【免费下载】spss实验报告1
- 格式:pdf
- 大小:221.14 KB
- 文档页数:6
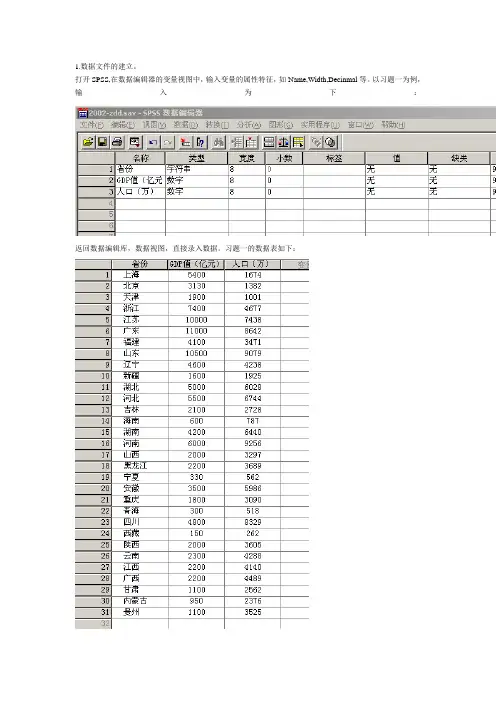
1.数据文件的建立。
打开SPSS,在数据编辑器的变量视图中,输入变量的属性特征,如Name,Width,Decinmal等。
以习题一为例,输入为下:返回数据编辑库,数据视图,直接录入数据。
习题一的数据表如下:点击Save,输入文件名将文件保存。
2.数据的整理数据编辑窗口的Date可提供数据整理功能。
其主要功能包括定义和编辑变量、观测量的命令,变量数据变换的命令,观测量数据整理的命令。
以习题一为例,将上图中的数据进行整理,以GDP值为参照,升序排列。
数据整理后的数据表为:整理后的数据,可以直观看出GDP值的排列。
3、频数分析。
以习题一为例(1).单击“分析→描述统计→频率”(2)打开“频率”对话框,选择GDP为变量(3)单击“统计量”按钮,打开“统计量”对话框.选择中值及中位数。
得到如下结果:(4)单击“分析→描述统计→探索”,打开“探索”对话框,选择GDP(亿元),输出为统计量。
结果如下:4、探索分析以习题2为例子:(1)单击“分析→统计描述→频率”,打开“频率”对话框,选择“身高”变量。
(2)选择统计量,分别选择百分数,均值,标准差,单击图标。
的如下结果:(3)单击“分析→统计描述→探索”,选择相应变量变量,单击“绘制”,选择如下图表,的如下结果:从上述图标可以看出,除了个别极端点以外,数据都围绕直线上下波动,可以看出,该组数据,在因子水平下符合正态分布。
4.交叉列联表分析:以习题3,原假设是吸烟与患病无关备择假设是吸烟与患病有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应变量变量,单击精确,并选择“统计量”按钮,选择“卡方”作为统计量检验,然后单击“单元格”按钮,选择“观测值”和“期望值”进行计数。
得出分析结果如下:分析得出卡方值为7.469,,自由度是1,P值为0.004<0.05拒绝原假设,故有大于95%的把握认为吸烟和换慢性气管炎有关。
习题4:原假设是性别与安全性能的偏好无关备择假设是性别与安全性能的偏好有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应行列变量然后选择“统计量”按钮,以“卡方”作为统计量检验.单击“单元格”按钮,选择“观测值”和“期望值”进行计数单击“确定”,得出分析结果如下:分析得出卡方值为19自由度是4,P值为0.001<0.05拒绝原假设,故有99.9%的把握认为性别与安全性能的偏好有关5实验作业补充。

SPSS统计分析软件实验报告石河子大学经济与管理学院经济与贸易系国际经济与贸易专业2009级1班雍荣2009165106实验一SPSS基本操作一、实验目的1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;2.掌握SPSS的数据管理功能。
二、实验内容及步骤(一)数据的输入和保存1. SPSS界面当打开SPSS后,展现在我们面前的界面如下:请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
该界面和EXCEL极为相似,很多操作也与EXCEL类似,同学们可以自己试试。
2.定义变量选择菜单Data==>Define Variable。
系统弹出定义变量对话框如下:对话框最上方为变量名,现在显示为“VAR00001”,这是系统的默认变量名;往下是变量情况描述,可以看到系统默认该变量为数值型,长度为8,有两位小数位,尚无缺失值,显示对齐方式为右对齐;第三部分为四个设置更改按钮,分别可以设定变量类型、标签、缺失值和列显示格式;第四部分实际上是用来定义变量属于数值变量、有序分类变量还是无序分类变量,现在系统默认新变量为数值变量;最下方则依次是确定、取消和帮助按钮。
假如有两组数据如下:GROUP 1: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 GROUP 2: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87先来建立分组变量GROUP。
请将变量名改为GROUP,然后单击OK按钮。
现在SPSS的数据管理窗口如下所示:第一列的名称已经改为了“group”,这就是我们所定义的新变量“group”。
现在我们来建立变量X。
单击第一行第二列的单元格,然后选择菜单Data==>Define Variable,同样,将变量名改为X,然后确认。
SPSS应用实验报告1孙华绪2016-4-28SPSS是进行数据文件分析的一项重要工具,在当前数据文件应用越来越广泛的情况下,掌握对数据进行处理的方法至关重要。
本节关于SPSS实验课中,我主要收获到了以下内容,形成如下报告。
我们实验课中所应用的SPSS软件实验环境是建立在Windows XP操作系统之下的SPSS12.0(汉化)版本,并有Excel软件系统。
首先在其启动时,有如下界面出现:选择“输入数据”即可进入其主界面,它是一个类似于Excel软件工作表的窗格:可以看到,在图中有“数据视图”和“变量视图”两个窗口标签,在“变量视图”定义了相关属性后,就可以在“数据视图”中录入数据并进行进一步编辑了,“变量视图”中属性系统最先会有默认值,如下所示:在实验中,最重要的还是对数据编辑与整理的操作,对此,我们借助了教材附带的光盘所提供的数据库。
进行编辑与处理时,主要是用菜单栏中“文件”、“编辑”等10项内容。
其中“数据”、“转换”、“分析”、“图形”是最主要的。
如下图所示:同时又可以看到,在菜单栏每个项目之下,又有许多包含的子功能。
因而毋庸置疑,SPSS处理数据的方面是非常广的,而这些广泛的功能正是我们所要掌握的。
举例来讲,最基础的是插入数据,利用“数据”—“插入个案”即可在光标的前上一行插入新数据。
如图,光标是在现在表格的第4行,于是在第3行形成了新的空白插入量。
再如,排序功能。
利用“数据”—“对个案排序”,选择要排序的项目,即可进行升序或降序的排列:当要选取数据的一部分时,可以采用“数据”—“选择个案”,它包含了“全部个案”、“如果条件满足”、“随机个案样本”等5个方面。
通常情况下我们会有条件的选择,那么就可以在对话框中设定好条件进行筛选,如下图所示:数据的分类汇总也是重要的一方面,在SPSS中也提供了这类功能。
例如对成绩,可以利用“数据”—“分类汇总”项目,从列表框中选定相关变量,在函数功能中确定汇总形式,设定好保存路径,就可以很快的实现汇总。

spss实验报告1《统计分析与SPSS的应用》实验报告一一、数据来源及说明本次试验报告数据来源于1991年美国社会变迁普查(1991 U.S. GeneralSocial Survey)。
在这次试验研究的是美国居民幸福感状况,分析性别、种族和地区之间的差异对幸福感的影响。
研究个案为1991年美国社会变迁普查的1517个个案,主要变量为sex、race、region、happy这四个。
二、统计分析结果(1)整体幸福感表1 General Happiness频率百分比有效百分比累计百分比有效Very Happy 467 30.8 31.1 31.1 Pretty Happy 874 57.5 58.0 58.0Not Too Happy 165 10.9 11.0 11.0 合计1504 99.1 100.0 100.0 缺失NA 13 .9合计1517 100.0图 1 General Happiness的直方图表2 关于General Happy的统计量(2)按性别分析幸福感表3 不同性别的幸福感Respondent’s Sex 频率百分比有效百分比Male 有效Very Happy 206 32.4 32.5Pretty Happy 374 58.8 59.1Not Too Happy 53 8.3 8.4合计633 99.5 100.0缺失NA 3 .5合计635 100Female 有效Very Happy 261 29.6 30.0Pretty Happy 498 56.557.2Not Too Happy 112 12.7 12.9合计871 98.9 100.0缺失NA 10 1.1合计881 100.0图2 分性别幸福箱图(3)按种族分析幸福感表 4 不同人种的幸福感Race of Respondent 频率百分比有效百分比White 有效Very Happy 409 32.4 32.6Pretty Happy 730 57.8 58.1Not Too Happy 117 9.3 9.3合计1256 99.4 100.0缺失NA 8 .6合计1264 100.0Black 有效Very Happy 46 22.5 22.9Pretty Happy 116 56.9 57.7Not Too Happy 39 19.1 19.4合计201 98.5 100.0缺失NA 3 1.5合计204 100.0Other 有效Very Happy 12 24.5 25.5Pretty Happy 26 53.1 55.3Not Too Happy 9 18.4 19.1合计47 95.9 100.0缺失NA 2 4.1合计49 100.0图3分人种幸福感箱图(4)按地区分析幸福感表5 不同地区的幸福感region of the United States 频率百分比有效百分比North East 有效Very Happy 185 27.2 27.5Pretty Happy 412 60.7 61.2Not Too Happy 76 11.2 11.3合计673 99.1 100.0 缺失NA 6 9合计679 100.0South East 有效Very Happy 149 35.9 36.3Pretty Happy 215 51.8 52.3Not Too Happy 47 11.3 11.4合计411 99.0 100.0 缺失NA 4 1.0合计415 100.0West 有效Very Happy 133 31.4 31.7Pretty Happy 245 57.9 58.3Not Too Happy 42 9.9 10.0合计420 99.3 100.0 缺失NA 3 7合计423 100.0图4 分地区幸福感箱图三、结论(1)根据表1的数据,在调查的1517个个案中有1504个个案是有效的,其中Very Happy的为31.1%,Pretty Happy的为58.0%,Not too Happy的为11.0%,均值为1.8,众数为2。

spss上机实验报告I. 实验目的本实验旨在通过使用SPSS软件进行数据分析,加深对SPSS软件的理解和掌握,巩固和深化统计分析的基础知识。
II. 实验内容本实验使用了SPSS软件对一组数据进行了统计分析。
数据包括了100名学生的语文成绩、数学成绩、英语成绩、性别和年龄等信息。
实验内容如下:1. 数据导入和检查将数据文件导入SPSS软件中,并对数据进行检查,排除异常数据。
2. 数据描述性统计分析使用SPSS软件对数据进行描述性统计分析,包括均值、中位数、标准差等统计指标的计算。
3. 方差分析使用SPSS软件对数据进行方差分析,分析不同性别和年龄段学生的语文、数学和英语成绩之间的差异。
III. 实验结果1. 数据导入和检查数据文件成功导入SPSS软件中,并且通过检查,排除了部分异常数据。
2. 数据描述性统计分析经过计算,该组数据的语文平均分为75.3分,数学平均分为78.6分,英语平均分为80.2分,标准差分别为8.5、7.9、6.8。
3. 方差分析通过方差分析,发现女生的语文成绩平均值显著高于男生,F(1,98)=10.76,p<0.01;年龄在18岁以下的学生数学成绩平均值显著高于18岁以上的学生,F(1,98)=3.94, p<0.05;年龄在18岁以上的学生英语成绩平均值显著高于18岁以下的学生,F(1,98)=6.19,p<0.05。
IV. 结论通过本实验,我们进一步掌握了SPSS软件的使用技巧,并且运用统计学基础知识对一组数据进行了分析,得出了有意义的结论。
在以后的学习和工作中,我们将会更加熟练地使用SPSS软件,为我们的研究和工作提供更多的支持和帮助。

实训报告实验课程名称SPSS软件实训系(部)年级专业班学生姓名学号开课时间至学年第学期实验一均值比较与T检验一实验目的1、掌握均值比较,用于计算指定变量的综合描述统计量,2、掌握单样本T检验(One—Sample T Test),检验单个变量的均值与假设之间是否存在差异;3、掌握独立样本T检验(Independent Samples Test),用于检验两组来自独立总体的样本,企图理综题的均值或中心位置是否一样4、掌握配对样本T检验(Paired Samples Test),用于检验两个相关的样本是否来自具有相同均值的总体。
二实验内容1 (1) 解决问题的原理:分析该班的数学成绩与全国的平均成绩70分之间是否有显著性差异,其中全班平均成绩为单个变量的均值,全国平均成绩70分之间为假设检验值,此问题满足单样本T检验(One—Sample T Test)的条件,因此用单样本T检验来解决此问题。
(2) 实验步骤;第1步数据组织;首先建立SPSS数据文件,只需建立一个变量“成绩”,录入相应的数据即可。
第2步打开主对话框;选择Analyze→ Compare Means → One-Sample T Test ,打开同下图样的单样本T检验主对话框。
第3步确定要进行T检验的变量;在上图所示的对话框中,选择“成绩”变量作为检验变量,移入“Test Variable(s)”框中。
第4步输入要检验的值;在上图的对话框中的“Test value”中输入要检验的值,本例应输入70。
(3)结果分析(1)单样本统计量单样本统计量(One-Sample Statistics)(2)单样本T检验结果:当置信水平为95%时,显著性水平为0.05,从单样本T检验(One—Sample T Test)结果表可以看出,双尾检验率P值为0.002,小于0.05,故拒绝原假设,也就是说该班的数学成绩与全国的平均成绩70分之间有显著性差异。

spss实验报告SPSS实验报告引言:本实验旨在探究男性和女性在处理视觉任务时的差异。
研究表明,男性和女性在处理不同类型的视觉信息时有着不同的注意倾向和反应时间。
本实验将运用SPSS软件对实验数据进行分析,进一步研究这种差异的存在及其具体表现。
方法:参与者:本实验共招募了60名大学本科生(30名男性和30名女性),无近视、色盲、疲劳等视觉障碍的健康受试者。
实验材料与设计:实验使用了一台电脑,显示器大小为17英寸,分辨率为1280×1024像素。
实验设计为重复测量设计,所有参与者将接受两个视觉任务:定向判断和颜色识别。
定向判断任务:参与者要在屏幕上显示的五个不同方向的箭头中,判断指向右边的箭头的个数。
该任务共有50个试次,每个试次的箭头数量和方向均不相同。
颜色识别任务:参与者需要判断屏幕上显示的5个不同颜色的圆圈中,颜色不同的圆圈的个数。
该任务共有50个试次,每个试次的颜色和位置均不相同。
数据收集:在每个试次开始时,实验者测量参与者所花费的时间,并将其记录在数据表中。
每个参与者完成两个任务,任务的顺序是随机分配的。
数据分析:首先,我们利用SPSS软件计算了整体样本的平均反应时间(RT)和标准偏差(SD)。
结果显示,整体样本的平均RT 为300.56毫秒,SD为25.34毫秒。
然后,我们将样本按照性别分组,并分别计算男性和女性的平均RT和SD。
结果显示,男性的平均RT为289.45毫秒,SD 为23.67毫秒;女性的平均RT为311.67毫秒,SD为27.98毫秒。
接下来,我们进行了配对样本t检验,比较了男性和女性在两个任务中的平均RT。
结果显示,男性在定向判断任务中的平均RT (279.89毫秒)显著低于女性(297.83毫秒)(t(29)= -2.45, p<0.05)。
然而,男性和女性在颜色识别任务中的平均RT(298.01毫秒和304.51毫秒,分别)之间的差异并不显著(t(29)= -1.32, p>0.05)。

湖北汽车工业学院SPSS实习报告学号20090530501姓名杨文弟指导教师彭娟娟曾智实验一描述性统计分析一、实验目的利用SPSS进行描述性统计分析。
要求掌握频数分析(Frequencies过程)、描述性分析(Descriptives过程)、交叉列联表分析(Crosstabs过程)。
二实验内容从某校选取的3个班级共16名学生的体检列表,要求以班级为单位列表计算年龄,体重和身高的统计量,包括极差,最小最大值,均值,标准差和方差。
给出操作步骤和分析结果。
三实验步骤1 定义变量2 输入数据3 选择分析方法4 单击“OK”按钮,得到输出结果。
对结果进行分析解释。
四实验结果与分析班级Frequency Percent Valid Percent Cumulative PercentValid 一班8 50.0 50.0 50.0 二班 4 25.0 25.0 75.0三班 4 25.0 25.0 100.0Total 16 100.0 100.0年龄12 9 56.3 56.3 87.513 2 12.5 12.5 100.0 Total 16 100.0 100.0体重Frequency Percent Valid Percent Cumulative PercentValid 39 1 6.3 6.3 6.340 1 6.3 6.3 12.541 1 6.3 6.3 18.842 1 6.3 6.3 25.044 6 37.5 37.5 62.545 1 6.3 6.3 68.846 1 6.3 6.3 75.049 1 6.3 6.3 81.350 2 12.5 12.5 93.852 1 6.3 6.3 100.0Total 16 100.0 100.0身高由以上表格可知:选取的三个班十六名学生中,年龄,体重,身高的平均值分别为11.65,44.88,128.625。
均值标准误差分别为0.241,1.05228,1.54347。


实验报告
实验目的: 通过上机操作, 熟练掌握spss相关知识。
实验内容:
(一)1、首先将表格导入到spss中, 出现如下图结果:
2.选择: 分析——描述统计—频率, 出现如下图的表格,
, /
3、将V1导入到变量中, 然后点击统计量, 出现如下图的表格, 在表格中, 点击, 均值、中位数、四分位数, 标准差。
点击继续, 就完成第一题, 出现下图的结果。
以上就是第一题的结果。
(二)
1.首先将表格导入到spss中, 如下图:
2.从上表中, 可知, 方法A要比B.C的只都要高, 可见平均值要高于B.C, 就应该对这三组进行平均值, 方差的计算进行比较。
选择: 分析——描述统计——描述, 出现如下图的表格:
将方法A.B.C分别导入到变量中, 然后点击选项这个按钮, 出现如下图的表格进行选择:
可以选择标准差, 最大值, 最小值, 均值, 然后点击继续, 则会出现结果, 通过对结果进行对比, 选择方案。
由图可知, 方法A的平均值高于B、C, 而且最小值也都大于B、C的最大值, 可知A的组装优越于B、C, 即使标准差大于B, 稳定性稍微差于B, 但总体上组装的结果要比B好, 所以要选择方案A。

CENTRAL SOUTH UNIVERSITYSPSS实验报告学生姓名王强学号**********指导教师邵留国学院商学院专业工商1101实验一、数据集实验目的:掌握基本的统计学理论,学会使用SPSS录入数据,建立SPSS数据集。
实验内容:1.3:三十名儿童身高、体重样本数据如下表所示。
建立SPSS数据集。
三十名儿童身高、体重样本数据实验步骤:步骤一:启动SPSS。
步骤二:选择文件,新建,数据,如图。
步骤三:切换到变量视图,定义变量。
其中,性别变量需要设置值标签。
如图所示。
步骤四:切换到数据视图,按照次序依次输入数据。
步骤五:保存数据.实验结果:实验二:统计量描述实验目的:(1)结合图表描述掌握各种描述性统计量的构造原理及其应用.(2)熟练掌握运用SPSS进行统计描述的基本技能。
实验内容:大学生在校期间的各门课程考试成绩,尽管在学生与学生之间、院系之间、男女生之间以及不同的课程之间,都存在着各种各样的差异,但整体上的分布状况还是有规律可循的.今有两个学院共1040名男女生的统计学和经济学期末考试成绩数据,储存在SPSS数据文件中,文件名:lytjcj。
sav。
试运用图表描述与统计量描述的方法,对此数据展开尽可能全面和深入的描述与分析。
实验步骤:步骤一:打开SPSS数据,文件名:lytjcj.sav。
如图。
步骤二:点击“分析"中的“描述统计",选择“频率",如图所示。
步骤三:弹出一个“频率"对话框,如图。
步骤四:将“统计成绩”和“经济成绩”拖入“变量"框中,点击确定。
实验结果:实验三:参数估计实验目的:(1)掌握单样本总体均值区间估计。
(2)掌握总体均值差区间估计.(3)熟练掌握相关的SPSS操作。
实验内容:某地区的一位针对老年人市场的电视节目赞助商,希望了解老年人每周看电视的时间,因为这个信息对电视节目设计以及广告策略和广告数量的制定有着重要的参考价值。
实验报告课程名称:统计分析软件(SPSS)学生实验报告一、实验目的及要求二、实验描述及实验过程(一)、利用SPSS绘制统计图1、打开“职工数据.sav”,调用Graphs 菜单的Bar功能,绘制直条图。
直条图用直条的长短来表示非连续性资料的数量大小。
弹出Bar Chart定义选项。
2、在定义选项框的下方有一数据类型栏,大多数情形下,统计图都是以组为单位的形式来体现数据的。
在定义选项框的上方有3种直条图可选:Simple为单一直条图、Clustered 为复式直条图、Stacked为堆积式直条图,本实验选单一直条图。
3、点击Define钮,弹出Define Clustered Bar: Summaries for groups of cases对话框,在左侧的变量列表中选基本工资点击按钮使之进入Bars Represent栏的Other summary function选项的Variable框,选性别/文化程度/职称点击按钮使之进入Category Axis框。
1.点击analyze中的Descriptive Statistics选择frequencies,弹出一个frequencies对话框,选中基本工资和年龄拖入Variable(s)列2.点击statistics选择相应的统计量(例如:Mean,.median,mode等)3.点击continue ,点击OK。
(三)、用SPSS做回归分析(一元线性回归)1.点击Graphs 选择Scatter/dot2.选择simple scatter 点击Define3.将基本工资这个变量输入Y-Axis ,将年龄输入X-Axise4.点击OK ,结果如图5.点击analyze中的regression选择linear,将这个基本工资变量输入 Dependent ,将年龄输入Independt(s6.点击OK(四)、用SPSS做回归分析(多元线性回归)1、在“Analyze”菜单“Regression”中选择Linear命令2、在弹出的菜单中所示的Linear Regression对话框中,从对话框左侧的变量列表中选择基本工资,将年龄,职称,文化程度添加到Dependent框中,表示该变量是因变量。
SPSS相关分析实验报告篇一:spss对数据进行相关性分析实验报告实验一一.实验目的掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。
二.实验原理相关性分析是考察两个变量之间线性关系的一种统计分析方法。
更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。
P值是针对原假设H0:假设两变量无线性相关而言的。
一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。
越小,则相关程度越低。
而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。
三、实验内容掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。
(1)检验人均食品支出与粮价和人均收入之间的相关关系。
a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击,弹出一个对话窗口。
C.在对话窗口中点击ok,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间显著相关。
人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间也显著相关。
(2)研究人均食品支出与人均收入之间的偏相关关系。
读入数据后:A.点击系统弹出一个对话窗口。
B.点击OK,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.000<0.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.8665<0.921,说明它们之间的显著性关系稍有减弱。
广东金融学院实验报告课程名称:社会科学统计软件SPSS应用
附四
4.1分析某班级学生的高考数学成绩和全国的平均成绩70之间是否存在显著性差异。
4.1.1 实验过程:
输入数据:
图4-1-1 输入数据
图4-1-2 选择变量
4.1.2实验结果:
下面为
从结果输出表中可以看出,在置信区间95%,其0.584>0.5,拒绝原假设,说明学生的高考数学成绩和全国的平均成绩70之间存在显著性差异。
4.2分析A、B两所高校大一学生的高考数学成绩之间是否存在显著性差异
4.2.1实验过程
图4-2-1 输入数据
图4-2-2 选择独立样本T检验
4.2.2
从上表可以看出,在95%的置信区间上,0.423>0.05,可以认为拒绝原假设。
两所高校大一学生的高考数学成绩之间存在显著性差异。
4.3 研究一个班同学在参加了暑期数学、化学培训班后,学习成绩是否有显著变化。
4.3.1实验过程
图4-3-1 选择配对样本T检验
4.3.2实验结果
从上表可以看出,培训前后的均值变化情况,数学1=72.944<数学2=84.7778;化学1=82.3333<化学2=89.9444;明显提高了。
从上表可以看出,在95%的置信区间上,概率分别为0.046<0.05,0.032<0.05,可以认为接受原假设,一个班同学在参加了暑期数学、化学培训班后,学习成绩不存在显著变化。
涉外经济学院实验报告课程名称:应用统计软件分析(SPSS)专业班级:姓名学号:指导教师:职称:副研究员实验日期: 2016.4.19学生实验报告实验序号一、实验目的及要求二、实验描述及实验过程产负债率、主营业务收入增长率、营收账款周转率、存货周转率、流动资产周转率等。
二、分析相关数据,部分无法直接获取的数据,通过compute过程计算相关指标。
三、将某个指标(变量)通过“可视离散化”或“重新编码为不同变量”进行统计分组,将其分成三组;自行练习个案排序和筛选个案的过程。
四、试着分析一部分总量指标进行统计描述,计算其均值、极值、标准差,并进行简单分析。
五、谈谈你对本次数据查找与分析的体会。
要求:一、数据下载要有数据来源说明,数据的SPSS分析过程和对话框要有相关截屏图。
二、相关数据以excel形式和实验报告以word形式提交,同时,实验报告要求打印。
三、第七周上交。
以上宏观数据可以通过国家统计局下载,企业数据可以通过resset数据库下载。
实验过程与步骤1.打开IBM SPSS Statistics 21,在文件—打开电子表格数据,如图2.选择菜单项转换—计算变量,如图3.选择菜单项转换—重新编码为不同变量,如图4.选择菜单项数据—排序个案5.选择菜单项数据—选择个案,出现一个窗口,如图6.选择菜单项数据—分类汇总,出现一个窗口,如图实验结果与解释得出employee data.Sav 表变量视图和数据视图心得体会我觉得spss对我用处非常大。
我练习了写实验方法和步骤,但在写实验感受方面还有所欠缺。
统计学是一门研究随机事件的学科,这类偶然现象是遵循统计规律的,当随机现象出现大量的次数时,就能体现统计平均规律。
我们只有对数据资料作统计处理,才可能发现它们的在规律,掌握现象的特征,检验研究的假设才能得出准确的、可靠的研究结果。