医学统计题目
- 格式:doc
- 大小:170.00 KB
- 文档页数:8

医学统计学考试题医学统计学是研究医学领域中各类数据的收集、整理、分析和解释的一门学科。
医学统计学的应用范围广泛,可以帮助医生和研究人员更好地理解和利用医学数据,以提高医疗和研究工作的效果。
以下是一些医学统计学考试题,供大家参考。
1. 病例-对照研究是一种常见的流行病学研究设计,它的特点是什么?请简要解释。
病例-对照研究是一种回顾性研究设计,通过比较一组病例和一组对照组之间的暴露情况,来探究暴露因素与疾病的关联性。
其特点包括:病例组和对照组是在时间上是一致的,选择上是独立的;回顾性收集病例组和对照组的暴露信息;通过计算比值比或者比例比来评估风险因素。
2. 请解释以下术语:敏感性、特异性和阳性预测值。
敏感性是指测试检测到的真阳性个体占所有实际阳性个体的比例,用于评估测试的准确性。
特异性是指测试检测到的真阴性个体占所有实际阴性个体的比例,同样也用于评估测试的准确性。
阳性预测值是指测试结果为阳性的个体中,真阳性个体占所有测试为阳性个体的比例,该指标可以帮助评估患病风险。
3. 请解释以下术语:标准差、标准误差和置信区间。
标准差是用来衡量一组数据的离散程度的指标,计算标准差可以帮助评估数据的变异性。
标准误差是指对样本均值估计的不确定性,在统计学中用来评估样本均值与总体均值之间的接近程度。
置信区间是通过对样本数据进行统计推断,给出一个范围,其中有一定概率(通常为95%)包含着总体参数的真值。
置信区间可以帮助我们对总体参数进行估计。
4. 解释以下术语:相关系数和回归分析。
相关系数用于衡量两个变量之间的线性关系强度和方向。
常见的相关系数有Pearson相关系数和Spearman等级相关系数。
回归分析用于探究一个或多个自变量与因变量之间的关系。
通过建立一个回归模型,可以预测因变量的数值,并评估自变量对因变量的影响程度。
5. 请解释以下概念:生存分析和危险比。
生存分析是一种用于研究时间至事件发生之间关系的方法,常用于分析患者生存时间的影响因素。

第一章绪论1.医学统计研究的对象是()A.医学中的小概率事件B. 各种类型的数据C. 动物和人的本质D. 有变异的医学事物E. 疾病的预防和治疗2.用样本推论整体,具有代表性的样本通常是指()A.总体中最容易获得的部分个体B. 在总体中随意抽取的任意个体C. 挑选总体中的具有代表性的部分个体D. 用方法抽取的部分个体E. 依照随机原则抽取总体中的部分个体3.下列观测结果属于有序数据的是()A. 收缩压测量值B. 脉搏数C. 住院天数D. 病情程度E. 四种血型4.随机测量误差是指()A.由某些固定因素引起的误差B. 由不可预知的偶然因素引起的误差C. 选择样本不当引起的误差D. 选择总体不当引起的误差E. 由操作失误引起的误差5.系统误差是指()A.由某些固定的因素引起的误差B. 由操作失误引起的误差C. 选择样本不当引起的误差D. 样本统计量与总体参数之间的误差E. 由不可预知的偶然因素引起的误差6.抽样误差是指()A.由某些固定因素引起的误差B. 由操作失误引起的误差C. 选择样本不当引起的误差D. 样本统计量与总体参数之间的误差E. 由不可预知的偶然因素引起的误差7.收集数据不可避免的误差是()A. 随机误差B. 系统误差C. 过失误差D. 记录误差E. 仪器故障误差8.统计学中所谓的总体通常是指()A.自然界中的所有研究对象B. 概括性的研究结果C. 同质观察单位的全体D. 所有的观察数据E. 具有代表性意义的数据9.统计学中所谓的样本通常是指()A.自然界中所有的研究对象B. 概括性的研究结果C. 某一变量的测量值D. 数据中有代表性的一部分E. 总体中具有代表性的部分观察单位10.医学研究中抽样误差的主要来源是()A.测量仪器不够准确B. 检测出现错误C. 统计设计不合理D. 生物个体的变异E. 样本量不够第二章定量数据的统计描述1.某医学资料数据大的一端没有确定数值描述其集中趋势适用的统计指标是()百分位数 E. 频数分布A. 中位数B. 几何均数C. 均数D. P952.算数均数与中位数相比,其特点是()A.不易受极端值的影响B. 能充分利用数据的信息C. 抽样误差极大D. 更适用于偏态分布资料E. 更适用于分布不明确资料3.将一组计量资料整理成频数表的主要目的是()A.化为计数资料B. 能充分利用数据信息C. 提供原始资料D. 能够能精确的检验E. 描述数据的分布特征4.6人接种流感疫苗一个月后测定抗体滴度为1:20、1:40、1:80、1:80、1:160、1:320,求品均滴度应选用的指标是()A. 均数B. 几何均数C. 中位数D. 百分位数E. 倒数的均数5.变异系数主要用于()A.比较不同变异指标的变异程度B. 衡量正态分布的变异程度C. 衡量测量的准确度D. 衡量偏态分布的变异程度E. 衡量样本抽样误差的大小6.对于正态或近似正态分布的资料,描述其变异程度应选用的指标是()A. 变异系数B. 离均差平方和C. 极差D. 四分位数间距E. 标准差7.已知动脉硬化患者载脂蛋白B的含量(mg/dl)呈明显偏态分布,描述其个体差异的统计指标应使用()A. 全距B. 标准差C. 变异系数D. 方差E. 四分位数间距8.一组原始数据的分布呈正偏态分布,其数据的特点是()A.数值离散度大B. 数值离散度小C. 数值偏向较大的方向D. 数值偏向较小的方向E. 数值分布不均9.对于正偏态分布总体,其均数与中位数的关系是()A.均数与中位数相同B. 均数大于中位数C. 均数小于中位数D. 两者有一定的数量关系E. 两者的数量关系不确定10.在衡量数据的变异度时,标准差与方差相比,其主要特点是()A.标准差小与方差B. 标准差大于方差C. 标准差更容易计算D. 标准差更为准确E. 标准差的计量单位与原始数据相同第三章正态分布与医学参考值范围1.正态曲线下,横轴上从均数到+∞的面积为()A. 50%B. 95%C. 97.5%D. 99%E. 不能确定(与标准差的大小有关)2.标准正态分布的形状参数和位置参数分别是()A. 0,1B. 1,0C. μ,σD. σ,μE. S,⎺X3.正态分布的均数、中位数和几何均数之间的关系为()A.均数与几何均数相等B. 均数与中位数相等C. 中位数与几何均数相等D. 均数、中位数、几何均数均不相等E. 均数、中位数、几何均数均相等4.正常成年男子的红细胞计数近似服从正态分布,已知⎺X=4.78*1012/L,S=0.38*1012/L,z=(4.00—4.78)/0.38=—2.05,1—φ(-2.05)=0.9798,则理论上红细胞计数为()A.高于4.78*1012/L的成年男子占97.988%B.低于4.78*1012/L的成年男子占97.988%C.高于4.00*1012/L的成年男子占97.988%D.低于4.00*1012/L的成年男子占97.988%E.在4.00*1012/L至4.78*1012/L的成年男子占97.98%5.某项指标95%医学参考值范围表示的是()A.在此范围“异常”的概率大于或等于95%B.在此范围“正常”的概率大于或等于95%C.在“异常”总体中有95%的人在此范围之外D.在“正常”总体中有95%的人在此范围E.在人群中检测指标由5%的可能超出此范围6.确定某项指标的医学参考范围值时,“正常人”指的是()A.从未患过疾病的人B. 患过疾病但不影响研究指标的人C. 排除了患过某种疾病的人D. 排除了影响研究指标的疾病或因素的人E. 健康状况良好的人7.某人群某项生化指标的医学参考值范围,该指标指的是()A.在所有人中的波动范围B. 在所有正常人中的波动范围C. 在绝大部分正常人中的波动范围D. 在少数正常人中的波动范围E. 在一个人不同时间的波动范围8.要评价某一地区一名5岁男孩的身高是否偏高,其统计学方法是()A.用均数来评价B. 用中位数来评价C. 用几何均数来评价D. 用变异系数来评价 D. 用参考值范围来评价9.应用百分位数法计算参考值范围的条件是()A.数据服从正态分布B. 数据服从偏态分布C. 有大样本数据D. 数据服从对称分布E. 数据变异不能太大10.某市1974年238名居民的发汞量(μmol/kg)如下,则该地居民发汞值得95%医学参考值范围是()第四章定性数据的统计描述1.如果一种新的治疗方法能够使不能治愈的疾病得到缓解并延长生命,则应发生的情况是()A.该病患病率增加B. 该病患病率减少C. 该病的发病率增加D. 该病的发病率减少E. 该病的死因构成比增加2.计算乙肝疫苗接种后血清学检查的阳转率,分母为()A.乙肝易感人数B. 平均人口数C. 乙肝疫苗接种人数D. 乙肝患者人数E. 乙肝疫苗接种后的阳转人数3.计算标准化死亡率的目的是()A.减少死亡率估计的偏倚B. 减少死亡率估计的抽样误差C. 便于进行不同地区死亡率的比较D. 消除各地区内部构成不同的影响E. 便于进行不同时间死亡率的比较4.已知男性的钩虫感染率高于女性,今欲比较甲乙两乡居民的钩虫感染率,但甲乡女性巨多,而乙乡男性居多适当的比较方法是()A.两个率直接比较B. 两个率间接比较C. 直接对感染人数进行比较D. 计算标准化率比较E. 不具备可比性5.甲县恶性肿瘤粗死亡率比乙县高,经标准化后甲县恶性肿瘤标准化死亡率比乙县低,其原因最有可能是()A.甲县的诊断水平高B. 甲县的肿瘤防治工作比乙县好C. 甲县的人口健康水平高D. 甲县的老年人口在总人口中所占比例更小E. 甲县的老年人口在总人口中所占比例更大6.相对危险度RR的计算方法是()A.两个标准化率之比B. 两种不同疾病的发病人数之比C. 两种不同疾病患病率之比D. 两种不同疾病发病率之比E. 两种不同条件下某疾病发生的概率之比7.比数比OR值表示的是()A.两个标准化率的差别大小B. 两种不同疾病的发病率差别程度C. 两种不同疾病患病率差别程度D. 两种不同疾病的严重程度E. 两种不同条件下某疾病发生的危险性程度8.计算患病率时的平均人口数的计算方法是()A.年初人口数和年末人口数的平均值B. 全年年初的人口数C. 全年年末的人口数D. 生活满一年的总人口数E. 生活至少在半年以上的总人口数9.死因构成比反映的是()A.各种疾病的发生的严重程度B. 疾病发生的主要原因C. 疾病在人群的分布情况D. 各种死因的相对重要性E. 各种疾病的死亡风险大小10.患病率与发病率的区别是()A.患病率高于发病率B. 患病率低于发病率C. 计算患病率不包括新发病例D. 发病率更容易获得E. 患病率与病程有关第五章统计表与统计图1.统计表的主要作用是()A.便于形象描述和表达结果B. 客观表达实验的原始数据C. 减少论文篇幅D. 容易进行统计描述和推断E. 代替冗长的文字叙述和便于分析对比2.描述某疾病患者年龄(岁)的分布,应采用的统计图是()A. 线图B. 直条图C. 百分条图D. 直方图E. 箱式图3.高血压临床试验分为试验组和对照组,分析考虑治疗0、2、4、6、8周血压的动态变化和改善情况,为了直观显示出两组血压平均变动情况,宜选用的统计图是()A. 半对数图B. 线图C. 直条图D. 直方图E.百分条图4.研究三种不同麻醉剂在麻醉后的镇痛效果,采用计量评分法,分数呈偏态分布,比较终点时分数的平均水平及个体变异程度,应使用的图形是()A. 复式条图B. 复式线图C. 散点图D.直方图E. 箱式图5.研究血清低密度脂蛋白LDL与载脂蛋白B-100的数量依存关系,应绘制的图形是()A. 直方图B. 箱式图C. 线图D. 散点图E. 直条图6.下列统计图适用于表示构成比关系的是()A.直方图B. 箱式图C. 误差条图、条图D. 散点图、线图E. 圆图、百分条图7.对有些资料构造统计表时,下列哪一项可以省略()A. 标题B. 标目C. 线条D. 数字E. 备注8.绘制下列统计图纵轴坐标刻度必须从“0”开始的有()A. 圆图B. 百分条图C. 线图D.半对数线图E. 直方图9.描述某现象频数分布情况可选择()A. 圆图B. 百分条图C. 箱式图D. 半对数线图E. 直方图10.对比某种清热解毒药物和对照药物的疗效,其单项指标为口渴、身痛、头痛、咳嗽、流涕、鼻塞、咽痛和发热的有效率,应选用的统计图是()A.圆图B. 百分条图C. 箱式图D. 复式条图E. 直方图第六章参数估计与假设检验1.样本均数的标准误差越小说明( )A.观察个体的变异越小B. 观察个体的变异越大C. 抽样误差越大D. 由样本均数估计整体均数的可靠性越小E. 由样本均数估计总体均数的可靠性越大2.抽样误差产生的原因是()A.样本不是随机抽取B. 测量不准确C. 资料不是正态分布D. 个体差异E. 统计指标选择不当3.要减少抽样误差,通常的做法是()A.减小系统误差B. 将个体变异控制在一定范围内C. 减小标准差D. 控制偏倚E. 适当增加样本含量4.对于正偏态分布的总体,当样本量足够大时,样本均数的分布近似为()A. 正偏态分布B. 负偏态分布C. 正态分布D. t分布E. 标准正态分布5.用某种中药治疗高血压患者100名,总有效率为80.2%,标准误为0.038,则总有效率的95%可信区间估计为()A. 0.802±1.64*0.083B. 0.802±1.96*0.083C. 0.802±2.58*0.083D. >0.802—1.64*0.083E. <0.802+1.64*0.0836.根据样本资料算得健康成人白细胞数的95%可信区间为7.2*109/L~9.1*109/L,其含义是()A.估计总体中有95%的观察值在此范围内B.总体均数在该区间的概率为95%C.样本中有95%的观察值在此范围内D.该地区包含样本均数的可能性为95%E.该区间包含总体均数的可能性为95%7.某地抽取正常成年人200名,测得其血清胆固醇的均数3.64mol/L,标准差为1.20mol/L,则该地正常成年人血清胆固醇均数95%的可信区间是()A. 3.64±1.96*1.20 B. 3.64±1.20 C. 3.64±1.96*1.20/√200D. 3.64±2.58*1.20/√200E. 3.64±2.58*1.208.假设检验的目的是()A.检验参数估计的准确度B. 检验样本统计量是否不同C. 检验样本统计量与总体参数是否不同D. 检验总体参数是否不同E. 检验样本的P值是否为小概率9.假设检验差别有统计学意义时,P值越小,说明()A.样本均数差别越大B. 总体均数差别越大C. 认为样本之间有差别的统计学证据越充分D. 认为总体之间有差别的统计学证据越充分E. 认为总体之间有差别的统计学证据越不充分10.关于假设检验,正确的说法是()A.检验水准必须设为0.05B. 必须采用双侧检验C. 必须根据样本大小选择检验水准D. 必须建立无效假设E. 要说明无效假设正确,必须计算P值第七章 t检验1.两样本均数之差的标准误反映的是()A.两样本数据集中趋势的差别B. 两样本数据的变异程度C. t分布的不同形状D. 数据的分布特性E. 两样本均数之差的变异程度2.两样本均数比较,检验结果P>0.05说明()A.两样本均数的差别较小B. 两总体均数的差别较大C. 支持两总体无差别的结论D. 不支持两总体有差别的结论E. 可以确认两总体无差别3.由两样本均数的差别推断两总体均数的差别,其差别有统计学意义指的是()A.两样本均数的差别具有实际意义B. 两总体均数的差别具有实际意义C. 两样本和两总体的差别都具有实际意义D. 有理由认为两样本均数有差别E. 有理由认为两总体均数有差别4.两样本均数比较,差别有统计学意义时,P值越小说明()A.两样本均数差别越大B. 两总体均数差别越大C. 越有理由认为两样本均数不同D. 越有理由认为两总体均数不同E. 越有理由认为两样本均数相同5.假设检验中的Ⅱ类错误指的是()A.可能出现的误判错误B. 可能出现的假阳性错误C. 可能出现的假阴性错误D. 可能出现的原假设错误E. 可能出现的备择假设错误6.减小假设检验的Ⅱ类错误,应该使用的方法是()A.减小Ⅰ类错误B. 减小测量的系统误差C. 减小测量的随机误差D. 提高检验界值E. 增加样本量7.以下不能用配对t检验方法的是()A.比较15名肝癌患者癌组织和癌旁组织中Sirt1基因的表达量B.比较两种检测方法测量十五名肝癌患者癌组织中Sirt1基因的表达量C.比较早期和晚期肝癌患者各15例癌组织中Sirt1基因的表达量D.比较糖尿病患者经某种药物治疗前后糖化血红蛋白的变化E.比较15名受试者针刺膻中穴前后的痛阈值8.两独立样本均数t检验,其前提要求是()A.两总体均数相等B. 两总体均数不等C. 两总体方差相等D. 两总体方差不等E. 两总体均属和方差都相等9.若将配对设计的数据进行两独立样本均数t检验,容易出现问题的是()A. 增加出现Ⅰ类错误的概率B. 增加出现Ⅱ类错误的概率C. 检验结果的P值不准D. 方差齐性检验的结果不准E. 不满足t检验的应用条件10.两组定量资料比较,当方差不齐时,应使用的检验方法是()A.配对t检验B. Satterthwaite t,检验C. 独立样本均数t检验D.方差齐性检验E. z检验第八章方差分析1.方差分析的基本思想是()A.组间均方大于组内均方B. 组内均方大于组间均方C. 不同来源的方差必须相等D. 两方差之比服从F分布E. 总变异及其自由度可按不同来源分解2.方差分析的应用条件之一是方差齐性,它是指()A.各比较组相应的样本方差相等B. 各比较组相应的总体方差相等C. 组内方差等于组间方差D. 总方差等于各组方差之和E. 总方差=组内方差+组间方差3.完全随机设计方差分析中的组间均方反映的是()A.随机测量误差大小B. 某因素效应大小C. 处理因素效应与随机误差综合结果D. 全部数据的离散度E. 个组方差的平均水平4.对于两组资料的比较,方差分析与t检验的关系是()A.t检验的结果更准确B. 方差分析结果更准确C. t检验对数据的要求更为严格D. 近似等价E. 完全等价5.多组均数比较的方差分析,如果P<0.05,则应该进一步做的是()A.两均数的t检验B. 区组方差分析C. 方差齐性检验D. SNK-q检验E. 确定单独效应6.完全随机设计的多个样本均数比较,经方差分析,若P<0.05,则结论为()A.各样本均数全相等B. 各样本均数全不相等C. 至少有两个样本均数不等D. 至少有两个总体均数不等E. 各总体均数全相等7.完全随机设计资料的多各样本均数的比较,若处理无作用,则方差分析的F值在理论上应接近于()A.Fa(v1,v2) B. SS处理/SS误差C. 0D. 1E. 任意值8.对于多个方差的齐性检验,若P<a,可认为()A.多个样本方差全不相等B. 多个总体方差全不相等C. 多个样本方差不全相等D. 多个总体方差不全相等E. 多个总体方差相等9.析因涉及的方差分析中,两因素X与Y具有交互作用指的是()A. X和Y的主效应互相影响B. X与Y对观测指标的影响相差较大C. X与Y有叠加作用D. X对观测指标的作用受Y水平的影响E. X与Y的联合作用较大10.某职业病防治院测定了年龄相近的45名男性用力肺活量,其中是石棉肺患者、石棉肺可疑患者和正常人各15名,其用力肺活量分别为(1.79±0.74)L、(2.31±0.87)L和(3.08±0.65)L,拟推断石棉肺患者、石棉肺可疑患者和正常人的用力肺活量是否不同,宜采用的假设检验方法是()A.两组均属比较的t检验B. 方差齐性检验C. 完全随机设计方差分析D. 随机区组设计方差分析E. 析因设计方差分析第九章χ2检验1.两样本率比较,差别具有统计学意义时,P值越小越说明()A.两样本率差别越大B. 两总体率差别越大C. 越有理由认为两样本率不同D. 越有理由认为两总体率不同E. 越有理由认为两样本率相同2.欲比较两组阳性反应率,在样本量非常小的情况下(如n1<10,n2<10),应采用的假设检验方法是()A.四表格χ2检验B. 校正四表格χ2检验C. Fisher确切概率法D. 配对χ2检验E. 校正配对χ2检验3.进行四组样本率比较的χ2检验,如χ2>χ20.01,3,可认为()A.四组样本率均不相同B. 四组总体率均不相同C. 四组样本率相差较大D. 至少有两组样本率不相同E. 至少有两组总体率不相同4.从甲、乙两文中,查到同类研究的两个率比较的χ2检验,甲文χ2>χ20.01,1,乙文χ2>χ20.05,1,可认为()A.两文结果有矛盾B. 两文结果完全相同C. 甲文结果更为可信D. 乙文结果更为可信E. 甲文说明总体的差异较大5.两组有效率比较的检验功效相关的因素是()A.检验水准和样本率B. 总体率差别和样本含量C. 样本含量和样本率D. 总体率差别和理论频数E. 容许误差和检验水准6.通常分析四格表需用连续性校正χ2检验方法的情况是()A.T<5B. T<1或n<40C. T<1且n<40D. 1≤T<5且n>40E. T<5且n<407.当四格表的周边合计数不变时,如果某格的实际频数有变化,则其理论频数是()A. 增大B. 减小C. 不变D. 不确定E. 随该格实际频数的增减而增减8.对四种药物进行临床试验,计算显效率,规定检验水准α=0.05,若需要进行多重比较,用Bonferroni方法校正后的检验水准应该是()A. 0.017B. 0.008C. 0.025D. 0.005E. 0.0139.对药物的四种剂量进行临床试验,计算有效率,规定检验水准α=0.05,若需要进行多重比较,用Bonferroni方法校正后的检验水准应该是()A. 0.050B. 0.010C. 0.025D.0.005E.0.01710.利用χ2检验公式不适合解决的实际问题是()A.比较两种药物的有效率B. 检验某种疾病与基因多态性的关系C. 两组有序试验结果的药物疗效D. 药物三种不同剂量显效率有无差别E. 两组病情“轻、中、重”的构成比例第十章非参数秩和检验1.对医学计量资料成组比较,相对参数检验来说,非参数秩和检验的优点是()A.适用范围广B. 检验效能高C. 检验结果更准确D. 充分利用资料信息E. 不易出现假阴性错误2.对于计量资料的比较,在满足参数法条件下用非参方法分析,可能产生的结果是()A. 增加Ⅰ类错误B. 增加Ⅱ类错误C. 减少Ⅰ类错误C. 减少Ⅱ类错误 E. 两类错误都减少3.两样本比较的秩和检验,如果样本含量一定,两组轶和的差别越大说明()A.两总体的差别越大B. 两总体的差别越小C. 两样本的差别可能越大D. 越有理由说明两总体有差别E. 越有理由说明两总体无差别4.多个计量资料的比较,当分布类型未知时,应选择的统计方法是()A.方差分析B. WilcoxonT检验C. Kruskal-Wallis H检验D. z检验E. 列联表χ2检验5.两组数据的秩和检验和t检验相比,其优点是()A.计算简便B. 检验假设合理C. 检验效能高D. 抽样误差更小E. 对数据分布不做限制6.两样本比较秩和检验,其检验统计量T是()A.例数较小的秩和B. 例数较小的秩和C. 较小的秩和D. 较大的秩和E. 任意一组数据的秩和7.两样本比较的秩和检验,其无效假设是()A.两样本有相同的秩和B. 两总体有相同的秩和C. 两样本分布相同D. 两总体分布相同E. 两总体分布位置相同8.两样本比较的Wilcoxon秩和检验结果显著,判断孰优孰劣的根据是()A.两样本的秩和大小B. P值大小C. 检验统计量T值大小D. 两样本秩和的差别大小E. 两样本平均秩的大小9.在一项临床试验研究中,疗效分为“痊愈、显效、有效、无效”四个等级,现欲比较试验组与对照组治疗效果有无差别,宜采用的统计方法是()A.Wilcoxon秩和检验 B. 2*4列联表χ2检验 C. 四格表χ2检验D. Fisher确切概率法E. 计算标准化率10.两样本比较的秩和检验中,甲组中最小数据有2个0.2,乙组中最小数据有3个0.2,则数据0.2对应的秩次是()A. 0.2B. 1.0C. 5.0D. 2.5E. 3.0。
五、其它30分(3~5道题目,每题6~10分)随访资料的生存分析:【06真题】九、某医生从 2002年 1月 1日起对某医院收治的 6名急性心肌梗塞病人进行跟踪观察,2002年 3月 25日结束观察,共 12周。
记录的资料如下:(5分)1、上述资料随访时间单位以(日)、(月)、(年)哪个较合适?为什么?2、判断上述随访时间哪些属截尾值?写出观察对象编号。
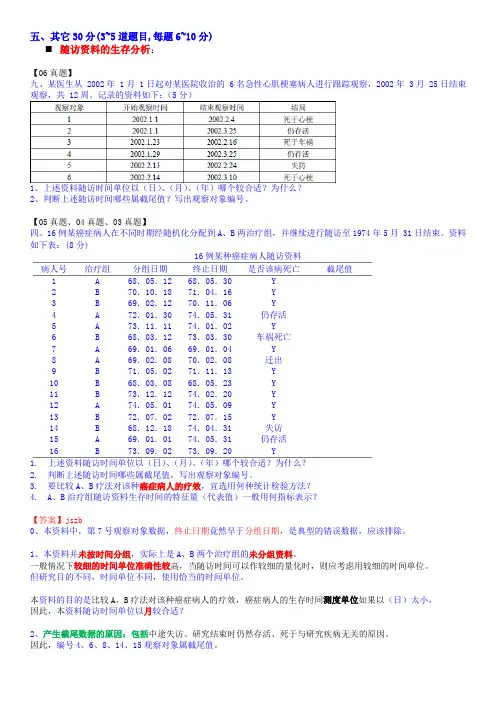
【05真题、04真题、03真题】四、16例某癌症病人在不同时期经随机化分配到A、B两治疗组,并继续进行随访至1974年5月 31日结束。
资料如下表:(8分)16例某种癌症病人随访资料病人号治疗组分组日期终止日期是否该病死亡截尾值1 A 68.05.12 68.05.30 Y2 B 70.10.18 71.04.16 Y3 B 69.02.12 70.11.06 Y4 A 72.01.30 74.05.31 仍存活5 A 73.11.11 74.01.02 Y6 B 68.03.12 73.03.30 车祸死亡7 A 69.01.06 69.01.04 Y8 A 69.02.08 70.02.08 迁出9 B 71.05.02 71.11.13 Y10 B 68.03.08 68.05.23 Y11 B 73.12.12 74.02.20 Y12 A 74.05.01 74.05.09 Y13 B 72.07.02 72.07.15 Y14 B 68.12.18 74.04.31 失访15 A 69.01.01 74.05.31 仍存活16 B 73.09.02 73.09.20 Y1.上述资料随访时间单位以(日)、(月)、(年)哪个较合适?为什么?2.判断上述随访时间哪些属截尾值,写出观察对象编号。
3.要比较A、B疗法对该种癌症病人的疗效,宜选用何种统计检验方法?4.A、B治疗组随访资料生存时间的特征量(代表值)一般用何指标表示?【答案】jszb0、本资料中,第7号观察对象数据,终止日期竟然早于分组日期,是典型的错误数据,应该排除。

因此,该地正常成年男性血红蛋白的 正常值范围为(12.014,16.045 ) g/dL 。
统计描血連拾标.TJ吗lid llixiing1QQ< 0 14.030013 7500Stii. Deviati on1 0282 :偏度采数 S kewnE 弱.044Std Error of公1Km-tQsis :喔度丟数Kurtosi s-.320 211, Err ox of4T0 Percentile :百分便?ere entilesL2 0L25£ 12 250025 13 250050 13 7500 75 14 7S0D£5 15 750097.5L6 2500因男性血红蛋白过多或过少均为异常,故按双侧估计, 下限:上限: + 1.96S = 14.03 + 1.96 X 1.0282 = 12.014X 1.0282 = 16.045 取95%界限:(g/dL ) (g/dL )五、其它30分(3~5道题目,每题6~10分)提供某一素材,可能要求:选择正确的统计方法并简述理由。
对错误进行分析,并予以纠正。
对某些数据、指标的含义作出正确的判断 正交试验表头设计及结果分析可能涉及范围:计量资料的统计描述、相对数应用注意事项,秩和检验,随访资料的生存分析,正交试验设计 方差分析。
【06真题、05真题】三、某市100名正常成人男性血红蛋白值(g/dL )频数分布表如下:(7分) 组段 11.5- 12.0- 12.5- 13.0- 13.5- 14.0- 14.5- 15.0- 15.5- 16.0- 频数 2671424121810341. 选用何种指标描述其 集中位置和离散程度 较好?为什么?2. 估计该地正常成年男性血红蛋白的 正常值范围。
SPSS 软件有关分析结果:【答案】jszb1、从SPSS 软件分析结果可知:偏度系数Skewness = 0.044 ;峰度系数 Kurtosis = -0.320 ;两个系数都小于 1,可认为近似于正态分布。

医学统计学试题及答案第一题:在研究中,一个群体的平均年龄为45岁,标准差为6岁。
假设这个年龄分布近似正态分布,计算出65岁以上的人口所占比例。
答案:根据正态分布的性质,我们可以使用标准正态分布表来计算出65岁以上的人口所占比例。
首先,我们需要将年龄转化为标准正态分布的Z得分。
Z = (X - μ) / σ其中,X为要计算的年龄值,μ为平均年龄,σ为标准差。
对于65岁以上的人口,我们可以计算Z值如下:Z = (65 - 45) / 6 = 3.33根据标准正态分布表,我们可以查找Z值为3.33对应的累积概率。
根据表格,Z值为3.33对应的累积概率为0.9993。
因此,65岁以上的人口所占比例为:1 - 0.9993 = 0.0007(约为0.07%)第二题:假设一项研究发现,吸烟者患肺癌的风险是非吸烟者的2倍。
在一组1000名受试者中,有150名吸烟者,请计算吸烟者中患肺癌的人数。
答案:根据题目信息,吸烟者患肺癌的风险是非吸烟者的2倍。
我们可以假设非吸烟者患肺癌的风险为R,则吸烟者患肺癌的风险为2R。
设吸烟者中患肺癌的人数为X,非吸烟者中患肺癌的人数为Y。
根据所给信息,有以下等式:X = 2Y (1)又根据题目信息,整个研究组的受试者人数为1000人,其中吸烟者150人,非吸烟者(包括患肺癌和不患肺癌的)850人。
所以有:X + Y = 1000 - 150 = 850 (2)将(1)式代入(2)式,得:2Y + Y = 8503Y = 850Y = 283.33(约为283人)将Y的值代入(1)式,得:X = 2 * 283.33 ≈ 566.67(约为567人)所以,吸烟者中患肺癌的人数约为567人。
第三题:在一项研究中,两种药物A和B用于治疗同一疾病。
通过随机对照试验,研究人员随机将100名患者分为两组,其中50人接受药物A治疗,另外50人接受药物B治疗。
在随访期结束时,共有40人痊愈,其中25人来自药物A组,15人来自药物B组。

基本概念:统计学研究的步骤变量分类频率与概率、小概率事件、小概率原理总体、个体、样本、样本含量总体参数、样本统计量随机同质、变异抽样误差下列变量中,属于定量变量的是()A性别B职业C血型D体重某医院某年口腔科就诊儿童的乳牙萌出时间资料属于()A定量资料B等级资料C计数资料D定性资料启东市癌症登记处1972年1月1日至2001年12月31日肺癌发病登记报告显示:30年间登记并经核实肺癌病例8167例,其中男性5859例,女性2308例。
该资料属于()A计量资料B计数资料C半定量资料D定量资料比较甲、乙两法对某病的治疗效果,结果如下:则该资料属于()A定性资料B定量资料C等级资料D计量资料某医师研究肝硬化患者血浆肾素活性,将患者按腹水程度分为大量腹水、有腹水、无腹水3组,比较这3患者血浆肾素活性有无差别。
则该资料类型是()A计量资料B计数资料C定量资料D等级资料正态分布的性质正态曲线下面积的分布规律参考值范围确定的原则和方法二X表示总体均数的标准误。
()S x 表示样本均数的标准误。
()同一批数值变量资料的标准差不会比标准误大。
()即使变量X偏离正态分布,只要每次抽样的样本数足够大,样本均数也近似服从正态分布。
()G _表示()x A总体标准差B 样本标准差C 抽样分布均数的理论标准差D抽样分布均数的估计标准差S x表示()A总体均数的离散程度B总体标准差的离散程度C样本均数的离散程度D样本标准差的离散程度从连续性变量X中反复随机抽样,随样本含量增加X -」将趋于()SxA X的原始分布B 正态分布C均数的抽样分布D 标准正态分布下面关于标准误的四种说法中,哪一种最不正确()A标准误是样本统计量的标准差B标准误反映了样本统计量的变异C标准误反映了总体参数的变异D标准误反映了抽样误差的大小请简述标准差与标准误的区别和联系。
区别:公式标准差-个体变异、标准误-抽样误差联系:固定(T时,抽样误差与样本量成反比均表示离散程度[个体值的,统计量的]下列说法正确吗?算得某95%的可信区间,则:总体参数有95%的可能落在该区间。

医学统计学题库医学统计学是一门运用概率论和数理统计的原理和方法,研究医学领域中数据的收集、整理、分析和解释的学科。
它对于医学研究、临床实践、公共卫生决策等都具有重要的意义。
以下是为您精心准备的一份医学统计学题库,希望能够帮助您加深对这门学科的理解和掌握。
一、选择题1、下列关于总体和样本的说法,错误的是()A 总体是根据研究目的确定的同质观察单位的全体B 样本是从总体中随机抽取的部分观察单位C 样本量越大,对总体的代表性越好D 总体中的个体一定都在样本中2、描述一组偏态分布资料的变异程度,宜用()A 全距B 标准差C 变异系数D 四分位数间距3、正态分布曲线下,横轴上从均数μ到μ +196σ的面积为()A 475%B 45%C 95%D 975%4、两样本均数比较的 t 检验,差别有统计学意义时,P 值越小,说明()A 两样本均数差别越大B 两总体均数差别越大C 越有理由认为两总体均数不同D 越有理由认为两样本均数不同5、完全随机设计方差分析中,若处理因素无作用,则 F 值为()A 1B <1C >1D 接近于 16、对于四格表资料,当n ≥ 40 且有一个理论频数1 ≤ T < 5 时,应采用的检验方法是()A 连续性校正的χ² 检验B 直接计算概率法C 四格表确切概率法D 不能进行χ² 检验7、相关系数 r 的取值范围是()A -1 < r < 1B ∞ < r <+∞C -1 ≤ r ≤ 1D 0 ≤ r ≤ 18、在直线回归分析中,如果自变量 X 的值增加,因变量 Y 的值也随之增加,则直线的斜率()A 大于 0B 小于 0C 等于 0D 等于 19、以下关于生存分析的说法,错误的是()A 生存分析可以同时分析多个因素对生存时间的影响B 生存时间通常定义为从某种起始事件到终点事件所经历的时间C 生存分析中的终点事件只能是死亡D 生存曲线可以直观地展示不同组的生存情况10、进行多个样本均数间的多重比较时,若采用 LSD t 检验,则会()A 增大犯Ⅰ型错误的概率B 增大犯Ⅱ型错误的概率C 减小犯Ⅰ型错误的概率D 减小犯Ⅱ型错误的概率二、填空题1、统计工作的基本步骤包括________、________、________和________。

第一章医学统计中的基本概念一、单向选择题1. 医学统计学研究的对象是A. 医学中的小概率事件B. 各种类型的数据C. 动物和人的本质D. 疾病的预防与治疗E.有变异的医学事件2. 用样本推论总体,具有代表性的样本指的是A.总体中最容易获得的部分个体 B.在总体中随意抽取任意个体C.挑选总体中的有代表性的部分个体 D.用配对方法抽取的部分个体E.依照随机原则抽取总体中的部分个体3. 下列观测结果属于等级资料的是A.收缩压测量值 B.脉搏数C.住院天数 D.病情程度E.四种血型4. 随机误差指的是A. 测量不准引起的误差B. 由操作失误引起的误差C. 选择样本不当引起的误差D. 选择总体不当引起的误差E. 由偶然因素引起的误差5. 收集资料不可避免的误差是A. 随机误差B. 系统误差C. 过失误差D. 记录误差E.仪器故障误差答案: E E D E A二、简答题1.常见的三类误差是什么?应采取什么措施和方法加以控制?[参考答案]常见的三类误差是:(1)系统误差:在收集资料过程中,由于仪器初始状态未调整到零、标准试剂未经校正、医生掌握疗效标准偏高或偏低等原因,可造成观察结果倾向性的偏大或偏小,这叫系统误差。
要尽量查明其原因,必须克服。
(2)随机测量误差:在收集原始资料过程中,即使仪器初始状态及标准试剂已经校正,但是,由于各种偶然因素的影响也会造成同一对象多次测定的结果不完全一致。
譬如,实验操作员操作技术不稳定,不同实验操作员之间的操作差异,电压不稳及环境温度差异等因素造成测量结果的误差。
对于这种误差应采取相应的措施加以控制,至少应控制在一定的允许范围内。
一般可以用技术培训、指定固定实验操作员、加强责任感教育及购置一定精度的稳压器、恒温装置等措施,从而达到控制的目的。
(3)抽样误差:即使在消除了系统误差,并把随机测量误差控制在允许范围内,样本均数(或其它统计量)与总体均数(或其它参数)之间仍可能有差异。

医学统计学课堂练习题(含答案)⽼师讲过的章节:第⼀章到第⼗四章(除第五章外)。
其中有⼀些章的某些节是没有讲的,⼤家以课件和下周⽼师复习为主。
芳芳给的⾥⾯的选择题⽬:1.⽅差分析结果,F>F0.05,V1,V2 ,则统计推论结论是( )A各总体均数不全相等B各总体均数都不相等C各样本均数都不相等D各样本均数间差别都有显著性2.单因素⽅差分析中的组内均⽅()的统计量A表⽰平均的随机误差度量B表⽰某处理因素的效应作⽤度量C表⽰某处理因素的效应和随机误差两者综合影响的结果D表⽰N个数据的离散程度3.在总体⽅差相等的条件下,由两个独⽴样本计算两个总体均数之差的可信区间包含了0,则:()A 可认为两样本均数差别⽆统计意义B可认为两样本均数差别有统计意义C可认为两总体均数差别⽆统计意义D可认为两总体均数差别有统计意义4.假设检验中的第⼆类错误是指()所犯的错误A 拒绝了实际上成⽴的H0B未拒绝了实际上成⽴的H0C拒绝了实际上不成⽴的H0D未拒绝了实际上不成⽴的H05.两样本均数⽐较的假设检验中,差别有统计学意义时,P越⼩说明( Dσ)A 两样本均数差别越⼤B 两总体均数差别越⼤C 越有理由认为两样本均数不同D 越有理由认为两总体均数不同6.作两样本均数差别的t检验中,P值与α值中()A α值是研究者指定的B P值是研究者指定的C 两者意义相同,数值不同D 两者意义相同,数值相同7.从两个不同总体中随机抽样,样本含量相同,则两总体均数95%可信区间( D )A 标准差⼩者,可信度⼤B 标准差⼩者,准确度⾼C 标准差⼩者,可信度⼤且准确度⾼D 两者的可信度相同8.其他条件不变,可信度1-α越⼤,则总体均数可信区间( A )A 越宽B 越窄C 不变D 还与第⼆类错误有关9.其他条件不变,可信度1-α越⼤,则随机抽样所获得的总体均数可信区间将不包含总体均数的概率( B )A 越⼤B 越⼩C 不变D 不确定10.µ±1.96σ,区间包含总体均数的概率为( D )A 95%B 97%C 99%D 100%11.从某正态总体中随机抽样,样本含量固定,µ±1.96σ,区间内包含样本均数的概率为( A )A 95%B 97.5%C 99%D 不确定12.两个样本均数不⼀致,t检验时P>0.05,则( C )A 可以认为两个总体均数相等B 可以认为总体均数不同C 没有⾜够证据可以推断总体均数不同D 可以认为两个样本来⾃同⼀总体13.两个独⽴样本均数的⽐较,P<0.001,拒绝H0 时可推论为( A )A 1与2间差异有统计学意义 B1与2间差异⽆统计学意义C µ1与µ2间差异⽆统计学意义 Dµ1与µ2间差异有统计学意义14.两独⽴样本连续型定量资料⽐较,当分布类型不清时,选择( C )总是正确的A t检验B Z检验C 秩和检验 Dχ2检验15.两独⽴样本连续定量资料的⽐较,应⾸先考虑( D )A t检验B 秩和检验C χ2检验D 资料符合哪些统计检验⽅法的条件,在符合的统计⽅法中选择Power ⾼的检验⽅法16.对两样本均数做⽐较时,已知n1, n2均⼩于30,总体⽅差不齐且分布呈偏态,宜⽤( C )A t检验B t检验C 秩和检验 D不确定17.变量X偏离正态分布,只要样本量⾜够⼤,样本均数()A 偏离正态分布B 服从F分布C 近似正态分布D 服从t分布18.完全随机设计资料的⽅差分析中,必然有()A SS组间>SS组内B SS组间C MS总=MS组间+MS组内D SS总=SS组间+SS组内E V组间 >V组内19.完全随机设计资料的⽅差分析中,必然有()A MS组内>MS误差B MS组间C MS组内=MS误差D MS组间=MS误差E MS组间>MS组内20.当组数等于2时,对于同⼀资料,⽅差分析结果与t检验结果()A 完全等价且F=√t B. ⽅差分析结果更准确C. t检验结果更准确D. 完全等价且t=√FE. 理论上不⼀致21. 1.⽅差分析结果,F处理>F0.05,V1,V2 ,则统计推论结论是( )A各总体均数不全相等B各总体均数都不相等C各样本均数都不相等D各样本均数间差别都有显著性E. 各总体⽅差不全相等25.完全随机设计⽅差分析的实例中,()A 组间SS不会⼩于组内SSB 组间MS不会⼩于组内MSC F值不会⼩于1D F值不会是负数E F值不会是正数26.配对设计资料,若满⾜正态性和⽅差齐性。

l.统计中所说的总体是指:AA根据研究目的确定的同质的研究对象的全体B随意想象的研究对象的全体C根据地区划分的研究对象的全体D根据时间划分的研究对象的全体E根据人群划分的研究对象的全体2.概率P=0,则表示 BA某事件必然发生 B某事件必然不发生 C某事件发生的可能性很小D某事件发生的可能性很大 E以上均不对3.抽签的方法属于 DA分层抽样 B系统抽样 C整群抽样 D单纯随机抽样 E二级抽样4.测量身高、体重等指标的原始资料叫:BA计数资料 B计量资料 C等级资料 D分类资料 E有序分类资料5.某种新疗法治疗某病患者41人,治疗结果如下:治疗结果治愈显效好转恶化死亡治疗人数 8 23 6 31该资料的类型是: DA计数资料 B计量资料 C无序分类资料 D有序分类资料 E数值变量资料6.样本是总体的 CA有价值的部分 B有意义的部分 C有代表性的部分D任意一部分 E典型部分7.将计量资料制作成频数表的过程,属于??统计工作哪个基本步骤:CA统计设计 B收集资料 C整理资料 D分析资料 E以上均不对8.统计工作的步骤正确的是 CA收集资料、设计、整理资料、分析资料 B收集资料、整理资料、设计、统计推断C设计、收集资料、整理资料、分析资料 D收集资料、整理资料、核对、分析资料E搜集资料、整理资料、分析资料、进行推断9.良好的实验设计,能减少人力、物力,提高实验效率;还有助于消除或减少:BA抽样误差 B系统误差 C随机误差 D责任事故 E以上都不对10.以下何者不是实验设计应遵循的原则 DA对照的原则 B随机原则 C重复原则D交叉的原则 E以上都不对第八章数值变量资料的统计描述11.表示血清学滴度资料平均水平最常计算 BA算术均数 B几何均数 C中位数 D全距 E率12.某计量资料的分布性质未明,要计算集中趋势指标,宜选择 CA XB GC MD SE CV13.各观察值均加(或减)同一数后:BA均数不变,标准差改变 B均数改变,标准差不变C两者均不变 D两者均改变 E以上均不对14.某厂发生食物中毒,9名患者潜伏期分别为:16、2、6、3、30、2、lO、2、24+(小时),问该食物中毒的平均潜伏期为多少小时? CA 5B 5.5C 6D 10E 1215.比较12岁男孩和18岁男子身高变异程度大小,宜采用的指标是:D A全距 B标准差 C方差 D变异系数 E极差16.下列哪个公式可用于估计医学95%正常值范围 AA X±1.96SB X±1.96SXC μ±1.96SXD μ±t0.05,υSXE X±2.58S17.标准差越大的意义,下列认识中错误的是 BA观察个体之间变异越大 B观察个体之间变异越小C样本的抽样误差可能越大 D样本对总体的代表性可能越差E以上均不对18.正态分布是以 EA t值为中心的频数分布B 参数为中心的频数分布C 变量为中心的频数分布D 观察例数为中心的频数分布E均数为中心的频数分布19.确定正常人的某项指标的正常范围时,调查对象是 BA从未患过病的人 B排除影响研究指标的疾病和因素的人C只患过轻微疾病,但不影响被研究指标的人D排除了患过某病或接触过某因素的人 E以上都不是20.均数与标准差之间的关系是 EA标准差越大,均数代表性越大 B标准差越小,均数代表性越小C均数越大,标准差越小 D均数越大,标准差越大E标准差越小,均数代表性越大第九章数值变量资料的统计推断21.从一个总体中抽取样本,产生抽样误差的原因是 AA总体中个体之间存在变异 B抽样未遵循随机化原则C被抽取的个体不同质 D组成样本的个体较少 E分组不合理22.两样本均数比较的t检验中,结果为P<0.05,有统计意义。

医学统计学基础考试试题本文按照试题的形式和格式进行回答,不包含标题和其他无关内容。
1. 题目:医学统计学基础考试试题一、选择题(每题5分,共60分)1. 下列哪个是描述样本数的指标?A. 均值B. 中位数C. 标准差D. 人数 <- 正确答案2. 在医学研究中,P值用来表示什么?A. 样本大小B. 方差C. 统计显著性D. 相关性 <- 正确答案3. 以下哪种图表适合用于展示不同医院疾病发病率的比较?A. 条形图 <- 正确答案B. 散点图C. 饼图D. 折线图4. 在一个双盲实验中,下列哪种情况可能发生?A. 参与者和研究人员都不知道给予的治疗是药物还是安慰剂 <- 正确答案B. 参与者和研究人员都知道给予的治疗是药物C. 参与者不知道给予的治疗是药物还是安慰剂,但研究人员知道D. 参与者知道给予的治疗是药物,但研究人员不知道5. 在医学统计学中,以下哪个指标可以用来衡量两个变量之间的线性相关性?A. 皮尔逊相关系数 <- 正确答案B. 方差C. 标准差D. 中位数二、填空题(每题10分,共40分)1. 在双盲实验中,参与者被分为两组,一组接受药物治疗,另一组接受安慰剂治疗。
这种实验设计被称为 __________。
2. _______ 是一种用于描述分布形状的统计指标。
3. 在医学研究中,__________ 是指在患病和未患病两组中,患病的相对风险。
4. 在统计学中,__________ 是用于比较两个或多个样本均值是否有显著差异的方法。
三、简答题(每题20分,共40分)1. 解释单盲实验和双盲实验的概念,并说明为什么对于药物研究来说,双盲实验设计更可靠。
2. 请解释P值的含义,以及一般所采用的显著性水平。
四、论述题(共40分)请阐述医学统计学在临床研究和医学实践中的作用,并举例说明其重要性。
以上为医学统计学基础试题,希望您能根据试题要求作答,并按照试题形式自行发挥展开。
医学统计选择题目1、卫生统计工作的步骤为(统计研究设计、搜集资料、整理资料、分析资料)2、统计学的研究内容是(研究资料或信息的收集、整理和分析)3、统计中所说的总体是指(根据研究目的确定的同质的研究对象的全体)4、统计上所说的样本是指(按照随机原则抽取总体有代表性个体)5.参数是指(总体的统计指标)6、关于随机抽样,下列说法哪一项是正确的(遵循随机化的原则从总体中抽取观察单位,便样本较好地代表总体特征)7、从一个总体中抽取样本,产生抽样误差的原因是(同一总体中的个体之间存在差异)8、抽样的目的是(由样本统计量推断总体参数)9、良好的实验设计,能减少人力、物力,提高实验效率,还有助于消除或减少(系统误差)10、关于统计学中的小概率事件,下面说法正确的是(在一次观察中,可以认为不会发生的事件)11、统计学上通常认为P小于等于多少的事件,在一次观察中不会发生(0.05)12、概率是描述某随机事件发生可能性大小的数值,以下对概率的描述哪项是错误的(其值必须由某一统计量对应的概率分布表中得到)13、随机事件一般是指(在一次试验中可能发生也可能不发生的事件,其发生的概率为0<P<1)14、用均数和标准差可以全面描述(正态与近似正态分布)资料的特征15、对数正态分布是一种(正偏态)分布16、变异系数CV的数值(可以大于1,也可小于1)17、各观察值乘以一个大于0的常数后,(变异系数)不变18、表示血清抗体滴度资料平均水平最常用的的指标是(几何均数)19、要表示某地区2007年强直性脊柱炎患者的职业构成,可以绘制(圆图)20、比较身高和体重两组数据变异度大小宜采用(变异参数)21、以下指标中(标准差)可用来描述计量资料的离散程度22、偏态分布宜用(四分位数间距)描述其变异程度23、(对称)分布的资料,均属等于中位数24、一组变量的标准差将(随变量值之间的变异增大而增大)25、最小组段无下限或最大值段无上限的频数分布资料,可用(中位数)描述其集中趋势26、(标准误)小,表示用该样本均数估计总体均数的可靠性大27~~29无(上课未提及)30、下列不属于相对数的是(百分位数)31、下列哪种说法是错误的(分析大样本数据时可以构成比代替率)32、定基比和环比指标属于(相对比)33~~35无(上课未提及)36、一种新的治疗方法可以延长生命,但不能治愈其病,则发生下列情况(该病患病率将增加)37、计算麻疹疫苗接种后血清检查的阳转率,分母是(麻疹疫苗接种人数)38、在实际工作中,发生把构成比作率分析的错误的主要原因是由于(计算构成比的原始资料较率容易得到)39、决定正态分布形状的是(总体标准差)40、正态分布有两个参数与σμ,(σ越大)相应的正态曲线的形状越扁平41、对正态分布曲线描述有误的是(正态分布曲线上下完全对称)42、下列是有关参考值范围的说法,其中争取的是(所谓的正常和健康都是相对的,在正常人或健康人身上都存在着某种程度的病理状态)43、正态曲线上的拐点所对应的横坐标为(μ±α)44、以下方法确定医学参考值范围最好的方法是(结合原始数据分布类型选择相应的方法)45、根据1000例正常人的发铅值原始数据(偏态分布),计算其95%医学参考值范围应采用(单上侧百分位数法)46、正态分布N(μ,δ²),当μ恒定,δ越大(观察值变异程度越大,曲线越“胖”)47、均数的标准误反映了(样本均数与总体均数的差异)48、用于描述均数抽样误差大小的指标是(S-x)49、抽样误差产生的原因是(个体差异)50、均数95%置信区间主要用于(反映总体均数有95%的可能在某范围内)51、反映抽样误差大小的指标是(Sp与S-x抽样平均误差和抽样极限误差)52、关于参数估计的说法正确的是(对于一个参数可以获得几个估计值)53、同一总体的两个样本中,以下哪种指标值小的其样本均数估计总体均数更可靠?(Sx)54、标准差与标准误的关系是()55、在同一正态总体中随机抽取含量为n的样本,理论上有99%的总体均数在何者范围内(均数加减2.58倍的标准误)56、57、Sx表示的是(样本内实测值与总体均数之差)58、抽样误差是指(由于抽样产生的观测值之间的差别)59、总体标准差描述的是(所以个体值对总体均数的离散程度)60、61、关于以0为中心的t分布,错误的是(相同v时,t绝对值越大,P越大)62、下列哪个公式可用于估计总体均数99%可信区间:(μ±2.58S-x)63、在一项抽样研究中,当样本含量逐渐增大时:(标准误逐渐减少)64、区间—X±1.96S-x的含义是(总体均数的95%置信区间)65、均数与标准差之间的关系是(标准差越小,均数代表性越大)66、统计推断的内容是(参数估计、假设检验和用样本统计量估计总体参数)67、两样本均数比较,经t检验,差别有统计学意义时,P值越小,说明(越有理由认为两总体均数不同)68、两样本均数比较的t检验的适用条件是(数值变量资料、两总体方差相等和资料服从正态分布)69、在显著性检验中,α分别取以下水准,犯第二类错误最小的是(α=0.20即α值越大)70、在两样本均数的比较t检验中,无效假设应该是(两总体均数不相等)71、关于检验假设,下面哪种说法是正确的(无论是采用配对t检验还是两样本的t检验,都应在实验设计方案中先设定)72、下列哪种情况应作单侧检验?(已知A药不会优于B药)73、74、检验假设的理论依据是(小概率事件的原理和反证法的原理)75、两小样本计量资料比较假设检验,首先考虑(资料是否符合t检验的条件)76、由两样本均数的差别推断两总体均数的差别,H0:μ1=μ2,H1:μ1≠μ2,现差别的假设假设检验结果为P<0.05,从而拒绝H0,接受H1,则(第一类误差小于5%)77、双侧t界值和单侧t界值的关系为(双侧t2α,v=单侧tα,v)78、配对t检验的无效假设(双侧检验)一般可表示为(μd=0)79、80、t界值表中,当v一定时,t值与P值的关系是(t值随P值增大而减小)81、当组数等于2时,对同一资料,方差分析结果与t检验结果(完全等价且√F=|t|)82、以下几种说法中,哪项是错误的?(区间估计等同于假设检验)83、在假设检验时,本应作单侧检验的问题误用了双侧检验,可导致(增加了第二类错误)84、当假设检验求得的概率值P在所定检验水准附近时,下结论要慎重,其原因是(如果增大样本量,可能得出有差别的结论和如果单侧检验改为双侧检验,可能得出有差别的结论)85、假设检验过程中,下列哪一项不可以由研究者事先设定(所比较的总体参数)86、完全随机设计资料的方差分析中,必然有(SS总=SS组间+SS组内)87、单因素方差分析中,当P<0.05时,可认为(各总体均数不等或不完全相等)88、以下说法不正确的是(标准差的平方,就是均方)89、对于同一份组数等于2的定量资料,方差分析结果与t检验结果(完全等价于F=t²)90、随机区组设计的方差分析中,v区组等于(v总—v处理—v误差)91、92、当自由度(v1,v2)及显著性水准α都相同时,方差分析的界值比方差齐性检验的界值(小)93、完全随机设计的四组均数如果采用t检验进行两两比较(会增大犯一类错误的可能性)94、变量变换的目的是(方差齐性化、曲线直线化、变量正态化)95、完全随机设计方差分析中,组间变异是(处理因素+随机误差)造成的96、完全随机设计方差中(总离均差平方和=组间离均差平方和+组内离均差平方和)97、方差分析有一个前提条件是方差齐性,是指(组间方差=组内方差)105、两个小样本计量资料比较假设检验,首先考虑(资料符合t检验还是秩和检验的条件)108、四格表中4个格子基本数字是(两对实测阳性绝对和阴性绝对数)109、4个百分率作比较,有一个理论数小于5,大于1,其他都大于5,则(作x²检验可不必校正)110、四格表如有一个实际数为0,则(还不能决定是否可作x²检验)。
医学统计学1-3章练习题1、样本是总体中:DA、任意一部分B、典型部分C、有意义的部分D、有代表性的部分E、有价值的部分2、参数是指:CA、参与个体数B、研究个体数C、总体的统计指标D、样本总和E、样本的统计指标3、抽样的目的是:EA、研究样本统计量B、研究总体统计量C、研究典型案例D、研究误差E、样本推断总体参数4、脉搏数(次/分)是: BA、观察单位B、数值变量C、名义变量 D.等级变量 E.研究个体5、疗效是: DA、观察单位B、数值变量C、名义变量D、等级变量E、研究个体6、某种新疗法治疗某病患者41人,治疗结果如下:治疗结果治愈显效好转恶化死亡治疗人数 8 23 6 3 1该资料的类型是: DA计数资料 B计量资料 C无序分类资料 D有序分类资料 E 数值7、统计工作的步骤正确的是 CA收集资料、设计、整理资料、分析资料B收集资料、整理资料、设计、统计推断C设计、收集资料、整理资料、分析资料D收集资料、整理资料、核对、分析资料E搜集资料、整理资料、分析资料、进行推断8、将计量资料制作成频数表的过程,属于统计工作哪个基本步骤:C A统计设计 B收集资料 C整理资料 D分析资料 E以上均不对9、对照组不给予任何处理,属 EA、相互对照B、标准对照C、实验对照D、自身对照E、空白对照10、统计学常将P≤0.05或P≤0.01的事件称 DA、必然事件B、不可能事件C、随机事件D、小概率事件E、偶然11.医学统计的研究内容是 EA.研究样本 B.研究个体 C.研究变量之间的相关关系 D.研究总体E.研究资料或信息的收集.整理和分析12.统计中所说的总体是指:AA根据研究目的确定的同质的研究对象的全体 B随意想象的研究对象的全体C根据地区划分的研究对象的全体 D根据时间划分的研究对象的全体 E根据人群划分的研究对象的全体13.概率P=0,则表示 BA某事件必然发生 B某事件必然不发生 C某事件发生的可能性很小D某事件发生的可能性很大 E以上均不对14.总体应该由 DA.研究对象组成 B.研究变量组成 C.研究目的而定 D.同质个体组成 E.个体组成15. 在统计学中,参数的含义是 DA.变量 B.参与研究的数目 C.样本的统计指标 D.总体的统计指标 E.与统计研究有关的变量16.调查某单位科研人员论文发表的情况,统计每人每年的论文发表数应属于 AA.计数资料 B.计量资料 C.总体 D.个体 E.样本17.统计学中的小概率事件,下面说法正确的是:BA.反复多次观察,绝对不发生的事件 B.在一次观察中,可以认为不会发生的事件C.发生概率<0.1的事件 D.发生概率<0.001的事件E.发生概率<0.1的事件18、良好的实验设计,能减少人力、物力,提高实验效率;还有助于消除或减少:BA抽样误差 B系统误差 C随机误差 D责任事故 E以上都不对19、以舒张压≥12.7KPa为高血压,测量1000人,结果有990名非高血压患者,有10名高血压患者,该资料属()资料。
卫生统计学习题假设有一家医院正在进行一项卫生统计调查,以收集关于某种疾病在不同群体中的发病率数据。
以下是相关的学习题,帮助我们更好地理解和应用卫生统计学的基本原理和方法。
题目一:发病率计算某城市中,100个成年女性参与了一项健康调查,其中14人被诊断出患有特定类型的疾病。
请计算该疾病在该城市成年女性中的发病率。
解析:发病率 = (患病人数 / 总人数)×100%发病率 = (14/100)×100% = 14%题目二:相对风险计算在一项针对两组人群的研究中,组A中有120人,其中有30人患有某种疾病;而组B中有80人,其中有10人患有同一种疾病。
请计算组A相对于组B的风险。
解析:相对风险 = (发病率A / 发病率B)发病率A = 30/120 = 25%发病率B = 10/80 = 12.5%相对风险 = 25% / 12.5% = 2题目三:平均生存时间计算某种严重疾病患者的随访数据如下:年份 | 存活患者数1 | 1002 | 803 | 604 | 405 | 206 | 107 | 5请计算该疾病患者的平均生存时间。
解析:平均生存时间= Σ(各年份生存人数 ×年份)/ 总人数平均生存时间 = (1×100 + 2×80 + 3×60 + 4×40 + 5×20 + 6×10 + 7×5)/ 315平均生存时间 = 105题目四:相对风险比较某项研究通过观察两种药物治疗同一种疾病的患者并统计结果。
结果显示,在服用药物A的患者中,发生不良反应的比例为15%,而在服用药物B的患者中,发生不良反应的比例为10%。
请计算药物A相对于药物B的相对风险。
解析:相对风险 = (发生不良反应比例A / 发生不良反应比例B)相对风险 = 15% / 10% = 1.5题目五:假设检验在某项针对男性和女性两组中食物中毒的研究中,发现男性组的食物中毒发病率为20%,而女性组的食物中毒发病率为15%。
一、两组计量资料比较(20分)题干由试题和相关SPSS分析结果组成1、根据资料选择正确的统计检验方法;2、请写出假设检验步骤:检验假设,检验水准,根据SPSS结果选择正确的统计量值和P值、并作出结果判断。
3、说明:正态性检验提供K-S检验结果;方差齐性检验提供Levene’s检验结果。
正态性检验和方差齐性检验不必列出检验步骤,作出判断即可。
可能包括的内容:●配对设计的两样本均数比较的t检验●成组设计的两样本均数比较的t检验●成组设计的两样本均数比较的近似t检验●配对设计的两样本比较的符号秩和检验●成组设计的两样本比较的秩和检验举例:例2.17 某医生测得18例慢性支气管炎患者及16例健康人的尿17酮类固醇排出量(mg/dl)分别为X1和X2,试问两组的均数有无不同。
X1:3.14 5.83 7.35 4.62 4.05 5.08 4.98 4.22 4.35 2.35 2.89 2.16 5.55 5.94 4.40 5.35 3.80 4.12X2:4.12 7.89 3.24 6.36 3.48 6.74 4.67 7.38 4.95 4.08 5.34 4.27 6.54 4.62 5.92 5.18Test Statistics b-1.334a .182Z Asymp. Sig. (2-tailed)健康者 - 慢支患者Based on negative ranks.a. Wilcoxon Signed Ranks Testb.根据SPSS 分析结果, 对资料分布正态性、方差齐性作出判断。
H 0: μ = μ 0 H 1: μ ≠ μ 0 α = 0.05ν = n1+n2-2=32 本例 t= -1.818, P=0.078>0.05 结论:【答案】jszb1、此资料是计量资料,研究设计为完全随机设计 (又称成组设计);2、根据正态性单样本K-S 检验结果:P 值分别为 0.992、0.987,均大于 0.1,因此两样本均服从正态分布;3、根据方差齐性检验结果:F=0.225、P=0.638,P >0.05,因此两样本总体方差齐性;4、根据以上三点,统计方法选用成组设计两样本 t 检验,其假设检验过程如下: (1)建立假设检验,确立检验水准:H0:u1=u2,即两组的总体均数相同 H1:u1≠u2,即两组的总体均数不同 α=0.05(2)计算检验统计量t 值:ν=18+16-2=32 t = -1.818(3)确定 P 值,做出统计推断:P=0.078>0.05根据α=0.05的检验水准,不拒绝 H0,差异无统计学意义。
医学统计学试题及其答案 The latest revision on November 22, 2020l.统计中所说的总体是指: A A根据研究目的确定的同质的研究对象的全体B随意想象的研究对象的全体C根据地区划分的研究对象的全体D根据时间划分的研究对象的全体E根据人群划分的研究对象的全体2.概率P=0,则表示 B A某事件必然发生B某事件必然不发生C某事件发生的可能性很小D某事件发生的可能性很大E以上均不对3.抽签的方法属于 D A分层抽样B系统抽样C整群抽样D单纯随机抽样E二级抽样4.测量身高、体重等指标的原始资料叫: B A计数资料B计量资料C等级资料D分类资料E有序分类资料5.某种新疗法治疗某病患者41人,治疗结果如下:治疗结果治愈显效好转恶化死亡治疗人数82363 1 该资料的类型是: D A计数资料 B计量资料 C无序分类资料 D有序分类资料 E数值变量资料6.样本是总体的 C A有价值的部分B有意义的部分C有代表性的部分D任意一部分E典型部分7.将计量资料制作成频数表的过程,属于统计工作哪个基本步骤:C A统计设计B收集资料C整理资料D分析资料E以上均不对8.统计工作的步骤正确的是 C A收集资料、设计、整理资料、分析资料 B收集资料、整理资料、设计、统计推断C设计、收集资料、整理资料、分析资料 D收集资料、整理资料、核对、分析资料E搜集资料、整理资料、分析资料、进行推断9.良好的实验设计,能减少人力、物力,提高实验效率;还有助于消除或减少: B A抽样误差B系统误差C随机误差D责任事故E以上都不对10.以下何者不是实验设计应遵循的原则 DA对照的原则B随机原则C重复原则D交叉的原则E以上都不对第八章数值变量资料的统计描述11.表示血清学滴度资料平均水平最常计算 B A算术均数B几何均数C中位数D全距E率12.某计量资料的分布性质未明,要计算集中趋势指标,宜选择 CA XB GC MD SE C V13.各观察值均加(或减)同一数后: B A均数不变,标准差改变B均数改变,标准差不变C两者均不变D两者均改变E以上均不对14.某厂发生食物中毒,9名患者潜伏期分别为:16、2、6、3、30、2、lO、2、24+(小时),问该食物中毒的平均潜伏期为多少小时 CA5B5.5C6D10E1 2 15.比较12岁男孩和18岁男子身高变异程度大小,宜采用的指标是:DA全距B标准差C方差D变异系数E极差16.下列哪个公式可用于估计医学95%正常值范围 AA X±B X±Cμ±Dμ±,υS X E X±17.标准差越大的意义,下列认识中错误的是 B A观察个体之间变异越大B观察个体之间变异越小C样本的抽样误差可能越大D样本对总体的代表性可能越差E以上均不对18.正态分布是以 E A t值为中心的频数分布B参数为中心的频数分布C变量为中心的频数分布D观察例数为中心的频数分布E均数为中心的频数分布19.确定正常人的某项指标的正常范围时,调查对象是 B A从未患过病的人B排除影响研究指标的疾病和因素的人C只患过轻微疾病,但不影响被研究指标的人D排除了患过某病或接触过某因素的人E以上都不是20.均数与标准差之间的关系是 E A标准差越大,均数代表性越大B标准差越小,均数代表性越小C均数越大,标准差越小 D均数越大,标准差越大E标准差越小,均数代表性越大第九章数值变量资料的统计推断21.从一个总体中抽取样本,产生抽样误差的原因是 AA总体中个体之间存在变异 B抽样未遵循随机化原则C被抽取的个体不同质 D组成样本的个体较少 E分组不合理22.两样本均数比较的t检验中,结果为P<,有统计意义。
※:算术均数:正态分布或近似正态分布;例:大多数正常生物的生理、生化指标(血红蛋白、白细胞数等)几何均数:非对称分布,按从小到大排列,数据呈倍数关系或近似倍数关系;如:抗体的平均滴度、药物的平均效价中位数:资料呈明显偏态分布、一端或两端无确定数值、资料的分布情况不清楚;如:某些传染病或食物中毒的潜伏期、人体的某些特殊测定指标(如发汞、尿铅等)全距:表示一组资料的离散程度※:X:正态分布或近似正态分布G:非正态分布、按大小排列后,各观察值呈倍数关系M:明显的偏态分布、资料一端或两端无确定值、资料情况分布不清楚S与CV均为离散趋势指标25、某厂发生食物中毒,9名患者潜伏期分别为:16、2、6、3、30、2、lO、2、24+(小时),问该食物中毒的平均潜伏期为多少小时:CA、5B、5.5C、6D、lOE、12※:按大小排列后为:30 24+ 16 10 6 3 2 2 2,取第5位的值,即为 6※:1.计算相对数的分母不宜过小;2.分析时不能以构成比代替率;3.正确计算平均率;4.相互比较时应注意可比性;5.样本率或构成比的比较应进行假设检验23.反映某一事件发生强度的指标应选用 DA 构成比B 相对比C 绝对数D 率E变异系数※:构成比:各组成部分构成比的总和为100%或1;相对比:方便两个指标的比较率:说明某现象发生的频率或强度24.反映事物内部组成部分的比重大小应选用 AA构成比 B 相对比C绝对数D率E变异系数25.计算标化率的目的是 DA使大的率变小, B使小的率变大 C使率能更好的代表实际水平D消除资料内部构成不同的影响,使率具有可比性 E起加权平均的作用26.在两样本率比较的X2检验中,无效假设(H0)的正确表达应为 CA μ1≠μ2B μ1=μ2 c π1=π2 D π1≠π2 E B=C※:卡方检验的H0假设应用π,u t q等检验均用μ率的比较用π,均数的比较用μ27.四格表中四个格子基本数字是 DA两个样本率的分子和分母B两个构成比的分子和分母C两对实测数和理论数D两对实测阳性绝对数和阴性绝对数 E两对理论数28、相对数使用时应注意以下各点,除了:EA、分母不宜过小B、不要把构成比当率分析C、可比性D、比较时应作假设检验E、平均水平与变异程度29、某种职业病检出率为:DA、100/100 ρ100/100B、检出病人数/在册人数ρ实有病人数/受检人数100/100 ρC、实存病人数/在册人数 100/100D、检出人数/受检人数E、以上全不对ρ30、说明一个地区死亡水平的指标主要是:DA.病死率B.死因构成比C.死因顺位D.死亡率E.上述都不对31、相对数中的构成指标是说明: BA.反映事物发生的严重程度B.事物内部构成比重C.两个有关指标的比 D.动态变化 E.以上都不是32、X2四格表中四个格子基本数字是:CA.两个样本率的分子与分母 B.两个构成比的分子与分母C.两对实测阳性绝对数和阴性绝对数 D.两对实测数和理论数 E.以上都不对33、四格表X2 检验的自由度是___。
基本概念:✓统计学✓研究的步骤✓变量分类✓频率与概率、小概率事件、小概率原理✓总体、个体、样本、样本含量✓总体参数、样本统计量✓随机✓同质、变异✓抽样误差下列变量中,属于定量变量的是()A性别B职业C血型D体重某医院某年口腔科就诊儿童的乳牙萌出时间资料属于()A定量资料B等级资料C计数资料D定性资料启东市癌症登记处1972年1月1日至2001年12月31日肺癌发病登记报告显示:30年间登记并经核实肺癌病例8167例,其中男性5859例,女性2308例。
该资料属于()A计量资料B计数资料C半定量资料D定量资料)A定性资料B定量资料C等级资料D计量资料某医师研究肝硬化患者血浆肾素活性,将患者按腹水程度分为大量腹水、有腹水、无腹水3组,比较这3患者血浆肾素活性有无差别。
则该资料类型是()A 计量资料B 计数资料C 定量资料D 等级资料 正态分布的性质正态曲线下面积的分布规律 参考值范围确定的原则和方法表示总体均数的标准误。
( ) 表示样本均数的标准误。
( )同一批数值变量资料的标准差不会比标准误大。
( )即使变量X 偏离正态分布,只要每次抽样的样本数足够大,样本均数也近似服从正态分布。
( )表示( )A 总体标准差B 样本标准差C 抽样分布均数的理论标准差D 抽样分布均数的估计标准差表示 ( )A 总体均数的离散程度B 总体标准差的离散程度C 样本均数的离散程度D 样本标准差的离散程度从连续性变量X 中反复随机抽样,随样本含量增加 将趋于( ) A X 的原始分布 B 正态分布C 均数的抽样分布D 标准正态分布下面关于标准误的四种说法中,哪一种最不正确( )A 标准误是样本统计量的标准差B 标准误反映了样本统计量的变异C 标准误反映了总体参数的变异D 标准误反映了抽样误差的大小请简述标准差与标准误的区别和联系。
区别:公式标准差-个体变异、标准误-抽样误差联系:固定σ时,抽样误差与样本量成反比 均表示离散程度[个体值的,统计量的]xσx σx s x s xx s μ-下列说法正确吗?算得某95%的可信区间,则:总体参数有95%的可能落在该区间。
有95%的总体参数在该区间内。
该区间有95%的可能包含总体参数。
该区间包含总体参数,可信度为95%。
μ±1.96 区间内包含总体均数的概率为()A 95%B 97.5%C 99%D 100%x±1.96 区间内包含总体均数的概率为()A 95%B 97.5%C 99%D 100%随着样本含量的增加,以下说法正确的是()A 标准差逐渐变大B 标准误逐渐变大C 标准差逐渐变小D 标准误逐渐变小可信度1-α越大,则总体均数可信区间()A 越宽B 越窄C 不变D 还与第二类错误有关测得1096名飞行员的红细胞数(万/mm3),该资料服从正态分布,其均数为414.1,标准差为42.8,求得区间(414.1-1.64×42.8,414.1+1.64×42.8),称为红细胞数的()A 总体均数的95%可信区间B 95%参考值范围C 总体均数的90%可信区间D 90%参考值范围下列说法正确吗?☐P是H0成立的概率。
☐P是I 型误差的概率。
☐P是H0 成立时,获得现有差别的概率。
☐P是H0 成立时,获得现有差别以及更大的差别的概率。
☐P是统计推断时的风险。
☐P是拒绝H0时所冒的风险。
☐统计推断的内容是A.用样本指标推断总体指标B.检验统计上的“假设”C.A、B 均不是D.A、B 均是☐ 关于假设检验的P 值,下列说法正确的是 A P 是H 0成立的概率 B P 是 I 型误差的概率C P 是 H 0 成立时,获得现有差别的概率。
D 统计推断时的风险。
E 拒绝H 0时实际所冒的风险。
☐ 由两样本均数的差别推断两总体均数的差别,得到差别有统计学意义的结论,是指 A 两样本均数差别有统计学意义 B 两总体均数差别有统计学意义C 两样本均数差别和两总体均数差别都有统计学意义D 其中一个样本均数和它的总体均数差别有统计学意义☐ 通常可采用以下那种方法来减小抽样误差: A .减小样本标准差 B .减小样本含量 C .扩大样本含量 D .以上都不对⏹ 配对设计的目的: A .提高测量精度 B .操作方便C .为了可以使用t 检验D .提高组间可比性⏹ 10例男性矽肺患者的血红蛋白 (g/L ) 的均数为125.9(g/L ),标准差为16.3(g/L ),已知男性健康成人的血红蛋白正常值为140.2(g/L ),问矽肺患者的血红蛋白是否与健康人不同。
H 0:μ=140.2,矽肺患者的血红蛋白与健康人相同; H 1:μ≠140.2,矽肺患者的血红蛋白与健康人不同。
α=0.05∵t >t 0.05,9=2.262 ∴ P <0.05按α =0.05的水准,拒绝H 0,接受H 1,差别有统计学意义。
认为矽肺患者的血红蛋白与健康人不同。
本例自由度ν=10-1=9,经查表得t 0.05,9=2.262,则矽肺患者的血红蛋白总体均数的95%CI:(114.24,137.56)g/dl ,不包括男性健康成人的血红蛋白的总体均数140.2(mg/dl ),所以说矽肺患者的血红蛋白与健康人不同。
⏹ 某医院用某新药与常规药物治疗婴幼儿贫血,将20名贫血患儿随机等分两组,分2.7743t ===0.05,9125.9 2.262114.24(/)X X t s g L -⨯=-⨯=0.05,9125.9 2.26216.3/137.56(/)X X t s g L +⨯=+⨯=别接受两种药物治疗,测得血红蛋白增加量(g/L )如下,问新药与常规药物的疗效H 0 :1=2,新药与常规药物的疗效相同 ; H 1 :μ1≠μ2 ,新药与常规药物的疗效不同 。
双侧α =0.05。
ν=n 1+n 2-2=10+10-2=18➢ t 0.20,18=1.330,t <t 0.20,18,P >0.20,差别无统计学意义,故尚且不能认为新药与常规药物的疗效有所不同 。
将20名某病患者随机分为两组,分别用甲、乙两药治疗,测得治疗前后(治后一月)的血沉(mm/小时)如下。
试问:(1)甲乙两药是否均有效?(2)甲乙两药的疗效有无差别?分析思路➢ 疗前两组同质性比较,以分析可比性;➢ 各组疗前疗后差值比较,分别确定各自的疗效;➢ 两组疗前疗后差值相互比较,分析两组的效果是否相同? 两组药物降血沉效果(mm/小时)的比较 疗前 疗后 差值甲药 8.70±2.41 5.50±3.10 3.20±1.93 乙药 9.60±1.84 4.60±1.96 5.00±2.98 1.用均数与标准差可全面描述( )资料的特征。
A 、正偏态分布 B 、负偏态分布C 、正态分布和近似正态分布D 、对称分布0195.1)101101(21010)23.4923.79(9.206.2322=+-+⨯+⨯-=t2.描述一组偏态资料的变异度,以()指标较好。
A、全距B、标准差C、变异系数D、四分位间距3.正态分布曲线下,横轴上,从均数μ到μ+1.96倍标准差的面积为()A、95%B、45%C、7.5%D、47.5%4. 两样本均数比较,经t检验,差别有显著性时,p越小,说明()A、两样本均数差别越大B、两总体均数差别越大C、越有理由认为两总体均数不同D、越有理由认为两样本均数不同5.下面关于标准误的四种说法中,哪一种最不正确?()A、标准误是样本统计量的标准差B、标准误反映重复试验准确度的高低C、标准误反映总体参数的波动大小D、标准误反映抽样误差的大小6. 假设检验中的第二列错误是指()所犯的错误。
A、拒绝实际上成立的H0B、不拒绝实际上成立的H0C、拒绝实际上不成立的H0D、不拒绝实际上不成立的H07. 下列有关双侧t检验中的P值与α值的描述,()是不适当的。
A、P值是:在H0规定的总体中随机抽样,统计量t的绝对值≥现有样本t值(绝对值)的概率。
B、α值的大小是研究者指定的C、P值与α值的概念是相同的D、P<α时,接受H₁8.两样本均数比较的统计检验中,,统计学结论是()A、两样本均数不同B、两总体均数不同C、两总体均数差别有意义D、两样本均数相同9. 在同一总体随机抽样,其他条件不变,样本含量越大,则()A、样本标准差越大B、样本标准差越小C、总体均数的95%可性区间越窄D、总体均数的95%可性区间越宽10、各观察值都加上同一个数值后计算得到的()A.均数不变,标准差改变B. 均数改变,标准差不变C. 两者均改变D. 两者均不变11. 两样本均数的t检验,按0.05的检验水准拒绝H0,若此时推断有误,其错误的概率为()A.0.05B. >0.05C. <0.05D.不一定1.反映数据的平均水平的指标有哪些?用于何种情况?2.可信区间和参考值范围有何不同?3.简述中心极限定理的含义?资料分析题-1为了考察出生时男婴是否比女婴重,研究者从加州大学伯克利分校(UC Berkley )的儿童健康与发展研究中心随机抽取了12例白种男婴和12例白种女婴的出生资料(单位:磅)(1)该资料是数值变量资料还是分类资料? (2)要比较白种人男性与女性的出生体重是否不同,应当选用成组t 检验还是配对t 检验?(3) 经过计算t 值为2.16,已知自由度为22时,双侧面积0.05对应的t 界值为2.07,自由度为11时,双侧面积0.05对应的t 界值为2.20。
试写出假设检验的全过程并下结论。
1、数值变量资料(定量资料) 2、成组t 检验 3、H0: ,白种人男性与女性的出生体重总体均数相同; H1: ,白种人男性与女性的出生体重总体均数不同。
t=2.16t0.05,22=2.07,t>t0.05,22,P<0.05 按 水准,拒绝H0,接受H1,差别有统计学意义,可以认为白种人男性与女性的出生体重总体均数不同。
资料分析题-211名志愿者接受胆固醇试验,受试者在用药前后各测量一次血清胆固醇(mmol/l )数据如下,试判断此药是否有效?前6.11,6.81,6.48,7.59,6.42,6.94,9.17,7.33,6.94,7.67,8.15 后 6.00,6.83,6.49,7.28,6.30,6.64,8.42,7.00,6.58,7.22,6.57 1.该资料属于什么研究类型? 2.写出该假设检验的假设?3.若算得到t=2.8518,查表知自由度为10时,双侧面积0.05对应的t 界值为2.228,自由度为20时,双侧面积0.05对应的t 界值为2.086,请问如何下统计结论? 1、配对设计2、H0: ,用药前后血清胆固醇(差值总体均数)相同; H1: ,用药前后血清胆固醇(差值总体均数)不同。