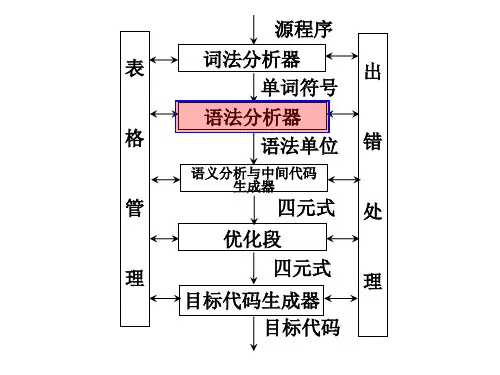
语法分析自下而上分析
- 格式:ppt
- 大小:80.50 KB
- 文档页数:9


实验5---语法分析器(自下而上):LR(1)分析法一、实验目的构造LR(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文法识别的句子,了解LR(K)分析方法是严格的从左向右扫描,和自底向上的语法分析方法。
二、实验内容程序输入/输出示例(以下仅供参考):对下列文法,用LR(1)分析法对任意输入的符号串进行分析:(1)E->E+T(2)E->E—T(3)T->T*F(4)T->T/F(5)F-> (E)(6)F->i输出的格式如下:(1)LR(1)分析程序,编制人:姓名,学号,班级(2)输入一个以#结束的符号串(包括+—*/()i#):在此位置输入符号串(3)输出过程如下:3.对学有余力的同学,测试用的表达式事先放在文本文件中,一行存放一个表达式,同时以分号分割。
同时将预期的输出结果写在另一个文本文件中,以便和输出进行对照。
三、实验方法1.实验采用C++程序语言进行设计,文法写入程序中,用户可以自定义输入语句;2.实验开发工具为DEV C++。
四、实验步骤1.定义LR(1)分析法实验设计思想及算法①若ACTION[sm , ai] = s则将s移进状态栈,并把输入符号加入符号栈,则三元式变成为:(s0s1…sm s , #X1X2…Xm ai , ai+1…an#);②若ACTION[sm , ai] = rj则将第j个产生式A->β进行归约。
此时三元式变为(s0s1…sm-r s , #X1X2…Xm-rA , aiai+1…an#);③若ACTION[sm , ai]为“接收”,则三元式不再变化,变化过程终止,宣布分析成功;④若ACTION[sm , ai]为“报错”,则三元式的变化过程终止,报告错误。
2.定义语法构造的代码,与主代码分离,写为头文件LR.h。
3.编写主程序利用上文描述算法实现本实验要求。
五、实验结果1. 实验文法为程序既定的文法,写在头文件LR.h中,运行程序,用户可以自由输入测试语句。





电力学院编译原理课程实验报告实验名称:实验三自下而上语法分析及语义分析院系:计算机科学与技术学院专业年级:学生:学号:指导教师:实验日期:实验三自上而下的语法分析一、实验目的:通过本实验掌握LR分析器的构造过程,并根据语法制导翻译,掌握属性文法的自下而上计算的过程。
二、实验学时:4学时。
三、实验容根据给出的简单表达式的语法构成规那么〔见五〕,编制LR分析程序,要求能对用给定的语法规那么书写的源程序进展语法分析和语义分析。
对于正确的表达式,给出表达式的值。
对于错误的表达式,给出出错位置。
四、实验方法采用LR分析法。
首先给出S-属性文法的定义〔为简便起见,每个文法符号只设置一个综合属性,即该文法符号所代表的表达式的值。
属性文法的定义可参照书137页表6.1〕,并将其改造成用LR分析实现时的语义分析动作〔可参照书145页表6.5〕。
接下来给出LR分析表。
然后程序的具体实现:●LR分析表可用二维数组〔或其他〕实现。
●添加一个val栈作为语义分析实现的工具。
编写总控程序,实现语法分析和语义分析的过程。
注:对于整数的识别可以借助实验1。
五、文法定义简单的表达式文法如下:(1)E->E+T(2)E->E-T(3)E->T(4)T->T*F(5)T->T/F(6)T->F(7)F->(E)(8)F->i五、处理程序例和处理结果例例如1:20213191*(20213191+3191)+ 3191#六、源代码【cifa.h】//cifa.h#include<string>using namespace std;//单词构造定义struct WordType{int code;string pro;};//函数声明WordType get_w();void getch();void getBC();bool isLetter();bool isDigit();void retract();int Reserve(string str); string concat(string str); 【Table.action.h】//table_action.hclass Table_action{int row_num,line_num;int lineName[8];string tableData[16][8]; public:Table_action(){row_num=16;line_num=8;lineName[0]=30;lineName[1]=7;lineName[2]=13;lineName[3]=8;lineName[4]=14;lineName[5]=1;lineName[6]=2;lineName[7]=15;lineName[8]=0;for(int m=0;m<row_num;m++)for(int n=0;n<line_num;n++)tableData[m][n]="";tableData[0][0]="S5";tableData[0][5]="S4";tableData[1][1]="S6";tableData[1][2]="S12";tableData[1][7]="acc";tableData[2][1]="R3";tableData[2][3]="S7"; tableData[2][4]="S13"; tableData[2][6]="R3"; tableData[2][7]="R3"; tableData[3][1]="R6"; tableData[3][2]="R6"; tableData[3][3]="R6"; tableData[3][4]="R6"; tableData[3][6]="R6"; tableData[3][7]="R6"; tableData[4][0]="S5"; tableData[4][5]="S4"; tableData[5][1]="R8"; tableData[5][2]="R8"; tableData[5][3]="R8"; tableData[5][4]="R8"; tableData[5][6]="R8"; tableData[5][7]="R8"; tableData[6][0]="S5"; tableData[6][5]="S4"; tableData[7][0]="S5";tableData[8][1]="S6"; tableData[8][2]="S12"; tableData[8][6]="S11"; tableData[9][1]="R1"; tableData[9][2]="R1"; tableData[9][3]="S7"; tableData[9][4]="S13"; tableData[9][6]="R1"; tableData[9][7]="R1"; tableData[10][1]="R4"; tableData[10][2]="R4"; tableData[10][3]="R4"; tableData[10][4]="R4"; tableData[10][6]="R4"; tableData[10][7]="R4"; tableData[11][1]="R7"; tableData[11][2]="R7"; tableData[11][3]="R7"; tableData[11][4]="R7"; tableData[11][6]="R7"; tableData[11][7]="R7";tableData[12][5]="S4";tableData[13][0]="S5";tableData[13][5]="S4";tableData[14][1]="R2";tableData[14][2]="R2";tableData[14][3]="S7";tableData[14][4]="S13";tableData[14][6]="R2";tableData[14][7]="R2";tableData[15][1]="R5";tableData[15][2]="R5";tableData[15][3]="R5";tableData[15][4]="R5";tableData[15][5]="R5";tableData[15][6]="R5";tableData[15][7]="R5";}string getCell(int rowN,int lineN) {int row=rowN;int line=getLineNumber(lineN);if(row>=0&&row<row_num&&line>=0&&line<=line_num) return tableData[row][line];elsereturn"";}int getLineNumber(int lineN){for(int i=0;i<line_num;i++)if(lineName[i]==lineN)return i;return -1;}};【Table_go.h】//table_go.hclass Table_go{int row_num,line_num;//行数、列数string lineName[3];int tableData[16][3];public:Table_go(){row_num=16;line_num=3;lineName[0]="E";lineName[1]="T";lineName[2]="F";for(int m=0;m<row_num;m++)for(int n=0;n<line_num;n++)tableData[m][n]=0;tableData[0][0]=1;tableData[0][1]=2;tableData[0][2]=3;tableData[4][0]=8;tableData[4][1]=2;tableData[4][2]=3;tableData[6][1]=9;tableData[6][2]=3;tableData[7][2]=10;tableData[12][1]=14;tableData[12][2]=3;tableData[13][2]=15;}int getCell(int rowN,string lineNa){int row=rowN;int line=getLineNumber(lineNa);if(row>=0&&row<row_num&&line<=line_num) return tableData[row][line];elsereturn -1;}int getLineNumber(string lineNa){for(int i=0;i<line_num;i++)if(lineName[i]==lineNa)return i;return -1;}};【Stack_num.h】class Stack_num{int i; //栈顶标记int *data; //栈构造public:Stack_num() //构造函数{data=new int[100];i=-1;}int push(int m) //进栈操作{i++;data[i]=m;return i;}int pop() //出栈操作{i--;return data[i+1];}int getTop() //返回栈顶{return data[i];}~Stack_num() //析构函数{delete []data;}int topNumber(){return i;}void outStack(){for(int m=0;m<=i;m++)cout<<data[m];}};【Stack_str.h】class Stack_str{int i; //栈顶标记string *data; //栈构造public:Stack_str() //构造函数{data=new string[50];i=-1;}int push(string m) //进栈操作{i++;data[i]=m;return i;}int pop() //出栈操作{data[i]="";i--;return i;}string getTop() //返回栈顶{return data[i];}~Stack_str() //析构函数{delete []data;}int topNumber(){return i;}void outStack(){for(int m=0;m<=i;m++)cout<<data[m];}};【cifa.cpp】//cifa.cpp#include<iostream>#include<string>#include"cifa.h"using namespace std;//关键字表和对应的编码string codestring[10]={"main","int","if","then","else","return","void","cout","endl"}; int codebook[10]={26,21,22,23,24,25,27,28,29};//全局变量char ch;int flag=0;/*//主函数int main(){WordType word;cout<<"请输入源程序序列:";word=get_w();while(word.pro!="#")//#为自己设置的完毕标志{cout<<"("<<word.code<<","<<"“"<<word.pro<<"〞"<<")"<<endl;word=get_w();};return 0;}*/WordType get_w(){string str="";int code;WordType wordtmp;getch();//读一个字符getBC();//去掉空白符if(isLetter()){ //以字母开头while(isLetter()||isDigit()){str=concat(str);getch();}retract();code=Reserve(str);if(code==-1){wordtmp.code=0;wordtmp.pro=str;}//不是关键字else{wordtmp.code=code;wordtmp.pro=str;}//是关键字}else if(isDigit()){ //以数字开头while(isDigit()){str=concat(str);getch();}retract();wordtmp.code=30;wordtmp.pro=str;}else if(ch=='(') {wordtmp.code=1;wordtmp.pro="(";} else if(ch==')') {wordtmp.code=2;wordtmp.pro=")";}else if(ch=='{') {wordtmp.code=3;wordtmp.pro="{";} else if(ch=='}') {wordtmp.code=4;wordtmp.pro="}";} else if(ch==';') {wordtmp.code=5;wordtmp.pro=";";}else if(ch=='=') {wordtmp.code=6;wordtmp.pro="=";} else if(ch=='+') {wordtmp.code=7;wordtmp.pro="+";} else if(ch=='*') {wordtmp.code=8;wordtmp.pro="*";} else if(ch=='>') {wordtmp.code=9;wordtmp.pro=">";} else if(ch=='<') {wordtmp.code=10;wordtmp.pro="<";} else if(ch==',') {wordtmp.code=11;wordtmp.pro=",";} else if(ch=='\'') {wordtmp.code=12;wordtmp.pro="\'";} else if(ch=='-') {wordtmp.code=13;wordtmp.pro="-";} else if(ch=='/') {wordtmp.code=14;wordtmp.pro="/";} else if(ch=='#') {wordtmp.code=15;wordtmp.pro="#";} else if(ch=='|') {wordtmp.code=16;wordtmp.pro="|";}else {wordtmp.code=100;wordtmp.pro=ch;}return wordtmp;}void getch(){if(flag==0) //没有回退的字符ch=getchar();else //有回退字符,用回退字符,并设置标志flag=0;}void getBC(){while(ch==' '||ch=='\t'||ch=='\n')ch=getchar();}bool isLetter(){if(ch>='a'&&ch<='z'||ch>='A'&&ch<='Z')return true;elsereturn false;}bool isDigit(){if(ch>='0'&&ch<='9')return true;elsereturn false;}string concat(string str){return str+ch;}void retract(){flag=1;}int Reserve(string str){int i;for(i=0;i<=8;i++){if(codestring[i]==str) //是某个关键字,返回对应的编码return codebook[i];}if(i==9) //不是关键字return -1;}【LR.cpp】#include<iostream>#include<string>#include<cstdlib>#include"cifa.h"#include"stack_num.h"#include"stack_str.h"#include"table_action.h"#include"table_go.h"using namespace std;void process(){int stepNum=1;int topStat;Stack_num statusSTK; //状态栈Stack_str symbolSTK; //符号栈Stack_num valueSTK; //值栈WordType word;Table_action actionTAB; //行为表Table_go goTAB; //转向表cout<<"请输入源程序,以#完毕:";word=get_w();//总控程序初始化操作symbolSTK.push("#");statusSTK.push(0);valueSTK.push(0);cout<<"步骤\t状态栈\t符号栈\t值栈\t当前词\t动作\t转向"<<endl;//分析while(1){topStat=statusSTK.getTop(); //当前状态栈顶string act=actionTAB.getCell(topStat,word.code);//根据状态栈顶和当前单词查到的动作//输出cout<<stepNum++<<"\t";statusSTK.outStack(); cout<<"\t";symbolSTK.outStack(); cout<<"\t";valueSTK.outStack(); cout<<"\t";cout<<word.pro<<"\t";//行为为“acc〞,且当前处理的单词为#,且状态栈里就两个状态//说明正常分析完毕if(act=="acc"&&word.pro=="#"&&statusSTK.topNumber()==1){cout<<act<<endl;cout<<"分析成功!"<<endl;cout<<"结果为:"<<valueSTK.getTop()<<endl;return;}//读到act表里标记为错误的单元格else if(act==""){cout<<endl<<"不是文法的句子!"<<endl;cout<<"错误的位置为单词"<<word.pro<<"附近。



LL分析法和LR分析法。
1、自上而下语法分析方法(LL分析法)
给定文法G和源程序串r。
从G的开始符号S出发,通过反复使用产生式对句型中的非终结符进行替换(推导),逐步推导出r 。
是一种产生的方法,面向目标的方法。
分析的主旨为选择产生式的合适的侯选式进行推导,逐步使推导结果与r匹配。
2、自下而上语法分析方法(LR分析法)
从给定的输入串r开始,不断寻找子串与文法G中某个产生式P的候选式进行匹配,并用P的左部代替(归约)之,逐步归约到开始符号S。
是一种辨认的方法,基于目标的方法。
分析的主旨为寻找合适的子串与P的侯选式进行匹配,直到归约到G的S为止。
扩展资料
LALR分析器可以对上下无关文法进行语法分析。
LALR即“Look-AheadLR”。
其中,Look-Ahead为“向前看”,L代表对输入进行从左到右的检查,R代表反向构造出最右推导序列。
LALR分析器可以根据一种程序设计语言的正式语法的产生式而对一段文本程序输入进行语法分析,从而在语法层面上判断输入程序是否合法。
实际应用中的LALR分析器并不是由人手工写成的,而是由类似于yacc和GNU Bison之类的LALR语法分析器生成工具构成。
由机器自动生成的代码相比较于程序员手工的代码,拥有更好的运行效率而且减少了程序员的工作量。
自下而上语法分析1、规约:自下而上的语法分析过程:分为简单优先分析法,算符优先分析法,LR分析法。
2、自下而上的语法分析过程思想:自下而上的语法分析过程是一个最左规约的过程,从输入串开始,朝着文法的开始符号进行规约,直到文法的开始符号为止的过程。
输入串在这里是指词法分析器送来的单词符号组成的二元式的有限序列。
3、自下而上的PDA(下推自动机)工作方式:“移近-规约”方式注:初态时栈内仅有栈顶符“#”,读头指在最左边的单词符号上。
语法分析程序执行的动作:◆移进:读入一个单词并压入栈内,读头后移◆规约:检查栈顶若干符号能否进行规约,若能,就以产生式左部代替该符号串,同时输出产生式编号。
◆识别成功:移近-规约的结局是栈内只剩下栈底符号和文法的开始符号,读头也指向语句的结束符。
◆识别失败。
4、判读一语句是否是该文法的合法语句(可以用语法树)5、优先分析器:简单优先分析法(理论简单,实际比较麻烦)算符优先分析法6、LR分析器7、相邻文法符号之间的优先关系◆在句型中,句柄内各相邻符号之间具有相同的优先级。
◆由于句柄要先规约,所以规定句柄两端符号的优先级要比位于句柄之外的相邻符号的优先级高。
(#的优先级是最低的。
)9、简单优先文法:定义:一个文法G,如果它不含ε的产生式,也不含任何右部相同的不同产生式,并且它的任何符号(X,Y)-X,Y是非终结符或终结符—或者没有关系,或者存在优先级相同或低于、高于等关系之一,则这是一个简单优先文法。
10、简短优先分析的思想1)简单优先矩阵:根据优先关系的定义:将简单优先文法中各文法符号之间的这种关系用一个矩阵表示,称作简单优先矩阵。
2)PDA读入一个单词后,比较栈顶符号和该单词的优先级,若栈顶符号优先级低于该单词,继续读入;若栈顶符号优先级高于或者等于读入符号,则找句柄进行规约,找不到句柄继续读入11、简单优先法的优缺点:1、优点:算法比较好理解。
2、缺点:适用范围小,分析表尺寸太大。
语法分析--⾃上⽽下分析的基本问题语法分析基本概念语法分析的前提:对语⾔的语法结构进⾏描述,采⽤正规式和有限⾃动机描述和识别语⾔的单词符号,⽤上下⽂⽆关⽂法来描述语法规则语法分析的任务:分析⼀个⽂法的句⼦的结构语法分析器的功能:按照⽂法的产⽣式(语⾔的语法规则),识别输⼊符号串是否为⼀个句⼦(合式程序)⾃下⽽上(Bottom-up):从输⼊串开始,逐步进⾏归约,直到⽂法的开始符号,归约:根据⽂法的产⽣式规则,把串中出现的产⽣式的右部替换成左部符号,从树叶节点开始,构造语法树,算符优先分析法、LR分析法⾃上⽽下(Top-down):从⽂法的开始符号出发,反复使⽤各种产⽣式,寻找"匹配"的推导,推导:根据⽂法的产⽣式规则,把串中出现的产⽣式的左部符号替换成右部,从树的根开始,构造语法树,递归下降分析法、预测分析程序⾃上⽽下分析⾯临的问题基本思想:从⽂法的开始符号出发,向下推导,推出句⼦,针对输⼊串,试图⽤⼀切可能的办法,从⽂法开始符号(根结点)出发,⾃上⽽下地为输⼊串建⽴⼀棵语法树多个产⽣式候选带来的问题,回溯问题:分析过程中,当⼀个⾮终结符⽤某⼀个候选匹配成功时,这种匹配可能是暂时的,出错时,不得不“回溯”⽂法左递归问题:⼀个⽂法是含有左递归的,如果存在⾮终结符P⾯临的问题⽂法左递归问题回溯问题构造不带回溯的⾃上⽽下分析算法消除⽂法的左递归性消除回溯消除⽂法的左递归直接左递归的消除间接左递归的消除消除左递归的算法由于对⾮终结符排序的不同,最后所得的⽂法在形式上可能不⼀样。
但不难证明,它们都是等价的消除回溯为了消除回溯必须保证:对⽂法的任何⾮终结符,当要它去匹配输⼊串时,能够根据它所⾯临的输⼊符号准确地指派它的⼀个候选去执⾏任务,并且此候选的⼯作结果应是确信⽆疑的FIRST和FOLLOW集合的构造FIRST集合令G是⼀个不含左递归的⽂法,对G的所有⾮终结符的每个候选α定义它的终结⾸符集FIRST(α)为:提取公共左因⼦FOLLOW集合L: 从左到右扫描输⼊串 L: 最左推导 1:每⼀步只需向前查看⼀个符号FIRST和FOLLOW集合的构造构造每个⽂法符号的FIRST集合构造FOLLOW(A)构造每个⾮终结符的FOLLOW集合对最后的FIRST、FOLLOW集合有点迷,真的有点迷,晚上不该看这个的!!o(╥﹏╥)o。
第五章语法分析——自下而上分析要紧内容:[1]自下而上分析的大体问题[2]算符优先分析法[3]算符优先分析表和优先函数的构造[4]LR分析器的大体原理大体要求:[1]明白得自下而上分析法的大体思想[2]明白得有关归约、短语、句柄、标准归约等概念[3]把握算符优先分析法[4]了解算符优先表和优先函数的构造技术[5]了解LR 分析器大体原理和工作方式教学要点:本章介绍自下而上语法分析方式。
所谓自下而上分析法确实是从输入串开始,慢慢进行“归约”,直至归约到文法的开始符号;或说,从语法树的结尾开始,步步向上“归约”,直到根结。
讲义摘要:5.1 自下而上分析大体问题自下而上分析法的大体思想:从输入串开始,慢慢进行“归约”,直到文法的开始符号。
即从树结尾开始,构造语法树。
所谓归约,是指依照文法的产生式规那么,把产生式的右部替换成左部符号。
自上而下分析的核心问题是:如何判定符号串的可归约性,和如何归约。
即,识别可归约串的问题。
归约自下而上分析法事实上确实是一种“移进-归约”法,即,采纳“移进-归约”思想进行。
实现思想是:对输入符号串自左向右进行扫描,并将输入符逐个移入一个后进先出栈中,边移入边分析,一旦栈顶符号串形成某个句型的句柄时,(该句型对应某产生式的右部,即栈顶生成了某产生式的右部的文法符号串),就将栈顶的这一部份替换成 (归约为) 该产生式的左部符号,这称为归约。
重复这一进程直到归约到栈中只剩文法的开始符号时那么为分析成功,也就确认输入串是文法的句子。
现举例说明。
例1:设文法G[S]为:(1) S→aAcBe(2) A→b(3) A→Ab(4) B→d试对abbcde进行“移进-归约”分析。
步骤: 1 2 3 4 5 6 7 8 9 10解:动作: 进a 进b 归(2) 进b 归(3) 进c 进d 归(4) 进e 归(1)表1符合栈的转变进程自下而上语法分析的进程也可看成自底向上构造语法树的进程,每步归约都是构造一棵子树,最后当输入串终止时恰好构造出整个语法树,如图1所示。