编 译 原 理 实 验 报 告
- 格式:doc
- 大小:105.00 KB
- 文档页数:11

学年第学期《编译原理》实验报告学院(系):计算机科学与工程学院班级:11303070A学号:***********姓名:无名氏指导教师:保密式时间:2016 年7 月目录1.实验目的 (1)2.实验内容及要求 (1)3.实验方案设计 (1)3.1 编译系统原理介绍 (1)3.1.1 编译程序介绍 (2)3.1.2 对所写编译程序的源语言的描述 (2)3.2 词法分析程序的设计 (3)3.3 语法分析程序设计 (4)3.4 语义分析和中间代码生成程序的设计 (4)4. 结果及测试分析 (4)4.1软件运行环境及限制 (4)4.2测试数据说明 (5)4.3运行结果及功能说明 (5)5.总结及心得体会 (7)1.实验目的根据Sample语言或者自定义的某种语言,设计该语言的编译前端。
包括词法分析,语法分析、语义分析及中间代码生成部分。
2.实验内容及要求(1)词法分析器输入源程序,输出对应的token表,符号表和词法错误信息。
按规则拼单词,并转换成二元形式;滤掉空白符,跳过注释、换行符及一些无用的符号;进行行列计数,用于指出出错的行列号,并复制出错部分;列表打印源程序;发现并定位词法错误;(2)语法分析器输入token串,通过语法分析,寻找其中的语法错误。
要求能实现Sample 语言或自定义语言中几种最常见的、基本的语法单位的分析:算术表达式、布尔表达式、赋值语句、if语句、for语句、while语句、do while语句等。
(3)语义分析和中间代码生成输入token串,进行语义分析,修改符号表,寻找其中的语义错误,并生成中间代码。
要求能实现Sample语言或自定义语言中几种最常见的、基本的语法单位的分析:算术表达式、布尔表达式、赋值语句、if语句、for语句、while 语句、do while语句等。
实验要求:功能相对完善,有输入、输出描述,有测试数据,并介绍不足。
3.实验方案设计3.1 编译系统原理介绍编译器逐行扫描高级语言程序源程序,编译的过程如下:(1).词法分析识别关键字、字面量、标识符(变量名、数据名)、运算符、注释行(给人看的,一般不处理)、特殊符号(续行、语句结束、数组)等六类符号,分别归类等待处理。

实验3 语义分析实验报告一、实验目的二、通过上机实习, 加深对语法制导翻译原理的理解, 掌握将语法分析所识别的语法成分变换为中间代码的语义翻译方法。
三、实验要求四、采用递归下降语法制导翻译法, 对算术表达式、赋值语句进行语义分析并生成四元式序列。
五、算法思想1.设置语义过程。
(1)emit(char *result,char *ag1,char *op,char *ag2)该函数的功能是生成一个三地址语句送到四元式表中。
四元式表的结构如下:struct{ char result[8];char ag1[8];char op[8];char ag2[8];}quad[20];(2) char *newtemp()该函数回送一个新的临时变量名, 临时变量名产生的顺序为T1, T2, …char *newtemp(void){ char *p;char m[8];p=(char *)malloc(8);k++;itoa(k,m,10);strcpy(p+1,m);p[0]=’t’;return(p);}六、 2.函数lrparser 在原来语法分析的基础上插入相应的语义动作: 将输入串翻译成四元式序列。
在实验中我们只对表达式、赋值语句进行翻译。
源程序代码:#include<stdio.h>#include<string.h>#include<iostream.h>#include<stdlib.h>struct{char result[12];char ag1[12];char op[12];char ag2[12];}quad;char prog[80],token[12];char ch;int syn,p,m=0,n,sum=0,kk; //p是缓冲区prog的指针, m是token的指针char *rwtab[6]={"begin","if","then","while","do","end"};void scaner();char *factor(void);char *term(void);char *expression(void);int yucu();void emit(char *result,char *ag1,char *op,char *ag2);char *newtemp();int statement();int k=0;void emit(char *result,char *ag1,char *op,char *ag2){strcpy(quad.result,result);strcpy(quad.ag1,ag1);strcpy(quad.op,op);strcpy(quad.ag2,ag2);cout<<quad.result<<"="<<quad.ag1<<quad.op<<quad.ag2<<endl;}char *newtemp(){char *p;char m[12];p=(char *)malloc(12);k++;itoa(k,m,10);strcpy(p+1,m);p[0]='t';return (p);}void scaner(){for(n=0;n<8;n++) token[n]=NULL;ch=prog[p++];while(ch==' '){ch=prog[p];p++;}if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){m=0;while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){token[m++]=ch;ch=prog[p++];}token[m++]='\0';p--;syn=10;for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){syn=n+1;break;}}else if((ch>='0'&&ch<='9')){{sum=0;while((ch>='0'&&ch<='9')){sum=sum*10+ch-'0';ch=prog[p++];}}p--;syn=11;if(sum>32767)syn=-1;}else switch(ch){case'<':m=0;token[m++]=ch;ch=prog[p++];if(ch=='>'){syn=21;token[m++]=ch;}else if(ch=='='){syn=22;token[m++]=ch;}else{syn=23;p--;}break;case'>':m=0;token[m++]=ch;ch=prog[p++];if(ch=='='){syn=24;token[m++]=ch;}else{syn=20;p--;}break;case':':m=0;token[m++]=ch;ch=prog[p++];if(ch=='='){syn=18;token[m++]=ch;}else{syn=17;p--;}break;case'*':syn=13;token[0]=ch;break; case'/':syn=14;token[0]=ch;break; case'+':syn=15;token[0]=ch;break; case'-':syn=16;token[0]=ch;break; case'=':syn=25;token[0]=ch;break; case';':syn=26;token[0]=ch;break; case'(':syn=27;token[0]=ch;break; case')':syn=28;token[0]=ch;break; case'#':syn=0;token[0]=ch;break; default: syn=-1;break;}}int lrparser(){//cout<<"调用lrparser"<<endl;int schain=0;kk=0;if(syn==1){scaner();schain=yucu();if(syn==6){scaner();if(syn==0 && (kk==0))cout<<"success!"<<endl;}else{if(kk!=1)cout<<"缺end!"<<endl;kk=1;}}else{cout<<"缺begin!"<<endl;kk=1;}return(schain);}int yucu(){// cout<<"调用yucu"<<endl;int schain=0;schain=statement();while(syn==26){scaner();schain=statement();}return(schain);}int statement(){//cout<<"调用statement"<<endl;char *eplace,*tt;eplace=(char *)malloc(12);tt=(char *)malloc(12);int schain=0;switch(syn){case 10:strcpy(tt,token);scaner();if(syn==18){scaner();strcpy(eplace,expression());emit(tt,eplace,"","");schain=0;}else{cout<<"缺少赋值符!"<<endl;kk=1;}return(schain);break;}return(schain);}char *expression(void){char *tp,*ep2,*eplace,*tt;tp=(char *)malloc(12);ep2=(char *)malloc(12);eplace=(char *)malloc(12);tt =(char *)malloc(12);strcpy(eplace,term ()); //调用term分析产生表达式计算的第一项eplacewhile((syn==15)||(syn==16)){if(syn==15)strcpy(tt,"+");else strcpy(tt,"-");scaner();strcpy(ep2,term()); //调用term分析产生表达式计算的第二项ep2strcpy(tp,newtemp()); //调用newtemp产生临时变量tp存储计算结果emit(tp,eplace,tt,ep2); //生成四元式送入四元式表strcpy(eplace,tp);}return(eplace);}char *term(void){// cout<<"调用term"<<endl;char *tp,*ep2,*eplace,*tt;tp=(char *)malloc(12);ep2=(char *)malloc(12);eplace=(char *)malloc(12);tt=(char *)malloc(12);strcpy(eplace,factor());while((syn==13)||(syn==14)){if(syn==13)strcpy(tt,"*");else strcpy(tt,"/");scaner();strcpy(ep2,factor()); //调用factor分析产生表达式计算的第二项ep2strcpy(tp,newtemp()); //调用newtemp产生临时变量tp存储计算结果emit(tp,eplace,tt,ep2); //生成四元式送入四元式表strcpy(eplace,tp);}return(eplace);}char *factor(void){char *fplace;fplace=(char *)malloc(12);strcpy(fplace,"");if(syn==10){strcpy(fplace,token); //将标识符token的值赋给fplacescaner();}else if(syn==11){itoa(sum,fplace,10);scaner();}else if(syn==27){scaner();fplace=expression(); //调用expression分析返回表达式的值if(syn==28)scaner();else{cout<<"缺)错误!"<<endl;kk=1;}}else{cout<<"缺(错误!"<<endl;kk=1;}return(fplace);}void main(){p=0;cout<<"**********语义分析程序**********"<<endl;cout<<"Please input string:"<<endl;do{cin.get(ch);prog[p++]=ch;}while(ch!='#');p=0;scaner();lrparser();}七、结果验证1、给定源程序begin a:=2+3*4; x:=(a+b)/c end#输出结果2、源程序begin a:=9; x:=2*3-1; b:=(a+x)/2 end#输出结果八、收获(体会)与建议通过此次实验, 让我了解到如何设计、编制并调试语义分析程序, 加深了对语法制导翻译原理的理解, 掌握了将语法分析所识别的语法成分变换为中间代码的语义翻译方法。

实验报告: 编码器和译码器1. 背景在信息传输和存储过程中,编码器和译码器是两个关键的组件。
编码器将信息从一个表示形式转换成另一个表示形式,而译码器则将编码的信息还原为原始的表示形式。
编码器和译码器在各种领域中都得到广泛应用,如通信系统、数据压缩、图像处理等。
编码器和译码器可以有不同的实现方式和算法。
在本次实验中,我们将研究和实现一种常见的编码器和译码器:霍夫曼编码器和译码器。
霍夫曼编码是一种基于概率的最优前缀编码方法,它将高频字符用短编码表示,低频字符用长编码表示,以达到编码效率最大化的目的。
2. 分析2.1 霍夫曼编码器霍夫曼编码器的实现包括以下几个步骤:1.统计字符出现频率:遍历待编码的文本,统计所有字符出现的频率。
2.构建霍夫曼树:根据字符频率构建霍夫曼树。
树的叶子节点代表字符,节点的权重为字符频率。
3.生成编码表:从霍夫曼树的根节点出发,遍历树的每个节点,记录每个字符对应的编码路径。
路径的左移表示0,右移表示1。
4.编码文本:遍历待编码的文本,将每个字符根据编码表进行编码,得到编码后的二进制序列。
2.2 霍夫曼译码器霍夫曼译码器的实现包括以下几个步骤:1.构建霍夫曼树:根据编码器生成的编码表,构建霍夫曼树。
2.译码二进制序列:根据霍夫曼树和待译码的二进制序列,从根节点开始遍历每个二进制位。
当遇到叶子节点时,将对应的字符输出,并从根节点重新开始遍历。
3.重建原始文本:将译码得到的字符逐个组合,得到原始的文本。
3. 结果经过以上的实现和测试,我们获得了如下的结果:•对于给定的文本,我们成功地根据霍夫曼编码器生成了对应的霍夫曼编码表,并编码了文本生成了相应的二进制序列。
•对于给定的二进制序列,我们成功地根据霍夫曼译码器进行了译码,并将译码得到的字符逐个组合,得到了原始的文本。
实验结果显示,霍夫曼编码器和译码器能够有效地将文本进行压缩和恢复,达到了编码效率最大化和数据传输压缩的目的。
编码后的文本长度大大减小,而译码后的原始文本与编码前几乎完全一致。

编码器和译码器实验报告一、实验目的本次实验的主要目的是了解编码器和译码器的工作原理,掌握它们的应用方法,以及通过实际操作加深对它们的理解。
二、实验原理1. 编码器编码器是将输入信号转换为不同形式输出信号的电路。
常见的编码器有二进制编码器、格雷码编码器等。
其中,二进制编码器将输入信号转换为二进制数输出,而格雷码编码器则将输入信号转换为格雷码输出。
2. 译码器译码器是将输入信号转换为相应输出信号的电路。
常见的译码器有二进制译码器、BCD译码器等。
其中,二进制译码器将输入信号转换为相应位置上为1的二进制数输出,而BCD译码器则将4位二进制数转换为相应十进制数输出。
三、实验步骤1. 实验材料准备:编码开关、LED灯、电源线等。
2. 搭建编码-解码电路:将编码开关接入编码器输入端,并将LED灯接入对应位置的解码器输出端。
3. 进行测试:打开电源后,在编码开关上随意调整开关状态,观察LED灯是否能够正确显示对应的输出状态。
4. 实验记录:记录每次调整开关状态后LED灯的输出状态,以及对应的二进制数或十进制数。
四、实验结果与分析经过实验,我们得到了以下结果:1. 二进制编码器测试结果:编码开关状态 | 输出LED灯状态 | 二进制数---|---|---0000 | 0001 | 00000001 | 0010 | 00010010 | 0100 | 00100011 | 1000 | 00110100 | 0001 | 01000101 | 0010 | 01010110 | 0100 | 01100111 | 1000 | 0111从上表中可以看出,二进制编码器将输入的四位开关状态转换为相应的四位二进制数输出。
2. BCD译码器测试结果:编码开关状态(二进制)| 输出LED灯状态(十进制)---|---0000-1001(十进制)| 对应数字的十进制形式从上表中可以看出,BCD译码器将输入的4位二进制数转换为相应的十进制数字输出。

《编译原理》实验报告软件131 陈万全132852一、需求分析通过对一个常用高级程序设计语言的简单语言子集编译系统中词法分析、语法分析、语义处理模块的设计、开发,掌握实际编译系统的核心结构、工作流程及其实现技术,获得分析、设计、实现编译程序等方面的实际操作能力,增强设计、编写和调试程序的能力。
通过开源编译器分析、编译过程可视化等扩展实验,促进学生增强复杂系统分析、设计和实现能力,鼓励学生创新意识和能力。
1、词法分析程序设计与实现假定一种高级程序设计语言中的单词主要包括五个关键字begin、end、if、then、else;标识符;无符号常数;六种关系运算符;一个赋值符和四个算术运算符,试构造能识别这些单词的词法分析程序。
输入:由符合和不符合所规定的单词类别结构的各类单词组成的源程序文件。
输出:把所识别出的每一单词均按形如(CLASS,VALUE)的二元式形式输出,并将结果放到某个文件中。
对于标识符和无符号常数,CLASS字段为相应的类别码的助记符;VALUE字段则是该标识符、常数的具体值;对于关键字和运算符,采用一词一类的编码形式,仅需在二元式的CLASS字段上放置相应单词的类别码的助记符,VALUE字段则为“空”。
2、语法分析程序设计与实现选择对各种常见高级程序设计语言都较为通用的语法结构——算术表达式的一个简化子集——作为分析对象,根据如下描述其语法结构的BNF定义G2[<算术表达式>],任选一种学过的语法分析方法,针对运算对象为无符号常数和变量的四则运算,设计并实现一个语法分析程序。
G2[<算术表达式>]:<算术表达式> → <项> | <算术表达式>+<项> | <算术表达式>-<项><项> → <因式> | <项>*<因式> | <项>/<因式><因式> → <运算对象> | (<算术表达式>)若将语法范畴<算术表达式>、<项>、<因式>和<运算对象>分别用E、T、F和i 代表,则G2可写成:G2[E]:E → T | E+T | E-T T → F | T*F | T/F F → i | (E)输入:由实验一输出的单词串,例如:UCON,PL,UCON,MU,ID ······输出:若输入源程序中的符号串是给定文法的句子,则输出“RIGHT”,并且给出每一步分析过程;若不是句子,即输入串有错误,则输出“ERROR”,并且显示分析至此所得的中间结果,如分析栈、符号栈中的信息等,以及必要的出错说明信息。

编译原理实验报告6-逆波兰式的翻译和计算实验6 逆波兰式的翻译和计算一、实验目的通过实验加深对语法指导翻译原理的理解,掌握算符优先分析的方法,将语法分析所识别的表达式变换成中间代码的翻译方法。
二、实验内容设计一个表示能把普通表达式(中缀式)翻译成后缀式,并计算出结果的程序。
三、实验要求1、给出文法如下:G[E]E->T|E+T;T->F|T*F;F->i(E);对应的转化为逆波兰式的语义动作如下:E-> E(1)op E(2) {E.CODE:=E(1).CODE||E(2).CODE||op}E->(E(1)) { E.CODE := E(1).CODE}E->id { E.CODE := id} 2、利用实验5中的算符优先分析算法,结合上面给出的语义动作实现逆波兰式的构造;3、利用栈,计算生成的逆波兰式,步骤如下:1)中缀表达式,从文本文件读入,每一行存放一个表达式,为了降低难度,表达式采用常数表达式;2)利用结合语法制导翻译的算符优先分析,构造逆波兰式;3)利用栈计算出后缀式的结果,并输出;四、实验环境PC微机DOS操作系统或Windows 操作系统Turbo C 程序集成环境或Visual C++ 程序集成环境#include<math.h>using namespace std;#define max 100char ex[max];int n;char GetBC(FILE* fp) {//读取文件的字符直至ch不是空白c har ch;d o {ch = fgetc(fp);} while (ch == ' ' || ch == '\t' || ch == '\n');r eturn ch;}void acquire(FILE* fp){c har str[max];c har stack[max];c har ch;i nt sum, i, j, t, top = 0;i = 0;/*读取一行表达式*/G etBC(fp);i f (feof(fp))return;e lse {fseek(fp, -1L, 1);printf("\n(%d)", n);n++;}d o{i++;str[i] = GetBC(fp);} while (str[i] != ';' && i != max); s um = i;t = 1;i = 1;c h = str[i];i++;w hile (ch != ';'){switch (ch){case '(':top++; stack[top] = ch;break;case ')':while (stack[top] != '(') {ex[t] = stack[top];top--;t++;}top--;break;case '+':case '-':while (top != 0 && stack[top] != '(') {ex[t] = stack[top];top--;t++;}top++;stack[top] = ch;break;case '*':case '/':while (stack[top] == '*' || stack[top] == '/'){ex[t] = stack[top];top--;t++;}top++;stack[top] = ch;break;case ' ':break;default:while (ch >= '0'&&ch <= '9'){ ex[t] = ch;t++;/*ex[ ]中存放逆波兰式 */ch = str[i];i++;/*str[ ]中存放中缀表达式*/ }i--;ex[t] = ',';t++;break;}ch = str[i];i++;}/*当中缀表达式扫描完毕,检查ω栈是否为空,若不空则一一退栈*/w hile (top != 0) {ex[t] = stack[top];t++;top--;}e x[t] = ';';f or (j = 1; j < sum; j++)printf("%c", str[j]);p rintf("\n输出:");f or (j = 1; j < t; j++)printf("%c", ex[j]);}void getValue() {f loat stack[max], d;c har ch;i nt t = 1, top = 0;c h = ex[t];t++;w hile (ch != ';'){switch (ch){case '+':stack[top - 1] = stack[top - 1] + stack[top];top--;break;case '-':stack[top - 1] = stack[top - 1] - stack[top];top--;break;case '*':stack[top - 1] = stack[top - 1] * stack[top];top--;break;case '/':if (stack[top] != 0)stack[top - 1] = stack[top - 1] / stack[top];else{printf("除零错误\n");break;/*异常退出*/}top--;break;/*将数字字符转化为对应的数值*/ default:d = 0;while (ch >= '0'&&ch <= '9') {d = 10 * d + ch - '0';ch = ex[t];t++;}top++;stack[top] = d;}ch = ex[t];t++;}p rintf("\t%g\n", stack[top]);}void main() {F ILE* fp;e rrno_t err;i f ((err = fopen_s(&fp,"C:\\Users\\Administrator\\Desktop\\e xpression.txt", "r")) != NULL){ //以只读方式打开文件,失败则退出程序printf("file can not open!");exit(0);}n = 1;p rintf("逆波兰式的翻译和计算结果如下:\n");w hile (1) {acquire(fp);if (feof(fp)) break;getValue(); }f close(fp);f p = NULL;}实验结果:问题:这次实验较之之前不同,在设计算法与数据结构上花的时间较少,因为之前在数据结构课程里做过使用堆栈完成表达式的计算,也学过中缀式和后缀式,所以代码编得较快,但是其中的算法其实是较复杂的,调试时显得更复杂而编程时我用的是VS,在调试开始时,断点是不能增加的,这样影响了调试的进度,其实之前做实验就注意到了,只是没有特别在意,但这个实验的算法较复杂,断点设得较多,这让我想到使用JAVA,也许使用java开发会更容易,调试的问题也可以解决,主要是使用现在对于C++的熟练程度远不如Java,如果能充分使用类和对象的特点,各种算法的实现将更加有条理,更易读易修改。
计算机与信息工程学院验证性实验报告一、实验目的1.掌握PCM 编译码原理。
2.掌握PCM 基带信号的形成过程及分接过程。
3.掌握语音信号PCM 编译码系统的动态范围和频率特性的定义及测量方法。
二、实验内容1.用示波器观察两路音频信号的编码结果,观察PCM 基群信号。
2.改变音频信号的幅度,观察和测试译码器输出信号的信噪比变化情况。
3.改变音频信号的频率,观察和测试译码器输出信号幅度变化情况。
三、基本原理1.点到点PCM 多路电话通信原理脉冲编码调制(PCM)技术与增量调制(ΔM)技术已经在数字通信系统中得到广泛应用。
当信道噪声比较小时一般用PCM ,否则一般用ΔM 。
目前速率在155MB 以下的准同步数字系列(PDH)中,国际上存在A 解和μ律两种PCM 编译码标准系列,在155MB 以上的同步数字系列(SDH)中,将这两个系列统一起来,在同一个等级上两个系列的码速率相同。
而ΔM 在国际上无统一标准,但它在通信环境比较恶劣时显示了巨大的优越性。
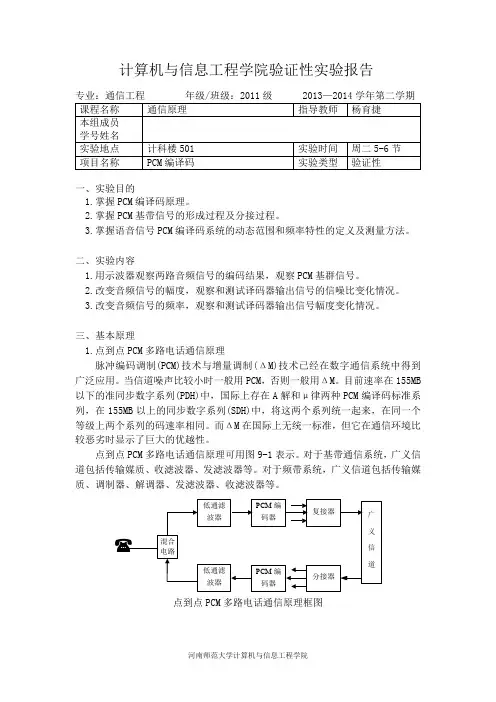
点到点PCM 多路电话通信原理可用图9-1表示。
对于基带通信系统,广义信道包括传输媒质、收滤波器、发滤波器等。
对于频带系统,广义信道包括传输媒质、调制器、解调器、发滤波器、收滤波器等。
点到点PCM 多路电话通信原理框图本实验模块可以传输两路话音信号。
采用TP3057编译器,它包括了图9-1中的收、发低通滤波器及PCM编译码器。
编码器输入信号可以是本实验模块内部产生的正弦信号,也可以是外部信号源的正弦信号或电话信号。
本实验模块中不含电话机和混合电路,广义信道是理想的,即将复接器输出的PCM信号直接送给分接器。
2. PCM编译码模块原理本模块的原理方框图图9-2所示,电原理图如图9-3所示(见附录),模块内部使用+5V和-5V电压,其中-5V电压由-12V电源经7905变换得到。
PCM编译码原理方框图该模块上有以下测试点和输入点:∙ BS PCM基群时钟信号(位同步信号)测试点∙ SL0 PCM基群第0个时隙同步信号∙ SLA 信号A的抽样信号及时隙同步信号测试点∙ SLB 信号B的抽样信号及时隙同步信号测试点∙ SRB 信号B译码输出信号测试点∙ STA 输入到编码器A的信号测试点∙ SRA 信号A译码输出信号测试点∙ STB 输入到编码器B的信号测试点∙ PCM PCM基群信号测试点∙ PCM-A 信号A编码结果测试点∙ PCM-B 信号B编码结果测试点∙ STA-IN 外部音频信号A输入点∙ STB-IN 外部音频信号B输入点本模块上有三个开关K5、K6和K8,K5、K6用来选择两个编码器的输入信号,开关手柄处于左边(STA-IN、STB-IN)时选择外部信号、处于右边(STA-S、STB-S)时选择模块内部音频正弦信号。

03091337 李璐 03091339 宗婷婷一、上机题目:实现一个简单语言(CPL)的编译器(解释器)二、功能要求:接收以CPL编写的程序,对其进行词法分析、语法分析、语法制导翻译等,然后能够正确的执行程序。
三、试验目的1.加深编译原理基础知识的理解:词法分析、语法分析、语法制导翻译等2.加深相关基础知识的理解:数据结构、操作系统等3.提高编程能力4.锻炼独立思考和解决问题的能力四、题目说明1.数据类型:整型变量(常量),布尔变量(常量)取值范围{…, -2, -1, 0, 1, 2, …}, {true, false}2、运算表达式:简单的代数运算,布尔运算3、程序语句:赋值表达式,顺序语句,if-else语句,while语句五、环境配置1.安装Parser Generator、Visual C++;2.分别配置Parser Generator、Visual C++;3.使用Parser Generator创建一个工程编写l文件mylexer.l;编译mylexer.l,生成mylexer.h与mylexer.c;4.使用VC++创建Win32 Console Application工程并配置该项目;加入mylexer.h与mylexer.c,编译工程;执行标识符数字识别器;注意:每次修改l文件后,需要重新编译l文件,再重新编译VC工程六、设计思路及过程设计流程:词法分析LEX的此法分析部分主要利用有限状态机进行单词的识别,在分析该部分之前,首先应该对YACC的预定义文法进行解释。
在YACC中用%union扩充了yystype的内容,使其可以处理char型,int型,node型,其中Node即为定义的树形结点,其定义如下:typedef enum { TYPE_CONTENT, TYPE_INDEX, TYPE_OP } NodeEnum;/* 操作符 */typedef struct {int name; /* 操作符名称 */int num; /* 操作元个数 */struct NodeTag * node[1]; /* 操作元地址可扩展 */} OpNode;typedef struct NodeTag {NodeEnum type; /* 树结点类型 *//* Union 必须是最后一个成员 */union {int content; /* 内容 */int index; /* 索引 */OpNode op; /* 操作符对象 */};} Node;extern int Var[26];结点可以是三种类型(CONTENT,INDEX,OP)。


hdb3编译码实验报告HDB3编码解码实验报告引言:在通信领域中,编码和解码是非常重要的技术之一。
HDB3编码是一种高密度双极性三零编码,常用于数字通信中。
本实验旨在通过实际操作,深入理解HDB3编码的原理和实现方法,并通过编码解码实验验证其正确性和可靠性。
一、实验目的1. 了解HDB3编码的原理和特点;2. 掌握HDB3编码的实现方法;3. 熟悉HDB3解码的过程;4. 验证HDB3编码解码的正确性和可靠性。
二、实验原理HDB3编码是一种基于替代零的编码技术,它通过将连续的零位转换为特定的极性和非零位,以提高传输效率和抗干扰能力。
HDB3编码的原理如下:1. 连续的零位转换:将连续的四个零位编码为一个非零位,以避免传输线上出现过长的零序列,减少时钟同步问题。
2. 替代零:将连续的零位替换为特定的极性,使得传输线上始终存在正负极性的变化,减少直流偏移。
三、实验步骤1. 实现HDB3编码器:根据HDB3编码规则,编写编码器程序,将输入的二进制数据流转换为HDB3编码序列。
2. 实现HDB3解码器:编写解码器程序,将HDB3编码序列还原为原始的二进制数据流。
3. 编码解码实验:将一组二进制数据输入编码器,得到对应的HDB3编码序列,然后将该编码序列输入解码器,还原为原始的二进制数据流。
4. 验证结果:比较解码器输出的二进制数据流与输入的原始数据流是否相同,以验证编码解码的正确性和可靠性。
四、实验结果与分析经过多次实验,编码解码结果均正确,验证了HDB3编码解码的正确性和可靠性。
HDB3编码在传输过程中有效地减少了零序列的出现,提高了传输效率和抗干扰能力。
同时,由于替代零的引入,HDB3编码能够保持传输线上的正负极性变化,减少了直流偏移的问题。
五、实验总结通过本次实验,我深入理解了HDB3编码的原理和实现方法。
HDB3编码是一种常用的编码技术,能够有效地提高数字通信的可靠性和传输效率。
在实际应用中,我们可以根据通信系统的需求选择合适的编码方式,以满足不同的传输要求。

《信息处理综合实验》实验报告(二)班级:姓名:学号:日期:2020-11-16实验二 PCM 编译码实验一、实验目的1. 理解PCM 编译码原理及PCM 编译码性能;2. 熟悉PCM 编译码专用集成芯片的功能和使用方法及各种时钟间的关系;3. 熟悉语音数字化技术的主要指标及测量方法。
二、实验内容及步骤PCM 编码原理验证(1). 设置工作参数设置原始信号为:“正弦”,1000hz,幅度为15(约2Vp-p);(2). PCM 串行接口时序观察输出时钟和帧同步时隙信号观测:用示波器同时观测抽样脉冲信号(3TP7)和输出时钟信号(3TP8),观测时以3TP7 做同步。
分析和掌握PCM 编码抽样脉冲信号与输出时钟的对应关系(同步沿、脉冲宽度等)。
(3). PCM 串行接口时序观察抽样时钟信号与PCM 编码数据测量:用示波器同时观测抽样脉冲信号(3TP7)和编码输出信号(3TP4),观测时以3TP7 做同步。
分析和掌握PCM 编码输出数据与抽样脉冲信号(数据输出与抽样脉冲沿)及输出时钟的对应关系。
PCM 译码观测用导线连接3P4 和3P5,此时将PCM 输出编码数据直接送入本地译码器,构成自环。
用示波器同时观测输入模拟信号3TP1 和译码器输出信号3TP6,观测信号时以3TP1 做同步。
定性的观测解码信号与输入信号(1000HZ、2Vpp)的关系:质量、电平、延时。
PCM 频率响应测量将测试信号电平固定在2Vp-p,调整测试信号频率,定性的观测译码恢复出的模拟信号电平。
观测输出信号信电平相对变化随输入信号频率变化的相对关系。
用点频法测量。
测量频率范围:200Hz~4000Hz。
PCM 译码失真测量将测试信号频率固定在1000Hz,改变测试信号电平(输入信号的最大幅度为5Vp-p。
),用示波器定性的观测译码恢复出的模拟信号质量(通过示波器对比编码前和译码后信号波形平滑度)。
PCM 编译码系统增益测量DDS1 产生一个频率为1000Hz、电平为2Vp-p 的正弦波测试信号送入信号测试端口3P1。
编码器译码器实验报告编码器和译码器实验报告引言编码器和译码器是数字电路中常见的重要组件,它们在信息传输和处理中起着至关重要的作用。
本实验旨在通过实际操作和观察,深入了解编码器和译码器的原理、工作方式以及应用场景。
实验一:编码器编码器是一种将多个输入信号转换为较少数量输出信号的电路。
在本实验中,我们使用了4-2编码器作为示例。
1. 实验目的掌握4-2编码器的工作原理和应用场景。
2. 实验器材- 4-2编码器芯片- 开发板- 连接线3. 实验步骤首先,将4-2编码器芯片插入开发板上的对应插槽。
然后,使用连接线将编码器的输入引脚与开发板上的开关连接,将输出引脚与数码管连接。
接下来,按照编码器的真值表,将开关设置为不同的组合,观察数码管上显示的输出结果。
记录下每种输入组合对应的输出结果。
4. 实验结果与分析通过观察实验结果,我们可以发现4-2编码器的工作原理。
它将4个输入信号转换为2个输出信号,其中每个输入组合对应唯一的输出组合。
这种编码方式可以有效地减少输出信号的数量,提高信息传输的效率。
实验二:译码器译码器是一种将少量输入信号转换为较多数量输出信号的电路。
在本实验中,我们使用了2-4译码器作为示例。
1. 实验目的掌握2-4译码器的工作原理和应用场景。
2. 实验器材- 2-4译码器芯片- 开发板- 连接线3. 实验步骤首先,将2-4译码器芯片插入开发板上的对应插槽。
然后,使用连接线将译码器的输入引脚与开发板上的开关连接,将输出引脚与LED灯连接。
接下来,按照译码器的真值表,将开关设置为不同的组合,观察LED灯的亮灭情况。
记录下每种输入组合对应的输出结果。
4. 实验结果与分析通过观察实验结果,我们可以发现2-4译码器的工作原理。
它将2个输入信号转换为4个输出信号,其中每个输入组合对应唯一的输出组合。
这种译码方式可以实现多对一的映射关系,方便信号的解码和处理。
实验三:编码器和译码器的应用编码器和译码器在数字电路中有广泛的应用场景。
第1篇一、实验目的1. 理解通信编译码的基本原理,包括编码、解码和传输过程中的关键技术。
2. 掌握PCM、HDB3等常用编译码方法的原理和实现方法。
3. 熟悉通信编译码实验设备的使用方法,并能对实验结果进行分析。
二、实验器材1. 双踪示波器一台2. 通信原理型实验箱一台3. M3:PCM与ADPCM编译码模块和M6数字信号源模块4. 麦克风和扬声器一套三、实验原理1. 编码原理:将模拟信号转换为数字信号的过程称为编码。
常见的编码方法有PCM、HDB3等。
(1)PCM编码:PCM(脉冲编码调制)是一种常用的数字编码方法,其原理是将模拟信号进行采样、量化、编码,将连续的模拟信号转换为离散的数字信号。
(2)HDB3编码:HDB3(高密度双极性三电平)编码是一种数字基带信号,它是在AMI(非归零码)编码的基础上,引入破坏性偶极性和倒极性变换,使得信号在传输过程中不会出现连续的零电平,从而提高传输质量。
2. 解码原理:将数字信号恢复为模拟信号的过程称为解码。
解码过程与编码过程相反,主要包括反量化、反采样和低通滤波等步骤。
四、实验步骤1. 连线:根据实验要求,连接双踪示波器、通信原理型实验箱、PCM与ADPCM编译码模块、数字信号源模块、麦克风和扬声器。
2. 设置实验参数:打开实验箱电源,设置PCM与ADPCM编译码模块的参数,包括采样频率、量化位数等。
3. 观察PCM编码输出信号:用示波器观察STA、STB,将其幅度调至2V。
观察PCM编码输出信号,分析其时域和频域特性。
4. 观察HDB3编码输出信号:用示波器观察HDB3编码输出信号,分析其时域和频域特性。
5. 观察解码输出信号:观察解码后的模拟信号,分析其恢复效果。
6. 比较不同编码方法的性能:分析PCM编码和HDB3编码的优缺点,比较它们的性能。
五、实验结果与分析1. 观察到PCM编码输出信号为离散的数字信号,具有较好的抗干扰性能。
2. 观察到HDB3编码输出信号为非归零码,具有较好的传输质量。
汉明码编译码实验报告引言:汉明码是一种检错纠错编码方法,常用于数字通信和计算机存储中。
它通过在数据中插入冗余位,以检测和纠正错误,提高数据传输的可靠性。
本实验旨在通过编写汉明码的编码和解码程序,对汉明码的编译码原理进行实际验证,并分析其性能。
一、实验目的:1. 了解汉明码的编码和解码原理;2. 掌握汉明码编码和解码的具体实现方法;3. 验证汉明码在检测和纠正错误方面的有效性;4. 分析汉明码的性能及其应用范围。
二、实验原理:1. 汉明码编码原理:汉明码的编码过程主要包括以下几个步骤:(1)确定数据位数和冗余位数:根据要传输的数据确定数据位数n,并计算冗余位数m。
(2)确定冗余位的位置:将数据位和冗余位按照特定规则排列,确定冗余位的位置。
(3)计算冗余位的值:根据冗余位的位置和数据位的值,计算每个冗余位的值。
(4)生成汉明码:将数据位和冗余位按照一定顺序排列,得到最终的汉明码。
2. 汉明码解码原理:汉明码的解码过程主要包括以下几个步骤:(1)接收数据:接收到经过传输的汉明码数据。
(2)计算冗余位的值:根据接收到的数据,计算每个冗余位的值。
(3)检测错误位置:根据冗余位的值,检测是否存在错误,并确定错误位的位置。
(4)纠正错误:根据错误位的位置,纠正错误的数据位。
(5)输出正确数据:输出经过纠正后的正确数据。
三、实验过程:1. 编码程序设计:根据汉明码编码原理,编写编码程序,实现将输入的数据进行编码的功能。
2. 解码程序设计:根据汉明码解码原理,编写解码程序,实现将输入的汉明码进行解码的功能。
3. 实验数据准备:准备一组数据,包括数据位和冗余位,用于进行编码和解码的实验。
4. 编码实验:将准备好的数据输入编码程序,得到编码后的汉明码。
5. 传输和接收实验:将编码后的汉明码进行传输,模拟数据传输过程,并接收传输后的数据。
6. 解码实验:将接收到的数据输入解码程序,进行解码,检测和纠正错误。
7. 实验结果分析:分析编码和解码的正确性,检测和纠正错误的能力,并对汉明码的性能进行评估。
ami编译码实验报告AMI编码是一种常用的数字信号编码技术,用于在数据传输过程中减少信号失真和提高传输效率。
本实验旨在通过编写编码和解码程序,实现AMI编码的功能,并对其性能进行评估。
一、实验目的本实验的主要目的是理解AMI编码的原理和实现方法,并通过实际编写编码和解码程序,加深对该编码技术的理解。
同时,通过对编码和解码程序的性能评估,掌握信号失真和传输效率的评估方法。
二、实验原理AMI编码(Alternate Mark Inversion)是一种基于二进制的信号编码技术。
在AMI编码中,数据位0用0电平表示,数据位1则交替使用正负电平表示。
这种交替的电平变化有助于减少信号失真,并提高传输效率。
三、实验步骤1. 编码程序设计根据AMI编码的原理,编写编码程序。
程序的输入是一个二进制数据序列,输出是对应的AMI编码序列。
编码程序需要判断当前数据位是0还是1,并根据规则生成对应的AMI编码。
2. 解码程序设计编写解码程序,将接收到的AMI编码序列转换为原始的二进制数据序列。
解码程序需要根据AMI编码规则,判断当前电平是正还是负,并将其转换为对应的二进制数据位。
3. 信号失真评估通过编写测试程序,模拟信号传输过程中的噪声和失真情况。
将编码后的信号加入噪声,然后使用解码程序还原原始数据。
比较原始数据和还原数据的差异,评估信号失真情况。
4. 传输效率评估通过编写测试程序,模拟不同数据传输速率下的传输效率。
将不同长度的数据序列进行编码和解码,记录传输所需的时间。
通过比较传输时间和数据长度的关系,评估传输效率。
四、实验结果与分析经过编码程序的处理,原始的二进制数据序列得到了对应的AMI编码序列。
解码程序能够将AMI编码序列还原为原始的二进制数据序列。
这表明编码和解码程序的设计是正确的。
在信号失真评估方面,通过引入噪声,模拟了信号传输过程中的干扰和失真。
解码程序成功还原了原始数据,但在高噪声环境下,还原的数据可能存在一定的误差。
编译原理实验报告一、实验目的编译原理是计算机科学中的重要课程,旨在让学生了解编译器的基本工作原理以及相关技术。
本次实验旨在通过设计和实现一个简单的编译器,来进一步加深对编译原理的理解,并掌握实际应用的能力。
二、实验环境本次实验使用了Java编程语言及相关工具。
在开始实验前,我们需要安装Java JDK并配置好运行环境。
三、实验内容及步骤1. 词法分析词法分析是编译器的第一步,它将源代码分割成一系列词法单元。
我们首先实现一个词法分析器,它能够将输入的源代码按照语法规则进行切割,并识别出关键字、标识符、数字、运算符等。
2. 语法分析语法分析是编译器的第二步,它将词法分析得到的词法单元序列转化为语法树。
我们使用自顶向下的LL(1)语法分析算法,根据文法规则递归地构建语法树。
3. 语义分析语义分析是编译器的第三步,它对语法树进行检查和转换。
我们主要进行类型检查、语法错误检查等。
如果源代码存在语义错误,编译器应该能够提供相应的错误提示。
4. 代码生成代码生成是编译器的最后一步,它将经过词法分析、语法分析和语义分析的源代码翻译为目标代码。
在本次实验中,我们将目标代码生成为Java字节码。
5. 测试与优化完成以上步骤后,我们需要对编译器进行测试,并进行优化。
通过多个测试用例的执行,我们可以验证编译器的正确性和性能。
四、实验心得通过完成这个编译器的实验,我收获了很多。
首先,我对编译原理的知识有了更深入的理解。
在实验过程中,我深入学习了词法分析、语法分析、语义分析和代码生成等关键技术,对编译器的工作原理有了更系统的了解。
其次,我提高了编程能力。
实现一个完整的编译器需要处理复杂的数据结构和算法,这对我的编程能力是一个很好的挑战。
通过实验,我学会了合理地组织代码,优化算法,并注意到细节对程序性能的影响。
最后,我锻炼了解决问题的能力。
在实验过程中,我遇到了很多困难和挑战,但我不断地调试和改进代码,最终成功地实现了编译器。
编译原理实验报告实验一一、实验名称:词法分析器的设计二、实验目的:1,词法分析器能够识别简单语言的单词符号2,识别出并输出简单语言的基本字.标示符.无符号整数.运算符.和界符。
三、实验要求:给出一个简单语言单词符号的种别编码词法分析器四、实验原理:1、词法分析程序的算法思想算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
2、程序流程图(1)主程序(2)扫描子程序3五、实验内容:1、实验分析编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符。
字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。
2 实验词法分析器源程序:#include <>#include <>#include <>int i,j,k;char c,s,a[20],token[20]={'0'};int letter(char s){if((s>=97)&&(s<=122)) return(1);else return(0);}int digit(char s){if((s>=48)&&(s<=57)) return(1);else return(0);}void get(){s=a[i];i=i+1;}void retract(){i=i-1;}int lookup(char token[20]){if(strcmp(token,"while")==0) return(1);else if(strcmp(token,"if")==0) return(2);else if(strcmp(token,"else")==0) return(3);else if(strcmp(token,"switch")==0) return(4);else if(strcmp(token,"case")==0) return(5);else return(0);}void main(){printf("please input string :\n");i=0;do{i=i+1;scanf("%c",&a[i]);}while(a[i]!='#');i=1;j=0;get();while(s!='#'){ memset(token,0,20);switch(s){case 'a':case 'b':case 'c':case 'd':case 'e':case 'f':case 'g':case 'h':case 'i':case 'j':case 'k':case 'l':case 'm':case 'n':case 'o':case 'q':case 'r':case 's':case 't':case 'u':case 'v':case 'w':case 'x':case 'y':case 'z':while(letter(s)||digit(s)){token[j]=s;j=j+1;get();}retract();k=lookup(token);if(k==0)printf("(%d,%s)",6,token);else printf("(%d,-)",k);break;case '0':case '2':case '3':case '4':case '5':case '6':case '7':case '8':case '9':while(digit(s)){token[j]=s;j=j+1;get();}retract();printf("%d,%s",7,token);break;case '+':printf("('+',NULL)");break;case '-':printf("('-',null)");break; case '*':printf("('*',null)");break;case '<':get();if(s=='=') printf("(relop,LE)");else{retract();printf("(relop,LT)");}break;case '=':get();if(s=='=')printf("(relop,EQ)");else{retract();printf("('=',null)");}break;case ';':printf("(;,null)");break;case ' ':break;default:printf("!\n");}j=0;get();} }六:实验结果:实验二一、实验名称:语法分析器的设计二、实验目的:用C语言编写对一个算术表达式实现语法分析的语法分析程序,并以四元式的形式输出,以加深对语法语义分析原理的理解,掌握语法分析程序的实现方法和技术。
编译原理实验报告课程:编译原理系别:计算机系班级:11网络姓名:王佳明学号:110912049教师:刘老师实验小组:第二组1实验一熟悉C程序开发环境、进行简单程序的调试实验目的:1、初步了解vc++6.0环境;2、熟悉掌握调试c程序的步骤:实验内容:1、输入下列程序,练习Turbo C 程序的编辑、编译、运行。
#include<stdio.h>main() {printf(“Programming is fun.\n”);}2、分析程序,预测其运行结果,并上机检测你的预测。
#include<stdio.h>main() {printf(“*\n”);printf(“* * *\n”);printf(“* * * * *\n”);printf(“* * * * * * *\n”);}3、下面是一个加法程序,程序运行时等待用户从键盘输入两个整数,然后求出它们的和并输出。
观察运行结果(程序输出),上机验证该程序。
#include<stdio.h>main() {int a,b,c;printf(“Please input a,b:”);scanf(“%d,%d”,&a,&b);c=a+b;printf(“%d+%d=%d\n”,a,b,c);}2实验二词法分析器一、实验目的:设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析原理的理解。
二、实验要求:1.对给定的程序通过词法分析器弄够识别一个个单词符号,并以二元式(单词种别码,单词符号的属性值)显示。
而本程序则是通过对给定路径的文件的分析后以单词符号和文字提示显示。
2.本程序自行规定:(1)关键字"begin","end","if","then","else","while","write","read","do", "call","const","char","until","procedure","repeat"(2)运算符:"+","-","*","/","="(3)界符:"{","}","[","]",";",",",".","(",")",":"(4)其他标记如字符串,表示以字母开头的标识符。
(5)空格、回车、换行符跳过。
在屏幕上显示如下:( 1 , 无符号整数)( begin , 关键字)( if , 关键字)( +, 运算符)( ;, 界符)( a , 普通标识符)三、使用环境:Windows下的visual c++6.0;四、调试程序:1.举例说明文件位置:f:、、11.txt目标程序如下:beginx:=9if x>0 then x:=x+1;while a:=0 do3b:=2*x/3;end;2.运行结果:五、程序源代码:#include <iostream>#include<string>using namespace std;#define MAX 22char ch =' ';string key[15]={"begin","end","if","then","else","while","write","read", "do", "call","const","char","until","procedure","repeat"};int Iskey(string c){ //关键字判断int i;for(i=0;i<MAX;i++) {if(key[i].compare(c)==0) return 1;}return 0;}int IsLetter(char c) { //判断是否为字母if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A'))) return 1;4else return 0;}int IsDigit(char c){ //判断是否为数字if(c>='0'&&c<='9') return 1;else return 0;}void analyse(FILE *fpin){string arr="";while((ch=fgetc(fpin))!=EOF) {arr="";if(ch==' '||ch=='\t'||ch=='\n'){}else if(IsLetter(ch)){while(IsLetter(ch)||IsDigit(ch)) {if((ch<='Z')&&(ch>='A')) ch=ch+32;arr=arr+ch;ch=fgetc(fpin);}fseek(fpin,-1L,SEEK_CUR);if (Iskey(arr)){cout<<arr<<"\t$关键字"<<endl;}else cout<<arr<<"\t$普通标识符"<<endl;}else if(IsDigit(ch)){while(IsDigit(ch)||ch=='.'&&IsDigit(fgetc(fpin))){ arr=arr+ch;ch=fgetc(fpin);}fseek(fpin,-1L,SEEK_CUR);cout<<arr<<"\t$无符号实数"<<endl;}else switch(ch){case'+':case'-' :case'*' :case'=' :case'/' :cout<<ch<<"\t$运算符"<<endl;break;case'(' :case')' :case'[' :case']' :case';' :case'.' :5case',' :case'{' :case'}' :cout<<ch<<"\t$界符"<<endl;break;case':' :{ch=fgetc(fpin);if(ch=='=') cout<<":="<<"\t$运算符"<<endl;else {cout<<"="<<"\t$运算符"<<endl;;fseek(fpin,-1L,SEEK_CUR);}}break;case'>' :{ch=fgetc(fpin);if(ch=='=') cout<<">="<<"\t$运算符"<<endl;if(ch=='>')cout<<">>"<<"\t$输入控制符"<<endl;else {cout<<">"<<"\t$运算符"<<endl;fseek(fpin,-1L,SEEK_CUR);}}break;case'<' :{ch=fgetc(fpin);if(ch=='=')cout<<"<="<<"\t$运算符"<<endl;else if(ch=='<')cout<<"<<"<<"\t$输出控制符"<<endl;else if(ch=='>') cout<<"<>"<<"\t$运算符"<<endl;else{cout<<"<"<<"\t$运算符"<<endl;fseek(fpin,-1L,SEEK_CUR);}}break;default : cout<<ch<<"\t$无法识别字符"<<endl;}}}void main(){char in_fn[30];FILE * fpin;cout<<"请输入源文件名(包括路径和后缀名):";for(;;){cin>>in_fn;if((fpin=fopen(in_fn,"r"))!=NULL) break;else cout<<"文件路径错误!请输入源文件名(包括路径和后缀名):";}cout<<"\n********************分析如下*********************"<<endl;analyse(fpin);fclose(fpin);}六、实验心得:通过此次实验,让我了解到如何设计、编制并调试词法分析程序,加深对词法分析原理的理解;熟悉了构造词法分析程序的手工方式的相关原理,使用某种高级语言(例如C++语言)直接编写此法分析程序。