版本V530和V548⾃带的⼯具列表,V548少了⼀些⼯具),两个版本的⼯具在本⽂最后有提供 准备⼯作做好后,下⾯开始⼀步步介绍中⽂字库的建⽴和汉字的显⽰1、建⽴所需⽂字字体库 1.1、导⼊需要显⽰的⽂字 ⾸先打开记事本并输⼊需要显⽰的⽂字,然后另存为,编码⽅式选择Unicode编码,如保存为Font.txt。
1.2、然后打开字体库转换软件FontCvtDemo.exe,设置好需要显⽰的字体,然后点击Edit>>Disable all characters屏蔽所有字符(默认是选择所有全字库,我们按需选择),接着点击Edit>>Read pattern file...,在对话框中选择我们上⼀步建⽴的⽂本Font.txt,我们可以在程序界⾯看到我们之前⽂本中的输⼊的字符处于选中状态,下图中只显⽰了英⽂字符的⼀部分,如果需要查看中⽂字符是否被选中可以先将中⽂字符转换为unicode码,再在程序中找到对应的位置即可,Unicode编码转换⽹址如: 1.3、成功导⼊⽂本后,在点击File>>Save as另存为c⽂件,这个C⽂件就是我们建⽴的⼩字体库2、把⽣成的字体库Font.c加⼊⼯程中并在⼯程需要调⽤的⽂件中对字体进⾏声明,代码(eMwin模拟器代码)⽰例如下:#include "GUI.h"//字体声明extern GUI_CONST_STORAGE GUI_FONT GUI_FontFont;static const char* _apText[] = {"Op Fancy's Blog","\xe4\xb8\xad\xe5\x8d\x8e\xe5\xa5\xbd\xe5\xb0\x91\xe5\xb9\xb4"//中华好少年};void MainTask(void) {unsigned i;GUI_Init();GUI_UC_SetEncodeUTF8();GUI_SetFont(&GUI_FontFont);GUI_DispStringAt(_apText[0], 70, 40);GUI_DispStringAt(_apText[1], 70, 90);while (1) {GUI_Delay(150);}} 运⾏结果如下图,其中字体都存在边框的原因是emWin官⽅提供的库⽂件包中的⼯具是Demo版的,使⽤有些限制,如果需要⽆边框的当然要收费的,有需要的可以购买,另外emWin官⽅和ST合作开发的⼀个版本STemWin⾥⾯的⼩⼯具功能很齐全(如FontCvtST.exe),⽣成的字体库没有边框,可以在ST官⽹下载,在本⽂最后都会提供下载链接。

构建GB2312 汉字库的unicode 码表作者:乾坤一笑下载源代码构建GB2312 汉字库的unicode 码表嵌入式系统总离不了处理汉字。
一般汉字的处理方法是(以手机接受短信为例):比如你收到了一封短信,该短信解码后是按照UTF-16 表示的,那么我们需要根据每一个汉字的unicode 码找到它在GB2312 库中的位置,然后再用对应的点阵数据在屏幕上显示出来。
于是乎,必须有一种手段将unicode 码和汉字字模的数据对应起来。
最常用的手段是做一个unicode 码表,在该数组中查找到匹配的unicode 码后,用匹配的index(数组索引)值在另外一个由该index 值对应的字模记录的数组中的数据去显示。
+-----------------+ 查表+-----------------+ 同index +-------------------+| 汉字的unicode码| ==> | unicode码表数组| =======> | 汉字字模数据数组| ==> 显示输出+-----------------+ +-----------------+ +-------------------+本文简要介绍一下如何生成unicode 码表,其它相关的汉字处理技术不在本文的讨论范围之内。
:)用下面两个函数可以把unicode 码表构造出来(*注1):void UnicodeToGB2312(unsigned char* pOut,unsigned short uData) {WideCharToMultiByte(CP_ACP,NULL,&uData,1,pOut,sizeof(unsigned short),NULL,NULL);return;}void Gb2312ToUnicode(unsigned short* pOut,unsigned char*gbBuffer){MultiByteToWideChar(CP_ACP,MB_PRECOMPOSED,gbBuffer,2,pOut,1);return;}一个简单的例子如下(随手写的一段代码,只是演示一下构造数组的过程,不要挑刺儿啊! ^_^ ):/*-----------------------------------------------*\| GB2312 unicode table constructor || author: Spark Song ||file : build_uni_table.c || date : 2005-11-18 |\*-----------------------------------------------*/#include <stdio.h>#include <windows.h>void UnicodeToGB2312(unsigned char* pOut,unsigned short uData); void Gb2312ToUnicode(unsigned short* pOut,unsigned char*gbBuffer);void construct_unicode_table();int main(int argc, char *argv[]){construct_unicode_table();return 0;}void construct_unicode_table(){#define GB2312_MATRIX (94)#define DELTA (0xA0)#define FONT_ROW_BEGIN (16 + DELTA)#define FONT_ROW_END (87 + DELTA)#define FONT_COL_BEGIN (1 + DELTA)#define FONT_COL_END (GB2312_MATRIX + DELTA)#define FONT_TOTAL (72 * GB2312_MATRIX)int i, j;unsigned char chr[2];unsigned short uni;unsigned short data[FONT_TOTAL] = {0};int index = 0;unsigned short buf;//生成unicode码表for (i=FONT_ROW_BEGIN; i<=FONT_ROW_END; i++)for(j=FONT_COL_BEGIN; j<=FONT_COL_END; j++){chr[0] = i;chr[1] = j;Gb2312ToUnicode(&uni, chr);data[index] = uni; index++;}//排个序,以后检索的时候就可以用binary-search了for (i=0;i<index-1; i++)for(j=i+1; j<index; j++)if (data[i]>data[j]){buf = data[i];data[i] = data[j];data[j] = buf;}//输出到STD_OUTprintf("const unsigned short uni_table[]={\n");for (i=0; i<index; i++){uni = data[i];UnicodeToGB2312(chr, uni);printf(" 0x%.4X%s /* GB2312 Code: 0x%.2X%.2X ==> Row:%.2d Col:%.2d */\n",uni,i==index-1?" ":",",chr[0],chr[1],chr[0] - DELTA,chr[1] - DELTA);}printf("};\n");return ;}void UnicodeToGB2312(unsigned char* pOut,unsigned short uData) {WideCharToMultiByte(CP_ACP,NULL,&uData,1,pOut,sizeof(unsigned short),NULL,NULL);return;}void Gb2312ToUnicode(unsigned short* pOut,unsigned char*gbBuffer){MultiByteToWideChar(CP_ACP,MB_PRECOMPOSED,gbBuffer,2,pOut,1);return;}用VC 编译后,在DOS 中执行:build_uni_table.exe > report.txt可以得到如下的txt文件:const unsigned short uni_table[]={0x4E00, /* GB2312 Code: 0xD2BB ==> Row:50 Col:27 */0x4E01, /* GB2312 Code: 0xB6A1 ==> Row:22 Col:01 */0x4E03, /* GB2312 Code: 0xC6DF ==> Row:38 Col:63 */0x4E07, /* GB2312 Code: 0xCDF2 ==> Row:45 Col:82 */ ... ...0x9F9F, /* GB2312 Code: 0xB9EA ==> Row:25 Col:74 */0x9FA0, /* GB2312 Code: 0xD9DF ==> Row:57 Col:63 */0xE810, /* GB2312 Code: 0xD7FA ==> Row:55 Col:90 */0xE811, /* GB2312 Code: 0xD7FB ==> Row:55 Col:91 */0xE812, /* GB2312 Code: 0xD7FC ==> Row:55 Col:92 */0xE813, /* GB2312 Code: 0xD7FD ==> Row:55 Col:93 */0xE814 /* GB2312 Code: 0xD7FE ==> Row:55 Col:94 */};然后把这个生成的数组copy到项目代码中使用就okey了。

C#生成汉字编码原理介绍及.Net程序处理汉字编码原理分析C#语言还是比较常见的东西,这里我们主要介绍C#生成汉字编码原理,包括介绍.Net程序处理汉字编码原理分析。
C#生成汉字编码原理到底怎么办到随机生成汉字的呢?汉字从哪里来的呢?是不是有个后台数据表,其中存放了所需要的所有汉字,使用程序随机取出几个汉字组合就行了呢?使用后台数据库先将所有汉字存起来使用时随机取出,这也是一种办法,但是中文汉字有这么多,怎么来制作呢?其实可以不使用任何后台数据库,使用程序就能做到这一切。
要知道如何生成汉字,就得先了解中文汉字的编码原理。
1980年,为了使每一个汉字有一个全国统一的代码,我国颁布了第一个汉字编码的国家标准: GB2312-80《信息交换用汉字编码字符集》基本集,简称GB2312,这个字符集是我国中文信息处理技术的发展基础,也是国内所有汉字系统的统一标准。
到了后来又公布了国家标准GB18030-2000《信息交换用汉字编码字符集基本集的扩充》,简称GB18030,编程时如果涉及到编码和本地化的朋友应该对GB18030很熟悉。
这是是我国继GB2312-1980和GB13000-1993之后最重要的汉字编码标准,同时也是未来我国计算机系统必须遵循的基础性标准之一。
.Net程序处理汉字编码原理分析在.Net中可以使用System.Text来处理所有语言的编码。
在System.Text命名空间中包含众多编码的类,可供进行操作及转换。
其中的Encoding类就是重点处理汉字编码的类。
通过在.NET文档中查询Encoding类的方法我们可以发现所有和文字编码有关的都是字节数组,其中有两个很好用的方法:◆Encoding.GetBytes ()方法将指定的 String 或字符数组的全部或部分内容编码为字节数组◆Encoding.GetString ()方法将指定字节数组解码为字符串。
using System;using System.Text;namespace ConsoleApplication{class ChineseCode{public static void Main(){//获取GB2312编码页(表)Encoding gb=Encoding.GetEncoding("gb2312");//调用函数产生4个随机中文汉字编码object[] bytes=CreateRegionCode(4);//根据汉字编码的字节数组解码出中文汉字string str1=gb.GetString((byte[])Convert.ChangeType(bytes[0], type of(byte[])));string str2=gb.GetString((byte[])Convert.ChangeType(bytes[1], type of(byte[])));string str3=gb.GetString((byte[])Convert.ChangeType(bytes[2], type of(byte[])));string str4=gb.GetString((byte[])Convert.ChangeType(bytes[3], type of(byte[])));//输出的控制台Console.WriteLine(str1 + str2 +str3 +str4);}以上介绍C#生成汉字编码原理。
摘要随着社会经济的迅速发展,如今汉字显示系统应用于各个领域中。
LCD显示屏的技术和产业都取得了长足的发展,作为重要的现代信息发布媒体之一,LCD显示屏在证券交易、金融、交通、体育、广告等领域被广泛的应用。
基于STM32的LCD显示可以更好的满足各种需求,也更便于操作和实现。
汉字显示系统主要由STM32芯片作为LCD 彩色显示屏的主要核心控制器,并且通过字库制作软件制作相应的字库经过SD卡将自己所制作的字库中的汉字在屏幕中依次显示出来,同时可以通过按键控制,来控制现实的汉字的暂停,继续,更新字库。
本系统是利用STM32开发板配合SD卡实现将已存入字库中的汉字完整的显示在LCD彩色显示屏上。
关键词:STM32开发板;LCD彩色显示屏;开关目录1 引言 ....................................................................................................... 错误!未定义书签。
2 总体设计 ............................................................................................... 错误!未定义书签。
2.1 汉字显示设计分析 (2)2.2 汉字显示的基本原理 (2)2.3 系统的结构框图 (3)3 详细设计 ............................................................................................... 错误!未定义书签。
3.1 硬件设计错误!未定义书签。
3.1.1 芯片介绍错误!未定义书签。
3.1.2 功能简介错误!未定义书签。
3.2 软件设计 (8)3.2.1 录字软件83.2.2主函数部分93.2.3硬件部分程序123.2.4字库相关程序143.2.5FAT系统183.2.6程序流程图194 实验结果及分析 (20)4.1 硬件实验结果204.2 结果分析205 结论21参考文献 (22)1引言随着嵌入式技术的迅猛发展,人机交互界面也越来越显示出它的重要性。
编码信息详解,C#获取中文编码(GBK,GB2312)2011-01-2621:28:45|分类:C#|标签:|字号大中小订阅以前在写C#代码时,感觉VS提供的没有系统默认的编码,现在发现虽然没有但可以通过如下方式获得中文编码信息(如GBK,GB2312),只需找到对应编码名称的codepage即可。
下面是微软编程提供的所有编码信息,包括编码名称,编码代码页标识符,编码说明,这对于编程转码相当有作用。
【C#Code】EncodingInfo[]info=Encoding.GetEncodings();Console.Write("编码名称"+"\t"+"编码代码页标识符"+"\t"+"编码说明"+"\n");for(int i=0;i<info.Length;i++){Console.Write(info[i].Name+"\t\t"+info[i].CodePage+ "\t\t\t"+info[i].DisplayName+"\n");}结果如下:编码名称|编码代码页标识符|编码说明IBM037|37|IBM EBCDIC(美国-加拿大)IBM437|437|OEM美国IBM500|500|IBM EBCDIC(国际)ASMO-708|708|阿拉伯字符(ASMO-708)DOS-720|720|阿拉伯字符(DOS)ibm737|737|希腊字符(DOS)ibm775|775|波罗的海字符(DOS)ibm850|850|西欧字符(DOS)ibm852|852|中欧字符(DOS)IBM855|855|OEM西里尔语ibm857|857|土耳其字符(DOS)IBM00858|858|OEM多语言拉丁语IIBM860|860|葡萄牙语(DOS)ibm861|861|冰岛语(DOS)DOS-862|862|希伯来字符(DOS)IBM863|863|加拿大法语(DOS)IBM864|864|阿拉伯字符(864)IBM865|865|北欧字符(DOS)cp866|866|西里尔字符(DOS)ibm869|869|现代希腊字符(DOS)IBM870|870|IBM EBCDIC(多语言拉丁语2) windows-874|874|泰语(Windows)cp875|875|IBM EBCDIC(现代希腊语)shift_jis|932|日语(Shift-JIS)gb2312|936|简体中文(GB2312)ks_c_5601-1987|949|朝鲜语big5|950|繁体中文(Big5)IBM1026|1026|IBM EBCDIC(土耳其拉丁语5)IBM01047|1047|IBM拉丁语1IBM01140|1140|IBM EBCDIC(美国-加拿大-欧洲) IBM01141|1141|IBM EBCDIC(德国-欧洲)IBM01142|1142|IBM EBCDIC(丹麦-挪威-欧洲) IBM01143|1143|IBM EBCDIC(芬兰-瑞典-欧洲) IBM01144|1144|IBM EBCDIC(意大利-欧洲) IBM01145|1145|IBM EBCDIC(西班牙-欧洲) IBM01146|1146|IBM EBCDIC(英国-欧洲)IBM01147|1147|IBM EBCDIC(法国-欧洲)IBM01148|1148|IBM EBCDIC(国际-欧洲)IBM01149|1149|IBM EBCDIC(冰岛语-欧洲)utf-16|1200|UnicodeunicodeFFFE|1201|Unicode(Big-Endian) windows-1250|1250|中欧字符(Windows) windows-1251|1251|西里尔字符(Windows) Windows-1252|1252|西欧字符(Windows) windows-1253|1253|希腊字符(Windows) windows-1254|1254|土耳其字符(Windows) windows-1255|1255|希伯来字符(Windows) windows-1256|1256|阿拉伯字符(Windows) windows-1257|1257|波罗的海字符(Windows) windows-1258|1258|越南字符(Windows)Johab|1361|朝鲜语(Johab)macintosh|10000|西欧字符(Mac)x-mac-japanese|10001|日语(Mac)x-mac-chinesetrad|10002|繁体中文(Mac)x-mac-korean|10003|朝鲜语(Mac)x-mac-arabic|10004|阿拉伯字符(Mac)x-mac-hebrew|10005|希伯来字符(Mac)x-mac-greek|10006|希腊字符(Mac)x-mac-cyrillic|10007|西里尔字符(Mac)x-mac-chinesesimp|10008|简体中文(Mac)x-mac-romanian|10010|罗马尼亚语(Mac)x-mac-ukrainian|10017|乌克兰语(Mac)x-mac-thai|10021|泰语(Mac)x-mac-ce|10029|中欧字符(Mac)x-mac-icelandic|10079|冰岛语(Mac)x-mac-turkish|10081|土耳其字符(Mac)x-mac-croatian|10082|克罗地亚语(Mac)utf-32|12000|Unicode(UTF-32)utf-32BE|12001|Unicode(UTF-32Big-Endian) x-Chinese-CNS|20000|繁体中文(CNS)x-cp20001|20001|TCA台湾x-Chinese-Eten|20002|繁体中文(Eten)x-cp20003|20003|IBM5550台湾x-cp20004|20004|TeleText台湾x-cp20005|20005|Wang台湾x-IA5|20105|西欧字符(IA5)x-IA5-German|20106|德语(IA5)x-IA5-Swedish|20107|瑞典语(IA5)x-IA5-Norwegian|20108|挪威语(IA5)us-ascii|20127|US-ASCIIx-cp20261|20261|T.61x-cp20269|20269|ISO-6937IBM273|20273|IBM EBCDIC(德国)IBM277|20277|IBM EBCDIC(丹麦-挪威)IBM278|20278|IBM EBCDIC(芬兰-瑞典)IBM280|20280|IBM EBCDIC(意大利)IBM284|20284|IBM EBCDIC(西班牙)IBM285|20285|IBM EBCDIC(UK)IBM290|20290|IBM EBCDIC(日语片假名)IBM297|20297|IBM EBCDIC(法国)IBM420|20420|IBM EBCDIC(阿拉伯语)IBM423|20423|IBM EBCDIC(希腊语)IBM424|20424|IBM EBCDIC(希伯来语)x-EBCDIC-KoreanExtended|20833|IBM EBCDIC(朝鲜语扩展) IBM-Thai|20838|IBM EBCDIC(泰语)koi8-r|20866|西里尔字符(KOI8-R)IBM871|20871|IBM EBCDIC(冰岛语)IBM880|20880|IBM EBCDIC(西里尔俄语)IBM905|20905|IBM EBCDIC(土耳其语)IBM00924|20924|IBM拉丁语1EUC-JP|20932|日语(JIS0208-1990和0212-1990)x-cp20936|20936|简体中文(GB2312-80)x-cp20949|20949|朝鲜语Wansungcp1025|21025|IBM EBCDIC(西里尔塞尔维亚-保加利亚语) koi8-u|21866|西里尔字符(KOI8-U)iso-8859-1|28591|西欧字符(ISO)iso-8859-2|28592|中欧字符(ISO)iso-8859-3|28593|拉丁语3(ISO)iso-8859-4|28594|波罗的海字符(ISO)iso-8859-5|28595|西里尔字符(ISO)iso-8859-6|28596|阿拉伯字符(ISO)iso-8859-7|28597|希腊字符(ISO)iso-8859-8|28598|希伯来字符(ISO-Visual)iso-8859-9|28599|土耳其字符(ISO)iso-8859-13|28603|爱沙尼亚语(ISO)iso-8859-15|28605|拉丁语9(ISO)x-Europa|29001|欧罗巴iso-8859-8-i|38598|希伯来字符(ISO-Logical)iso-2022-jp|50220|日语(JIS)csISO2022JP|50221|日语(JIS-允许1字节假名)iso-2022-jp|50222|日语(JIS-允许1字节假名-SO/SI) iso-2022-kr|50225|朝鲜语(ISO)x-cp50227|50227|简体中文(ISO-2022)euc-jp|51932|日语(EUC)EUC-CN|51936|简体中文(EUC)euc-kr|51949|朝鲜语(EUC)hz-gb-2312|52936|简体中文(HZ)GB18030|54936|简体中文(GB18030)x-iscii-de|57002|ISCII梵文x-iscii-be|57003|ISCII孟加拉语x-iscii-ta|57004|ISCII泰米尔语x-iscii-te|57005|ISCII泰卢固语x-iscii-as|57006|ISCII阿萨姆语x-iscii-or|57007|ISCII奥里雅语x-iscii-ka|57008|ISCII卡纳达语x-iscii-ma|57009|ISCII马拉雅拉姆语x-iscii-gu|57010|ISCII古吉拉特语x-iscii-pa|57011|ISCII旁遮普语utf-7|65000|Unicode(UTF-7)utf-8|65001|Unicode(UTF-8)想要使用某种编码时可以这样,Encoding Gbk=Encoding.GetEncoding(int codepage);如果想使用gb2312编码,则可以Encoding Gbk=Encoding.GetEncoding(936);下面就是一段GB2312编码的代码:byte[]dataArray=new byte[100];new Random().NextBytes(dataArray);Encoding Gbk=Encoding.GetEncoding(936);Console.WriteLine(Gbk.GetString(dataArray));依次类推~备注:(什么是编码代码页标识符)运行-cmd-顶部右键-属性-选项-当前代码页(可以发现大陆装的系统默认就是codpage是936也即GBK)。
威尔取模软件使用介绍(V1.0)一、简介1.1 界面介绍二、我要取几个汉字的字模2.1 取模2.1.1 打开软件2.1.2 在中文字符集文本框中输入要取模的文字,比如“欢迎使用威尔取模软件”,如下图所示。
2.1.3 选择要取模的字体,比如我要取宋体的字模,就选择宋体。
如下图所示。
此处列出的是系统安装的所有字体,如果要取自己下载的字体的模,请先安装该字体。
2.1.4 添加我要取模的字号,宽度,高度等信息。
点击添加按钮,打开添加窗口,如下图所示。
在字号,宽度,高度框中输入你要取模的文字大小。
比如我要取16*16的点阵,就在宽度和高度中输入16、16。
然后计算字号,字号=0.75*宽度。
输入12。
点击添加。
点击添加以后回到主界面,你会发现主界面字号列表框里面就多了一种你刚刚添加的字号了。
这时候点击你刚刚添加的字号选中它,然后再在预览框中输入一个汉字,看看效果。
2.1.5 如果效果不错可以跳过这一步。
如果效果不好有以下两种情况。
1.文字太大或者太小,如下图两种情况所示。
这时候就需要重新设置字号了。
增大或者减小字号。
2.字符不居中,如下图所示。
这时候调节右下方的位置调整滑块,将文字调节居中,如下图所示。
2.1.6 选择要生成C语言格式还是二进制文件格式。
如果是C语言格式,还可以选择是否生成数组的数组名。
2.1.7 假如我只要取我刚刚设置的16*16点阵字体,那么就要选择“取选中字号”,并选中16*16那一列。
如下图所示。
2.1.8 假如我只要取中文字模,那么就勾上取模中文,同时去掉取模英文的勾,如下图所示。
2.1.9 好了,所有设置妥当,可以开始取模啦。
点击“开始取模”。
如果选择的是C语言格式则取模完成后自动弹出结果窗口,如下图所示。
三、我要取整个GBK字库或者GB2312字库的字模3.1 取模3.1.1 打开软件3.1.2 假如我要取整个GBK字库的字模,那么点击右侧“GBK字库”按钮,自动输入GBK字符集所有文字。
emWin中文字体显示概述:本文档要紧介绍STemWin显示中文汉字的步骤,分为以下部份:汉字C文件字库的制作,显示文字UTF-8码的制作,程序实现。
一,汉字C文件字库的制作第一步:安装字体函数生成软件:如下安装完成后:电脑桌面显示图标如下第二步:创建自己想要的字体库:1、开始创建一个TXT格式的文本文件2、打开文本文件输入想要在VS2021中调试EMWIN界面显示的所需中文文字3、文字输入完成后,另存TXT文件为Unicode格式文件注意:另存文件名最好不要利用中文(建议取字体类型:如宋体:songFont),保留编码选项必然要选Unicode,最后保留在自己创建的文件夹中,文件夹最好不用中文(建议:保留字库的文件夹放在工程项目文件夹中)4、另存好文件后,打开第一步安装好的软件,初始界面如下字体类型选择以下教程只做国际标准字体显示,其他字体类型相信步骤一样,因此选择Standard点击OK,进入字体选项界面一、字体选择2字形3字体大小5、黄色圆框(字体显示方式:Pixels:像素点;Points:点),其被选中Points才能够选择字体大小,设置完成点击确信。
显现界面6、接下来:禁止所有字符然后读取(添加)前面所创建另存为Unicode编码格式的文件添加自己的文件后,另存文件保留文件在第二步-3的文件夹中,也能够从头创建,但前提是不用利用中文文件夹名,保留的.c文件也不用中文。
保留后在文件夹中会生成一个c_file(.c文件)打开大体上是:(显现很多XXX组成的实际中文字)致此,汉字C文件字库的制作完成。
二,显示文字UTF-8码的制作Step1:创建一个TXT格式的文本文件,把要显示的汉字写入其中。
Step2:文字输入完成后,另存TXT文件为UTF-8格式的文件,文件名为数字或英文字母。
Step3:打开软件:界面如下:点击A,进入文件选择,要选择的文件是Step2:中保留的文件,然后点击B进行转换,这时,在同一文件夹中会显现与Step2同名的c_file(即.c文件),此文件确实是接下来复制到模拟器工程中需要显示的中文汉字UTF-8码,(格式如:)注:此步骤的转化方式多样:还能够在线网页等。
第25章全字库在S T e m W i n上的实现(G B2312编码)本章节为大家讲解GB2312编码全字库的实现,对于习惯了GB2312编码的用户来说,使用本章节的方法非常合适。
emWin本身是不支持GB2312编码字符显示的,本章节是新创建一种字体类型来实现GB2312编码字符的显示,所采用的方式是早期UCGUI3.98时期遗留下来,但对那种方法进行了修改,以适合高版本emWin5.xx的使用。
25.1 初学者重要提示25.2 GB2312编码全字库说明25.3 GB2312全字库的移植方法25.4 移植文件简易说明25.5 GB2312字库使用方法25.6 实验例程说明(RTOS)25.7 实验例程说明(裸机)25.8总结25.1初学者重要提示◆对于不习惯前面章节讲解的XBF格式和SIF格式的Unicode编码全字库的用户来说,使用GB2312编码是很好的选择,很适合初学者,汉字操作方式与大家使用裸机代码(没有使用GUI)时是一样的。
◆GB2312编码的全字库文件可以存到任何外部存储介质中。
本章节配套例子是将其存储到SPI Flash里面了。
◆使用GB2312编码也是有缺点的,相比前面章节使用FontCvt生成的XBF格式和SIF格式全字库,GB2312编码全字库不支持抗锯齿效果,且仅支持等宽字体(仅支持等宽是因为当前新字体的创建方法不支持非等宽字体)。
25.2G B2312编码全字库说明本章节配套例子使用的字库是从字库芯片提取出来的,下面是点阵字库相关信息,仅列出了要用到的点阵字符:1 11x12点阵 GB2312 A1A1-F7FE 6763+846 0000 24字节3 24x24点阵 GB2312 A1A1-F7FE 6763+846 68190 72字节4 32x32点阵 GB2312 A1A1-F7FE 6763+846 EDF00 128字节5 6x12点ASCII ASCII 20-7F 96 1DBE00 12字节6 8x16点ASCII ASCII 20-7F 96 1DD780 16字节7 12x24点ASCII ASCII 20-7F 96 1DFF00 36字节8 16x32点ASCII ASCII 20-7F 96 1E5A50 64字节了解了点阵字体的相关信息后,剩下就是寻址算法了。
汉字点阵在汉字库中的地址计算:汉字库种类繁多,但都是按照区位的顺序排列的。
前一个字节为该汉字的区号,后一个字节为该字的位号,位号是该字在该区中的位置。
GB2312编码区范围是A1A1到F7FE,一共F7-A1+1 = 87个区,每区有FE-A1+1=94个字符,因此GB2312可以表示87*94=8178个字符。
计算公式为:(94 * (区号 - 1) + 位号 - 1) * 一个汉字字模占用字节数 我们在计算机中常用的汉字编码为汉字内码,不是区位码,需要进行转换。
因此最终的计算公式为:ADDRESS = [(内码1 - 0xa1) * 94 + (内码2 - 0xa1)] *一个汉字字模占用字节数 (内码1对应区号,内码2对应位号)ASCII区,GB2312编码的全角字符区和汉字区的所有字符可以看下这个帖子:/read.php?tid=201,初学者务必看下,非常有必要。
下面对这8种点阵依次做下说明:汉字点阵GB2312编码字库地址计算GBCode表示汉字内码。
MSB 表示汉字内码GBCode的高8bits,LSB 表示汉字内码GBCode的低8bits。
Address 表示汉字或ASCII字符点阵在芯片中的字节地址。
BaseAdd:说明点阵数据在字库中的起始地址。
11*12点阵计算方法:BaseAdd=0x0;if(MSB >=0xA1 && MSB <= 0Xa9 && LSB >=0xA1)Address =( (MSB – 0xA1) * 94 + (LSB – 0xA1))*24+ BaseAdd;else if(MSB >=0xB0 && MSB <= 0xF7 && LSB >=0xA1)Address = ((MSB – 0xB0) * 94 + (LSB – 0xA1)+ 846)*24+ BaseAdd;15*16点阵计算方法:BaseAdd=0x2C9D0;if(MSB >=0xA1 && MSB <= 0Xa9 && LSB >=0xA1)Address =( (MSB - 0xA1) * 94 + (LSB - 0xA1))*32+ BaseAdd;else if(MSB >=0xB0 && MSB <= 0xF7 && LSB >=0xA1)Address = ((MSB - 0xB0) * 94 + (LSB - 0xA1)+ 846)*32+ BaseAdd;24*24点阵计算方法:BaseAdd=0x68190;if(MSB >=0xA1 && MSB <= 0Xa9 && LSB >=0xA1)Address =( (MSB - 0xA1) * 94 + (LSB - 0xA1))*72+ BaseAdd;else if(MSB >=0xB0 && MSB <= 0xF7 && LSB >=0xA1)Address = ((MSB - 0xB0) * 94 + (LSB - 0xA1)+ 846)*72+ BaseAdd;32*32点阵计算方法:BaseAdd=0XEDF00;if(MSB >=0xA1 && MSB <= 0Xa9 && LSB >=0xA1)Address =( (MSB - 0xA1) * 94 + (LSB - 0xA1))*128+ BaseAdd;else if(MSB >=0xB0 && MSB <= 0xF7 && LSB >=0xA1)Address = ((MSB - 0xB0) * 94 + (LSB - 0xA1)+ 846)*128+ BaseAdd;这四种点阵字体除了每个点阵字符的字节数和起始地址不一样,其余都是一样的。
其中第一个if条件语句是判断区号在0xA1到0xA8里面的全角字符区,共846个字符。
第二个else if条件语句是判断区号在0xB0到0xF7里面的汉字区,共6763个汉字。
ASCII字符地址计算ASCIICode:表示 ASCII 码( 8bits)BaseAdd:说明该套字库在芯片中的起始地址。
Address: ASCII 字符点阵在芯片中的字节地址。
6x12点阵ASCII计算方法:BaseAdd=0x1DBE00if (ASCIICode >= 0x20) and (ASCIICode <= 0x7E)Address = (ASCIICode –0x20 ) * 12+BaseAdd8x16点阵ASCII计算方法:BaseAdd=0x1DD780if (ASCIICode >= 0x20) and (ASCIICode <= 0x7E)Address = (ASCIICode –0x20 ) * 16+BaseAdd12x24点阵ASCII计算方法:BaseAdd=0x1DFF00if (ASCIICode >= 0x20) and (ASCIICode <= 0x7E)Address = (ASCIICode –0x20 ) * 48+BaseAdd16x32点阵ASCII计算方法:BaseAdd=0x1E5A50if (ASCIICode >= 0x20) and (ASCIICode <= 0x7E)Address = (ASCIICode –0x20 ) * 64+BaseAdd这四种点阵字体除了每个点阵字符的字节数和起始地址不一样,其余都是一样的。
每个点阵都是只用 到了0x20到0x7E,共96个字符。
---------------------------------------------------------------讲解完编码地址的计算后,再说一个比较重要的知识点,初学者容易在这个问题上面犯迷糊。
汉字内码在文件里面存储的时候就是按照高低字节依次存储的,比如汉字“我”的GB2312编码是0xced2,汉字“们”的编码是0xc3c7,现在我们在电脑端新建一个记事本文件,然后将“我们”这两个字写到电脑端的记事本里面,然后保存,文本编码类型选择ANSI即可。
此时将这个文本文件用winhex打开,可以看到,编码数值如下:跟汉字的编码值对比后发现汉字的编码值存储就是高低字节依次存储的。
那么问题来了,一般情况下,使用MCU微控制器的时候都是用的小端模式,即低地址存储低位数据,高地址存储高位数据。
现在我们采用如下的程序做简单的测试:char *ptr = {"我们"};U16 c1, c2;c1 = *(U16 *)ptr;c2 = *(U16 *)(ptr + 2);printf("c1 = %x, c2 = %x\r\n", c1, c2);串口打印的输出结果就是 c1 = 0xd2ce , c2 = 0xc7c3。
正好与汉字内码的高低字节反过来了,初学者在学习的时候务必要注意这个问题。
25.3G B2312全字库的移植方法这里用到的几个移植文件是早期UCGUI3.XX版本时代遗留下来的,但都进行了修改,更加适合STemWin5.xx版本使用(由于早期UCGUI3.XX版本是有源码的,这种方式是在源码的基础上新创建的一种字体方式,适合国内用的GB编码)。
图25-1GUI_Font12.c,GUI_Font16.c,GUI_Font24.c和GUI_Font32.c都是相同的代码结构,仅仅是定义的点阵大小不同,用户要实现其它点阵大小的字体,只需根据这几个文件照葫芦画瓢即可。
剩下的两个文件GUI_UC_EncondeNone.c和GUICharPEx.c是必须要包含的,用户需要根据字库的起始位置做修改(如何修改,看本章节的25.4小节,本章节配套的例子不用改,因为已经根据25.2小节的起始地址设置好了)。
接下来要做的移植工作比较简单,仅需两步即可完成:第1步:将图25-1中的6个文件全部添加到工程中,IAR和MDK是一样的,下面以MDK为例进行说明。