统计学第五版课后习题答案
- 格式:ppt
- 大小:544.50 KB
- 文档页数:24

统计学第五版贾俊平版课后题答案(部分)第7章抽样与参数估计7.1(1)已知: EMBED Equation.3 , EMBED Equation.3 , EMBED Equation.3。
, EMBED Equation.3 , EMBED Equation.3样本均值的抽样标准差 EMBED Equation.3。
(2)估计误差 EMBED Equation.3。
7.2(1)已知: EMBED Equation.3 , EMBED Equation.3 , EMBED Equation.3。
, EMBED Equation.3 , EMBED Equation.3。
样本均值的抽样标准差 EMBED Equation.3。
(2)估计误差 EMBED Equation.3(3)由于总体标准差已知,所以总体均值 EMBED Equation.3 的95%的置信区间为:,即(115.8,124.2)。
EMBED Equation.37.3已知: EMBED Equation.3 , EMBED Equation.3 , EMBED Equation.3。
, EMBED Equation.3 , EMBED Equation.3由于总体标准差已知,所以总体均值 EMBED Equation.3 的95%的置信区间为:,即(87818.856,121301.144)。
EMBED Equation.37.4(1)已知: EMBED Equation.3 , EMBED Equation.3 , EMBED Equation.3。
, EMBED Equation.3 , EMBED Equation.3由于 EMBED Equation.3 为大样本,所以总体均值 EMBED Equation.3 的90%的置信区间为:,即(79.026,82.974)。
EMBED Equation.3。
(2)已知: EMBED Equation.3 , EMBED Equation.3由于 EMBED Equation.3 为大样本,所以总体均值 EMBED Equation.3 的95%的置信区间为:,即(78.648,83.352)。

统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。

统计学(第五版)课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。

统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)整理by__kiss-ahuang第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。

统计学第五版课后题答案李金昌第1章绪论 1 .试述数据、数据库、数据库系统、数据库管理系统的概念。
答:( l )数据( Data ) :叙述事物的符号记录称作数据。
数据的种类存有数字、文字、图形、图像、声音、正文等。
数据与其语义就是不可分的。
解析在现代计算机系统中数据的概念就是广义的。
早期的计算机系统主要用作科学计算,处置的数据就是整数、实数、浮点数等传统数学中的数据。
现代计算机能够存储和处置的对象十分广为,则表示这些对象的数据也越来越繁杂。
数据与其语义就是不可分的。
500 这个数字可以表示一件物品的价格是 500 元,也可以表示一个学术会议参加的人数有 500 人,还可以表示一袋奶粉重 500 克。
( 2 )数据库( DataBase ,缩写 DB ) :数据库就是长期储存在计算机内的、存有非政府的、可以共享资源的数据子集。
数据库中的数据按一定的数据模型非政府、叙述和储存,具备较小的冗余度、较低的数据独立性和易扩展性,并可向各种用户共享资源。
( 3 )数据库系统( DataBas 。
Sytem ,缩写 DBS ) :数据库系统就是所指在计算机系统中导入数据库后的系统形成,通常由数据库、数据库管理系统(及其开发工具)、应用领域系统、数据库管理员形成。
解析数据库系统和数据库就是两个概念。
数据库系统就是一个人一机系统,数据库就是数据库系统的一个组成部分。
但是在日常工作中人们常常把数据库系统缩写为数据库。
期望读者能从人们讲话或文章的上下文中区分“数据库系统”和“数据库”,不要引发混为一谈。
( 4 )数据库管理系统( DataBase Management sytem ,简称 DBMs ) :数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。
DBMS 的主要功能包含数据定义功能、数据压低功能、数据库的运转管理功能、数据库的创建和保护功能。
解析 DBMS 就是一个大型的繁杂的软件系统,就是计算机中的基础软件。
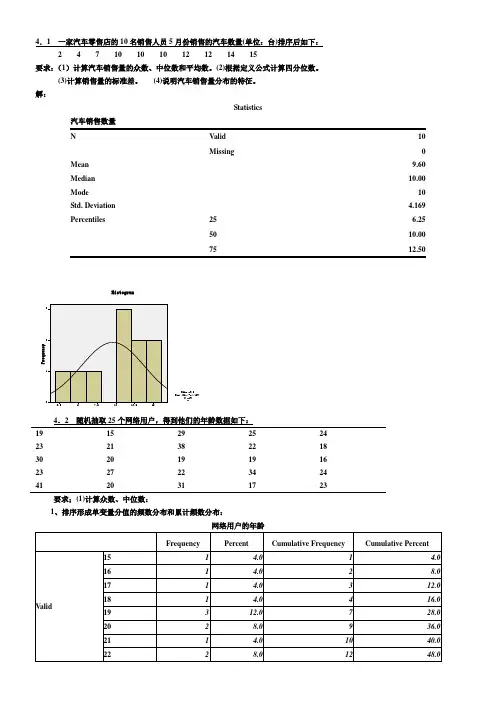
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量N Valid 10Missing 0 Mean 9.60 Median 10.00 Mode 10 Std. Deviation 4.169 Percentiles 25 6.2550 10.0075 12.504.2 随机抽取25个网络用户,得到他们的年龄数据如下:19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:1、排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25 和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差; Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数: Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线:分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K=+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄(Binned)分组后的均值与方差:分组后的直方图:4.6 在某地区抽取120家企业,按利润额进行分组,结果如下:要求:(1)计算120家企业利润额的平均数和标准差。

统计学第五版课后练答案(7-8章)(总11页)-本页仅作为预览文档封面,使用时请删除本页-第七章 参数估计(1)x σ==(2)2x z α∆= 1.96=某快餐店想要估计每位顾客午餐的平均花费金额。
在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
x σ==(2)在95%的置信水平下,求估计误差。
x x t σ∆=⋅,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=2z α 因此,x x t σ∆=⋅2x z ασ=⋅0.025x z σ=⋅=×=(3)如果样本均值为120元,求总体均值 的95%的置信区间。
置信区间为:22x z x z αα⎛-+ ⎝=()120 4.2,120 4.2-+=(,)22x z x z αα⎛-+ ⎝=104560±=(,) 从总体中抽取一个n=100的简单随机样本,得到x =81,s=12。
要求:大样本,样本均值服从正态分布:2,x N n σμ⎛⎫ ⎪⎝⎭或2,s x N n μ⎛⎫⎪⎝⎭置信区间为:22x z x z αα⎛-+ ⎝= (1)构建μ的90%的置信区间。
2z α=0.05z =,置信区间为:()81 1.645 1.2,81 1.645 1.2-⨯+⨯=(,)(2)构建μ的95%的置信区间。
2z α=0.025z =,置信区间为:()81 1.96 1.2,81 1.96 1.2-⨯+⨯=(,) (3)构建μ的99%的置信区间。
2z α=0.005z =,置信区间为:()81 2.576 1.2,81 2.576 1.2-⨯+⨯=(,)(1)2x z α±=25 1.96±=(,) (2)2x z α±=119.6 2.326±=(,)(3)2x z α±=3.419 1.645±=(,)(1)2x z α±=8900 1.96±=(,)(2)2x z α±=8900 1.96±=(,)(3)2x z α±=8900 1.645±=(,) (4)2x z α±=8900 2.58±=(,)某大学为了解学生每天上网的时间,在全校7 500名学生中采取重复抽样方法随机抽取36解:(1)样本均值x =,样本标准差s=1α-=,t=2z α=0.05z =,2x z α±=3.32 1.645±=(,)1α-=,t=2z α=0.025z =,2x zα±3.32 1.96±=(,)1α-=,t=2z α=0.005z =,2x z α±3.32 2.76±(,)x t α±=10 2.365±某居民小区为研究职工上班从家里到单位的距离,抽取了由16个人组成的一个随机样本,他们到单位的距离(单位:km)分别是: 10 3 14 8 6 9 12 11 7 5 10 15 9 16 13 2假定总体服从正态分布,求职工上班从家里到单位平均距离的95%的置信区间。

统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题1。
1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1。
2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的.(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1。
4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1。
6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1。
7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。

统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)整理by__kiss—ahuang第一部分思考题第一章思考题1。
1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1。
2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据.它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的.实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1。
31。
5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量.经验变量和理论变量。
1。
7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数"连续型变量,取之连续不断,不能一一列举,比如“温度”。

统计学第五版贾俊平版课后题答案(部分)第三章数据的图表展示3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB AC E E A BD D CA DBC C A ED C BC B C ED B C C B C要求:(1)指出上面的数据属于什么类型。
顺序数据(2)用Excel制作一张频数分布表。
用数据分析——直方图制作:接收频率E16D17C32B21A14(3)绘制一张条形图,反映评价等级的分布。
用数据分析——直方图制作:(4)绘制评价等级的帕累托图。
逆序排序后,制作累计频数分布表:接收 频数 频率(%) 累计频率(%) C 32 32 32 B 21 21 53 D 17 17 70 E 16 16 86 A14141005101520253035CDBAE204060801001203.2 某行业管理局所属40个企业2002年的产品销售收入数据如下: 152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 9788123115119138112146113126要求:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
1、确定组数: ()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(152-87)÷6=10.83,取10 3(2)按规定,销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115 万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
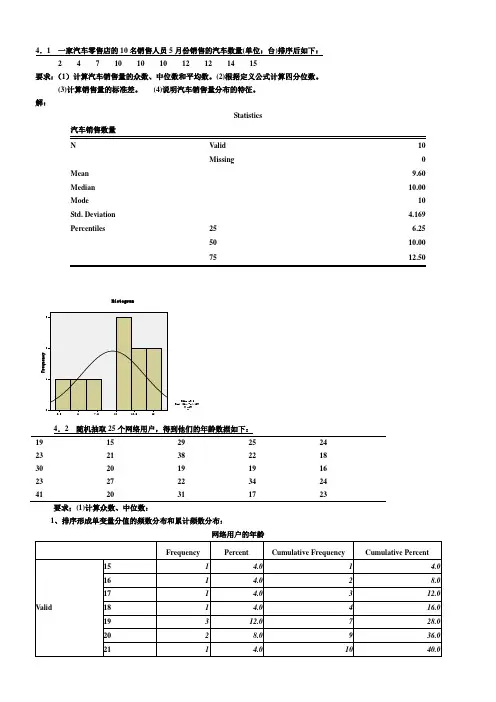
第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
1、确定组数: ()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。
统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1。
2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据.它也是有类别的,但这些类别是有序的.(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值.统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1。
4解释分类数据,顺序数据和数值型数据答案同1。
31。
5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1。
6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量.经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数"连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
第一章导论1.1(1)数值型变量。
(2)分类变量。
(3)离散型变量。
(4)顺序变量。
(5)分类变量。
1.2(1)总体是该市所有职工家庭的集合;样本是抽中的2000个职工家庭的集合。
(2)参数是该市所有职工家庭的年人均收入;统计量是抽中的2000个职工家庭的年人均收入。
1.3(1)总体是所有IT从业者的集合。
(2)数值型变量。
(3)分类变量。
(4)截面数据。
1.4(1)总体是所有在网上购物的消费者的集合。
(2)分类变量。
(3)参数是所有在网上购物者的月平均花费。
(4)参数(5)推断统计方法。
第二章数据的搜集1.什么是二手资料?使用二手资料需要注意些什么?与研究内容有关的原始信息已经存在,是由别人调查和实验得来的,并会被我们利用的资料称为“二手资料”。
使用二手资料时需要注意:资料的原始搜集人、搜集资料的目的、搜集资料的途径、搜集资料的时间,要注意数据的定义、含义、计算口径和计算方法,避免错用、误用、滥用。
在引用二手资料时,要注明数据来源。
2.比较概率抽样和非概率抽样的特点,举例说明什么情况下适合采用概率抽样,什么情况下适合采用非概率抽样。
概率抽样是指抽样时按一定概率以随机原则抽取样本。
每个单位被抽中的概率已知或可以计算,当用样本对总体目标量进行估计时,要考虑到每个单位样本被抽中的概率,概率抽样的技术含量和成本都比较高。
如果调查的目的在于掌握和研究总体的数量特征,得到总体参数的置信区间,就使用概率抽样。
非概率抽样是指抽取样本时不是依据随机原则,而是根据研究目的对数据的要求,采用某种方式从总体中抽出部分单位对其实施调查。
非概率抽样操作简单、实效快、成本低,而且对于抽样中的专业技术要求不是很高。
它适合探索性的研究,调查结果用于发现问题,为更深入的数量分析提供准备。
非概率抽样也适合市场调查中的概念测试。
3.调查中搜集数据的方法主要有自填式、面方式、电话式,除此之外,还有那些搜集数据的方法?实验式、观察式等。
统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。