北科SPSS软件练习试题
- 格式:doc
- 大小:445.00 KB
- 文档页数:16

spss练习题库SPSS(Statistical Package for the Social Sciences)是一款常用于统计分析的软件,它提供了丰富的功能和方法,能够帮助研究人员和数据分析师处理和分析大量数据。
为了帮助大家熟悉SPSS的使用,下面将提供一系列练习题,希望能够帮助读者更好地掌握SPSS的基本操作和数据分析技巧。
题目一:数据导入与数据管理1. 下载并导入"survey_data.csv"数据集2. 查看数据集的基本信息:变量名、数据类型、缺失值情况等3. 根据需要进行数据清洗和变量转换:删除无用变量、处理缺失值等题目二:描述性统计分析1. 计算各个变量的均值、标准差和分位数等统计量2. 绘制变量之间的散点图和箱线图,了解变量之间的关系和分布情况3. 利用交叉表进行统计分析,了解不同变量之间的相互影响题目三:假设检验和相关分析1. 对两个或多个样本进行独立样本t检验,比较不同组别之间的差异2. 对两个或多个变量进行相关分析,探究变量之间的关系3. 进行方差分析(ANOVA),比较多个组别之间的均值差异题目四:回归分析和预测建模1. 构建回归模型,探究自变量对因变量的影响程度和方向2. 进行多元回归分析,考察多个自变量对因变量的联合作用3. 通过预测建模,进行未来事件或结果的预测和分析题目五:聚类分析和因子分析1. 进行聚类分析,将数据集中的个体划分为若干互不重叠的组别2. 进行因子分析,提取潜在因子,简化数据集并解释变量之间的关系题目六:可视化分析和报告生成1. 利用SPSS的图表功能,绘制各种统计图表,如柱状图、饼图、雷达图等2. 利用SPSS的报告生成功能,整理和导出统计分析结果,并生成可供阅读和展示的报告通过以上练习题,读者可以逐步掌握SPSS的基本操作和常用分析方法,提高数据处理和分析的能力。
当然,除了练习题库中的内容,还可以根据自己的需求和实际情况,灵活运用SPSS进行更深入的数据分析和研究。

《spss统计软件》练习题库及答案XXX《SPSS统计软件》练题库及答案(本科)一、选择题(选择类)(A)1、在数据中插入变量的操作要用到的菜单是:AInsert Variable;BInsert Case;CGo to Case;DWeight Cases(C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是:ASort Cases;BSelect Cases;CCompute;DCategorize Variables(C)3、Transpose菜单的功能是:A对数据进行分类汇总;B对数据进行加权处理;C对数据进行行列转置;D按某变量分割数据(A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明:A.按照0.05显著性水平,拒绝H,说明三种城市的平均身高有差别;B.三种城市身高没有差别的可能性是0.043;C.三种城市身高有差别的可能性是0.043;D.申明城市不是身高的一个影响身分(B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A家庭主妇和女大学生对同种商品喜好的差异;B 服用某种药物前后病情的改变情况;C服用药物和没有服用药物的病人身体状况的差异;D性别和年龄对雇员薪水的影响二、填空题(填空类)6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。
7、用于对计数资料和有序分类资料进行统计描绘和简单的统计揣度,在分析时能够产生二维或多维列联表,在统计揣度时能进行卡方检修的菜单是_Crosstabs__。
8、One-Samples T Test过程用于进行样本地点总体均数___与__已知总体均数_的比较。
3、名词解释(问答类)9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。

SPSS实际操作练习题实习一SPSS基本操作第1题:请把下面的频数表资料录入到SPSS数据库中,并划出直方图,同时计算均数和标准差。
身高组段频数110~ 1112~ 3114~ 9116~ 9118~ 15120~ 18122~ 21124~ 14126~ 10128~ 4130~ 3132~ 2134~136 1解答:1、输入中位数(小数位0):111,113,115,117,....135;和频数1,3,. (1)2、对频数进行加权:DATA━Weigh Cases━Weigh Cases by━频数━OK3、Analyze━Descriptive Statistics━Frequences━将组中值加入Variable框━点击Statistics按钮━选中Mean和Std.devision━Continue━点击Charts按钮━选中HIstograms━Continue━OK第2题某医生收集了81例30-49岁健康男子血清中的总胆固醇值(mg/dL)测定结果如下,试编制频数分布表,并计算这81名男性血清胆固醇含量的样本均数。
219.7 184.0 130.0 237.0 152.5 137.4 163.2 166.3 181.7176.0 168.8 208.0 243.1 201.0 278.8 214.0 131.7 201.0199.9 222.6 184.9 197.8 200.6 197.0 181.4 183.1 135.2169.0 188.6 241.2 205.5 133.6 178.8 139.4 131.6 171.0155.7 225.7 137.9 129.2 157.5 188.1 204.8 191.7 109.7199.1 196.7 226.3 185.0 206.2 163.8 166.9 184.0 245.6188.5 214.3 97.5 175.7 129.3 188.0 160.9 225.7 199.2174.6 168.9 166.3 176.7 220.7 252.9 183.6 177.9 160.8117.9 159.2 251.4 181.1 164.0 153.4 246.4 196.6 155.4解答:1、输入数据:单列,81行。

spss大学考试题及答案一、选择题(每题2分,共20分)1. 在SPSS中,以下哪项不是数据视图(Data View)中的数据属性?A. 数字B. 日期C. 图片D. 标签答案:C2. SPSS中,用于描述性统计分析的命令是:A. AnalyzeB. TransformC. GraphD. File答案:A3. 在SPSS中,要进行t检验,应该选择以下哪个菜单?A. Analyze > Compare MeansB. Analyze > RegressionC. Analyze > Descriptive StatisticsD. Analyze > Nonparametric Tests答案:A4. 在SPSS中,如果需要计算一个变量的总和,应该使用以下哪个功能?A. ComputeB. AggregateC. AlgebraicD. Recode答案:B5. 在SPSS中,以下哪个命令用于因子分析?A. FactorB. ClusterC. Reliability AnalysisD. Canonical Correlation答案:A6. 要在SPSS中创建一个频率分布表,应该选择以下哪个命令?A. Analyze > Descriptive Statistics > FrequenciesB. Analyze > Descriptive Statistics > DescriptivesC. Analyze > Descriptive Statistics > ExploreD. Analyze > Descriptive Statistics > Crosstabs答案:A7. 在SPSS中,如果需要对数据进行排序,应该使用以下哪个命令?A. Sort CasesB. Rank CasesC. Order CasesD. Arrange Cases答案:A8. 在SPSS中,要进行卡方检验,应该选择以下哪个菜单?A. Analyze > Descriptive Statistics > CrosstabsB. Analyze > Compare Means > Independent-Samples T TestC. Analyze > Nonparametric Tests > Chi-SquareD. Analyze > Regression > Binary Logistic答案:C9. 在SPSS中,以下哪项不是数据录入时的变量属性?A. 变量类型B. 变量标签C. 缺失值D. 数据格式答案:D10. 在SPSS中,要进行相关性分析,应该选择以下哪个命令?A. Analyze > CorrelationB. Analyze > RegressionC. Analyze > FactorD. Analyze > Cluster答案:A二、简答题(每题5分,共30分)1. 描述SPSS中的数据录入过程。

spss考试题及答案1. 单选题:在SPSS中,以下哪个选项不是数据清洗的步骤?A. 缺失值处理B. 异常值检测C. 数据转换D. 数据备份答案:D2. 多选题:在SPSS中进行描述性统计分析时,可以输出哪些统计量?A. 均值B. 中位数C. 众数D. 标准差E. 方差答案:A, B, C, D, E3. 判断题:在SPSS中,使用“描述统计”功能可以计算出数据的峰度。
对错答案:错4. 填空题:在SPSS中,进行相关性分析时,可以使用_________菜单下的“相关性”选项。
答案:分析5. 简答题:请简述SPSS中因子分析的步骤。
答案:因子分析的步骤包括:a. 确定分析变量b. 进行KMO和Bartlett的球形度检验c. 选择提取方法(如主成分分析或因子分析)d. 确定因子数量e. 进行因子旋转(如需要)f. 解释因子6. 案例分析题:某研究者收集了一组数据,想要使用SPSS进行方差分析。
请描述方差分析的一般步骤。
答案:方差分析的一般步骤如下:a. 确定研究假设b. 选择合适的方差分析类型(如单因素方差分析或多因素方差分析)c. 输入数据并设置因子和因变量d. 进行方差分析e. 检查方差齐性f. 进行后续多重比较(如果需要)g. 解释结果7. 操作题:使用SPSS进行回归分析,并解释回归系数的意义。
答案:进行回归分析的步骤包括:a. 选择分析菜单下的回归选项b. 选择线性回归c. 设置因变量和自变量d. 运行回归分析e. 查看输出结果f. 解释回归系数,即自变量每变化一个单位,因变量预期的变化量以上即为SPSS考试题及答案的排版及格式。
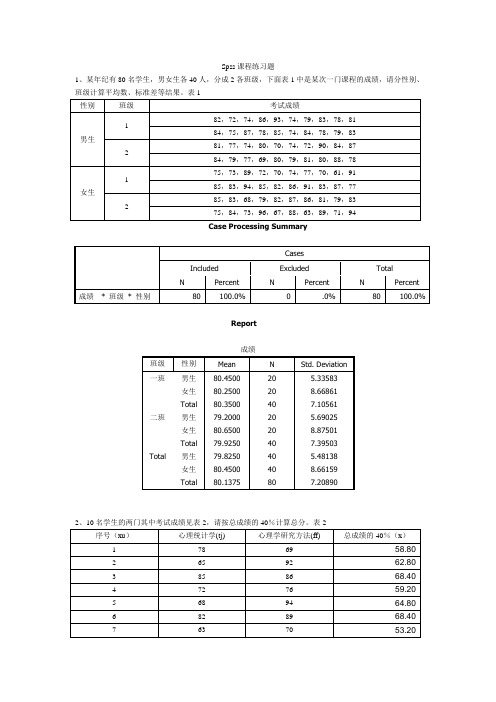
Spss课程练习题1、某年纪有80名学生,男女生各40人,分成2各班级,下面表1中是某次一门课程的成绩,请分性别、班级计算平均数、标准差等结果。
表1Case Processing SummaryReport成绩2、10名学生的两门其中考试成绩见表2,请按总成绩的40%计算总分。
表23、将表1中的数据合并,即不再分组,试整理成频数分布表,绘制出频数分布图,计算出常用的统计量。
Statistics成绩N Valid 80Missing 0Mean 80.1375Std. Error of Mean .80598Median 80.5000Mode 74.00(a)Std. Deviation 7.20890Minimum 61.00Maximum 96.00Sum 6411.00Percentiles 25 74.250050 80.500075 85.0000a Multiple modes exist. The smallest value is shown成绩F r e q u e n c y4、正常人的脉搏平均 数为72次/分。
现测得15名患者的脉搏:71,55,76,68,72,69,56,70,79,67,58,77,63,66,78 试问这15名患者的脉搏与正常人的脉搏是否有差异?One-Sample Test由结果可知,因为0.088>0.05,所以在p=0.05的显著性水平上差异不显著5、收集了20名学生的自信心值,见表3,试问该指标是否与性别有关?表3Independent Samples Test由数据可知,F检验的p=0.608>0.05,所以两组样本的方差差异不显著,所以t检验应该是Equal variances assumed一项进行判断。
双侧t检验的p=0.392>0.05,表示两个样本没有显著性差异4,试问两种训练方法的效果是否相同?表4注:x1、x2表示两组学生的跳高成绩,单位厘米(cm)配对样本T检验:Analyze -Compare Means -Paried-sample T TestPaired Samples CorrelationsPaired Samples Test由配对样本相关性检验可知,两样本相关性的p=0.00<0.05,因此两者存在相关性,由配对样本T检验的数据分析可得,两组数据的p=0.006<0.05所以两者之间在0.05的差异水平上差异显著7、为了探讨不同教法对英语教学效果的影响,将一个班级随机分成3组,接受3种不同的教法,英语成绩见表5,试问不同的教法之间是否存在着差异。
spss考试试题及答案一、选择题(每题2分,共20分)1. SPSS中,用于描述数据集中的观测值的中心趋势的统计量是:A. 方差B. 均值C. 标准差D. 众数答案:B2. 在SPSS中,以下哪个选项不是数据转换的方法?A. 计算变量B. 重新编码C. 描述统计D. 计算描述答案:C3. 在SPSS中,进行相关性分析的命令是:A. CORRELATEB. REGRESSIONC. T-TESTD. ANOVA答案:A4. SPSS中,用于创建新的变量或修改现有变量的命令是:A. COMPUTEB. DESCRIPTIVESC. AGGREGATED. RECODE答案:A5. 在SPSS中,用于比较两个独立样本均值差异的统计检验是:A. 卡方检验B. T检验C. 方差分析D. 相关性检验答案:B6. SPSS中,用于检查数据中是否存在缺失值的命令是:A. DESCRIPTIVESB. FREQUENCIESC. MISSING VALUESD. DETECT答案:A7. 在SPSS中,用于创建数据集的副本的命令是:A. SPLIT FILEB. SAVE ASC. TRANSPOSED. DATASET ACTIVATE答案:B8. SPSS中,用于生成数据集的频率分布表的命令是:A. DESCRIPTIVESB. FREQUENCIESC. CROSSTABSD. DESCRIPTIVES EXPLORE答案:B9. 在SPSS中,用于执行多重回归分析的命令是:A. REGRESSIONB. MANOVAC. FACTORD. CLUSTER答案:A10. SPSS中,用于绘制箱线图的命令是:A. CHARTSB. PLOTC. GRAPHD. EXAMINE答案:A二、简答题(每题5分,共20分)1. 请简述SPSS中数据清洗的步骤。
答案:数据清洗通常包括以下步骤:检查缺失值、异常值、错误数据,进行数据转换,以及数据标准化等。
Spss第 4 次作业第1题(1)【实验目的】学会用spss进行相关分析(2)【实验内容】1、对15家商业企业进行客户满意度调查,同时聘请相关专家对这15家企业的综合竞争力进行评分,结果如下表这些数据能否说明企业的客户满意度与综合竞争力存在较强的正相关关系?为什么?(3)【操作步骤】1.输入数据→图形→散点图/点图→选择“简单散点图”→定义→将“综合竞争得分”导入“Y轴”→将“客户满意度得分”导入“X轴”→确定;2.在数据输出窗口,双击图形空白处→元素→总计拟合线→线性→应用;3.分析→回归→线性→添加客户满意度得分到因变量,综合竞争力的分到自变量→确定(4)【输出结果】(5)【结果分析】拟合线性直线的方程为:y=10.86+0.86x, 相关系数r为0.864,当显著性水平α为0.01时拒绝原假设,表明两个变量(企业的客户满意度与综合竞争力)之前具有较强的线性关系,相关性显著。
第2题(1)【实验目的】学会用spss进行相关分析(2)【实验任务】绘制散点图,并计算相关系数,说明香烟消耗量与肺癌死亡率之间是否存在显著的相关关系。
(3)【操作步骤】1.输入数据→图形→散点图/点图→选择“简单散点图”→定义→将“1950年每百万男子中死于肺癌的人数”导入“Y轴”→将“1930年人均香烟消耗量”导入“X轴”→确定;2.在数据输出窗口,双击图形空白处→元素→总计拟合线→线性→应用;3.在数据编辑窗口,分析→相关→双变量→将“1930年人均香烟消耗量”、“1950年每百万男子中死于肺癌的人数”导入变量中→选项→选中“平均值和标准差”、“叉积偏差和协方差”→继续→确定。
(4)【输出结果】(5)【结果分析】回归分析显著性为0.202,皮尔逊相关系数相差较大,可能是有最后几组差异较大的数据点所影响。
线性回归方程:1950年每百万男子中死于肺癌人数=67.561+ 1930年人均香烟消耗量*0.228。
第3题(1)【实验目的】学会用spss进行相关分析(2)【实验任务】变量之间的关系,应对数据如何处理后再绘图?(2)选择恰当的统计方法分析销售额与销售价格之间的相关关系。
spss练习题(打印版)SPSS练习题一、选择题1. 在SPSS中,数据视图(Data View)显示的是:- A. 变量标签- B. 变量名- C. 观察值- D. 变量类型2. 以下哪个命令可以用来计算描述性统计量?- A. `DESCRIPTIVES`- B. `FREQUENCIES`- C. `CORRELATIONS`- D. `T-TEST`3. 如果你想要在SPSS中查看数据集的变量信息,你应该使用:- A. `DATASET`- B. `VARIABLE`- C. `VIEW`- D. `INFO`二、填空题1. 在SPSS中,使用________命令可以进行变量的转换和计算。
2. 当你想要对数据进行分组分析时,可以使用SPSS的________功能。
3. 为了在SPSS中创建一个新的数据集,可以使用________命令。
三、简答题1. 描述如何在SPSS中进行单样本t检验,并解释其应用场景。
2. 解释在SPSS中使用交叉表(Crosstabs)的目的,并说明如何解读交叉表的结果。
四、操作题1. 假设你有一个包含学生成绩的数据集,变量包括:学生ID(ID),姓名(Name),数学成绩(Math),英语成绩(English)。
请写出在SPSS中计算数学和英语成绩平均值的步骤。
2. 如果你想要在SPSS中删除一个名为“Math”的变量,应该如何操作?参考答案一、选择题1. D2. A3. C二、填空题1. `COMPUTE`2. `SPLIT FILE`3. `SAVE AS`三、简答题1. 在SPSS中进行单样本t检验的步骤如下:- 首先,确保你的数据已经正确输入到SPSS的数据视图中。
- 选择“分析”菜单下的“比较均值”选项。
- 选择“单样本t检验...”。
- 将需要检验的变量移动到“检验变量”框中。
- 在“测试值”框中输入你想要比较的均值。
- 点击“确定”进行检验。
单样本t检验通常用于检验单个样本的均值是否显著不同于已知的总体均值。
Spss试题(附解答和Spss数据库)一、对某型号的20根电缆依次进行耐压试验,测得数据如数据1,试在α=0.10的水平下检验这批数据是否受到非随机因素干扰。
解:本题采用单样本游程检验的方法来判断样本随机性。
原假设:这批数据是随机的;备择假设:这批数据不是随机的。
SPSS操作:Analyze -> Nonparametric Test -> Runs数据分析结果如下表所示:Runs Test耐电压值aTest Value 204.55Cases < Test Value 10Cases >= Test Value 10Total Cases 20Number of Runs 13Z .689Asymp. Sig. (2-tailed) .491a. Median结果:-- Test Value:204.55(即上面Cut Point设置的值)-- Asymp. Sig.=0.491,即P值=0.491大于显著水平0.10,则接受原假设,即样本是随机抽取的,这批数据未收到非随机因素干扰。
1二、为研究吸烟有害广告对吸烟者减少吸烟量甚至戒烟是否有作用。
从吸烟者总体中随机抽取33位吸烟者,调查他们在观看广告前后的每天吸烟量(支)。
试问影片对他们的吸烟量有无产生作用,(见数据2)解:本题采用配对样本T检验的方法。
原假设:影片对他们的吸烟量无显著影响;备择假设:影片对他们的吸烟量有显著影响。
SPSS操作:Analyze -> Compare Means -> Paired-Samples T Test… 数据分析结果如下表所示:Paired Samples StatisticsMean N Std. Deviation Std. Error MeanPair 1 21.58 33 10.651 1.854 看前(支)17.58 33 10.680 1.859 看后(支)Paired Samples CorrelationsN Correlation Sig.Pair 1 33 .878 .000 看前(支) & 看后(支)Paired Samples TestPaired Differences95% ConfidenceInterval of the Std.Difference Sig. Std. ErrorMean Deviation Mean Lower Upper t df (2-tailed)Pair 1 看前(支) 4.000 5.268 .917 2.132 5.868 4.362 32 .000 - 看后(支) 由表可知,看前样本均值为21.58,看后样本均值为17.58,此外,p值为0.000<0.05,因此,拒绝原假设,接受备择假设,即在α=0.05显著性水平下,影片对他们的吸烟量有显著影响。
Spss第 4 次作业
第1题
(1)【实验目的】
学会用spss进行相关分析
(2)【实验内容】
1、对15家商业企业进行客户满意度调查,同时聘请相关专家对这15家企业的综合竞争力进行评分,结果如下表
编号客户满意度得分综合竞争力得分
1 90 70
2 100 80
3 150 150
4 130 140
5 120 90
6 110 120
7 40 20
8 140 130
9 10 60
10 20 30
11 80 100
12 70 110
13 30 10
14 50 40
15 60 50
这些数据能否说明企业的客户满意度与综合竞争力存在较强的正相关关系?为什么?
(3)【操作步骤】
1.输入数据→图形→散点图/点图→选择“简单散点图”→定义→将“综合竞争得分”导入“Y
轴”→将“客户满意度得分”导入“X轴”→确定;
2.在数据输出窗口,双击图形空白处→元素→总计拟合线→线性→应用;
3.分析→回归→线性→添加客户满意度得分到因变量,综合竞争力的分到自变量→确定
(4)【输出结果】
输入/除去的变量a
模型输入的变量除去的变量方法
1 综合竞争力得分b. 输入
a. 因变量:客户满意度得分
b. 已输入所请求的所有变量。
模型摘要
模型R R 方调整后 R 方标准估算的误差
1 .864a.747 .728 23.344
a. 预测变量:(常量), 综合竞争力得分
(5)【结果分析】
拟合线性直线的方程为:y=10.86+0.86x, 相关系数r为0.864,当显著性水平α为0.01时拒绝原假设,表明两个变量(企业的客户满意度与综合竞争力)之前具有较强的线性关系,相关性显著。
第2题
(1)【实验目的】
学会用spss进行相关分析
(2)【实验任务】
为研究香烟消耗量与肺癌死亡率的关系,收集到下表数据。
(3)【操作步骤】
1.输入数据→图形→散点图/点图→选择“简单散点图”→定义→将“1950年每百万男子中死
于肺癌的人数”导入“Y轴”→将“1930年人均香烟消耗量”导入“X轴”→确定;
2.在数据输出窗口,双击图形空白处→元素→总计拟合线→线性→应用;
3.在数据编辑窗口,分析→相关→双变量→将“1930年人均香烟消耗量”、“1950年每百万男子中死于肺癌的人数”导入变量中→选项→选中“平均值和标准差”、“叉积偏差和协方差”→继续→确定。
(4)【输出结果】
描述统计
平均值标准差个案数
客户满意度得分80.00 44.721 15
综合竞争力得分80.00 44.721 15
相关性
客户满意度得分综合竞争力得分客户满意度得分皮尔逊相关性 1 .864**
显著性(双尾)
.000
平方和与叉积28000.000 24200.000
协方差2000.000 1728.571
个案数15 15
综合竞争力得分皮尔逊相关性.864** 1
显著性(双尾)
.000
平方和与叉积24200.000 28000.000
协方差1728.571 2000.000
个案数15 15
**. 在 0.01 级别(双尾),相关性显著。
(5)【结果分析】
回归分析显著性为0.202,皮尔逊相关系数相差较大,可能是有最后几组差异较大的数据点所影响。
线性回归方程:1950年每百万男子中死于肺癌人数=67.561+ 1930年人均香烟消耗量*0.228。
第3题
(1)【实验目的】
学会用spss进行相关分析
(2)【实验任务】
(1)绘制销售额,销售价格以及家庭收入两两变量间的散点图,如果所绘制的图形不能比较清晰地展示变量之间的关系,应对数据如何处理后再绘图?
(2)选择恰当的统计方法分析销售额与销售价格之间的相关关系。
(3)【操作步骤】
步骤:图形>旧对话框>散点图>矩阵散点图>定义>添加销售额(万元),销售价格(元)家庭收入(元)>确定
步骤:分析>相关>双变量>销售价格,家庭收入,销售额添加到变量中>选择皮尔逊相关系数>选择双尾显著性检验>确定>>
(4)【输出结果】
相关性
销售价格(元)家庭收入(元)销售额(万元)
销售价格(元)皮尔逊相关性 1 -.857**-.933**
显著性(双尾)
.002 .000
个案数10 10 10
家庭收入(元)皮尔逊相关性-.857** 1 .880**
显著性(双尾)
.002 .001
个案数10 10 10
销售额(万元)皮尔逊相关性-.933**.880** 1
显著性(双尾)
.000 .001
个案数10 10 10
**. 在 0.01 级别(双尾),相关性显著。
(5)【结果分析】
1.从相关性分析表中得出:销售价格与家庭收入与销售额三者两两相关,并且皮尔逊相关系数绝对值较
大成很强的相关性。
2. 结论分析:如图所拟合的直线,销售额与销售价格由较强的负相关。
回归分析
第4题
(1)【实验目的】
学会用spss进行回归分析
(2)【实验任务】
1、数据学生成绩一.sav 和学生成绩二.sav ,任意选择两门成绩作为解释变量和被解释变量,利用
SPSS提供的绘制散点图功能进行一元线性回归分析,请绘制全部样本以及不同性别下两门成绩的散点图,并在图上绘制三条回归直线,其中,第一条针对全体样本,第二条和第三条分别针对男生样本和女生样本,并对各回归直线的拟合效果进行评价。
(3)【操作步骤】
打开“学生成绩一.sav”→图形→散点图/点图→简单散点图→定义→将数据导入“X轴”、“Y轴”→确定;在查看器中→图形→激活;→选择元素→总计拟合曲线和子组拟合曲线。
分析→回归→线性→将数据导入“因变量”、“自变量”→统计→选中“共线性诊断”→继续→确定。
(4)【输出结果】
(5)【结果分析】
上表得出,不论是总体拟合效果还是男女分类拟合效果,都比较差,这说明,这两门成绩的相关性弱。
第5题
(1)【实验目的】
建立多元线性回归方程,分析影响的主要因素。
(2)【实验任务】
请先收集若干年粮食总产量以及播种面积,使用化肥量,农业劳动人数等数据,然后建立多元线性回归方程,分析影响粮食总产量的主要因素,数据文件“粮食总产量.sav”
(3)【操作步骤】
分析—回归—线形
(4)【输出结果】
(5)【结果分析】
结论分析:从最后的系数的分析表中得出,其中施用化肥量与粮食总产量的相关性最大。
第6题
(1)【实验目的】
完成下列题目
(2)【实验任务】
一家产品销售公司在30个地区设有销售分公司。
为研究产品销售量(y)与销售价格(x1)各地区的人均收入(x2),广告费用(x3)之间的关系,搜集到30个地区的有关数据。
进行多元回归分析所得的结果如下:
表1
表2
a)将表 1 中的数据补齐.
如图一
b)写出销售量与销售价格,年人均收入,广告费用的多元线性回方程,并解释各回归系数的意义。
Y=-117.9X1+80.6X2+0.5012X3+7589.1
c)检验回归方程的线性关系是否显著。
显著
d)检验各回归系数是否显著,
均小于0.05,显著
e)计算判定系数,并解释它的实际意义。
12026774.1/13458586.7=0.91
表明回归方程对样本数据点拟合优度高。
第7题
(1)【实验目的】
用spss预测数据,并估计误差
(2)【实验任务】
试根据“粮食总产量.sav”数据,利用SPSS曲线估计方法选择恰当的模型,对样本期外的粮食总产量进行外推预测,并对平均预测预测误差进行估计。
(3)【操作步骤】
图形,旧对话框,线图,简单,个案组摘要,定义,类别轴选择“年份”,其他统计量变量选择“粮食总产量”。
确定
步骤:分析,回归,曲线估计,将“粮食总产量”导入因变量。
选择时间,选择二次项和指数分布。
保存,确定。
(4)【输出结果】
二次
指数
(5)【结果分析】
分析1 :由线图可以看出,粮食总产量非线性增加,因此,可以通过曲线估计进行分析。
所以在用二次曲线和指数曲线拟合。
分析2:指数曲线模型,明显优于二次曲线模型,
所以利用指数模型进行合理预测未来粮食总产量。