编译原理语义分析详解
- 格式:ppt
- 大小:1.15 MB
- 文档页数:110

.编译原理课程实验报告实验3:语义分析. .. ...要求:对如下工作进行展开描核心数据结构的设(1Nod本程序使用了两个新的实体类,分别I的属性I是标识符里面也包含了该标识符在本程序中存储的地址和长度等信息I下/privat String name;/基本类privat String type/起始地privatin offset/长in length privat/该数组各维的长publi List<Integer> arr_length得/变量的维度可以根arr_length.size(的属性如下Nod是语法生成树的节点Nod节点/privat String nam父节/privat Node fathe/子节publi List<Node>son/属Map<String,String>attribut publi使用哈希表这是因为各个节点的属性不是统一的的类型是哈Ma其atrribut以方便地创建、使用属性主要功能函数说(2因为语义分析过程与语法分析同步进此次试验的语义分析部分并没有新的功能函数文法符号匹配的过程中,插入语义的,代码都是在第二次第二次实验的基础上,LL(l的功能发作代码。
所以,只有句法分析函analysis(List<Token> token_list了变化,添加了语义分析的功能,其他函数功能基本与实验二相同(3程序核心部分的程序流程图..是否否是否是3-1图四、实验结果及分析得分..要求:对实验结果进行描述和分析,基本内容包括针对一测试程序输出其语义分析结果输出针对此测试程序对应的语义错误报告输出针对此测试程序经过语义分析后的符号表对实验结果进行分析注:其中的测试样例需先用已编写的词法分析程序进行处理测试程序void main () {double d;int a[2][3];d = 0;a[0][1] = 2;if (d == 0) {a[0][1] = d;}else {a[1][1] = 0;}while (a[0][1]<3) {++a[0][1];}}分析结果以及错误报告:. .4-1 图标识符表:4-2图实验结果分析:. ..。

实验3 语义分析实验报告一、实验目的二、通过上机实习, 加深对语法制导翻译原理的理解, 掌握将语法分析所识别的语法成分变换为中间代码的语义翻译方法。
三、实验要求四、采用递归下降语法制导翻译法, 对算术表达式、赋值语句进行语义分析并生成四元式序列。
五、算法思想1.设置语义过程。
(1)emit(char *result,char *ag1,char *op,char *ag2)该函数的功能是生成一个三地址语句送到四元式表中。
四元式表的结构如下:struct{ char result[8];char ag1[8];char op[8];char ag2[8];}quad[20];(2) char *newtemp()该函数回送一个新的临时变量名, 临时变量名产生的顺序为T1, T2, …char *newtemp(void){ char *p;char m[8];p=(char *)malloc(8);k++;itoa(k,m,10);strcpy(p+1,m);p[0]=’t’;return(p);}六、 2.函数lrparser 在原来语法分析的基础上插入相应的语义动作: 将输入串翻译成四元式序列。
在实验中我们只对表达式、赋值语句进行翻译。
源程序代码:#include<stdio.h>#include<string.h>#include<iostream.h>#include<stdlib.h>struct{char result[12];char ag1[12];char op[12];char ag2[12];}quad;char prog[80],token[12];char ch;int syn,p,m=0,n,sum=0,kk; //p是缓冲区prog的指针, m是token的指针char *rwtab[6]={"begin","if","then","while","do","end"};void scaner();char *factor(void);char *term(void);char *expression(void);int yucu();void emit(char *result,char *ag1,char *op,char *ag2);char *newtemp();int statement();int k=0;void emit(char *result,char *ag1,char *op,char *ag2){strcpy(quad.result,result);strcpy(quad.ag1,ag1);strcpy(quad.op,op);strcpy(quad.ag2,ag2);cout<<quad.result<<"="<<quad.ag1<<quad.op<<quad.ag2<<endl;}char *newtemp(){char *p;char m[12];p=(char *)malloc(12);k++;itoa(k,m,10);strcpy(p+1,m);p[0]='t';return (p);}void scaner(){for(n=0;n<8;n++) token[n]=NULL;ch=prog[p++];while(ch==' '){ch=prog[p];p++;}if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){m=0;while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){token[m++]=ch;ch=prog[p++];}token[m++]='\0';p--;syn=10;for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){syn=n+1;break;}}else if((ch>='0'&&ch<='9')){{sum=0;while((ch>='0'&&ch<='9')){sum=sum*10+ch-'0';ch=prog[p++];}}p--;syn=11;if(sum>32767)syn=-1;}else switch(ch){case'<':m=0;token[m++]=ch;ch=prog[p++];if(ch=='>'){syn=21;token[m++]=ch;}else if(ch=='='){syn=22;token[m++]=ch;}else{syn=23;p--;}break;case'>':m=0;token[m++]=ch;ch=prog[p++];if(ch=='='){syn=24;token[m++]=ch;}else{syn=20;p--;}break;case':':m=0;token[m++]=ch;ch=prog[p++];if(ch=='='){syn=18;token[m++]=ch;}else{syn=17;p--;}break;case'*':syn=13;token[0]=ch;break; case'/':syn=14;token[0]=ch;break; case'+':syn=15;token[0]=ch;break; case'-':syn=16;token[0]=ch;break; case'=':syn=25;token[0]=ch;break; case';':syn=26;token[0]=ch;break; case'(':syn=27;token[0]=ch;break; case')':syn=28;token[0]=ch;break; case'#':syn=0;token[0]=ch;break; default: syn=-1;break;}}int lrparser(){//cout<<"调用lrparser"<<endl;int schain=0;kk=0;if(syn==1){scaner();schain=yucu();if(syn==6){scaner();if(syn==0 && (kk==0))cout<<"success!"<<endl;}else{if(kk!=1)cout<<"缺end!"<<endl;kk=1;}}else{cout<<"缺begin!"<<endl;kk=1;}return(schain);}int yucu(){// cout<<"调用yucu"<<endl;int schain=0;schain=statement();while(syn==26){scaner();schain=statement();}return(schain);}int statement(){//cout<<"调用statement"<<endl;char *eplace,*tt;eplace=(char *)malloc(12);tt=(char *)malloc(12);int schain=0;switch(syn){case 10:strcpy(tt,token);scaner();if(syn==18){scaner();strcpy(eplace,expression());emit(tt,eplace,"","");schain=0;}else{cout<<"缺少赋值符!"<<endl;kk=1;}return(schain);break;}return(schain);}char *expression(void){char *tp,*ep2,*eplace,*tt;tp=(char *)malloc(12);ep2=(char *)malloc(12);eplace=(char *)malloc(12);tt =(char *)malloc(12);strcpy(eplace,term ()); //调用term分析产生表达式计算的第一项eplacewhile((syn==15)||(syn==16)){if(syn==15)strcpy(tt,"+");else strcpy(tt,"-");scaner();strcpy(ep2,term()); //调用term分析产生表达式计算的第二项ep2strcpy(tp,newtemp()); //调用newtemp产生临时变量tp存储计算结果emit(tp,eplace,tt,ep2); //生成四元式送入四元式表strcpy(eplace,tp);}return(eplace);}char *term(void){// cout<<"调用term"<<endl;char *tp,*ep2,*eplace,*tt;tp=(char *)malloc(12);ep2=(char *)malloc(12);eplace=(char *)malloc(12);tt=(char *)malloc(12);strcpy(eplace,factor());while((syn==13)||(syn==14)){if(syn==13)strcpy(tt,"*");else strcpy(tt,"/");scaner();strcpy(ep2,factor()); //调用factor分析产生表达式计算的第二项ep2strcpy(tp,newtemp()); //调用newtemp产生临时变量tp存储计算结果emit(tp,eplace,tt,ep2); //生成四元式送入四元式表strcpy(eplace,tp);}return(eplace);}char *factor(void){char *fplace;fplace=(char *)malloc(12);strcpy(fplace,"");if(syn==10){strcpy(fplace,token); //将标识符token的值赋给fplacescaner();}else if(syn==11){itoa(sum,fplace,10);scaner();}else if(syn==27){scaner();fplace=expression(); //调用expression分析返回表达式的值if(syn==28)scaner();else{cout<<"缺)错误!"<<endl;kk=1;}}else{cout<<"缺(错误!"<<endl;kk=1;}return(fplace);}void main(){p=0;cout<<"**********语义分析程序**********"<<endl;cout<<"Please input string:"<<endl;do{cin.get(ch);prog[p++]=ch;}while(ch!='#');p=0;scaner();lrparser();}七、结果验证1、给定源程序begin a:=2+3*4; x:=(a+b)/c end#输出结果2、源程序begin a:=9; x:=2*3-1; b:=(a+x)/2 end#输出结果八、收获(体会)与建议通过此次实验, 让我了解到如何设计、编制并调试语义分析程序, 加深了对语法制导翻译原理的理解, 掌握了将语法分析所识别的语法成分变换为中间代码的语义翻译方法。



编译原理中的词法分析与语法分析原理解析编译原理是计算机科学中的重要课程,它研究的是如何将源程序翻译成目标程序的过程。
而词法分析和语法分析则是编译过程中的两个重要阶段,它们负责将源程序转换成抽象语法树,为接下来的语义分析和代码生成阶段做准备。
本文将从词法分析和语法分析的原理、方法和实现技术角度进行详细解析,以期对读者有所帮助。
一、词法分析的原理1.词法分析的定义词法分析(Lexical Analysis)是编译过程中的第一个阶段,它负责将源程序中的字符流转换成标记流的过程。
源程序中的字符流是没有结构的,而编程语言是有一定结构的,因此需要通过词法分析将源程序中的字符流转换成有意义的标记流,以便之后的语法分析和语义分析的进行。
在词法分析的过程中,会将源程序中的字符划分成一系列的标记(Token),每个标记都包含了一定的语义信息,比如关键字、标识符、常量等等。
2.词法分析的原理词法分析的原理主要是通过有限状态自动机(Finite State Automaton,FSA)来实现的。
有限状态自动机是一个数学模型,它描述了一个自动机可以处于的所有可能的状态以及状态之间的转移关系。
在词法分析过程中,会将源程序中的字符逐个读取,并根据当前的状态和字符的输入来确定下一个状态。
最终,当字符读取完毕时,自动机会处于某一状态,这个状态就代表了当前的标记。
3.词法分析的实现技术词法分析的实现技术主要有两种,一种是手工实现,另一种是使用词法分析器生成工具。
手工实现词法分析器的过程通常需要编写一系列的正则表达式来描述不同类型的标记,并通过有限状态自动机来实现这些正则表达式的匹配过程。
这个过程需要大量的人力和时间,而且容易出错。
而使用词法分析器生成工具则可以自动生成词法分析器的代码,开发者只需要定义好源程序中的各种标记,然后通过这些工具自动生成对应的词法分析器。
常见的词法分析器生成工具有Lex和Flex等。
二、语法分析的原理1.语法分析的定义语法分析(Syntax Analysis)是编译过程中的第二个阶段,它负责将词法分析得到的标记流转换成抽象语法树的过程。

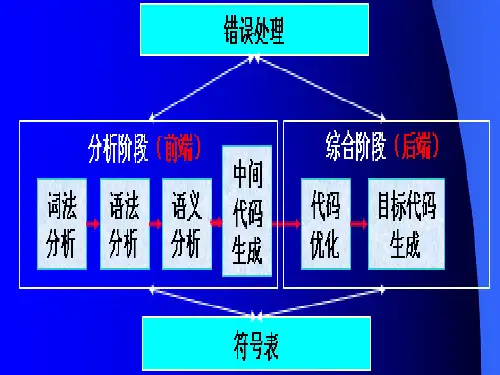


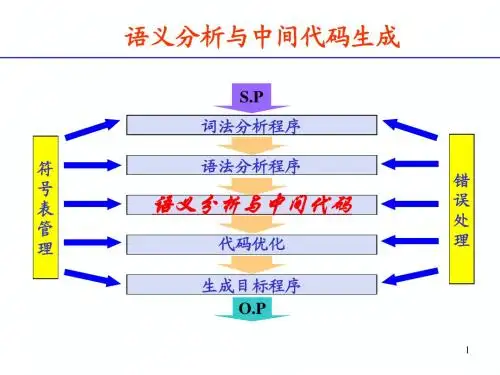

编译原理实验三语法分析并进行语义分析输入:经过词法分析后形成的token[]和tokenstring[]输出:检查有无语法错误,形成语法树,并检查是否符合语义。
样例程序已经能对变量声明填符号表、进行类型检查。
文法:stmt_seq -->statement ; stmt_seq | statementstatement-->decl_stmt | assign_stmtdecl_stmt-->type var_listtype-->int |floatvar_list-->id , var_list | idassign_stmt--> id := expexp-->exp + term | exp - term |termterm--> term * factor | term * factor | factorfactor-->id | num | ( exp )要求掌握理解程序设计方法。
样例程序#include<stdio.h>#include<ctype.h>typedef enum {MINUS,PLUS,TIMES,OVER,LPAREN,RPAREN,SEMI,ASSIGN,NUM,ID,INT,FLOAT,COM MA,DOLLAR} tokentype;/*记号*/typedef enum {stmtk,expk} nodekind;typedef enum {ifk,assignk,declk} stmtkind;typedef enum {opk,constk,idk} expkind;typedef enum {integer,real} exptype;typedef struct treenode{ struct treenode * child[3];struct treenode * sibling;nodekind nodek;exptype dtype ;union { stmtkind stmt; expkind exp;} kind;union { tokentype op;int val;char * name; } attr;} treenode;typedef struct bucket{char * name; exptype dtype; struct bucket * next;} bucket;bucket * hashtable[211];/*tokentype token[6]={ID,ASSIGN,NUM,PLUS,NUM,INT,FLOAT,COMMA,DOLLAR};char tokenstring[6][30]={"ab",":=","12","+","5","$"};*/tokentype token[]={INT,ID,COMMA,ID,SEMI, ID,ASSIGN,NUM,PLUS,NUM,TIMES,NUM,SEMI,ID,ASSIGN,NUM,DOLLAR};chartokenstring[][30]={"int","ab",",","xy",";","ab",":=","12","+","5","*","3",";","xy",":=","34","$"}; int wordindex=0; /*以上两个数组的索引*/treenode * decl();treenode * factor();treenode * term();treenode * exp();treenode * assign_stmt();treenode * stmt_seq();pretraverse(treenode *);int hash ( char * );void st_insert( char * ,exptype);int st_lookup ( char * );void buildsymtab(treenode * );void setnodetype(treenode * );main(){treenode * t;t=stmt_seq(); /*语法分析建语法树*/buildsymtab(t); /*建符号表*/pretraverse(t); /*遍历语法树*/setnodetype(t); /*类型检查设置*/}treenode * stmt_seq(){treenode * t;treenode * p;if(( token[wordindex]==INT)||(token[wordindex]==FLOA T)){t=decl(); }if(token[wordindex]==ID) t=assign_stmt();p=t;while( (token[wordindex]==SEMI)&& (token[wordindex]!=DOLLAR)){treenode * q;wordindex++;q=assign_stmt();p->sibling=q;p=q;}return t;}treenode * assign_stmt(){treenode * t=(treenode *)malloc(sizeof(treenode));if(token[wordindex]==ID){t->nodek=stmtk;t->kind.stmt=assignk;t->=tokenstring[wordindex];wordindex++;}else {printf("error");exit(1);}if(token[wordindex]==ASSIGN)wordindex++;else {printf("error");exit(1);}t->child[0]=exp();t->child[1]=NULL;t->child[2]=NULL;t->sibling=NULL;return t;}treenode * exp(){treenode * t;t=term();while((token[wordindex]==PLUS)||(token[wordindex]==MINUS)) {treenode * p=(treenode *)malloc(sizeof(treenode));p->nodek=expk;p->kind.exp=opk;p->attr.op=token[wordindex];p->child[0]=t;t=p;wordindex++;t->child[1]=term();t->child[2]=NULL;t->sibling=NULL;}return t;}treenode * term(){treenode * t=factor();while((token[wordindex]==TIMES)||(token[wordindex]==OVER)) {treenode * p=(treenode *)malloc(sizeof(treenode));p->nodek=expk;p->kind.exp=opk;p->attr.op=token[wordindex];p->child[0]=t;t=p;wordindex++;t->child[1]=factor();t->child[2]=NULL;t->sibling=NULL;}return t;}treenode * factor(){treenode * t;switch(token[wordindex]){case LPAREN :wordindex++;t=exp();if(token[wordindex]==RPAREN)wordindex++;else {printf("error");exit(1);}break;case NUM :t=(treenode *)malloc(sizeof(treenode));t->nodek=expk;t->kind.exp=constk;t->attr.val=atoi(tokenstring[wordindex]);t->child[0]=NULL;t->child[1]=NULL;t->child[2]=NULL;t->sibling=NULL;wordindex++;break;case ID :t=(treenode *)malloc(sizeof(treenode));t->nodek=expk;t->kind.exp=idk;t->=tokenstring[wordindex];wordindex++;break;default:printf("error");}return t;}pretraverse(treenode * t){if (t!=NULL){ if (t->nodek==stmtk) printf("stmt-id:%s\n",t->);if (t->nodek==expk && t->kind.exp==idk) printf("exp-id:%s\n",t->);if (t->nodek==expk && t->kind.exp==opk) printf("exp-op:%d\n",t->attr.op);if (t->nodek==expk && t->kind.exp==constk) printf("exp-val:%d\n",t->attr.val);if(t->child[0]!=NULL) pretraverse(t->child[0]);if(t->child[1]!=NULL) pretraverse(t->child[1]);if(t->child[2]!=NULL) pretraverse(t->child[2]);if(t->sibling!=NULL) pretraverse(t->sibling);}}treenode * decl(){treenode * p,* q,* t1;treenode * t=(treenode *)malloc(sizeof(treenode));t->nodek=stmtk;t->kind.stmt=declk;t->=tokenstring[wordindex];t->child[1]=NULL;t->child[2]=NULL;wordindex++;if(token[wordindex]==ID){t1=(treenode *)malloc(sizeof(treenode));t->child[0]=t1;t1->nodek= expk;t1->kind.exp=idk;t1->=tokenstring[wordindex];t1->child[0]=NULL;t1->child[1]=NULL;t1->child[2]=NULL;t1->sibling=NULL;wordindex++;p=t1;while( token[wordindex]==COMMA){ wordindex++;q=(treenode *)malloc(sizeof(treenode));q->nodek= expk;q->kind.exp=idk;q->=tokenstring[wordindex];q->child[0]=NULL;q->child[1]=NULL;q->child[2]=NULL;q->sibling=NULL;p->sibling=q;wordindex++;p=q;}return t;}}int hash ( char * key ){ int temp = 0;int i = 0;while (key[i] != '\0'){ temp = ((temp << 4) + key[i]) % 211;++i;}return temp;}void st_insert( char * name,exptype datatype){ int h = hash(name);bucket * l = hashtable[h];while ((l != NULL) && (strcmp(name,l->name) != 0)) l = l->next;if (l == NULL) /* variable not yet in table */{ l = (bucket *) malloc(sizeof(bucket));l->name = name;l->dtype=datatype;l->next = NULL;l->next = hashtable[h];hashtable[h] = l; }}int st_lookup ( char * name ){ int h = hash(name);bucket * l = hashtable[h];while ((l != NULL) && (strcmp(name,l->name) != 0)) l = l->next;if (l == NULL) return -1;else return 1;}void buildsymtab(treenode * t){exptype datatype;treenode * q;if (t!=NULL){ if (t->nodek==stmtk && t->kind.stmt==declk){ if (strcmp(t->,"int")==0) datatype=integer;if(t->=="float") datatype=real;q=t->child[0];while(q!=NULL){ st_insert(q->,datatype);q=q->sibling;}}if(t->nodek!=stmtk && t->kind.stmt!=declk && t->child[0]!=NULL) buildsymtab(t->child[0]);if(t->child[1]!=NULL) buildsymtab(t->child[1]);if(t->child[2]!=NULL) buildsymtab(t->child[2]);if(t->sibling!=NULL) buildsymtab(t->sibling);}}void setnodetype(treenode * t){if(t!=NULL){if(t->child[0]!=NULL) setnodetype (t->child[0]);if(t->child[1]!=NULL) setnodetype (t->child[1]);if (t->nodek==expk && t->kind.exp==idk) {int h = hash(t->);bucket * l = hashtable[h];while ((l != NULL) && (strcmp(t->,l->name) != 0))l = l->next;if (l==NULL) {printf("no declare");exit(1);}else t->dtype=l->dtype;}if (t->nodek==expk && t->kind.exp==constk) t->dtype=integer;if (t->nodek==expk && t->kind.exp==opk) {if(t->child[1]==NULL) t->dtype=t->child[0]->dtype;elseif(t->child[0]->dtype==t->child[1]->dtype )t->dtype=t->child[0]->dtype;else {printf("type no match");exit(1);}} if (t->nodek==stmtk) t->dtype=t->child[0]->dtype;if(t->sibling!=NULL) setnodetype (t->sibling);}}查看主要内存变量:t-> t->attr.valt->child[0]-> t->child[0]->attr.valt->child[1]-> t->child[1]->attr.valt->sibling-> t->sibling->attr.val语法树样例:。