编译原理文法与语言
- 格式:ppt
- 大小:113.00 KB
- 文档页数:50



第3章文法和语言第1题文法G=({A,B,S},{a,b,c},P,S)其中P为:S→Ac|aBA→abB→bc写出L(G[S])的全部元素。
答案:L(G[S])={abc}第2题文法G[N]为:N→D|NDD→0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?答案:G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD....=>NDDDD...D=>D......D或者:允许0开头的非负整数?第3题为只包含数字、加号和减号的表达式,例如9-2+5,3-1,7等构造一个文法。
答案:G[S]:S->S+D|S-D|DD->0|1|2|3|4|5|6|7|8|9第4题已知文法G[Z]:Z→aZb|ab写出L(G[Z])的全部元素。
答案:Z=>aZb=>aaZbb=>aaa..Z...bbb=>aaa..ab...bbbL(G[Z])={anbn|n>=1}第5题写一文法,使其语言是偶正整数的集合。
要求:(1)允许0打头;(2)不允许0打头。
答案:(1)允许0开头的偶正整数集合的文法E→NT|DT→NT|DN→D|1|3|5|7|9D→0|2|4|6|8(2)不允许0开头的偶正整数集合的文法E→NT|DT→FT|GN→D|1|3|5|7|9D→2|4|6|8F→N|0G→D|0第6题已知文法G:<表达式>::=<项>|<表达式>+<项> <项>::=<因子>|<项>*<因子><因子>::=(<表达式>)|i试给出下述表达式的推导及语法树。
(5)i+(i+i)(6)i+i*i答案:(5)<表达式>=><表达式>+<项>=><表达式>+<因子>=><表达式>+(<表达式>)=><表达式>+(<表达式>+<项>)=><表达式>+(<表达式>+<因子>)=><表达式>+(<表达式>+i)=><表达式>+(<项>+i)=><表达式>+(<因子>+i)=><表达式>+(i+i)=><项>+(i+i)=><因子>+(i+i)=>i+(i+i)(6)<表达式>=><表达式>+<项>=><表达式>+<项>*<因子>=><表达式>+<项>*i=><表达式>+<因子>*i=><表达式>+i*i=><项>+i*i=><因子>+i*i=>i+i*i<表达式><表达式>+<项><因子><表达式><表达式>+<项><因子>i<项><因子>i<项><因子>i()<表达式><表达式>+<项><项>*<因子><因子>i<项><因子>ii第7题证明下述文法G[〈表达式〉]是二义的。
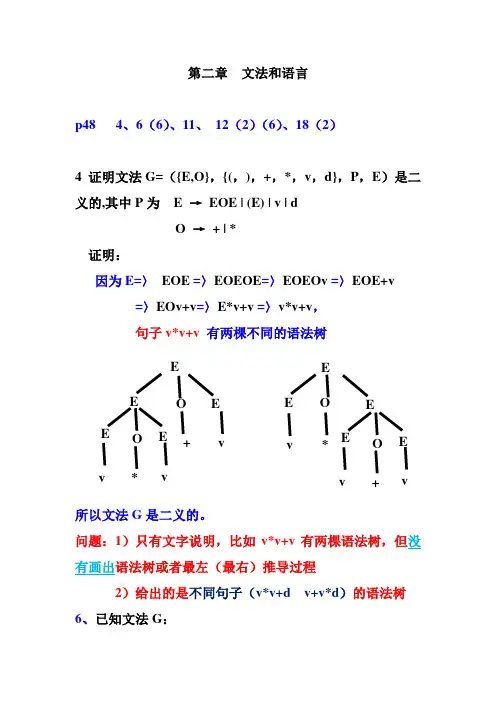
第二章 文法和语言p48 4、6(6)、11、 12(2)(6)、18(2)4 证明文法G=({E,O},{(,),+,*,v ,d},P ,E )是二义的,其中P 为 E → EOE | (E) | v | d O → + | * 证明:因为E=〉 EOE =〉EOEOE =〉EOEOv =〉EOE+v=〉EOv+v =〉E*v+v =〉v*v+v , 句子v*v+v 有两棵不同的语法树所以文法G 是二义的。
问题:1)只有文字说明,比如v*v+v 有两棵语法树,但没有画出语法树或者最左(最右)推导过程2)给出的是不同句子(v*v+d v+v*d )的语法树 6、已知文法G :EEEE OO v*v+ vE EE E O O v+v* v〈表达式〉∷=〈项〉|〈表达式〉+〈项〉〈项〉∷=〈因子〉|〈项〉*〈因子〉〈因子〉∷=(〈表达式〉)| i试给出下述表达式的推导及语法树(6)i+i*i推导过程:〈表达式〉=〉〈表达式〉+〈项〉E=〉E+T =〉〈表达式〉+〈项〉*〈因子〉=〉E+ T*F=〉〈表达式〉+〈项〉* i =〉E+ T*i=〉〈表达式〉+ 〈因子〉* i =〉E+F*i=〉〈表达式〉+ i* i =〉E+i*i=〉〈项〉+ i* i =〉T +i*i=〉〈因子〉+ i* i =〉F +i*i=〉i +i*i =〉i +i*i 共8步推导语法树:〈表达式〉+〈因子〉〈项〉i 〈因子〉i〈项〉〈项〉〈因子〉i*11、一个上下文无关文法生成句子abbaa的推导树如下:(1)给出该句子相应的最左推导和最右推导(2)该文法的产生式集合P可能有哪些元素?(3)找出该句子的所有短语、简单短语、句柄。
(1)最左推导:S=〉ABS=〉aBS=〉aSBBS=〉aBBS=〉abBS=〉abbS =〉abbAa=〉abbaa最右推导:S =〉ABS=〉ABAa=〉ABaa=〉ASBBaa=〉ASBbaa=〉ASbbaa=〉Abbaa=〉abbaa(2)该文法的产生式集合P可能有下列元素:S→ABS | Aa|εA→a B→SBB|b(3)因为字符串中的各字符有相对的位置关系,为了能相互区别,给相同的字符标上不同的数字。




第二章文法和语言本章讲述目前广泛使用的上下文无关文法。
即用上下文无关文法作为程序设计语言语法的描述工具。
阐明语法的一个工具是文法。
本章将介绍文法和语言的概念。
本章重点:上下文无关文法及其句型分析中的有关问题。
第一节文法的直观概念当我们表述一种语言时,无非是说明这种语言的句子,如果语言只含有有穷多个句子,则只需列出句子的有穷集就行了,但对于有无穷句子的语言来讲,存在着如何给出它的有穷表示的问题。
以自然语言为例,人们无法列出全部句子,但是人们可以给出一些规则,用这些规则来说明(或者定义)句子的组成结构,比如:“我是大学生”。
是汉语的一个句子。
汉语句子可以是由主语后随谓语而成,构成谓语的是动词和直接宾语,我们采用EBNF来表示这种句子的构成规则:〈句子〉∷=〈主语〉〈谓语〉〈主语〉∷=〈代词〉|〈名词〉〈代词〉∷=我|你|他〈名词〉∷=王明|大学生|工人|英语〈谓语〉∷=〈动词〉〈直接宾语〉〈动词〉∷=是|学习〈直接宾语〉∷=〈代词〉|〈名词〉“我是大学生”的构成符合上述规则,而“我大学生是”不符合上述规则,我们说它不是句子。
这些规则成为我们判别句子结构合法与否的依据。
一旦有了一组规则以后,我们可以按照如下方式用它们去推导或产生句子。
我们开始去找∷=左端的带有〈句子〉的规则并把它表示成∷=右端的符号串,这个动作表示成:〈句子〉⇒〈主语〉〈谓语〉,然后在得到的串〈主语〉〈谓语〉中,选取〈主语〉或〈谓语〉,再用相应的规则∷=右端代替之。
比如,选取了〈主语〉,并采用规则〈主语〉∷=〈代词〉,那么得到:〈主语〉〈谓语〉⇒〈代词〉〈谓语〉,重复做下去,我们得到句子:“我是大学生”的全部动作过程是:〈句子〉⇒〈主语〉〈谓语〉⇒〈代词〉〈谓语〉⇒我〈谓语〉⇒我〈动词〉〈直接宾语〉⇒我是〈直接宾语〉⇒我是〈名词〉⇒我是大学生符号⇒的含义是,使用一条规则,代替⇒左边的某个符号,产生⇒右端的符号串。
显然,按照上述办法,不仅生成“我是大学生”这样的句子,还可以生成“王明是大学生”,“王明学习英语”,“我学习英语”,“他学习英语”,“你是工人”,“你学习王明”等几十个句子。



四种文法的类型(编译原理)在编译原理中,文法是描述一种语言的形式规则的形式化规范。
根据规则的定义方式和特点,可以将文法分为四类类型,分别是正规文法、上下文无关文法、上下文有关文法和无限制文法。
下面将对这四种文法类型进行详细介绍。
1. 正规文法(Regular Grammar):正规文法是一种最简单的文法类型,也是最严格的限制。
它的产生式右部只能是终结符或一个终结符紧跟一个非终结符,不允许使用任何其它的形式。
正规文法通常用于描述正则语言,而正则语言可以用有限自动机(如DFA、NFA)来识别和生成。
正规文法常用于词法分析中的正则表达式的产生。
2. 上下文无关文法(Context-Free Grammar):上下文无关文法是一种描述语言结构的文法,它具有比正规文法更高的表达能力。
这种文法的产生式右部可以是终结符或非终结符的任意组合顺序。
上下文无关文法通常用于描述上下文无关语言,而上下文无关语言可以用上下文无关文法来生成和识别。
上下文无关文法是编译器设计和分析的主要方法之一,包括语法分析和语法制导翻译等。
3. 上下文有关文法(Context-Sensitive Grammar):上下文有关文法是一种更加灵活的文法,它的产生式右部除了可以是终结符和非终结符的任意组合外,还可以根据上下文条件改变生成式。
产生式的左部和右部可以有相同数量的非终结符,但右部至少有一个符号。
上下文有关文法常用于描述上下文有关语言,也被用于描述自然语言处理等。
4. 无限制文法(Unrestricted Grammar):无限制文法是一种最灵活的文法类型。
它的产生式左部和右部可以是任意长度的终结符和非终结符的组合,没有任何限制和约束条件。
无限制文法通常用于描述递归可枚举语言,递归可枚举语言是图灵机可以识别的语言。
无限制文法被广泛应用于编译器的各个阶段,包括语法制导翻译和语义分析等。
综上所述,正规文法、上下文无关文法、上下文有关文法和无限制文法是编译原理中常用的四种文法类型。
《编译原理》第2章文法和语言的形式定义编译原理是计算机科学中的一门重要课程,它研究的是将高级程序语言翻译成机器语言的方法和技术。
在编译原理中,文法和语言的形式定义是非常重要的概念,本文将围绕这个主题展开详细的讨论。
第2章《文法和语言的形式定义》主要介绍文法和语言的概念、应用及其形式定义的方法。
文法是描述语言结构和语法规则的形式化产物,而语言则是文法所描述的符号集合。
在编译原理中,我们需要通过形式定义的方式来描述和理解程序语言的结构和规则。
下面将对文法和语言的形式定义进行详细解释。
1.文法的定义文法是由产生式(Production)组成的四元组(G,N,P,S),其中:-G:表示文法-N:表示非终结符集合,即一组可以推导出或展开的符号。
-T:表示终结符集合,即不再进行推导或展开的符号。
-P:表示产生式规则集合,是一组指定如何生成目标符号串的规则。
-S:表示一个特殊的非终结符,称为开始符号或起始符号,表示文法的初始状态。
文法的定义可以采用两种形式:巴科斯-诺尔范式(Backus-Naur Form,BNF)和扩充背景文法表达式(Extended Backus-Naur Form,EBNF)。
BNF是最常用的文法定义方法,它使用产生式规则来描述语言的结构和规则。
2.产生式的定义产生式规定了如何用一个符号串替换或展开另一个符号串。
一个产生式由一个非终结符和一个由非终结符和终结符组成的字符串组成。
例如,产生式A->BC,表示用符号串BC替换非终结符A。
产生式可以有多个产生式体,每个产生式体之间使用“,”符号分隔。
例如,产生式A->B,C,表示非终结符A可以被替换成非终结符B或C。
产生式体中可以使用如下符号:-终结符:表示语法中不再与其他符号进行推导的符号,如数字、运算符、关键字等。
-非终结符:表示语法中可以被进一步推导的符号。
-空串:表示不产生任何字符的特殊终结符。
-ε:表示空串。
3.语言的定义语言是符合一些特定文法规则的所有符号串的集合。