spss数据库的建立与编辑.
- 格式:doc
- 大小:2.75 MB
- 文档页数:21

第2章 SPSS数据文件的建立和管理学习目标1.明确SPSS数据的基本组织形式和数据行列的含义。
2.掌握应从哪些方面描述SPSS数据文件的结构特征。
3.熟练掌握建立SPSS数据文件以及管理SPSS数据的基本操作。
4.熟练掌握在SPSS中读取Excel工作表数据的基本操作,了解读取文本和数据库数据的基本方法。
建立SPSS数据文件是利用SPSS软件进行数据分析的首要工作。
没有完整且高质质的数据,也就没有值得信赖的数据分析结论。
2.1 SPSS数据文件建立SPSS数据文件,应首先了解SPSS数据文件的特点、数据组织的基本方式和相关概念等。
只有这样才能够建立一个完整且全面的数据环境,服务于以后的数据分析工作。
2.1.1SPSS数据文件的特点SPSS数据文件是一种有别于其他文件(如Word文档、文本文件)的有特殊性的文件。
从应用角度理解,这种特殊性表现在两方面。
第一,SPSS数据文件的扩展名是.sav;第二,SPSS数据文件是一种有结构的数据文件。
它由数据的结构和内容两部分组成。
其中,数据的结构记录了数据的类型、取值说明、数据缺失情况等的必要信息,数据的内容是那些待分析的具体数据。
SPSS数据文件与一般文本数据的不同在于:一般文本文件仅有纯数据部分,而没有关于结构的描述。
正是如此,SPSS数据文件不能像一般文件那样可以直接被大多数编辑软件读取,而只能在SPSS软件中打开。
基于上述特点,建立SPSS数据文件时应完成两项任务,第一,描述SPSS数据的结构;第二,录入编辑SPSS的数据内容。
这两部分工作分别在SPSS数据编辑窗口的变量视图中完成。
2.1.2 SPSS数据的基本组织方式SPSS的数据将直观地显示在数据编辑窗口中,形成一张平面二维表格。
待分析的数据将按原始数据方式和计数数据方式组织。
一、原始数据的组织方式如果待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标,那么这些数据就可按原始数据的方式组织。


实验二 SPSS数据录入与编辑一、实验目的通过本次实验,要求掌握SPSS的基本运行程序,熟悉基本的编码方法、了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法。
二、实验性质必修,基础层次三、主要仪器及试材计算机及SPSS软件四、实验内容1.录入数据2.保存数据文件3.编辑数据文件五、实验学时2学时(可根据实际情况调整学时)六、实验方法与步骤1.开机2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS3.认识SPSS数据编辑窗4.按要求录入数据5.联系基本的数据修改编辑方法6.保存数据文件7.关闭SPSS,关机。
七、实验注意事项1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。
2.遇到各种难以处理的问题,请询问指导教师。
3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员同意,禁止使用移动存储器。
4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换,应报指导教师或实验室管理人员同意。
5.上机时间,禁止使用计算机从事与课程无关的工作。
八、上机作业一、定义变量1.试录入以下数据文件,并按要求进行变量定义。
数据:要求:1)对性别(Sex)设值标签“男=0;女=1”。
2)正确设定变量类型。
其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。
3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
2.试录入以下数据文件,保存为“数据”。
实验三统计图的制作与编辑一、实验目的通过本次实验,了解如何制作与编辑各种图形。
二、实验性质必修,基础层次三、主要仪器及试材计算机及SPSS软件四、实验内容1.条形图的绘制与编辑2.直方图的绘制与编辑3.饼图的绘制与编辑五、实验学时2学时六、实验方法与步骤1.开机;2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS;3.按要求完成上机作业;4. 关闭SPSS,关机。
七、实验注意事项1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。






SPSS操作步骤汇总SPSS学习第⼀章数据⽂件的建⽴数据编码Type:Numeric:数值型 string:字符串型Missing:Measure:scale定量变量 nominal定性变量根据已有的变量建⽴新变量1、对于数据进⾏重新编码Transform—recode into different variables—选择input variable output variable –定义新变量的名称—change—开始定义新旧变量—continue2、通过SPSS函数建⽴新变量Transform—compute variable –从function group中选择公式范围下⾯选择具体的公式—if中设置要改变—continue—OK(可以对变量进⾏各种计算)第⼆章清除数据与基本统计分析1、对不合理的数据检查并清理检查:analysis-description statistic-frequencies—选⼊要检查的数据—OK结果:频数统计表—看是否有错误—missing system清理:1.对系统缺失值的清理Data—select case—if condition is satisfied—if—function group(missing)--下⾯选(missing)--continue—output(delete unselected cases)--OK—对num为哪⼀位的进⾏修改2.对sex=3的清理(直接就清除了)Data—select case—if condition is satisfied—if—sex调⼊再输⼊=3—continue-- output(delete unselected cases)--OK—对num为哪⼀位的进⾏修改2. 对相关变量间逻辑性检查和清理Data—select case—if condition is satisfied—if—输⼊表达式(前后逻辑不相符合的表达式)-- continue-- output(delete unselected cases)--OK—对num为哪⼀位的进⾏修改3.统计描述正态分布统计描述1、正态性检验:Analysis—nonparametric tests—legacy dialogs—1-sample K-S—one-sample Kolomogorov Smirnov test –normal—ok/2、统计描述:Analysis—descriptives--time选⼊—options—ok3、按照男⼥统计描述:data—split file –compare group –sex 调⼊—okAnalysis-descriptive statistic –descriptive—time 调⼊—options选择—OK⾮正态分布资料统计描述1、正态性检验nonparametric2、Analysis—descriptive statistics—frequencies 选⼊--statistics选择—OK第三章T检验1、单样本t检验正态性检验—analyze—compare means—one-sample t test—test value选择要对⽐的数值—OK2、配对样本t检验建⽴数据⽂档—两列(前和后)--正态性检验—analysis- compare means—paired sample t test –调⼊—ok3、两独⽴样本t检验(正态性检验的时候采⽤分开组,其他都要合并在⼀起)建⽴数据库—第⼀列(group)第⼆列(数值)-- data—split file –compare group—调⼊group—ok-正态性检验—OK-- data—split file—选择analysis all—analyze—compare means—independent sample t test—选⼊,分组—OK结果分⽅差齐与否第四章⽅差分析(前提正态)1、单因素⽅差分析(就是平常的三个组⽐较)建⽴数据库—第⼀列(group)第⼆列(数值)- data—split file –compare group—调⼊group—ok-正态性检验—OK-- data—splitfile—选择analysis all--analyze—compare means—one-way-anova—数据调⼊dependent list—分组调⼊factor------options—descriptive基本统计描述—homogeneity of variance做⽅差齐性分析—OK2、⽅差分析两两⽐较analyze—compare means—one-way-anova---数据调⼊dependent list—分组调⼊factor—点post hoc—选择SNK LSD3、随机区组设计⽅差分析建⽴数据库—第⼀列(group)第⼆列(block)第三列(数值)--按照group split开,进⾏正态性检验—OK—general liner model—univairate—数值调⼊dependent variable—group和block 调⼊fixed factor—model—custom—build terms(main effects)再把group和block调⼊model下的矩形框---continue—OK如果区组间⽆差别,组间进⾏两两⽐较。

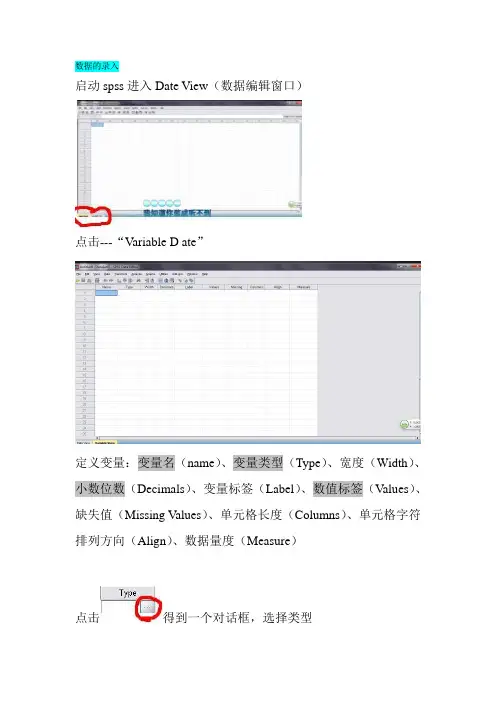
数据的录入启动spss进入Date View(数据编辑窗口)点击---“Variable D ate”定义变量:变量名(name)、变量类型(Type)、宽度(Width)、小数位数(Decimals)、变量标签(Label)、数值标签(Values)、缺失值(Missing V alues)、单元格长度(Columns)、单元格字符排列方向(Align)、数据量度(Measure)点击得到一个对话框,选择类型系统默认宽度为8,小数位2位;一般数字和字符比较常用-------Lable中可以取汉字名字方便查看------Values中可以设定数值标签,既将非数值的记录转换成数值;比如:性别1-女,2-男(一般默认为none)如图填写,点击----“And”----“OK”。
------在Missing中系统默认缺失值“none”用户可自己定义-------其他几项一般都用默认数据的录入-------回到“Date View”中逐个录入数据------“File”--“Save”(或者Ctrl+s)保存到适当的位置内即可数据的导入-----“File”---“Open”---“Date”数据的整理:数据分值转换数据分值的转换时通过对数据的重编码来实现的。
(比如将选项ABCD变成数值进行积分)----数据输入后----“Transform”--“Recode into different Variables”选中其中一个变量将其移到Numeric Variable->Output V ariable在那么中重编码----点击“Change”----“Old And New Values”例如:“Old”中写A----“New”中写1,此时A对应的数值就是1;同理写BCD-------点击“And”----“continue”----回到前一个界面-------将其它需要重编码的都编写一次(不要为了偷懒而一次性写,不会达到相同效果)------编完后-----点击“OK”表2.13前身量表的统分假定一个量表由两个分量表组成,其一为1、2、5、8、9题组成,另一个由3、4、6、7、10题,要求计算出分量表和总量表的分。
spss数据录入教程
1、首先打开SPSS,就是打开之后的初始页面;
2、点击左上角的文件,新建一个文件,文件类型设置为数据;
3、新建结束后,我们就进入了一个界面。
仔细看左下角,分为数据视图和变量视图。
要想输入数据,我们必须先设置好变量;
4、点击变量视图,即可出现如下界面。
我们可以看到变量视图中,第一个变量可以设置的包括名称、类型、宽度、小数、标签、和值等设置类型;
5、这里我们设置两个变量,分别为姓名和年龄。
姓名设置为字符串型,宽度为8位,小数位为0;
6、年龄设置为数值型,宽度为2位,小数位为0;
7、当这些设置完成后,即可出现下列界面,表示变量定义完成;
8、然后点击保存该文档(文件——保存),存在一个自己记得的位置,方便下次可以快速找到它;
9、保存成功后,我们再回到刚刚已经保存的这个界面中,点击左下角的数据视图,就可以输入数据。
授课内容(项目,任务)项目二SPSS Statistics数据创建与数据预处理任务1 数据录入教学目标:1.掌握SPSS Statistics文件打开的方法。
2.掌握SPSS Statistics变量属性设置的方法。
3.掌握SPSS Statistics数据输入的方法。
教学重点、难点:重点:理解数据输入方法。
难点:掌握数据变量各个属性的作用。
教学内容及过程设计补充内容和时间分配一、SPSS Statistics数据编辑窗口子任务1:打开“人口普查.sav”文件,观察数据视图和变量视图。
【步骤1】~【步骤3】子任务2:在打开的“人口普查.sav”文件中,删掉重复的行与空白的行,并保存文件。
【步骤1】~【步骤2】二、SPSS Statistics数据录入与变量设置1.单变量的录入方法(1)变量名称(2)常见变量类型子任务3:打开“变量设置.sav”文件,进行设置。
将“Name”的变量类型改为“字符串”、宽度为6,将“性别”的变量类型改为“字符串”、宽度为2,将“成绩”的变量类型改为“数值”、宽度为3、小数点为0。
【步骤1】~【步骤4】(3)变量标签子任务4:给英文变量Name添加标签“姓名”。
【步骤1】~【步骤2】(4)值标签子任务5:对“性别”变量设置值标签,“1”表示“男”,“2”表示“女”,并在“性别”变量中输入数据“1”“2”,并切换值标签。
【步骤1】~【步骤6】(5)缺失值子任务6:设置缺失值范围,并通过平均值的计算,查看缺失值对于数据分析的影响。
【步骤1】~【步骤8】(5分钟) (5分钟)(10分钟) (5分钟) (10分钟) (15分钟)(6)列宽度(7)对齐方式(8)测量标准①度量变量②有序变量③名义变量子任务7:把“Name”“性别”“成绩”变量都设为“居中”,将“Name”“性别”“成绩”的测量标注设为“名义”“名义”“度量”。
【步骤1】~【步骤2】2.多重响应分析子任务8:在“变量设置.sav”文件中添加4个变量“兼职_家教”(A选项)“兼职_客服”(B选项)“兼职_餐饮”(C选项)“兼职_超市”(D选项),设置变量宽度为1、小数为0、对齐方式为居中,录入3条数据,第1条为“兼职_家教”“兼职_餐饮”,第2条为“兼职_客服”“兼职_餐饮”“兼职_超市”,第3条为“兼职_家教”“兼职_超市”,根据情况录入“1”或“0”,如果选择则录入“1”,不选则录入“0”,并统计结果。