R语言实验二
- 格式:doc
- 大小:226.50 KB
- 文档页数:5
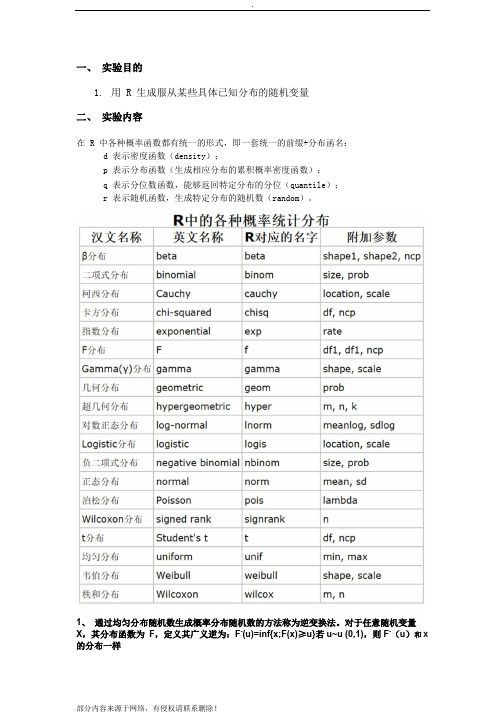
一、实验目的1.用 R 生成服从某些具体已知分布的随机变量二、实验内容在 R 中各种概率函数都有统一的形式,即一套统一的前缀+分布函名:d 表示密度函数(density);p 表示分布函数(生成相应分布的累积概率密度函数);q 表示分位数函数,能够返回特定分布的分位(quantile);r 表示随机函数,生成特定分布的随机数(random)。
1、通过均匀分布随机数生成概率分布随机数的方法称为逆变换法。
对于任意随机变量X,其分布函数为F,定义其广义逆为:F-(u)=inf{x;F(x)≥u}若u~u (0,1),则F-(u)和X 的分布一样Example 1 如果X~Exp(1)(服从参数为 1 的指数分布),F(x)=1-e-x。
若u=1-e-x并且u~u(0,1),则X=-logU~Exp(1)则可以解出x=-log(1-u)通过随机数生成产生的分布与本身的指数分布结果相一致R 代码如下:nsim = 10^4U = runif(nsim)X = -log(U)Y = rexp(nsim)X11(h=3.5)Xpar(mfrow=c(1,2),mar=c(2,2,2,2))hist(X,freq=F,main="Exp from Uniform",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)hist(Y,freq=F,main="Exp from R",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)2、某些随机变量可由指数分布生成。

R语言实战(第2版)——第2章-2.2数据结构#R语言实战#第2章创建数据集#2.2 数据结构#P21 标量:只含一个元素的向量,用于保存常量f <- -3g <- "US"h <- TRUE#P21 向量:用于存储数值型、字符型或逻辑型数据的一维数组。
单个向量中的数据必须拥有相同的模式a <- c(1,2,5,3,6,-2,4) #数值型向量b <- c("one","two","three") #字符型向量c <-c(TRUE,TRUE,TRUE,FALSE,TRUE,FALSE) #逻辑型向量a <- c("k", "j", "h", "a", "c", "m")a[3] #方括号返回给定元素所处位置的数值a[c(1,3,5)]a[2:6] #冒号用于生成一个数值序列a <- c(2:6)a <- c(2,3,4,5,6) #二者等价#矩阵:二维数组,每个元素有相同的模式(数值型、字符型或逻辑型)#matrix创建矩阵,ncol和nrow指定行和列的维度,dimnames行名、列名,byrow=T按行填充,byrow=F按列填充,默认按列填充#mymatrix <- matrix(vector,nrow=numble_of_rows, ncol = number_of_columns,byrow = logical_value,# dimnames = list(char_vector_rownames,char_vector_colnames))#P22 2-1创建矩阵y <- matrix(1:20,nrow = 5,ncol = 4)cells <- c(1,26,24,68)rnames <- c("R1","R2")cnames <- c("C1","C2")mymatrix <- matrix(cells,nrow = 2,ncol = 2,byrow = TRUE,dimnames = list(rnames,cnames)) #按行填充mymatrix <- matrix(cells,nrow = 2,ncol = 2,byrow = FALSE,dimnames = list(rnames,cnames)) #按列填充#使用下标和方括号选择矩阵的行列和元素x <- matrix(1:10,nrow = 2)x[2,]x[,2]x[1,4]x[1,c(4,5)]#数组:当维度超过2时,可以用数组代替矩阵#P23 2-3创建数组#myarray <- array(vector,dimensions,dimnames)#vector包含了数组中的数据,dimensions是数值型向量,给出了各维度下标的最大值,dimnames是可选的,各维度名称标签的列表dim1 <- c("A1","A2")dim2 <- c("B1","B2","B3")dim3 <- c("C1","C2","C3","C4")z <- array(1:24,c(2,3,4),dimnames = list(dim1,dim2,dim3))#使用方括号和下标选择数组中的元素z[1,2,3]#数据框:多种数据模式,包含数值型、字符型、逻辑型#mydata <- data.frame(col1,col2,col3,...)#P24 2-4创建数据框patientID <- c(1,2,3,4)age <- c(25,34,28,52)diabates <- c("type1","type2","type1","type1")status <- c("poor","improved","excellent","poor")patientdata <- data.frame(patientID,age,diabates,status)#P24 2-5选取数据框中的元素,下标和列名等价,美元符$列名patientdata[1:2]patientdata[c("diabates","status")]patientdata$agetable(patientdata$diabates,patientdat a$status) #生成列联表#在每个变量名前都输一边数据框名$太麻烦了,走一些捷径:attach()/detach()/with()summary(mtcars$mpg)plot(mtcars$mpg,mtcars$disp)plot(mtcars$mpg,mtcars$wt)#也可写成attach(mtcars) #将数据框添加到R的搜索路径中summary(mpg)plot(mpg,disp)plot(mpg,wt)detach(mtcars) #将数据框从搜索路径中移除#也可写成with(mtcars,{print(summary(mpg))plot(mpg,disp)plot(mpg,wt)})#with赋值仅在括号内生效,若需创建在括号外生效的变量,是用特殊赋值符号<<- with(mtcars,{nokeepstats <- summary(mpg)keepstats<<-summary(mpg)})nokeepstatskeepstats#实例标识符patientID <- c(1,2,3,4)age <- c(25,34,28,52)diabates <- c("type1","type2","type1","type1")status <- c("poor","improved","excellent","poor")patientdata <- data.frame(patientID,age,diabates,status,rs = patientID) #指定patientID作为打印输出和图形中实例名称所用变量#因子:名义和有序变量在R中称为因子diabates <- c("type1","type2","type1","type1")diabates <- factor(diabates)status <- c("poor","improved","excellent","poor")status <- factor(status,ordered = T) #1=excellent2=improved 3=poorstatus <- factor(status,order=T,levels = c("poor","improved","excellent")) #指定levels覆盖默认顺序sex <- factor(sex,levels = c(1,2),labels = c("male","female")) #数值型变量编码成因子,所有非1非2均被当做缺失值#P28 2-6因子的使用patientID <- c(1,2,3,4)age <- c(25,34,28,52)diabates <- c("type1","type2","type1","type1")status <- c("poor","improved","excellent","poor")diabates <- factor(diabates)status <- factor(status,ordered = T)patientdata <- data.frame(patientID,age,diabates,status)str(patientdata) #显示数据框的信息summary(patientdata) #区别对待不同类型变量#列表:R中最复杂的数据类型,是一些对象的有序集合。

精心整理实验8假设检验(二)一、实验目的:1.掌握若干重要的非参数检验方法( 2检验——列联表独立性检验,Mcnemar检验——对一个样本两种研究方法是否有差异的检验,符号检验,Wilcoxon 符号秩检验,Wilcoxon秩和检验);2.掌握另外两个相关检验:Spearman秩相关检验,Kendall秩相关检验。
二、实验内容:练习:要求:①完成练习并粘贴运行截图到文档相应位置(截图方法见下),并将所有自己输入文字的字体颜色设为红色(包括后面的思考及小结),②回答思考题,③简要书写实验小结。
④修改本文档名为“本人完整学号姓名1”,其中1表示第1次实验,以后更改为2,3,...。
如文件名为“09张立1”,表示学号为09的张立同学的第1次实验,注意文件名中没有空格及任何其它字符。
最后连同数据文件、源程序文件等(如果有的话,本次实验没有),一起压缩打包发给课代表,压缩包的文件名同上。
截图方法:法1:调整需要截图的窗口至合适的大小,并使该窗口为当前激活窗口(即该窗口在屏幕最前方),按住键盘Alt键(空格键两侧各有一个)不放,再按键盘右上角的截图键(通常印有“印屏幕”或“PrScrn”等字符),即完成截图。
再粘贴到word文档的相应位置即可。
法2:利用QQ输入法的截屏工具。
点击QQ输入法工具条最右边的“扳手”图标,选择其中的“截屏”工具。
)1.自行完成教材第五章的例题。
2.(习题5.11)为研究分娩过程中使用胎儿电子监测仪对剖腹产率有无影响,对5824例分娩的经产妇进行回顾性调查,结果如下表所示,试进行分析。
5824例经产妇回顾性调查结果HHP=9.552e-10<0.05,拒绝原假设,分娩过程中使用胎儿电子监测仪对剖腹产率有影响3.(习题5.12)在高中一年级男生中抽取300名考察其两个属性:B是1500米长跑,C是每天平均锻炼时间,得到4×3列联表,如下表所示。
试对 =0.05,检验B 与C是否独立。


R语言两层2^k析因试验设计(因子设计)分析工厂产量数据和Lenth方法检验显著性可视化数据分享原文链接:/?p=25921假设调查人员有兴趣检查减肥干预方法的三个组成部分。
这三个组成部分是:•记录食物日记(是/否)•增加活动(是/否)•家访(是/否)调查员计划调查所有,实验条件的组合。
实验条件为•要执行因子设计,您需要为多个因子(变量)中的每一个选择固定数量的水平,然后以所有可能的组合运行实验。
•这些因素可以是定量的或定性的。
•定量变量的两个水平可以是两个不同的温度或两个不同的浓度。
•定性因素可能是两种类型的催化剂或某些实体的存在和不存在。
符号:- 因子数 (3) - 每个因子的水平数 (2) - 设计中有多少实验条件 ()因子实验可以涉及具有不同水平数量的因子。
测试:考虑一个设计。
•有多少因子?•每个因子有多少个水平?•多少实验条件?答案:(a) 有 2+2+1 = 5 个因数。
(b) 两个因素有4个水平,2个因素有3个水平,1个因素有2个水平。
(c) 有 288 个实验条件。
向下滑动查看答案▼方差分析和因子设计之间的区别在 ANOVA 中,目标是比较各个实验条件。
让我们考虑一下上面的食物日记研究。
我们可以通过比较食物日记设置为 NO(条件 1-4)的所有条件的平均值和食物日记设置为YES(条件5-8)的所有条件的平均值来估计食物日记的效果。
这也被称为食物日记的主效应,形容词主要是提醒这个平均值超过了其他因素的水平。
食物日记的主效应是:体育锻炼的主效应是:家访的主效应是:使用了所有实验对象,但重新排列以进行每次比较。
受试者被回收以测量不同的效应。
这是析因实验更有效的原因之一。
执行因子设计要执行因子设计:•为每个因子选择固定数量的水平。
•以所有可能的组合运行实验。
我们将讨论每个因子只有两个水平的设计。
因素可以是定量的或定性的。
两个水平的定量变量可以是两个不同的温度或浓度。
定量变量的两个级别可以是两种不同类型的催化剂或某些实体的存在/不存在。

R语言实验指导书
二
R语言实验指导书(二)
10月27日
实验三创立和使用R语言数据集
一、实验目的:
1.了解R语言中的数据结构。
2.熟练掌握她们的创立方法,和函数中一些参数的使用。
3.对创立的数据结构进行,排序、查找、删除等简单的操作。
二、实验内容:
1.向量的创立及因子的创立和查看
有一份来自澳大利亚所有州和行政区的20个税务会计师的信息样本1 以及她们各自所在地的州名。
州名为:tas, sa, qld, nsw, nsw, nt, wa, wa, qld, vic, nsw, vic, qld, qld, sa, tas, sa, nt, wa, vic。
1)将这些州名以字符串的形式保存在state当中。
2)创立一个为这个向量创立一个因子statef。
3)使用levels函数查看因子的水平。
2.矩阵与数组。
i.创立一个4*5的数组如图,创立一个索引矩阵如图,用
这个索引矩阵访问数组,观察结果。
3.将之前的state,数组,矩阵合在一起创立一个长度为3的
列表。
4.创立一个数据框如图。
R语言实验报告范文实验报告:基于R语言的数据分析摘要:本实验基于R语言进行数据分析,主要从数据类型、数据预处理、数据可视化以及数据分析四个方面进行了详细的探索和实践。
实验结果表明,R语言作为一种强大的数据分析工具,在数据处理和可视化方面具有较高的效率和灵活性。
一、引言数据分析在现代科学研究和商业决策中扮演着重要角色。
随着大数据时代的到来,数据分析的方法和工具也得到了极大发展。
R语言作为一种开源的数据分析工具,被广泛应用于数据科学领域。
本实验旨在通过使用R语言进行数据分析,展示R语言在数据处理和可视化方面的应用能力。
二、材料与方法1.数据集:本实验使用了一个包含学生身高、体重、年龄和成绩的数据集。
2.R语言版本:R语言版本为3.6.1三、结果与讨论1.数据类型处理在数据分析中,需要对数据进行适当的处理和转换。
R语言提供了丰富的数据类型和操作函数。
在本实验中,我们使用了R语言中的函数将数据从字符型转换为数值型,并进行了缺失值处理。
同时,我们还进行了数据类型的检查和转换。
2.数据预处理数据预处理是数据分析中的重要一步。
在本实验中,我们使用R语言中的函数处理了异常值、重复值和离群值。
通过计算均值、中位数和四分位数,我们对数据进行了描述性统计,并进行了异常值和离群值的检测和处理。
3.数据可视化数据可视化是数据分析的重要手段之一、R语言提供了丰富的绘图函数和包,可以用于生成各种类型的图表。
在本实验中,我们使用了ggplot2包绘制了散点图、直方图和箱线图等图表。
这些图表直观地展示了数据的分布情况和特点。
4.数据分析数据分析是数据分析的核心环节。
在本实验中,我们使用R语言中的函数进行了相关性分析和回归分析。
通过计算相关系数和回归系数,我们探索了数据之间的关系,并对学生成绩进行了预测。
四、结论本实验通过使用R语言进行数据分析,展示了R语言在数据处理和可视化方面的强大能力。
通过将数据从字符型转换为数值型、处理异常值和离群值,我们获取了可靠的数据集。
r语言实验报告R语言实验报告引言R语言是一种广泛应用于数据分析和统计建模的开源编程语言,具有丰富的包和函数库,适用于各种数据处理和可视化任务。
本实验旨在探讨R语言在数据处理和可视化方面的应用,通过实际案例展示其强大的功能和灵活性。
数据导入与处理我们需要导入数据集,并进行初步的处理。
在R语言中,可以使用read.csv()函数导入csv格式的数据文件,然后通过head()函数查看数据的前几行,以了解数据结构和内容。
接下来,可以使用subset()函数筛选出需要的数据列,并使用na.omit()函数删除缺失值,确保数据的完整性和准确性。
数据可视化数据可视化是数据分析的重要环节,可以帮助我们更直观地理解数据的分布和关系。
在R语言中,可以使用ggplot2包来绘制各种类型的图表,如散点图、折线图和直方图等。
通过设置不同的参数和颜色,可以定制化图表的样式,使其更具有美感和可读性。
统计分析除了数据可视化,R语言还提供了丰富的统计分析函数,可以帮助我们进行各种统计推断和建模分析。
例如,可以使用lm()函数进行线性回归分析,通过summary()函数查看回归模型的拟合效果和显著性检验结果。
此外,还可以使用t.test()函数进行假设检验,判断样本均值之间是否存在显著差异。
结果解释与总结我们需要对分析结果进行解释和总结。
在解释结果时,应该清晰地说明分析方法和推断过程,避免歧义和误导。
在总结部分,可以简要概括分析的主要发现和结论,指出数据分析对问题的解决和决策的重要性和价值。
结论通过本实验,我们深入探讨了R语言在数据处理和可视化方面的应用,展示了其强大的功能和灵活性。
R语言不仅可以帮助我们高效地处理和分析数据,还可以帮助我们更好地理解数据的特征和规律。
希望本实验可以帮助读者更好地掌握R语言的应用技巧,提升数据分析和统计建模的能力。
一、数据可视化1.对于iris数据,用每类花(iris$Speciees)的样本数作为高度,制作条形图。
2.用每类花的Sepal.Length、Sepal.Width、Petal.Length、Petal.Width的平均值分别制作条形图,四图同显。
3.分别制作Sepal.Length、Sepal.Width、Petal.Length、Petal.Width的直方图(用密度值做代表,设置prob=T),添加拟合的密度曲线,四图同显。
二、中国地图:(Note:首先从网上下载GIS数据,解压到GIS_data目录。
/wp-content/uploads/2009/07/chinaprovinceborderdata _tar_gz.zip)setwd('F:/GIS_data') ### 设置工作目录install.packages('maptools');library(maptools)china<- readShapePoly('bou2_4p.shp') ### 获得各省的边界信息plot(china)>> names(map_data)[1] "AREA" "PERIMETER" "BOU2_4M_" "BOU2_4M_ID" "ADCODE93"[6] "ADCODE99" "NAME"可以看出map_data中有7列,对应的字段名如上面显示。
>> map_data$AREA #925个区域单元的面积>> map_data$PERIMETER #925个区域单元的周长>> map_data$BOU2_4M_ #没有重复的数字,2~926,可作为区域单元ID>> map_data$BOU2_4M_ID #有重复数字,特定情况下可作为区域单元ID>> map_data$ADCODE93 #93版ADCODE地理编码>> map_data$ADCODE93 #99版ADCODE地理编码>> map_data$NAME #各区域单元所隶属的省级行政单元的名称>> unique(map_data$NAME) #查看各区域的名称是什么文本[1] 黑龙江省内蒙古自治区新疆维吾尔自治区吉林省[5] 辽宁省甘肃省河北省北京市[9] 山西省天津市陕西省宁夏回族自治区[13] 青海省山东省西藏自治区河南省[17] 江苏省安徽省四川省湖北省[21] 重庆市上海市浙江省湖南省[25] 江西省云南省贵州省福建省[29] 广西壮族自治区台湾省广东省香港特别行政区[33] 海南省<NA>33 Levels: 安徽省北京市福建省甘肃省广东省广西壮族自治区 ...重庆市provname=c("北京市","天津市","河北省","山西省","内蒙古自治区", "辽宁省","吉林省","黑龙江省","上海市","江苏省", "浙江省","安徽省","福建省","江西省","山东省", "河南省","湖北省","湖南省","广东省","广西壮族自治区","海南省","重庆市","四川省","贵州省", "云南省","西藏自治区","陕西省","甘肃省","青海省","宁夏回族自治区","新疆维吾尔自治区","台湾省", "香港特别行政区") ###省份向量pop=c(1633,1115,6943,3393,2405,4298,2730,3824,1858,7625,5060,6118,3581 ,4368,9367,9360,5699,6355,9449,4768,845,2816,8127,3762,4514,284,3748,26 17,552,610,2095,2296,693) ###各省人口向量根据各省人口数量给地图着色。
实验2 R基础(二)
一、实验目的:
1.掌握数字与向量的运算;
2.掌握对象及其模式与属性;
3.掌握因子变量;
4.掌握多维数组和矩阵的使用。
二、实验内容:
1.完成教材例题;
2.完成以下练习。
练习:
要求:①完成练习并粘贴运行截图到文档相应位置(截图方法见下),并将所有自己输入文字的字体颜色设为红色(包括后面的思考及小结),②回答思考题,③简要书写实验小结。
④修改本文档名为“本人完整学号姓名1”,其中1表示第1次实验,以后更改为2,3,...。
如文件名为“1305543109张立1”,表示学号为1305543109的张立同学的第1次实验,注意文件名中没有空格及任何其它字符。
最后连同数据文件、源程序文件等(如果有的话),一起压缩打包发给课代表,压缩包的文件名同上。
截图方法:
法1:调整需要截图的窗口至合适的大小,并使该窗口为当前激活窗口(即该窗口在屏幕最前方),按住键盘Alt键(空格键两侧各有一个)不放,再按键盘右上角的截图键(通常印有“印屏幕”或“Pr Scrn”等字符),即完成截图。
再粘贴到word文档的相应位置即可。
法2:利用QQ输入法的截屏工具。
点击QQ输入法工具条最右边的“扳手”图标,选择其中的“截屏”工具。
)
1.自行完成教材P58页
2.2-2.5节中的例题。
2.(习题2.1)建立一个R文件,在文件中输入变量x = (1,2,3)T,y = (4,5,6)T,
并作以下运算
(1)计算z = 2x + y + e,其中e = (1,1,1)T;
(2)计算x与y的内积;
(3)计算x与y的外积。
解:源代码:
(1)x<-c(1,2,3)
y<-c(4,5,6)
e<-c(1,1,1)
z=2*x+y+e
z1=crossprod(x,y) #z1为x与y的内积或者x%*%y
z2=tcrossprod(x,y) #z2为x与y的外积或者x%o%y
z;z1;z2
(2) x<-c(1,2,3)
y<-c(4,5,6)
e<-c(1,1,1)
z=2*x+y+e
z1= x%*%y
z2=x%o%y
z;z1;z2
运行截图:
3.(习题2.2)将1,2,…,20构成两个4×5阶的矩阵,其中矩阵A是按列输入,
矩阵B是按行输入,并作如下运算
(1)C = A + B;(相对应的数相加)
(2) D = AB T;
(3)E = (e ij )4×5,其中e ij = a ij·b ij;(相对应的数相乘)
(4)F是由A的前3行和前3列构成的矩阵;
(5)G是由矩阵B的各列构成的矩阵,但不含B的第3列。
解:源代码:
A<-matrix(1:20,c(4,5));A # A<-matrix(1:20,nrow=4,byrow=F);A/ A<-matrix(1:20,nrow=4);A # A<-matrix(1:20,ncol=5);A # A<-matrix(1:20,ncol=5,byrow=F);A
B<-matrix(1:20,nrow=4,byrow=TRUE);B
C=A+B;C
D<-A%*%t(B);D
E=A*B;E
F<-A[1:3,1:3];F
G<-B[,-3];G
运行截图:
D:第一个数175=1*1+5*2+9*3+13*4+17*5
400=1*6+5*7+9*8+13*9+17*10
类似……..
4.(习题2.3)构造一个向量x,向量是由5个1,3个2,4个3和2个4构成,注
意用到rep()函数。
解:源代码:
x<-c(rep(1,times=5),rep(2,times=3),rep(3,times=4),rep(4,times=2)); x
x<-c(rep(1,5),rep(2,3),rep(3,4),rep(4,2));x
运行截图:
思考:(以下题目请先进行笔算后,再在R中运算核对)
1.c(1,4)*c(2,3)的输出结果是什么?
[1] 2 12
2.matrix(1:2,ncol=2,nrow=2)的输出结果是什么?(重复)
[,1] [,2]
[1,] 1 1
[2,] 2 2
3.vec<- c(2,4,6,8,10); vec[2]; vec[-2]的输出结果是什么?(找到相对应下标的数,负
数表示去掉)
[1] 4
[1] 2 6 8 10
4.测量得到了5位男士的体重和身高的数据如下:
体重(kg):60, 75, 65, 68, 70
身高(cm):170, 180, 165, 172, 178
分别存储在向量weight和height中。
若想得到那些身高超过170cm的男士的体重
数据,请写出相应的R代码。
weight<-c(60, 75, 65, 68, 70)
height<-c(170, 180, 165, 172, 178)
weight[height>170]
运行截图:
5.下面这一命令的输出结果是什么?
Mat<-matrix(1:12,nrow=4,byrow=TRUE); Mat[3,];Mat[2,2:3]
[1] 7 8 9
[1] 5 6
6.apply()函数与tapply()函数有什么区别?
apply()是针对数组其一维(或若干维)进行某种运算;
tapply()是针对向量中的数据进行分组处理,而非对整体数据进行处理。
三、实验小结(必写,但字数不限)
首先需熟悉数字、向量、因子变量和多维数组和矩阵相对应的运算函数,理解和熟记相对应的函数,一道题中的源代码可能某部分有多种写法,选择简单适合的源代码,学会举一反三,最后要掌握相似函数的区别。