层次分析法例题资料讲解
- 格式:docx
- 大小:94.14 KB
- 文档页数:9

层次分析法例题详解
例题:假设一家公司想要改善客户满意度,以下是几项建议:
A. 增加客户服务
B. 提高产品质量
C. 提高客户服务质量
层次分析法:
1.首先,将上述三项建议放入一个表格中,比较它们之间的关系。
建议 | 增加客户服务 | 提高产品质量 | 提高客户服务质量
------|-----------------|------------------|------------------------
关系 | 相关 | 相关 | 直接相关
2.然后,根据上表的关系,将建议分类:
A. 增加客户服务和提高客户服务质量:这两项建议直接相关,可以归为一类,即增加客户服务和提高客户服务质量。
B. 提高产品质量:这一项建议与其他两项建议相关,但不属
于同一类别,可以独立归类。
3.最后,根据分类的结果,提出有效的解决方案:
A. 增加客户服务和提高客户服务质量:可以采取措施增加客
户服务人员的数量,同时提高客户服务质量,如培训客服人员,
提升服务水平。
B. 提高产品质量:可以采取措施改善产品质量,如改进生产流程,提高材料质量,以及实施质量控制等。

二、AHP 求解层次分析法(Analytic Hierarchy Process )是一种定量与定性相结合的多目标决策分析法, 将决策者的经验给予量化,这在对目标(因素)结构复杂且缺乏必要数据的情况下较为实用。
(一)、建立递阶层次结构目标层:最优生鲜农产品流通模式。
准则层:方案的影响因素有:c 1自然属性、c 2经济价值、C 3基础设施、c 5政府政策。
方案层:设三个方案分别为:A i 农产品产地一产地批发市场一销地批发市场一消费者、A 2农产品产地一产地批发市场一销地批发市场一农贸市场一消费者、A 3农业合作社一第三方物流企业一超市一消费者(本文假设农产品的生产地和销地不在同一个地区 )。
A 3图3— 1递阶层次结构(二)、构造判断(成对比较)矩阵所谓判断矩阵是以矩阵的形式来表述每一层次中各要素相对其上层要素的相对重要程度。
为目标层:G :最优生鲜农产品流通模式准则层:自然属性经济价值基础设施政府政策方案层:了使各因素之间进行两两比较得到量化的判断矩阵,弓I入1〜9的标度,见表3—1.为了构造判断矩阵,作者对6个专家进行了咨询,根据专家和作者的经验,四个准则下的两两比较矩阵分别为:(三)、层次单排序及其一致性检验层次单排序就是把本层所有要素针对上一层某一要素,排出评比的次序,这种次序以相对的数值大小来表示。
对应于判断矩阵最大特征根入max的特征向量,经归一化(使向量中各元素之和等于1)后记为W。
W的元素为同一层次因素对于上一层次因素某因素相对重要性的排序权值,这一过程称为层次单排序。
能否确认层次单排序,需要进行一致性检验,所谓一致性检验是指对A确定不一致的允许范围。
由于入连续的依赖于a ij,则入比n大的越多,A 的不一致性越严重。
用最大特征值对应的特征向量作为被比较因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。
因而可以用入一n数值的大小来衡量A的不一致程度。
用一致性指标进行检验:CImax nCRCI RI用一致性指标进行检验:CI 工 n。


层次分析法实例讲解学习生活实际例题:旅游实例,有三个旅游地点供游客们选择,连云港,常州,徐州。
影响游客们决策的因素主要有以下五项:景色、费用、居住、饮食、旅途。
请根据个人偏好选择最佳旅游地点。
分析 : 旅游点是方案层,将它们分别用B1 , B2, B3表示,影响旅游决策的因素为准则层 A1, A2, A3 , A4 , A5;目标层为选择旅游地,即可以建立以下模型:选择旅游地景色费用居住饮食旅途连云港常州徐州建立判断矩阵:准则层判断矩阵(即各种因素在旅客偏好选择中所占有的不同比重):1 1/2 43321755A1/ 41/ 711/ 21/ 31/3 1/5 2111/3 1/5 311方案层判断矩阵建立(针对每一个影响因素来对方案层建立):12511/31/8113B1 1/212B1311/3 B11131/ 51/2 18311/3 1/3 1134111/4B1 1/311B1111/41/411441求准则层判断矩阵 A 的特征值:Matlab 运行程序:[a,b]=eig(A)‘ 矩b ’阵的对角线为准则层判断矩阵 A 的特征值:5.0730 0 0 00.0310 0 b0 0 0.0310 0 0 0 0 0.005 00.005即 1 5.073,20.031,30.031,40.005, 50.005选出最大特征值:max (1, 2, 3, 4,5)1最大特征值的特征向量即为准则层的影响因素所占的权重, 所对应的特征向量为:w 1- 0.4658 - 0.8409 - 0.0951 - 0.1733 - 0.1920归一化(最简 matlab 程序为 w=w1./sum(w1) )w0.2636 0.4759 0.0538 0.0981 0.1087一致性指标的检验:由 max 是否等于 5 来检验判断矩阵 A 是否为一致矩阵。
由于特征根连续地依赖于矩阵 A 中的值 ,故 max 比 5 大得越多, A 的非一致性程度也就越严重,max 对应的标准化特征向量也就越不能真实地反映出对因素 A i (i 1, ,5) 的影响中所占的比重。


旅游业发展水平评价问题摘要为了研究比较两个旅游城市Q、Y的旅游业发展水平,建立层次分析法]3[数学模型,对两个旅游城市Q、Y的旅游业发展水平进行了评价.首先,通过对题目中的图1、表1进行了分析与讨论,根据层次分析法,建立了目标层A、准则层B和子准则层C、方案层D四个层次,通过同一层目标之间的重要性的两两比较,得出判断矩阵,利用]1[MATLAB编程对每个判断矩阵进行求解.其次,用MATLAB软件算出决策组合向量,再比较决策组合向量的大小,由“决策组合向量最大”为目标,得出城市Y的决策组合向量为0.4325,城市Q组合向量为0.5675.最后,通过城市Q旅游业发展水平与旅游城市Y旅游业发展水平的决策组合向量比较,得出城市Q的旅游业发展水平较高.关键词层次分析法MATLAB旅游业发展水平决策组合向量1.问题重述本文要求分析QY,两个旅游城市旅游业发展水平,并且给出了两个城市各方面因素的对比,如城市规模与密度,经济条件,交通条件,生态环境条件,宣传与监督,旅游规格,空气质量,城市规模,人口密度,人均GDP,人均住房面积,第三产业增加值占GDP比重,税收GDP,外贸依存度,市内外交通,人均拥有绿地面积,污水集中处理率,环境噪音,国内外旅游人数,理赔金额,立案数量,A级景点数量,旅行社数量,星级饭店数量.建立数学模型进行求解.2.问题分析本文要求分析QY,两个城市的分析Y,两个旅游城市旅游业发展水平,在对Q中,发现需要考虑因素较多,第一、城市规模与密度,包括城市规模与人口密度.第二、经济条件,包括外贸依存度,人均GDP,人均住房面积,第三产业增加值占GDP比重,税收GDP.第三、交通条件,包括市内外交通.第四,生态环境条件包括空气质量,人均绿地面积,污水处理能力,环境噪音.第五、宣传与监督,包括国内外旅游人数,游客投诉立案件数.第六、旅游规格,包括A级景点个数,旅行社个数,星级饭店个数,这就涉及到层次分析法来估算各个指标的权重,评出最优方案.具体内容如下:(1)本文选择了对QY,两个旅游城市旅游业发展水平有影响的19个指标作为评价要素,指标规定如下:城市规模:城市的人口数量.人口密度:单位面积土地上居住的人口数.是反映某一地区范围内人口疏密程度的指标.人口影响城市规模.人口密度越大城市规模也就越大.人均GDP:即人均国内生产总值.人均城建资金:即用于城市建设的资金总投入.第三产业增加值:增加值率指在一定时期内单位产值的增加值.即第三产业增加值越高越能带动城市经济的发展.税收GDP:税收是国家为实现其职能,凭借政治权力,按照法律规定,通过税收工具强制地、无偿地征收参与国民收入和社会产品的分配和再分配取得财政收入的一种形式.外贸依存度:即城市对于外贸交易的依赖程度.市内交通:即城市市区交通情况.市外交通:即城市郊区交通情况.市内交通与市外交通对于城市交通条件具有同等的重要性.空气质量:即城市总体空气质量情况.空气质量越好对于城市生态环境就越好.人均绿地面积:即反应城市绿化面积以及人口密度的比值关系.污水处理能力:城市污水处理水平.环境噪音:城市环境噪音情况.国内外旅客人数:国内外来旅客一年总人数.人数越多说明宣传与监督就越好.理赔金额:即立案后需要赔付的资金数.立案件数:即在旅游时发生违法事件后公安部立案的件数.A 级景点数量:即A 级景点的个数.A 级景点越多,越能带动旅行社数量以及星级饭店数量,则旅游规格越大.旅行社数量:即旅行社的个数.星级饭店数量:即星级饭店在旅游景点的个数.(2)用层次分析法建立模型,根据判断矩阵,利用MATLAB 软件,算出每个判断矩阵的特征向量W 、最大特征根c 、一次性指标CI ,再结合随机一次性指标,得出每个指标的特征向量.(3)用(2)得出的数据,运用MATLAB 软件算出两个城市的决策组合向量,做比较.3.模型假设1.假设两个城市Q 、Y 的人口流动不大.2.假设两个城市Q 、Y 的各项指标短期内不会发生太大的改变.4.符号说明A : 表示目标层;j B : 表示准则层第j 个指标的名称)6,,2,1( =j ;i C : 表示子准则层第i 个指标的名称()19,,2,1 =i ; q D : 表示方案层第q 个指标的名称()2,1=q ;1w : 表示准则层对目标层的特征向量组成的矩阵; 2w : 表示子准则层对准则层的特征向量组成的矩阵; 3w : 表示方案层对子准则层的特征向量组成的矩阵;CI : 表示一次性指标;CR : 表示随机一次性指标; Z : 表示决策组合向量.5.模型建立与求解5.1 根据层次分析法分析以及题目中的图1可以建立如下表5-1的层次分析结构,并构造两两比较判断矩阵在递阶层次结构中,设上一层元素B 为准则层,所支配的下一层元素为1C ……19C ,要确定元素1C ……n C 对于准则层B 相对的重要性即权重,可分为两种情况:(1)如果1C 2C ……n C 对B 的重要性可定量,其权重可直接确定; (2)如果问题复杂,1C 2C ……n C 对B 的重要性无法直接定量,而是一些定性的,确定权重用两两比较方法.(3)其方法是,对于准则层C ,元素i C 和j C 哪一个更重要,重要多少,按1-9比例标度对重要性程度赋值.表5-2中列出了1-9标度的含义.对于准则B ,n 个元素之间相对重要性的比较得到一个两两比较判断矩阵P =()mxn ij P ,表示其中ij P 表示i P 和j P 对B 的影响之比,显然ij P >0,ij P =ijP 1,ij P =1,由ij P 的特点,P 称为正互反矩阵.通过两两判断矩阵用方根法求出他们的最大特征根和特征向量,求法如下: 1. 判断矩阵每一行元素的乘积,其中ij n1j 1p m =∏=,i =1,2…,n .2. 计算i m 的n 次方根_i w ,_i w =n i m .3. 对向量Tn w w w ⎪⎭⎫ ⎝⎛=__1,...,归一化,即∑==n j ji w 1__i w w ,则Tn w w w ⎪⎭⎫⎝⎛=__1,.为所求的特征向量.4. 计算判断矩阵的最大特征跟max λ,()∑==n1max i iinw pw λ,式中()i pw 表示pw 的第i 个元素.5. 定义⎪⎭⎫ ⎝⎛--=1max n n CI CI λ为矩阵A 的一致性指标,为了确定A 的不一致性程度的容许范围,需要找出衡量A 的一致性指标CI 的标准.引入随机一致性指标RI .平均随机一致性指标RI 是这样得到的;对于固定的n ,随机构造正互反矩阵A ,其中ij a 是从1,2,……9,91......31,21中随机抽取的,这样的A 是最不一致的,取充分大的样子(500个样本)得到A 的最大特征跟的平均值max λ,定义⎪⎭⎫ ⎝⎛--=1max n n RI λ,对于不同的n 得出随机一致性指标RI 的数值如下表5-3表中n =1,2时RI =0,是因为1,2阶的正互反矩阵总是一致阵.令RICICR =,称CR 为一致性比率,当CR <0.1时,本文认为判断矩阵具有满意的一致性,否则就需要调整判断矩阵,使之具有满意的一致性.最后通过计算得出下表5-4(其中n B 表示准则层的特征向量中的第n 个数值,in C 表示指标层的特征向量第n 个准则对第j 个指标的数值)层次总排序一致性检验的方法j n1CI c CI j j ∑==j n 1c RI RI j j ∑==RICI CR =若1.0CR时,所以认为判断矩阵具有满意的一致性,否则就需要调整判断.矩阵,使之具有满意的一致性.5.2根据层次分析法求出各个指标的权重依据题目中的表1分析,对本题做出其中一种假设:(1)经济条件和交通条件重要性相当,生态环境条件最重要,旅游规格、宣传与监督、城市规模与密度依次次之.(2)在城市规模与密度中,城市人口比人口密度重要一点.(3)在经济条件中,第三产业增加值GDP第一重要,其次是人均GDP,税收GDP、外贸依存度、人均城建资金依次次之.(4)在交通条件中,市内交通和市外交通的重要性相当.(5)在生态环境条件中,空气质量第一重要,其次是人均绿地面积,污水处理能力、环境噪音依次次之.(6)在宣传与监督中,国内外旅游人数第一重要,理赔金额、游客投诉立案件数重要性相当.(7)在旅游规格中,A级景点个数第一重要,星级饭店个数、旅行社个数依次次之.(8)对于城市规模,城市Q比城市Y的重要性小一些;对于人口密度,城市Y比城市Q的重要性明显重要;对于人均GDP,城市Q比城市Y的重要性稍重要;对于人均城建资金,城市Q比城市Y的重要性稍微重要;对于第三产业增加值GDP,城市Q比城市Y的重要性小一些;对于税收GDP,城市Q比城市Y的重要性稍小一点;对于外贸依存度,城市Q比城市Y的重要性稍重要;对于市内交通,城市Y比城市Q的重要性稍重要一点;对于市外交通,城市Y比城市Q的重要性比稍重要小一点;归于空气质量,城市Q比城市Y的重要性相当;对于人均绿地面积,城市Y比城市Q的重要性稍重要;对于污水处理能力,城市Y比城市Q的重要性稍重要一些;对于环境噪音,城市Q比城市Y的重要性相当;对于国内外旅游人数,城市Q比城市Y的重要性稍重要;对于理赔金额,城市Q比城市Y的重要性稍重要一些;对于游客投诉立案件数,城市Q比城市Y的重要性稍重要;对于A级景点个数,城市Y比城市Q的重要性稍重要小一些;对于旅行社个数,城市Y比城市Q的重要性稍重要小一些;对于星级饭店个数,城市Q比城市Y的重要性相当.根据上述分析,按1-9比例标度对准则层对目标层、子准层对准则层、目标层对子准则层的重要程度进行赋值,构造准则层对目标层的判断矩阵、子准则层对准则层的判断矩阵、方案层对子准则层的判断矩阵.准则层()6,,2,1 =j B j 对目标层A 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=12312121321141313123412252321114232111431215141411A 利用MATLAB 软件(附录1)求得 最大特征值0719.6m ax =λ特征向量⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=1219.00753.03422.02057.02057.00492.01w一致性检验比率1.00116.0<=CR所以矩阵满足一致性检验.子准则层21,C C 对准则层1B 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=131311B利用MATLAB 软件(附录2)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 子准则层76543,,,,C C C C C 对准则层2B 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=121412312131321431522131511413221412B 利用MATLAB 软件(附录3)求得 最大特征值0681.5m ax =λ特征向量⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=0973.01599.04185.00618.02625.0w一致性检验比率1.00152.0<=CR所以矩阵满足一致性检验.子准则层98,C C 对准则层3B 的判断矩阵⎥⎦⎤⎢⎣⎡=11113B 利用MATLAB 软件(附录4)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 子准则层13121110,,,C C C C 对准则层4B 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎣⎡=1121311121312212133214B 利用MATLAB 软件(附录5)求得最大特征值0104.4m ax =λ特征向量⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=1409.01409.02628.04554.0w 一致性检验比率1.00038.0<=CR所以矩阵满足一致性检验.子准则层161514,,C C C 对准则层5B 的判断矩阵⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=1221211212215B 利用MATLAB 软件(附录6)求得最大特征值0536.3m ax =λ特征向量⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=3108.01958.04934.0w 一致性检验比率1.00462.0<=CR所以矩阵满足一致性检验.子准则层191817,,C C C 对准则层6B 的判断矩阵⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=1221211312316B 利用MATLAB 软件(附录7)求得最大特征值0092.3m ax =λ特征向量⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=2970.01634.05396.0w 一致性检验比率1.00079.0<=CR所以矩阵满足一致性检验.方案层对子准则层的判断矩阵 方案层21,D D 对子准则层1C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=122111C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层2C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=155112C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎢⎣=1667.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层3C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=133113C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层4C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=144114C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层5C 的判断矩阵:⎥⎥⎦⎤⎢⎢⎣⎡=122115C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎢⎣=3333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层6C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=133116C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层7C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=141417C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层8C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=155118C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎢⎣=8333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层9C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=122119C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层10C 的判断矩阵⎥⎦⎤⎢⎣⎡=111110C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层11C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1313111C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=7500.02500.0w因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层12C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1414112C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2000.08000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层13C 的判断矩阵⎥⎦⎤⎢⎣⎡=111113C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层14C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331114C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验.2115⎥⎥⎦⎤⎢⎢⎣⎡=1441115C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层16C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331116C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层17C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331117C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验.2118⎥⎥⎦⎤⎢⎢⎣⎡=1221118C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子19C 的判断矩阵: ⎥⎦⎤⎢⎣⎡=111119C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 通过准则层()6,,2,1 =j B j 对目标层A 的判断矩阵、子准则层()19,,2,1 =i C i 对准则层()6,,2,1 =j B j 的判断矩阵得出特征向量,建立层次总表5-5层次总排序一致性检验如下:0073.061==∑=j j j CI B CI65274.0j 61j j ==∑=RI B RI0111.065274.00073.0===RI CI CR 由于1.00111.0<=CR ,所以认为层次总排序的结果具有满意的一致性,因此不需要重新调整判断矩阵的元素取值.5.3 利用MATLAB 进行决策组合向量的运算(附录9)⋅⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=⋅⋅=Tw w w Z 2970.0001634.0000005396.00000003108.0000001958.0000004934.00000001409.0000001409.0000002628.0000004554.00000005000.0000005000.00000000973.0000001599.0000004185.0000000618.0000002625.00000002500.0000007500.0132⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡5000.05000.06667.03333.06667.03333.02500.07500.08000.02000.02500.07500.05000.05000.02000.08000.07500.02500.05000.05000.06667.03333.01667.08333.08000.02000.02500.07500.06667.03333.02000.08000.02500.07500.08333.01667.03333.06667.0⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡⋅1219.00753.03422.02057.02057.00492.0 Z ⎥⎦⎤⎢⎣⎡=5675.04325.0 比较Z 值大小可知,12Z Z >,表明城市Q 的旅游发展也水平最高,城市Y 的旅游业发展水平次之,所以城市Q 的旅游发展也水平高.6模型的评价优点:(1) 本文选择了计算比较简单的层次分析法,经过计算得到了相应的综合发展旅游业的估计值,为城市旅游业的发展提供了依据.(2) 使用了MATLAB 软件,减少了计算工作量,大大降低了运算的困难.缺点:判断的结果具有一定的主观性,不能比较切实的结合当地的具体情况,做出科学的决策方案.7参考文献[1] 姜启源等,数学建模(第四版)北京:高等教育出版社.2011年[2] 马莉,数学实验与建模,北京:清华大学出版2010年[3] 王莲芬,层次分析法引论,北京:中国人民大学出版社,1990年附录:附录1x=[1 1/4 1/4 1/5 1/2 1/3;4 1 1 1/2 3 2;4 1 1 1/2 3 2;5 2 2 1 4 3;2 1/3 1/3 1/4 1 1/2;3 1/2 1/2 1/3 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-6)/5 %一致性指标CR=CI/1.24 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =6.0719W =0.04920.20570.20570.34220.07530.1219B =0.04670.21410.21410.29180.08810.1452CI =0.0144CR =0.0116C =0.2146附录2:>> x=[1 3;1/3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250附录3:x=[1 4 1/2 2 3;1/4 1 1/5 1/3 1/2;2 5 1 3 4;1/2 3 1/3 1 2;1/3 2 1/4 1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-5)/4 %一致性指标CR=CI/1.12 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =5.0681W =0.26250.06180.41850.15990.0973B =0.27340.05940.36640.18730.1135CI =0.0170CR =0.0152C =0.2698附录4:x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000附录5:x=[1 2 3 3;1/2 1 2 2;1/3 1/2 1 1;1/3 1/2 1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-4)/3 %一致性指标CR=CI/0.90 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =4.0104W =0.45540.26280.14090.1409B =0.43950.27870.14090.1409CI =0.0035CR =0.0038C =0.3131附录6:x=[1 2 2;1/2 1 1/2;1/2 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-3)/2 %一致性指标CR=CI/0.58 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =3.0536W =0.49340.19580.3108B =0.46060.18790.3515CI =0.0268CR =0.0462C =0.3733附录7:x=[1 3 2;1/3 1 1/2;1/2 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-3)/2 %一致性指标CR=CI/0.58 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =3.0092W =0.53960.16340.2970B =0.51990.16200.3181CI =0.0046CR =0.0079C =0.4015附录8:% 目标层Q,Y对子准则层C1的赋值>> x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C2的赋值x=[1 5;1/5 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.83330.1667B =0.83330.1667CI =CR =NaNC =0.7222End% 目标层Q,Y对子准则层C3的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C4的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.80000.2000B =0.80000.2000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C5的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.66670.3333B =0.66670.3333CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C6的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C7的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.20000.8000B =0.20000.8000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C8的赋值x=[1 5;1/5 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.16670.8333B =0.16670.8333CI =CR =NaNC =0.7222End% 目标层Q,Y对子准则层C9的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C10的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =NaNC =0.5000% 目标层Q,Y对子准则层C11的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.25000.7500B =0.25000.7500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C12的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =W =0.80000.2000B =0.80000.2000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C13的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000% 目标层Q,Y对子准则层C14的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C15的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.20000.8000B =0.20000.8000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C16的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C17的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C18的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C19的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000附录9:% 最终组合权向量:x=[0.75 0 0 0 0 0;0.25 0 0 0 0 0;0 0.2625 0 0 0 0;0 0.0618 0 0 0 0;0 0.4185 0 0 0 0;0 0.1599 0 0 0 0;0 0.0973 0 0 0 0;0 0 0.5 0 0 0;0 0 0.5 0 0 0;0 0 0 0.4554 0 0;0 0 0 0.2628 0 0;0 0 0 0.1409 0 0;0 0 0 0.1409 0 0;0 0 0 0 0.4934 0;0 0 0 0 0.1958 0;0 0 0 0 0.3108 0;0 0 0 0 0 0.5396;0 0 0 0 0 0.1634;0 0 0 0 0 0.2970]x =0.7500 0 0 0 0 00.2500 0 0 0 0 00 0.2625 0 0 0 00 0.0618 0 0 0 00 0.4185 0 0 0 00 0.1599 0 0 0 00 0.0973 0 0 0 00 0 0.5000 0 0 00 0 0.5000 0 0 00 0 0 0.4554 0 00 0 0 0.2628 0 00 0 0 0.1409 0 00 0 0 0.1409 0 00 0 0 0 0.4934 00 0 0 0 0.1958 00 0 0 0 0.3108 00 0 0 0 0 0.53960 0 0 0 0 0.16340 0 0 0 0 0.2970y=[0.0492;0.2057;0.2057;0.3422;0.0753;0.1219]y =0.04920.20570.20570.34220.07530.1219z=x*y运算结果:z =0.03690.01230.05400.01270.08610.03290.02000.10290.10290.15580.08990.04820.04820.03720.01470.02340.06580.01990.0362a=[0.3333 0.8333 0.75 0.2 0.3333 0.75 0.2 0.1667 0.3333 0.5 0.25 0.8 0.5 0.75 0.2 0.75 0.3333 0.3333 0.5;0.6667 0.1667 0.25 0.8 0.6667 0.250.8 0.8333 0.6667 0.5 0.75 0.2 0.5 0.25 0.8 0.25 0.6667 0.6667 0.5]a =Columns 1 through 70.3333 0.8333 0.7500 0.2000 0.3333 0.7500 0.20000.6667 0.1667 0.2500 0.8000 0.6667 0.2500 0.8000Columns 8 through 140.1667 0.3333 0.5000 0.2500 0.8000 0.5000 0.75000.8333 0.6667 0.5000 0.7500 0.2000 0.5000 0.2500Columns 15 through 190.2000 0.7500 0.3333 0.3333 0.50000.8000 0.2500 0.6667 0.6667 0.5000c=a*z运算结果:c =0.43250.5675。


构建风险层次结构通过选取的指标可以看出这是一个多目标的且问题涉及到许多因素,各种因素的作用相互,情况复杂。
依据层次分析法处理这类复杂的问题就需要对所涉及的因素指标进行分析:哪些是需相互比较的;哪些是需相互影响的。
把那些需相互比较的因素归成同一类,构造出一个各因素类之间相互联结的层次结构模型。
各因素类的层次级别由其与目标的关系而定:第一层是目标层,也就是国家风险的评价排序第二层是准则层,这一层中是国家风险排序所涉及的国家风险类型,即政治风险、经济风险、社会风险。
第三层是子准则层,这一层是评价衡量准则层中各要素的影响因素及评价指标,即政权凝聚力、腐败状况、相关法律政策、国际关系、官僚主义、经济政策、汇率稳定性、金融环境、内部冲突、外部冲突、民族差异等。
第四层也就是我们要选择的方案即所要选择的并购方案国家。
图5.1风险层次结构模型Fig.5.1 The hierarchical structure model of country risk为了方便计算以及模型的理解,层次结构中各层次均用字母代替,目标层为iA ,准则层为B i ,子准则层为C i ,方案层为D i 。
5.2.2 重要性程度描述为了将上述复杂的多因素综合比较问题转化为简单的两因素相对比较问题。
首先找出所有两两比较的结果,并且把它们定量化;然后再运用适当的数学方法从所有两两相对比较的结果之中求出多因素综合比较的结果。
进行定性的成对比较时,我们将比较结果分为5种等级:相同、稍强、强、明显强、绝对强并将我们所做出的比较结果应用1~9个数字尺度来进行定量化,比较具体含义及相应数字对应如下表:表5.2 AHP重要程度描述表Table 5.2 Described table of AHP important degree 定性比较结果数字定量因素1相较于因素2具有相同的重要性 1因素1与因素2相比,前者重要性稍强 3因素1与因素2相比,前者重要性强 5因素1与因素2相比,前者重要性明显强7因素1与因素2相比,前者重要性绝对强9因素1与因素2相比,相对重要性处于上述等级之间2、4、6、8(续表5.2)定性比较结果数字定量因素1与因素2相比,后者的重要性要稍强、强、明显强、绝对强于前者1/3、1/5、1/7、1/9例如:在准则层中有三个因素政治风险B1、经济风险B2以及社会风险B3,假设如果政治风险B1相较于经济风险B2在风险中的重要性稍强那么就是B1:B2=3:1也就是3。


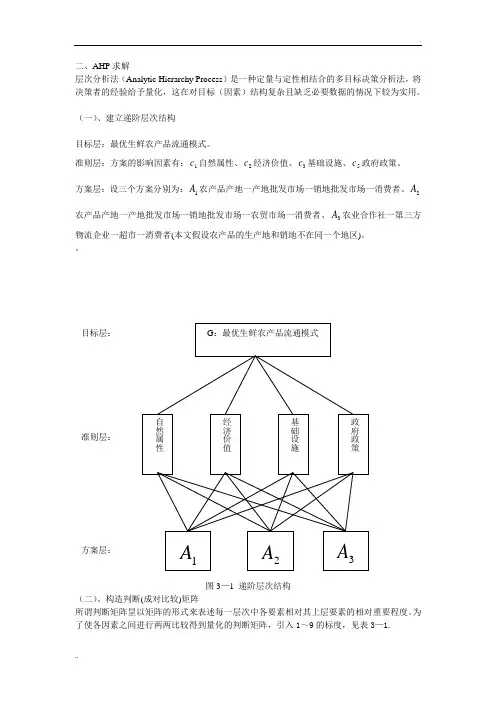
二、AHP 求解层次分析法(Analytic Hierarchy Process )是一种定量与定性相结合的多目标决策分析法,将决策者的经验给予量化,这在对目标(因素)结构复杂且缺乏必要数据的情况下较为实用。
(一)、建立递阶层次结构目标层:最优生鲜农产品流通模式。
准则层:方案的影响因素有:1c 自然属性、2c 经济价值、3c 基础设施、5c 政府政策。
方案层:设三个方案分别为:1A 农产品产地一产地批发市场一销地批发市场一消费者、2A 农产品产地一产地批发市场一销地批发市场一农贸市场一消费者、3A 农业合作社一第三方物流企业一超市一消费者(本文假设农产品的生产地和销地不在同一个地区)。
。
图3—1 递阶层次结构(二)、构造判断(成对比较)矩阵所谓判断矩阵昰以矩阵的形式来表述每一层次中各要素相对其上层要素的相对重要程度。
为了使各因素之间进行两两比较得到量化的判断矩阵,引入1~9的标度,见表3—1.目标层:准则层:方案层:表3—1 标度值为了构造判断矩阵,作者对6个专家进行了咨询,根据专家和作者的经验,四个准则下的两两比较矩阵分别为:(三)、层次单排序及其一致性检验层次单排序就是把本层所有要素针对上一层某一要素,排出评比的次序,这种次序以相对的数值大小来表示。
对应于判断矩阵最大特征根λmax的特征向量,经归一化(使向量中各元素之和等于1)后记为W。
W的元素为同一层次因素对于上一层次因素某因素相对重要性的排序权值,这一过程称为层次单排序。
能否确认层次单排序,需要进行一致性检验,所谓一致性检验是指对A确定不一致的允许范围。
a,则λ比n 大的越多,A 的不一致性越严重。
用最大特征值对由于λ连续的依赖于ij应的特征向量作为被比较因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。
因而可以用λ―n数值的大小来衡量 A 的不一致程度。
用一致性指标进行检验:max 1nCI n λ-=-。
其中max λ是比较矩阵的最大特征值,n 是比较矩阵的阶数。
关于层次分析法的例题与解旅游发展水平评价摘要为了研究和比较两个旅游城市的旅游发展水平,建立了层次分析法[数学模型,对两个旅游城市的旅游发展水平进行了评价.首先,通过对本课题中图1和表1的分析和讨论,按照层次分析法,建立了四个层次:目标层a、准则层b、子准则层c和方案层d,通过比较同一层目标之间的重要度,得到判断矩阵,每个判断矩阵用MATLAB[1]编程求解。
其次,利用MATLAB软件计算决策组合向量,然后比较决策组合向量的大小。
以“最大决策组合向量”为目标,Y市的决策组合向量为0.4325,Q市的决策组合向量为0.5675。
最后,通过比较q市和y市旅游发展水平的决策组合向量,得出q市旅游发展水平较高的结论。
层次分析法MATLAB旅游发展水平;决策组合向量11.问题重述本文要求对Y和Q两个旅游城市的旅游发展水平进行分析,并对两个城市的各种因素进行比较,如城市规模和密度、经济条件、交通条件、生态环境条件、宣传监督、旅游规格、空气质量、城市规模、人口密度、人均国内生产总值、人均住房面积、第三产业增加值占国内生产总值的比重、税收国内生产总值、对外贸易依存度、城市内外交通、人均绿地等。
污水集中处理率、环境噪声、国内外游客数量、索赔金额、立案数量、甲级景区数量、旅行社数量、星级酒店数量。
建立数学模型来解决这个问题。
2.问题分析本文要求对Y、Q旅游城市的旅游业发展水平进行分析。
在对Y和Q 旅游城市的分析中,发现有许多因素需要考虑。
首先,城市规模和密度,包括城市规模和人口密度。
第二,经济条件,包括对外贸易依存度,人均国内生产总值,人均住房面积,第三产业增加值占国内生产总值的比重,税收占国内生产总值的比重。
第三,运输条件,包括内部运输和外部运输。
第四,生态环境条件包括空气质量、人均绿地面积、污水处理能力和环境噪声。
第五,宣传和监督,包括国内外游客人数,以及游客投诉的数量。
第六,旅游指标,包括甲类景区的数量、旅行社的数量、星级酒店的数量,用层次分析法来估计各指标的权重,并对最优方案进行评价。
层次分析法例题专题:层次分析法一般情况下,物流系统的评价属于多目标、多判据的系统综合评价。
如果 仅仅依靠评价者的定性分析和逻辑判断,缺乏定量分析依据来评价系统方案的 优劣,显然是十分困难的。
尤其是物流系统的社会经济评价很难作出精确的定 量分析°层次分析法(Analytical Hierarchy Process)由美国著名运筹学家萨蒂(T.L. Saaty)于1982年提出,它综合了人们主观判断,是一种简明、实用的定性 分析与定量分析相结合的系统分析与评价的方法。
目前,该方法在国内已得到 广泛的推广应用,广泛应用于能源问题分析、科技成果评比、地区经济发展方 案比较,尤其是投入产出分析、资源分配、方案选择及评比等方面。
它既是一 种系统分析的好方法,也是一种新的、简洁的、实用的决策方法。
♦层次分析法的基本原理人们在日常生活中经常要从一堆同样大小的物品中挑选出最重的物品。
这 时,一般是利用两两比较的方法来达到目的。
假设有n 个物品,其真实重量用 W1 , W2,--W n 表示。
要想知道W1 , W2,--W n 的值,最简单的就 是用秤称出它 们的重量,但如果没有秤,可以将几个物品两两比较,得到它们的重量比矩阵 A 。
W/叫/讥zWVV.VVPW/1V如果用物品重量向量W=[W1,W2右乘矩阵A,则有:由上式可知,n 是A 的特征值,W 是A 的特征向量。
根据矩阵理论, 矩阵A 的唯一非零解,也是最大的特征值。
这就提示我们,可以利用求物/W2 /W2叫/W]叫/叫/W]W1"'2/ W] W’r / us• • •/w” • • •■nw 2/ W]叫/ “2 叫=nW品重量比判断矩阵的特征向量的方法来求得物品真实的重量向量W。
从而确定最重的物品。
将上述n个物品代表n个指标(要素),物品的重量向量就表示各指标(要素)的相对重要性向量,即权重向量;可以通过两两因素的比较,建立判断矩阵,再求出其特征向量就可确定哪个因素最重要。
层次分析法例题专题:层次分析法一般情况下,物流系统的评价属于多目标、多判据的系统综合评价。
如果仅仅依靠评价者的定性分析和逻辑判断,缺乏定量分析依据来评价系 统方案的优劣,显然是十分困难的。
尤其是物流系统的社会经济评价很难 作出精确的定量分析。
层次分析法(Analytical Hierarchy Process )由美国著名运筹学家萨蒂 (T .L . Saaty )于1982年提出,它综合了人们主观判断,是一种简明、实 用的定性分析与定量分析相结合的系统分析与评价的方法。
目前,该方法 在国内已得到广泛的推广应用,广泛应用于能源问题分析、科技成果评 比、地区经济发展方案比较,尤其是投入产出分析、资源分配、方案选择 及评比等方面。
它既是一种系统分析的好方法,也是一种新的、简洁的、 实用的决策方法。
♦层次分析法的基本原理人们在日常生活中经常要从一堆同样大小的物品中挑选出最重的物 品。
这时,一般是利用两两比较的方法来达到目的。
假设有 n 个物品,其 真实重量用w 1 , w 2,…W n 表示。
要想知道w 1 , w 2,…W n 的值,最简单的就 是用秤称出它们的重量,但如果没有秤,可以将几个物品两两比较,得到 它们的重量比矩阵A 。
如果用物品重量向量W=[w 1 , w 2 ,…W n ]T 右乘矩阵A ,则有:矩阵A 的唯一非零解,也是最大的特征值。
这就提示我们,可以利用求物/ w 2 / w 2V V ■叫/叫W /叫/讥zWV V PW /1V由上式可知, n 是A 的特征值,W 是A 的特征向量。
根据矩阵理论,品重量比判断矩阵的特征向量的方法来求得物品真实的重量向量W。
从而确定最重的物品。
将上述n个物品代表n个指标(要素),物品的重量向量就表示各指标(要素)的相对重要性向量,即权重向量;可以通过两两因素的比较,建立判断矩阵,再求出其特征向量就可确定哪个因素最重要。
依此类推,如果n个物品代表n 个方案,按照这种方法,就可以确定哪个方案最有价值。
♦应用层次分析法进行系统评价的主要步骤如下:(1)将复杂问题所涉及的因素分成若干层次,建立多级递阶的层次结构模型(目标层、判断层、方案层)。
(2)标度及描述。
同一层次任意两因素进行重要性比较时,对它们的重要性之比做出判断,给予量化。
(3)对同属一层次的各要素以上一级的要素为准则进行两两比较,根据评价尺度确定其相对重要度,据此构建判断矩阵A。
(4)计算判断矩阵的特征向量,以此确定各层要素的相对重要度(权重)。
(5)最后通过综合重要度(权重)的计算,按照最大权重原则,确定最优方案。
某物流企业需要采购一台设备,在采购设备时需要从功能、价格与可维护性三个角度进行评价,考虑应用层次分析法对3个不同品牌的设备进行综合分析评价和排序,从中选出能实现物流规划总目标的最优设备,其层次结构如下图所示。
以A表示系统的总目标,判断层中B i表示功能,B2表示价格,B3表示可维护性。
C i , C2 , C3表示备选的3种品牌的设备解题步骤:目标层判断层功能B i价格B2维护性B3W r产品C i产品C2产品C3购买设备A图设备采购层次结构图1、标度及描述人们定性区分事物的能力习惯用5个属性来表示,即同样重要、稍微重要、较强重要、强烈重要、绝对重要,当需要较高精度时,可以取两个相邻属性之间的值,这样就得到9个数值,即9个标度。
为了便于将比较判断定量化,引入1〜9比率标度方法,规定用1、3、5、7、9分别表示根据经验判断,要素i与要素j相比:同样重要、稍微重要、较强重要、强烈重要、绝对重要,而2、4、6、8表示上述两判断级之间的折衷值。
注:a jj表示要素i与要素j相对重要度之比,且有下述关系:a ij=1/a ji ;a i=1 ;i, j=1 , 2,…,n 显然,比值越大,则要素i的重要度就越高。
2、构建判断矩阵A判断矩阵是层次分析法的基本信息,也是进行权重计算的重要依据。
根据结构模型,将图中各因素两两进行判断与比较,构造判断矩阵:•判断矩阵A B(即相对于物流系统总目标,判断层各因素相对重要性比较)如表1所示;•判断矩阵B1 C (相对功能,各方案的相对重要性比较)如表2所示;•判断矩阵B2 C (相对价格,各方案的相对重要性比较)如表3所示;•判断矩阵B3 C (相对可维护性,各方案的相对重要性比较)如表4所示。
表1判断矩阵A B表2判断矩阵B1 C2 C2311/3 C3531表3判断矩阵B2-CB2C1C2C3 C1127 C21/215 C31/71/51表4判断矩阵B3 CB3C1C2C3 C1131/7 C2l/311/9C3791、计算各判断矩阵的特征值、特征向量及一致性检验指标一般来讲,在AHP法中计算判断矩阵的最大特征值与特征向量,必不需要较高的精度,用求和法或求根法可以计算特征值的近似值。
•求和法1)将判断矩阵A按列归一化(即列元素之和为1): b j= a j/逊;2)将归一化的矩阵按行求和:C i=Ib ij (i=1 , 2, 3….n);3)将C i归一化:得到特征向量W= (w1, w2,…W n)T, W i=C i /艺i C, W即为A的特征向量的近似值;4)求特征向量W对应的最大特征值:sax•求根法1)计算判断矩阵A每行元素乘积的n次方根;w i2) _________________________ 将W i归一化,得到w i n ;W= (w1,w2,…w n) T即为A的特w ii 1征向量的近似值;3)求特征向量W对应的最大特征值:(1)判断矩阵A B的特征根、特征向量与一致性检验(i =1,①计算矩阵A B的特征向量。
计算判断矩阵A B各行元素的乘积M i,并求其n次方根,如1 2 一 _____ __________________________ ______Mi 1 2,Wi3Mi 0.874,类似地有,W2 3M2 2.466,3 3W3 3M;0.464。
对向量W [W i,W2,, W n]T规范化,有XA/ W0.874 ccccW 7 0.230n W 0.874 2.466 0.464i类似地有W2 0.684,W3 0.122。
所求得的特征向量即为:W [0.230, 0.648, 0.122]T②计算矩阵A B的特征根1 1/3 2AW 3 1 5 [0.230, 0.648, 0.122]T1/2 1/5 11AW1 1 0.230 - 0.648 2 0.122 0.693类似地可以得到AW2 1.948,AW3 0.3666按照公式计算判断矩阵最大特征根:③一致性检验。
实际评价中评价者只能对A进行粗略判断,这样有时会犯不一致的错误。
如,已判断。
比6重要,6比$较重要,那么,C1应该比C3更重要如果又判断0比。
3较重要或同等重要,这就犯了逻辑错误。
这就需要进行一致性检验。
根据层次法原理,利用A的理论最大特征值£ax与n之差检验一致性。
一致性指标:时,判断矩阵的一致性可以接受,否则重新两两进行比较)表5平均随机一致性指标阶数34567891011121314 RI0.580.89 1.12:1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58(2)判断矩阵B1 C的特征根、特征向量与一致性检验类似于第(1)步的计算过程,可以得到矩阵B i C的特征根、特征向量与一致性检验如下:maxn(AW)ji 1 nW0.69 1.9483 0.230 3 0.6480.36663 0.1223.004n n 1随机一致性指标(表计算CI30节O.。
02®, CR CI 0.003 0.1,查同阶平均5 所示)知RI 0.58,(一般认为Cl<0.1、CR<0.1maxW [0.105, 0.258, 0.637]T,max 3.039,CR 0.033 0.1(3) 判断矩阵B2 C的特征根、特征向量与一致性检验类似于第(1)步的计算过程,可以得到矩阵刀:一C的特征根、特征向量与一致性检验如下:W [0.592, 0.333, 0.075]T,max 3.014,CR 0.012 0.1(4) 判断矩阵B3 C的特征根、特征向量与一致性检验类似于第(1)步的计算过程,可以得到矩阵B3 C的特征根、特征向量与一致性检验如下:W [0.149, 0.066, 0.785]T,max 3.08,CR 0.069 0.14、层次总排序获得同一层次各要素之间的相对重要度后,就可以自上而下地计算各级要素对总体的综合重要度。
设二级共有m个要素c1, q,…,m,它们对总值的重要度为W2,…,w m;她的下一层次三级有》P2,…卫共门个要素,令要素P i对C j的重要度(权重)为V ij,则三级要素P i的综合重要度为:眄二工叫SJ方案C1的重要度(权重)=0.230 迥.105+0.648 (X529+0.122 0.149=0.426方案C2的重要度(权重)=0.230 迥.258+0.648 (X333+0.122 0.066=0.283方案C3的重要度(权重)=0.230 ..637+0.648 .075+0.122 0.785=0.291依据各方案综合重要度的大小,可对方案进行排序、决策。
层次总排序如表6所示。
表6层次总排序5、结论由表5可以看出,3种品牌设备的优劣顺序为:C1, C3, C2,且品牌1 明显优于其他两种品牌的设备。
作业:某配送中心的设计中要对某类物流装备进行决策,现初步选定三种设备配套方 案,应用层次分析法对优先考虑的方案进行排序。
解:对设备方案的判断主要可以从设备的功能、成本、维护性三方面进行评价。
当然,如何评价功能、维护性等,还会用更细一级的指标来衡量。
这里为分析的简 便,省略了更详细的指标。
这样,可建立对设备方案进行比较的层次分析结构图,如 图:根据以往经验和相关调查结果显示:相关指标两两比较的结果如下 重要度C l C 2 C 3C 115 3判据/指标层方案层。