spark之内存计算框架
- 格式:pdf
- 大小:1.33 MB
- 文档页数:21

spark基础教程Spark基础教程介绍了如何使用Spark进行数据处理和分析。
Spark是一个开源的分布式计算框架,旨在通过内存计算以及并行处理来加速大规模数据处理任务。
首先,我们需要安装Spark并配置环境。
Spark支持多种编程语言,包括Scala、Java、Python和R。
可以根据自己的需求选择合适的语言。
一旦环境配置完成,我们可以开始使用Spark的核心概念,如Resilient Distributed Datasets(RDDs)。
RDDs是Spark的灵魂,它代表了分布在集群中的不可变的分区数据集。
我们可以通过RDDs进行数据的转换和操作。
Spark提供了丰富的操作和转换函数,如map、filter、reduce 等,可以对RDDs进行各种运算。
此外,Spark还支持一些高级函数,如join、groupByKey等,用于更复杂的数据处理和分析。
在实际应用中,我们可能需要从外部数据源加载数据,如文本文件、HDFS、数据库等。
Spark提供了用于读取和存储数据的API,可以轻松处理不同格式的数据。
除了RDDs,Spark还引入了DataFrame和Dataset,用于进行结构化数据的处理。
DataFrame是具有命名列的分布式数据集,类似于关系型数据库中的表。
Dataset是DataFrame的扩展,提供了类型安全的API。
Spark还支持常见的机器学习和图计算算法,如分类、回归、聚类、图计算等。
可以使用MLlib进行机器学习任务,使用GraphX进行图计算。
最后,我们需要注意Spark的调优和性能优化。
Spark提供了多种机制来提高作业的性能,如广播变量、累加器、数据分区等。
理解这些机制并进行适当的优化可以显著提升Spark作业的效率。
总结一下,Spark基础教程介绍了Spark的安装和环境配置,RDDs的基本概念和操作,DataFrame和Dataset的使用,以及机器学习和图计算的应用。

Spark大数据处理框架入门与实践概述Spark是现今最流行的大数据处理框架之一,它可以处理多种类型的数据,包括结构化数据、半结构化数据、非结构化数据、日志数据等。
本文将介绍Spark的基本概念与使用方法,并通过实际案例帮助读者快速掌握Spark大数据处理框架。
Spark的基本概念Spark是一种基于内存的分布式计算框架,可以将数据分布在多个节点上进行计算,从而提高计算效率。
Spark的核心理念是弹性分布式数据集(Resilient Distributed Dataset,简称RDD),它是一种分布式的元素集合,通过分布式群集实现高效计算。
RDD 分为两种类型:Spark的高级API中,基于RDD构建的应用程序称为Spark Core。
Spark的优势Speed:Spark使用内存计算,因此速度要比Hadoop快。
Ease of Use:Spark的API非常友好,许多用户花费很短的时间在上手Spark上。
Unified Engine:Spark的统一计算引擎可以处理多个任务,包括批量处理、流处理等。
Real-time stream processing:Spark有流计算框架Spark Streaming,可以进行流处理。
安装Spark安装Java环境下载Spark启动SparkSpark的实践在下面的实践中,我们将从实际的案例开始使用Spark构建项目。
案例描述我们将使用Spark来分析一份数据,该数据是储格拉斯选举数据,包括每个区域的投票情况和每个候选人得票情况。
步骤1:数据探索我们先下载数据并使用Spark来分析。
下载数据分析数据在Spark中,数据可以从多种来源读取,例如HDFS、S3、HTTP等。
对于我们的数据,我们可以使用以下代码从文件中读取。
在将数据读取到Spark中之后,我们可以使用一些API来处理数据。
下面是一些示例代码,用于清理数据并返回有关储格拉斯选举的一些统计信息。
步骤2:数据处理在数据探索之后,我们需要进一步处理数据。
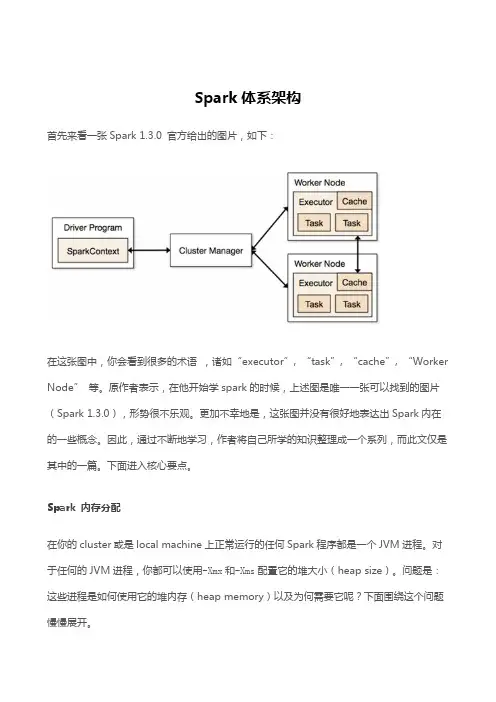
Spark体系架构首先来看一张Spark 1.3.0 官方给出的图片,如下:在这张图中,你会看到很多的术语,诸如“executor”, “task”, “cache”, “Worker Node”等。
原作者表示,在他开始学spark的时候,上述图是唯一一张可以找到的图片(Spark 1.3.0),形势很不乐观。
更加不幸地是,这张图并没有很好地表达出Spark内在的一些概念。
因此,通过不断地学习,作者将自己所学的知识整理成一个系列,而此文仅是其中的一篇。
下面进入核心要点。
Spark 内存分配在你的cluster或是local machine上正常运行的任何Spark程序都是一个JVM进程。
对于任何的JVM进程,你都可以使用-Xmx和-Xms配置它的堆大小(heap size)。
问题是:这些进程是如何使用它的堆内存(heap memory)以及为何需要它呢?下面围绕这个问题慢慢展开。
首先来看看下面这张Spark JVM堆内存分配图:Heap Size默认情况下,Spark启动时会初始化512M的JVM 堆内存。
处于安全角度以及避免OOM 错误,Spark只允许使用90%的的堆内存,该参数可以通过Spark的spark.storage.safetyFraction参数进行控制。
OK,你可能听说Spark是基于内存的工具,它允许你将数据存在内存中。
如果你读过作者的 Spark Misconceptions 这篇文章,那么你应该知道Spark其实不是真正的基于内存(in-memory)的工具。
它仅仅是在LRU cache (/wiki/Cache_algorithms) 过程中使用内存。
所以一部分的内存用在数据缓存上,这部分通常占安全堆内存(90%)的60%,该参数也可以通过配置spark.storage.memoryFraction进行控制。
因此,如果你想知道在Spark中可以缓存多少数据,你可以通过对所有executor的堆大小求和,然后乘以safetyFraction和storage.memoryFraction即可,默认情况下是0.9 * 0.6 = 0.54,即总的堆内存的54%可供Spark使用。

基于Spark的大规模数据分析与挖掘实践随着互联网的发展,大数据的挖掘和分析变得越来越重要。
而Spark作为一种开源的大数据处理框架,其灵活性和高性能使其在大规模数据分析与挖掘中得到广泛的应用。
本文将介绍如何使用Spark进行大规模数据分析与挖掘的实践。
首先,我们需要了解Spark的基本概念和特点。
Spark是一种基于内存的计算框架,通过将数据存储在内存中进行计算,可以大大提高数据处理的速度。
而且,Spark还具有很好的可扩展性,可以处理从几十兆字节到几百个同样大小的数据集。
此外,Spark还提供了丰富的库,包括Spark SQL、Spark Streaming和MLlib等,可用于不同类型的数据分析和挖掘任务。
接下来,我们需要准备好数据。
在大规模数据分析与挖掘中,数据的质量和量级是至关重要的。
我们可以使用Spark针对不同的数据源进行数据加载,如Hadoop文件系统、关系数据库、NoSQL数据库等。
Spark可以很好地处理结构化、半结构化和非结构化数据。
一旦我们准备好数据,就可以开始进行数据分析和挖掘了。
首先,我们可以使用Spark SQL来进行数据查询和处理。
Spark SQL提供了类似于SQL的语法,可以方便地对数据进行过滤、排序和聚合等操作。
同时,Spark SQL还支持对结构化数据和半结构化数据的处理,如JSON、CSV等。
除了Spark SQL,Spark还提供了MLlib库来进行机器学习和数据挖掘。
MLlib包含了许多常用的机器学习算法和工具,如分类、聚类、回归、推荐系统等。
我们可以使用MLlib来构建一个数据挖掘模型,并对数据进行预测和分类等任务。
此外,Spark还提供了Spark Streaming库,用于处理实时数据流。
Spark Streaming可以将实时数据分成小批次进行处理,并提供了类似于Spark SQL的API来进行数据操作。
我们可以使用Spark Streaming来进行实时数据分析、实时推荐等任务。

Spark大数据处理框架解读与实践案例随着大数据应用的不断增长,高效的大数据处理框架成为了企业和研究机构的关注焦点。
Spark作为一种快速、通用的大数据处理框架,已经成为了业界的热门选择。
本文将对Spark进行深入解读,并通过一个实践案例来展示其强大的大数据处理能力。
Spark是一个基于内存计算的大数据处理框架,由于其强大的计算引擎和丰富的功能,成为了大数据处理领域的佼佼者。
与传统的MapReduce框架相比,Spark 具有以下几个显著优势:首先,Spark充分利用内存计算,大大提高了处理速度。
传统MapReduce框架需要将数据存储在磁盘上,而Spark将数据存储在内存中,从而避免了频繁的I/O 操作,极大地提高了计算效率。
其次,Spark支持多种语言,包括Java、Scala和Python等,使得开发者可以根据自己的偏好和实际应用场景选择最合适的编程语言。
同时,Spark提供了丰富的API和库,如Spark SQL、Spark Streaming和MLlib等,使得开发者可以在同一框架下完成各种不同类型的大数据处理任务。
另外,Spark还支持交互式查询和实时流处理。
通过Spark的交互式Shell,开发者可以快速地进行数据查询和分析,对于业务场景下需要即时响应的数据处理需求非常有用。
而Spark Streaming则提供了实时流处理的功能,使得开发者可以对即时数据进行流式处理和分析。
为了更好地理解Spark的强大能力,我们接下来将通过一个实践案例来演示其在大数据处理中的应用。
假设我们要对一个电子商务网站的用户行为数据进行分析,以了解用户的购买行为和喜好。
首先,我们需要从网站的服务器日志中提取所需的数据。
通过Spark 的强大文件读取功能,我们可以快速地读取和处理大量的日志文件。
接下来,我们可以使用Spark的数据处理和分析功能对提取到的日志数据进行清洗和转换。
比如,我们可以筛选出某一时间段内的用户购买记录,并进行聚合分析,以确定最受欢迎的商品和购买次数最多的用户。

Spark大数据技术简介与应用场景分析Spark是一种开源的大数据处理框架,被广泛应用于各种大数据处理场景中。
它的出现弥补了Hadoop MapReduce模型的不足,并且在性能方面有了极大的提升。
本文将对Spark大数据技术进行简介,并分析其在不同应用场景下的具体应用。
首先,让我们简要介绍一下Spark的基本概念和特点。
Spark是基于内存计算的大数据处理框架,它具有以下几个重要特点:速度快、易于使用、支持多种编程语言、可扩展性强以及丰富的库支持。
Spark的速度快是其最大的优势之一。
相比于Hadoop MapReduce模型,Spark将数据存储在内存中进行处理,大大减少了磁盘读写操作,从而提升了处理速度。
同时,Spark还使用了弹性分布式数据集(Resilient Distributed Datasets,简称RDD)的概念,使得数据可以在内存中快速分布式处理。
除了速度快之外,Spark还非常易于使用。
它提供了丰富的API和内置的机器学习、图计算等库,使得开发者可以很方便地进行大数据处理和分析。
同时,Spark支持多种编程语言,如Java、Scala、Python和R,使得开发者可以选择自己最擅长的语言进行开发。
Spark的可扩展性也是其重要特点之一。
它可以轻松地在集群中添加和移除节点,实现资源的动态分配和调度。
这使得Spark可以应对不同规模和需求的大数据场景,保持良好的性能。
接下来,让我们来分析一些Spark在不同应用场景下的具体应用。
1. 批处理:Spark可以用于大规模批处理任务,如ETL(Extract, Transform, Load)任务、离线数据分析和数据仓库构建等。
通过Spark的并行计算和内存处理,可以更快地完成这些任务,并且可以直接使用SQL语言进行数据查询和分析。
2. 流式处理:Spark提供了流式处理库Spark Streaming,可以处理实时数据流。
它使用微批处理的方式对数据进行处理,支持高容错性和低延迟。

基于Spark的大数据分布式计算框架研究在当今信息时代,随着网络科技和技术的发展,数据的规模逐渐呈指数级增长。
所以,如何快速高效地处理这些海量数据成为了一个亟待解决的问题。
而大数据分布式计算框架就是解决这一问题的最佳方案之一。
其中,Spark就是大数据分布式计算中备受关注的一个框架,本篇文章就将对Spark进行研究探讨。
一、Spark框架概述Spark是一个大数据分布式计算框架,它支持速度快、易于使用的API,并具有适用于内存和磁盘上的计算模式。
Spark的核心思想是将数据集合分为若干小块(分区),将这些数据分别分布到不同的计算节点上进行处理,最后将结果合并得到最终的结果。
其内部实现采用了内存计算和读取磁盘的策略,使得Spark具有了较高的运算速度。
另外,Spark的API接口非常丰富,同时也兼容Java、Scala、Python等各种编程语言,更为方便应用于不同的业务场景。
二、Spark的核心组件Spark主要包含了以下四个核心组件:1. Spark CoreSpark Core是Spark的核心组件,它提供RDD(Resilient Distributed Datasets,具有弹性的分布式数据集)的API接口,实现了快速分布式计算和物化计算功能。
Spark Core的RDD可以缓存到内存中,因此读取速度远高于Hadoop中的MapReduce。
2. Spark SQLSpark SQL是一种基于SQL的查询引擎,针对结构化数据进行SQL查询和化简,并支持使用SQL语句连接多个数据源。
除了基于SQL的查询外,Spark SQL还提供了许多有用的操作,如withColumnRenamed、groupBy和agg等函数。
3. Spark StreamingSpark Streaming是一种分布式计算模型,支持实时处理数据流。
它采用微小批处理(Micro-batch Processing)技术,将数据分为小批次处理,从而保证了高吞吐量和可扩展性。

Spark大数据技术介绍与应用案例分析随着互联网的迅速发展,大数据的产生量越来越大,并且其价值也越来越被企业所重视。
大数据技术的应用成为了企业在数据分析和决策制定过程中不可或缺的一部分。
在众多的大数据技术中,Spark作为一种快速、通用的集群计算系统,以其高效的处理能力和丰富的功能广受欢迎。
本文将介绍Spark大数据技术及其在实际应用中的案例分析。
Spark是一种在大数据处理、数据分析和机器学习领域广泛使用的开源分布式计算框架。
相较于传统的Hadoop MapReduce系统,Spark具有更好的性能和灵活性。
Spark的核心理念是将数据存储在内存中,通过内存计算提高处理速度。
与传统的磁盘读写方式相比,内存计算可以大大减少数据的读写时间,从而提高了处理速度。
Spark支持多种编程语言,包括Java、Scala、Python和R等,这使得开发者可以根据自己的喜好和需求选择合适的编程语言进行开发。
Spark提供了丰富的API,例如Spark SQL、Spark Streaming和MLlib等,使得开发者可以在同一个框架内进行数据处理、实时流处理和机器学习等任务。
在实际应用中,Spark在各个行业都有广泛的应用。
以下是几个Spark在不同领域的应用案例:1. 金融行业:金融行业的数据量庞大且需要实时处理,Spark可以帮助金融机构进行实时风险管理、实时欺诈检测和实时交易分析等任务。
例如,美国一家大型银行使用Spark来分析顾客的交易数据,并根据这些数据构建预测模型,以便更好地了解和服务于客户。
2. 零售行业:零售行业的数据分析对于提高销售效率和预测市场需求非常重要。
Spark可以帮助零售商进行销售数据分析、用户行为分析和商品推荐等任务。
例如,一些电子商务公司使用Spark来分析用户的购买行为和偏好,并根据这些数据进行个性化推荐,从而提高销售额和用户满意度。
3. 健康医疗行业:健康医疗行业的数据涉及到患者的健康记录、医学研究和药物开发等方面。

Spark大数据处理框架与传统Hadoop技术的对比与分析大数据处理已成为当今信息时代的一个重要挑战,企业和组织需要强大而高效的框架来处理和分析大规模数据集。
在大数据处理领域,Spark和传统Hadoop技术是两个备受关注的框架。
本文将对Spark大数据处理框架与传统Hadoop技术进行对比与分析,了解它们的共同点和区别,以及在不同场景下的适用性。
首先,让我们先了解一下Spark和Hadoop的基本概念。
Spark是一个开源的通用集群计算系统,能够高效地处理大规模数据集并提供实时的数据分析。
它使用内存计算技术,可以将中间结果存储在内存中,从而大大缩短了计算时间。
相比之下,Hadoop是一个基于分布式存储和计算的开源框架,它由HDFS(分布式文件系统)和MapReduce计算模型组成,适合处理批量数据。
在功能上,Spark和Hadoop都提供了分布式计算和数据处理的能力。
然而,它们的实现方式和原理有所不同。
Hadoop使用了磁盘读写作为主要的数据存储和传输方式,而Spark则基于内存进行数据处理,在处理速度上具有明显优势。
因此,当需要进行实时计算和迭代算法时,Spark可以比Hadoop更快地完成任务。
此外,Spark还提供了更为丰富的API和开发工具,使得数据分析和处理更加灵活和便捷。
Spark的核心抽象是弹性分布式数据集(RDD),它允许用户在内存中存储和操作任意类型的数据。
而Hadoop的MapReduce编程模型则需要在每个数据处理阶段都将数据持久化到磁盘上,这样就增加了磁盘IO的开销。
因此,对于复杂的数据处理任务和机器学习应用,Spark更适用于快速迭代和交互式分析。
此外,Spark还提供了Spark Streaming和Spark SQL等组件,进一步扩展了其在实时计算和数据处理方面的能力。
Spark Streaming可以对实时数据流进行处理和分析,而Spark SQL则提供了一种类SQL的查询语言来方便用户对数据进行查询和分析。

Spark是加州大学伯克利分校的AMP实验室开源的类似MapReduce的通用并行计算框架,拥有MapReduce所具备的分布式计算的优点。
但不同于MapReduce 的是,Spark更多地采用内存计算,减少了磁盘读写,比MapReduce性能更高。
同时,它提供了更加丰富的函数库,能更好地适用于数据挖掘与机器学习等分析算法。
Spark在Hadoop生态圈中主要是替代MapReduce进行分布式计算,如下图所示。
同时,组件SparkSQL可以替换Hive对数据仓库的处理,组件Spark Streaming可以替换Storm对流式计算的处理,组件Spark ML可以替换Mahout数据挖掘算法库。
Spark在Hadoop生态圈中的位置01Spark的运行原理如今,我们已经不再需要去学习烦琐的MapReduce设计开发了,而是直接上手学习Spark的开发。
这一方面是因为Spark的运行效率比MapReduce高,另一方面是因为Spark有丰富的函数库,开发效率也比MapReduce高。
首先,从运行效率来看,Spark的运行速度是Hadoop的数百倍。
为什么会有如此大的差异呢?关键在于它们的运行原理,Hadoop总要读取磁盘,而Spark更多地是在进行内存计算,如下图所示。
Hadoop的运行总是在读写磁盘前面谈到,MapReduce的主要运算过程,实际上就是循环往复地执行Map与Reduce的过程。
但是,在执行每一个Map或Reduce过程时,都要先读取磁盘中的数据,然后执行运算,最后将执行的结果数据写入磁盘。
因此,MapReduce的执行过程,实际上就是读数据、执行Map、写数据、再读数据、执行Reduce、再写数据的往复过程。
这样的设计虽然可以在海量数据中减少对内存的占用,但频繁地读写磁盘将耗费大量时间,影响运行效率。
相反,Spark的执行过程只有第一次需要从磁盘中读数据,然后就可以执行一系列操作。

分布式计算框架SparkApache Spark是⼀个开源分布式运算框架,最初是由加州⼤学柏克莱分校AMPLab所开发。
Hadoop MapReduce的每⼀步完成必须将数据序列化写到分布式⽂件系统导致效率⼤幅降低。
Spark尽可能地在内存上存储中间结果,极⼤地提⾼了计算速度。
MapReduce是⼀路计算的优秀解决⽅案,但对于多路计算的问题必须将所有作业都转换为MapReduce模式并串⾏执⾏。
Spark扩展了MapReduce模型,允许开发者使⽤有向⽆环图(DAG)开发复杂的多步数据管道。
并且⽀持跨有向⽆环图的内存数据共享,以便不同的作业可以共同处理同⼀个数据Spark不是Hadoop的替代⽅案⽽是其计算框架Hadoop MapReduce的替代⽅案。
Hadoop更多地作为集群管理系统为Spark提供底层⽀持。
Spark可以使⽤本地Spark, Hadoop YARN或Apache Mesos作为集群管理系统。
Spark⽀持HDFS,Cassandra, OpenStack Swift作为分布式存储解决⽅案。
Spark采⽤Scala语⾔开发运⾏于JVM上,并提供了Scala,Python, Java和R语⾔API,可以使⽤其中的Scala和Python进⾏交互式操作。
本⽂测试环境为Spark 2.1.0, Python API.初识Spark弹性分布式数据集(Resilient Distributed Dataset, RDD)是Saprk的基本数据结构,代表可以跨机器进⾏分割的只读对象集合。
RDD可以由Hadoop InputFormats创建(⽐如HDFS上的⽂件)或者由其它RDD转换⽽来, RDD⼀旦创建便不可改变。
RDD操作分为变换和⾏动两种:变换(Transformation): 接受⼀个RDD作为参数,返回⼀个新的RDD,原RDD不变。
包括:map,filter,flatMap,groupByKey,reduceByKey,aggregateByKey,pipe以及coalesce⾏动(Action): 接受⼀个RDD作为参数,进⾏查询并返回⼀个值。
Spark大数据处理架构设计与实践经验分享随着大数据时代的到来,对于数据处理和分析的需求日益增长。
传统的数据处理方式已经难以满足大规模数据的处理需求。
在这个背景下,Apache Spark的出现为大数据处理带来了全新的解决方案。
本文将分享Spark大数据处理架构设计和实践经验,探讨如何充分发挥Spark的优势进行高效的大数据处理。
首先,我们将介绍Spark的架构设计。
Spark采用了分布式的内存计算模型,通过将数据存储在内存中进行计算,大大提高了计算性能。
Spark的核心是弹性分布式数据集(RDD),RDD是一个容错的、可并行化的数据结构,能够在集群中进行分布式计算。
Spark的计算模型是基于RDD的转换(Transformation)和行动(Action)操作,通过一系列的转换操作构建数据处理的流程,最后触发行动操作执行计算。
其次,我们将分享Spark的实践经验。
在实际的大数据处理项目中,我们需要考虑以下几个方面。
首先是数据的预处理和清洗,包括数据的清理、转换和过滤等操作,以保证数据的准确性和一致性。
其次是合理的数据分区和调度策略,以避免数据倾斜和计算节点的负载不均衡问题。
此外,我们还需要充分利用Spark的并行计算能力,通过合理的并行化操作将计算任务分解为多个子任务并行执行,提高数据处理的效率。
最后是结果的输出和可视化,我们可以使用Spark的输出操作将处理结果保存到文件系统或者数据库中,并通过可视化工具展示结果,帮助我们更好地理解和分析数据。
此外,值得注意的是,Spark还支持多种数据处理引擎和编程语言,如Spark SQL、Spark Streaming、Spark MLlib等,可以根据具体的需求选择合适的引擎和语言进行数据处理。
在实践中,我们需要根据项目的具体要求选择合适的组件和工具来搭建Spark的架构,以满足不同数据处理场景的需求。
在实际的大数据处理项目中,我们还需要考虑数据安全和隐私保护的问题。
基于Spark的大数据处理技术研究随着互联网、物联网、人工智能等技术的发展,大数据处理技术已经成为了不可或缺的一个组成部分。
Spark作为最为常用的大数据处理框架之一,其高性能、易用性以及丰富的API等优点,已经得到了广泛的应用和认可。
本文将对基于Spark的大数据处理技术进行探究和研究,深入分析其特点和优势,探讨其在各个领域的应用情况。
一、Spark的基本原理及特点Spark是一种基于内存计算的大数据处理框架,它利用内存计算技术和RDD(弹性分布式数据集)的概念,能够实现快速高效的大数据处理。
Spark具有以下优点:1、高性能:Spark采用内存计算方式,减少了I/O,因此其性能比Hadoop MapReduce有显著提升。
2、易用性:Spark提供了多种API,包括Scala、Java和Python 等,使用者可以选择适合自己的编程语言,并且Spark还提供了丰富的内置函数以便用户使用。
3、数据处理能力:Spark可以处理不同种类的数据,例如图形数据、流数据和机器学习数据等。
4、实时计算:Spark具有较强的实时计算能力,能够快速响应不同业务的需求。
二、基于Spark的大数据处理技术的应用随着各行各业对大数据的需求日益增加,基于Spark的大数据处理技术正在得到广泛的应用。
以下是该技术在不同领域的典型应用情况:1、电商行业:电商企业需要处理大量的用户数据、商品销售数据等,因此Spark成为了电商行业中主流的大数据处理技术。
Spark可以帮助电商企业实现用户画像、商品推荐等功能。
2、金融行业:金融企业需要处理大量的交易数据、客户数据等,Spark可以帮助金融企业实现欺诈检测、风险评估等功能。
3、医疗行业:医疗行业需要处理大量的医疗数据,例如各种疾病的数据、医疗影像数据等,Spark可以帮助医疗企业实现疾病预测、诊断辅助等功能。
4、政府行业:政府需要处理大量的人口数据、城市数据等,Spark可以帮助政府实现城市规划、公共安全监控等功能。
【总结】Spark任务的core,executor,memory资源配置⽅法执⾏Spark任务,资源分配是很重要的⼀⽅⾯。
如果配置不准确,Spark任务将耗费整个集群的机缘导致其他应⽤程序得不到资源。
怎么去配置Spark任务的executors,cores,memory,有如下⼏个因素需要考虑:数据量任务完成时间点静态或者动态的资源分配上下游应⽤Spark应⽤当中术语的基本定义:Partitions : 分区是⼤型分布式数据集的⼀⼩部分。
Spark使⽤分区来管理数据,这些分区有助于并⾏化数据处理,并且使executor之间的数据交换最⼩化Task:任务是⼀个⼯作单元,可以在分布式数据集的分区上运⾏,并在单个Excutor上执⾏。
并⾏执⾏的单位是任务级别。
单个Stage 中的Tasks可以并⾏执⾏Executor:在⼀个worker节点上为应⽤程序创建的JVM,Executor将巡⾏task的数据保存在内存或者磁盘中。
每个应⽤都有⾃⼰的⼀些executors,单个节点可以运⾏多个Executor,并且⼀个应⽤可以跨多节点。
Executor始终伴随Spark应⽤执⾏过程,并且以多线程⽅式运⾏任务。
spark应⽤的executor个数可以通过SparkConf或者命令⾏ –num-executor进⾏配置Cores:CPU最基本的计算单元,⼀个CPU可以有⼀个或者多个core执⾏task任务,更多的core带来更⾼的计算效率,Spark中,cores决定了⼀个executor中并⾏task的个数Cluster Manager:cluster manager负责从集群中请求资源cluster模式执⾏的Spark任务包含了如下步骤:1. driver端,SparkContext连接cluster manager(Standalone/Mesos/Yarn)2. Cluster Manager在其他应⽤之间定位资源,只要executor执⾏并且能够相互通信,可以使⽤任何Cluster Manager3. Spark获取集群中节点的Executor,每个应⽤都能够有⾃⼰的executor处理进程4. 发送应⽤程序代码到executor中5. SparkContext将Tasks发送到executors以上步骤可以清晰看到executors个数和内存设置在spark中的重要作⽤。
大数据技术与应用考核试题一、选择题(每小题2分,共20分)1、大数据的定义是()A. 数据量大B. 数据质量高C. 数据结构复杂D. 数据价值高答案:A2、大数据的特点是()A. 存储量大B. 运算速度快C. 结构复杂D. 可视化好答案:A3、Hadoop是一个()A. 数据库B. 操作系统C. 编程语言D. 分布式计算框架答案:D4、MapReduce是一个()A. 数据库B. 操作系统C. 编程语言D. 分布式计算框架答案:D5、HBase是一个()A. 关系型数据库B. 非关系型数据库C. 搜索引擎D. 分布式文件系统答案:B二、填空题(每小题2分,共20分)1、Hadoop的核心是________ 和________ 。
答案:HDFS、MapReduce2、MapReduce的两个阶段是________ 和________ 。
答案:Map、Reduce3、HBase是一个________ 的分布式数据库。
答案:非关系型4、Hive是一个________ 的分布式数据仓库。
答案:基于Hadoop5、Spark是一个________ 的分布式内存计算框架。
答案:内存密集型三、问答题(共60分)1、请介绍大数据的定义及特点。
答:大数据是指海量、高速生成和处理的数据,它的特点有存储量大、运算速度快、结构复杂、可视化好。
大数据不仅仅是数量上的海量,还包含了数据的多样性、复杂性和动态性。
大数据可以带来新的商业价值,可以帮助企业做出正确的决策。
2、请介绍Hadoop的特点以及应用场景。
答:Hadoop是一个开源的分布式计算框架,它的特点有:1、可扩展性强,可以通过增加节点来扩展集群的规模;2、容错性强,可以在出现故障时保证数据的安全性和可靠性;3、低成本,使用Hadoop可以节省成本。
Hadoop的应用场景包括:1、大数据存储和分析;2、机器学习和人工智能;3、实时流处理和事件处理;4、图形计算和图形处理。
1. 以下哪种技术不是大数据存储技术?A. HadoopB. MongoDBC. MySQLD. Cassandra2. Hadoop的核心组件包括哪些?A. HDFS和MapReduceB. HDFS和YARNC. MapReduce和YARND. HDFS、MapReduce和YARN3. HDFS的默认块大小是多少?A. 64MBB. 128MBC. 256MBD. 128KB4. 在Hadoop中,MapReduce的主要作用是什么?A. 数据存储B. 数据处理C. 数据查询D. 数据传输5. 以下哪个是NoSQL数据库?A. OracleB. MySQLC. MongoDBD. PostgreSQL6. 在Spark中,RDD代表什么?A. Resilient Distributed DatasetB. Relational Data DictionaryC. Remote Data DescriptorD. Real-time Data Distribution7. Spark与Hadoop的主要区别在于什么?A. Spark更快B. Hadoop更快C. Spark更适合批处理D. Hadoop更适合实时处理8. 以下哪个是Spark的核心组件?A. HDFSB. YARNC. Spark CoreD. MapReduce9. 在Spark中,以下哪个操作不是转换操作?A. mapB. filterC. reduceD. flatMap10. 以下哪个是Spark的内存计算框架?A. HDFSB. YARNC. Spark CoreD. MapReduce11. 在Spark中,以下哪个操作是行动操作?A. mapB. filterC. reduceD. flatMap12. 以下哪个是Spark的流处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX13. 在Spark中,以下哪个库用于机器学习?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX14. 以下哪个是Spark的图处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX15. 在Spark中,以下哪个库用于SQL查询?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX16. 以下哪个是Spark的内存计算框架?A. HDFSB. YARNC. Spark CoreD. MapReduce17. 在Spark中,以下哪个操作是行动操作?A. mapB. filterC. reduceD. flatMap18. 以下哪个是Spark的流处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX19. 在Spark中,以下哪个库用于机器学习?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX20. 以下哪个是Spark的图处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX21. 在Spark中,以下哪个库用于SQL查询?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX22. 以下哪个是Spark的内存计算框架?A. HDFSB. YARNC. Spark CoreD. MapReduce23. 在Spark中,以下哪个操作是行动操作?A. mapB. filterC. reduceD. flatMap24. 以下哪个是Spark的流处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX25. 在Spark中,以下哪个库用于机器学习?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX26. 以下哪个是Spark的图处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX27. 在Spark中,以下哪个库用于SQL查询?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX28. 以下哪个是Spark的内存计算框架?A. HDFSB. YARNC. Spark CoreD. MapReduce29. 在Spark中,以下哪个操作是行动操作?A. mapB. filterC. reduceD. flatMap30. 以下哪个是Spark的流处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX31. 在Spark中,以下哪个库用于机器学习?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX32. 以下哪个是Spark的图处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX33. 在Spark中,以下哪个库用于SQL查询?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX34. 以下哪个是Spark的内存计算框架?A. HDFSB. YARNC. Spark CoreD. MapReduce35. 在Spark中,以下哪个操作是行动操作?A. mapB. filterC. reduceD. flatMap36. 以下哪个是Spark的流处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX37. 在Spark中,以下哪个库用于机器学习?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX38. 以下哪个是Spark的图处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX39. 在Spark中,以下哪个库用于SQL查询?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX40. 以下哪个是Spark的内存计算框架?A. HDFSB. YARNC. Spark CoreD. MapReduce41. 在Spark中,以下哪个操作是行动操作?A. mapB. filterC. reduceD. flatMap42. 以下哪个是Spark的流处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX43. 在Spark中,以下哪个库用于机器学习?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX44. 以下哪个是Spark的图处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX45. 在Spark中,以下哪个库用于SQL查询?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX46. 以下哪个是Spark的内存计算框架?A. HDFSB. YARNC. Spark CoreD. MapReduce47. 在Spark中,以下哪个操作是行动操作?A. mapB. filterC. reduceD. flatMap48. 以下哪个是Spark的流处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX49. 在Spark中,以下哪个库用于机器学习?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX50. 以下哪个是Spark的图处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX51. 在Spark中,以下哪个库用于SQL查询?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX52. 以下哪个是Spark的内存计算框架?A. HDFSB. YARNC. Spark CoreD. MapReduce53. 在Spark中,以下哪个操作是行动操作?A. mapB. filterC. reduceD. flatMap54. 以下哪个是Spark的流处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX55. 在Spark中,以下哪个库用于机器学习?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX56. 以下哪个是Spark的图处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX57. 在Spark中,以下哪个库用于SQL查询?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX58. 以下哪个是Spark的内存计算框架?A. HDFSB. YARNC. Spark CoreD. MapReduce59. 在Spark中,以下哪个操作是行动操作?A. mapB. filterC. reduceD. flatMap60. 以下哪个是Spark的流处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX61. 在Spark中,以下哪个库用于机器学习?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX62. 以下哪个是Spark的图处理框架?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX63. 在Spark中,以下哪个库用于SQL查询?A. Spark SQLB. Spark StreamingC. MLlibD. GraphX答案部分:1. C2. D3. B5. C6. A7. A8. C9. C10. C11. C12. B13. C14. D15. A16. C17. C18. B19. C20. D21. A22. C23. C24. B25. C26. D27. A28. C29. C30. B31. C32. D33. A34. C35. C36. B37. C38. D39. A40. C41. C42. B43. C44. D45. A46. C47. C48. B49. C50. D51. A52. C53. C55. C56. D57. A58. C59. C60. B61. C62. D63. A。