SVAR模型制作过程
- 格式:docx
- 大小:534.52 KB
- 文档页数:9
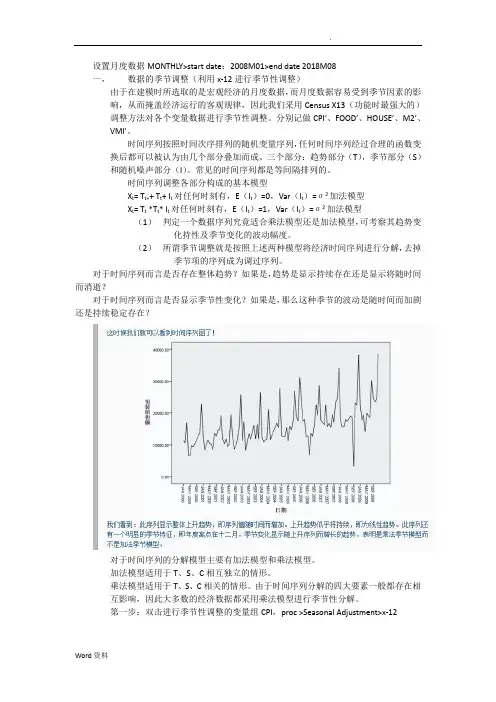
设置月度数据MONTHLY>start date:2008M01>end date 2018M08一,数据的季节调整(利用x-12进行季节性调整)由于在建模时所选取的是宏观经济的月度数据,而月度数据容易受到季节因素的影响,从而掩盖经济运行的客观规律,因此我们采用Census X13(功能时最强大的)调整方法对各个变量数据进行季节性调整。
分别记做CPI’、FOOD’、HOUSE’、M2’、VMI’。
时间序列按照时间次序排列的随机变量序列,任何时间序列经过合理的函数变换后都可以被认为由几个部分叠加而成。
三个部分:趋势部分(T),季节部分(S)和随机噪声部分(I)。
常见的时间序列都是等间隔排列的。
时间序列调整各部分构成的基本模型X t= T t++ T t+ I t对任何时刻有,E(I t)=0,Var(I t)=σ2加法模型X t= T t *T t* I t对任何时刻有,E(I t)=1,Var(I t)=σ2加法模型(1)判定一个数据序列究竟适合乘法模型还是加法模型,可考察其趋势变化持性及季节变化的波动幅度。
(2)所谓季节调整就是按照上述两种模型将经济时间序列进行分解,去掉季节项的序列成为调过序列。
对于时间序列而言是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝?对于时间序列而言是否显示季节性变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在?对于时间序列的分解模型主要有加法模型和乘法模型。
加法模型适用于T、S、C相互独立的情形。
乘法模型适用于T、S、C相关的情形。
由于时间序列分解的四大要素一般都存在相互影响,因此大多数的经济数据都采用乘法模型进行季节性分解。
第一步:双击进行季节性调整的变量组CPI,proc >Seasonal Adjustment>x-12第二步:用Eviews软件进行季节调整的操作步骤:1,准备一个用于调整的时间序列(GDP)(注意:序列需同口径(当月或当季)、不变价、足够长)2,在Eviews中建立工作文件,导入序列数据3,序列图形分析(1)观察序列中的是否有季节性(2)是否有离群值或问题值(3)序列的趋势变动(是加法还是乘法模型)(加法模型主要适用于呈线性增长的数据序列,或者是围绕某一个中指波动的数据序列,如pmi数据序列)(乘法模型主要适用于呈指数级数增长的序列,如GDP、工业增加值,投资数据的名义值、实际值及物价的指数序列等。

1、结构向量自回归模型(SVAR )(1)系统概述结构向量自回归模型(SVAR )的结构(表达式)、识别与约束、估计、诊断检验(如滞后结构检验、残差检验等)及应用(如脉冲响应分析、方差分解等)、预测及评估。
(2)利用例题9.1中的数据,构建结构向量自回归模型,实现以上内容,分析结果。
结构V AR 模型(Structural V AR ,SV AR),实际是指V AR 模型的结构式,即在模型中包含变量之间的当期关系。
1.两变量的SV AR 模型含有两个变量(k=2)、滞后一阶(p=1)的V AR 模型结构式可以表示为下式(9.1.8) 在模型(9.1.8)中假设:(1)随机误差u xt 和u zt 是白噪声序列,不失一般性,假设方差σx 2 = σz 2 =1 ; (2)随机误差u xt 和u zt 之间不相关,cov(u xt , u zt )=0 。
式(9.1.8)一般称为一阶结构向量自回归模型(SV AR(1))。
它是一种结构式经济模型,引入了变量之间的作用与反馈作用,其中系数c 12 表示变量z t 的单位变化对变量x t 的即时作用,γ21表示x t-1的单位变化对z t 的滞后影响。
虽然u xt 和u zt 是单纯出现在x t 和z t 中的随机冲击,但如果c 21 ≠ 0,则作用在x t 上的随机冲击u xt 通过对x t 的影响,能够即时传到变量z t 上,这是一种间接的即时影响;同样,如果c 12 ≠ 0,则作用在z t 上的随机冲击u zt 也可以对x t 产生间接的即时影响。
冲击的交互影响体现了变量作用的双向和反馈关系。
为了导出V AR 模型的简化式方程,将上述模型表示为矩阵形式该模型可以简单地表示为 (9.1.9)2.多变量的SV AR 模型p 阶结构向量自回归模型SV AR(p )为(9.1.13) 其中:10121111212021211221t t t t xtt t t t zt x c z x z u z c x x z u γγγγγγ----=++++=++++1,2,,t T=10121111212021211221t t t t xt t t t t ztx c z x z u z c x x z u γγγγγγ----=++++=++++10112111220121212211t t xt t t zt x x u c z z u c γγγγγγ---⎛⎫⎛⎫⎛⎫⎛⎫⎛⎫⎛⎫=++ ⎪ ⎪⎪ ⎪ ⎪ ⎪-⎝⎭⎝⎭⎝⎭⎝⎭⎝⎭⎝⎭0011t t t-=++C y ΓΓy u 1,2,,t T=01122t t t p t p t---=++++C y Γy Γy Γy u 121212012111k k k k c c c c c c --⎡⎤⎢⎥--⎢⎥=⎢⎥⎢⎥--⎣⎦C p i i kk i k i k i k i i i k i i i,,2,1,)()(2)(1)(2)(22)(21)(1)(12)(11 =⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=γγγγγγγγγΓ12t t t kt u u u ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦u可以将式(9.1.13)写成滞后算子形式(9.1.14)其中:C (L ) = C 0 -Γ1L -Γ2L 2 -… -Γp L p ,C (L )是滞后算子L 的k ⨯k 的参数矩阵,C 0≠I k 。

AB型SVAR模型公式第一部分经典论文解读第二部分操作步骤余结果解读1、单位根检验,季节调整2、最优滞后阶数得选择3、建立约束矩阵4、建模分析5、模型稳定性的检验6、进行脉冲响应7、方差分解在20世纪80年代,传统的联立方程模型曾经很流行。
这些结构模型越建越大,仿佛能够很好的反应样本的情况,但是对样本外的数据预测能力却很弱。
因此Sim(1980)提出了VAR模型。
简化的VAR 模型的脉冲效应函数并不是唯一的,并且不包含变量之间的当期影响。
经济学是一门不断发展的学问,经济学家试图将结构重新纳入VAR模型之中,并且考虑变量之间的当期影响。
以下是结构VAR模型的设定。
第一部分经典论文解读文章题目:人民币汇率变动对国内价格水平的传递效应文章来源:统计研究内容提要:本文运用长期约束的结构VAR,试图从一个崭新的视角实证考察人民币名义有效汇率对我国价格水平的传递效应。
文章特点在于考虑了汇率和价格可能都是受各种宏观经济因素影响的内生变量,以深入揭示两者之间的内在关系。
研究发现:(1)当发生汇率冲击时,人民币名义有效汇率对国内各价格水平的传递是不完全的,汇率变动对进口价格的影响强于对消费者价格的影响;(2)一旦考虑了经济体受到其他类型的宏观经济冲击后,估计的人民币汇率价格传递率则显得更为明显;(3)汇改后我国汇率传递效应趋于强化。
本文还分析了实证结果背后可能的深层次原因,并讨论相应的政策启示。
关键词:人民币名义有效汇率;汇率传递;宏观经济冲击;结构VAR结论与政策含义:本文采用基于Blanchard-Quah 识别方法的结构VAR,实证研究了1996 年1 月到2008 年10 月期间的人民币汇率价格传递效应。
研究发现:①当经济系统发生了汇率冲击,人民币名义有效汇率对我国消费者价格和进口价格的传递效应不完全,这与许多国内外同类研究结论一致。
②然而,当考虑了我国经济受其他宏观经济变量的冲击后,估计的人民币汇率价格的“传递”效应则显得更为迅速和强烈。




svr模型的构建方法SVR模型的构建方法一、引言支持向量回归(Support Vector Regression,SVR)是一种机器学习算法,用于解决回归问题。
与传统的线性回归模型相比,SVR通过引入核函数和支持向量的概念,能够更好地处理非线性问题。
本文将介绍SVR模型的构建方法,包括数据预处理、选择合适的核函数、确定超参数和模型评估等步骤。
二、数据预处理在构建SVR模型之前,我们需要对数据进行预处理,包括数据清洗、缺失值处理和特征标准化等。
数据清洗的目的是去除异常值和噪声数据,以保证模型的准确性和稳定性。
缺失值处理可以选择删除含有缺失值的样本或使用插补方法填充缺失值。
特征标准化可以将各个特征的取值范围统一,避免某些特征对模型的影响过大。
三、选择合适的核函数核函数是SVR模型的关键组成部分,它用于将输入空间映射到一个高维特征空间,从而使非线性问题变为线性问题。
常用的核函数包括线性核函数、多项式核函数和径向基核函数等。
选择合适的核函数需要考虑数据的特点和问题的复杂度。
线性核函数适用于线性可分问题,多项式核函数适用于具有多项式结构的问题,径向基核函数适用于非线性问题。
四、确定超参数超参数是在模型构建过程中需要手动设置的参数,包括惩罚参数C、核函数参数和松弛变量等。
惩罚参数C控制了模型的复杂度,过大的C会导致过拟合,而过小的C会导致欠拟合。
核函数参数用于调整核函数的形状,不同的核函数有不同的参数设置方式。
松弛变量用于容忍一定程度的误差,过大的松弛变量会导致模型过于宽松,而过小的松弛变量会导致模型过于严格。
确定超参数的方法可以采用网格搜索、交叉验证等。
网格搜索是一种穷举搜索的方法,遍历给定的参数组合,通过交叉验证选择最优的参数组合。
交叉验证是一种模型评估的方法,将数据集划分为训练集和验证集,通过在验证集上的表现评估模型的性能,从而选择最优的超参数。
五、模型评估在构建SVR模型之后,我们需要对模型进行评估,以判断其性能和泛化能力。


S V A R模型制作过程设置月度数据MONTHLY>start date:2008M01>end date 2018M08一,数据的季节调整(利用x-12进行季节性调整)由于在建模时所选取的是宏观经济的月度数据,而月度数据容易受到季节因素的影响,从而掩盖经济运行的客观规律,因此我们采用Census X13(功能时最强大的)调整方法对各个变量数据进行季节性调整。
分别记做CPI’、FOOD’、HOUSE’、M2’、VMI’。
时间序列按照时间次序排列的随机变量序列,任何时间序列经过合理的函数变换后都可以被认为由几个部分叠加而成。
三个部分:趋势部分(T),季节部分(S)和随机噪声部分(I)。
常见的时间序列都是等间隔排列的。
时间序列调整各部分构成的基本模型X t= T t++ T t+ I t对任何时刻有,E(I t)=0,Var(I t)=σ2加法模型X t= T t *T t* I t对任何时刻有,E(I t)=1,Var(I t)=σ2加法模型(1)判定一个数据序列究竟适合乘法模型还是加法模型,可考察其趋势变化持性及季节变化的波动幅度。
(2)所谓季节调整就是按照上述两种模型将经济时间序列进行分解,去掉季节项的序列成为调过序列。
对于时间序列而言是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝?对于时间序列而言是否显示季节性变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在?对于时间序列的分解模型主要有加法模型和乘法模型。
加法模型适用于T、S、C相互独立的情形。
乘法模型适用于T、S、C相关的情形。
由于时间序列分解的四大要素一般都存在相互影响,因此大多数的经济数据都采用乘法模型进行季节性分解。
第一步:双击进行季节性调整的变量组CPI,proc >Seasonal Adjustment>x-12第二步:用Eviews软件进行季节调整的操作步骤:1,准备一个用于调整的时间序列(GDP)(注意:序列需同口径(当月或当季)、不变价、足够长)2,在Eviews中建立工作文件,导入序列数据3,序列图形分析(1)观察序列中的是否有季节性(2)是否有离群值或问题值(3)序列的趋势变动(是加法还是乘法模型)(加法模型主要适用于呈线性增长的数据序列,或者是围绕某一个中指波动的数据序列,如pmi数据序列)(乘法模型主要适用于呈指数级数增长的序列,如GDP、工业增加值,投资数据的名义值、实际值及物价的指数序列等。

SVAR模型制作过程
1.SVAR模型的概念
SVAR模型(Structural Vector Autoregression Model)是基于序
列矩阵和 Vector Autoregression结合的一种统计模型,是一种时间序
列模型,主要用于分析经济数据表现出的动态相互依赖关系。
SVAR模型
又可以分为无参数模型和有参数模型两种,无参数模型是不给定参数的情
况下假设模型结构,而有参数模型是根据具体的历史数据估计出参数值。
传统的 VAR模型以及SVAR模型都假定变量之间是线性关系,然而在现实中,这种关系往往不再是线性关系。
这就需要分析带有非线性关系的变量,这就是SVAR模型的由来。
2.SVAR模型的建立
(1)首先,用户可以设置SVAR模型的有效参数格式,即通过自变量
和因变量之间的关系式来确定模型的参数。
用户可以根据实际需要调整参
数变量的时间顺序,调整模型的预测准确率。
(2)然后,用户可以设置SVAR模型的起始时间段,使模型更突出变
量在一些时间段内的影响。
(3)接着,用户可以收集指定时间段内的实际数据,对数据进行诊断,进行统计和数值分析,以确定模型各个参数的精准值。
(4)最后,用户可以制定模型的拟合方法,通过拟合优化模型的参数,使模型能够适应更多的历史数据。
svar模型的起源、识别、估计与应用以svar模型的起源、识别、估计与应用为标题,本文将介绍svar 模型的背景和原理、如何识别svar模型、如何估计svar模型参数以及svar模型在实际应用中的一些例子。
一、svar模型的起源与背景svar模型(Structural Vector Autoregression Model)是一种经济学中常用的时间序列分析方法,用于研究多个经济变量之间的关系。
svar模型可以用来分析变量之间的因果关系、冲击传导机制等。
svar模型的起源可以追溯到20世纪60年代,由于其简单而灵活的特点,逐渐成为经济学中的重要工具。
二、svar模型的识别在应用svar模型之前,首先需要识别模型的结构。
svar模型的结构识别是指确定模型中的内生变量和外生变量,以及它们之间的因果关系。
常用的结构识别方法有脉冲响应函数、方差分解和瞬时冲击反应函数等。
这些方法可以帮助研究者推断变量之间的因果关系,进而进行后续的分析。
三、svar模型的估计svar模型的估计是对模型参数进行求解的过程。
常用的估计方法有最小二乘法(OLS)和贝叶斯方法。
最小二乘法是一种经典的估计方法,通过最小化残差平方和来估计模型的参数。
贝叶斯方法则是一种基于贝叶斯统计理论的估计方法,可以提供参数的后验分布。
根据实际情况和研究目的,选择合适的估计方法非常重要。
四、svar模型的应用svar模型在经济学领域有着广泛的应用。
首先,svar模型可以用来分析宏观经济变量之间的关系,比如GDP、通胀率、利率等。
通过建立svar模型,可以研究这些变量之间的因果关系,对经济政策的制定提供参考。
其次,svar模型还可以用于分析金融市场的波动和冲击传导机制。
通过估计svar模型,可以研究金融市场变量之间的关系,预测市场的变动趋势。
此外,svar模型还可以应用于其他领域,比如医学、环境科学等,用于分析变量之间的关系和相互影响。
svar模型是一种重要的时间序列分析方法,用于研究变量之间的关系。
(完整版)SVAR模型制作过程设置⽉度数据MONTHLY>start date:2008M01>end date 2018M08⼀,数据的季节调整(利⽤x-12进⾏季节性调整)由于在建模时所选取的是宏观经济的⽉度数据,⽽⽉度数据容易受到季节因素的影响,从⽽掩盖经济运⾏的客观规律,因此我们采⽤Census X13(功能时最强⼤的)调整⽅法对各个变量数据进⾏季节性调整。
分别记做CPI’、FOOD’、HOUSE’、M2’、VMI’。
时间序列按照时间次序排列的随机变量序列,任何时间序列经过合理的函数变换后都可以被认为由⼏个部分叠加⽽成。
三个部分:趋势部分(T),季节部分(S)和随机噪声部分(I)。
常见的时间序列都是等间隔排列的。
时间序列调整各部分构成的基本模型X t= T t++ T t+ I t对任何时刻有,E(I t)=0,Var(I t)=σ2加法模型X t= T t *T t* I t对任何时刻有,E(I t)=1,Var(I t)=σ2加法模型(1)判定⼀个数据序列究竟适合乘法模型还是加法模型,可考察其趋势变化持性及季节变化的波动幅度。
(2)所谓季节调整就是按照上述两种模型将经济时间序列进⾏分解,去掉季节项的序列成为调过序列。
对于时间序列⽽⾔是否存在整体趋势?如果是,趋势是显⽰持续存在还是显⽰将随时间⽽消逝?对于时间序列⽽⾔是否显⽰季节性变化?如果是,那么这种季节的波动是随时间⽽加剧还是持续稳定存在?对于时间序列的分解模型主要有加法模型和乘法模型。
加法模型适⽤于T、S、C相互独⽴的情形。
乘法模型适⽤于T、S、C相关的情形。
由于时间序列分解的四⼤要素⼀般都存在相互影响,因此⼤多数的经济数据都采⽤乘法模型进⾏季节性分解。
第⼀步:双击进⾏季节性调整的变量组CPI,proc >Seasonal Adjustment>x-12第⼆步:⽤Eviews软件进⾏季节调整的操作步骤:1,准备⼀个⽤于调整的时间序列(GDP)(注意:序列需同⼝径(当⽉或当季)、不变价、⾜够长)2,在Eviews中建⽴⼯作⽂件,导⼊序列数据3,序列图形分析(1)观察序列中的是否有季节性(2)是否有离群值或问题值(3)序列的趋势变动(是加法还是乘法模型)(加法模型主要适⽤于呈线性增长的数据序列,或者是围绕某⼀个中指波动的数据序列,如pmi数据序列)(乘法模型主要适⽤于呈指数级数增长的序列,如GDP、⼯业增加值,投资数据的名义值、实际值及物价的指数序列等。
傅里叶红外光谱模型建立
傅里叶红外光谱模型建立是在对样品进行红外光谱分析的过程中,根据样品的光谱特征来建立数学模型的过程。
该模型可以用于对未知样品的鉴定和定量分析。
建立傅里叶红外光谱模型的过程包括以下几个步骤:
1. 数据采集:通过红外光谱仪对一系列标准样品进行光谱采集,得到一系列光谱曲线。
2. 数据处理:将采集到的光谱曲线进行预处理,包括光谱去基线、光谱平滑等处理,以提高数据的质量。
3. 特征提取:对预处理后的光谱曲线进行特征提取,提取出与样品特征相关的光谱数据。
4. 模型建立:将提取到的特征作为输入变量,根据标准样品的已知性质(如成分、含量等)作为输出变量,通过数学方法建立起模型。
5. 模型评估:对模型进行评估,通过交叉验证等方法判断模型的预测能力。
6. 模型应用:将建立好的模型用于未知样品的分析,预测未知样品的性质和含量。
总之,建立傅里叶红外光谱模型的关键在于准确的数据处理和特征提取,以及有效的模型建立和评估。
设置月度数据MONTHLY>start date:2008M01>end date 2018M08一,数据的季节调整(利用x-12进行季节性调整)由于在建模时所选取的是宏观经济的月度数据,而月度数据容易受到季节因素的影响,从而掩盖经济运行的客观规律,因此我们采用Census X13(功能时最强大的)调整方法对各个变量数据进行季节性调整。
分别记做CPI’、FOOD’、HOUSE’、M2’、VMI’。
时间序列按照时间次序排列的随机变量序列,任何时间序列经过合理的函数变换后都可以被认为由几个部分叠加而成。
三个部分:趋势部分(T),季节部分(S)和随机噪声部分(I)。
常见的时间序列都是等间隔排列的。
时间序列调整各部分构成的基本模型X t= T t++ T t+ I t对任何时刻有,E(I t)=0,Var(I t)=σ2加法模型X t= T t *T t* I t对任何时刻有,E(I t)=1,Var(I t)=σ2加法模型(1)判定一个数据序列究竟适合乘法模型还是加法模型,可考察其趋势变化持性及季节变化的波动幅度。
(2)所谓季节调整就是按照上述两种模型将经济时间序列进行分解,去掉季节项的序列成为调过序列。
对于时间序列而言是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝?对于时间序列而言是否显示季节性变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在?对于时间序列的分解模型主要有加法模型和乘法模型。
加法模型适用于T、S、C相互独立的情形。
乘法模型适用于T、S、C相关的情形。
由于时间序列分解的四大要素一般都存在相互影响,因此大多数的经济数据都采用乘法模型进行季节性分解。
第一步:双击进行季节性调整的变量组CPI,proc >Seasonal Adjustment>x-12第二步:用Eviews软件进行季节调整的操作步骤:1,准备一个用于调整的时间序列(GDP)(注意:序列需同口径(当月或当季)、不变价、足够长)2,在Eviews中建立工作文件,导入序列数据3,序列图形分析(1)观察序列中的是否有季节性(2)是否有离群值或问题值(3)序列的趋势变动(是加法还是乘法模型)(加法模型主要适用于呈线性增长的数据序列,或者是围绕某一个中指波动的数据序列,如pmi数据序列)(乘法模型主要适用于呈指数级数增长的序列,如GDP、工业增加值,投资数据的名义值、实际值及物价的指数序列等。
)(对数加法模型主要适用于同比增速呈线性增长的数据序列,如GDP、工业、投资及cpi的同比增速数据;伪加法模型则主要是对某些非负时间序列进行季节调整,他们具有这样的性质:在每一年中的相同月份出现接近与0的正值,在这些月份含有接近于0的季节因子,受这些小因子的影响,季节调整结果将出现偏差。
在一年的特定时期,农产品产量就是这样的数据序列)Cpi,vmi为对数加法模型,(4)必要时还要分析谱图和自相关、偏相关图4,季节调整参数设定(1)季节调整选择项(模型分解方法、季节虑子、调整后的序列变量名)a.勾选x11 method中的multiplicative,seasonal filter中的auto x12defaultb.Component series to save 选择final seasonal factor(_SF)Trend Filter选择Auto (X12 fefat)(2)ARIMA模型参数(序列是否需要做转换、ARIMA说明)(主要是做预测用)(3)交易节假日设定(西方模式,不适合中国模式)(4)离群值设定(5)模型诊断(选上)5,执行季节调整6,查看季节调整后的结果7,分析季节调整的结果诊断报告主要查看M1-M11、以及Q统计量有没有通过检验如果诊断报告不好,返回第4步8,导出数据,在EXCEL中计算环比增长率在建立SVAR模型时,需要考虑变量序列的平稳性,这就要求在建模前需要对变量进行平稳性检验,如果变量序列是平稳的,那么可以直接进行SVAR模型的构建,但是如果变量为非平稳序列那么需要对变量序列进行平稳性处理,常用的方法是做差分和取对数,如若变量序列满足同阶单整,则可以进行协整检验,如若各个变量序列满足协整检验,具有长期的均衡关系,则可以建立SVAR模型。
PROC>Seasonal Adjustment>Census X12Sensonal adjustment(季节调整选择设定),ARMIA Option,Trading Day/Holiday(交易日、节假日设定),Outliers(离群值设定),diagnostics(诊断)。
做的比较粗糙一点:(1)打开变量列,proc>x-13>method>x-11>additive(加法)(2)Output>seasonally adjusted一,对各变量序列的平稳性检验(ADF检验)原因:模型要求所需的变量数据为平稳序列。
(1)单位根检验单位根检验是检验数据的平稳性,或是说单整阶数。
引用高人的回答:滞后阶数的问题。
最佳滞后阶数主要根据AIC SC准则判定,当你选择好检验方式,确定好常数项、趋势项选择后,在lagged differences栏里可以从0开始尝试,最大可以尝试到7。
你一个个打开去观察,看哪个滞后阶数使得结论最下方一栏中的AIC 和SC值最小,那么该滞后阶数则为最佳滞后阶数。
单位根是否应该包括常数项和趋势项可以通过观察序列图确定,通过Quick-graph-line操作观察你的数据,若数据随时间变化有明显的上升或下降趋势,则有趋势项,若围绕0值上下波动,则没有趋势项;其二,关于是否包括常数项有两种观点,一种是其截距为非零值,则取常数项,另一种是序列均值不为零则取常数项。
使得t大于1%,5%,10%条件小的值步骤:第一:利用图形确定常数项和趋势项Quick>series statistic>unit root test其中:检验对象Level(水平序列),1st difference(一阶差分序列),2st difference(二阶差分序列)检验附加项Intercept(常数项,漂移项),trend and intercept(趋势项和漂移项),none(无附加项)Lag length(之后长度)lagged differencesAutomatic selection(系统自动选择之后长度)AIC SIC 等。
User specified(用户自己选择)第二,确定滞后项方法一是在User specified(用户自选模式)中选择从0开始慢慢增加,看下面的AIC与sic的大小,最后AIC与sic最小时,就是滞后项数。
方法二是在Automatic selection中选择AIC模式,可以把最大滞后项数选大一点(7或者以上),软件会自动选择AIC最小时的项,即为滞后项。
D(x(-1))为滞后1项。
(3)Johansen检验(视单整情况而定)Johansen检验的关键是有同阶单整可以进行协整检验。
非同阶单整可不需要进行Johansen检验。
协整检验是两个或多个变量之间具有长期的稳定关系。
但变量协整的必要条件是他们之间时同阶单整,也就是说在进行协整检验之前进行单位根检验。
根据SIMS(1990)的研究结果,只有在变量序列之间存在长期的均衡关系即协整关系时,VAR模型才能避免出现错误识别,才能通过最小二乘法得到一致估计。
(4)建立VAR模型(不断重复直至模型通过三项检验:稳定性,滞后阶数正确,外生变量与内生变量明晰)第一步估计var模型,Objects>New object/Var选择VAR type为:unrestrictedEndogenous Variables :内生变量(d(vmi_d11)差分)(有内生变量为1,有外生变量为0)Exogenous Variables:外生变量估计系数的标准差(圆括号中)及t-统计量(方括号中)d(cpi_d11) d(food_d11) house_d11 d(m1_d11) d(vmi_d11)不断改变Endogenous Variables中(1,?)?=1,2,3……比较结果最下面的AIC 与SC DE 值越小越好,最后确定VAR模型的滞后阶数。
(注意:1,其实在初始设置VAR模型的时候可以任意设置为(1,?)(后面检验的时候才会确认?的滞后阶数是什么)。
(1,1)自己2,默认为全体变量为内生变量(后面检验的时候可以确定哪些是外生变量))。
第二步检验所估计的VAR模型(三个检验)1,VAR 的滞后阶数检验在VAR工作表中VIEWS>lag structure>lag length criteria (填写最大阶数)软件将会用“*”给出某个AIC 或者SC准则的最小值。
(滞后阶数越小越好)。
2,的稳定性检验(AR根小于1,在单位圆内才能满足脉冲分析及方差分解所需条件)。
VIEWS>lag structure>AR ROOTS TABLE/ GRAPH3,Granger检验VIEWS>lag structure>Pairwise Granger Causality Tests3,建立的简约式VAR(?)?为滞后阶数的模型输出样式VIEW>REPRESPENTATION(5)在构建成功VAR模型后,为了验证扰动项之间是否存在同期相关关系,可用残差的同期相关矩阵来描述,可以利用这个模型进行预测即下一步的分析,为了验证扰动项之间是否存在同期相关关系,可以利用残差的同期相关矩阵来描述。
在构建的VAR窗口中:VIEWS>Residuals>correlation matrix进一步表明可以利用同期的影响来构建SVAR 模型。
(5)在已构建的VAR 模型上构建SVAR 模型第一步:实施约束识别条件为k (k -1)/2个,识别约束条件可以是短期约束条件,也可以长期约束条件。
短期约束意味着脉冲响应函数随着时间的变化将会消失,(对D 0进行影响)而长期约束意味着对响应变量未来的值有一个长期的影响。
(更像是累计影响如∑D q ∞q=0不能同时施加长期与短期约束。
短期约束是基于A -B 型SVAR 模型(Ae t =Bu ^t ),长期约束基于脉冲响应的累积响应函数。
(1)短期约束可识别条件:AB 型SVAR 模型至少需要2k 2-k(k+1)/2个约束可识别条件一般假设结构新息u ^t 有单位方差,因此通常对矩阵B 的约束为对角阵(约束个数为k 2-k )或者单位矩阵(约束个数为K 2),以致获得冲击的标准偏差A 矩阵主对角元素一般设为1(约束个数为k )在矩阵B 为单位阵情况下,对A 矩阵的约束相当于对C 0矩阵施加约束,即对变量间同期相关关系的约束,如有三个内生变量税收(1),政府支出(2),产出(3),根据经济理论当期产出不会影响当期政府支出,即矩阵C 0中C 23=0,在约束时当B 为单位阵时,直接写成a 23=约束矩阵中未知元素定义为NA(2)长期约束建立包括长期响应矩阵Ψ模块,约束处填写0,比如第2个内生变量对第1个结构冲击的长期影响为0,则长期响应矩阵模块中第2行第1列约束为0,其他类同,无约束的填写NA施加在当期的约束就是短期约束,(3)为了简便起见应按如下进行SVAR短期约束条件的设立1,AB型SVAR模型至少需要2k2-k(k+1)/2个约束(AB型的特点是,可以明确建立系统内各个内生变量的当期结构关系,并且可以直观地分析标准正交随机扰动项对系统产生冲击后的影响情况,即e t就是所谓的“标准正交随机扰动项”,因为它的组成元素之间互相正交(即互相独立),并且其方差-协方差为单位阵)2,若约束矩阵B为单位阵,此时约束个数为K2个3,若约束矩阵A为主对角元素为1,约束个数为K4,再加上经济原理上,使得在矩阵A中至少增加2k2-k(k+1)/2-(k2+k)个0约束5,构造的约束按照C12=0或者C21=0来进行。