ENDF数据库介绍
- 格式:pptx
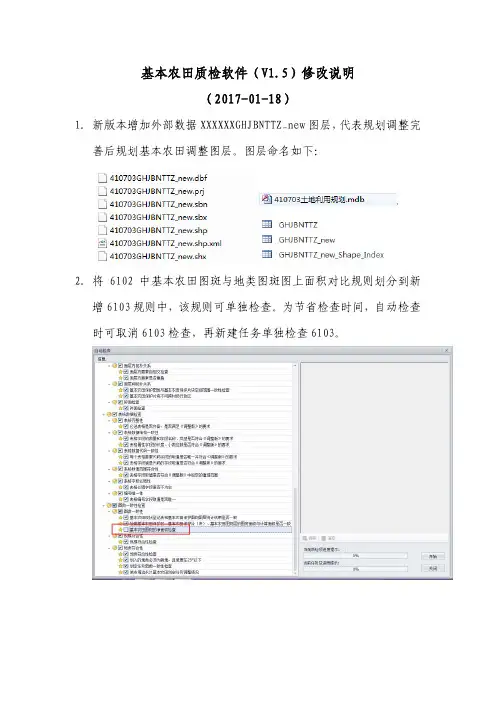
- 大小:134.62 KB
- 文档页数:25

数据库三大范式的理解一、数据库三大范式数据库三大范式(Database Normalization)是由 Edgar F. Codd 博士提出的三个范式,用于保护数据的完整性和准确性,确保数据的有效管理。
这三个范式分别是:1NF(一级范式)、2NF(二级范式)和3NF(三级范式)。
1.1NF(一级范式)--字段内不可再分割1NF(一级范式)是最低级的形式,也是一个表最基本的要求,要求每一个属性或字段都是不可分割的原子值,也就是说,每一个字段里只能存储一个完整的数据项,且不可再分割。
1.2NF(二级范式)--具有唯一标识性的字段2NF(二级范式)要求表中的实体不能有重复项,也就是说,每条记录都必须具有唯一标识性的字段,这个字段可以用作主键(Primary Key),主键是由一个或多个字段组成的字段,是唯一性的。
1.3NF(三级范式)--非主属性完全依赖于主属性3NF(三级范式)要求每一个非主属性(Non-prime Attribute)都只和一个主属性(Prime Attribute)相关,也就是说,非主属性必须完全依赖于主属性,而不能有其他的依赖关系。
在3NF的要求下,一个表中的属性必须都是原子值,即一个表中只能存储完整的数据项。
二、数据库三大范式的优点1.避免数据冗余采用数据库三大范式的优点之一就是避免数据冗余,以节省磁盘存储空间,减少系统对数据的查询,更新操作,以及维护完整性所需的开销。
2.减少数据的插入、删除、更新错误使用数据库三大范式可以减少数据插入、删除、更新错误。
一个表中的字段必须是原子值,即一个表中只能存储完整的数据项,从而避免多个表之间互相依赖及冗余带来的信息不准确的问题。
3.增强数据的可靠性使用数据库三大范式可以明确定义表、字段,以及定义每个字段的类型。
这样可以提高数据的可靠性,保证数据的准确性和完整性。
4.简化和统一系统设计数据库三大范式将表的设计规范化,使表之间的设计具有一致性,从而简化和统一系统设计。

第一范式(1NF)第一范式,强调属性的原子性约束,要求属性具有原子性,不可再分解。
举个例子,活动表(活动编码,活动名称,活动地址),假设这个场景中,活动地址可以细分为国家、省份、城市、市区、位置,那么就没有达到第一范式。
第二范式(2NF)第二范式,强调记录的唯一性约束,表必须有一个主键,并且没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
举个例子,版本表(版本编码,版本名称,产品编码,产品名称),其中主键是(版本编码,产品编码),这个场景中,数据库设计并不符合第二范式,因为产品名称只依赖于产品编码。
存在部分依赖。
所以,为了使其满足第二范式,可以改造成两个表:版本表(版本编码,产品编码)和产品表(产品编码,产品名称)。
第三范式(3NF)第三范式,强调属性冗余性的约束,即非主键列必须直接依赖于主键。
举个例子,订单表(订单编码,顾客编码,顾客名称),其中主键是(订单编码),这个场景中,顾客编码、顾客名称都完全依赖于主键,因此符合第二范式,但是顾客名称依赖于顾客编码,从而间接依赖于主键,所以不能满足第三范式。
为了使其满足第三范式,可以拆分两个表:订单表(订单编码,顾客编码)和顾客表(顾客编码,顾客名称),拆分后的数据库设计,就可以完全满足第三范式的要求了。
值得注意的是,第二范式的侧重点是非主键列是否完全依赖于主键,还是依赖于主键的一部分。
第三范式的侧重点是非主键列是直接依赖于主键,还是直接依赖于非主键列。
修正的第三范式(BCNF)修正的第三范式,是防止主键的某一列会依赖于主键的其他列。
举个例子,每个管理员只能管理一个仓库,那么如果设计库存表(仓库名,管理员名,商品名,数量),主键为(仓库名,管理员名,商品名),这是满足前面三个范式的,但是仓库名和管理员名之间存在依赖关系,因此删除某一个仓库,会导致管理员也被删除,因此设计不合理。
第四范式(4NF)当一个表中的非主属性相互独立时(3NF),这些非主属性不应该有多值。

数据库范式通俗讲解
数据库范式是一种设计数据库表结构的方法,旨在消除数据冗余并提高数据存储的效率。
通俗来讲,数据库范式就是一种规范,它告诉我们如何把数据存储在数据库中,以便更好地组织和管理数据。
数据库范式通常分为不同的级别,即第一范式(1NF)、第二范式(2NF)、第三范式(3NF)等。
每个级别都有其特定的规则和要求,用于确保数据库表的结构合理且数据不会重复存储。
第一范式要求每个数据表中的每一列都是不可再分的原子值,不可再分的意思是不能再分解为更小的数据单元。
这样可以避免数据冗余和复杂的数据结构。
第二范式要求数据表中的非主键列完全依赖于主键,即非主键列必须完全依赖于主键,而不是部分依赖。
这样可以确保数据表中的数据结构更加清晰和简洁。
第三范式要求数据表中的每一列都与主键直接相关,而不是与其他非主键列相关。
这样可以进一步减少数据冗余,提高数据的一
致性和完整性。
总的来说,数据库范式的目标是通过合理的数据表设计,减少数据冗余,提高数据存储和检索的效率,确保数据的一致性和完整性。
然而,有时候过度范式化也可能导致查询性能下降,因此在实际应用中需要根据具体情况进行权衡和调整。

数据库设计是指按照特定的规范和要求,对数据库的数据存储和管理进行规划和设计的过程。
数据库设计的三个范式是指数据库设计中的基本规范,其中第一范式(1NF)、第二范式(2NF)和第三范式(3NF)分别规定了数据库中的数据应该满足的标准和要求。
下面我们将简要介绍数据库设计的三个范式的含义。
一、第一范式(1NF)1. 第一范式是指数据库表中的所有字段都是不可再分的最小单元,即每个数据项都是不可再分的,不能再被分割为更小的数据项。
2. 数据库表中的每一列都是单一的值,不可再分。
3. 所有的字段都应该是原子性的,即不能再分。
4. 如果数据库表中的字段不满足第一范式的要求,就需要进行适当的调整和修改,使之满足第一范式的要求。
二、第二范式(2NF)1. 第二范式是指数据库表中的所有非主属性都完全依赖于全部主键。
2. 所谓主属性是指唯一标识一个记录的属性,而非主属性是指与主键相关的其他属性。
3. 如果一个表中的某些字段与主键没有直接关系,而是依赖于其他字段,则需要将这些字段拆分到另一个表中。
4. 通过将非主属性与主键分离,可以避免数据冗余和更新异常。
5. 第二范式要求数据库表中的数据项应该是唯一的,不可再分,且完全依赖于全部主键。
三、第三范式(3NF)1. 第三范式是指数据库表中的所有字段都不依赖于其他非主字段。
2. 也就是说,一个表中的字段之间应该相互独立,不应该存在字段之间的传递依赖关系。
3. 如果一个字段依赖于其他非主字段,则应该将其拆分到另一张表中,以避免数据冗余和更新异常。
4. 第三范式要求数据库表中的字段之间应该是独立的,不应该存在传递依赖关系。
数据库设计的三个范式分别规范了数据库表中数据的原子性、依赖性和独立性。
遵循这些范式可以有效地减少数据冗余和更新异常,提高数据库的数据完整性和稳定性。
在进行数据库设计时,设计人员应该严格遵循这些范式的要求,以确保数据库的高效性和可靠性。
众所周知,数据库设计的三个范式是设计和维护关系型数据库时非常重要的标准和指导原则。

数据库范式名词解释
数据库范式是数据库设计中的一种理论,它基于离散数学中的知识,主要为了解决数据存储和优化的问题。
其核心目标是为了减少数据冗余,提高数据的一致性和完整性。
范式包括六种,从低到高依次是:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
其中,满足最低要求的范式是第一范式(1NF)。
第一范式(1NF)要求在关系模型中,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合、数组、记录等非原子数据项。
如果实体中的某个属性有多个值时,必须拆分为不同的属性。
在符合第一范式(1NF)的表中,每个域值只能是实体的一个属性或一个属性的一部分。
简而言之,第一范式就是无重复的域。
数据库范式的主要作用是解决关系数据库中数据冗余、更新异常、插入异常、删除异常问题。
通过应用数据库范式,可以避免数据冗余,减少数据库的存储空间,并降低维护数据完整性的成本。
数据库范式是关系数据库核心的技术之一,也是从事数据库开发人员必备知识。

数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。
反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。
范式说明第一范式(1NF)无重复的列所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。
如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。
在第一范式(1NF)中表的每一行只包含一个实例的信息。
简而言之,第一范式就是无重复的列。
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
例如,如下的数据库表是符合第一范式的:字段1 字段2 字段3 字段4而这样的数据库表是不符合第一范式的:字段1 字段2 字段3 字段4字段字段数据库表中的字段都是单一属性的,不可再分。
这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。
很显然,在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。
因此,你想在现有的DBMS中设计出不符合第一范式的数据库都是不可能的。
第二范式(2NF)属性完全依赖于主键[ 消除部分子函数依赖]如果关系模式R为第一范式,并且R中每一个非主属性完全函数依赖于R的某个候选键,则称为第二范式模式。
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。
为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。

finalreport基因组数据格式介绍摘要:一、引言二、基因组数据格式概述1.基因组数据的基本组成2.常见的基因组数据格式三、FASTA 格式1.FASTA 格式的特点2.FASTA 格式的应用场景四、GenBank 格式1.GenBank 格式的特点2.GenBank 格式的应用场景五、FASTQ 格式1.FASTQ 格式的特点2.FASTQ 格式的应用场景六、SAM 格式1.SAM 格式的特点2.SAM 格式的应用场景七、BED 格式1.BED 格式的特点2.BED 格式的应用场景八、结论正文:一、引言随着基因组学研究的发展,基因组数据在生物信息学领域中占据越来越重要的地位。
对于这些庞大的基因组数据,我们需要一种合适的格式进行存储和传输。
本文将对基因组数据格式进行介绍,并重点分析几种常见的格式。
二、基因组数据格式概述基因组数据通常包括序列数据和注释信息。
序列数据可以是DNA、RNA 或蛋白质序列,而注释信息包括基因注释、转录因子结合位点、调控元件等。
为了方便存储和传输这些数据,科学家们制定了许多基因组数据格式。
三、FASTA 格式FASTA 格式是一种常用于表示核酸或蛋白质序列的文本格式。
它以简单的文本形式存储序列数据,易于阅读和编辑。
FASTA 格式的主要特点包括:每行包含一个序列,序列之间以空行分隔;序列中的碱基或氨基酸用单个字符表示;对于核酸序列,碱基T 在文件中用字母"U"表示。
FASTA 格式适用于序列数据的初稿存储和传输。
四、GenBank 格式GenBank 格式是一种二进制格式,主要用于存储基因组序列和相关的注释信息。
GenBank 文件通常包含多个序列,每个序列都由独立的记录组成。
每个记录包括序列标识符、物种信息、序列长度、核酸类型、存放位置等信息。
GenBank 格式适用于基因组数据的长期存储和分布式共享。
五、FASTQ 格式FASTQ 格式是一种用于表示高通量测序数据的文本格式。



Wind金融工程数据库数据字典目录1约定 (21)1.1文档说明 (21)1.1.1子库 (21)1.1.2表属性 (21)1.1.3字段属性 (21)1.2主要关联关系说明 (23)1.2.1公司、证券、个人ID->公司、证券、个人 (23)1.2.2交易代码->公司、证券ID (23)2数据库结构 (24)2.1.1证券列表 (24)2.1.1.1品种列表 (24)2.1.1.1.1证券(TB_OBJECT_1090) (24)2.1.1.1.2证券更名(TB_OBJECT_1091) (26)2.1.1.1.3特别处理(TB_OBJECT_1123) (27)2.1.1.1.4证券置换(TB_OBJECT_1401) (29)2.1.1.2公司列表 (30)2.1.1.2.1公司(TB_OBJECT_1018) (30)2.1.1.2.2公司更名(TB_OBJECT_1037) (35)2.1.1.2.3公司别名(TB_COM_COLLECTION) (36)2.1.1.3板块列表 (37)2.1.1.3.1板块(TB_OBJECT_1022) (37)2.1.1.3.2板块成份(TB_OBJECT_1400) (38)2.1.2股票 (39)精于数据一直进步I2.1.2.1股票交易数据 (39)2.1.2.1.1行情(TB_OBJECT_1120) (39)2.1.2.1.2复权行情(TB_OBJECT_1425) (42)2.1.2.1.3上市定价预测(TB_OBJECT_1114) (43)2.1.2.1.4交易日(TB_OBJECT_1010) (45)2.1.2.1.5证券交易异动营业部买卖信息(TB_OBJECT_1156) (45)2.1.2.2上市公司财务数据 (47)2.1.2.2.1审计意见(TB_OBJECT_1033) (47)2.1.2.2.2财务指标(TB_OBJECT_1039) (50)2.1.2.2.3资产负债表(非金融类)(TB_OBJECT_1040) (56)2.1.2.2.4资产负债表(金融类)(TB_OBJECT_1040) (65)2.1.2.2.5利润表(金融类)(TB_OBJECT_1070) (71)2.1.2.2.6利润表(非金融类)(TB_OBJECT_1070) (74)2.1.2.2.7现金流量表(金融类)(TB_OBJECT_1079) (78)2.1.2.2.8现金流量表(非金融类)(TB_OBJECT_1079) (89)2.1.2.2.9业绩预告(TB_OBJECT_1087) (101)2.1.2.2.10报告期内指标(TB_OBJECT_1129) (102)2.1.2.2.11公布重要指标(TB_OBJECT_1158) (105)2.1.2.2.12股东权益增减变动表(TB_OBJECT_1260) (107)2.1.2.2.13应交增值税明细表(TB_OBJECT_1261) (111)2.1.2.2.14资产减值准备明细表2(TB_OBJECT_1373) (113)2.1.2.3上市公司财务附注 (116)2.1.2.3.1财务附注(TB_OBJECT_1249) (116)2.1.2.3.2应收账款账龄结构(TB_OBJECT_1044) (117)2.1.2.3.3应收账款大股东欠款(TB_OBJECT_1253) (118)2.1.2.3.4主要应收账款明细(TB_OBJECT_1254) (120)精于数据一直进步II2.1.2.3.5税率明细(TB_OBJECT_1276) (121)2.1.2.3.6存货明细(TB_OBJECT_1274) (122)2.1.2.3.7资产减值准备明细表(TB_OBJECT_1259) (124)2.1.2.3.8资产减值准备明细表2(TB_OBJECT_1373) (126)2.1.2.4股票发行与分配 (129)2.1.2.4.1新股发行(TB_OBJECT_1095) (129)2.1.2.4.2增发(TB_OBJECT_1094) (135)2.1.2.4.3配股(TB_OBJECT_1092) (143)2.1.2.4.4分红(TB_OBJECT_1093) (148)2.1.2.4.5除权除息记录(TB_OBJECT_1427) (151)2.1.2.4.6法人投资者获配明细(TB_OBJECT_1150) (152)2.1.2.4.7募集资金(TB_OBJECT_1082) (154)2.1.2.4.8募集资金投向(TB_OBJECT_1083) (155)2.1.2.4.9募集资金投入说明(TB_OBJECT_1111) (158)2.1.2.4.10国有股配售(TB_OBJECT_1098) (159)2.1.2.5上市公司股权 (162)2.1.2.5.1股本(TB_OBJECT_1084) (162)2.1.2.5.2大股东(TB_OBJECT_1017) (165)2.1.2.5.3流通股东(TB_OBJECT_1450) (167)2.1.2.5.4股东户数(TB_OBJECT_1151) (168)2.1.2.5.5国有股减持(TB_OBJECT_1264) (169)2.1.2.6上市公司资本运作 (170)2.1.2.6.1控股参股(TB_OBJECT_1032) (170)2.1.2.6.2[内部]资产重组(TB_OBJECT_1122) (173)2.1.2.6.3资产托管(TB_OBJECT_1284) (174)2.1.2.6.4参股券商(TB_OBJECT_1088) (175)精于数据一直进步III2.1.2.7上市公司重大事项 (177)2.1.2.7.1股东大会通知(TB_OBJECT_1159) (177)2.1.2.7.2关联交易(TB_OBJECT_1031) (178)2.1.2.7.3诉讼(TB_OBJECT_1038) (180)2.1.2.7.4违规(TB_OBJECT_1124) (183)2.1.2.7.5[废弃]购销(TB_OBJECT_1279) (184)2.1.2.7.6[废弃]借贷(TB_OBJECT_1280) (185)2.1.2.7.7[废弃]代理(TB_OBJECT_1282) (186)2.1.2.7.8[废弃]租赁(TB_OBJECT_1286) (187)2.1.2.8上市公司高管 (188)2.1.2.8.1董事会届次(TB_OBJECT_1220) (188)2.1.2.8.2监事会届次(TB_OBJECT_1221) (189)2.1.2.8.3董事会成员(TB_OBJECT_1222) (191)2.1.2.8.4监事会成员(TB_OBJECT_1223) (192)2.1.2.8.5高管成员(TB_OBJECT_1224) (193)2.1.2.8.6管理层个人档案(TB_OBJECT_1219) (194)2.1.2.8.7管理层报酬及持股(TB_OBJECT_1225) (195)2.1.2.9上市公司公告、新闻、评述 (197)2.1.2.9.1公司文本信息(TB_OBJECT_1136) (197)2.1.2.9.2公告所属主题(MT_COL_TEXT) (199)2.1.2.10股票衍生数据 (200)2.1.2.10.1财务数据 (200)2.1.2.10.2行情指标 (200)2.1.2.10.3股东数据 (200)2.1.2.11股权分置 (200)2.1.2.11.1股权分置方案类型代码配置表(TB_OBJECT_1686) (200)精于数据一直进步IV2.1.2.11.2参与股权分置改革非流通股东(TB_OBJECT_1687) (201)2.1.2.11.3股权分置方案(TB_OBJECT_1673) (202)2.1.2.12财务数据(新准则) (202)2.1.2.12.1资产负债表(新准则)(TB_OBJECT_1853) (202)2.1.2.12.2利润表(新准则)(TB_OBJECT_1854) (202)2.1.2.12.3现金流量表(新准则)(TB_OBJECT_1855) (218)2.1.3基金 (227)2.1.3.1基金基本资料 (227)2.1.3.1.1基金基本资料和发行(TB_OBJECT_1099) (227)2.1.3.1.2基金经理(TB_OBJECT_1272) (235)2.1.3.1.3开放式基金费率表(TB_OBJECT_1521) (236)2.1.3.1.4LOF基本资料(TB_OBJECT_1535) (238)2.1.3.1.5ETF基金基本资料(TB_OBJECT_1604) (239)2.1.3.1.6ETF申购赎回基本信息(TB_OBJECT_1605) (240)2.1.3.1.7ETF申购赎回成分股信息(TB_OBJECT_1606) (241)2.1.3.2基金净值 (242)2.1.3.2.1基金净值(TB_OBJECT_1101) (242)2.1.3.2.2基金净值变动表(TB_OBJECT_1399) (244)2.1.3.2.3货币市场基金收益(TB_OBJECT_1449) (246)2.1.3.3基金投资组合 (247)2.1.3.3.1基金投资组合持仓明细(TB_OBJECT_1102) (247)2.1.3.3.2基金投资组合行业配置(TB_OBJECT_1103) (249)2.1.3.3.3基金投资组合资产配置(TB_OBJECT_1104) (251)2.1.3.3.4[废弃]基金新增股票(TB_OBJECT_1246) (254)2.1.3.3.5[废弃]基金投资组合剔除品种(TB_OBJECT_1247) (256)2.1.3.3.6基金席位交易(TB_OBJECT_1138) (258)精于数据一直进步V2.1.3.3.7基金持有流通受限证券明细(TB_OBJECT_1523) (260)2.1.3.3.8基金投资组合重大变动(TB_OBJECT_1532) (261)2.1.3.3.9货币市场基金投资组合剩余期限(TB_OBJECT_1565) (262)2.1.3.4封闭式基金交易数据 (263)2.1.3.4.1行情(TB_OBJECT_1120) (263)2.1.3.4.2复权行情(TB_OBJECT_1425) (266)2.1.3.4.3交易日(TB_OBJECT_1010) (267)2.1.3.5基金发行与分配 (268)2.1.3.5.1基金分红(TB_OBJECT_1245) (268)2.1.3.5.2基金扩募(TB_OBJECT_1176) (270)2.1.3.5.3除权除息记录(TB_OBJECT_1427) (274)2.1.3.6基金财务数据 (275)2.1.3.6.1基金资产负债表(TB_OBJECT_1126) (275)2.1.3.6.2基金利润表(TB_OBJECT_1127) (278)2.1.3.6.3基金财务指标(TB_OBJECT_1125) (282)2.1.3.6.4基金季报财务指标(TB_OBJECT_1496) (284)2.1.3.6.5基金净值表现(TB_OBJECT_1530) (286)2.1.3.7基金持有人 (287)2.1.3.7.1大股东(TB_OBJECT_1017) (287)2.1.3.7.2基金份额(TB_OBJECT_1115) (289)2.1.3.7.3基金关联方持有份额(TB_OBJECT_1100) (291)2.1.3.7.4基金申购与赎回情况(TB_OBJECT_1495) (292)2.1.3.7.5基金持有人结构及其它重要事项(TB_OBJECT_1533) (293)2.1.3.7.6ETF每周申购赎回数据(TB_OBJECT_1729) (294)2.1.3.8基金公告、新闻、评述 (295)2.1.3.8.1公司文本信息(TB_OBJECT_1136) (295)精于数据一直进步VI2.1.3.8.2公告所属主题(MT_COL_TEXT) (297)2.1.4权证 (298)2.1.4.1权证基本资料 (298)2.1.4.1.1权证基本资料(TB_OBJECT_1714) (298)2.1.4.1.2权证余额(TB_OBJECT_1715) (301)2.1.4.1.3权证行权价及比例(TB_OBJECT_1716) (302)2.1.4.1.4权证创设与注销明细(TB_OBJECT_1730) (302)2.1.4.1.5权证持有人(持有量超过5%)(TB_OBJECT_1731) (303)2.1.4.1.6权证创设与注销合计(TB_OBJECT_1732) (304)2.1.5债券 (305)2.1.5.1债券基本资料 (305)2.1.5.1.1债券基本资料(TB_OBJECT_1429) (305)2.1.5.1.2债券付息(TB_OBJECT_1270) (311)2.1.5.1.3除权除息记录(TB_OBJECT_1427) (313)2.1.5.2可转债基本资料 (314)2.1.5.2.1可转债发行(TB_OBJECT_1269) (314)2.1.5.2.2可转债转股(TB_OBJECT_1271) (320)2.1.5.2.3可转债持有人(TB_OBJECT_1394) (322)2.1.5.2.4可转债份额变动(TB_OBJECT_1395) (323)2.1.5.2.5可转债转股价格变动(TB_OBJECT_1477) (324)2.1.5.2.6转股价修正条件(TB_OBJECT_1595) (325)2.1.5.2.7转债回售赎回条款(TB_OBJECT_1596) (328)2.1.5.2.8转债有条件回售价格和触发比例(TB_OBJECT_1597) (331)2.1.5.2.9转债有条件回售触发比例(TB_OBJECT_1598) (332)2.1.5.2.10转债有条件赎回价格和触发比例(TB_OBJECT_1599) (333)2.1.5.2.11转债有条件赎回触发比例(TB_OBJECT_1600) (334)精于数据一直进步VII2.1.5.2.12转债实际利率(TB_OBJECT_1447) (334)2.1.5.3债券交易数据 (335)2.1.5.3.1行情(TB_OBJECT_1120) (335)2.1.5.3.2银行间债券市场现券行情(TB_OBJECT_1344) (338)2.1.5.3.3银行柜台债券行情(TB_OBJECT_1391) (339)2.1.5.3.4债券应计利息(TB_OBJECT_1387) (340)2.1.5.3.5交易日(TB_OBJECT_1010) (341)2.1.5.4回购交易数据 (342)2.1.5.4.1行情(TB_OBJECT_1120) (342)2.1.5.4.2银行间债券市场回购行情(TB_OBJECT_1343) (345)2.1.5.4.3回购标准券折算率(TB_OBJECT_1265) (346)2.1.5.4.4交易日(TB_OBJECT_1010) (347)2.1.5.5债券一级市场 (347)2.1.5.5.1国债发行预测(TB_OBJECT_1347) (347)2.1.5.5.2银行间债券市场承销团认购明细(TB_OBJECT_1346) (348)2.1.5.5.3[内部]浮动利率债券利率变动表(一级市场)(TB_OBJECT_1349) (350)2.1.5.5.4[内部]浮动利率债券利率变动表(二级市场)(TB_OBJECT_1350) (351)2.1.5.5.5[内部]债券发行(一级市场)(TB_OBJECT_1345) (352)2.1.5.5.6[内部]债券发行(一级市场)(TB_OBJECT_1348) (353)2.1.5.6公开市场业务 (356)2.1.5.6.1公开市场回购交易(TB_OBJECT_1441) (356)2.1.5.6.2公开市场现券交易(TB_OBJECT_1442) (356)2.1.5.6.3央行票据发行(TB_OBJECT_1435) (357)2.1.5.7债券公告、新闻、评述 (359)2.1.5.7.1公司文本信息(TB_OBJECT_1136) (359)2.1.5.7.2公告所属主题(MT_COL_TEXT) (361)精于数据一直进步VIII2.1.5.8资产证券化 (362)2.1.5.9信用评级 (362)2.1.5.10债券衍生数据 (362)2.1.6指数 (362)2.1.6.1指数基本资料 (362)2.1.6.1.1指数基本资料(TB_OBJECT_1289) (362)2.1.6.1.2指数成份(TB_OBJECT_1402) (363)2.1.6.2指数交易数据 (364)2.1.6.2.1行情(TB_OBJECT_1120) (364)2.1.6.2.2市场指数行情(TB_OBJECT_1288) (367)2.1.6.2.3交易日(TB_OBJECT_1010) (369)2.1.7期货 (370)2.1.7.1财经日历 (370)2.1.7.2期货基本资料 (370)2.1.7.3交割仓库资料 (370)2.1.7.4行情 (370)2.1.7.5会员 (370)2.1.8其他品种 (370)2.1.8.1贵金属基本资料 (370)2.1.8.2贵金属交易数据 (370)2.1.8.3外汇交易数据 (370)2.1.8.3.1人民币外汇牌价(TB_OBJECT_1233) (370)2.1.9宏观与区域经济数据 (372)2.1.9.1国内宏观数据 (372)2.1.9.1.1宏观经济重要指标 (372)2.1.9.1.1.1宏观经济(TB_OBJECT_1109) (372)精于数据一直进步IX2.1.9.1.2国民经济核算 (381)2.1.9.1.2.1国内生产总值(TB_OBJECT_1311) (381)2.1.9.1.2.2国内生产总值指数(TB_OBJECT_1312) (382)2.1.9.1.2.3支出法国内生产总值(TB_OBJECT_1313) (384)2.1.9.1.2.4收入法国内生产总值(TB_OBJECT_1314) (385)2.1.9.1.2.5国民经济核算(季)(TB_OBJECT_1315) (386)2.1.9.1.3工业生产与企业经营 (387)2.1.9.1.3.1工业生产(TB_OBJECT_1318) (387)2.1.9.1.3.2产品销售率(现价)(TB_OBJECT_1326) (389)2.1.9.1.3.3工业企业效益(TB_OBJECT_1319) (390)2.1.9.1.3.4工业(TB_OBJECT_1325) (391)2.1.9.1.3.5产品产量(TB_OBJECT_1327) (393)2.1.9.1.3.6重要物资(TB_OBJECT_1322) (394)2.1.9.1.4固定资产投资 (396)2.1.9.1.4.1按产业分固定资产投资完成额(TB_OBJECT_1323) (396)2.1.9.1.4.2按建设性质分固定资产投资完成额(TB_OBJECT_1375) (400)2.1.9.1.4.3按建设性质分基本建设投资完成额(TB_OBJECT_1376) (401)2.1.9.1.4.4按建设性质分更新改造投资完成额(TB_OBJECT_1377) (402)2.1.9.1.4.5固定资产投资资金来源(TB_OBJECT_1378) (402)2.1.9.1.4.6基本建设投资资金来源(TB_OBJECT_1379) (403)2.1.9.1.4.7更新改造投资资金来源(TB_OBJECT_1380) (405)2.1.9.1.4.8房地产开发投资资金来源(TB_OBJECT_1381) (406)2.1.9.1.4.9按工程用途分的房地产投资完成额(TB_OBJECT_1382) (407)2.1.9.1.4.10房地产开发、销售面积(TB_OBJECT_1383) (408)2.1.9.1.4.11建筑业(TB_OBJECT_1328) (409)2.1.9.1.4.12房地产开发(TB_OBJECT_1292) (411)精于数据一直进步X2.1.9.1.5对外贸易及投资 (412)2.1.9.1.5.1海关进出口贸易(TB_OBJECT_1293) (412)2.1.9.1.5.2海关进出口商品贸易方式总值(按贸易方式分)(TB_OBJECT_1294) (413)2.1.9.1.5.3海关出口商品贸易方式总值(按贸易方式分)(TB_OBJECT_1295) (415)2.1.9.1.5.4海关进口商品贸易方式总值(按贸易方式分)(TB_OBJECT_1296) (416)2.1.9.1.5.5对外贸易和旅游(TB_OBJECT_1338) (418)2.1.9.1.6物价指数 (420)2.1.9.1.6.1消费和零售价格指数(TB_OBJECT_1298) (420)2.1.9.1.6.2城市居民消费价格分类指数(TB_OBJECT_1300) (421)2.1.9.1.6.3城市商品零售价格分类指数(TB_OBJECT_1301) (422)2.1.9.1.6.4农村商品零售价格分类指数(TB_OBJECT_1302) (423)2.1.9.1.6.5居民消费价格分类指数(TB_OBJECT_1299) (424)2.1.9.1.6.6农村居民消费价格分类指数(TB_OBJECT_1303) (425)2.1.9.1.6.7工业品出厂价格指数(按大类分)(TB_OBJECT_1304) (425)2.1.9.1.6.8工业品出厂价格指数(按工业部门分)(TB_OBJECT_1305) (426)2.1.9.1.6.9工业品出厂价格指数(按行业分)(TB_OBJECT_1306) (427)2.1.9.1.6.10原材料、燃料、动力购进价格指数(TB_OBJECT_1307) (428)2.1.9.1.6.11全国房地产销售价格指数(TB_OBJECT_1308) (429)2.1.9.1.6.12全国房地产租赁价格指数(TB_OBJECT_1309) (430)2.1.9.1.6.13全国土地交易价格指数(TB_OBJECT_1310) (431)2.1.9.1.7工资与就业 (432)2.1.9.1.7.1[废弃]就业和职工工资(TB_OBJECT_1316) (432)2.1.9.1.8运输邮电 (433)2.1.9.1.8.1交通运输(TB_OBJECT_1320) (433)2.1.9.1.8.2铁路营业里程(TB_OBJECT_1329) (434)2.1.9.1.8.3客运量(TB_OBJECT_1330) (435)精于数据一直进步XI2.1.9.1.8.4货运量(TB_OBJECT_1331) (437)2.1.9.1.8.5旅客周转量(TB_OBJECT_1332) (438)2.1.9.1.8.6货物周转量(TB_OBJECT_1333) (440)2.1.9.1.8.7民用汽车拥有量(TB_OBJECT_1334) (441)2.1.9.1.8.8邮电业务量(TB_OBJECT_1335) (442)2.1.9.1.8.9电话用户数量及电话机拥有量(TB_OBJECT_1336) (443)2.1.9.1.9能源 (444)2.1.9.1.9.1能源生产(TB_OBJECT_1321) (444)2.1.9.1.10国内贸易 (445)2.1.9.1.10.1消费品零售(TB_OBJECT_1297) (445)2.1.9.1.10.2消费品零售总额(TB_OBJECT_1337) (447)2.1.9.1.11财政 (448)2.1.9.1.11.1财政收支(TB_OBJECT_1361) (448)2.1.9.1.12银行与货币 (450)2.1.9.1.12.1货币供应(TB_OBJECT_1363) (450)2.1.9.1.12.2货币概览(TB_OBJECT_1370) (452)2.1.9.1.12.3金融机构资金来源(人民币)(TB_OBJECT_1364) (453)2.1.9.1.12.4国家银行资金来源(人民币)(TB_OBJECT_1365) (455)2.1.9.1.12.5金融机构资金运用(人民币)(TB_OBJECT_1366) (458)2.1.9.1.12.6国家银行资金运用(人民币)(TB_OBJECT_1367) (461)2.1.9.1.12.7金融机构现金收入(TB_OBJECT_1368) (464)2.1.9.1.12.8金融机构现金支出(TB_OBJECT_1369) (466)2.1.9.1.12.9外汇概览(TB_OBJECT_1359) (467)2.1.9.1.12.10汇率、外汇(期末数)(TB_OBJECT_1362) (468)2.1.9.1.12.11同业拆借交易情况(TB_OBJECT_1360) (469)2.1.9.1.13利率 (470)精于数据一直进步XII2.1.9.1.13.1法定贷款利率(TB_OBJECT_1256) (470)2.1.9.1.13.2法定存款利率(TB_OBJECT_1255) (471)2.1.9.1.14证券 (473)2.1.9.1.14.1沪深市场总体指标(TB_OBJECT_1422) (473)2.1.9.1.15人民生活 (475)2.1.9.1.16景气指数 (475)2.1.9.1.17旅游 (475)2.1.9.2国内区域宏观数据 (475)2.1.9.2.1工业生产与企业效益 (475)2.1.9.2.1.1工业生产(地区)(TB_OBJECT_1351) (475)2.1.9.2.1.2工业企业效益(地区)(TB_OBJECT_1352) (477)2.1.9.2.2固定资产投资 (481)2.1.9.2.2.1固定资产投资(地区)(TB_OBJECT_1353) (481)2.1.9.2.2.2房地产开发(地区)(TB_OBJECT_1354) (483)2.1.9.2.3对外贸易与投资 (487)2.1.9.2.3.1对外贸易(地区)(TB_OBJECT_1356) (487)2.1.9.2.4物价指数 (490)2.1.9.2.4.1消费与物价(地区)(TB_OBJECT_1357) (490)2.1.9.2.5工资与就业 (492)2.1.9.2.5.1工资与就业(地区)(TB_OBJECT_1358) (492)2.1.9.2.6农业生产 (494)2.1.9.2.7国内贸易 (494)2.1.9.2.8财政 (494)2.1.9.2.8.1财政金融(地区)(TB_OBJECT_1355) (494)2.1.9.2.9人民生活 (496)2.1.9.2.10国民经济核算 (496)精于数据一直进步XIII2.1.9.3港澳台地区宏观数据 (496)2.1.9.4国际宏观数据 (496)2.1.9.4.1各国宏观数据(统计年鉴) (496)2.1.9.4.2利率及债券 (496)2.1.9.4.2.1美国债券期限结构(TB_OBJECT_1341) (496)2.1.9.4.3OECD宏观数据 (498)2.1.9.5其他 (498)2.1.10行业数据 (498)2.1.10.1化工行业数据 (498)2.1.10.2汽车行业数据 (498)2.1.10.3其他行业数据 (498)2.1.10.4房地产行业数据 (498)2.1.10.5钢铁行业数据 (498)2.1.10.6煤炭行业数据 (498)2.1.10.7纺织行业数据 (498)2.1.10.8有色金属行业数据 (498)2.1.10.9行业财务指标 (498)2.1.10.9.1各行业财务指标(TB_OBJECT_1339) (498)2.1.10.10农业行业数据 (502)2.1.10.10.1农业(TB_OBJECT_1324) (502)2.1.10.11港口行业数据 (505)2.1.10.12行业综合数据 (505)2.1.11金融机构研究 (505)2.1.11.1金融机构基本资料 (505)2.1.11.2金融机构股权 (505)2.1.11.2.1券商增资扩股(TB_OBJECT_1119) (505)精于数据一直进步XIV2.1.11.3金融机构财务数据 (506)2.1.11.4QFII专题 (506)2.1.11.4.1QFII基本资料(TB_OBJECT_1444) (506)2.1.11.4.2QFII投资额度变动(TB_OBJECT_1445) (508)2.1.11.5集合理财 (509)2.1.11.6社保基金 (509)2.1.12新闻法规 (509)2.1.12.1财经新闻 (509)2.1.12.1.1普通文本信息(TB_OBJECT_1135) (509)2.1.12.1.2财经信息栏目(TB_OBJECT_1142) (511)2.1.12.1.3中国金融市场大事记(TB_OBJECT_1063) (512)2.1.12.2财经法规 (513)2.1.12.2.1普通文本信息(TB_OBJECT_1135) (513)2.1.12.2.2财经信息栏目(TB_OBJECT_1142) (514)2.1.13网站F10专用 (515)2.1.13.1个股资料文本信息(TB_OBJECT_1149) (515)2.1.14手机短信专用 (517)2.1.14.1手机短信公告提示(TB_OBJECT_1393) (517)2.1.15第三方数据 (517)2.1.15.1[内部]Wind行业成份明细(TB_OBJECT_1576) (517)2.1.16评级、预测和研究报告 (518)2.1.17咨询 (518)2.1.18代码配置 (518)2.1.18.1布尔代码表(TB_OBJECT_1001) (518)2.1.18.2个人代码表(TB_OBJECT_1014) (519)2.1.18.3中介机构从业人员代码表(TB_OBJECT_1016) (520)精于数据一直进步XV2.1.18.4券商代码表(TB_OBJECT_1020) (521)2.1.18.5中介机构代码表(TB_OBJECT_1021) (522)2.1.18.6货币代码表(TB_OBJECT_1023) (523)2.1.18.7证券类型代码表(TB_OBJECT_1024) (524)2.1.18.8股本性质代码表(TB_OBJECT_1025) (524)2.1.18.9股本变动原因代码表(TB_OBJECT_1143) (525)2.1.18.10关联关系代码表(TB_OBJECT_1144) (526)2.1.18.11审计结果类型代码表(TB_OBJECT_1145) (526)2.1.18.12公司类型代码表(TB_OBJECT_1180) (527)2.1.18.13增发类型代码表(TB_OBJECT_1193) (528)2.1.18.14特别处理类型代码表(TB_OBJECT_1201) (528)2.1.18.15方案进度代码表(TB_OBJECT_1214) (529)2.1.18.16性别代码表(TB_OBJECT_1228) (530)2.1.18.17财务附注项目代码表(TB_OBJECT_1248) (530)2.1.18.18产品状态代码表(TB_OBJECT_1252) (531)2.1.18.19存贷款品种代码表(TB_OBJECT_1257) (532)2.1.18.20公司交易类型代码表(TB_OBJECT_1266) (533)2.1.18.21国有股减持方式代码表(TB_OBJECT_1267) (533)2.1.18.22债券期限代码表(TB_OBJECT_1342) (533)2.1.18.23宏观经济项目代码表(TB_OBJECT_1372) (534)2.1.18.24资产减值准备明细表2类别代码表(TB_OBJECT_1374) (535)2.1.18.25证券交易状态代码表(TB_OBJECT_1388) (536)2.1.18.26有效申购类型代码表(TB_OBJECT_1389) (536)2.1.18.27回拨方向代码表(TB_OBJECT_1390) (537)2.1.18.28柜台债券交易银行代码表(TB_OBJECT_1392) (538)2.1.18.29可转债份额变动原因代码表(TB_OBJECT_1396) (538)精于数据一直进步XVI2.1.18.30基金净值表现期间代码配置表(TB_OBJECT_1531) (538)2.1.19情报站 (539)2.1.20媒体版 (539)2.1.21外部客户定制表 (539)2.1.22控股参股 (539)2.2其他 (539)2.2.1[内部]上市公司代码表(TB_OBJECT_1019) (539)2.2.2[废弃]中介机构类型代码表(TB_OBJECT_1029) (540)2.2.3[内部]债转股(TB_OBJECT_1086) (540)2.2.4[内部]参与生物(TB_OBJECT_1089) (542)2.2.5[内部]参与网络(TB_OBJECT_1118) (543)2.2.6[废弃]关键字代码配置表(TB_OBJECT_1128) (544)2.2.7[内部]股评(TB_OBJECT_1130) (545)2.2.8[内部]停牌提示信息(TB_OBJECT_1137) (546)2.2.9[内部]国债发行(TB_OBJECT_1140) (547)2.2.10[内部]企债发行(TB_OBJECT_1141) (550)2.2.11[废弃]募集资金途径代码表(TB_OBJECT_1146) (554)2.2.12[内部]基金投资方式代码表(TB_OBJECT_1152) (555)2.2.13[废弃]投资记录表(TB_OBJECT_1154) (556)2.2.14[废弃]更新操作任务表(TB_OBJECT_1155) (557)2.2.15[内部]涨跌幅前五名统计(TB_OBJECT_1157) (558)2.2.16[内部]今日特别提示(TB_OBJECT_1174) (559)2.2.17公司类别代码(TB_OBJECT_1179) (560)2.2.18[内部]支付方式配置表(TB_OBJECT_1181) (561)2.2.19[内部]交易方式配置表(TB_OBJECT_1182) (562)2.2.20[内部]财务报表类型配置表(TB_OBJECT_1183) (562)精于数据一直进步XVII2.2.21[内部]诉讼类型配置表(TB_OBJECT_1184) (563)2.2.22[内部]交易所配置表(TB_OBJECT_1186) (564)2.2.23[内部]上市板配置表(TB_OBJECT_1187) (564)2.2.24[内部]配股方式配置表(TB_OBJECT_1188) (565)2.2.25[内部]分配对象配置表(TB_OBJECT_1189) (565)2.2.26[内部]配股认购方式配置表(TB_OBJECT_1190) (566)2.2.27[内部]承销方式配置表(TB_OBJECT_1191) (567)2.2.28[内部]发行方式配置表(TB_OBJECT_1192) (567)2.2.29[内部]发行对象配置表(TB_OBJECT_1194) (568)2.2.30[内部]基金类型配置表(TB_OBJECT_1195) (569)2.2.31[内部]资产重组类型配置表(TB_OBJECT_1197) (569)2.2.32[内部]特别处理原因配置表(TB_OBJECT_1198) (570)2.2.33[内部]报告期内指标变动原因配置表(TB_OBJECT_1199) (571)2.2.34[内部]停牌期限配置表(TB_OBJECT_1200) (571)2.2.35[内部]券商与基金关联关系配置表(TB_OBJECT_1202) (572)2.2.36[废弃]债券发行人配置表(TB_OBJECT_1203) (572)2.2.37[内部]利率类型配置表(TB_OBJECT_1204) (573)2.2.38[内部]计息方式配置表(TB_OBJECT_1206) (574)2.2.39[内部]债券偿付方式配置表(TB_OBJECT_1207) (574)2.2.40[内部]债券形式配置表(TB_OBJECT_1208) (575)2.2.41[内部]付息方式配置表(TB_OBJECT_1209) (576)2.2.42[内部]信用评级配置表(TB_OBJECT_1210) (576)2.2.43[内部]担保方式配置表(TB_OBJECT_1211) (577)2.2.44[内部]法人投资者类型配置表(TB_OBJECT_1212) (577)2.2.45[内部]股东大会类型配置表(TB_OBJECT_1213) (578)2.2.46[内部]参与网络类型配置表(TB_OBJECT_1217) (579)精于数据一直进步XVIII2.2.47[内部]学历配置表(TB_OBJECT_1229) (579)2.2.48[内部]国家配置表(TB_OBJECT_1230) (580)2.2.49[内部]职务配置表(TB_OBJECT_1231) (581)2.2.50[内部]持股数量变动原因配置表(TB_OBJECT_1232) (581)2.2.51[内部]历史交易所会员总交易量排名(TB_OBJECT_1234) (582)2.2.52[内部]历史交易所会员交易量排名-股票基金(TB_OBJECT_1235) (583)2.2.53[内部]历史交易所会员交易量排名-债券(TB_OBJECT_1236) (584)2.2.54[内部]历史证券发行筹资综合统计(TB_OBJECT_1237) (585)2.2.55[内部]历史交易地区分布(TB_OBJECT_1240) (586)2.2.56[内部]历史深市月度概况(TB_OBJECT_1241) (587)2.2.57[内部]历史沪市月度概况(TB_OBJECT_1242) (588)2.2.58公司产品(TB_OBJECT_1250) (589)2.2.59[内部]产品名录配置表(TB_OBJECT_1251) (591)2.2.60交易(TB_OBJECT_1262) (591)2.2.61[内部]股权转让(TB_OBJECT_1263) (595)2.2.62板块栏目对照表(TB_OBJECT_1273) (596)2.2.63[废弃]存货项目配置表(TB_OBJECT_1275) (597)2.2.64[内部]资产剥离(TB_OBJECT_1277) (598)2.2.65[内部]收购兼并(TB_OBJECT_1278) (599)2.2.66[内部]担保(TB_OBJECT_1281) (599)2.2.67[内部]资产置换(TB_OBJECT_1283) (600)2.2.68[内部]资产交易(TB_OBJECT_1285) (601)2.2.69发起成立(TB_OBJECT_1287) (602)2.2.70人民生活(TB_OBJECT_1317) (603)2.2.71[内部]业绩预告类型(TB_OBJECT_1412) (604)精于数据一直进步XIX精于数据一直进步XX1约定1.1文档说明分子库、表属性和字段属性三层描述数据库。
ndba结构式
ndba结构式是一种常用于描述数据库设计的模式。
它由四个主要组成部分组成,分别是命名实体、定义属性、建立关系和确立约束。
通过这种结构式的设计方法,可以清晰地描述数据库中的各个实体及其之间的联系,从而提高数据库的可读性和可维护性。
在ndba结构式中,命名实体是指数据库中的各个实体,可以是具体的事物或抽象的概念。
每个实体都有一个唯一的标识符,用于在数据库中进行区分。
比如,在一个图书管理系统中,可以定义图书、读者、作者等实体。
在定义属性的过程中,需要确定每个实体的属性,即实体所包含的信息。
属性可以是实体的特征或描述,比如图书的书名、作者的姓名等。
每个属性都有一个数据类型,用于确定属性的取值范围。
此外,还可以为属性定义其他约束条件,比如唯一性约束、非空约束等。
建立关系是ndba结构式的核心部分。
通过建立关系,可以描述实体之间的联系和依赖关系。
在数据库中,关系可以分为一对一关系、一对多关系和多对多关系等。
通过建立关系,可以更好地组织和管理数据库中的信息。
在确立约束的过程中,需要定义数据库中的各种约束条件,以保证数据的完整性和一致性。
常见的约束条件包括主键约束、外键约束、
唯一性约束、非空约束等。
这些约束条件可以限制数据的输入和更新,从而保证数据库的数据质量。
总结来说,ndba结构式是一种用于描述数据库设计的模式,通过命名实体、定义属性、建立关系和确立约束这四个步骤,可以清晰地描述数据库中的各个实体及其之间的联系。
这种设计方法可以提高数据库的可读性和可维护性,从而更好地满足用户的需求。
2范式的概念第二范式(Second Normal Form,2NF)是关系数据库设计中的一个重要概念。
它是在第一范式(1NF)的基础上进一步规范化数据库模型,以降低数据冗余和保证数据结构的正确性。
在理解第二范式之前,让我们先回顾一下第一范式。
第一范式要求数据库中的每个数据格都是不可再分解的原子值,即不含有重复和组合的数据。
这意味着每个实体在一个关系表中只能出现一次,且表中的每个字段都是原子的。
然而,即使遵循第一范式,数据库模型仍然可能存在一些问题。
第二范式旨在解决以下两个问题:数据冗余和数据部分依赖。
数据冗余是指在数据库中重复存储相同的信息,这样会导致存储空间的浪费和数据的不一致性。
数据部分依赖是指一个多属性的关系表中,某些字段只依赖于关键字(主键)的一部分,这样会导致数据的不完整和冗余。
为了符合第二范式的要求,需要满足以下两个条件:1. 关系表必须符合第一范式。
2. 数据表中的非关键字字段必须完全依赖于关键字。
为了更好地理解第二范式,让我们通过一个例子来说明。
假设我们有一个数据库表格,用于记录学生的成绩信息。
表格的结构如下:学生表(Student):学生ID 学生姓名课程分数001 张三语文80002 李四数学90001 张三数学85这个例子中,学生ID和课程构成了学生表的关键字,其他字段为非关键字字段。
现在我们来分析这个表格是否满足第二范式。
首先,我们检查表格是否符合第一范式。
由于每个数据格都是原子的,学生表满足第一范式的要求。
然后,我们检查非关键字字段是否完全依赖于关键字。
在学生表中,分数字段只依赖于学生ID和课程这两个关键字。
然而,学生姓名字段只依赖于学生ID,而与课程无关。
这导致了数据的不完整和冗余。
为了符合第二范式,我们可以对学生表进行进一步规范化。
我们可以将学生姓名和学生ID分离出来,建立一个学生信息表。
然后,在学生表中只保存学生ID和课程以及分数。
修改后的表格如下:学生信息表(Student_Info):学生ID 学生姓名001 张三002 李四学生成绩表(Student_Grade):学生ID 课程分数001 语文80002 数学90001 数学85通过这样的改变,我们解决了数据的不完整和冗余问题。
数据库三范式解释-概述说明以及解释1.引言1.1 概述在数据库设计中,三范式是指关系数据库中的数据规范化的一种理论。
它是为了解决数据冗余和数据更新异常而提出的一种设计原则。
通过将数据分解成多个表,并确保每个表都符合一定的规范,可以有效地减少数据冗余,提高数据的一致性和完整性。
三范式包括第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。
每个范式都有其特定的规范要求,通过逐步满足这些要求,可以确保数据库设计得到最优化的结构。
在本文中,我们将对三范式进行详细解释,并探讨其在数据库设计中的应用和局限性。
通过本文的阅读,读者将能够更加深入地理解数据库三范式,并在实际工作中更好地运用它们。
1.2 文章结构文章结构部分主要是讲述整篇长文的结构和内容安排。
在本篇长文中,我们将首先介绍数据库三范式的概念及其重要性(引言部分),然后详细解释第一范式、第二范式和第三范式的含义和原理(正文部分),最后总结三范式的应用和局限性(结论部分)。
通过这样的结构,读者可以系统地了解数据库三范式的概念和应用,为其在实际工作中的应用提供理论支持和指导。
1.3 目的数据库三范式是设计关系型数据库的重要原则,其目的在于消除数据冗余和数据插入、更新和删除异常,使数据库结构更加规范化和高效。
本文旨在深入解释数据库三范式的概念,帮助读者了解每个范式的特点和应用场景。
通过本文的阐述,读者可以更好地应用三范式原则来设计和规划数据库结构,从而提高数据库的性能和可维护性。
同时,也可以帮助读者理解三范式在实际数据库设计中的局限性和不足之处,以便在设计数据库时做出更明智的决策。
通过对数据库三范式的深入理解,读者可以更好地应用这一原则来设计规范化的数据库结构,避免常见的数据库设计问题,提高数据的一致性和完整性,从而为企业和个人提供更加可靠和高效的数据管理和应用服务。
2.正文2.1 第一范式第一范式是关系数据库设计中的基本原则,指的是每个列都是原子性的,不可再分。
数据库第四范式一、什么是数据库第四范式1.1 第四范式的概念在数据库理论中,关系数据库设计的规范是由不同的范式来定义的,分别包括第一范式(1NF)、第二范式(2NF)、第三范式(3NF)以及第四范式(4NF)。
第四范式是在前三个范式的基础上进行的进一步优化和规范。
1.2 第四范式的目标第四范式的目标是要避免数据冗余和数据传递依赖,以提高数据库的完整性和性能。
它通过对原始数据表的分解,消除多值依赖和联合依赖,使得数据处理更加高效和精确。
二、第四范式的优势2.1 数据库结构的优化第四范式的设计可以消除冗余数据和多值依赖,对数据库结构进行了优化。
通过彻底解决各种数据依赖关系,可以减少数据存储空间,提高数据库的性能和响应速度。
2.2 数据一致性的保障第四范式的设计可以提高数据一致性的保障。
通过将关联的数据分离到不同的表中,可以确保数据的一致性和完整性。
任何对数据的更新操作都会被正确地应用到相应的表中,避免了数据冲突和不一致的情况。
2.3 数据处理的准确性第四范式的设计可以提高数据处理的准确性。
通过消除冗余和依赖,可以避免数据传递错误导致的数据处理错误。
数据的更新和查询操作都可以更加精确地进行,减少了数据处理的错误率。
三、第四范式的实现方法3.1 分解表结构第四范式的实现方法之一是对原始表结构进行分解。
根据多值依赖和联合依赖的规则,将原始表拆分成多个表,并建立相应的关联关系。
通过分解表结构,可以消除数据冗余,提高数据库性能。
3.2 建立关联关系在拆分表结构的同时,还需要建立相应的关联关系。
通过主键和外键的关联,确保数据的一致性和完整性。
在进行数据更新和查询操作时,需要同时更新和查询相关的表,以保证数据的准确性。
3.3 设计联合查询语句第四范式的实现还需要设计相应的联合查询语句。
通过联合查询可以将相关的表进行关联,并在查询时获取所需的数据。
联合查询语句的设计需要根据具体的业务需求和表关系来确定,以达到高效和准确的数据处理。
数据库三个范式的定义
关系数据库设计中的三个范式是一组规范,用于确保数据库表的结构是高度规范化的,以减少数据冗余、提高数据完整性和减少数据插入、更新和删除操作的异常。
这三个范式通常称为第一范式、第二范式和第三范式。
以下是它们的定义:
1. 第一范式(1NF):一个关系被认为是在第一范式下,如果它满足以下条件:
•每个表中的所有列都是不可再分的原子值,即每个列不再包含多个值。
•表中的每一行都必须具有唯一的标识符,通常是一个主键。
第一范式确保了数据的原子性,防止将多个值存储在单个列中。
2. 第二范式(2NF):一个关系在第二范式下,需要满足以下条件:
•必须符合第一范式。
•所有非主键列必须完全依赖于整个主键,而不是仅依赖于主键的一部分。
第二范式消除了部分依赖,确保每个非主键列都与整个主键相关。
3. 第三范式(3NF):一个关系在第三范式下,需要满足以下条件:
•必须符合第二范式。
•任何非主键列之间不能存在传递依赖关系。
如果非主键列A依赖于非主键列B,而非主键列B依赖于主键列,那么这是一个传递依赖。
第三范式消除了传递依赖,确保每个非主键列只依赖于主键。
遵循这三个范式有助于数据库设计中的规范化,以减少数据冗余并确保数据的一致性和完整性。
然而,在某些情况下,为了性能或其他原因,可能会选择部分冗余数据或放宽规范化要求。
在设计数据库时,需要权衡规范化和性能之间的需求。