字符串精确匹配及比对
- 格式:ppt
- 大小:1.03 MB
- 文档页数:10

字符串差异对比算法
1.暴力算法(BruteForce算法):这是一种最简单直观的
算法,也被叫做盲目比较算法。
它的原理是从字符串的第一个
字符开始比较,逐个字符进行比较,直到找到差异或者字符比
较完毕。
这种算法的时间复杂度较高,对于较大的字符串效率
较低。
2.动态规划算法(LongestCommonSubsequence,LCS
算法):LCS算法通过构建一个二维矩阵,比较两个字符串的
每个字符,找出最长公共子序列。
最长公共子序列即是两个字
符串中同时出现的最长的子序列。
LCS算法的时间复杂度为
O(m*n),其中m和n分别为两个字符串的长度。
3.基于哈希的算法(Diff算法):Diff算法通过将字符串分
成较小的块或行,然后计算每个块的哈希值,比较两个字符串
中相同的块,并使用其他算法处理不同的块。
这种算法常用于
文本编辑器中的差异对比。
4.基于后缀树的算法(SuffixTree算法):后缀树是一种特殊的树结构,用于表示一个字符串的所有后缀。
SuffixTree算
法通过构建两个字符串的后缀树,并比较两个树的结构,找出
差异。
这种算法的时间复杂度为O(m+n),其中m和n分别为两个字符串的长度。
这些算法各有优缺点,根据具体的应用场景选择合适的算法。
例如,对于较小的字符串比较,暴力算法可能足够简单而有效。
而对于较大的字符串比较,可以采用更为高效的算法,如动态规划算法或基于哈希的算法。
取决于需求,我们可以选择合适的算法来实现字符串差异对比。

数据清洗与整理中的字符串处理与匹配技巧导语:在数据分析和挖掘的过程中,数据清洗与整理是一个关键的环节。
而字符串处理与匹配技巧在数据清洗中扮演着重要角色。
本文将针对数据清洗中常见的字符串处理问题,介绍一些字符串处理与匹配技巧。
一、数据清洗的重要性数据清洗是指对原始数据进行筛选、排除和变换等操作,以保证数据质量和准确性。
数据清洗是数据分析的前提,也是保证数据可靠性的关键。
二、字符串处理的基本技巧1. 字符串的分割在清洗数据时,常常需要将一个包含多个字段的字符串进行分割。
可以使用Python的split()函数或正则表达式来实现字符串的分割。
2. 字符串的替换在数据清洗过程中,有时需要将字符串中的某些特定字符或子串替换为其他字符。
可以使用Python的replace()函数来实现字符串的替换。
3. 字符串的合并当多个字段的数据需要合并成一个字段时,可使用Python的join()函数将它们连接起来。
也可以使用"+"或其他运算符进行合并。
4. 字符串的提取在处理文本数据时,有时需要从一个字符串中提取出特定格式的内容。
此时可以使用正则表达式来匹配并提取需要的内容。
三、常见的字符串处理问题1. 批量修改文件名当需要对多个文件进行批量操作时,常常需要修改它们的文件名。
此时可以通过Python的os模块和正则表达式来批量修改文件名。
2. 清洗HTML标签在从网页抓取数据时,经常会出现HTML标签的干扰。
可以使用正则表达式将HTML标签去除,以便得到干净的文本数据。
3. 清洗特殊字符在文本数据中,常常会出现一些特殊字符,如换行符、制表符等。
可以通过字符串替换或正则表达式来清洗掉这些特殊字符。
4. 提取关键词在文本分析中,提取关键词是一个重要的步骤。
可以使用Python的jieba库来进行中文分词,并结合停用词表和词频统计来提取关键词。
四、字符串匹配的技巧1. 精确匹配在字符串匹配中,有时需要进行精确匹配。

匹配模式的分类及具体应用匹配模式是指对于一些特定的字符串进行匹配,从而得到想要的结果。
它被广泛应用于计算机领域,尤其是在数据处理、搜索引擎、网络爬虫等方面。
根据不同的需求和用途,匹配模式可以分为以下几种:1.精确匹配模式:精确匹配模式是最基本的模式之一,它只能匹配完全相同的字符串。
这种模式很少应用于实际场景,因为大部分情况下所需匹配的字符串并不是完全一致的。
2.模糊匹配模式:模糊匹配模式是一种常见的模式,它可以匹配一些相似的字符串。
在模糊匹配中,常用的算法有模式匹配算法、编辑距离算法等。
这种模式常用于大型搜索引擎中,以提高搜索的准确度。
3.正则表达式匹配模式:正则表达式匹配模式是一种强大的字符串匹配工具,它通过一些特定的符号和规则,可以匹配符合一定规则的字符串。
正则表达式广泛应用于各种编程语言中,如Python、Java 等,用于字符串的提取、过滤及替换操作。
4.文本匹配模式:文本匹配模式是一种针对大文本的匹配方式,通过复杂的算法、分析和数据挖掘技术,可以对海量的文本进行匹配和分析,从而得到所需的结果。
文本匹配常用于情感分析、舆情监测等领域。
在实际应用中,匹配模式的选择取决于不同的需求和场景。
例如,在网络爬虫中,若需要爬取某个网站中的所有URL,可以使用正则表达式匹配模式;若需要对用户的搜索内容进行分析,可以使用文本匹配模式等。
不同的模式擅长解决不同的问题,比较一下它们的优劣,并在实际应用中灵活运用,是解决问题的关键。
总之,匹配模式是一项重要的计算机技术,在我们的日常工作和生活中都扮演着至关重要的角色。
在不断学习和实践中,我们应该熟悉各种模式的特点和应用,才能更好地解决实际问题,提高工作效率。

mysql 匹配字符串的方法一、引言在MySQL中,字符串匹配是一种常见的操作,用于查找、替换或比较字符串数据。
本篇文章将介绍几种常用的方法,帮助您在MySQL 中高效地进行字符串匹配。
二、字符串匹配方法1. LIKE运算符LIKE运算符是MySQL中最常用的字符串匹配方法之一。
它允许您使用通配符来查找包含特定模式的字符串。
常用的通配符有百分号(%)表示任意字符出现任意次数,下划线(_)表示单个字符,和方括号([])内的字符集合。
例如:```scssSELECT * FROM table_name WHERE column_name LIKE'%pattern%';```上述语句将返回column_name中包含指定模式的所有字符串。
2. REGEXP运算符REGEXP运算符用于执行正则表达式匹配。
它提供了更强大的字符串匹配功能,可以匹配更复杂的模式。
例如:```sqlSELECT * FROM table_name WHERE column_name REGEXP'pattern';```上述语句将返回column_name中与指定正则表达式模式匹配的所有字符串。
3. BINARY运算符BINARY运算符用于区分大小写匹配。
在某些情况下,您可能希望将字符串视为大小写敏感进行匹配。
例如:```sqlSELECT * FROM table_name WHERE BINARY column_name ='pattern';```上述语句将返回column_name中与指定模式完全匹配(忽略大小写)的所有字符串。
4. 函数匹配方法除了运算符之外,MySQL还提供了许多字符串函数,可用于匹配字符串。
常用的函数包括LIKE BINARY、REGEXP_LIKE、STRPOS、SUBSTRING_INDEX等。
这些函数提供了更多的灵活性和功能,以满足不同的匹配需求。

python文本对比逻辑在 Python 中,你可以使用字符串操作和比较函数来实现文本对比逻辑。
下面是一些常见的文本对比操作的示例:1. 字符串相等性比较:```pythonstring1 = "这是一个示例文本。
"string2 = "这是一个示例文本。
"if string1 == string2:print("字符串相等")else:print("字符串不相等")```在这个示例中,使用 `==` 操作符来比较两个字符串是否相等。
2. 字符串包含性比较:```pythonstring1 = "这是一个示例文本。
"string2 = "示例文本"if string1.contains(string2):print("string1 包含 string2")else:print("string1 不包含 string2")```在这个示例中,使用 `contains()` 方法来检查 `string1` 是否包含 `string2`。
3. 字符串相似性比较(模糊匹配):```pythonstring1 = "这是一个示例文本。
"string2 = "这是一个类似的示例文本。
"if fuzz.ratio(string1, string2) > 75:print("字符串相似")else:print("字符串不相似")```在这个示例中,使用了 `fuzz.ratio()` 函数来计算两个字符串之间的相似度(百分比)。
如果相似度大于 75%,则认为字符串相似。
这些是一些常见的文本对比逻辑操作的示例,你可以根据具体的需求选择适当的方法进行文本比较。
此外,还有其他更高级的文本比较和相似性计算方法,如词频-逆文档频率(TF-IDF)、余弦相似度等,如果需要更精确的文本对比,可以考虑使用自然语言处理(NLP)相关的库和技术。

python 正则表达式模糊匹配和精确匹配在Python中,正则表达式(regex)是用于模式匹配和数据提取的强大工具。
模糊匹配和精确匹配是两种常用的匹配方式。
模糊匹配:模糊匹配通常用于查找与给定模式相似的字符串。
在Python的正则表达式中,可以使用.*来匹配任意字符(包括空字符)出现任意次数。
例如,正则表达式a.*b将匹配所有以a开始,以b结束的字符串,其中a和b之间的字符数量和内容可以变化。
pythonimport repattern = 'a.*b'text = 'apple banana orange a b'matches = re.findall(pattern, text)print(matches) # 输出: ['apple banana orange a b']精确匹配:精确匹配用于查找与给定模式完全一致的字符串。
在Python的正则表达式中,可以使用^和$分别表示字符串的开头和结尾。
例如,正则表达式^hello$将只匹配字符串hello,而不匹配包含hello的更长字符串。
pythonimport repattern = '^hello$'text = 'hello world'matches = re.findall(pattern, text)print(matches) # 输出: []要使用正则表达式进行模糊匹配和精确匹配,您需要使用Python的re模块。
上面的例子演示了如何使用re模块的findall函数来查找与给定模式匹配的所有字符串。

常见5种基本匹配算法匹配算法在计算机科学和信息检索领域广泛应用,用于确定两个或多个对象之间的相似度或一致性。
以下是常见的5种基本匹配算法:1.精确匹配算法:精确匹配算法用于确定两个对象是否完全相同。
它比较两个对象的每个字符、字节或元素,如果它们在相同位置上完全匹配,则返回匹配结果为真。
精确匹配算法适用于需要确定两个对象是否完全相同的场景,例如字符串匹配、图像匹配等。
2.模式匹配算法:模式匹配算法用于确定一个模式字符串是否出现在一个文本字符串中。
常见的模式匹配算法有暴力法、KMP算法、BM算法等。
暴力法是最简单的模式匹配算法,它按顺序比较模式字符串和文本字符串的每个字符,直到找到一次完全匹配或结束。
KMP算法通过预处理建立一个跳转表来快速定位比较的位置,减少了无效比较的次数。
BM算法利用模式串的后缀和模式串的字符不完全匹配时在文本串中平移模式串的位置,从而快速定位比较的位置。
3.近似匹配算法:4.模糊匹配算法:5.哈希匹配算法:哈希匹配算法用于确定两个对象之间的哈希值是否相等。
哈希值是通过将对象映射到一个固定长度的字符串来表示的,相同的对象会产生相同的哈希值。
常见的哈希匹配算法有MD5算法、SHA算法等。
哈希匹配算法适用于需要快速判断两个对象是否相等的场景,例如文件的完整性校验、数据校验等。
以上是常见的5种基本匹配算法,它们各自适用于不同的场景和需求,选择合适的匹配算法可以提高效率和准确性,并且在实际应用中经常会结合多种算法来获取更好的匹配结果。

字符串匹配度算法字符串匹配度算法是计算两个字符串之间相似程度的一种算法。
在信息检索、文本分类、推荐系统等领域广泛应用。
它通过计算字符串之间的相似度来判断它们之间的关系,从而方便我们进行各种文本处理和分析工作。
字符串匹配度算法的核心思想是将字符串转换为向量表示,然后通过比较向量之间的距离或相似度来衡量字符串之间的相似程度。
常用的字符串匹配度算法有编辑距离算法、余弦相似度算法、Jaccard相似度算法等。
编辑距离算法是最常见的字符串匹配度算法之一,它衡量两个字符串之间的差异程度。
编辑距离算法将两个字符串进行插入、删除和替换操作,使它们变得相同。
通过计算进行了多少次操作,就可以得到它们之间的编辑距离。
编辑距离越小,表示两个字符串越相似。
余弦相似度算法是一种常用的基于向量的字符串匹配度算法。
它将字符串转换为向量表示,然后计算它们之间的夹角余弦值。
夹角余弦值越接近于1,表示两个字符串越相似;越接近于0,表示两个字符串越不相似。
Jaccard相似度算法是一种用于计算集合之间相似度的算法,也可以用于衡量字符串之间的相似度。
Jaccard相似度算法将字符串看作是字符的集合,然后计算它们之间的共同元素比例。
共同元素比例越高,表示两个字符串越相似。
除了这些常用的字符串匹配度算法外,还有很多其他的算法可以用于字符串的相似性比较。
不同的算法适用于不同的场景和需求,我们可以根据具体情况选择合适的算法。
总的来说,字符串匹配度算法是一种十分重要的工具,它可以帮助我们理解和处理文本数据。
在实际应用中,我们可以根据具体的需求选择合适的算法,从而完成各种文本处理和分析任务。
通过深入研究和应用这些算法,我们可以提高信息检索的准确性,加快文本处理的速度,提升推荐系统的效果。
希望大家能够重视字符串匹配度算法的研究和应用,为解决实际问题做出更多贡献。

python字符串匹配算法一、引言在计算机科学中,字符串匹配是指在文本中查找特定模式的子串。
这种操作在很多实际应用中都非常重要,例如在文件搜索、数据过滤、自然语言处理等领域。
Python提供了一些内置函数和库,可以方便地进行字符串匹配。
二、基本算法1. 朴素字符串匹配算法(Naive String Matching):这是一种简单的字符串匹配算法,通过遍历文本串,逐个字符地与模式串进行比较,以确定是否存在匹配。
2. 暴力匹配算法(Brute Force):这是一种基于字符比较的字符串匹配算法,通过逐个字符地比较文本串和模式串,直到找到匹配或者遍历完整个文本串为止。
3. KMP算法(Knuth-Morris-Pratt Algorithm):这是一种高效的字符串匹配算法,通过记忆已经比较过的字符,减少不必要的重复比较,从而提高匹配速度。
三、Python实现1. 朴素字符串匹配算法:在Python中,可以使用`str.find()`方法或`str.index()`方法来查找模式串在文本串中的位置。
示例如下:```pythontext = "Hello, world!"pattern = "world"index = text.find(pattern)if index != -1:print("Pattern found at index", index)else:print("Pattern not found")```2. 暴力匹配算法:在Python中,可以使用`re`模块来实现暴力匹配算法。
示例如下:```pythonimport retext = "Hello, world! This is a test."pattern = "world"matches = re.findall(pattern, text)if matches:print("Pattern found in text")else:print("Pattern not found in text")```3. KMP算法:在Python中,可以使用`re`模块中的`search()`方法来实现KMP算法。
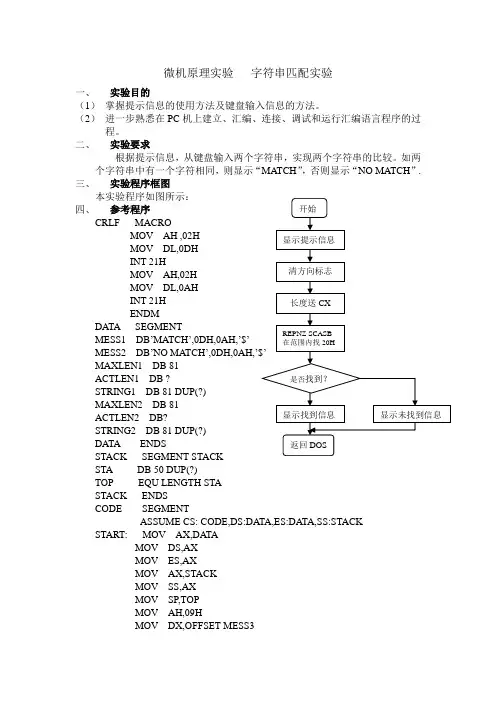
微机原理实验字符串匹配实验一、实验目的(1)掌握提示信息的使用方法及键盘输入信息的方法。
(2)进一步熟悉在PC机上建立、汇编、连接、调试和运行汇编语言程序的过程。
二、实验要求根据提示信息,从键盘输入两个字符串,实现两个字符串的比较。
如两个字符串中有一个字符相同,则显示“MATCH”,否则显示“NO MA TCH”.三、实验程序框图本实验程序如图所示:Array四、参考程序CRLF MACROMOV AH ,02HMOV DL,0DHINT 21HMOV AH,02HMOV DL,0AHINT 21HENDMDATA SEGMENTMESS1 DB’MATCH’,0DH,0AH,’$’MESS2 DB’NO MA TCH’,0DH,0AH,’MAXLEN1 DB 81ACTLEN1 DB ?STRING1 DB 81 DUP(?)MAXLEN2 DB 81ACTLEN2 DB?STRING2 DB 81 DUP(?)DATA ENDSSTACK SEGMENT STACKSTA DB 50 DUP(?)TOP EQU LENGTH STASTACK ENDSCODE SEGMENTASSUME CS: CODE,DS:DA TA,ES:DATA,SS:STACK START: MOV AX,DA TAMOV DS,AXMOV ES,AXMOV AX,STACKMOV SS,AXMOV SP,TOPMOV AH,09HMOV DX,OFFSET MESS3INT 21HCRLFMOV AH,0AHMOV DX,OFFSET MAXLEN1INT 21HCRLFMOV AH,09HMOV DX,OFFSET MESS4INT 21HMOV AX,0AHMOV DX,OFFSET MAXLEN2INT 21HCRLFCLDMOV SI,OFFSET STRING1MOV CL,[SI-1]MOV CH,00HKKK: MOV DI,OFFSET STRING2 PUSH CXMOV CL,[DI-1]MOV CH,00HMOV AL,[SI]MOV DX,DIREPNZ SCASBJZ GGGINC SIPOP CXLOOP KKKMOV AH,09HMOV DX,OFFSET MESS2INT 21HJMP PPPGGG: MOV AH,09HMOV DX,OFFSET MESS1INT 21HPPP: MOV AX,4C00HINT 21HCODE ENDSEND START。

在网络安全的研究中,字符串匹配是一种使用普遍而关键的技术,如杀毒软件、IDS中的特征码匹配、内容过滤等,都需要用到字符串匹配。
作为字符串匹配中的一种特殊情况,近似字符串匹配的研究也同样重要。
这里对经典的字符串匹配算法与思想进行简要分析和总结。
本文的主要参考了《柔性字符串匹配》一书。
不可多得的一部专业书籍,有兴趣者可移步这里下载PDF电子书:柔性字符串匹配下载地址一精确字符串匹配字符串的精确匹配算法中,最著名的有KMP算法和BM算法。
下面分别对几种常用的算法进行描述。
1:KMP算法KMP算法,即Knuth-Morris-Pratt算法,是一种典型的基于前缀的搜索的字符串匹配算法。
Kmp算法的搜索思路应该算是比较简单的:模式和文件进行前缀匹配,一旦发现不匹配的现象,则通过一个精心构造的数组索引模式向前滑动的距离。
这个算法相对于常规的逐个字符匹配的方法的优越之处在于,它可以通过数组索引,减少匹配的次数,从而提高运行效率。
详细算法介绍参考:KMP算法详解(matrix67原创)2:Horspool算法和KMP算法相反,Horspool算法采用的是后缀搜索方法。
Horspool 算法可以说是BM算法的意见简化版本。
在进行后缀匹配的时候,若发现不匹配字符,则需要将模式向右移动。
假设文本中对齐模式最后一个字符的元素是字符C,则Horspool算法根据C的不同情况来确定移动的距离。
实际上,Horspool算法也就是通过最大安全移动距离来减少匹配的次数,从而提高运行效率的。
算法参考:《算法设计与分析基础》第二版清华大学出版社3:BM算法BM算法采用的是后缀搜索(Boyer-Moore算法)。
BM算法预先计算出三个函数值d1、d2、d3,它们分别对应三种不同的情形。
当进行后缀匹配的时候,如果模式最右边的字符和文本中相应的字符比较失败,则算法和Horspool的操作完全一致。
当遇到不匹配的字符并非模式最后字符时,则算法有所不同。
字符串精确匹配算法改进的探讨如何改进字符串匹配算法,提高查询速度,是目前研究的重要领域之一,本文在对BF算法、KMP算法、BM算法、BMH算法、RK算法和SUNDAY算法等几种常见算法分析的基础上,提出改进的意见。
标签:精确匹配;KMP算法;模糊匹配一、引言字符串精确匹配在计算机领域有着广泛的应用, 它可用于数据处理、数据压缩、文本编辑、信息检索等多方面。
如何改进字符串匹配算法,提高查询速度,是目前研究的重要领域之一。
所谓精确字符串匹配问题,是在文本S中找到所有与查询P 精确匹配的子串。
字符串精确匹配要求匹配严格准确,其实现算法主要有BF算法、KMP算法、BM算法、BMH算法、RK算法和SUNDAY算法等。
本文在对这几种常见算法分析的基础上,提出改进的意见。
二、常见算法分析1.BF算法BF(Brute Force)算法是效率最低的算法。
其核心思想是:T是文本串,P是模式串。
首先S[1]和P[1]比较,若相等,则再比较S[2]和P[2],一直到P[M]为止;若S[1]和P[1]不等,则P 向右移动一个字符的位置,再依次进行比较。
如果存在t,1≤t≤N,且S[t+1..t+M]= P[1..M],则匹配成功;否则失败。
该算法最坏情况下要进行M*(N-M+1)次比较,时间复杂度为O(M*N)。
2.KMP 算法KMP(Knuth-Morris-Pratt)算法是D.E.Knuth、J.H.Morris和V.R.Pratt 3 人于1977 年提出来的。
其核心思想是:在匹配失败时,正文不需要回溯,而是利用已经得到的“部分匹配”结果将模式串右移尽可能远的距离,继续进行比较。
这里要强调的是,模式串不一定向右移动一个字符的位置,右移也不一定必须从模式串起点处重新试匹配,即模式串一次可以右移多个字符的位置,右移后可以从模式串起点后的某处开始试匹配。
KMP算法的时间复杂度是O(m+n),最坏情况下时间复杂度为O(m*n)。
实验三、串的模式匹配赵俊1041901229 一、实验内容在给出主串S和模式T(子串)后,实现模式匹配。
若在S中含有模式T,返回子串T在主串S中首次出现的位置。
若T不是S的子串,则匹配失败,返回0。
要求:1. 在串的顺序存储结构下,采用朴素的模式匹配算法BF实现;2.在串的顺序存储结构下,选用模式匹配的KMP算法实现;3.考虑在链式存储结构下,试实现串的模式匹配。
二、实验目的1. 掌握串的顺序存储结构;2. 掌握串的模式匹配的BF算法;3. 掌握串的模式匹配的实现方法;4.了解模式匹配的KMP算法及失效函数的计算方法;5.了解串的链式存储结构三、实验代码#include<stdio.h>#include<tchar.h>int KMPSearch(const char * main_str, const char * sub_str, int * next);void CalculateNext(const char * sub_str, int len, int * next);int BFSearch(const char *main_str,const char *sub_str);#include"stdafx.h"#include<iostream>#include<string>using namespace std;int _tmain(int argc, _TCHAR* argv[]){char*a="abcdeabcdeabc";char *b="eabc";BFSearch(a,b);int next[100];CalculateNext(b,5,next);KMPSearch(a,b,next);return 0;}int BFSearch(const char *main_str,const char *sub_str){int i=0;int j=0;int main_len=strlen(main_str);int sub_len=strlen(sub_str);while((i<main_len)&&(j<sub_len)){if( main_str[i] == sub_str[j]){j++;i++;}else{j=1;i=i-j+2;}}if(j == sub_len){return i-sub_len;}return -1;}int KMPSearch(const char * main_str, const char * sub_str, int * next) {int i=0;int j=0;int main_len=strlen(main_str);int sub_len=strlen(sub_str);while((i<main_len)&&(j<sub_len)){if(j == -1 || main_str[i] == sub_str[j]){j++;i++;}else{j=next[j];}}if(j == sub_len){return i-sub_len;}return -1;}void CalculateNext(const char * sub_str, int len, int * next){int k=-1;int j=0;next[0]=-1;while(j<len){if(k == -1 || sub_str[k] == sub_str[j]){k++;j++;next[j]=k; }else{k=next[k];}}}四、调试和运行结果。
C语言中的字符串匹配算法实现在C语言中,字符串匹配算法用于判断一个字符串是否包含另一个字符串。
本文将介绍几种常见的字符串匹配算法及其实现。
一、暴力匹配算法(Brute-Force Algorithm)暴力匹配算法是最简单直观的字符串匹配算法,也被称为朴素字符串匹配算法。
算法思想:从主字符串的第一个字符开始,依次与模式字符串的字符逐个比较,如果出现字符不匹配的情况,则主字符串的指针后移一位,再从下一个字符开始重新比较。
实现代码示例:```c#include <stdio.h>#include <string.h>int bruteForceMatch(char *str, char *pattern) {int len1 = strlen(str);int len2 = strlen(pattern);int i = 0, j = 0;while(i < len1 && j < len2) {if(str[i] == pattern[j]) {i++;j++;} else {i = i - j + 1;j = 0;}}if(j == len2) {return i - len2; // 返回匹配位置的索引} else {return -1; // 未找到匹配}}int main() {char str[] = "Hello, world!";char pattern[] = "world";int index = bruteForceMatch(str, pattern);if(index >= 0) {printf("匹配成功,匹配位置为:%d\n", index);} else {printf("未找到匹配\n");}return 0;}```上述示例代码中,我们使用了一个bruteForceMatch函数来实现暴力匹配算法。
VBA中的字符串比较与匹配方法指南VBA(Visual Basic for Applications)是一种强大的编程语言,广泛用于Microsoft Office套件中的自动化任务和宏编程。
在VBA编程过程中,处理和比较字符串是常见的需求之一。
本文将为您介绍一些VBA中常用的字符串比较与匹配方法,旨在帮助您更好地处理和操作字符串。
1. 字符串比较字符串比较是一种常见的操作,用于判断两个字符串是否相等。
在VBA中,可以使用“=”运算符来进行字符串比较。
例如:```vbaDim str1 As StringDim str2 As Stringstr1 = "Hello"str2 = "World"' 使用“=”运算符进行字符串比较If str1 = str2 ThenMsgBox "字符串相等"ElseMsgBox "字符串不相等"End If```上述代码会弹出消息框显示字符串不相等,因为“Hello”与“World”是不同的字符串。
2. 字符串忽略大小写比较在某些情况下,我们希望忽略字符串的大小写进行比较。
在VBA中,可以使用StrComp函数来实现。
StrComp函数可以返回一个整数值,表示两个字符串的比较结果。
例如:```vbaDim str1 As StringDim str2 As StringDim result As Integerstr1 = "Hello"str2 = "hello"' 使用StrComp函数进行字符串比较(忽略大小写)result = StrComp(str1, str2, vbTextCompare)If result = 0 ThenMsgBox "字符串相等"ElseMsgBox "字符串不相等"End If```上述代码会弹出消息框显示字符串相等,因为在忽略大小写的情况下,“Hello”和“hello”是相同的字符串。
c语言字符串之间的比较C语言是一种广泛应用于系统程序开发和嵌入式系统领域的编程语言。
字符串是C语言中最常用的数据类型之一,主要用于存储和操作文本数据。
字符串之间的比较是C语言中一个基本的操作,它可以帮助我们判断两个字符串是否相等,或者确定一个字符串在字典中的顺序。
一、比较字符串的方法在C语言中,我们可以使用几种不同的方法来比较字符串。
下面是最常见的几种方法:1.使用strcmp函数进行比较strcmp函数是C语言标准库中提供的一个用于比较字符串的函数。
它的函数原型为:```int strcmp(const char *str1, const char *str2);```该函数接受两个字符串作为参数,并返回一个整数值。
如果两个字符串相等,返回0;如果str1小于str2,则返回一个小于0的值;如果str1大于str2,则返回一个大于0的值。
下面是一个使用strcmp函数比较字符串的示例代码:```c#include <stdio.h>#include <string.h>int main() {char str1[] = "hello";char str2[] = "world";int result = strcmp(str1, str2);if (result == 0) {printf("str1和str2相等\n");} else if (result < 0) {printf("str1小于str2\n");} else {printf("str1大于str2\n");}return 0;}```2.使用strncmp函数进行比较strncmp函数和strcmp函数类似,但是它可以指定比较的字符数。
它的函数原型为:```int strncmp(const char *str1, const char *str2, size_t n);```该函数接受三个参数,分别是两个字符串和要比较的字符数n。